基于圖模型與注意力機制的室外場景點云分割模型
2024-01-09 04:01:22廉飛宇張良王杰棟靳于康柴玉
計算機應用 2023年12期
廉飛宇,張良*,王杰棟,靳于康,柴玉
基于圖模型與注意力機制的室外場景點云分割模型
廉飛宇1,2,張良1,2*,王杰棟3,靳于康1,2,柴玉1,2
(1.湖北大學 資源環境學院,武漢 430062; 2.區域開發與環境響應湖北省重點實驗室(湖北大學),武漢 430062; 3.浙江省第二測繪院,杭州 310012)(?通信作者電子郵箱zhangliang@hubu.edu.cn)
針對在多對象且空間拓撲關系復雜的室外場景環境中相似地類區分難的問題,提出一種結合圖模型與注意力機制模塊的A-Edge-SPG(Attention-EdgeConv SuperPoint Graph)圖神經網絡。首先,利用圖割和幾何特征結合的方法對超點進行分割;其次,在超點內部構造局部鄰接圖,從而在捕獲場景中點云的上下文信息的同時利用注意力機制模塊凸顯關鍵信息;最后,構建超點圖(SPG)模型,并采用門控循環單元(GRU)聚合超點和超邊特征,實現對不同地類點云間的精確分割。在Semantic3D數據集上對A-Edge-SPG模型和SPG-Net(SPG neural Network)模型的語義分割效果進行比較分析。實驗結果表明,相較于SPG模型,A-Edge-SPG模型在總體分割精度(OA)、平均交并比(mIoU)和平均精度均值(mAA)上分別提升了1.8、5.1和2.8個百分點,并且在高植被、矮植被等相似地類的分割精度上取得了明顯的提升,改善了相似地類間語義分割的效果。
語義分割;室外場景;局部特征;注意力機制模塊;局部鄰接圖;圖模型
0 引言
近年來,激光掃描技術[1]迅速發展,已成為一種快速采集三維信息的重要途徑,在自動駕駛、智慧城市建設等領域具有廣泛的應用。對點云進行高效準確的語義分割是上述應用的前提。點云語義分割指通過分析三維點云數據的原始信息、局部鄰域等信息,將特定語義標簽分配給每個點云數據的過程;在數據量大、地物種類復雜的室外場景中對地類的準確語義分割是一項具有挑戰性的難題[2-3],特別是部分形態差異小的地物種類難以區分,如高植被與矮植被、自然地面與人造地面等。現有大多數研究通過人工特征進行點云語義分割[4-7],但人工特征的設計建立在一定的先驗知識和假設上,存在一定的局限性,難以準確描述室外復雜場景中的高層次語義特征,表征地類有效信息,限制了基于人工特征的點云語義分割方法在室外場景的應用[8]。
為實現高層次語義特征信息的自動提取,建立從特征信息到語義標簽的映射關系[9],大量學者開始將深度學習的方法應用在點云語義分割領域。根據處理單元的不同,點云深度學習網絡主要分為以下三類[10]:
1)基于體素的方法。由于點云具有稀疏性和離散型的特點,圖像領域的網絡架構難以直接應用于點云數據,部分學者通過對點云進行體素化處理后再進行語義分割。體素是二維柵格在三維空間的延伸,將三維空間按照一定的分辨率進行格網劃分,落在同一格網內部的點云視為一個體素。