圖像分割引導的散堆工件結構光三維位姿估計
2024-01-01 00:00:00鄧君李娜王亞凱高振國
華僑大學學報(自然科學版) 2024年6期








摘要: 針對散堆工件場景中點云生成耗時久、位姿估計困難、多類工件混合情形難處理等問題,提出圖像分割引導的散堆工件結構光三維位姿估計方法,并基于JAkA Zu3 6-DoF機器人開發散堆工件抓取實驗系統。采用YOLACT模型獲取散堆工件圖像中的工件信息,通過自適應閾值篩選待抓取工件,利用雙目結構光生成目標工件所在區域的局部點云,并基于投票匹配算法和迭代最近鄰算法估計工件位姿。通過搭建的實驗系統對文中方法進行測試。實驗結果表明:系統完成目標工件位姿估計時間約為3.641 s,其中,點云計算需0.536 s,點云配準需0.446 s;與其他方法相比,文中方法平均可縮小點云規模44%,點云生成時間平均縮減24%,配準成功率提升至100%。
關鍵詞: 雙目結構光; 點云生成; 點云配準; 位姿估計; 圖像分割
中圖分類號: TP 391文獻標志碼: A"" 文章編號: 1000-5013(2024)06-0696-10
Structured Light-Based 3D Pose Estimation of Piled Workpieces Guided by Image Segmentation
DENG Jun1,2, LI Na2,3, WANG Yakai1,2, GAO Zhenguo1,2
(1. College of Computer Science and Technology, Huaqiao University, Xiamen 361021, China;
2. Key Laboratory of Computer Vision and Machine Learning, Huaqiao University, Xiamen 361021, China;
3. College of Mechanical and Electrical Engineering, Huaqiao University, Xiamen 361021, China)
Abstract: Aiming at the problems of point cloud generation time-consuming, pose estimation difficulty, and multi class workpiece mixing difficult handling in the scene of piled workpieces, a" structured light-based 3D pose estimation of piled workpieces guided by image segmentation is proposed, and an experimental system of piled workpiece picking is developed based on the JAkA Zu3 6-DoF robot. The YOLACT model is used to extract workpiece information from the piled workpieces images. The workpiece to be grabbed is filtered through adaptive threshold, the local point clouds in the area where the target workpiece is generated using binocular structured light. The workpiece pose based on the voting matching algorithm and the iterative nearest neighbor algorithm is estimated. The