基于加強灰狼優化VMD-DBN的變壓器故障檢測
2024-02-21 09:40:52趙一鈞石雷齊笑郝成鋼祝曉宏王昕
電測與儀表 2024年2期
趙一鈞,石雷,齊笑,郝成鋼,祝曉宏,王昕
(1.上海電力大學 電氣工程學院,上海 200090; 2.國網吉林省電力有限公司四平供電公司,吉林 四平136000; 3.上海交通大學 電工與電子技術中心,上海 200240)
0 引 言
電力系統中的重要組成部分變壓器的運行狀態影響著整個電網的安全運行,及時發現潛在故障隱患并實施檢修計劃,能大幅提升電網運行安全、可靠以及經濟性。因為近年來的研究發現,在變壓器故障中,繞組和鐵芯是故障多發部件,所以對兩者的故障識別也是當前研究的重點[1]。
當前已有的變壓器狀態檢測方法有很多,如短路阻抗法[2]、低壓脈沖法、頻響分析法、油色譜分析法等。但前三種方法都需要對變壓器進行脫網實驗,且短路阻抗法對繞組形變的靈敏度較低。低壓脈沖法實驗易受干擾,設備布置要求苛刻。頻響分析法要求實驗人員具有較高的經驗。油色譜分析法需要較長的實驗周期,并且對機械結構性故障識別靈敏度較低。因此許多學者提出利用振動法來診斷變壓器運行工況的方法,實現帶電檢測。近年來變壓器故障識別研究的流程主要分為三個步驟,(1)信號分解;(2)提取特征向量;(3)學習訓練特征構成診斷模型。文獻[3]中提出用EEMD拆解變壓器箱壁的振動信號,提取特征向量表征變壓器運行工況,用Fisher 判別法進行識別驗證,但EEMD分解時存在模態混疊現象,分解結果難以提取出變壓器中有效的故障信息。Dragomiretskiy提出了一種新的自適應分解方法:變分模態分解法(VMD)[4],該方法通過求解變分問題,控制帶寬能有效避免模態混疊問題,目前以其顯著的優勢廣泛應用在機械和電氣故障檢測領域中[5]。但其參數需要依靠經驗人工預設,分解效果存在隨機性。
文獻[6-7]通過提取振動分量的能量熵值用作特征數據集,使用BP神經網絡和支持向量機(SVM)來進行訓練識別,但這兩種經典的智能識別算法,結構較簡單,特征學習能力較弱,使得對變壓器故障識別的精確度較低,穩定性略差。文獻[8]提出的深度置信網絡(DBN),很好地解決了深層神經網絡易陷于局部極小值的問題,相較于上述兩種智能算法特征學習能力更強,可靠性更高,具有極強的非線性表達能力和判別能力,已在聲音識別、自然語言處理等音頻領域取得了突破性的進展,運用該算法能夠大大提高對變壓器狀態的識別率。目前,研究人員將DBN主要應用在變壓器油色譜分析當中[9],但在振動法檢測變壓器故障診斷領域使用較少。
考慮上述因素,本文提出基于加強灰狼優化的VMD-DBN檢測法。首先利用加強灰狼算法,優化VMD的重要參數(分解層數k和懲罰因子α),優化改進后,有效避免常規變分模態分解人為選擇參數的主觀隨機性,同時也使得分解得到的各IMF分量不存在混疊現象,獨立性較強,能夠更好地表征變壓器的運行工況。然后分解計算各獨立分量的能量標值,構成特征數據集,用來表征變壓器運行工況。最后使用深度置信網絡對特征數據集進行反復學習和訓練,形成故障診斷模型,能夠根據變壓器表面的振動數據對其進行狀態評估。通過實驗驗證,本文方法能夠精準、可靠地識別出變壓器正常、繞組輻向形變、繞組軸向形變、鐵芯故障四種工況,具有一定的應用價值。
1 變分模態分解
變分模態分解是將輸入信號f(t)分解成多個特定帶寬的子信號uk(t),這些子信號集聚在各自的中心頻率ωk附近,即本征模態分量。相比較經驗模態分解(EMD)通過遞歸式的方法來獲得IMF, VMD分解則通過求解變分問題的最優解來實現信號分解目的。
對于約束變分模型的建立通過以下三個步驟:(1)針對每個模態量,進行對應希爾伯特變換;(2)將每個模態量的指數調諧到估計中心頻率,使得模態頻譜轉移至基帶上;(3)將解調信號的梯度進行二范數運算,由此估算得到各模態量頻帶帶寬。由此產生的約束變分模型如式(1)所示:
(1)
式中{uk}={u1,u2,…,uK};{ωk}={ω1,ω2,…,ωK}分別代表所有的模態分量集以及他們各自的中心頻率集;“*”代表卷積運算;δ(t)是單位脈沖函數;?t代表偏導運算;j為虛數單位;f(t)即目標函數。
為了求解這個約束變分模型,通過引入二次罰項α和拉格朗日乘子λ來計算。這兩項的組合能夠求解最優解,一是得益于有限權二次罰函數的良好收斂性,即使源信號存在高斯噪聲,任能保證信號重構的精準度。二是得益于拉格朗日乘子嚴格執行約束。引入上述兩個參數后,所得增廣拉格朗日表達式如下:

(2)
通過交替方向乘子算法計算式(2)的鞍點,迭代更新uk和ωk如下式所示,最終獲得約束變分模型的優解。
(3)
(4)

同時通過式(5)更新λ,其中τ代表噪聲容許參數。
(5)
通過式(6)計算,判斷是否達到精度ε要求,決定迭代是否結束。
(6)
最終輸出分解后所有的模態分量,以及他們的中心頻率。這些模態分量就構成了信號的特征集,為后面特征學習,以及狀態識別提供數據支持。
2 加強灰狼算法
GWO(灰狼算法)是受狼群合作捕食行為啟發,模擬捕食過程的仿生群智優化算法。狼群內分為四個等級,從上到下依次為ε、β、δ、ω,權力隨等級遞減而降低。每只狼的位置代表一個可行解,通過捕食獵物的過程搜索最優解[10]。算法具體步驟如下所示。
步驟1:包圍獵物
(7)
式中t代表當前的迭代次數;YP(t)代表當前食物位置;Y(t)代表灰狼所在位置;r1,r2為0到1之間的隨機數,是調節系數,隨迭代增加而線性衰減至零;C表示擺動影響因子;A表示收斂影響因子。
步驟2:捕食過程:
在開始包圍成功后,選擇適應度值最佳的三匹狼:ε,β,δ的位置來更新狼群下一次迭代位置解向量,重復上述步驟,直至迭代結束。
(8)
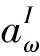
(9)
(10)
3 基于加強灰狼優化VMD分解特征值提取
在執行VMD算法之前,需要對信號分解層數K以及懲罰因子α進行設置。由于目前沒有統一的標準,一般依靠人工經驗進行賦值,但這兩個參數的取值對分解的效果起到明顯的作用。本文通過加強灰狼優化算法對分解層數和懲罰因子進行優化取值,達到分解最佳效果,最后,通過對比實驗,證實了優化后的方法分解結果沒有產生模態欠分解或者過分解的情況,各模態量之間,獨立性較強,能很好地表征變壓器運行工況,為后續變壓器狀態檢測識別提供可靠數據基礎。
3.1 能量誤差
理想狀況下原始信號經VMD分解后不存在模態欠分解與過分解情況,各固有模態分量之間相互獨立,若分量間彼此正交,那么分量的能量之和等于源信號的能量。
源信號f(t)經VMD分解成n個本征模態分量:
(11)
假設各分量間相互正交,那么總能量可以表示為各模態分量之和:
(12)
若各分量間存在混疊現象,不是完全正交,那么能量之和Eall與源信號能量E存在誤差Eer:
Eer=Eall-E=(E1+…En)-E
(13)
當分解后能量誤差的絕對值越接近零時,代表分解效果最佳,各分量獨立性較強,包含豐富的模態信息,便于后續的特征提取。
3.2 加強灰狼優化變分模態分解
懲罰因子(α)作為變分模態分解過程中約束帶寬的重要影響因子,決定著各模態的能量變化,其取值影響最終分解效果以及后續信號處理的準確性。傳統變分模態分解都是通過經驗人工預設該參數,或者人工對比調參,嚴重影響分解的高效性與精確性。使得分解后的模態分量,有可能發生模態混疊現象,無法有效表征變壓器的振動特征,也會降低后面變壓器狀態識別的精準度。文中結合了加強灰狼優化算法,將能量誤差的絕對值|Eer|作為優化過程中的適應度函數,以適應度函數取得最小值作為優化目標,對懲罰因子和分解層數進行優化取值。具體算法步驟如下所示:
首先對加強灰狼優化算法進行初始化。設置各項參數,其中包含狼群數量S,優化參數個數DIM=2,單狼學習算子c1,群狼學習算子c2,最終迭代的次數TMAX。通過對狼群的初始化,確定初始狼群位置向量ε。
