基于YOLOv5的輕量化交通標(biāo)志檢測方法
2024-01-12 12:32:58何鑫陳輝
山東理工大學(xué)學(xué)報(自然科學(xué)版) 2024年2期
何鑫,陳輝
(安徽理工大學(xué) 計算機(jī)科學(xué)與工程學(xué)院,安徽 淮南 232001)
隨著人工智能技術(shù)的快速發(fā)展,智能汽車的自動駕駛已經(jīng)逐步走入人們的生活,并已開始投入商業(yè)應(yīng)用。交通標(biāo)志識別(traffic sign recognition,TSR)是自動駕駛的基礎(chǔ)性技術(shù),也是自動駕駛系統(tǒng)的關(guān)鍵技術(shù)[1],對其研究也逐漸成為目標(biāo)識別領(lǐng)域的熱點(diǎn)。交通標(biāo)志識別方法可以分為兩大類:傳統(tǒng)識別方法和基于深度學(xué)習(xí)的識別方法[2]。傳統(tǒng)識別方式主要基于顏色、形狀等方法識別,如Romdhane等[3]結(jié)合顏色分割、HOG(histogram of oriented gridients)和SVM分類器以識別交通標(biāo)志;Shang[4]基于HOG特征訓(xùn)練級聯(lián)分類器的方法識別交通標(biāo)志。近年來隨著卷積神經(jīng)網(wǎng)絡(luò)的高速發(fā)展,深度學(xué)習(xí)的檢測方法逐漸成為熱門的研究方向。深度學(xué)習(xí)方法有兩類,一類是先進(jìn)行候選框的篩選再提取特征進(jìn)行分類、預(yù)測回歸的兩階段目標(biāo)檢測算法(two-stage),代表性的算法有RCNN[5]、Fast-RCNN[6]、Mask-RCNN[7];另一類是一次檢測即可產(chǎn)生預(yù)測的單階段目標(biāo)檢測算法(one-stage),典型的算法有YOLO系列[8]、SSD系列[9]。雖然傳統(tǒng)依賴顏色、形狀的交通標(biāo)志識別方法魯棒性較強(qiáng),但實(shí)時檢測中受限于天氣情況、光照條件、交通標(biāo)志損壞等因素的干擾,基于檢測RoI(region of interest)進(jìn)行分類的傳統(tǒng)檢測方法往往不能在其他因素影響下達(dá)到理想的識別效果,且算法計算量大,而基于深度學(xué)習(xí)的識別方法特征表達(dá)能力強(qiáng),也不易受到復(fù)雜環(huán)境的影響而導(dǎo)致識別精度大幅下降。因此,深度學(xué)習(xí)用于交通標(biāo)志識別在某些方面更具優(yōu)勢。如江金洪等[10]將深度可分離卷積((depthwise separable convolution,DSC)[11]引入YOLOv3[12],并更換損失函數(shù)MSE為GIOU來檢測交通標(biāo)志;呂禾豐等[13]替換YOLOv5損失函數(shù)為EIOU[14],并使用加權(quán)Cluster非極大抑制(NMS)改進(jìn)YOLOv5中原NMS以提升檢測精度。雖然這些改進(jìn)算法相較于傳統(tǒng)檢測方法在精度方面有所進(jìn)步,但依舊存在算法計算量大、模型尺寸大等問題。
綜上所述,基于顏色、形狀和基于深度學(xué)習(xí)的交通標(biāo)志識別技術(shù)分別存在著檢測精度低和計算量大、模型尺寸大、推理速度慢的問題,使得模型難以部署到移動設(shè)備中。鑒于此,本文以YOLOv5為基礎(chǔ)網(wǎng)絡(luò)結(jié)構(gòu),通過GhostNet和坐標(biāo)注意力機(jī)制的有效位置融合以及SIOU損失函數(shù)優(yōu)化使用,提出一種輕量化改進(jìn)的YOLOv5交通標(biāo)志檢測模型。
