我國勞動力市場研究中大數據應用現狀與前景:基于范圍綜述的方法
2024-01-08 09:50:52王燊成周鎮忠
社會建設 2023年6期
王燊成 周鎮忠
一、問題的提出
在勞動力市場領域,隨著互聯網應用規模不斷擴大,勞動力市場大數據應運而生(史珍珍、曾湘泉,2016)。與此同時,一系列大數據技術更迭涌現,也為廣大就業群體帶來了新的機遇與挑戰。一方面,大數據可以擴大人群獲得就業的機會,數字經濟的發展可以幫助返鄉農民、待就業人員以及殘疾人等群體通過網絡平臺找到工作(張新紅,2016);另一方面,由于算法決策工具中根深蒂固的偏見,低收入人群也有可能會被排除在機會之外。由于使用機會受限并且缺乏數字技能(Hargittai & Hinnant,2008),被排斥的群體也可能無法像更多特權群體那樣從信息技術中獲得收益(Blank & Lutz,2018)。因此,正確認識勞動力市場中的大數據并掌握相應的分析技術,對于激活勞動力市場具有重要的意義。
事實上,基于網絡招聘信息的大數據分析已經成為國外勞動力市場研究的一種重要方法。勞動力市場大數據廣泛地運用于雇傭標準、搜尋與匹配過程、搜尋持續時間、雇主偏好等研究議題當中(史珍珍、曾湘泉,2016)。而在我國,由于勞動統計數據不完備或不公開,統計口徑和方法都存在較大爭議,利用各類大數據深入開展我國勞動力市場理論研究和政策分析顯得尤為重要(曾湘泉,2017)。不過,隨著近年來互聯網、人工智能、5G 等信息技術在我國勞動力市場的廣泛運用,探討勞動力市場中大數據及其技術應用的研究也開始涌現。基于此,本文利用范圍綜述的研究方法,全面呈現我國勞動力市場研究中大數據應用現狀及其主要特點,并在此基礎上嘗試提出運用大數據及其技術促進就業的相關建議。
二、研究方法:范圍綜述
自20 世紀70 年代早期以來,隨著循證實踐的發展,一系列的研究綜述方法也隨之產生。在14 種最常見的評述方法中,范圍綜述(scoping review)是一種針對探索性研究問題的知識綜合,即通過系統地搜索、選擇和綜合現有知識,并遵循既定的方法學框架,繪制與某一特定領域相關的關鍵概念、證據類型和研究空白。這種方法不僅對于通過鞏固證據推進實踐和研究至關重要,而且可以幫助知識用戶更有效地做出基于證據的決策(Colquhoun et al.,2014)。
范圍綜述是一個相對較新的方法,目前尚無通用的研究定義以及應用程序。Arksey 與O’Malley(2005)最早提出了開展范圍綜述的五個步驟:第一,明確研究問題,這對于搜索策略的構建十分重要;第二,確定相關研究,即盡可能全面地確定原始研究,并審查是否適合回答中心研究問題;第三,研究選擇,需要確定一種機制來幫助排除沒有解決研究問題的研究,即確定研究納入或排除的標準;第四,繪制數據圖表;第五,整理、總結和報告結果。目前,使用范圍綜述的研究主要集中于公共衛生與醫療健康領域,比如公共衛生干預中的行為和行為理論(Davis et al.,2015)、心理健康中的機器學習(Shatte et al.,2019)等。本研究基于Arksey 與O’Malley提出的范圍綜述的五個步驟開展我國勞動力市場研究中大數據運用的文獻回顧。