proposed method is tested by the constructed experimental system. The experimental results show that the system takes approximately 3.641 s to complete the target workpiece pose esti-mation. Among them, point cloud computing takes 0.536 s and point cloud registration takes 0.446 s. Compared with other methods, the proposed method can reduce the size of point clouds by an average of 44%, reduce the time of the point clouds generation by an average of 24%, and improve the registration success rate to 100%.
Keywords:binocular structured light; point cloud generation; point cloud registration; pose estimation; image segmentation
散堆工件分揀是工業生產中的常見任務,散堆工件分揀系統需要檢測工件,對工件進行三維點云生成(三維重建)和位姿估計,再控制機械臂完成抓取。目標工件三維點云生成和位姿估計是整個系統至關重要的部分。
三維點云生成方法可以分為主動式與被動式兩種。被動式方法不與場景交互,通過相機采集場景圖片,根據圖像的紋理分布等信息恢復深度信息,進而生成點云[1-2]。雙目視覺利用左、右相機對同一場景拍攝的圖像進行特征點匹配,獲得視差,進而獲得三維點云。該方法難點在于左、右圖片像素點的匹配,匹配精確度會直接影響生成點云的效果。主動式方法通過傳感器主動向場景照射信號,通過解析返回的信號計算場景的三維信息[3-4]。主動式方法能夠提供高質量的三維數據,但通常需要更多的傳感器[5]。結構光三維點云生成技術通過主動投射編碼圖案,更好地實現更多像素點的匹配,從而形成高密度三維點云。
對于機器人工件分揀系統,不僅需要檢測工件,還需要估計工件的位姿。傳統的位姿估計方法依賴于深度圖或與RGB圖像結合使用[6-13]。這類方法難于處理散堆工件之間遮擋問題,因此大多數姿態估計方法是基于點云進行的。目前,基于點云的目標位姿估計方法主要分為基于卷積神經網絡(CNN)的方法和基于特征的方法。CNN在點云領域中已被廣泛應用[14-20],基于特征的方法十分依賴于特征點,若物體缺乏明顯的特征點,使得特征提取不準確,則位姿估計會受影響[21-33]。
上述方法在處理復雜場景時需要重建整個場景,這不僅會消耗大量時間和資源,還會生成大量冗余點,導致后續計算效率低、所需存儲空間大等問題。針對這些問題,本文對圖像分割引導的散堆工件結構光三維位姿估計進行研究[34-35]。
1 系統設計
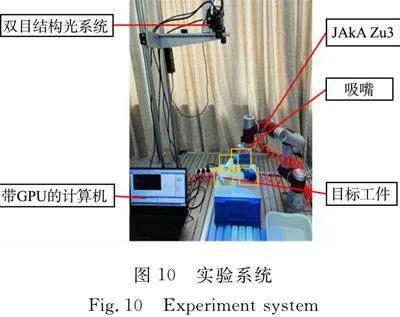
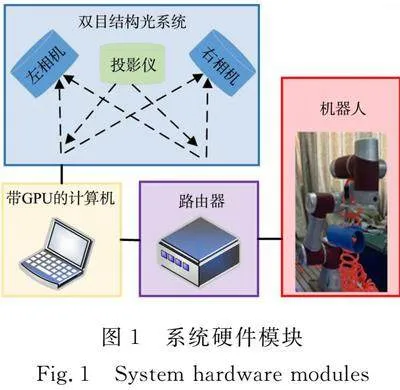
雙目結構光系統中的左、右相機和投影儀分別通過USB接口和HDMI接口與計算機連接,計算機通過路由器與機器人連接。系統硬件模塊,如圖1所示。
系統架構主要由5個模塊組成:點對特征庫構建模塊、YOLACT訓練模塊、雙目結構光局部點云生成模塊、位姿估計模塊、機械臂抓取模塊。其中,前兩個模塊構成系統離線準備部分,后3個模塊構成系統在線運行部分。系統架構,如圖2所示。