Maturana等[11]提出了VoxNet,通過集成體積占用網格與監督三維卷積神經網絡(Convolutional Neural Network, CNN)解決點云語義分割的框架;Wu等[12]利用體素描述三維模型,并使用卷積深度置信網絡,對體素化后的數據實現目標識別;Li等[13]利用條件隨機場(Conditional Random Field, CRF)框架,結合全局和局部特征信息分割體素化后的點云。體素化過程解決了不規則點云數據難以直接采用傳統圖像深度學習網絡進行學習的問題,但不可避免地造成了信息丟失,信息丟失程度與體素分辨率密切相關;另外,由于點云的稀疏分布,存在大量的無效體素,運算效率低。
2)基于原始點云的方法。為解決體素化方法對點云信息造成的損失和計算量大等問題,學者們對如何利用深度學習網絡直接處理原始點云數據展開研究。相較于二維圖像,解決點云的無序性、不規則分布問題是將點云數據直接應用于深度學習網絡的關鍵。Qi等[14]提出的PointNet通過可學習的旋轉矩陣對齊輸入數據和特征,利用多層感知機(MultiLayer Perceptron, MLP)學習特征,采用對稱函數緩解點云的無序性問題,成為基于原始點云數據進行深度學習的開端,但由于PointNet僅考慮點云的單點信息,導致對局部的學習能力不足,在復雜場景下學習效果不好;改進的PointNet++[15]通過最遠點采樣選取一定的種子點后,針對種子點的鄰域分析PointNet,提升了復雜場景的學習效果;DGCNN(Dynamic Graph CNN)[16]采用EdgeConv卷積方式,通過全連接層學習邊特征反映全局信息,且EdgeConv能夠有效地集成其他已有網絡;趙中陽等[17]通過建立多個不同尺度的鄰域空間,提出一種多尺度特征與PointNet結合的模型,結合顏色特征對城區目標進行分類。上述方法直接處理點云,為深度學習網絡應用于點云領域奠定了應用基礎;但是,針對單個點云進行處理,難以滿足大場景中海量點云的需求;其次,單點包含的特征信息有限,限制了復雜場景中的分割效果。
3)面向對象的方法。為提高點云語義分割的效率、考慮點云間的上下文信息,將面向對象的思想引入點云深度學習網絡領域:馬京暉等[18]利用均值(-Means)聚類方法對點云進行聚類,通過PointNet分類聚類后的點簇;羅海峰等[19]通過連通分支聚類算法聚類點云,并采用基于體素的方法分割重疊點云,最后利用深度信念網絡對目標對象的二值圖像實現語義分割;Wang等[20]考慮利用點間空間結構獲得高質量的分類結果,首先對原始點云進行分簇,結合點簇之間點的空間信息,通過CNN分類點簇;Landrieu等[21]提出SPG-Net(SuperPoint Graph neural Network)點云語義分割算法,通過對點云數據構建超點圖,結合圖卷積模型,實現大場景點云的語義分割,有效彌補了PointNet等網絡處理大場景點云的弊端。
上述三類方法中,面向對象的方式在一定程度上減輕了對最優鄰域的依賴,減小了點云中噪聲對特征計算的影響,有利于幾何特征的計算,降低信息提取的不確定性;其次,對象衍生的一些新的特征屬性與所包含的點云間上下文信息有利于提高分類精度,在復雜的室外場景中表現出不錯的效果[22]。