(一)研究問題的確定
基于前文所述的研究背景,并結合研究者已有的專業知識以及對文獻的初步閱讀,本文將主要問題確定為我國勞動力市場研究中大數據運用的范圍、特征等是什么。
(二)確定相關研究
本文通過搜索詞“大數據”“機器學習”與搜索詞“就業”“失業”“勞動力”的組合檢索方式來識別符合研究問題的相關研究。文獻搜索主要在中國知網中開展。考慮到已有研究的質量以及聚焦性,納入研究的文獻僅限于CSSCI(含擴展版)來源期刊。此外,為確保全面審查已有文獻,搜索不僅包括上述數據庫中的定量與定性研究,還通過滾雪球、手動搜索、搜索認證、引用文章等方式確定其他來源的文獻。
(三)研究選擇
如果符合以下標準,文獻將包括在本綜述中:第一,文章發表在同行評議的學術期刊上;第二,文章屬于實證性研究;第三,文章利用大數據來分析就業、失業等與勞動力市場有關的現象或解決了相關問題。如果滿足以下條件,則將文章排除在綜述外:第一,文章屬于概念性研究;第二,文章屬于綜述性研究,沒有原始貢獻;第三,文章使用的數據不屬于大數據或沒有利用大數據技術。本文的選擇沒有關于發表時間、地理位置、人口或研究設計的限制。
(四)繪制數據圖表
確定相關研究后,研究人員將對全文開展進一步評估,并提取每篇文章中勞動力市場所涉及的領域、大數據來源與類型、大數據處理與分析技術、學科領域、作者信息、發表年份以及期刊名稱等內容。文章的引文主要通過Zotero 軟件進行管理。
(五)整理、總結和報告結果
研究人員集中比較和討論了各類數據。一方面,對研究文獻進行描述性統計。考慮到已有研究中使用的數據類型,本綜述并不適用于薈萃分析的方法,因此主要通過敘事性綜述的綜合方法來呈現已有研究。另一方面,對研究結果進行了比較評估和焦點討論,確定已有研究的趨勢和不足。
三、我國勞動力市場研究中大數據應用現狀
截至2022 年12 月31 日,本研究基于搜索詞組合共確定297 篇CSSCI文章,通過手動檢索、引用文獻滾雪球檢索等渠道共確定16 篇CSSCI 文獻,共計313 篇文獻,其中重復文獻共有55 篇。研究人員對這些文獻的摘要進行了回顧,剔除了與研究問題不相關的199 篇。此外,通過對剩下的59 篇文獻的全文回顧,結合本研究范圍綜述的文獻納入與排除標準,共篩選出35 篇文獻。因此,最終納入綜述的文獻共有35 篇。本研究的范圍綜述具體流程參見圖1。
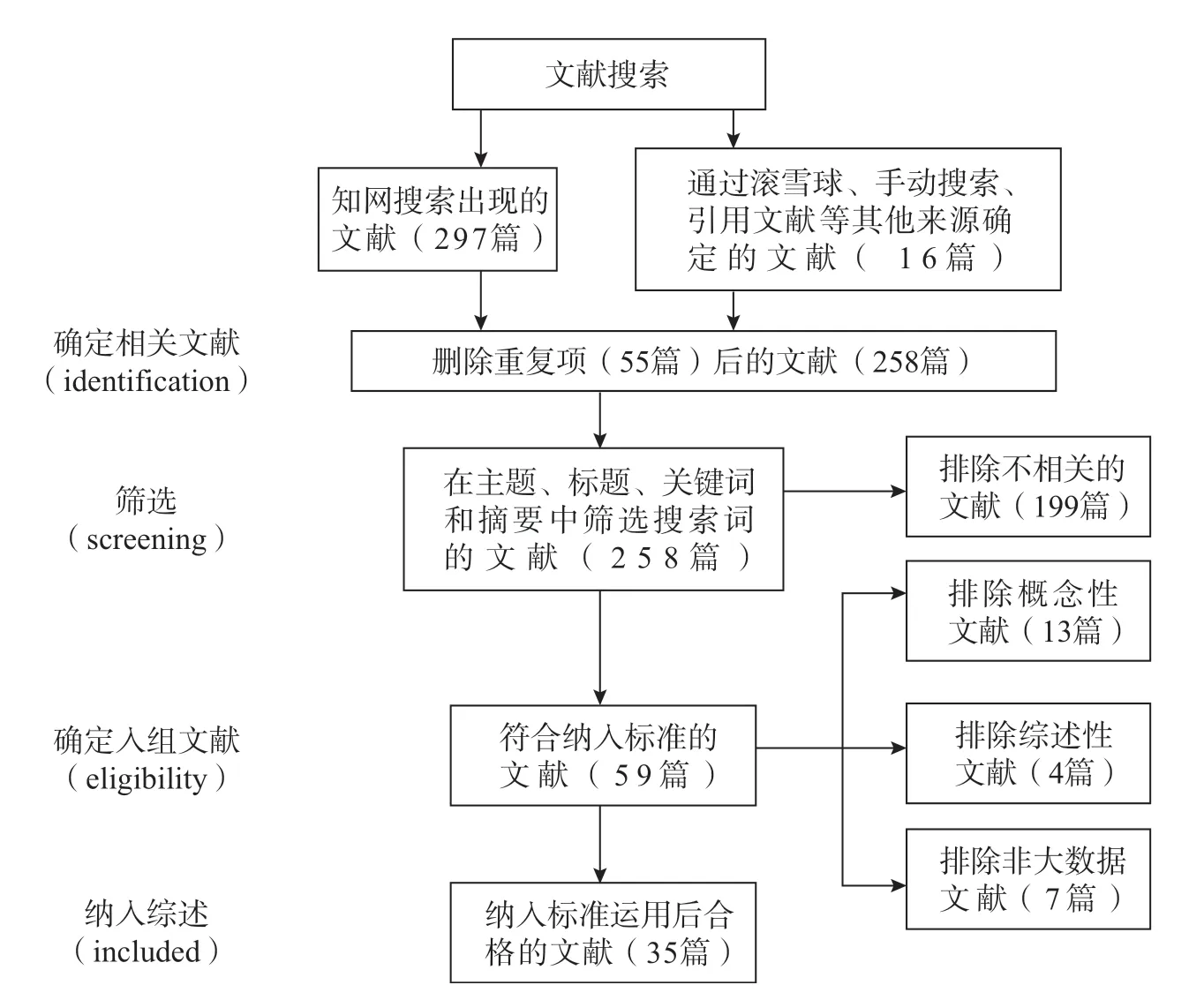
圖1 范圍綜述流程圖
(一)文獻的基本信息
入選范圍綜述的文獻主要發表于2016—2022 年,其中2016 年共有3 篇,2017 年共有5 篇,2018 年共有4 篇,2019 年共有7 篇,2020 年共有6 篇,2021 年共有5 篇,2022 年共有5 篇。根據中國知網的學科分類統計,35 篇文章中涉及勞動經濟的有13 篇、城市經濟9 篇、教育6 篇、通信經濟5 篇、計算機5 篇、工商管理4 篇、社會4 篇、城鄉規劃與市政3 篇、語言2 篇、農業經濟2 篇,涉及政治、國民經濟、交通運輸經濟、金融的各1 篇。