散堆工件圖像庫存儲了1 000幅利用Labelme標注的散堆工件圖片,圖片用于訓練YOLACT網絡模型。系統需要操作的各類型工件由預先準備的系統工件類型模型決定。工件類型模型為相應類型標準工件的三維點云集合,存儲于工件類型模型庫中。為進行點云匹配位姿估計,計算每個工件類型的模型點云的點對特征集合,并用該集合作為相應類型工件模型的特征模型,存儲于模型點對特征庫中。
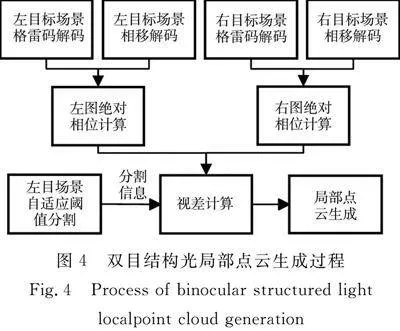
雙目結構光局部點云生成模塊包含工件篩選、結構光投影、點云計算3個環節。該模塊通過雙目系統中的左目相機拍攝散堆工件場景圖像,利用YOLACT模型對圖像進行實例分割,通過自適應閾值篩選出所有適合抓取的工件。在點云生成過程中,雙目結構光系統通過投影儀將編碼圖案投影在散堆工件上,利用雙目相機捕獲帶有編碼圖案的場景圖像,生成所有適合抓取工件處的局部點云。在位姿估計模塊,根據YOLACT輸出的工件類別信息,在模型點對特征庫中找到對應的模型,先后通過位姿粗配準與精配準獲取工件位姿,從而指導機械臂抓取工件。工件位姿估計過程,如圖3所示。圖3(d)中:藍色點云為模型點云。
2 雙目結構光局部點云
雙目結構光局部點云生成過程中,通過雙目相機同步采集投影儀投射編碼圖案后的散堆工件場景圖片。隨后,通過解碼計算每個像素點的絕對相位[36],結合篩選出適合抓取工件的分割信息計算目標工件區域視差。為提高重建速度,減小點云規模,在計算目標工件區域內每行像素點對應的視差時,每隔n個像素點計算一次視差,生成視差圖,進而轉換為點云。雙目結構光局部點云生成過程,如圖4所示。
YOLACT模型對散堆工件場景圖像實例分割時,存在分割被遮擋工件的情況。為從實例分割結果中篩選出適合抓取工件的部分,引入了閾值策略。把標準工件水平放置,通過相機拍攝標準工件獲取其二維圖像,由YOLACT進行實例分割。YOLACT把圖像像素分為工件內部、工件邊緣和工件外部3類。需要把工件邊緣像素歸類入工件內部和工件外部,為此計算工件內部像素點的平均灰度值F,再計算對應工件邊緣像素點的灰度值g。若glt;F/2,則將邊緣像素點歸入工件外部像素點,反之,歸入工件內部像素點。計算工件內部像素數量,并以此值的70%作為閾值來篩選適合抓取的工件。當同類型工件內部像素數量超過該閾值時,認為該工件適合抓取,反之,則刪除該工件的信息。散堆工件場景圖像原始分割結果與篩選結果,如圖5所示。
2.1 混合結構光編碼方案
為減少結構光投影時間,采用格雷碼與相移碼相結合的結構光編碼方式,共投射p幅格雷碼圖案,q幅相移碼圖案,以左相機為例,左相機采集的結構光投影場景圖片,如圖6所示。
經過格雷碼編解碼,p位格雷碼將整個圖像劃分為2p個區域,每個區域內像素點的格雷碼值相同。相移圖案是周期性圖案,在一個周期內,相位值是連續且唯一的。把相移碼周期長度和每個區域長度設為相同,通過格雷碼與相移碼混合編碼得到的每個像素點的絕對相位ψ為
ψ=2kπ+φ。(1)
式(1)中:k為像素位置的格雷碼值;φ為像素位置的相位值。
通過混合編碼,可進一步區分每個區域內的像素點。格雷碼解碼時,為避免環境中陰影區域解碼的錯誤二值化,通過投影正、反格雷碼圖案,計算帶正、反格雷碼圖案灰度差值的方式,進行圖像二值化。設I(x,y)為投影格雷碼時圖像中位置(x,y)處的像素灰度值(光強),Ir(x,y)為投影反格雷碼圖案時圖像中位置(x,y)處的光強,若I(x,y)≥Ir(x,y),則認為該位置對應格雷碼亮條紋,二值化為1;若I(x,y)lt;Ir(x,y),則認為該位置對應格雷碼暗條紋,二值化為0。對拍攝的所有帶格雷碼圖案的場景圖片進行上述解碼過程,就可得到每個位置的格雷碼值。
相移碼解碼的目的是從捕獲的帶相移碼的場景圖像計算每個像素點的相位值。投射的相移圖案為灰度條紋,光強表達式為
I(x,y)=a(x,y)+b(x,y)cos(φ(x,y)+φi)。(2)
式(2)中:a(x,y)為背景光強;b(x,y)為調制強度;φ(x,y)表示相位值;φi表示相移值。