1 基于 YOLOv5的輕量化改進(jìn)算法
1.1 主干網(wǎng)絡(luò)的改進(jìn)
YOLO算法是Redmon等于2016年首次提出的目標(biāo)檢測算法,在不同領(lǐng)域得到廣泛應(yīng)用。YOLOv5是YOLO系列的第五個版本,主要由輸入端、Backbone、Neck、Prediction四部分組成。輸入端主要負(fù)責(zé)圖像的輸入,Backbone負(fù)責(zé)對輸入圖片進(jìn)行不同程度的特征提取,Neck部分融合、組合這些不同尺寸特征提取后的特征圖,最后由Prediction預(yù)測。YOLOv5依照深度寬度的不同劃分為五個不同的版本,其中YOLOv5m、YOLOv5l以及YOLOv5x網(wǎng)絡(luò)結(jié)構(gòu)復(fù)雜、體積過大,難以部署到嵌入式設(shè)備中,YOLOv5n模型尺寸過小,精度難以達(dá)到一定的高度,故本文選用深度較小,特征圖寬度較小的YOLOv5s作為基礎(chǔ)算法加以改進(jìn)。改進(jìn)模型的整體框架如圖1所示。

圖1 改進(jìn)模型框架
改進(jìn)模型利用GhostNet網(wǎng)絡(luò)對YOLOv5s整體架構(gòu)進(jìn)行輕量化,將結(jié)構(gòu)復(fù)雜、參數(shù)較高的C3模塊與Ghost Bottleneck融合為C3Ghost模塊,替換模型中所有原Bottleneck模塊,剩余Conv模塊更換為Ghost模塊,實(shí)現(xiàn)網(wǎng)絡(luò)結(jié)構(gòu)的精簡,最后在模型的小目標(biāo)尺寸特征提取區(qū)部署CA坐標(biāo)注意力機(jī)制,即YOLOv5s中Backbone最后一層,增強(qiáng)模型小目標(biāo)的識別能力。
1.2 GhostNet網(wǎng)絡(luò)
鑒于YOLOv5s存在網(wǎng)絡(luò)復(fù)雜度高的問題,使用構(gòu)建好的C3Ghost模塊和普通Ghost模塊融合搭建新YOLOv5s網(wǎng)絡(luò)框架,不僅能有效減小模型整體參數(shù)以壓縮模型體積,且能保證其具有一定的準(zhǔn)確性。GhostNet是由Han等[15]在2020年提出的一種輕量化神經(jīng)網(wǎng)絡(luò)架構(gòu),該網(wǎng)絡(luò)不僅能大幅度減少模型參數(shù),且具有較高的識別性能,可以在同等計算成本下?lián)碛汹s超Mobilenetv3[16]的準(zhǔn)確性。主流卷積神經(jīng)網(wǎng)絡(luò)在訓(xùn)練過程中會產(chǎn)生大量特征映射冗余,GhostNet網(wǎng)絡(luò)提出一種新的Ghost模塊。圖2為GhostNet網(wǎng)絡(luò)結(jié)構(gòu)圖,可以看出,GhostNet主要分兩步,首先進(jìn)行常規(guī)卷積運(yùn)算得到一半特征圖,再通過廉價的線性變換將其中一半卷積生成具有更多相似特征的另一半特征圖,最后兩部分相結(jié)合輸出,這種方式提高了卷積量,同時減少了參數(shù)量和計算量。
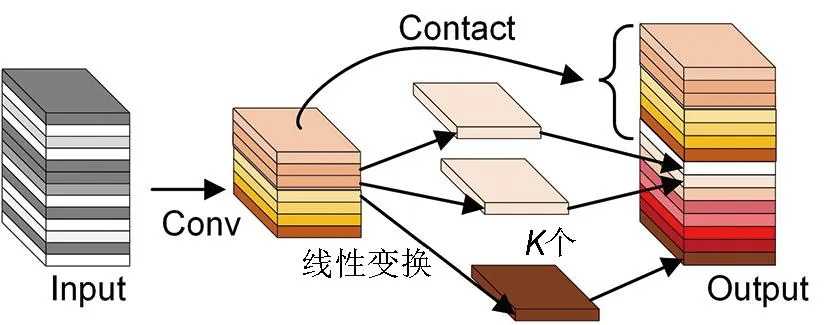
圖2 GhostNet網(wǎng)絡(luò)結(jié)構(gòu)
GhostNet 參考 了ResNet先升維再降維的網(wǎng)絡(luò)結(jié)構(gòu),如圖 3 所示。Ghost Bottlenecks 由兩個Ghost 模塊構(gòu)成,第一個 Ghost 模塊主要作用是擴(kuò)展并增加通道數(shù)量;第二個 Ghost 模塊主要負(fù)責(zé)減少匹配通道數(shù)量以及鏈接兩模塊輸入輸出。GhostNet 借鑒 MobileNetv2[17]中的設(shè)計技巧,在第一個 Ghost 模塊后不使用 ReLu 激活函數(shù),其余層都進(jìn)行 BN (batch normalization) 批歸一化和 ReLu非線性激活。這種特殊的結(jié)構(gòu)設(shè)計,不但能夠壓縮參數(shù)量和計算量,還可以優(yōu)化特征圖,提高模型的性能。
