帶狀稀疏矩陣乘法及高效GPU實現
2024-01-09 04:00:22劉麗陳長波
計算機應用 2023年12期
劉麗,陳長波*
帶狀稀疏矩陣乘法及高效GPU實現
劉麗1,2,陳長波1*
(1.中國科學院 重慶綠色智能技術研究院,重慶 400714; 2.中國科學院大學 重慶學院,重慶 400714)(?通信作者電子郵箱chenchangbo@cigit.ac.cn)
稀疏-稠密矩陣乘法(SpMM)廣泛應用于科學計算和深度學習等領域,提高它的效率具有重要意義。針對具有帶狀特征的一類稀疏矩陣,提出一種新的存儲格式BRCV(Banded Row Column Value)以及基于此格式的SpMM算法和高效圖形處理單元(GPU)實現。由于每個稀疏帶可以包含多個稀疏塊,所提格式可看成塊稀疏矩陣格式的推廣。相較于常用的CSR(Compressed Sparse Row)格式,BRCV格式通過避免稀疏帶中列下標的冗余存儲顯著降低存儲復雜度;同時,基于BRCV格式的SpMM的GPU實現通過同時復用稀疏和稠密矩陣的行更高效地利用GPU的共享內存,提升SpMM算法的計算效率。在兩種不同GPU平臺上針對隨機生成的帶狀稀疏矩陣的實驗結果顯示,BRCV的性能不僅優于cuBLAS(CUDA Basic Linear Algebra Subroutines),也優于基于CSR和塊稀疏兩種不同格式的cuSPARSE。其中,相較于基于CSR格式的cuSPARSE,BRCV的最高加速比分別為6.20和4.77。此外,將新的實現應用于圖神經網絡(GNN)中的SpMM算子的加速。在實際應用數據集上的測試結果表明,BRCV的性能優于cuBLAS和基于CSR格式的cuSPARSE,且在大多數情況下優于基于塊稀疏格式的cuSPARSE。其中,相較于基于CSR格式的cuSPARSE,BRCV的最高加速比為4.47。以上結果表明BRCV可以有效提升SpMM的效率。
帶狀稀疏矩陣;稀疏存儲格式;稀疏矩陣乘法;圖形處理單元;共享內存
0 引言
稀疏矩陣是元素大部分為零的矩陣,它的非零元素占比非常小,通常小于總數的1%。稀疏矩陣乘法廣泛應用于大型科學計算[1]、深度學習[2-6]、分子化學[7]和圖形分析計算[8-10]等領域。特別在深度學習領域,利用矩陣的稀疏性已成為提高深度神經網絡訓練和推理性能,以及在保持準確性的同時減小模型大小的主要方法之一[2,11-13]。在圖神經網絡(Graph Neural Network, GNN)[4]中,表示圖的鄰接矩陣通常具有稀疏性,稀疏-稠密矩陣乘法(Sparse-dense Matrix Multiplication, SpMM)因此成為GNN訓練和推理中的主要操作之一[8-9,14]。
稀疏矩陣的存儲格式很多,其中以下4種基本的存儲格式被廣泛接受:行壓縮(Compressed Sparse Row, CSR)格式、坐標格式(COOrdinate format, COO)、ELLPACK(ELL)和對角線格式(DIAgonal format, DIA)[15-16]。此外,Liu等[17]提出了基于CSR擴展的CSR5格式;Ecker等[18]針對3種不同的并行處理器架構提出了CSR5BC(CSR5 Bit Compressed)、HCSS(Hybrid Compressed Slice Storage)和LGCSR(Local Group CSR)這3種新的稀疏矩陣格式,均分別在相應的目標架構上提供了良好的性能;Xie等[19]提出了CVR(Compressed Vectorization-oriented sparse Row)格式,可以同時處理輸入矩陣中的多個行以提高緩存效率;程凱等[20]提出了由ELL和CSR格式混合而成的HEC(Hybrid ELL and CSR)格式,改善稀疏矩陣的存儲效率;Zhang等[21]提出了兩種適用于ARM處理器的對齊存儲格式ACSR(Aligned