以4步相移法為例,在一個2π周期內,相位每次移動幅度為π/2。第i副圖像的光強為I1(x,y)=a(x,y)+b(x,y)cos(φ(x,y)),I2(x,y)=a(x,y)+b(x,y)cosφ(x,y)+π2,I3(x,y)=a(x,y)+b(x,y)cos(φ(x,y)+π),I4(x,y)=a(x,y)+b(x,y)cosφ(x,y)+3π2。
每個像素點的相位為
φ(x,y)=arctanI4(x,y)-I2(x,y)I1(x,y)-I3(x,y)。(3)
2.2 縮減像素點匹配搜索范圍
左、右場景圖案解碼后,為左圖像的像素點在右圖像中尋找匹配點時,可以搜索所有像素點,但這樣效率較低。為節省資源開銷,基于YOLACT輸出的工件分割信息,只對工件內部像素點進行匹配,并利用極線約束,將搜索范圍縮小為右圖像對應的極線,再通過延伸工件包絡框邊界,進一步將匹配范圍縮小為對應極線中的一段。
為簡化極線的計算,先對左、右圖片進行極線校正。極線校正把兩幅原始圖像轉化為兩幅新圖像。這兩幅新圖像中,對應極線均在與橫軸平行的同一直線上,即兩幅圖像中互相匹配的像素點具有相同的縱坐標。
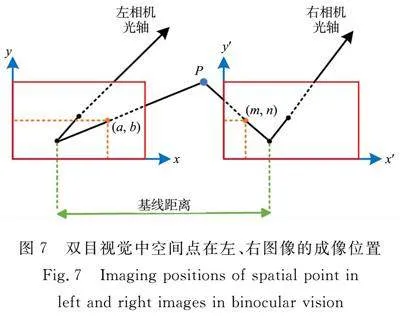
雙目視覺中空間點在左、右圖像的成像位置,如圖7所示。圖7中:P在極線校正后的左、右圖像上的坐標分別為(a,b),(m,n);兩個紅色方框代表極線校正后的左、右圖像平面,以圖像的左邊界為x方向的零起始邊;左圖像中的像素位置(a,b)在x方向上相對于右圖像中的像素位置(m,n)更靠右,即agt;m,且圖像極線校正后使得b=n,因此,把右目圖像中搜索匹配點的范圍縮減為第b行中[0,a]區間。右圖工件包絡框獲取過程,如圖8所示。
由圖8可知:左圖分割得到的掩膜和包絡框可以覆蓋右圖對應工件的大部分區域;通過計算雙目系統拍攝圖像的最大視差v,在右圖上將包絡框的左邊界向左延伸(v+c)個像素點,其中,c是為保證匹配的準確性而額外延伸的像素數量;延伸后的包絡框就可包含左圖工件區域內像素點對應的匹配點,左圖點(a,b)的匹配范圍縮減為右圖像對應極線中[0,a]區間。通過延伸包絡框邊界,進一步將匹配點搜索范圍縮減為[h,a]區間,其中,h為原包絡框左邊界所在像素點位置向左延伸(v+c)個像素點后的左邊界位置。
3 位姿估計
3.1 模型數據庫
獲取工件模型點云有兩種方式:一是通過工件的CAD模型轉換為點云,將降采樣后的點云作為工件模型點云;二是將雙目結構光生成的工件稀疏點云通過Cloud Compare軟件進行去噪和平滑等處理,將處理后的點云作為工件模型點云。
將工件模型點云轉換為PPF特征,并用該特征作為相應類型工件模型的特征模型,以工件類型為索引構建模型點對特征庫。每個模型都包含一個從PPF特征到具有相似特征的點對集合的映射,該映射關系采用哈希表存儲。
PPF特征是一個4維向量,用于表示兩個空間點p1和p2之間的相對位置和方向關系,即
PPF(p1,p2)=[d2,n1,n2,u]。(4)
式(4)中:d為p1到p2的方向向量;d2為p1和p2之間的歐氏距離;n1和n2分別為p1和p2處的法向量與向量d之間的夾角;u為p1和p2處的兩法向量之間的夾角。
3.2 基于投票匹配和迭代最近鄰位姿的估計
位姿估計過程,如圖9所示。
首先,使用直通濾波定義點云的有效范圍,去除離群點云。接著,通過移動最小二乘法濾波平滑點云,以減少噪聲影響,提高匹配的穩定性。隨后,計算工件點云的點對特征集合,并以工件類別信息為索引找到對應模型進行配準。最后,通過投票匹配和ICP算法估計工件位姿。
設M為模型點云的點對特征,S為環境點云的點對特征,模型點云的點對特征(PPFΘ(pn,pm))和場景點云的點對特征(PPFΩ(qj,qk))為
M={PPFΘ(p1,p2),…,PPFΘ(pn,pm)},S={PPFΩ(q1,q2),…,PPFΩ(qj,qk)}。(5)
根據YOLACT得到的工件種類信息,可以在模型點對特征庫中選擇對應的模型,并為每個場景點建立投票箱。比較模型點對(pn,pm)和場景點對(qj,qk)的特征向量,若相似,則為該模型點投票。對場景點構建的所有點對特征集合完成投票后,將投票數(f)的最大值作為匹配點的權值oi,即