(二)文獻使用大數據的基本情況
研究發現,入選文獻所使用的大數據大體上可以分為四種類別:第一類主要來源于智聯招聘、前程無憂、應屆生求職網、看準網、拉勾網、大街網、獵聘網、領英等國內外招聘網站,共有19 篇文章涉及,大數據主要以崗位與就業信息為主,少數研究使用訪問量次數與訪問人數數據、評論文本等信息;第二類主要來源于手機信令數據,手機信令數據指的是當手機與基站進行通信連接(如接打電話、接發短信、位置更新等)時,基站會進行記錄并產生一條包含基站位置信息的信令數據,實際上這是一種人口流動的檢測方式(王德等,2020),共有7 篇文章涉及;第三類主要來源于騰訊地圖、高德地圖、百度地圖、微信熱力大數據、一卡通刷卡數據等勞動力遷徙通勤大數據,共有5 篇文章涉及,比如“宜出行”是騰訊公司開發的基于地圖顯示當前選定區域人流分布的手機端小程序, 能夠有效分析既定區域內的人流熱度和分布變化(申犁帆等,2019);第四類主要來源于興趣點(Point of Interest,POI)數據,指的是一些與人們生活密切相關的地標建筑和地理實體的點數據,如學校、醫院、商場、公園以及政府機構等,常用于城市研究中,共有4 篇文章涉及;此外,還有研究使用的大數據主要來源于新聞報道、微博數據集、百度搜索行為數據、全樣本行政大數據、啟信寶(產業大數據)、房地產網絡平臺、美團網等。
(三)文獻主要關注的勞動力市場話題
基于對35 篇入選文獻的全文閱讀,本文對其關注的勞動力市場話題進行了提煉與概括,大體可以分為勞動力市場供求關系、勞動力市場結構、勞動力市場預警預測、職住空間關系以及其他等五個方面。
在勞動力市場中,供求關系是最基本的關系,影響經濟發展的諸多方面,是連接人口與經濟發展的重要環節,決定著失業率、勞動力價格等多重要素,入選的文獻中共有12 篇主要關注該話題。在這些文獻中,共有3 篇主要關注高校畢業生群體。劉全等(2016)基于網絡爬蟲技術所獲得招聘高校畢業生信息,對我國人才市場對高校畢業生的需求進行了分析;宋齊明(2018)探討了雇主對本科畢業生通用性能力的要求以及其中的差異化特征。許艷麗、呂建強(2019)檢驗和探討了人工智能領域對高職畢業生的技能需求。其次,共有3 篇文獻關注人才培養的議題,王梅等(2019)分析了勞動力市場對碩士生提出的復合性可雇傭能力需求以及相應的人才培養應對之策;王輝、夏金鈴(2019)分析了非通用語人才培養現狀及人才培養與市場需求的關系、問題及相應建議;姚亞芝、司顯柱(2018)探討了語言服務行業人才需求。此外,還有6 篇文章主要關注部分特殊崗位的市場需求,劉睿倫等(2017)對大數據工作崗位需求文本進行挖掘,探討了企業對大數據崗位的需求特點。張俊峰、魏瑞斌(2018)基于國內招聘類網站的數據類崗位招聘信息,分析了數據類崗位人才需求的主要特點、相似性以及差異性。唐春勇等(2018)分析了新環境下員工對組織人力資源管理的關注點,總結出新環境下員工的個性化需求的聚焦點。王奕俊、楊悠然(2020)分析了人工智能時代下職業技能需求結構面臨的變化與挑戰。馬曄風、蔡躍洲(2019)基于官方統計和領英平臺大數據,就中國ICT 勞動力供給狀況及分布特征進行了實證分析。周金燕、馮思澈(2020)利用網絡爬蟲獲取的6 萬多條教師招聘信息,對教師勞動力市場的技能或特征需求進行了研究。
