基于APF-LSTM-DDPG算法的移動機器人局部路徑規劃
2024-02-15 01:50:50李永迪李彩虹張耀玉張國勝周瑞紅梁振英
山東理工大學學報(自然科學版) 2024年1期
李永迪,李彩虹,張耀玉,張國勝,周瑞紅,梁振英
(山東理工大學 計算機科學與技術學院,山東 淄博 255049)
近年來,深度學習DL(deep learning)[1]和強化學習RL(reinforcement learning)[2]成為人工智能領域的熱門。傳統的強化學習用于機器人路徑規劃時,不能適應環境復雜度高的狀況;而深度學習具有較強的感知能力,能夠適應更加復雜的問題,但是決策能力稍欠缺。將深度學習和強化學習相結合的深度強化學習DRL( deep reinforcement learning)[3]算法, 取長補短,具有二者的感知優勢和決策優勢[4],目前在移動機器人路徑規劃[5]技術中得到了廣泛應用。
DDPG[6]是將DPG(deterministic policy gradient)和神經網絡相融合的策略方法。DDPG算法具有多維特征提取能力,能從樣本中習得避障經驗,具備一定的泛化能力,可根據不同的環境選擇合適的避障策略[7-8]。周盛世等[9]在DDPG算法的基礎上結合人工勢場法設計了回報函數,但并未對模型收斂效果進行探討;Wang等[10]在Q學習[11]中添加LSTM層用于Q函數的近似過程,提高了算法的魯棒性;Lobos-Tsunekawa等[12]基于DDPG算法和LSTM,記憶地圖障礙物位置并實現雙足機器人避障,但在算法收斂速度方面討論較少;袁帥等[13]在算法感知端引入LSTM,將障礙物狀態信息作為輸入,提高了記憶和認知障礙物的能力,但未對復雜環境進行驗證;楊秀霞等[14]采用基于LSTM和速度障礙法的DDPG避障方法,解決了算法無法表示不同數量障礙物的狀態信息的問題,提高了泛化能力,但未對算法訓練效率進行討論。
本文針對上述問題,對DDPG算法進行改進。引入LSTM結構,將移動機器人搭載的激光雷達的探測信息、機器人的狀態信息以及機器人當前位置與目標點的距離和角度作為網絡的輸入,角速度和線速度作為輸出,遺忘和記憶樣本信息;結合人工勢場法[15],賦予目標點和障礙物對機器人的引力和斥力,設計勢場獎懲函數,解決環境獎勵稀疏的缺點;利用勢場的合力對機器人的角速度進行調節,減少路徑冗余路段。
1 算法原理分析
1.1 DDPG算法原理
DDPG算法基于Actor-Critic算法[16]框架,與DQN算法結合,使用卷積神經網絡[17]模擬策略函數和價值函數,算法訓練使用深度學習的方法,準確模擬非線性函數,并且在高維度動作空間下有較好的收斂性。
