中文重疊關系抽取的動態分層級聯標記模型
2024-01-01 00:00:00張利張歡歡袁玉波
華東理工大學學報(自然科學版) 2024年3期
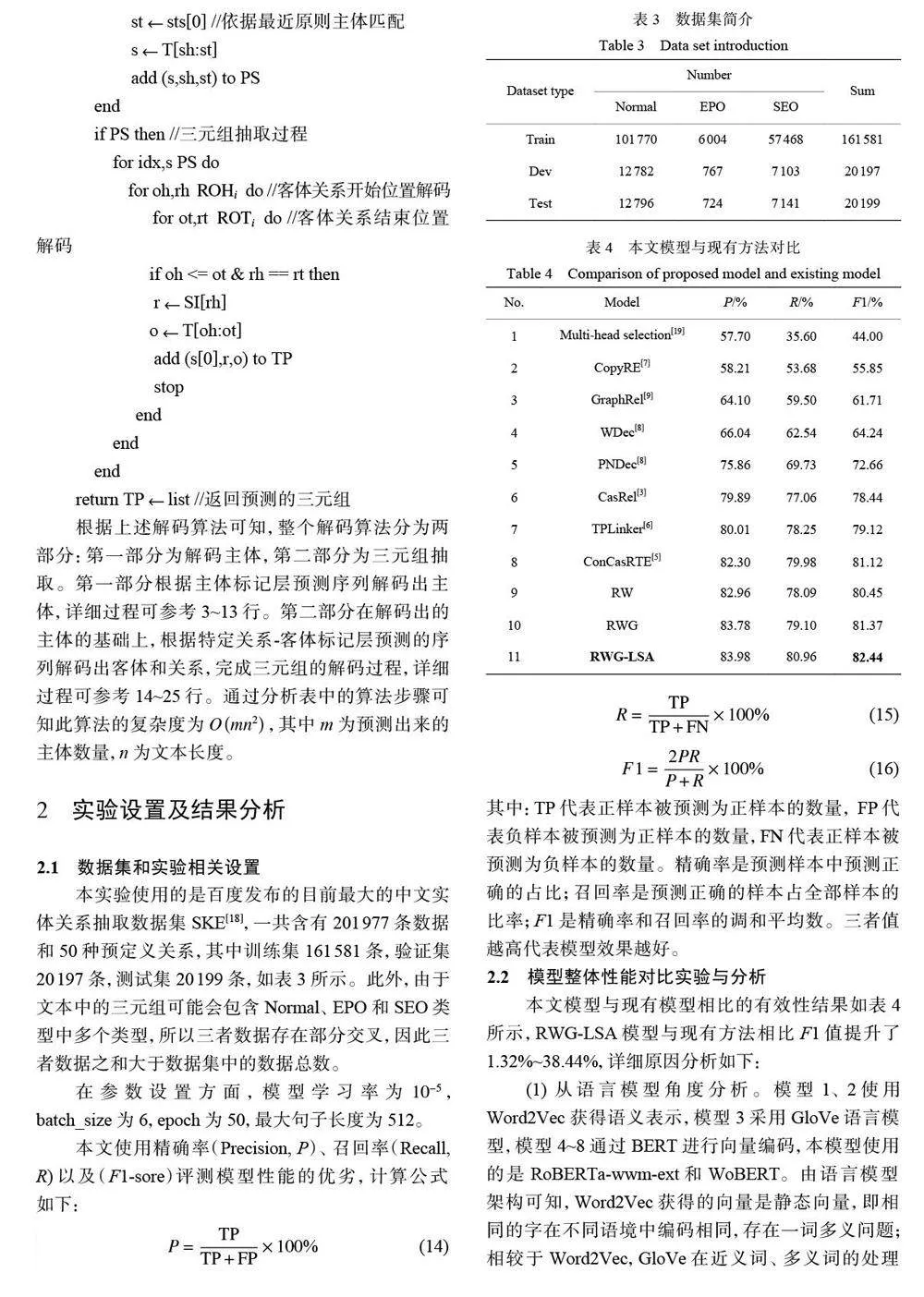





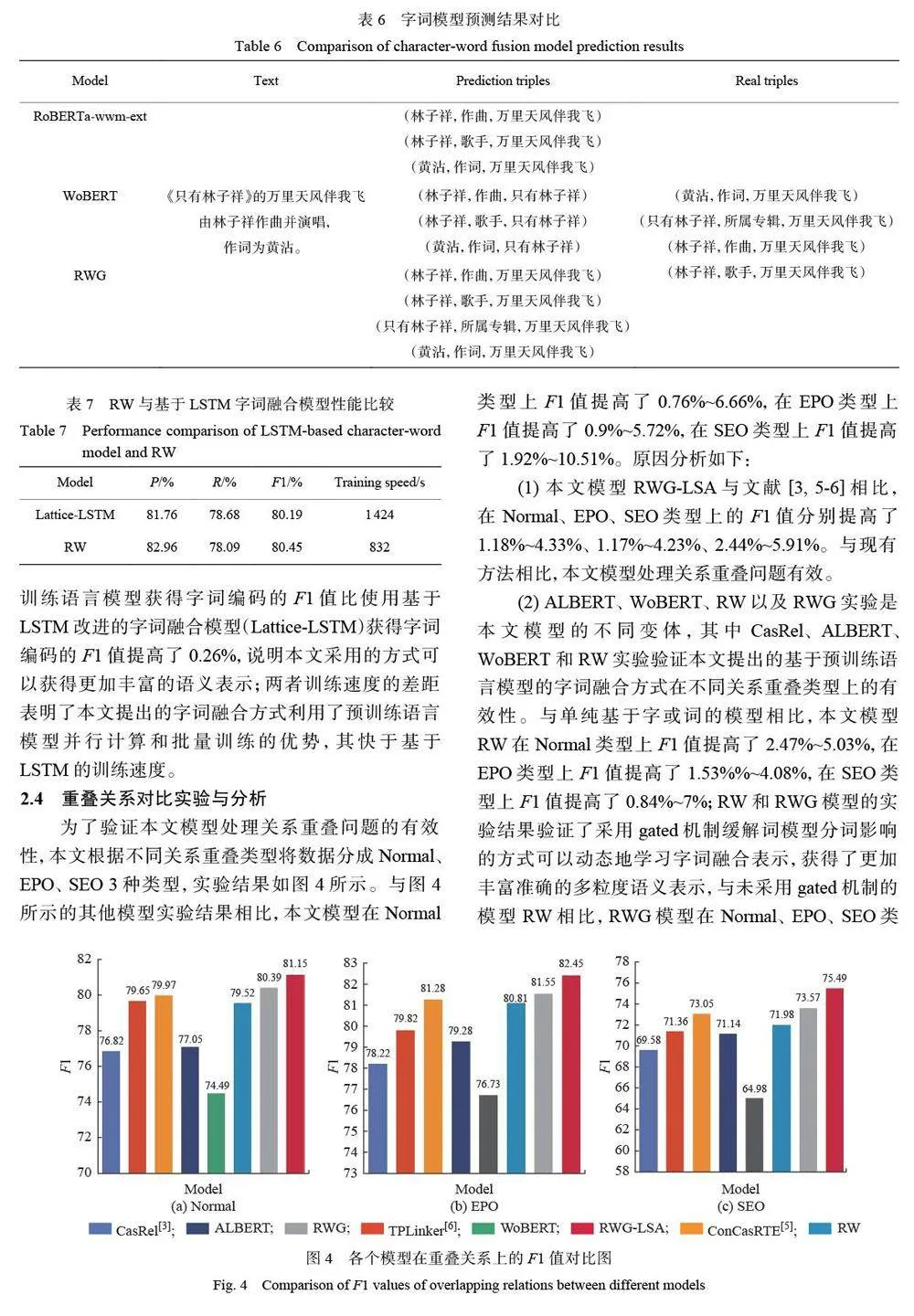

摘要:構建了動態分層級聯標記中文重疊關系抽取(RWG-LSA)模型:首先基于預訓練語言模型和gated 機制構建了動態字詞融合特征學習模型(RWG),有效避免了主體標記模塊的特征缺失和無法并行計算等問題;其次引入動態權局部自注意力(LSA),自主學習到主體層面的語義特征;最后在有效融合了輸入序列的全局和主體局部特征的基礎上,實現RWG-LSA 模型對文本中實體對和關系的抽取。在SKE 中文數據集上的實驗表明,本模型對重疊關系抽取有顯著效果,F1 值達到了82.44%。
關鍵詞:文本挖掘;中文重疊關系抽取;動態字詞融合;預訓練語言模型;gated 機制;局部自注意力機制
中圖分類號:TP391.1 文獻標志碼:A
在文本數據爆炸式增長的今天,如何從海量文本數據中挖掘出重要信息成為自然語言處理領域的主流方向,關系抽取是其中的一項重要方式。關系抽取任務是從非結構化文本數據中抽取出結構(主體、關系、客體)的三元組數據,以此表達實體以及實體間的語義關系。