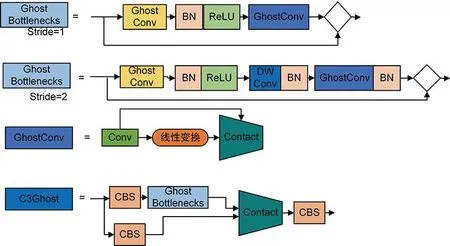
圖3 GhostNet結(jié)構(gòu)圖
圖3所示C3Ghost模塊參考CSP模塊的構(gòu)建思路,利用兩個CBS(由普通卷積加批歸一化加silu激活函數(shù)構(gòu)成)和一個Ghost Bottlenecks組成。輸入特征信息分別通過Ghost Bottlenecks以及CBS處理拼接成新的特征圖,這樣的構(gòu)成方式減少了整體參數(shù),同時還能保證特征信息的最大保留。
1.3 CA坐標(biāo)注意力
對于輸入圖像來說,背景復(fù)雜,交通標(biāo)志空間占比小,模型往往會受到大量冗余背景信息干擾導(dǎo)致?lián)p失小目標(biāo)的特征信息,致使識別精度下降。此外,經(jīng)過輕量化后的YOLOv5s中存在大量Ghost模塊,Ghost模塊使用分組卷積,減少了通道的數(shù)量,使得通道特征僅與自己建立聯(lián)系。這一方面令參數(shù)量降低、網(wǎng)絡(luò)復(fù)雜度減小,但是另一方面會影響對全局特征的提取,導(dǎo)致交通標(biāo)志檢測精度降低。因此本文將位置信息嵌入到通道注意力的坐標(biāo)注意力機(jī)制[18],引入CA注意力機(jī)制到已優(yōu)化的YOLOv5s網(wǎng)絡(luò)結(jié)構(gòu)Backbone部分的最后一層的C3模塊,幫助模型把握全局特征,抵消部署Ghost模塊帶來的特征缺失。
有別于其他主流注意力模塊,如SE通過全局池化來計算通道注意力[19],CA將全局池分解為兩個一維的特征編碼以緩解二維池化造成的位置信息缺失,并使坐標(biāo)信息和輸入特征圖形成交互。圖4為坐標(biāo)注意力機(jī)制CA的網(wǎng)絡(luò)結(jié)構(gòu)圖,由坐標(biāo)信息的嵌入和坐標(biāo)注意力生成兩部分構(gòu)成。

圖4 CA網(wǎng)絡(luò)結(jié)構(gòu)圖
首先,坐標(biāo)信息的嵌入,對于給定維度為C×H×W的輸入特征圖,使用空間范圍分別為(H,1)或(1,W)的池化層沿X軸和Y軸兩個不同方向坐標(biāo)的每個通道進(jìn)行編碼,經(jīng)過編碼平均池化后得到尺寸為C×H×1和C×1×W的特征圖;其次,坐標(biāo)注意力生成,通過拼接和1×1卷積將兩種尺寸的特征圖聚合成一個C/r×1×(W+H)的特征圖,維度也從C維降成了C/r維;再分別用1×1卷積進(jìn)行維度提升,并使用Sigmoid激活函數(shù)激活;最后進(jìn)行特征圖重加權(quán),即將生成的兩個同緯度特征圖與輸入特征圖相乘,完成對模型坐標(biāo)注意力的添加。
圖5(a)為主干網(wǎng)絡(luò)沒有添加CA的識別效果,5(b)為添加后的效果,可以看出未添加CA會出現(xiàn)對小目標(biāo)漏檢的情況,添加后漏檢情況得到改善。

(a)未添加CA (b)添加CA圖5 CA識別效果對比圖
1.4 邊框回歸損失函數(shù)
損失函數(shù)能夠度量模型的預(yù)測值與真實(shí)值差異程度,其設(shè)定也會直接影響模型優(yōu)化的速度和定位的準(zhǔn)確性,因此選擇合適的損失函數(shù)對模型起著至關(guān)重要的作用。