室外場景點云通常包含一定的噪聲,地物種類和空間拓撲關系復雜。針對上述特點,Landrieu等[21]提出SPG-Net對室外場景點云進行語義分割,通過PointNet對分割對象提取特征,利用最大池化實現特征聚合,此類方式能夠在室外場景中不同地類之間存在較大形態差異時取得不錯的效果;然而,和其他大部分算法一樣,SPG-Net的特征提取方式過于簡單,當形態相似地物無法準確表達地類有效信息,進而難以取得理想的分割效果。基于此,本文在SPG-Net的基礎上提出一種結合圖模型與注意力機制模塊的A-Edge-SPG(Attention-EdgeConv SPG)圖神經網絡,通過在超點內部構建圖模型獲取點間上下文信息,得到超點內部細節特征,并結合注意力機制模塊,凸顯超點的關鍵信息,實現對有效信息的自適應選擇,最后結合循環神經網絡實現點云語義分割,解決復雜室外場景中形態相似的地物難以精確區分的問題。通在過在Semantic3D數據集上與SPG-Net進行分割精度對比,驗證了該網絡模型在室外場景中的有效性。
1 A?Edge?SPG
為了更高效地挖掘點云空間關系,本文以超點為基礎,結合圖模型與注意力機制模塊準確描述超點內部點云關系,通過構建深度超點圖網絡模型實現點云語義分割。具體步驟如下:1)首先利用圖割對室外大場景點云進行幾何同質分割,生成具備對象唯一性的分割對象,即超點;2)在超點內部構建局部鄰接圖,利用圖模型準確表征超點內部點云局部特征,通過圖節點與邊的關系更新信息,采用注意力機制模塊凸顯關鍵點信息,并通過多層A-EdgeConv(Attention-EdgeConv)模塊疊加不同特征空間的有效信息,實現對超點圖網絡節點的準確描述;3)最后通過門控循環單元(Gated Recurrent Unit, GRU)算法聚合超點、超邊特征,實現點云語義分割。網絡的整體架構如圖1所示。
1.1 基于超點的圖節點特征提取
1.1.1基于圖割的聚類
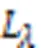

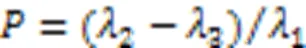

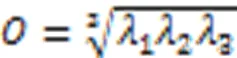
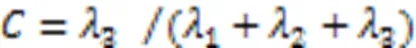
為構建超點圖網絡模型,對具有相同幾何特性的點云聚類生成超點。采用全局能量優化的方法將具有相同幾何特征的點進行聚類,根據文獻[24],定義全局能量函數如式(6)所示:

1.1.2基于A-EdgeConv的特征提取
對于超點,大多采用MLP獲取每個超點的屬性,這類方法將點云分塊后通過共享MLP提取全局特征信息,作為超點的特征向量,忽略了點云之間的上下文信息,造成局部信息提取不充分,無法滿足室外場景的需求。
為更好表征超點內部點云關系,本文以內部點云為中心構建局部鄰接圖,利用鄰接圖節點與邊的關系更新超點特征信息,準確描述超點局部結構;其次,考慮到不同特征信息在語義分割中的貢獻差異,提出融合注意力機制的A-EdgeConv特征提取模塊,突出關鍵信息,通過堆疊多層A-EdgeConv模塊解決復雜地物對象特征信息提取不充分的問題。超點信息提取模型的框架如圖2所示。圖2中,T-Net表示點云空間旋轉矩陣;表示超點內部點云數;表示超點內部單點的特征描述。
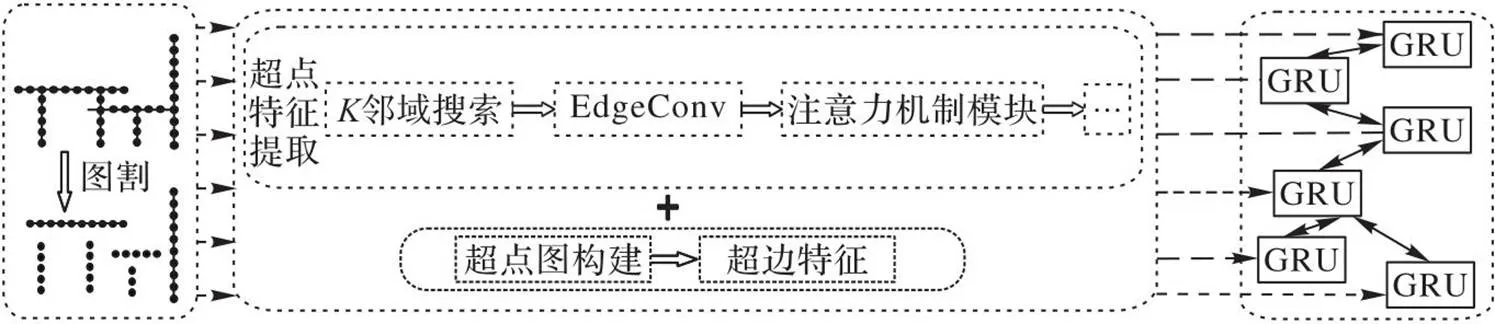
圖1 A-Edge-SPG圖神經網絡框架

圖2 超點信息提取模型的框架