oi=Max(f1,f2,…,fm)。(6)
為所有場景點獲取匹配結果后,可以得到多個位姿,將相似的位姿結果分配到相同的簇中。計算簇中所有位姿投票數的總和作為該簇的總得分(Wn),即
Wn=∑nuj=1∑nji=1oi。(7)
式(7)中:nu為簇中的位姿個數;nj為場景點個數。
選擇總得分最高的簇,并計算其聚類中心的對應位姿,作為粗配準位姿結果。首先,計算所有位姿的位置向量的平均值來求解位置均值,其次,計算該簇聚類中心對應的旋轉矩陣(A),即
A=1nu∑nui=1wi(uTi×ui)。(8)
式(8)中:ui為位姿的旋轉矩陣;wi為位姿的權重。
通過投票匹配和位姿聚類,得到了模型點云到場景點云的初始變換矩陣。使用ICP算法[33]進一步精細調整,減少點云對應點匹配的距離誤差。
4 實驗驗證
4.1 散堆工件抓取實驗系統
通過測試系統抓取工件的平均耗時、平均點云生成時間、配準成功率和平均配準時間驗證方法的整體性能。
平均耗時為系統抓取目標工件過程中各環節單次所耗平均時間;平均點云生成時間與平均配準時間為獲取單個工件位姿所需點云生成時間和配準時間;配準成功率為實驗中位姿估計成功次數所占比例。
搭建的散堆工件抓取實驗系統(圖10)包含標準工業6-DoF機器人JAkA Zu3、末端執行器、雙目結構光系統、帶高性能圖形處理單元(GPU)的計算機。系統采用吸嘴作為末端執行器,結合氣泵、電磁閥和繼電器完成抓取。吸嘴由于其工作原理,需要接觸面平滑,且吸嘴工作時吸力較小,因此,將抓取點選在工件重心附近。
4.2 散堆工件抓取流程實驗
工件搬移過程,如圖11所示。
抓取全部工件僅需兩次結構光點云生成(圖11(a)):
1) 系統利用YOLACT對圖片進行實例分割,并篩選出3個適合抓取的表層工件;
2) 利用雙目結構光系統生成3個目標工件區域的局部點云,并計算工件的位姿,指導機械臂搬移工件。完成對表層3個工件的抓取后,系統捕獲當前場景圖像進行實例分割,篩選出下層的5個適合抓取的工件。
隨后,重復上述過程,完成對下層5個工件的搬移。搬移下層5個工件后,系統再次捕獲場景圖像進行實例分割,發現無適合抓取的工件,系統結束抓取任務。
點云生成環節的工件搬移過程總耗時(t)為
t=ts+tj+tr+te+tc。(9)
式(9)中:ts為工件篩選環節耗時;tj為結構光投影環節耗時;tr為計算工件點云環節耗時;te為工件位姿估計環節耗時;tc為機械臂搬移工件環節耗時。
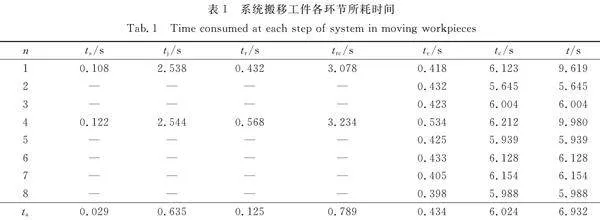
沒有點云生成環節的工件搬移過程中,單次搬移過程總耗時t為機械臂搬移過程耗時。系統搬移工件各環節所耗時間,如表1所示。表1中:n為抓取次數;trc=ts+tj+tr;ta為平均時間。
機械臂搬移工件環節平均耗時為6.024 s,遠高于估計單個工件位姿平均耗時。為提升散堆工件抓取系統工作效率,令機械臂搬移工件環節與下一個工件點云的配準過程并行執行。
4.3 相關方法對比測試
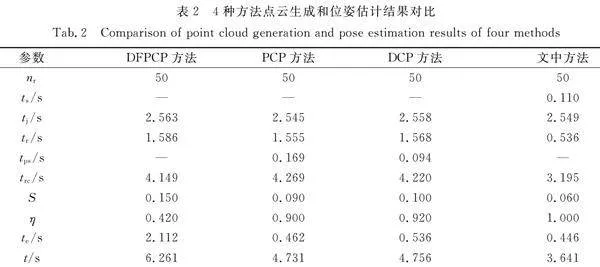
基于DFP[35](DFPCP)方法、基于PointNet++[15](PCP)方法及基于DGCNN[16](DCP)方法均利用雙目結構光生成點云,使用投票匹配和迭代最近鄰算法[33]估計工件位姿。所有方法均在相同場景下實驗了50次,4種方法點云生成和位姿估計結果對比,如表2所示。表2中:nr為重建的次數;η為配準成功率;tps為分割時間;S為點云規模。
由表2可知:DFPCP方法的配準成功率遠低于其他方法,這是由于DFPCP方法生成的整個散堆工件場景點云包含大量無關點,并且DFPCP不能選擇對應模型進行配準,而是需要依次和L型、T型工件的點對特征集合進行配準,T型工件的點對特征與L型工件的點對特征相似,L型工件模型點云易配準到場景點云中T型工件區域,導致配準成功率低;另外3種方法均是針對目標工件點云進行配準,大幅度提升了配準成功率;PCP方法和DCP方法需要計算完整場景點云,然后,對場景點云進行分割,以獲取目標工件點云,這導致點云生成時間較長,且在散堆工件之間存在遮擋情況,兩種方法都存在分割被遮擋工件的點云的情況,進而導致配準失敗;文中方法結合YOLACT輸出的目標工件的分割信息,只生成待抓取工件的點云,與其他方法相比,文中方法平均可縮小點云規模約44%,點云生成時間平均縮短24%,配準成功率平均提升25%。