CSR)和AELL(Aligned ELL),實驗結果證明了這兩種格式均具有明顯的性能優勢;Coronado-Barrientos等[22]提出了適用于不同體系結構的AXT格式,實驗結果表明它可提高不同稀疏模式矩陣的存儲效率;Bian等[23]提出了單一格式CSR2,實驗表明該格式可實現低開銷的格式轉換和高吞吐量的計算性能,與CSR5相比,性能有明顯提升;Karimi等[24]提出了一種平衡線程級并行和內存效率優化的圖形處理單元(Graphics Processing Unit,GPU)內存感知格式VCSR(Vertical CSR),通過設計可配置的重排序方案可以最小化轉換開銷,顯著減少全局內存事務的數量。
很多學者針對特殊稀疏結構提出特殊格式,特別是針對分塊稀疏的研究工作有很多,其中應用最廣泛的是塊壓縮稀疏行(Blocked Compressed Sparse Row, BCSR)格式以及基于此的一些變體。由于BCSR格式對整個矩陣使用單一的分塊劃分大小,并且要求分塊嚴格對齊,因此會顯式地引入更多的零填充。Vuduc等[25]提出了不對齊的BCSR(Unaligned BCSR, UBCSR)和可變塊行(Variable Block Row, VBR)格式,以存儲不同分塊大小的子矩陣;Almasri等[26]提出了一種稀疏矩陣壓縮塊存儲格式CCF(Compressed Chunk storage Format),將非零元數相同的行分配給同一個塊,以增強負載平衡,在Intel x86處理器上的實驗結果表明它為非結構化矩陣提供了優異的性能;楊世偉等[27]提出了基于BRC格式改進的BRCP(Blocked Row-Column Plus)存儲格式,這種格式采用二維分塊的方法,針對稀疏矩陣非零元分布特點,自適應地選擇分塊參數,保證了BRC格式的高效運行,優化了計算結果的確定性,且確保了再現性,具有較高的效率;Li等[28]提出了VBSF(Variable Blocked SIMD Format)格式,解決了主存訪問的不連續性的問題,提高了存儲和計算效率;Ahrens等[29]提出一種快速優化的VBR矩陣行劃分算法1D-VBR(1D-Variable Block Row),在固定列分組的條件下確定最佳的行分組劃分方式;Aliaga等[30]提出一種基于坐標稀疏矩陣格式的變體,將稀疏矩陣的非零元劃分為相等大小的塊以分配工作負載,該格式平衡了工作負載并壓縮了索引數組和數值信息,適用于多種多核處理器平臺。
由于稀疏矩陣乘法的重要性,很多學者基于上述稀疏格式,特別是CSR格式,在CPU、GPU、FPGA(Field-Programmable Gate Array)等不同硬件平臺上對稀疏矩陣的效率進行改進,特別地,基于GPU的研究工作較多。NVIDIA 公司提供了一個cuSPARSE庫[31]處理稀疏矩陣的乘法,在cuSPARSE庫中,有一組基本線性代數子程序,用于處理稀疏矩陣。此外,Yang等[3]基于CSR格式,在GPU上實現了兩種高效的SpMM算法,主要采取行劃分和均勻分配非零值兩種策略,以實現稠密矩陣的合并訪問以及TLP(Thread-Level Parallelism)和ILP(Instruction-Level Parallelism)的負載平衡,實驗結果表明該算法相較于cuSPARSE平均可實現2.69的加速比;Huang等[8]提出GE-SpMM(GEneral-purpose Sparse Matrix-matrix Multiplication),用于GNN在GPU上的應用,可以更高效地加載數據,減少總內存事務,并優于cuSPARSE庫的SpMM算法;Wang等[11]提出了一種基于GPU用于SpMM算法的代碼生成器SparseRT,直接生成PTX(Parallel Thread Execution)代碼,加速了DNN(Deep Neural Network)的推理;Gale等[2]開發了基于CSR存儲格式的專門針對深度學習應用的SpMM算法的GPU實現,可以降低內存需求,相較于cuSPARSE平均可達到3.58的加速比;但當問題規模較大時,算法的性能會受到共享內存帶寬的限制。