YOLOv5原損失函數(shù)為CIOU損失函數(shù)[20],CIOU不僅吸收了GIOU[21]、DIOU[20]的優(yōu)點(diǎn),即在IOU的基礎(chǔ)上加上對預(yù)測框和真實(shí)框的重疊面積、中心點(diǎn)距離的考慮,而且提出對回歸框?qū)捀弑冗M(jìn)行損失計算,使得目標(biāo)框回歸更加趨于穩(wěn)定。
雖然CIOU考慮到了預(yù)測框和真實(shí)框的重疊面積、中心點(diǎn)距離以及寬高比,但忽略了其方向之間不匹配的問題,導(dǎo)致模型收斂速度不理想。本文選用SIOU損失函數(shù)[22]替換YOLOv5中的CIOU損失函數(shù)。SIOU吸收了CIOU的優(yōu)點(diǎn),并添加了對真實(shí)框和預(yù)測框之間角度的損失計算,提高了模型的訓(xùn)練效率和收斂速度。SIOU損失函數(shù)由角度損失(angle cost)、距離損失(distance cost)、形狀損失(shape cost)、IOU損失(IOU cost)四部分組成。
角度損失的添加是為了最大程度地減少與距離相關(guān)的變量數(shù)量,在模型訓(xùn)練收斂過程中首先將預(yù)測帶到最靠近的坐標(biāo)軸(X軸或Y軸),再沿此軸繼續(xù)進(jìn)行訓(xùn)練,其計算公式為
(1)
式中:ch為真實(shí)框和預(yù)測框的高度差,σ為真實(shí)框和預(yù)測框中心點(diǎn)的距離。
考慮到角度損失的添加,需要實(shí)現(xiàn)角度損失和距離損失的平衡。距離損失公式為:
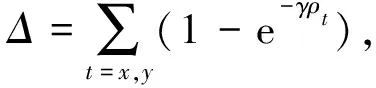
(2)
(3)
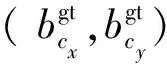
形狀損失指的是兩框中心位置的偏差,計算公式為:
(4)
(5)
式中:w和wgt分別為預(yù)測框和真實(shí)框的寬度,h和hgt分別為預(yù)測框和真實(shí)框的高度,θ體現(xiàn)了對形狀損失的關(guān)注程度。
IOU損失表示真實(shí)框和預(yù)測框之間的交集和并集之比,計算公式為
(6)
最終損失函數(shù)表達(dá)式為
(7)
2 TensorRT
TensorRT是由NVIDIA公司提出的一個基于深度學(xué)習(xí)的高性能學(xué)習(xí)推理優(yōu)化器,它支持TensorFlow、Caffe、Mxnet、Pytorch等幾乎所有的深度學(xué)習(xí)框架,將TensorRT和NVIDIA的GPU結(jié)合起來,能在幾乎所有的深度學(xué)習(xí)框架中進(jìn)行快速和高效的部署推理。本文利用TensorRT對已訓(xùn)練好的模型權(quán)重進(jìn)行優(yōu)化,以加速模型推理速度。
3 實(shí)驗(yàn)結(jié)果與分析
3.1 數(shù)據(jù)集
為了驗(yàn)證輕量化改進(jìn)模型的效果,本文采用由長沙理工大學(xué)采集并制作的交通標(biāo)志數(shù)據(jù)集CCTSDB2021(csust Chinese traffic sign detection benchmark 2021)[23]作為實(shí)驗(yàn)所用數(shù)據(jù)集,驗(yàn)證本文算法。CCTSDB2021由三大類交通標(biāo)志構(gòu)成,分別為指示標(biāo)志、禁止標(biāo)志和警告標(biāo)志,數(shù)據(jù)集制作規(guī)范符合實(shí)驗(yàn)要求。隨機(jī)選取其中6 000張圖片,按照VOC2007數(shù)據(jù)集格式調(diào)整,按照4∶1的比例劃分為訓(xùn)練集和驗(yàn)證集進(jìn)行實(shí)驗(yàn)驗(yàn)證。