5 結束語
提出了一種圖像分割引導的散堆工件結構光三維位姿估計方法,并基于所搭建的散堆工件抓取實驗系統進行了散堆工件抓取實驗。實驗結果表明,該方法能快速生成所有適合抓取工件的局部點云,顯著減少了點云規模和點云生成時間,雙目結構光點云生成平均時間僅為3.195 s。通過以種類為索引找到對應的模型進行基于投票匹配和ICP算法的位姿配準,提高了配準成功率,配準平均成功率達100%。相較其他方法,文中方法在減小點云規模、提高點云生成速度和提高配準成功率方面表現出色,從而有效提高了抓取效率。文中方法在更復雜環境下的工件掩膜分割質量方面仍有進一步提高的空間。對于不適合抓取的工件,系統通過機械臂對工件進行調整,確定抓取點,進而完成抓取,將是未來研究的主題。
參考文獻:
[1] SCHONBERGER J L,FRAHM J M.Structure-from-motion revisited[C]∥IEEE Conference on Computer Vision and Pattern Recognition.Piscataway:IEEE Press,2016:4104-4113.DOI:10.1109/CVPR.2016.445.
[2] 黃及遠,李敏,謝兵兵,等.雙目視覺關鍵技術研究綜述[J].制造業自動化,2023,45(5):166-171.DOI:1009-0134(2023)05-0166-06.
[3] FOIX S,ALENYA G,TORRAS C.Lock-in time-of-flight (ToF) cameras: A survey[J].IEEE Sensors Journal,2011,11(9):1917-1926.DOI:10.1109/JSEN.2010.2101060.
[4] 夏晨旭,郝群,張一鳴,等.基于結構光投影三維重建的人臉特征檢測[J].激光與光電子學進展,2023,60(22):186-192.DOI:10.3788/LOP230620.
[5] AHARCHI M,AITKBIR M.A review on 3D reconstruction techniques from 2D images[C]∥International Conference on Smart Cities Applications.Berlin:Springer,2020:510-522.DOI:10.1007/978-3-030-37629-1_37.
[6] MAYER N,ILG E,HAUSSER P,et al.A large dataset to train convolutional networks for disparity, optical flow, and scene flow estimation[C]∥IEEE Conference on Computer Vision and Pattern Recognition.Piscataway:IEEE Press,2016:4040-4048.DOI:10.1109/CVPR.2016.438.
[7] SUNDERMEYER M,MARTON Z C,DURNER M,et al.Implicit 3D orientation learning for 6D object detection from RGB images[C]∥European Conference on Computer Vision.Cham:Springer,2018:699-715.DOI:10.1007/978-3-030-01231-1_43.