本文針對一類稀疏矩陣提出一種新的存儲格式BRCV(Banded Row Column Value)。這一類稀疏矩陣的特點是非零元素呈帶狀分布,即具有一致列下標的相鄰行天然形成不同的帶子,同一帶子中非零元素的列下標可以不連續,即同一帶子中的非零元素呈線狀或塊狀分布;反之,位于相同行的所有塊也可形成一個帶子。因此帶稀疏存儲格式BRCV可看作分塊稀疏格式,包括均勻分塊稀疏格式BCSR及其變種可變分塊格式UBCSR的一種推廣。與這些分塊格式不同,BRCV不需要對帶子中的塊單獨標記和處理。帶狀稀疏矩陣廣泛存在于和圖相關的應用中,如現實世界中的圖廣泛存在社區結構[32-35],這種圖的鄰接矩陣就天然呈稀疏帶狀分布,且該帶狀不是傳統的對角帶狀[36]。
本文的主要工作如下:
1)提出了帶稀疏存儲格式BRCV。與CSR格式相比,可以顯著降低存儲復雜度。
2)提出了基于BRCV格式的spMM算法以及高效的GPU實現。與已有的基于CSR格式的GPU實現相比,基于BRCV格式的GPU實現能同時對稀疏和稠密矩陣高效地利用GPU的共享內存。
3)提出了一種新的基于CSR格式的SpMM的高效GPU實現SCSR(Shared-memory CSR)。它采用了分塊和針對稀疏矩陣的共享內存優化等技術,效率優于NVIDIA的cuSPARSE。
4)在隨機生成的帶狀稀疏矩陣和GNN實際應用的數據集上對基于BRCV的SpMM實現的性能進行了評估。結果表明SpMM算法的GPU實現性能明顯優于SCSR、cuBLAS(CUDA Basic Linear Algebra Subroutines)和基于CSR格式的cuSPARSE,多數情況下性能優于基于塊稀疏格式的cuSPARSE,驗證了BRCV格式的優勢。
本文團隊針對工作1)和2)已提交了一篇專利[37],并簡單地報告了基于BRCV格式的稀疏稠密矩陣乘法的GPU性能。
1 背景知識
1.1 稀疏矩陣及存儲格式


圖1 稀疏矩陣
1.2 稀疏矩陣乘法

1.3 塊稀疏格式
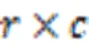
BCSR相較于CSR具有數據連續性的優勢,且分塊大小固定使得并行優化效率提升。但由于BCSR格式要求分塊嚴格對齊,當矩陣維度不能整除分塊大小時,需要填充整行或整列的零元;另一方面,BCSR格式在存儲過程中將每個非零塊看作稠密矩陣進行存儲,因此會顯式地引入更多零元素,尤其當非零元在稀疏矩陣中分布較為分散時,會帶來較大的存儲代價和性能損失。
圖2顯示了如何對圖1中的矩陣以BCSR格式存儲(分塊大小為2×2)。實際計算中,分塊大小的取值可以根據矩陣特征取最優值。

圖2 BCSR格式
1.4 GPU及CUDA編程模型
GPU的系統架構是單指令多線程(Single Instruction Multiple Threads, SIMT)。一個GPU由多個流多處理器(Streaming Multiprocessor, SM)組成,一個SM由多個流處理器(Streaming Processor, SP)和一些其他的關鍵資源(寄存器、共享內存)組成。統一計算設備架構(Compute Unified Device Architecture, CUDA)提供了應用程序和GPU硬件之間的橋梁。在CUDA架構下,一個程序被劃分為Host端和Device端兩部分:Host 端指在CPU上執行的部分,Device 端指在GPU上執行的部分。CUDA中的核心概念是內核函數,內核函數從 CPU 端調用,運行在GPU上,一般把算法最耗時的部分放在內核函數中,利用GPU強大的計算能力快速完成。