1)EdgeConv。
PointNet率先將標準的CNN應用于點云特征提取,利用共享MLP將低維信息投影到高維空間,結合最大池化函數實現點云特征提取。這種信息提取方式沒有考慮鄰域內的點云空間關系,削弱了復雜環境下不同地物的特征表述,因此,本文通過構建局部鄰接圖(EdgeConv)描述超點局部結構,如圖3所示,在提取全局信息的同時,保留內部點云間的上下文信息,完善超點信息表述。

圖3 EdgeConv模塊示意圖
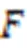
2)A-EdgeConv。
構建鄰接圖后,需要通過特征聚合壓縮高維特征信息,現有特征聚合方式通常采用最大/平均池化集成相鄰特征,簡單粗暴的池化操作易導致關鍵特征信息的丟失。關鍵特征信息丟失不僅增加了模型訓練的復雜程度,也導致了特征信息難以充分提取,影響分割精度。為增強關鍵信息在表征超點過程中的作用,在模型中針對不同特征部分賦予不同的權重,提出一種結合注意力機制自動學習超點重要局部特征的模塊A-EdgeConv,在構建局部鄰接圖時,不僅考慮鄰域點間距離差異對目標點的影響,并結合注意力機制模塊自適應地調節鄰域內點云對目標點的貢獻程度,突出關鍵信息。
注意力機制是一種基于Encoder-Decoder框架,模擬人腦注意力工作的模型,通過計算不同特征信息的概率分布,突出關鍵信息對輸出的影響,抽取更重要和關鍵的信息,從而優化模型并作出更為準確的判斷[26]。文獻[27]中表明,注意力機制使訓練網絡更加關注有效信息,有效減少最大池化/平均池化過程中的信息損失。利用注意力機制改進EdgeConv模塊,在考慮不同維度特征重要性的同時進行局部特征學習,有效減少信息丟失。實現流程如下:

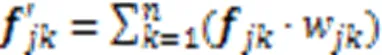
3)依此類推,獲取超點內采樣點云的特征描述。在獲取相對高維的特征信息后,在高維特征空間重復上述流程,以實現不同特征空間下的特征信息提取,最后通過多維特征空間的信息融合實現超點特征提取。A-EdgeConv模塊如圖4所示。圖4中,表示為超點內部點云X的個鄰近點,表示超點內部各點的特征描述。
圖4 A-EdgeConv模塊
Fig.4 A-EdgeConv module
特征提取器的偽代碼如下所示,其余過程代碼可參考文獻[21]。
for=1 todo //表示超點內部的點云數
nn.Sequential(nn.Conv2d(),nn.BatchNorm2d(),
nn.LeakyReLU()) //將低維特征升至高維
…
torch.cat(); //不同維度特征的拼接
nn.Dropout(); //防止數據過擬合
end

1.2 基于超點的語義分割
1.2.1超點圖構建

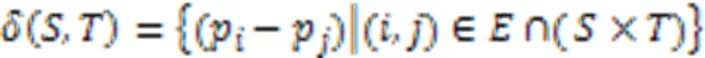
表1超邊特征定義
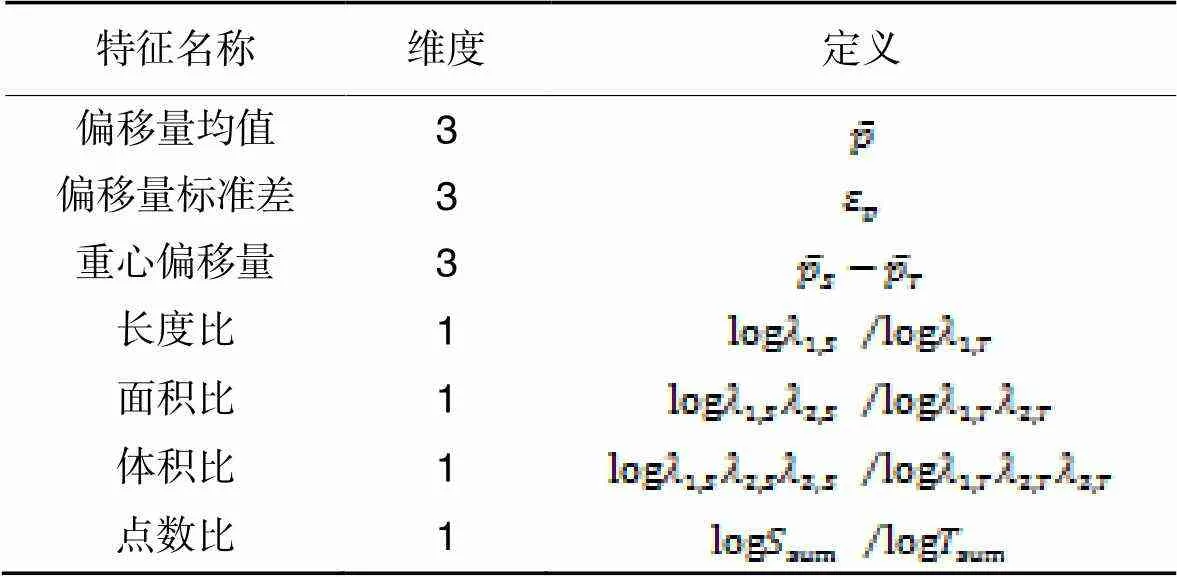
Tab.1 Hyperedge feature definition
1.2.2GRU控制單元