入選文獻中共有9 篇主要關注了勞動力市場結構議題,包括勞動力的遷徙流動、勞動力或就業崗位的空間分布、工資結構的分布與調整等。部分研究分別利用爬蟲獲取的網絡招聘崗位信息、手機信令數據、產業大數據,分析了城市就業崗位空間分布特征、影響因素(孫晨等,2016;謝智敏等,2021;劉煒等,2022)。張濤、劉寬斌(2019)基于網民對于“找工作”的搜索痕跡大數據,測算了中國經濟增長與失業率和農業勞動力轉移之間的關系。還有研究分別利用騰訊遷徙大數據、手機信令大數據、美團大數據動態監測了人口遷徙流動的軌跡特點、影響因素等(陳雙等,2020;陳莎、李春朋,2021;張文武、余泳澤,2021)。有學者基于網絡零工招聘數據,探討了數字技術對零工就業及其收入的主要影響(張藝、明娟,2022;張藝、皮亞彬,2022)。
入選文獻中共有5 篇主要關注勞動力市場預警預測的話題。其中3 篇文章使用的均是中國人民大學中國就業研究所利用智聯招聘大數據發布的中國就業市場景氣指數(CIER),該指數涵蓋了智聯招聘提供的注冊求職人數、發布的崗位空缺數量等大數據,基于市場招聘需求人數與市場求職申請人數的比值計算得出。該指數以1 為分水嶺,指數大于1 表明就業市場中勞動力需求多于市場勞動力供給,就業市場競爭趨于緩和,就業市場景氣程度高,就業信心較高,指數越大說明就業市場的景氣程度越高。具體而言,耿林、毛宇飛(2017)的研究重點介紹了CIER 指數的構建方法,并搭建計量模型探討CIER 指數與宏觀經濟景氣指標的關聯程度,從而對就業形勢進行短期預測。王輝、曾湘泉(2017)結合CIER 指數和雇主—雇員匹配數據,探討了我國勞動者工資和勞動力市場緊張程度之間的關系。毛宇飛、曾湘泉(2022)結合CIER 指數和微觀數據,發現在疫情沖擊下畢業生就業市場供需兩端均受到影響。此外,董倩(2017)運用招聘網站的訪問數據對失業率變化情況趨勢進行了擬合,發現招聘網站活躍度與失業率之間高度相關,用其來預測與體現失業率變化趨勢是可行的。黃冠華等(2021)基于某城市全樣本行政大數據,利用機器學習算法,對每個城鎮居民每個月的就業狀態進行預測,再利用統計核算方法估計出該城市的失業率。
職住空間關系即居住就業空間關系,指居住地和工作地之間的空間聯系與位置關系,主要包括居住、就業、通勤三大部分,已經成為勞動力市場以及城市可持續發展共同關注的重要議題(劉望保、侯長營,2013)。入選文獻中共有7 篇主要關注這一研究議題。有研究利用騰訊“宜出行”定位數據、軌道站點POI、一卡通刷卡數據、微信熱力大數據、手機信令數據等大數據,探討了職住空間關系中的職住平衡問題(申犁帆等,2019;仇璟等,2020;周作江,2020;周新剛等,2021)。有研究基于手機信令數據,探討了大數據如何應用于通勤模型構建等問題(顧家煥、王德,2020)。也有研究結合與城市生活設施相關的POI 大數據和居民住房與交通狀況調查問卷,分析了居民個體屬性及其對公共服務空間偏好與通勤距離的內在關系(王振坡等,2020)。還有研究使用多源大數據實證分析,比較了不同園區職住空間關系的演變特征和演變機制,歸納了后工業化背景下產業轉型帶來的產業園區職住空間關系演變模式(鈕心毅、林詩佳,2022)。