策略π是動作概率分布的映射,而確定性策略π去掉了概率分布,只取最大概率的動作,定義為
πθ(s)=a,
(1)
式中θ為確定性策略π的參數,目標是尋找一個θ使動作策略π的選擇最優。
在DDPG算法中,智能體與當前環境進行交互從而獲取當前時刻的狀態信息,通過神經網絡對獲取的信息進行分析,輸出智能體要執行的動作策略,智能體行動后與環境交互獲得反饋,再對反饋后的各個動作策略進行評價,最后更新神經網絡的參數。DDPG算法框架如圖1所示。
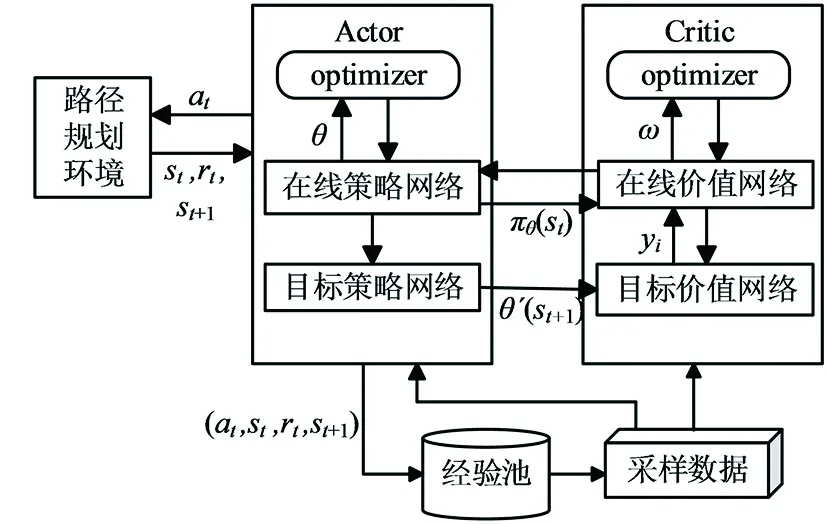
圖1 DDPG算法框架
在Actor網絡中,在線策略網絡負責根據當前的狀態信息st選擇要執行的動作at,智能體執行動作后生成下一時刻的st+1和獎勵rt;目標策略網絡負責根據從經驗池中抽取的采樣數據選擇下一步執行的動作at+1,并更新網絡參數θ。計算公式為
θt+1=θt+αθπ(st,θ)[?atQ(st,at,ω)]a=πθ(s)。
(2)
在Critic網絡中,在線價值網絡負責根據獲取的當前時刻的狀態st和動作at計算網絡的Q值,并更新目標價值yi和網絡參數ω;目標價值網絡負責更新網絡參數ω′,計算st+1的Q值Q(st+1,at+1,ω′)。網絡參數ω和目標Q值yi的更新公式為:
ωt+1=ωt+αω[yi-Q(st,at,ω)]?ωQ(st,at,ω),
yi=rt+γQ(st+1,at+1,ω′)。
(3)
1.2 人工勢場法
人工勢場法是移動機器人路徑規劃常用的方法,其原理是在環境中設置人工引力和斥力,使目標點和障礙物分別產生對機器人的引力和斥力,越靠近目標點引力越大,方向始終朝向目標點;越靠近障礙物斥力越大,方向從障礙物指向機器人。通過引力和斥力的合力作用使機器人在運動過程中有方向引導,最終避開障礙物,到達目標點。
引力勢場函數Uatt表示為
(4)
式中:ηa為引力系數,始終大于0;ρ(qgoal,q)為當前機器人與目標點的距離。
斥力勢場函數Urep表示為
(5)
式中:ηr為斥力系數;ρ(q,qobs)為機器人與障礙物的實時距離;ρ0為障礙物的安全距離,當障礙物進入這個范圍就會受到斥力勢場影響。
總勢場U和機器人受到的合力F為:
(6)
2 APF-LSTM-DDPG算法設計
為提高訓練速度和穩定性,本文提出了APF-LSTM-DDPG算法。基于DDPG算法,結合LSTM和人工勢場法,設計勢場獎懲函數作為前期的輔助,加快訓練速度;利用人工勢場法調整算法的動作選擇策略,提升所規劃路徑的平滑程度,并減少路徑長度。APF-LSTM-DDPG算法包含了連續的狀態空間和動作空間[18]、獎懲函數以及網絡結構的設計。
2.1 連續的狀態空間和動作空間設計
移動機器人模型如圖2所示。