為更加高效地捕捉超點間的空間關系,將高維特征嵌入到循環神經單元[28]中,通過GRU控制單元實現超點圖模型的特征聚合。GRU是新一代的遞歸神經網絡,在結構上比標準長短期記憶網絡(Long Short-Term Memory, LSTM)更加簡單,擺脫了細胞狀態,通過隱藏狀態來傳輸信息,有效提高了特征聚合的時間效率[29]。GRU的示意圖如圖5所示。
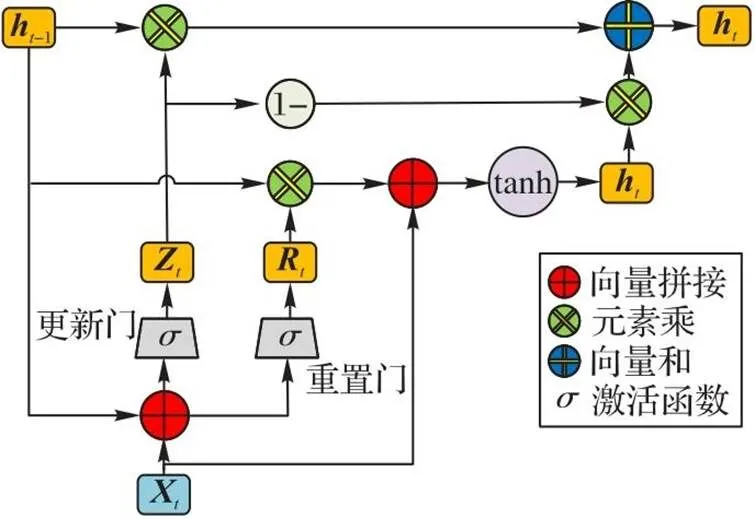
圖5 GRU示意圖
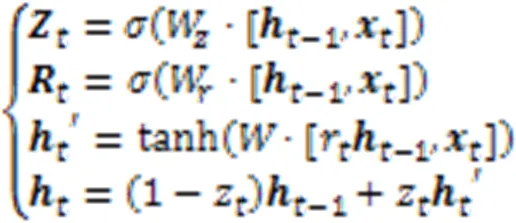
2 實驗與結果分析
2.1 實驗數據與網絡模型設計
為驗證模型在室外點云語義分割的有效性,本文采用Semantic3D數據集[30]中的bildstein_station1、domfountain _station1、bildstein_station3、domfountain_station2、neugasse_station1、sg27_station1、sg27_station2、sg27_station4、sg27_station5和sg28_station4共10塊數據集作為訓練數據,采用bildstein_station5、domfountain_station3和sg27_station9這3塊數據作為測試集驗證精度。實驗環境為RTX 1080Ti GPU顯卡,CPU為IntelCore-i5 10400F,服務器系統為Ubuntu 16.04,編程語言為Python 3.7,PyTorch 1.2。比較A-Edge-SPG和SPG-Net兩種網絡模型,循環迭代200次(epoch),學習率設為0.01,對比兩種網絡模型的分割精度。
2.2 語義分割精度評價
表2、3分別反映了A-Edge-SPG和SPG-Net在3塊測試數據下的總體分割精度(Overall segmentation Accuracy, OA)、平均精度均值(mean Average Accuracy, mAA)、平均交并比(mean Intersection over Union, mIoU)與各類別平均分割精度。A-Edge-SPG的分割精度整體優于SPG-Net,OA、mAA和mIoU上分別提高1.8、2.8和5.1個百分點。借助點云鄰接圖與注意力機制模塊,本文方法在高植被、矮植被、汽車等復雜地類的分割精度取得了明顯改進。
A-Edge-SPG模型對復雜地類具有較強的識別能力,能夠有效捕獲復雜地類的關鍵信息。各個類別中,在高植被、矮植被、汽車等結構較為復雜的地類,本文方法在分割精度上取得明顯的提升,分別提高了7.6、4.4和4.7個百分點,表明了局部特征與關鍵點信息在超點分割中具有顯著影響,驗證了本文方法的有效性;模型對于建筑、移動物體的精度也有一定提升,分別增加了2.1和0.4個百分點;由于人造地面與自然地面的特征較簡單且數據量較大,分割精度提升不明顯,分別提高0.1和1.1個百分點;在一些室外場景小類別地類上,如人造景觀,分割精度偏低,仍有較大提升空間。圖6展示了bildstein_station5數據的語義分割結果。

表2 兩個模型的OA、mAA與mIoU對比 單位:%
表3各類別平均精度均值對比 單位:%
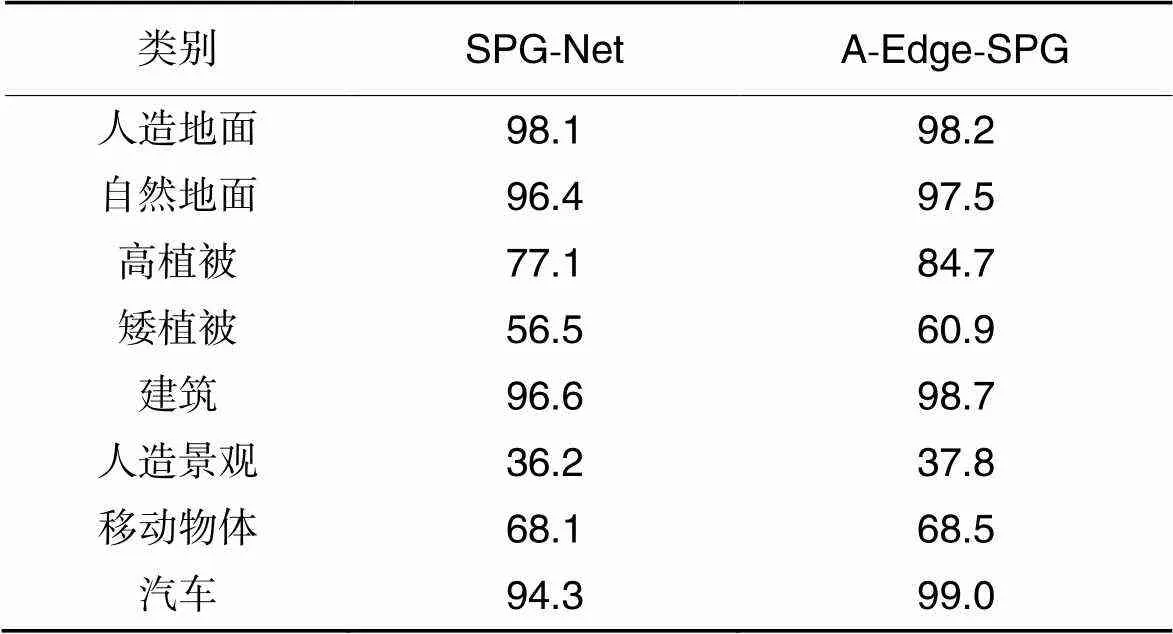
Tab.3 mAA comparison of different types unit:%