3.2 數(shù)據(jù)增強(qiáng)處理
為了提升模型的泛化性能,使用Mosaic和Mixup數(shù)據(jù)增強(qiáng)方法處理數(shù)據(jù)集。Mosaic數(shù)據(jù)增強(qiáng)方法通過隨機(jī)排列拼接經(jīng)過裁剪、縮放的四張輸入圖片形成新的圖片輸入訓(xùn)練模型,擴(kuò)充小樣本目標(biāo)的同時提升模型訓(xùn)練速度,增強(qiáng)網(wǎng)絡(luò)的魯棒性;而Mixup數(shù)據(jù)增強(qiáng)方法則是通過隨機(jī)疊加融合兩張不同的圖片豐富樣本數(shù)量,實(shí)現(xiàn)對小目標(biāo)檢測能力和模型魯棒性的增強(qiáng)。圖6為使用Mosaic和Mixup數(shù)據(jù)增強(qiáng)后的效果圖。

(a)Mosaic (b)Mixup圖6 數(shù)據(jù)增強(qiáng)后的效果圖
Mixup計算公式為:
(8)
(9)
式中:(xi,yi)和(xj,yj)是原始數(shù)據(jù)的隨機(jī)樣本對;λ是服從beta分布的一個參數(shù),λ∈[0,1]。
為驗(yàn)證數(shù)據(jù)增強(qiáng)方法對YOLOv5s模型檢測產(chǎn)生的影響,將未開啟數(shù)據(jù)增強(qiáng)與開啟數(shù)據(jù)增強(qiáng)的YOLOv5s模型進(jìn)行實(shí)驗(yàn)對比,表1為對比實(shí)驗(yàn)結(jié)果。
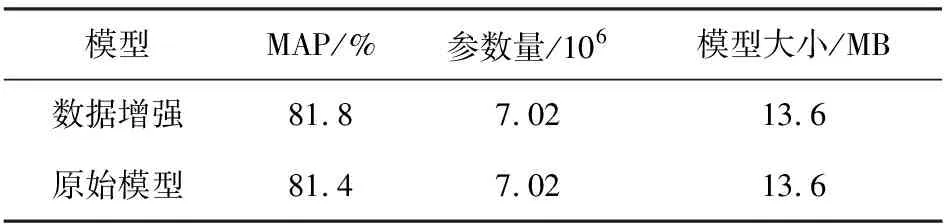
表1 數(shù)據(jù)增強(qiáng)前后對比結(jié)果
從表1可以看出,采用數(shù)據(jù)增強(qiáng)后的YOLOv5s模型MAP值有了提升,說明在YOLOv5s模型中,上述兩種數(shù)據(jù)處理方式均可以有效提升模型的平均精度。
3.3 實(shí)驗(yàn)配置
本實(shí)驗(yàn)使用Pytorch深度學(xué)習(xí)框架搭建、訓(xùn)練改進(jìn)模型,實(shí)驗(yàn)環(huán)境為Ubuntu20.04,CPU采用Intel(R)Xeon(R)Platinum8255C,GUP為V-100SXM2,內(nèi)存為32 G。實(shí)驗(yàn)輸入的圖像尺寸為640×640,批訓(xùn)練處理量為32,初始學(xué)習(xí)率為0.01,IOU閾值為0.2,權(quán)重衰減為0.000 5,共訓(xùn)練150輪。
3.4 評價指標(biāo)
實(shí)驗(yàn)使用平均精度(mean average precision,MAP)、推理速度、參數(shù)數(shù)量、模型大小作為對改進(jìn)模型的評價指標(biāo)。其中MAP通過準(zhǔn)確率(Precision)和平均正確率(average precision,AP)計算得出。
準(zhǔn)確率即網(wǎng)絡(luò)檢測到正樣本數(shù)量占總樣本數(shù)量的比率,公式為
(10)
式中:TP(true positive)為被正確識別為正樣本的正樣本數(shù)量,FP(false positive)為被錯誤識別為正樣本的負(fù)樣本數(shù)量。AP、MAP分別為預(yù)測樣本的平均正確率、平均精度,所有類別的平均精度為:
(11)
(12)
3.5 實(shí)驗(yàn)結(jié)果與分析
本文選用YOLOv5s、YOLOv3-tiny、YOLOv4-tiny、YOLOv5s+Shufflenetv2、SSD五種網(wǎng)絡(luò)進(jìn)行交通標(biāo)志檢測實(shí)驗(yàn),選用模型涵蓋了近年來目標(biāo)檢測領(lǐng)域內(nèi)經(jīng)典框架和輕量型改進(jìn)算法,并將本文模型與之進(jìn)行性能對比,以驗(yàn)證本模型的可行性,對比結(jié)果見表2。