圖2 Turtlebot3機器人模型
使用兩輪差分的Turtlebot3作為移動機器人仿真模型,搭載全方位的雷達傳感器,機器人結構和其激光雷達數據采集結構如圖3的(a)和(b)所示。
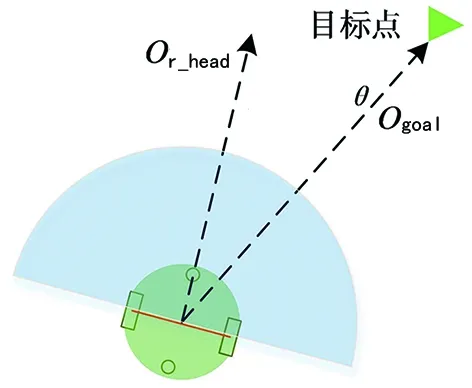
(a) Turtlebot3機器人結構圖
圖3(a)中θ是機器人當前行進方向Or_head與目標點方向Ogoal的夾角,θ∈[-π, π];機器人與周圍環境中的障礙物相關信息通過激光雷達獲取,使用機器人前方180°的探測范圍和10個方向上的雷達數據。
在仿真環境中,機器人當前位置、行駛角度和速度信息由定位系統獲取,機器人的位姿信息由激光雷達測距信息di以及機器人與目標點之間的距離ρ(qgoal,q)和角度θ組成,狀態空間st定義為
st=(d1~d10,ρ(qgoal,q),θ)。
(7)
機器人在行駛過程中遇到障礙物需改變方向來避障,通過改變線速度和角速度來控制轉彎幅度,線速度的取值范圍為[0.0, 0.22],單位m/s;角速度的取值范圍為[-2.0, 2.0 ],單位rad/s。機器人的運動過程如圖4所示。
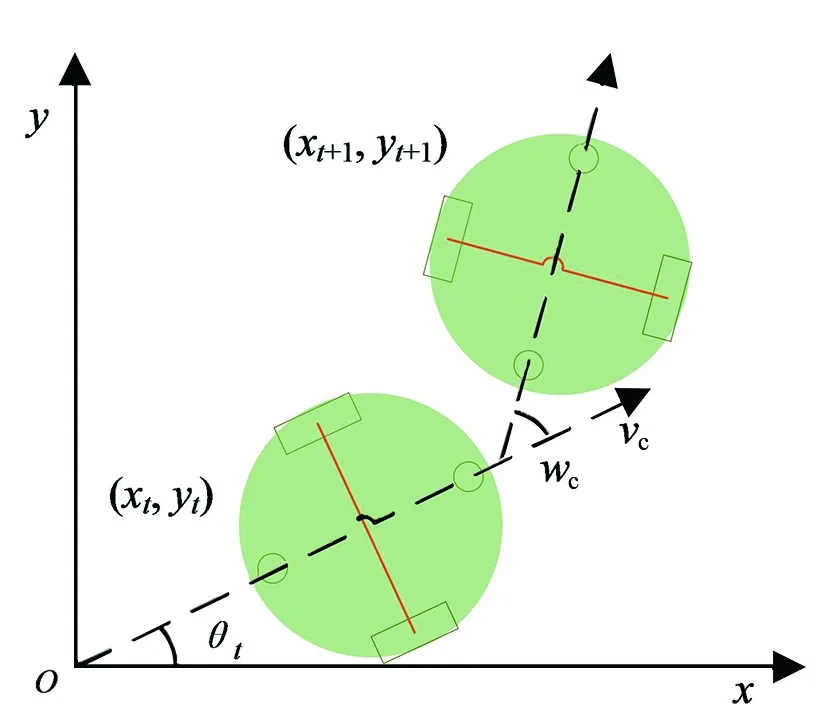
圖4 機器人運動過程
圖4中,(xt,yt)為在t時刻機器人的坐標,θt為t時刻機器人行進朝向和x軸正方向的夾角,當前時刻的機器人位姿信息pt定義為
pt=[xt,yt,θt]T,
(8)
機器人的運動學模型為
(9)
式中:T為機器人采樣周期,(xt+1,yt+1,θt+1)是根據t時刻的位姿信息和運動信息計算而來,[vc,wc]表示當前機器人的線速度和角速度。則移動機器人動作空間A定義為
A=(vc,wc)。
(10)
2.2 勢場獎懲函數設計
在訓練初期,DDPG算法會選擇隨機動作策略而探索不必要的區域,致使算法收斂時間長且不穩定,設計連續的勢場獎懲函數,以提高學習效率。
當機器人與目標點的距離ρt小于目標點范圍cg,或離最近障礙物距離minx小于障礙物碰撞距離co時給予相應獎勵:
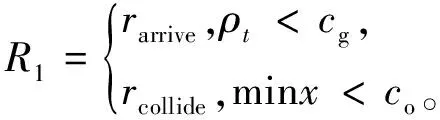
(11)
根據機器人在運動過程中與目標點的距離dt變化量給予相應獎勵:
(12)
在訓練前期會隨機選擇多余動作,造成機器人行進方向頻繁變化而增加多余訓練,增加累計轉角和θs的相應獎勵:
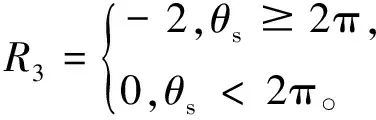
(13)
在機器人進入一個或多個障礙物的斥力勢場范圍cr時會給予斥力獎勵,獎勵與距離正相關:
(14)
式中di為機器人與第i個障礙物的距離,當機器人離開斥力勢場范圍后獎勵為0。