在CUDA架構下,GPU執行時的最小單位是線程(Thread)。CUDA將線程組織成幾個不同的層次:網格(Gird)、線程塊(Thread Block)、線程束(Warp)和線程。幾個線程可以組成一個線程塊,幾個線程塊可以組成一個線程網格,線程塊中的線程被組織成Warp的形式,每個周期、每個SM的硬件調度程序都會選擇下一個要執行的Warp(即只有Warp被交換進出,而不是單獨的線程),使用細粒度多線程同步隱藏內存訪問延遲。在內核函數中,不同線程塊之間彼此獨立,不能相互通信,按照任意順序串行或并行執行。每個線程有自己的寄存器空間,同一個線程塊中的每個線程則可以共享一份共享內存,所有的線程都共享一份全局內存、常量內存和紋理內存。共享內存比寄存器慢,但是比全局內存快,因此適當使用共享內存和寄存器資源利用數據重用和局部性對性能至關重要。
1.5 GNN和圖社區結構
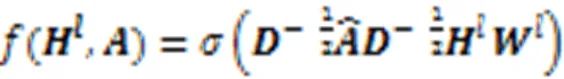
一個網絡中的社區結構是指網絡中的節點集合滿足:1)同一社區的節點之間聯系相對緊密;2)不同社區的節點之間聯系相對稀疏的結構屬性,這些節點組成的集合就是社區,一個簡單的具有社區結構的網絡如圖3(a)所示,它的鄰接矩陣見圖3(b)。容易看出,鄰接矩陣有4個帶子,對于一般的具有社區結構性質的圖,鄰接矩陣也具有帶狀稀疏結構。

圖3 社區結構網絡
2 帶稀疏矩陣存儲格式
2.1 帶稀疏矩陣概念
稀疏矩陣中有一種常見的具有局部性特征結構的矩陣:帶稀疏矩陣,如圖4所示。該類型的矩陣有若干稀疏帶,同一個稀疏帶里所有行的非零元列下標均相同,稀疏帶內的行數稱為該稀疏帶的高度。

圖4 帶稀疏矩陣
2.2 帶稀疏格式
針對帶稀疏矩陣的性質,對CSR格式改進,提出了帶稀疏矩陣的數據存儲格式BRCV,以減小冗余的存儲空間,有利于帶稀疏矩陣乘法的高效GPU實現。
采用BRCV格式存儲時可表示為:
因此,采用BRCV格式只需存儲42個元素,而采用CSR格式需要存儲63個元素,采用BCSR格式需要存儲75個元素。顯然,BRCV格式優于CSR和BCSR格式。其中,BCSR格式所需存儲空間與分塊大小有關,實驗中根據平臺特征和優化技術的不同,定義的分塊大小也不同,在此例中即使采用更佳的分塊大小5×1,BCSR格式仍需存儲45個元素,存儲復雜度高于BRCV格式。
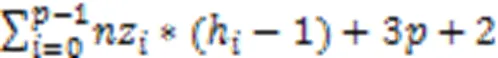
證明 BRCV格式的存儲復雜度為:

CSR格式的存儲復雜度為:
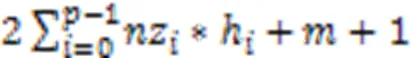
式(2)減去式(1)得到:

因此,當式(3)結果大于0時,CSR格式的存儲復雜度高于BRCV格式的存儲復雜度。

推論得證。
2.3 稀疏稠密矩陣乘法
本文給出一種基于BRCV格式的SpMM算法,見算法1。
算法1 基于BRCV格式的SpMM算法。
1) for=0 to-1 do
2) for=0 to-1 do
3)=[+1]-[]
4) for=0 to[+1]-[]-1 do
5)=0
6)=[] +
7) for=0 to-1 do
8)=[[]+]
9)+=[+]*[,]
10)[+[],]=
2.4 等高帶稀疏矩陣乘法EBRCV
2.5 BRCV相對于CSR的優勢
3 帶稀疏矩陣GPU實現
3.1 基本思想
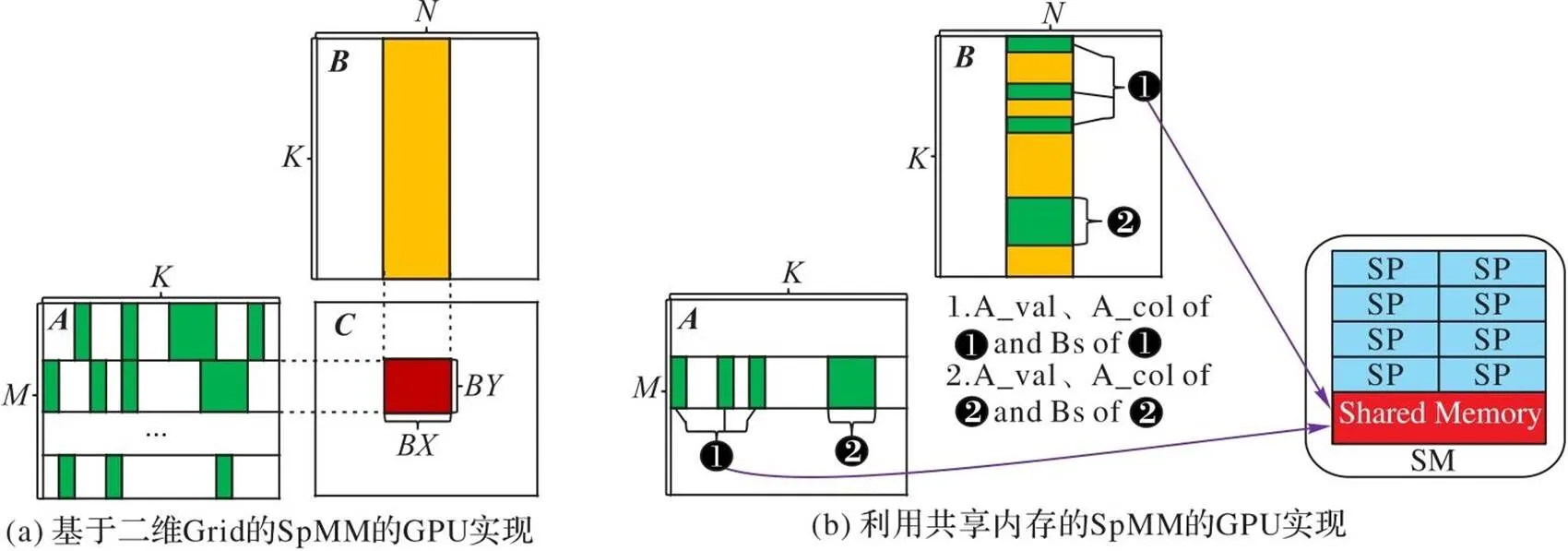
圖5 基于BRCV格式的SpMM的GPU實現
3.2 具體實現
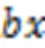
1)=blockIdx.,=blockIdx.
2)=threadIdx.,=threadIdx.