[8] 牟向偉,孫國奇,陳林濤,等.基于Kinect相機的多視角RGB-D信息融合的甜椒姿態估計研究[J].中國農機化學報,2023,44(10):159-167.DOI:10.13733/j.jcam.issn.2095-5553.2023.10.023.
[9] BRACHMANN E,KRULL A,MICHEL F,et al.Learning 6D object pose estimation using 3D object coordinates[C]∥European Conference on Computer Vision.Cham:Springer,2014:536-551.DOI:10.1007/978-3-319-10605-2_35.
[10] KRULL A,BRACHMANN E,MICHEL F,et al.Learning analysis-by-synthesis for 6D pose estimation in RGB-D images[C]∥IEEE International Conference on Computer Vision.Piscataway:IEEE Press,2015:954-962.DOI:10.1109/ICCV.2015.115.
[11] CRIVELLARO A,RAD M,VERDIE Y,et al.A novel representation of parts for accurate 3D object detection and tracking in monocular images[C]∥IEEE International Conference on Computer Vision.Piscataway:IEEE Press,2015:4391-4399.DOI:10.1109/ICCV.2015.499.
[12] HODAN T,HALUZA P,OBDRLEK ,et al.T-LESS: An RGB-D dataset for 6D pose estimation of texture-less objects[C]∥IEEE Winter Conference on Applications of Computer Vision.Piscataway:IEEE Press,2017:880-888.DOI:10.48550/arXiv.1701.05498.
[13] JAFARI O H,MITZEL D,LEIBE B.Real-time RGB-D based people detection and tracking for mobile robots and head-worn cameras[C]∥IEEE International Conference on Robotics and Automation.Piscataway:IEEE Press,2014:5636-5643.DOI:10.1109/ICRA.2014.6907688.
[14] QI C R,SU Hao,MO Kaichun,et al.PointNet: Deep learning on point sets for 3D classification and segmentation[C]∥IEEE Conference on Computer Vision and Pattern Recognition.Piscataway:IEEE Press,2017:652-660.DOI:10.1109/CVPR.2017.16.
[15] QI C R,YI Li, SU Hao,et al.Pointnet++: Deep hierarchical feature learning on point sets in a metric space[C]∥Annual Conference on Neural Information Processing Systems.New York:MIT Press,2017:5099-5108.DOI:10.48550/arXiv.1706.02413.
[16] WANG Yue,SUN Yongbin,LIU Ziwei,et al.Dynamic graph CNN for learning on point clouds[J].ACM Transactions on Graphics,2019,38(5):1-12.DOI:10.48550/arXiv.1801.07829.
[17] WANG Chen,XU Danfei,ZHU Yuke,et al.DenseFusion: 6D object pose estimation by iterative dense fusion[C]∥IEEE Conference on Computer Vision and Pattern Recognition.Piscataway:IEEE Press,2019:3343-3352.DOI:10.48550/arXiv.1901.04780.
[18] GAO Ge,LAURI M,WANG Yulong,et al.6D object pose regression via supervised learning on point clouds[C]∥IEEE International Conference on Robotics and Automation.Piscataway:IEEE Press,2020:3643-3649.DOI:10.1109/ICRA40945.2020.9197461.
[19] ZHUANG Chuangang,LI Shaofei,DING Han.Instance segmentation based 6D pose estimation of industrial objects using point clouds for robotic bin-picking[J].Robotics and Computer-Integrated Manufacturing,2023,82:102541.DOI:10.1016/j.RCIM.2023.102541.
[20] ZHUANG Chuangang,WANG Haoyu,DING Han.Attention vote: A coarse-to-fine voting network of anchor-free 6D pose estimation on point cloud for robotic bin-picking application[J].Robotics and Computer-Integrated Manufacturing,2024,86:102671.DOI:10.1016/J.RCIM.2023.102671.
[21] PAVLAKOS G,ZHOU Xiaowei,CHAN A,et al.6-DoF object pose from semantickeypoints[C]∥IEEE International Conference on Robotics and Automation.Piscataway:IEEE Press,2017:2011-2018.DOI:10.1109/ICRA.2017.7989233.