獎懲函數包括到達目標點和觸碰障礙物的獎勵R1、距離變化量獎勵R2、轉角和獎勵R3以及斥力獎勵R4,在訓練前期勢場作為輔助,能夠快速學習避障到達目標點,隨著訓練的增加,權重k逐漸增大。所以總的獎勵函數設置為
R=R1+R2+R3+(1-k)R4。
(15)
2.3 基于LSTM的網絡結構
APF-LSTM-DDPG算法在Actor網絡和Critic網絡的基礎上增加了LSTM網絡層。
如圖5所示,LSTM用于處理移動機器人狀態信息。在每一時刻t,將機器人狀態信息Ct-1=(s1,a1,...,sn,an)作為LSTM的輸入序列,經過遺忘門提取關鍵信息后存儲在ht。在經驗池中保存數據時將表現較好的樣本存入,為后續更新Actor網絡和Critic網絡提供樣本數據。所有障礙物的狀態信息輸入后,將存儲在ht中的數據維度轉換為狀態向量ht:
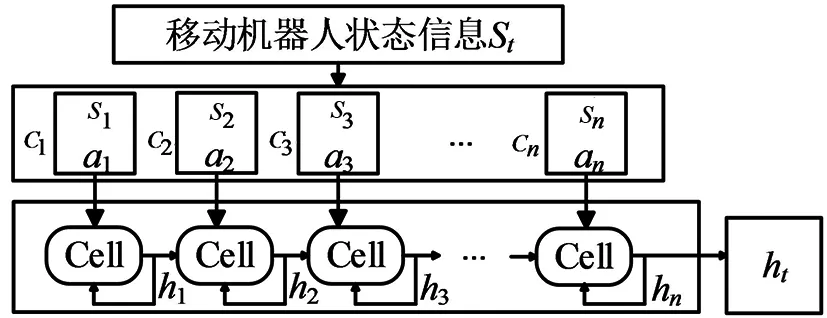
圖5 LSTM處理數據模型
(16)
移動機器人的當前狀態st經過LSTM處理后作為APF-LSTM-DDPG網絡的輸入ht,輸送給Actor網絡和Critic網絡的全連接層。
如圖6所示,APF-LSTM-DDPG神經網絡由四層網絡組成。第一層為LSTM層,包含兩個隱含的LSTM記憶單元,以獲取時間序列信息,對當前狀態信息和上一時刻的狀態信息的遺忘和記憶;第二、三層為全連接層,包含512個神經元節點,將LSTM處理后的狀態信息作為輸入;第四層為全連接層,輸出發送給機器人的角速度和線速度。Actor網絡和Critic網絡的隱藏層相同,Critic網絡給出機器人當前狀態和動作的Q值。
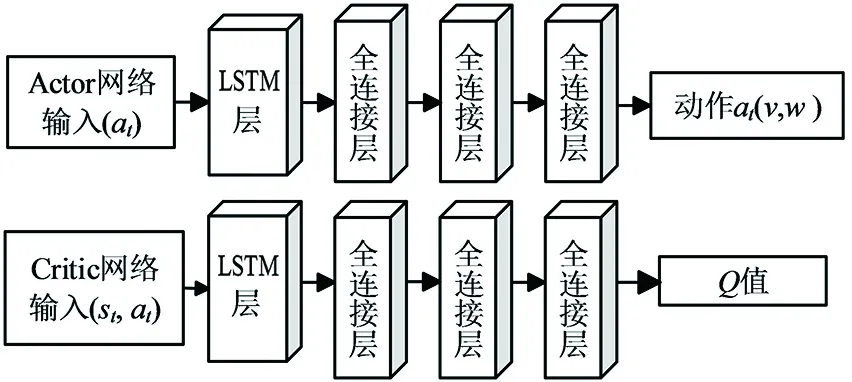
圖6 APF-LSTM-DDPG網絡結構
APF-LSTM-DDPG算法包含14個輸入和2個輸出,其中10個方向的雷達信息和線速度、角速度以及與目標點距離和角度為輸入,機器人執行的動作為輸出。如圖7所示。
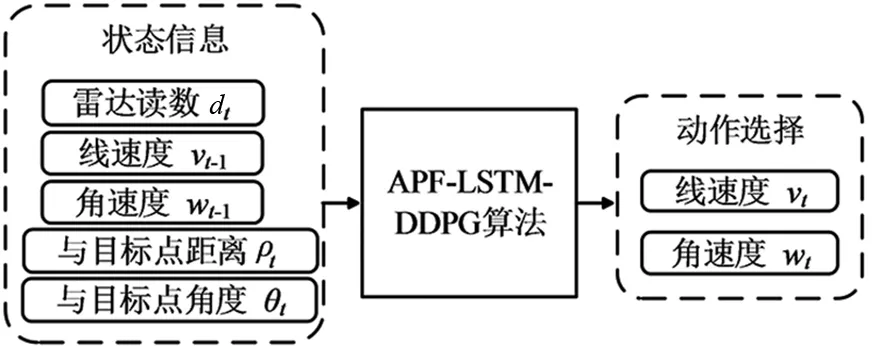
圖7 APF-LSTM-DDPG算法的輸入輸出
2.4 融合路徑規劃算法
機器人通過APF-LSTM-DDPG算法選擇動作與環境交互,交互后得到狀態信息并存入到經驗池中作為樣本,在移動過程中受到人工勢場法干預。算法在訓練時從經驗池中隨機采樣n個樣本,經LSTM單元處理數據后進行網絡的更新。改進后的算法流程如圖8所示。
為減少算法選擇冗余動作,利用人工勢場法為動作的選擇做引導。當移動機器人周圍存在障礙物時受到斥力Frep,靠近目標點時受到引力Fatt,通過合力F引導機器人的運動行為。機器人受力分析如圖9所示。
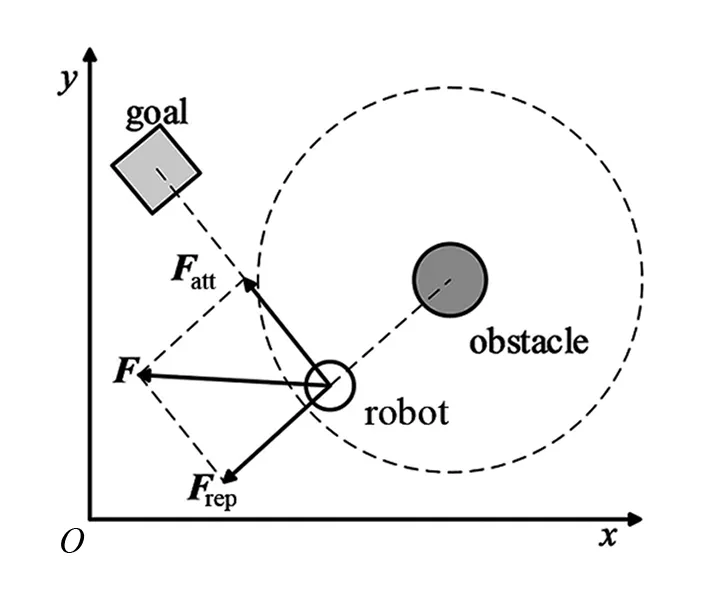