除了上述四類主題以外,胡恩華等(2016)利用中華全國總工會網站上共計1 853 篇工會動態報道,運用扎根理論方法在完整呈現出中國工會實踐職能現狀的基礎上探討了工會的勞資關系調節職能。黃榮貴(2017)基于SMP2015 微博數據,集中篩選出含有種子用戶的51 288 條博文并基于“網絡與文化”和關系社會學的理論,探討了目前勞動議題的主要社群關注點以及當前該研究領域的新趨勢。
(四)大數據的主要分析技術
大數據的分析技術主要包括可視化技術、數據挖掘技術、預測技術以及語義分析技術。其中,可視化技術分為文本可視化、網絡(圖)可視化、時空數據可視化、多維數據可視化技術等;數據挖掘技術分為聚類分析(如K-means 算法、K-中心點算法、層次方法、基于密度的方法、基于網格的方法以及基于模型的方法等)、分類和預測(如決策樹、粗糙集、貝葉斯、遺傳算法、BP 和RBF 神經網絡算法等)、關聯分析(如Apriori 算法);預測分析技術主要指利用統計、建模、數據挖掘工具對已有數據進行研究以完成預測,分為定性預測(如集思廣益法、德爾菲法、Boosting、貝葉斯網絡等)與定量預測(如統計分析、因果聯系模擬、人工智能算法等);語義分析技術指的是識別文本的意義、主題、類別等語義信息的過程,大體分為基于統計的文本語義分析(如潛在語義分析、概率潛在語義分析和隱含狄利克雷分布等)和基于語義學的文本語義分析。
入選文獻使用的分析技術主要涉及三種類型:第一類是適用于大數據的特定技術,大多數研究習慣利用Python 工具包中TF-IDF 算法、Word2Vec 開源工具、python-digraph 模塊、漢語分詞系統(PyNLPIR)、LDA 模型、K-means 聚類等對大數據文本進行分詞和詞頻分析、聚類分析、話題模型分析等,也有研究使用KNIME 開源數據分析平臺對大數據進行關鍵詞提取以及文本內容分析(王梅等,2019),還有研究利用基于R-gram的語料庫分詞和詞頻統計軟件PowerConc 對大數據文本進行了分詞和詞頻分析以確定高頻關鍵詞(宋齊明,2018);第二類主要結合空間地理信息,通過模型建構以可視化的方式呈現研究主要發現,比如基于核密度分析圖形研究法、多尺度GIS 空間分析等;第三類主要是在結合截面或面板數據的基礎上,利用描述性分析以及計量模型進行模擬分析等。
四、結論與思考