結合bildstein_station5數據語義分割結果可以發現,本文方法對高植被、矮植被的錯分效果得到了明顯改善,如圖中1、2區域所示,改正了大量的高、矮植被的錯分情況;其次,對于人造地面與自然地面的區分也有一定的提高,如圖中3、4區域所示,在一些細節區域能夠正確分割。綜上,本文方法在相似地物中的分割精度要優于SPG-Net,相較于SPG-Net,本文方法能夠有效捕捉高植被、矮植被的細節特征,在糾正相似地類的錯分情況方面表現出一定的魯棒性,提高了復雜地物的分割精度。
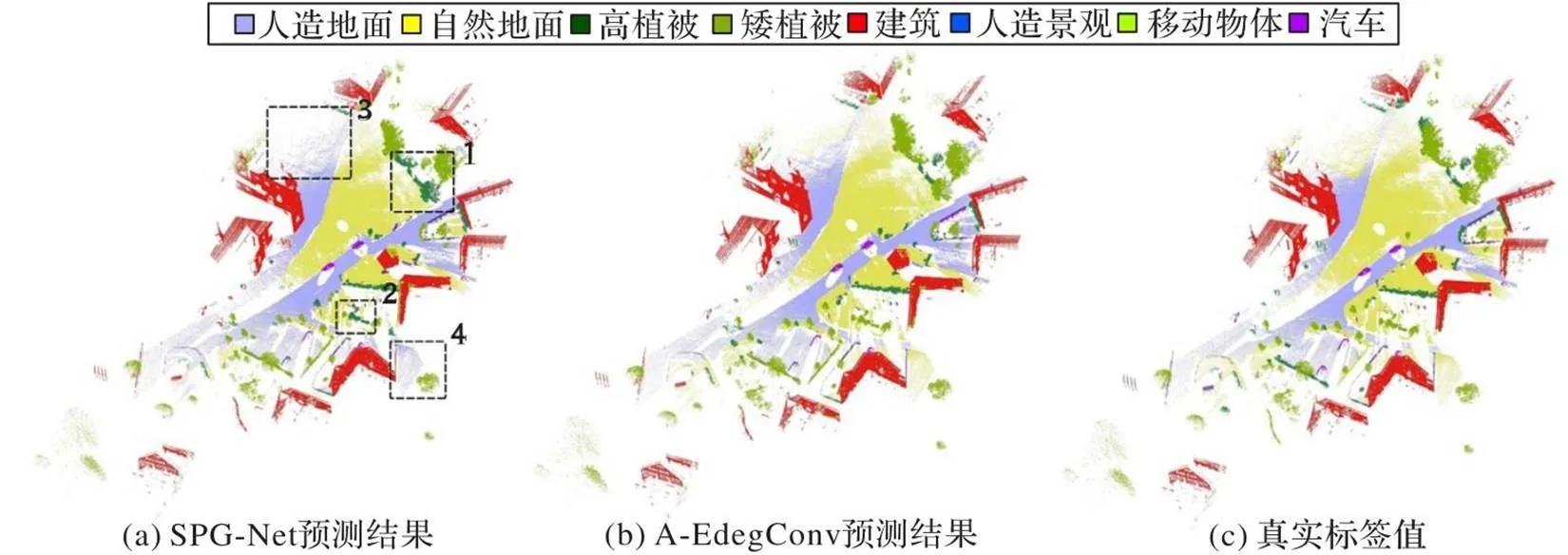
圖6 bildstein_station5數據語義分割結果
2.3 相關性能分析
2.3.1不同近鄰分析

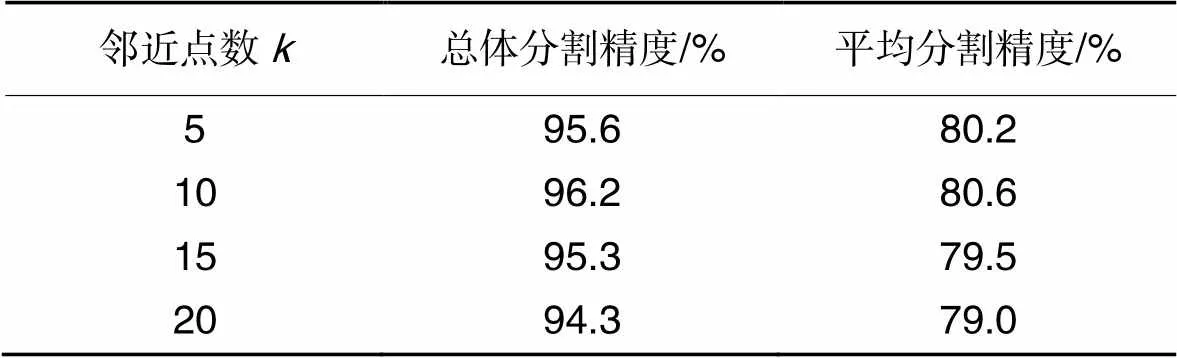
表4 不同近鄰數的分割精度對比
2.3.2網絡模型耗時分析
本文方法與SPG-Net的耗時環節主要為:點云下采樣、特征提取、超點圖構建、超點特征提取和標簽映射這5個部分。
由于本文方法在超點內部進行了局部鄰接圖的遍歷,相較于SPG-Net的時間消耗有所增加。針對該問題,采用k-d樹[31]的組織方式提高運行效率,結合GPU加速使每個epoch訓練時間增加在5 s內,總體運行時間不大于4 000 s,相較于SPG-Net的時間復雜度僅增加約16%,滿足實驗基本需求。兩種方法各階段的耗時對比如圖7所示。
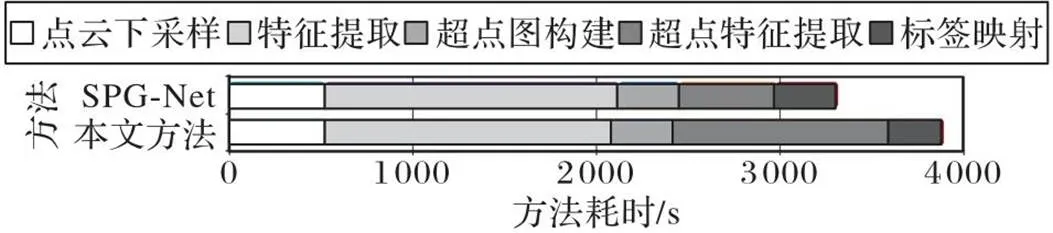
圖7 兩種方法耗時對比
3 結語
高質量的點云語義分割是點云數據在各個領域得以應用的前提。針對室外場景環境下形態相似地類區分程度低的問題,本文提出一種基于圖模型與注意力機制的A-EdgeConv模塊能夠更準確地提取超點信息,通過構建點云鄰接圖,描述超點局部結構,結合注意力機制考慮鄰域內不同特征的貢獻程度,突出關鍵點特征,以提高不同地類間的區分程度。通過對比實驗結果,本文方法優于SPG語義分割網絡,在精度方面取得一定的提升,改善了相似地類之間的區分效果,對高植被、矮植被等相似地類的識別結果取得明顯提高。然而,初始的聚類結果受人為特征算子的影響,如何采用深度學習的方法優化初始聚類方法成為下一步的研究重點;其次,考慮到本文方法在耗時上相較于SPG-Net仍有一定的提升空間,如何優化鄰域點遍歷方式也是下一步研究的重要方向。
[1] YANG B, WEI Z, LI Q, et al. Semiautomated building facade footprint extraction from mobile LiDAR point clouds[J]. IEEE Geoscience and Remote Sensing Letters, 2013, 10(4): 766-770.
[2] YANG B, DONG Z, ZHAO G, et al. Hierarchical extraction of urban objects from mobile laser scanning data[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2015, 99: 45-57.