圖9 機器人受力分析
如果機器人到達勢場區域,基于人工勢場法,根據當前移動機器人受到的合力F來修正其角速度,表達式為
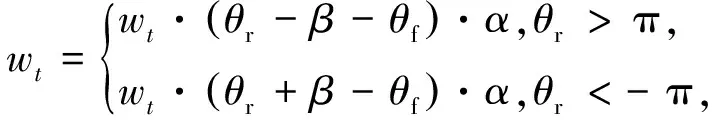
(17)
式中:θf是機器人以自身為坐標受到合力的角度,θr為當前機器人朝向的角度,α=0.3為調節系數,β=2π,(θr-β-θf)和(θr+β-θf)為機器人朝向與合力方向外角的差值。
2.5 遷移學習
局部路徑規劃中的大部分任務存在相關性,在不同地圖環境中利用參數遷移來初始化相關任務中的參數,可以加快移動機器人在不同場景下策略的學習。
訓練開始階段加載初始模型,獲取全部的模型參數。通過隨機初始化訓練獲得趨向目標點的模型參數ωi,將ωi初始化為離散場景ωs,再將離散環境下的模型參數初始化為特殊障礙物場景ωt,完善避障規則Vs與Vt,實現局部路徑規劃。本文所設計的的遷移學習結構圖如圖10所示。
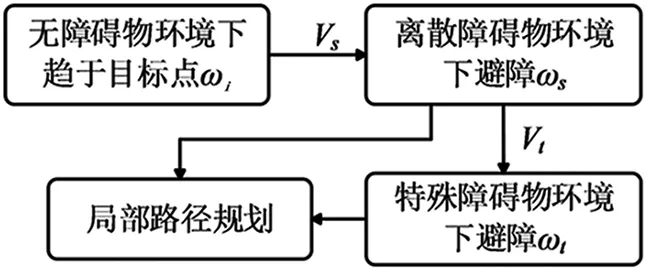
圖10 遷移學習結構圖
3 仿真驗證
為驗證所設計的APF-LSTM-DDPG算法在機器人路徑規劃中的有效性,基于Python語言,在ROS平臺上利用Gazebo搭建不同的3D仿真環境:離散型障礙物、一型障礙物、U型障礙物和混合障礙物環境,進行模型的訓練。
為更清晰地觀察實驗結果,將繪制兩種算法訓練的每輪平均獎勵對比圖,橫坐標為訓練的迭代次數,設為n,縱坐標為迭代到第n輪時本輪的平均獎勵,設為r;將機器人和仿真環境實時投影在Rviz軟件中顯示,并繪制出機器人行走的軌跡。在Rviz中,機器人所在位置為起點,綠色方框代表目標點,黑色圓柱體代表障礙物,藍色實線代表規劃的路徑軌跡。
在Gazebo中搭建訓練環境,設置并初始化APF-LSTM-DDPG算法的參數,使移動機器人經過訓練學習到繞過障礙物的經驗,能夠到達目標點,部分參數設置見表1。
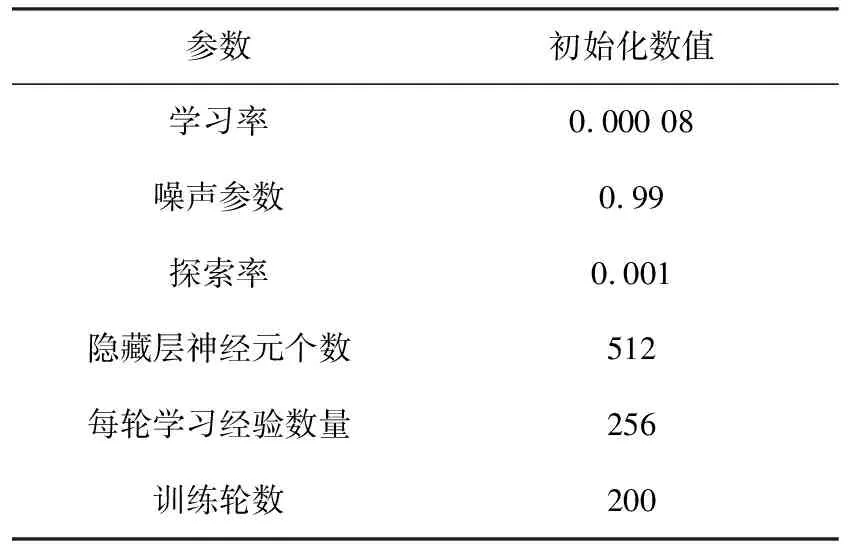
表1 路徑規劃任務參數設置
3.1 無障礙物下的仿真
Gazebo搭建的仿真環境如圖11所示。

圖11 無障礙物環境
在訓練過程中隨機生成目標點,根據獎懲函數給予獎勵,經過訓練后輸出每輪的平均獎勵,如圖12所示。APF-LSTM-DDPG算法由于人工勢場法力的作用對角速度進行調節,會迅速找尋到目標點,得到更多獎勵高的樣本,算法更快地收斂。從圖12中可以看出APF-LSTM-DDPG算法在30輪后開始收斂,原始算法在100輪左右開始收斂,且收斂后APF-LSTM-DDPG算法較為穩定。
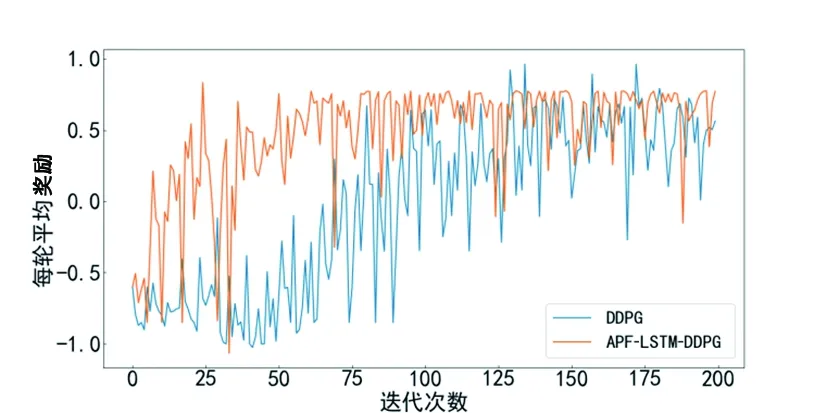