基于我國勞動力市場研究中大數據應用相關文獻的范圍綜述,本文發現以核心關鍵詞在中國知網進行檢索雖然可以獲取一定文獻,但其中真正使用大數據且聚焦勞動力市場議題的研究并不多見。在符合各項指標要求的文章中,使用的大數據一方面主要源于求職網站中與勞動力市場緊密相關的崗位信息、求職信息等,另一方面主要源于互聯網信息技術應用于勞動力工作生活場景后產生的相關數據。這些相關研究主要關注勞動力市場供求關系、勞動力市場預警預測、勞動力市場結構、職住空間關系等話題,涉及可視化、數據挖掘、預測分析、語義分析等大數據分析技術。不過,現階段我國勞動力市場大數據仍處于發展初期,無論是大數據的收集,還是大數據的篩選,抑或是大數據的使用,都有待進一步發展。此外,相較于國外勞動力市場研究中大數據的應用,我國無論在技術手段上,還是在分析深度上,抑或是在大數據與政策制度的融合上均有很大的拓展空間。比如,有研究指出,利用大數據可以分析或預測宏觀經濟指標,從而做出精準的決策,紐約聯儲銀行工作人員對國民生產總值進行早期估算的創新技術很好地詮釋了大數據與政策制定的深度融合(Bok et al.,2018)。雖然當前可獲得的大數據有限,但努力完善和利用現有數據不僅可以改善當前的分析工作,而且還可以未來的分析奠定基礎(Dimas et al.,2023)。鑒于此,綜合相關討論,本文認為為了更好地利用大數據來開展勞動力市場研究并指導實踐,可以在以下三個方面發力。
第一,進一步挖掘獲取勞動力市場大數據。數據源是應用大數據的前提,沒有豐富的數據源,大數據就無從談起(陳之常,2015)。對此,首先,建立數據收集與整合協作機制,一方面建立一個全面的數據收集系統,包括政府機構、企業、教育機構和研究機構的數據源;另一方面,整合各種數據,包括就業統計、人力資源信息、教育背景、技能培訓記錄等,以形成全面的勞動力市場數據集。其次,推動數據標準化與共享,通過制定統一的數據標準和格式,確保各個數據源可以互相對接和共享。此外,目前國內研究使用的就業大數據主要依賴于各大招聘求職網站提供,這樣可能會導致樣本選擇性偏差的出現,低學歷、高齡、農民工等就業弱勢群體容易被網絡求職平臺排斥在外。因此,本文建議提高就業弱勢群體的信息化技術,培養網絡求職招聘的習慣。最后,強化數據分析與挖掘能力,鼓勵利用先進的數據分析技術,如機器學習、人工智能和數據挖掘算法,對勞動力市場數據進行深入分析。
第二,多渠道保障大數據的真實性。獲取的大數據也并不一定是有效的,因為數據和數據集并不是完全客觀的,不同的人會構建不同的信息系統來收集、存儲、分析和解釋數據,而這些信息系統是由價值系統塑造的。年齡、性別、民族、社會經濟地位、在線體驗和互聯網技能都會影響人們使用習慣,這會在其行為痕跡中顯示出來,并影響基于特定站點用戶數據得出的結論(Hargittai,2015)。鑒于此,在使用大數據進行計算的過程中,認識 “小數據” 的價值變得越來越重要。與大數據相比,小數據需要更高的質量水平,因為它的特性可能會加劇或放大錯誤的結論(Dimas et al.,2023)。因此在某些情況下,關注 “特殊” 的單個人可能會非常有價值。此外,由于當下可以對大型數據集進行建模,這通常會將數據簡化為適合數學模型的數據。但是一旦脫離上下文,數據就失去了意義和價值(Danah & Kate,2012)。所以需要注意警惕“唯數據論”,大數據本身就是一門技術,無法全面反映就業群體的就業意愿、能力以及機會等,在利用大數據技術的同時需要發揮好其他方法的作用。無論如何,大規模數據集都不能替代理論和小數據技術,理論仍然是數據分析的寶貴指南,而為回答特定問題而構建的小數據仍然可以提供最精確的答案(Mergel,2016)。