3)=*blockDim.+
4)=[],=[]
5)=[+1]–[]
6)=%= 0?:%
7)=*+
8) if 9)=[+1]–[] 10)=0 11)=[]+* 12) for=0 to-1 stepdo 13) /*apply for shared memory:[]、 [][]、[][]*/ /*load.col、.val with tile*/ 14) if+ 15)[]=[[]++] 16)[][]=[++] 17) __syncthreads() 18) /*loadwith tile×*/ 19) for=0 to-1 stepdo 20)=+ 21) if 22)=[] 23)[][]=[,] 24) __syncthreads() 25) /*consume the loaded elements*/ 26) for=0 to-1 do 27) if<-then 28)+=[][]*[][] 29) __syncthreads() 30)[[]+,] = 基準三為NVIDIA公司開發的一個高性能cuBLAS數值庫,記為cuBLAS[39]。cuBLAS是標準基本線性代數子例程(Basic Linear Algebra Subroutine, BLAS)的CUDA實現,包含了高性能的矩陣乘法。 在以下兩種不同的GPU平臺上對隨機生成的稀疏帶狀矩陣進行實驗,實驗更具有說服性,更能說明本文格式的優勢。 1)CPU為Intel Core i9-9900 3.10 GHz,8核,16 GB內存,GPU為NVIDIA GeForce RTX 2060,CUDA Version:11.7。 2)CPU為11th Gen Intel Core i9-11900K CPU,3.50 GHz,8核,128 GB內存,顯卡為NVIDIA GeForce RTX 3080,CUDA Version:11.6。 為了科學地評估SpMM的3種GPU實現的性能,選取了5類測試用例。 針對等高帶稀疏矩陣: 例1 固定帶高,考察每行非零元數變化時3種實現的性能差異。 例2 固定每行非零元數,考察稀疏帶高度變化時3種實現的性能差異。 針對非等高的帶稀疏矩陣: 例3 考察線程塊的負載均衡率變化時3種實現的性能差異。 例4 令稀疏帶的高度在不同范圍內取值,以考察BRCV效率較高的稀疏帶高度范圍。 例5 稀疏帶的高度與每行非零元數均隨機,以考察一般情況下不同實現的性能差異。 此外,為了評估BRCV格式的SpMM的GPU實現在GNN應用中的性能,選取了兩類用于不同圖任務的數據集。 1)圖分類任務。 選自不同領域內的6組數據集。生物化學領域:BZR_MD、COX2_MD、DHFR_MD和ER_MD;社交網絡領域:IMDB-BINARY和IMDB-MULTI,這幾組數據均可在TUDataset數據集[41]中找到(TUDataset是一組用于圖形學習的基準數據集)。 以用于苯二氮卓受體的配體數據集BZR_MD為例,如表1所示,BZR_MD數據集由306個子圖組成,每個子圖對應一個鄰接矩陣,每個鄰接矩陣均可視為一個稀疏帶,子圖的節點數代表這個稀疏帶的帶高,則由這些子圖拼接而成的大的稀疏矩陣自然地形成帶狀結構,數據集的總節點數代表稀疏矩陣的維度。其他數據集同理。 表1圖分類數據集的詳情 2)社區探測任務。 選自社交網絡領域的兩組數據集:AIRPORT[42]、email-Eu-core[43]。AIRPORT是一個直推式的數據集,其中節點表示機場,邊表示連接機場間的航線,選取部分機場和航線數;email-Eu-core數據集節選自某個歐洲大型研究機構在18個月期間的電子郵件網絡,給定一組電子郵件,每個節點對應一個電子郵件,如果存在兩個節點雙向交換消息,就在它們中間創建一個邊。 對于這兩組數據集,對選取的部分節點進行了重排,使它呈現更規則的帶狀稀疏分布,并且由于機場數據集AIRPORT和電子郵件數據集email-Eu-core的特殊性,在合理范圍內增加了一些節點之間的邊。AIRPORT數據集包含3188個節點,48441條邊;email-Eu-core數據集包含1005個節點,28469條邊。 針對隨機生成的例1~4,本文綜合考慮了每行非零元數、稀疏帶高度和線程塊的負載均衡等相關因素,對比實驗基準一cuSPARSE和實驗基準二SCSR,驗證BRCV實現的適用范圍和算法性能加速效果。針對隨機生成的例5和GNN應用中的數據集,本文對比了4個實驗基準:cuSPARSE、SCSR、cuBLAS和Block-SpMM,以考察一般情況下,以及GNN的算子加速中不同SpMM實現的性能差異。 圖6 不同GPU上稀疏矩陣每行非零元數變化時,不同SpMM實現在例1上的性能 Fig. 6 Performance of different SpMM implementations for example 1 on different GPU when number of non-zero elements on each row of sparse matrix varies 圖7 不同GPU上稀疏矩陣帶高變化時,不同SpMM實現在例2上的性能 圖8 不同GPU上線程塊負載均衡率變化時,不同SpMM實現在例3上的性能 圖9 不同GPU上非等高帶稀疏矩陣帶高變化時,不同SpMM實現在例4上的性能 圖8、9表示非等高帶稀疏矩陣在不同GPU平臺上3種SpMM實現的實驗結果。可以看出:隨著線程塊負載均衡率的增大,BRCV性能明顯提升,并逐漸超過SCSR;隨著非等高帶稀疏矩陣最小帶高的增大,BRCV的性能逐漸超過cuSPARSE和SCSR。性能提升的主要原因是:與SCSR和cuSPARSE這兩種實現相比,BRCV實現對SpMM算法中的稀疏矩陣和稠密矩陣均使用了共享內存優化,實現了稠密矩陣的行復用,減少了數據傳輸時間,提高了計算效率。 表2不同GPU上非等高帶稀疏矩陣帶高和每行非零元數均變化時,不同SpMM實現的性能對比 Tab.2 Performance comparison of different SpMM implementations on different GPU when both band height and the number of non-zero elements on each row of non-equal height band sparse matrix vary 注:加粗表示最大值,下畫線表示次優值,雙下畫線表示最差結果;最大、最小加速比表示本文算法與最差及次優結果的比值。 表3BRCV相較于其他4種SpMM在圖分類和社區探測數據集上實現的加速比 Tab.3 Speedup ratios of BRCV compared to other four SpMM implementations on graph classification and community detection datasets [1] 劉偉峰. 高可擴展、高性能和高實用的稀疏矩陣計算研究進展與挑戰[J]. 數值計算與計算機應用, 2020, 41(4): 259-281.(LIU W F. Highly-scalable, highly-performant and highly-practical sparse matrix computations: progress and challenges[J]. Journal of Numerical Computation and Computer Applications, 2020, 41(4): 259-281.) [2] GALE T, ZAHARIA M, YOUNG C, et al. Sparse GPU kernels for deep learning[C]// Proceedings of the 2020 International Conference for High Performance Computing, Networking, Storage and Analysis. Piscataway: IEEE, 2020: 1-14. [3] YANG C, BULU? A, OWENS J D. Design principles for sparse matrix multiplication on the GPU[C]// Proceedings of the 2018 European Conference on Parallel Processing, LNCS 11014. Cham: Springer, 2018: 672-687. [4] XU K, HU W, LESKOVEC J, et al. How powerful are graph neural networks?