[22] ROTHGANGER F,LAZEBNIK S,SCHMID C,et al.3D object modeling and recognition using local affine-invariant image descriptors and multi-view spatial constraints[J].International Journal of Computer Vision,2006,66(3):231-259.DOI:10.1007/s11263-005-3674-1.
[23] TULSIANI S,MALIK J.Viewpoints and keypoints[C]∥IEEE Conference on Computer Vision and Pattern Recognition.Piscataway:IEEE Press,2015:1510-1519.DOI:10.1109/CVPR.2015.7298758.
[24] RUBLEE E,RABAUD V,KONOLIGE K,et al.ORB: An efficient alternative to SIFT or SURF[C]∥IEEE International Conference on Computer Vision.Piscataway:IEEE Press,2011:2564-2571.DOI:10.1109/ICCV.2011.6126544.
[25] BAY H,TUYTELAARS T,VAN GOOL L.Surf: Speeded up robust features[C]∥European Conference on Computer Vision.Berlin:Springer,2006:404-417.DOI:10.1007/11744023_32.
[26] RUSU R B,BLODOW N,BEETZ M.Fast point feature histograms (FPFH) for 3D registration[C]∥IEEE International Conference on Robotics and Automation.Piscataway:IEEE Press,2009:3212-3217.DOI:10.1109/ROBOT.2009.5152473.
[27] TOMBARI F,SALT S,DI STEFANO L.Unique signatures of histograms for local surface description[C]∥European Conference on Computer Vision.Berlin:Springer,2010:356-369.DOI:10.1007/978-3-642-15558-1_26.
[28] VIDAL J,LIN C Y,MART R.6D pose estimation using an improved method based on point pair features[C]∥International Conference on Control, Automation, and Robotics.Piscataway:IEEE Press,2018:405-409.DOI:10.1109/ICCAR.2018.8384709.
[29] SHARP G C,LEE S W,WEHE D K.ICP registration using invariant features[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2002,24(1):90-102.DOI:10.1109/34.982886.
[30] YANG Jiaolong,LI Hongdong,CAMPBELL D,et al.Go-ICP: A globally optimal solution to 3D ICP point-set registration[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2015,38(11):2241-2254.DOI:10.1109/TPAMI.2015.2513405.
[31] 汪霖,郭佳琛,張璞,等.基于改進ICP算法的三維點云剛體配準方法[J].西北大學學報(自然科學版),2021,51(2):183-190.DOI:10.16152/j.cnki.xdxbzr.2021-02-002.
[32] 荊路,武斌,方錫祿.基于SIFT特征點結合ICP的點云配準方法[J].激光與紅外,2021,51(7):944-950.DOI:10.3969/j.issn.1001-5078.2021.07.019.
[33] ZHANG Jing,YIN Baoqun,XIAO Xianpeng,et al.3D detection and 6D pose estimation of texture-less objects for robot grasping[C]∥International Conference on Control and Robotics Engineering.Piscataway:IEEE Press,2021:33-38.DOI:10.1109/ICCRE51898.2021.9435702.
[34] BOLYA D,ZHOU Chong,XIAO Fanyi,et al.YOLACT: Real-time instance segmentation[C]∥IEEE International Conference on Computer Vision.Piscataway:IEEE Press,2019:9157-9166.DOI:10.1109/ICCV.2019.00925.
[35] LI Beiwen,AN Yatong,CAPPELLERI D,et al.High-accuracy, high-speed 3D structured light imaging techniques and potential applications to intelligent robotics[J].International Journal of Intelligent Robotics and Applications,2017,1(1):86-103.DOI:10.1007/s41315-016-0001-7.
[36] 熊宗剛.結構光雙目三維成像關鍵技術研究[D].成都:電子科技大學,2021.
(責任編輯: 陳志賢" 英文審校: 陳婧)
通信作者: 高振國(1976-),男,教授,博士,主要從事智能制造、機器視覺及無線自組網絡等的研究。E-mail:gaohit@sina.com。
基金項目: 國家自然科學基金資助項目(62372190, 61972166); 福建省高校產學合作資助項目(2021H6030)https://hdxb.hqu.edu.cn/