圖12 無障礙物環境每輪平均獎勵對比
設置三個不同的目標點,使機器人按右上、左上和左下的順序依次尋路,利用訓練后的模型進行路徑規劃的結果如圖13所示。APF-LSTM-DDPG算法由于學習到的經驗較好,規劃的路徑更短,轉彎角度更小。

(a) DDPG算法 (b) APF-LSTM-DDPG算法圖13 無障礙物環境路徑規劃
3.2 離散障礙物下的仿真
離散障礙物訓練環境在Gazebo中顯示如圖14所示。
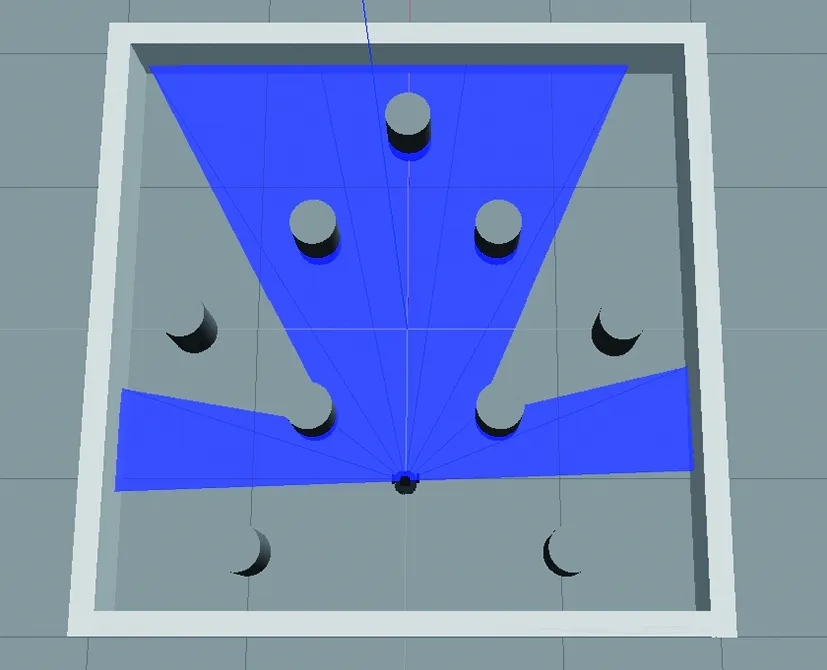
圖14 離散障礙物環境
利用遷移學習將具有趨向目標點經驗的無障礙物環境模型遷移到離散環境中作為初始化模型,設置實驗參數,機器人碰撞障礙物后給予負獎勵并立即進入下一輪,縮短訓練周期,進行200輪訓練后,輸出平均獎勵,如圖15所示。從圖15可以看出機器人在離散障礙物場景中獲得的平均獎勵在訓練前期處于正負值交替狀態,說明還沒有學習到充足的避障經驗,每輪的平均獎勵隨著迭代次數的增加逐漸上升,算法開始逐漸收斂,且APF-LSTM-DDPG算法的收斂速度明顯快于原始算法。
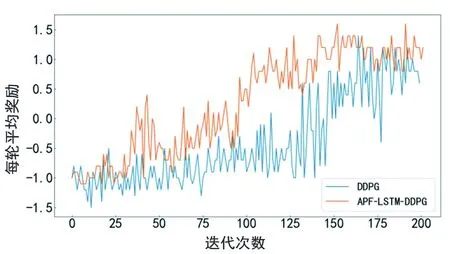
圖15 離散障礙物環境每輪平均獎勵對比
利用訓練得到的模型進行從起點到目標點的路徑規劃,規劃結果如圖16所示。從圖16可以看出,相比于原始DDPG算法,APF-LSTM-DDPG算法規劃的路徑更短,冗余路段更少。
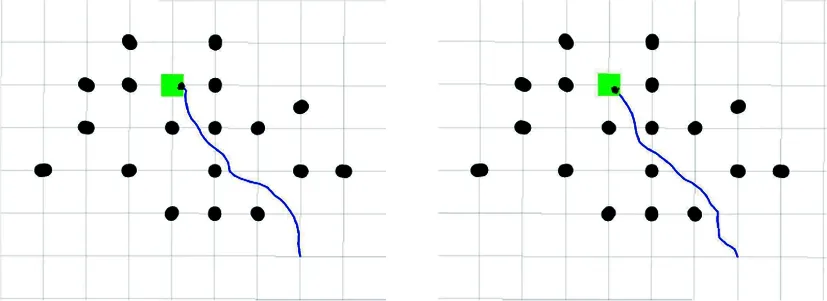
(a) DDPG算法 (b) APF-LSTM-DDPG算法圖16 離散障礙物環境路徑規劃
3.3 U型障礙物下的仿真
特殊障礙物包括一型和U型,存在陷入局部最優等問題,通過LSTM單元和人工勢場法合力的作用,使機器人更快地繞過障礙物,提高模型收斂的速度。U型障礙物環境如圖17所示。
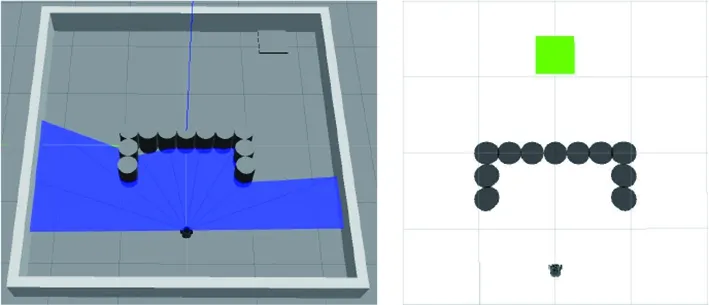
(a) Gazebo中的U型環境 (b) Rviz中的U型環境圖17 U型障礙物環境
將APF-LSTM-DDPG算法和原始算法在離散障礙物環境下學習到避障經驗的算法模型用作U型障礙物環境的初始化模型,同樣進行200輪訓練,輸出每輪平均獎勵,如圖18所示。APF-LSTM-DDPG算法訓練到25輪前后,平均獎勵上升到正值,說明算法已經學習到部分避障經驗;而在130輪左右時,每輪的平均獎勵基本穩定,說明算法趨于收斂。
圖19為兩個算法在U型障礙物環境中規劃的路徑。U型環境中,APF-LSTM-DDPG算法從起點到終點所用步數為179,原始DDPG算法為191。從圖19可以看出,在人工勢場法輔助下訓練出的算法模型,能夠在激光雷達探測到障礙物時直接繞過,在不觸碰障礙物的條件下規劃出一條從起點到目標點的較優路線,且APF-LSTM-DDPG算法規劃的路徑較短。