由三元組數據作為基本構成單元的知識圖譜和智能問答系統,可以協助司法案件處理、企業合同智能管理等方面的相關人員更好地掌握信息情報、識別相關風險,實現智能化輔助決策。因此,關系抽取作為這些下游任務的數據來源,具有較高的應用價值和研究價值。
目前,聯合抽取實體和關系的方法是關系抽取中的主流方法。許多新穎的聯合抽取方法被提出[1-2],其效果優于基于流水線[1] 的方法。然而,大多數現有的方法并不能有效處理實體間存在重疊語義關系的情況。現有的解決關系重疊問題的聯合抽取方法大致可分為3 種:(1)基于分層級聯標記的方法通常使用二進制(0/1) 標記序列來確定主體的開始和結束標記,以及每種關系下客體的開始和結束標記。Wei 等[3]基于BERT[4](Bidirectional Encoder Representationsfrom Transformers) 提出分層級聯標記(CasRel)的方式解決關系重疊問題,在數據集NYT 和WebNLG 上取得了顯著效果;Ren 等[5] 針對關系類別不均衡的問題,構建了基于BERT 和交叉熵損失的置信度閾值的級聯標記模型(ConCasRTE)。(2)基于表格填充的方法為每種關系維護一個擁有該關系的實體開始位置和結束位置的表。Wang等[6] 采用單階段標記對鏈接(TPLinker)方式實現關系表填充,并解決了暴露偏差問題。(3)基于Seq2Seq 的方法將三元組視為序列數據,按一定順序生成三元組。Zeng等[7] 按照先生成關系再生成實體的順序,提出了復制機制(CopyRE)解決關系重疊問題;Nayak 等[8] 針對復制機制無法識別完整實體的缺點改進解碼方式,一種方法以字逐個預測,即WDec( Word-based Decoding) ,另一種方法是解碼生成實體頭尾位置, 即PNDec( PointerNetwork-based Decoding)。除上述方法外,Fu 等[9] 還引入圖卷積網絡(Graph Convolutional Network,GCN)將文本建模作為關系圖來預測每個實體對的潛在關系。
猜你喜歡
四川勞動保障(2021年9期)2022-01-18 05:11:08
文苑(2018年21期)2018-11-09 01:23:06
軟件導刊(2016年12期)2017-01-21 15:55:21
電子技術與軟件工程(2016年22期)2016-12-26 20:29:58
商(2016年34期)2016-11-24 16:28:51
中國遠程教育(2016年9期)2016-11-19 12:26:00
中國衛生(2016年9期)2016-11-12 13:28:08
語文教學之友(2016年5期)2016-06-15 12:15:44
電腦知識與技術(2016年5期)2016-04-14 13:51:02
中國衛生(2015年9期)2015-11-10 03:11:12