表2 不同算法對比結(jié)果
從表2可以看出,本文模型與輕量化網(wǎng)絡(luò)模型YOLOv3-tiny相比平均精度提升了6.7%,參數(shù)量和模型大小分別減少了63.8%和61.9%;與另一主流輕量化網(wǎng)絡(luò)模型YOLOv4-tiny相比平均精度提升了3.7%,參數(shù)量降低了46.9%,模型大小降低了71.8%;和引入Shufflenetv2的YOLOv5s的輕量化模型YOLOv5s+Shufflenetv2相比精度有較大提升,參數(shù)量和模型大小均有所減小;相較于主流檢測模型SSD,精度大幅提升,參數(shù)量和模型大小大幅減小;與原模型YOLOv5s相比,平均精度只有0.1%的損失,但參數(shù)量和模型大小大幅度減小。
改進(jìn)YOLOv5和原模型YOLOv5s對交通標(biāo)志數(shù)據(jù)集訓(xùn)練結(jié)果的平均精度如圖7所示,可以看出改進(jìn)模型與原模型相比平均精度幾乎沒有差距,在訓(xùn)練前期效果甚至略強(qiáng)于原模型。

圖7 平均精度對比圖
另外改進(jìn)模型推理速度也有提升。實(shí)驗(yàn)結(jié)果表明,原模型的推理時間為9.4 ms,改進(jìn)模型的為9.2 ms,提升幅度為2%;在經(jīng)過TensorRT加速后,模型推理時間更是可以達(dá)到4 ms,比原模型提升了57.4%。
改進(jìn)模型對比主流檢測模型、輕量化網(wǎng)絡(luò)模型,不僅在精度上更具優(yōu)勢,且參數(shù)量和模型大小也遠(yuǎn)遠(yuǎn)小于其他模型;在和原模型的對比上,雖然精度有些許損失,但模型尺寸和參數(shù)量減小,且推理速度遠(yuǎn)超原模型,綜合來看改進(jìn)模型的綜合性能優(yōu)于原模型。
為了驗(yàn)證所改部分的有效性,對改進(jìn)模型進(jìn)行消融實(shí)驗(yàn)。實(shí)驗(yàn)對比結(jié)果見表3。表3中改進(jìn)模型1為融入GhostNet的YOLOv5s模型,改進(jìn)模型2添加了CA注意力。從表3可以看出,利用GhostNet對YOLOv5網(wǎng)絡(luò)架構(gòu)進(jìn)行優(yōu)化使得參數(shù)量和模型尺寸減小,但模型精度過低;而在主干網(wǎng)絡(luò)加入CA坐標(biāo)注意力模塊后,模型對重點(diǎn)信息定位能力有所加強(qiáng),精度增加較大,且參數(shù)量和模型尺寸進(jìn)一步減小;YOLOv5s將原損失函數(shù)CIOU優(yōu)化為SIOU后,彌補(bǔ)了CIOU在真實(shí)框和預(yù)測框角度問題的不足,精度略微增加;可以看出本文模型在保證了較少精度損失的同時,有效地壓縮了參數(shù)量和模型大小。

表3 消融實(shí)驗(yàn)對比結(jié)果
4 結(jié)論
1)融合CA注意力與GhostNet網(wǎng)絡(luò)結(jié)構(gòu)的YOLOv5模型,相較于原模型,參數(shù)量減少50%,模型大小減小53.5%,對嵌入式設(shè)備的有限計算資源占用較少,利于部署。
2)輕量化模型精度損失僅0.1%,并未因參數(shù)量、計算量的減少造成過大的精度損失,相對而言改進(jìn)模型綜合性能更強(qiáng)。
3)改進(jìn)模型推理速度快于原模型,相較于原模型推理速度提升了57.4%。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