[EB/OL]. (2019-02-22)[2023-02-25].https://arxiv.org/pdf/1810.00826.pdf. [5] XIN J, YE X, ZHENG L, et al. Fast sparse deep neural network inference with flexible SpMM optimization space exploration[C]// Proceedings of the 2021 IEEE High Performance Extreme Computing Conference. Piscataway: IEEE, 2021: 1-7. [6] DAVE S, BAGHDADI R, NOWATZKI T, et al. Hardware acceleration of sparse and irregular tensor computations of ML models: a survey and insights [J]. Proceedings of the IEEE, 2021, 109(10): 1706-1752. [7] COLEY C W, JIN W, ROGERS L, et al. A graph-convolutional neural network model for the prediction of chemical reactivity[J]. Chemical Science, 2019, 10(2): 370-377. [8] HUANG G, DAI G, WANG Y, et al. GE-SpMM: general-purpose sparse matrix-matrix multiplication on GPUs for graph neural networks [C]// Proceedings of the 2020 International Conference for High Performance Computing, Networking,Storage and Analysis. Piscataway: IEEE, 2020: 1-12. [9] NAGASAKA Y, NUKADA A, KOJIMA R, et al. Batched sparse matrix multiplication for accelerating graph convolutional networks[C]// Proceedings of the 19th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing. Piscataway: IEEE, 2019: 231-240. [10] HOEFLER T, ALISTARH D, BEN-NUN T, et al. Sparsity in deep learning: pruning and growth for efficient inference and training in neural networks[J]. Journal of Machine Learning Research, 2021, 22: 1-124. [11] WANG Z. SparseRT: accelerating unstructured sparsity on GPUs for deep learning inference [C]// Proceedings of the 2020 ACM International Conference on Parallel Architectures and Compilation Techniques. New York: ACM, 2020: 31-42. [12] CHILD R, GRAY S, RADFORD A, et al. Generating long sequences with sparse Transformers[EB/OL]. (2019-04-23)[2023-02-25].https://arxiv.org/pdf/1904.10509.pdf. [13] KITAEV N, KAISER ?, LEVSKAYA A. Reformer: the efficient Transformer [EB/OL]. (2020-02-18)[2023-02-25].https://arxiv.org/pdf/2001.04451.pdf. [14] YANG C, BULU? A, OWENS J D. GraphBLAST: a high-performance linear algebra-based graph framework on the GPU[J]. ACM Transactions on Mathematical Software, 2022, 48(1): 1-51. [15] LANGR D, TVRDíK P. Evaluation criteria for sparse matrix storage formats [J]. IEEE Transactions on Parallel and Distributed Systems, 2016, 27(2): 428-440. [16] CHOU S, KJOLSTAD F, AMARASINGHE S. Automatic generation of efficient sparse tensor format conversion routines[C]// Proceedings of the 41st ACM SIGPLAN Conference on Programming Language Design and Implementation. New York: ACM, 2020: 823-838. [17] LIU W, VINTER B. CSR5: an efficient storage format for cross-platform sparse matrix-vector multiplication[C]// Proceedings of the 29th ACM International Conference on Supercomputing. New York: ACM, 2015: 339-350. [18] ECKER J P, BERRENDORF R, MANNUSS F. New efficient general sparse matrix formats for parallel SpMV operations [C]// Proceedings of the 2017 European Conference on Parallel Processing, LNCS 10417. Cham: Springer, 2017: 523-537. [19] XIE B, ZHAN J, LIU X, et al. CVR: efficient vectorization of SpMV on x86 processors[C]// Proceedings of the 2018 International Symposium on Code Generation and Optimization. New York: ACM, 2018: 149-162. [20] 程凱,田瑾,馬瑞琳.基于GPU的高效稀疏矩陣存儲格式研究[J].計算機工程, 2018, 44(8): 54-60.