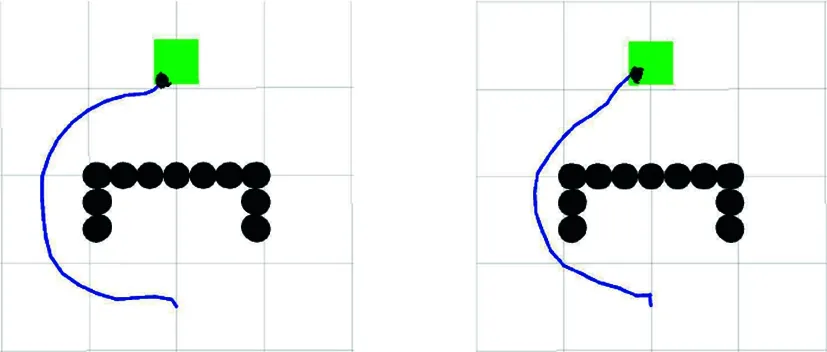
(a) DDPG算法 (b) APF-LSTM-DDPG算法圖19 U型障礙物環境路徑規劃
3.4 一型障礙物下的仿真
一型障礙物環境將作為U型環境訓練模型的泛化測試環境,所以不單獨在一型環境下進行訓練,將APF-LSTM-DDPG算法在U型環境中的訓練模型用于一型障礙物環境的路徑規劃任務。一型障礙物環境如圖20所示。
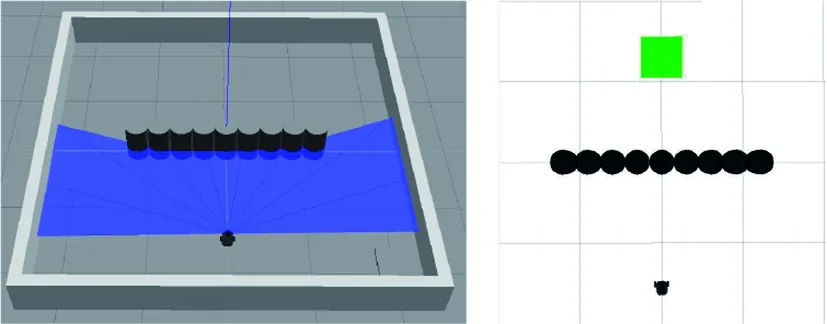
(a) Gazebo中的一型環境 (b) Rviz中的一型環境圖20 一型障礙物環境
圖21為兩個算法在一型障礙物環境中規劃的路徑。APF-LSTM-DDPG算法從起點到終點所用步數為181,原始DDPG算法為186。從結果可知,該算法具有一定的泛化性。
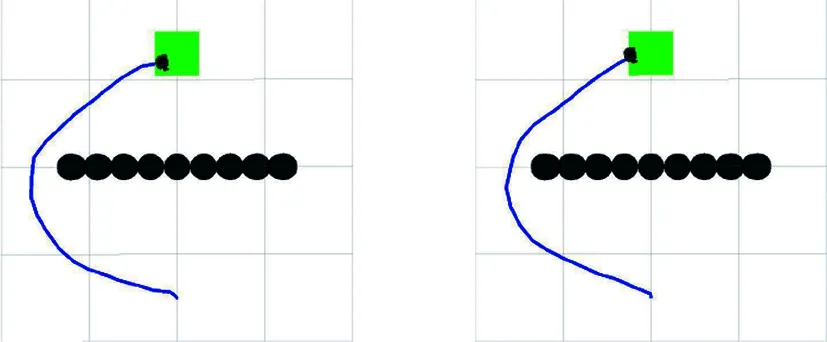
(a) DDPG算法 (b) APF-LSTM-DDPG算法圖21 一型障礙物環境路徑規劃
對兩種算法在四種障礙物環境中路徑規劃時從起點到目標點的步數進行匯總,見表2。從表2可以看出,在每個環境中APF-LSTM-DDPG算法路徑規劃所用步數均較少。
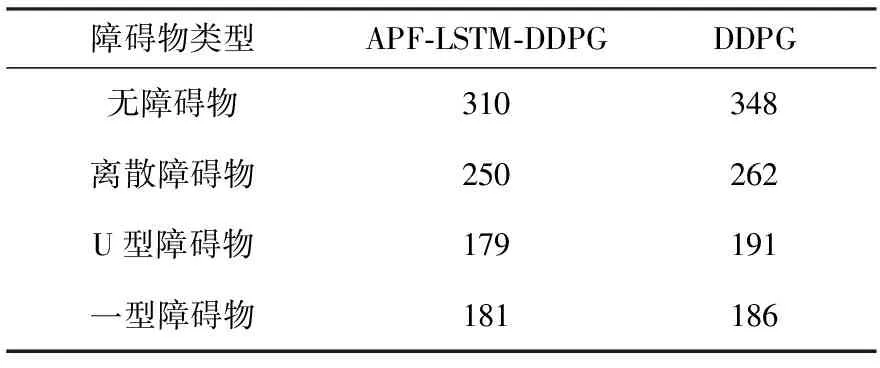
表2 到達目標點所用步數 單位:步
3.5 混合障礙物環境中對比仿真測試
在混合障礙物場景中,分別基于傳統DDPG算法、文獻[19]復現的算法和本文提出的APF-LSTM-DDPG算法進行仿真驗證。為方便稱呼,簡稱文獻[19]中的算法為LDDPG算法。LDDPG算法是結合LSTM神經網絡并以環境圖像作為輸入的路徑規劃算法,將其輸入改為與本文設計的算法同樣的14個輸入,以便進行仿真測試。對比平均獎勵和利用收斂模型進行路徑規劃的成功率,搭建的環境如圖22所示。
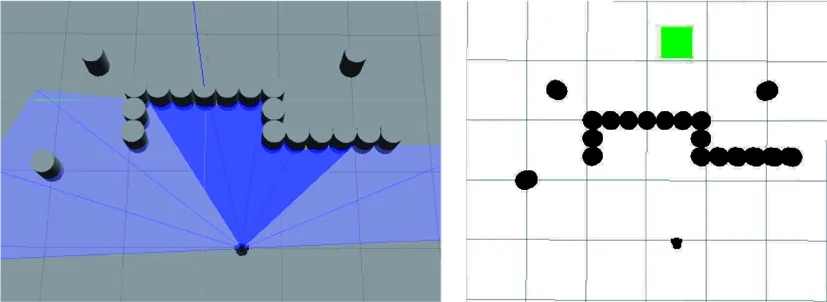
(a) Gazebo中的混和環境 (b) Rviz中的混和環境圖22 混合障礙物環境
圖23給出了三種算法在混和障礙物下訓練所獲得的平均獎勵。
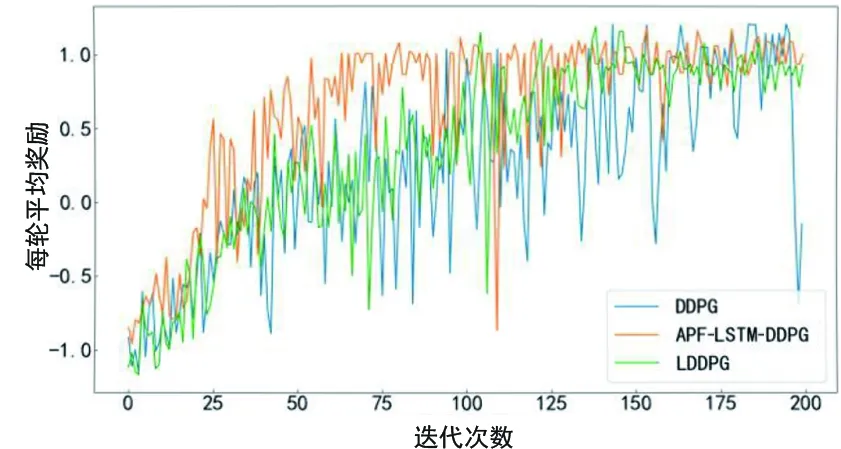
圖23 混合障礙物環境每輪平均獎勵對比
LDDPG算法由于具有LSTM結構,對于時序輸入數據有記憶功能,能夠更好地學習狀態信息,相較于原始DDPG算法能夠更快學習到經驗,加快收斂;APF-LSTM-DDPG算法在具有LSTM結構的基礎上引入了人工勢場法作為輔助策略,獲取更多有效的狀態信息,所以收斂速度最快。