[3] ZHANG J, LIN X. Advances in fusion of optical imagery and LiDAR point cloud applied to photogrammetry and remote sensing[J]. International Journal of Image and Data Fusion, 2017, 8(1): 1-31.
[4] 范士俊,張愛武,胡少興,等. 基于隨機森林的機載激光全波形點云數據分類方法[J]. 中國激光, 2013, 40(9): No.0914001.(FAN S J, ZHANG A W, HU S X, et al. A method of classification for airborne full waveform LiDAR data based on random forest[J]. Chinese Journal of Lasers, 2013, 40(9): No.0914001.)
[5] 楊必勝,梁福遜,黃榮剛. 三維激光掃描點云數據處理研究進展、挑戰與趨勢[J]. 測繪學報, 2017, 46(10): 1509-1516.(YANG B S, LIANG F X, HUANG R G. Progress, challenges and perspectives of 3D LiDAR point cloud processing[J]. Acta Geodaetica et Cartographica Sinica, 2017, 46(10): 1509-1516.)
[6] 郭波,黃先鋒,張帆,等. 顧及空間上下文關系的JointBoost點云分類及特征降維[J]. 測繪學報, 2013, 42(5): 715-721.(GUO B, HUANG X F, ZHANG F, et al. Points cloud classification using JointBoost combined with contextual information for feature reduction[J]. Acta Geodaetica et Cartographica Sinica, 2013, 42(5): 715-721.)
[7] WEINMANN M, JUTZI B, HINZ S, et al. Semantic point cloud interpretation based on optimal neighborhoods, relevant features and efficient classifiers [J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2015, 105: 286-304.
[8] LIU W, SUN J, LI W, et al. Deep learning on point clouds and its application: a survey [J]. Sensors, 2019, 19(19): No.4188.
[9] BENGIO Y. Learning deep architectures for AI[J]. Foundations and Trends in Machine Learning, 2009, 2(1): 1-127.
[10] 楊柳,劉啟亮,袁浩濤. 城市激光點云語義分割典型方法對比研究[J]. 地理與地理信息科學, 2021, 37(1):17-25.(YANG L, LIU Q L, YUAN H T. A comparative study on typical methods for semantic segmentation of laser point clouds in urban areas [J]. Geography and Geo-Information Science, 2021, 37(1):17-25.)
[11] MATURANA D, SCHERER S. VoxNet: a 3D convolutional neural network for real-time object recognition [C]// Proceedings of the 2015 IEEE/RSJ International Conference on Intelligent Robots and Systems. Piscataway: IEEE, 2015: 922-928.
[12] WU Z, SONG S, KHOSLA A, et al. 3D ShapeNets: a deep representation for volumetric shapes[C]// Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2015: 1912-1920.
[13] YI L, KIM V G, CEYLAN D, et al. A scalable active framework for region annotation in 3D shape collections[J]. ACM Transactions on Graphics, 2016, 35(6): No.210.
[14] QI C R, SU H, MO K, et al. PointNet: deep learning on point sets for 3D classification and segmentation [C]// Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2017: 77-85.
[15] QI C R, YI L, SU H, et al. PointNet++: deep hierarchical feature learning on point sets in a metric space [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. Red Hook, NY: Curran Associates Inc., 2017:5101-5114.
[16] WANG Y, SUN Y, LIU Z, et al. Dynamic graph CNN for learning on point clouds[J]. ACM Transactions on Graphics, 2019, 38(5): No.146.
[17] 趙中陽,程英蕾,釋小松,等. 基于多尺度特征和PointNet的LiDAR點云地物分類方法[J]. 激光與光電子學進展, 2019, 56(5): No.052804.(ZHAO Z Y, CHENG Y L, SHI X S, et al. Terrain classification of LiDAR point cloud method based on multi-scale features and PointNet [J]. Laser and Optoelectronics Progress, 2019, 56(5): No.052804.)
[18] 馬京暉,潘巍,王茹. 基于-means聚類的三維點云分類[J]. 計算機工程與應用, 2020, 56(17):181-186.(MA J H, PAN W,WANG R. 3D point cloud classification based on-means clustering[J]. Computer Engineering and Applications, 2020, 56(17):181-186.)
[19] 羅海峰,方莉娜,陳崇成,等. 基于DBN的車載激光點云路側多目標提取[J]. 測繪學報, 2018, 47(2): 234-246.(LUO H F, FANG L N, CHEN C C, et al. Roadside multiple objects extraction from mobile laser scanning point cloud based on DBN[J]. Acta Geodaetica et Cartographica Sinica, 2018, 47(2): 234-246.)
[20] WANG Z, ZHANG L, ZHANG L, et al. A Deep Neural Network with Spatial Pooling (DNNSP) for 3-D point cloud classification[J]. IEEE Transactions on Geoscience and Remote Sensing, 2018, 56(8): 4594-4604.
[21] LANDRIEU L, SIMONOVSKY M. Large-scale point cloud semantic segmentation with superpoint graphs [C]// Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Piscataway: IEEE, 2018: 4558-4567.
[22] FILLIN S, PFEIFER N. Segmentation of airborne laser scanning data using a slope adaptive neighborhood [J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2006, 60(2): 71-80.
[23] DEMANTKé J, MALLET C, DAVID N, et al. Dimensionality based scale selection in 3D lidar point clouds[J]. The International Archives of the Photogrammetry, Remote Sensing and Spatial Information Sciences, 2012, 38(5): 97-102.