第三,高效安全地使用大數據。如何運用大數據實現政府決策觀念、決策方式、決策手段、決策過程的轉型,引領地方政府實現決策機制的優化,已經成為政府管理領域的方向性問題(謝治菊,2018)。在勞動力市場領域,生產大批量大數據的同時如何有效地利用大數據來促進就業的高質量發展需要在制度設計、機制體制、政策執行等方面共同發力,尤其是在國家數據局成立的背景下,需要更加積極主動地融入數字社會建設的潮流,提高大數據的使用效率,提高各級政府、社會科學界利用各類大數據深入開展我國勞動力市場理論研究和政策分析的能力。具體而言,可以利用大數據分析結果進行勞動力市場的預測和趨勢分析,通過建立預測模型來預測就業市場的發展趨勢、勞動力需求的變化以及技能需求的演變,從而幫助個人、企業和政府做出更明智的決策。與此同時,基于大數據分析結果,可以制定和優化與勞動力市場相關的政策和措施。尤其是通過深入了解勞動力市場的供需狀況、結構性問題和瓶頸,政府可以有針對性地制定就業培訓政策、職業發展規劃和人才引進政策,以促進勞動力市場的發展。不過,技術是一把雙刃劍,在收集并利用勞動力市場大數據的同時,還需要做好個人信息安全保護等工作。因此,在利用勞動力市場大數據的同時,需要進一步強化研究者以及數據使用者的隱私觀念,加強法律體系與道德體系的“雙約束”作用,在進行大數據分析之前,對敏感信息進行匿名化或脫敏處理,以避免個人身份的泄露。還可以建立包括招聘企業、政府法律部門、就業群體等相關利益主體的對話機制,保證數據取之于就業群體,同時也用之于就業促進。
2021 年11 月,工業和信息化部發布的《“十四五”大數據產業發展規劃》中指出,強化大數據在政府治理、社會管理等方面的應用,提升態勢研判、科學決策、精準管理水平。本文通過對我國勞動力市場大數據應用相關文獻的系統綜述,在一定程度上能夠從宏觀層面整體把握我國勞動力市場中大數據的立體畫像,以期為更好地將大數據及其技術運用于勞動力市場提供一定啟示。不過需要說明的是,本文也存在一定的不足,比如對于現有文獻的綜述并沒有考慮外文文獻,同時受研究方法的局限,一些正在研究的最新成果可能無法及時有效地捕捉到。
猜你喜歡
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
科技傳播(2019年22期)2020-01-14 03:06:54
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
石油瀝青(2018年6期)2018-12-29 12:07:04
NBA特刊(2018年21期)2018-11-24 02:47:52
電子制作(2018年18期)2018-11-14 01:48:24
山東工業技術(2016年15期)2016-12-01 05:31:22
功能高分子學報(2016年1期)2016-04-26 01:39:05