(CHENG K, TIAN J, MA R L. Study on efficient storage format of sparse matrix based on GPU[J]. Computer Engineering, 2018, 44(8): 54-60.) [21] ZHANG Y, YANG W, LI K, et al. Performance analysis and optimization for SpMV based on aligned storage formats on an ARM processor[J]. Journal of Parallel and Distributed Computing, 2021, 158: 126-137. [22] CORONADO-BARRIENTOS E, ANTONIOLETTI M, GARCIA-LOUREIRO A. A new AXT format for an efficient SpMV product using AVX-512 instructions and CUDA[J]. Advances in Engineering Software, 2021, 156: No.102997. [23] BIAN H, HUANG J, DONG R, et al. A simple and efficient storage format for SIMD-accelerated SpMV[J]. Cluster Computing, 2021, 24(4): 3431-3448. [24] KARIMI E, AGOSTINI N B, DONG S, et al. VCSR: an efficient GPU memory-aware sparse format[J]. IEEE Transactions on Parallel and Distributed Systems, 2022, 33(12):3977-3989. [25] VUDUC R W, MOON H J. Fast sparse matrix-vector multiplication by exploiting variable block structure[C]// Proceedings of the 2005 International Conference on High Performance Computing and Communications, LNCS 3726. Berlin: Springer, 2005: 807-816. [26] ALMASRI M, ABU-SUFAH W. CCF: an efficient SpMV storage format for AVX512 platforms[J]. Parallel Computing, 2020, 100: No.102710. [27] 楊世偉,蔣國平,宋玉蓉,等. 基于GPU的稀疏矩陣存儲格式優化研究[J]. 計算機工程, 2019, 45(9): 23-31,39.(YANG S W, JIANG G P, SONG Y R, et al. Research on storage format optimization of sparse matrix based on GPU[J]. Computer Engineering, 2019, 45(9): 23-31, 39.) [28] LI Y, XIE P, CHEN X, et al. VBSF: a new storage format for SIMD sparse matrix-vector multiplication on modern processors[J]. The Journal of Supercomputing, 2020, 76(3): 2063-2081. [29] AHRENS P, BOMAN E G. On optimal partitioning for sparse matrices in variable block row format[EB/OL]. (2021-05-25)[2023-02-25].https://arxiv.org/pdf/2005.12414.pdf. [30] ALIAGA J I, ANZT H, GRüTZMACHER T, et al. Compression and load balancing for efficient sparse matrix-vector product on multicore processors and graphics processing units[J]. Concurrency and Computation: Practice and Experience, 2022, 34(14): No.e6515. [31] NVIDIA. cuSPARSE library [EB/OL]. (2022-12)[2023-02-28].https://docs.nvidia.com/cuda/pdf/CUSPARSE_Library.pdf. [32] CHEN C, WU W. A geometric approach for analyzing parametric biological systems by exploiting block triangular structure[J]. SIAM Journal on Applied Dynamical Systems, 2022, 21(2): 1573-1596. [33] WU Z, PAN S, CHEN F, et al. A comprehensive survey on graph neural networks [J]. IEEE Transactions on Neural Networks and Learning Systems, 2021, 32(1): 4-24. [34] LIU F, XUE S, WU J, et al. Deep learning for community detection: progress, challenges and opportunities[C]// Proceedings of the 29th International Joint Conference on Artificial Intelligence. California: ijcai.org, 2020: 4981-4987. [35] RANI S, MEHROTRA M. Community detection in social networks: literature review[J]. Journal of Information and Knowledge Management, 2019, 18(2): No.1950019. [36] GALLOPOULOS E, PHILIPPE B, SAMEH A H. Banded linear systems[M]// Parallelism in Matrix Computations, SCIENTCOMP. Dordrecht: Springer, 2016: 91-163. [37] 中國科學院重慶綠色智能技術研究院. 一種帶狀稀疏矩陣的數據存儲格式及其乘法加速方法: 202210931011.6[P]. 2022-11-08.(Chongqing Institute of Green and Intelligent Technology of Chinese Academy of Sciences. A data storage format for strip sparse matrix and its multiplication acceleration method: 202210931011.6 [P]. 