[24] KOLMOGOROV V, ZABIN R. What energy functions can be minimized via graph cuts?[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2004, 26(2): 147-159.
[25] LANDRIEU L, OBOZINSKI G. Cut Pursuit: fast algorithms to learn piecewise constant functions on general weighted graphs [J]. SIAM Journal on Imaging Sciences, 2017, 10(4): 1724-1766.
[26] 任歡,王旭光. 注意力機制綜述[J]. 計算機應用,2021, 41(S1):1-6.(REN H, WANG X G. Review of attention mechanisms[J]. Journal of Computer Applications, 2021, 41(S1): 1-6.)
[27] 朱張莉,饒元,吳淵,等.注意力機制在深度學習中的研究進展[J]. 中文信息學報, 2019, 33(6): 1-11.(ZHU Z L, RAO Y, WU Y, et al. Research progress of attention mechanism in deep learning [J]. Journal of Chinese Information Processing, 2019, 33(6): 1-11.)
[28] 楊麗,吳雨茜,王俊麗,等.循環神經網絡研究綜述[J]. 計算機應用, 2018, 38(S2): 1-6, 26.(YANG L, WU Y X, WANG J L, et al. Research on recurrent neural network[J]. Journal of Computer Applications, 2018, 38(S2): 1-6, 26.)
[29] 馬超. 融合卷積神經網絡和循環神經網絡的車輪目標檢測[J]. 測繪通報, 2020(8):139-143.(MA C. Wheel detection integrating convolutional neural network and recurrent neural network[J]. Bulletin of Surveying and Mapping, 2020(8):139-143.)
[30] HACKEL T, SAVINOV N, LADICKY L, et al. Semantic3D.net: a new large-scale point cloud classification benchmark [J]. ISPRS Annals of the Photogrammetry, Remote Sensing and Spatial Information Sciences, 2017, IV-1/W1: 91-98.
[31] BENTLEY J L. Multidimensional binary search trees used for associative searching [J]. Communications of the ACM, 1975, 18(9): 509-517.
Outdoor scene point cloud segmentation model based on graph model and attention mechanism
LIAN Feiyu1,2, ZHANG Liang1,2*, WANG Jiedong3, JIN Yukang1,2, CHAI Yu1,2
(1,,430062,;2(),430062,;3,310012,)
Aiming at the problem that it is difficult to distinguish similar land types in outdoor scenes with multiple objects and complex spatial topological relationships, an A-Edge-SPG (Attention-EdgeConvSuperPoint Graph) graph neural network combining graph model and attention mechanism module was proposed. Firstly, the superpoints were segmented by the combination of graph cut and geometric features. Secondly, the local adjacency graph was constructed inside the superpoint to capture the context information of the point cloud in the scene and use the attention mechanism module to highlight the key information. Finally, a SuperPoint Graph (SPG) model was constructed, and the features of hyperpoints and hyperedges were aggregated by Gated Recurrent Unit (GRU) to realize accurate segmentation among different land types of point cloud. On Semantic3D dataset,the semantic segmentation effect of A-Edge-SPG model and SPG-Net (SPG neural Network) model was compared and analyzed. Experimental results show that compared with the SPG model, A-Edge-SPG model improves the Overall segmentation Accuracy(OA), mean Intersection over Union (mIoU) and mean Average Accuracy (mAA) by 1.8, 5.1 and 2.8 percentage points respectively, and significantly improves the segmentation accuracy of similar land types such as high vegetation and dwarf vegetation, improving the effect of distinguishing similar land types.
semantic segmentation; outdoor scene; local feature; attention mechanism module; local adjacency graph; graph model
This work is partially supported by National Natural Science Foundation of China (41601504), Major Project of High?Resolution Earth Observation System (11?H37B02?900?19/22).
LIAN Feiyu, born in 1997, M. S. candidate. His research interests include three-dimensional point cloud processing, point cloud segmentation.
ZHANG Liang, born in 1986, Ph. D., associate professor. His research interests include machine learning, intelligent classification of remote sensing images, three-dimensional point cloud processing.
WANG Jiedong,born in 1986, M. S.,engineer. His research interests include photogrammetry, remote sensing applications.
JIN Yukang, born in 1997, M. S. candidate. His research interests include unmanned aerial vehicle point cloud filtering.
CHAI Yu, born in 1999, M. S. candidate. Her research interests include three-dimensional point cloud processing.
TP183
A
1001-9081(2023)12-3911-07
10.11772/j.issn.1001-9081.2022111704
2022?11?15;
2023?03?13;
2023?03?20。
國家自然科學基金資助項目(41601504);高分辨率對地觀測系統重大專項(11?H37B02?9001?19/22)。
廉飛宇(1997—),男,山東臨沂人,碩士研究生,主要研究方向:三維點云處理、點云分割;張良(1986—),男,浙江紹興人,副教授,博士,主要研究方向:機器學習、遙感影像智能分類、三維點云處理;王杰棟(1986—),男,寧夏銀川人,工程師,碩士,主要研究方向:攝影測量、遙感應用;靳于康(1997—),男,河南南陽人,碩士研究生,主要研究方向:無人機點云濾波;柴玉(1999—),女,河南信陽人,碩士研究生,主要研究方向:三維點云處理。
猜你喜歡
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中華手工(2017年2期)2017-06-06 23:00:31
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
中外會展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:19:15
外語學刊(2011年1期)2011-01-22 03:38:33