利用三種算法的收斂模型進行路徑規劃,如圖24所示。顯然,傳統DDPG算法模型規劃出的路徑更加冗余;LDDPG算法模型規劃的路徑相比傳統DDPG算法較短,但避障策略不充足;而本文提出的APF-LSTM-DDPG算法模型可以規劃出一條較優路徑。
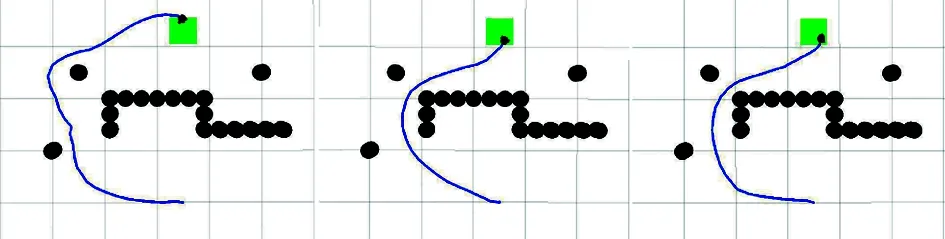
(a) DDPG算法(b) APF-LSTM-DDPG算法(c) LDDPG算法圖24 路徑規劃對比
將算法收斂模型在混合障礙物場景中重復進行100輪路徑規劃,統計到達目標點的成功率,見表3。相較于其他兩種算法,APF-LSTM-DDPG算法的成功率更高、魯棒性更強。

表3 算法成功率對比
4 結論
本文提出了一種基于DDPG算法,引入LSTM結構和人工勢場法的融合路徑規劃算法,利用合力調節動作策略的選擇,通過LSTM的記憶功能提高學習的效率,并且在ROS中搭建不同環境進行仿真,驗證了該算法的有效性。APF-LSTM-DDPG算法具有以下特點:
1)算法分別賦予目標點和障礙物引力和斥力,設計相應的勢場函數加快學習避障策略,通過合力的作用調節角速度,引導機器人更快到達目標點。
2)在神經網絡中增加一層LSTM網絡,通過對狀態信息的遺忘和記憶功能加快算法收斂速度,使訓練好的模型具有更強的泛化性能。
3)算法的在線運行時間和訓練時間沒有關聯,并且算法充分訓練后得到的收斂模型,實際運行時不需要再進行訓練。機器人通過傳感器實時感知當前環境信息,經訓練模型可以求出一條合理的局部規劃路徑,滿足運行的實時性需求。
算法在簡單的混合障礙物環境中可以實現路徑規劃任務,考慮到實際應用中,障礙物環境會更復雜且存在動態障礙物,所以之后的工作是設計訓練效率更高的神經網絡模型,應對機器人更加復雜多變的工作環境。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中老年保健(2021年12期)2021-08-24 03:30:40
中國傳媒大學學報(自然科學版)(2021年1期)2021-06-09 08:43:00
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中國生殖健康(2020年6期)2020-02-01 06:28:50
中國生殖健康(2019年11期)2019-01-07 01:28:02
領導決策信息(2018年50期)2018-02-22 06:17:16
商周刊(2017年5期)2017-08-22 03:35:26
中國衛生(2016年2期)2016-11-12 13:22:16