2022-11-08.) [38] KIPF T N, WELLING M. Semi-supervised classification with graph convolutional networks [EB/OL]. (2017-02-22)[2023-03-01].https://arxiv.org/pdf/1609.02907.pdf. [39] NVIIDA. Introduction of cuBLAS library[EB/OL]. [2023-04-01].http://docs.nvidia.com/cuda/cublas/index.html. [40] YAMAGUCHI T, BUSATO F. Accelerating matrix multiplication with block sparse format and NVIDIA tensor cores[EB/OL]. (2021-03-19)[2023-04-09].https://developer.nvidia.com/blog/accelerating- matrix- multiplication- with- block-sparse-format-and-nvidia-tensor-cores. [41] MORRIS C, KRIEGE N M,BAUSE F, et al. TUDataset: a collection of benchmark datasets for learning with graphs[EB/OL]. (2020-07-16)[2023-02-28].https://arxiv.org/pdf/2007.08663.pdf. [42] ZHANG M, CHEN Y. Link prediction based on graph neural networks [C]// Proceedings of the 32nd International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2018: 5171-5181. [43] LESKOVEC J, KLEINBERG J, FALOUTSOS C. Graph evolution: densification and shrinking diameters[J]. ACM Transactions on Knowledge Discovery from Data, 2007, 1(1): No.2. Band sparse matrix multiplication and efficient GPU implementation LIU Li1,2, CHEN Changbo1* (1,,400714,;2,,400714,) Sparse-dense Matrix Multiplication (SpMM) is widely used in the fields such as scientific computing and deep learning, and it is of great importance to improve its efficiency. For a class of sparse matrices with band feature, a new storage format BRCV (Banded Row Column Value) and an SpMM algorithm based on this format as well as an efficient Graphics Processing Unit (GPU) implementation were proposed. Due to the fact that each sparse band can contain multiple sparse blocks, the proposed format can be seen as a generalization of the block sparse matrix format. Compared with the commonly used CSR (Compressed Sparse Row)format, BRCV format was able to significantly reduce the storage complexity by avoiding redundant storage of column indices in sparse bands. At the same time, the GPU implementation of SpMM based on BRCV format was able to make more efficient use of GPU’s shared memory and improve the computational efficiency of SpMM algorithm by reusing the rows of both sparse and dense matrices. For randomly generated band sparse matrices, experimental results on two different GPU platforms show that BRCV outperforms not only cuBLAS (CUDA Basic Linear Algebra Subroutines), but also cuSPARSE based on CSR and block sparse formats. Specifically, compared with cuSPARSE based on CSR format, BRCV has the maximum speedup ratio of 6.20 and 4.77 respectively. Moreover, the new implementation was applied to accelerate the SpMM operator in Graph Neural Network (GNN). Experimental results on real application datasets show that BRCV outperforms cuBLAS and cuSPARSE based on CSR format, also outperforms cuSPARSE based on block sparse format in most cases. In specific, compared with cuSPARSE based on CSR format, BRCV has the maximum speedup ratio reached 4.47. The above results indicate that BRCV can improve the efficiency of SpMM effectively. band sparse matrix; sparse matrix storage format; sparse matrix multiplication; Graphics Processing Unit (GPU); shared memory This work is partially supported by Youth Top-notch Talent Project of Chongqing Talent Plan (2021000263). LIU Li, born in 1998, M. S. candidate. Her research interests include high-performance computing, deep learning. CHEN Changbo, born in 1981, Ph. D., research fellow. His research interests include computer algebra, high-performance computing, applied machine learning. TP332 A 1001-9081(2023)12-3856-12 10.11772/j.issn.1001-9081.2022111720 2022?11?21; 2023?05?04; 2023?05?06。 重慶英才計劃青年拔尖人才項目(2021000263)。 劉麗(1998—),女,河南信陽人,碩士研究生,CCF會員,主要研究方向:高性能計算、深度學習;陳長波(1981—),男,山東濟寧人,研究員,博士,CCF會員,主要研究方向:計算機代數、高性能計算、應用機器學習。3.3 等高的簡化處理
4 實驗與結果分析

4.1 基準

4.2 實驗平臺
4.3 測試用例
4.4 實驗結果分析









5 結語