根據單狼位置向量賦值分解參數進行變分模態分解,計算對應適應度函數值|Eer|,選取能量誤差最小的三匹狼的位置,定義為ε,β,δ狼的位置。
由式(8)更新狼群位置,求解對應適應度函數值,選出當前最佳的三個值,更新ε,β,δ精英狼的位置。重復迭代直到滿足算法終止條件。輸出最佳ε狼的位置[k,α],將其作為最佳分解層數和懲罰因子。對VMD進行參數設置,分解得到優化后的最終模態分量。
3.3 振動特征向量提取
變壓器振動信號分解后的各分量,互不相關,且各自能量值不同,變壓器在不同工況下,分量間的能量分布也不同。所以可以把優化參數后的VMD算法分解得到的各IMF能量作為特征向量。具體步驟如下所示:
(1)通過式(14)計算分解后各IMF的能量值。
(14)
(2)為了便于對比計算,去除量綱,進行如下集合處理,令:
(15)
(3)總能量集合處理后,各IMF能量標值為式(16):
(16)
將所有分量的能量標值構成特征數據集,表征變壓器運行工況,作為后續深度置信網絡的輸入信號。
4 深度置信網絡
深度置信網絡(Deep Belief Networks,DBN)屬于機器學習算法中神經網絡的一種,它不僅可以用于非監督學習,也可以用于有監督學習。DBN的組成元件是受限玻爾茲曼機 (Restricted Boltzmann Machines, RBM)。
通過多個RBM疊加構成具有多隱含層的神經網絡即深度置信網絡的本質。圖1是3個受限玻爾茲曼機組成的深度置信網絡模型。而每個玻爾茲曼機又是由可見層v和隱含層h構成,具體結構如圖2所示。
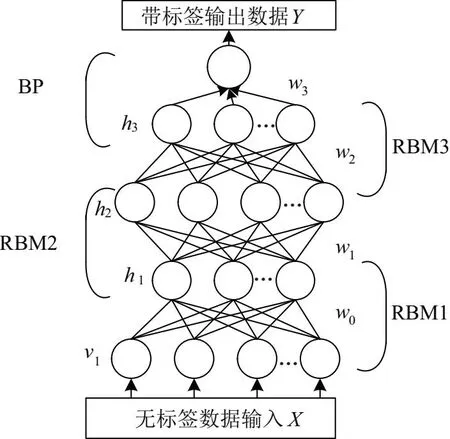
圖1 網絡結構圖
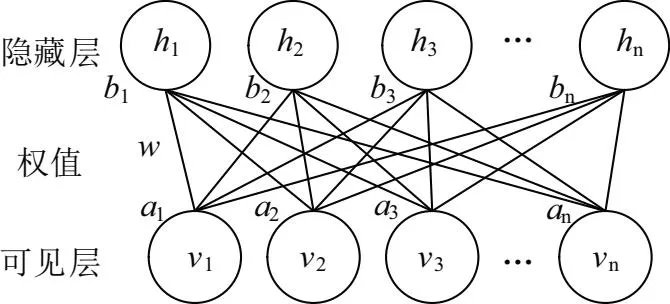
圖2 RBM模型圖
求解深度置信網絡模型參數主要由以下兩部分組成。
前向無監督預訓練:如圖1中輸入數據(X1,X2,…,Xn),從底層RBM1開始訓練,訓練結束后由其輸出層h作為下一個RBM2的輸入,繼續訓練參數,通過逐層學習的方法實現模型預訓練的目標。
反向微調:如圖1中所示最后一層加入了BP神經網絡,以實現分類器的功能,并且對預訓練給予的數據和結果進行對比,通過反向微調的方法在監督下實現了模型參數的優化,從而進一步提升網絡模型的識別率。
5 基于優化參數VMD-DBN變壓器故障診斷
5.1 算法實現
本文首先利用加強灰狼優化算法對變分模態分解中的重要參數[k,α]進行優化取值,使得分解后的固有模態分量更具獨立性和特征性,然后計算各分量的能量標值組成狀態特征向量作為深度置信網絡的輸入數據對網絡進行訓練,最后通過DBN實現變壓器運行狀態的診斷。流程圖如圖3所示。

圖3 變壓器工況識別流程圖
5.2 變壓器振動采集
實驗采用的變壓器的振動采集系統主要包含有加速度傳感器,數據采集卡和計算機,采集系統框架如圖4所示。
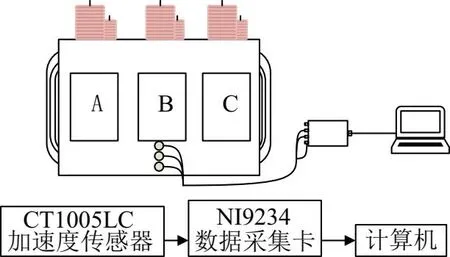
圖4 振動采集系統
為了驗證文中基于加強灰狼優化VMD-DBN的變壓器故障識別方法的有效性,利用某公司的110 kV三相油浸式變壓器進行實驗分析。本次實驗過程中,將加速度傳感器吸附于變壓器B相表面的底端。在電壓、電流以及變壓器油溫等外界環境一致的情況下,采集各試驗變壓器的振動信號,事后對吊罩檢查結果是正常狀態,繞組輻向形變,繞組軸向形變和鐵芯故障對應的變壓器做好標注。數據采集卡的采集頻率設置為固定的25.6 kHz。實驗現場如圖5所示。

圖5 現場采集實驗圖
5.3 振動信號特征提取
首先對四種工況下的變壓器振動信號進行優化參數后的變分模態分解,圖6為四種工況下振動信號和分解得到的模態量,然后計算其相應的能量標值,組成特征向量(X1,X2,……,Xn)用來表征變壓器的運行工況。

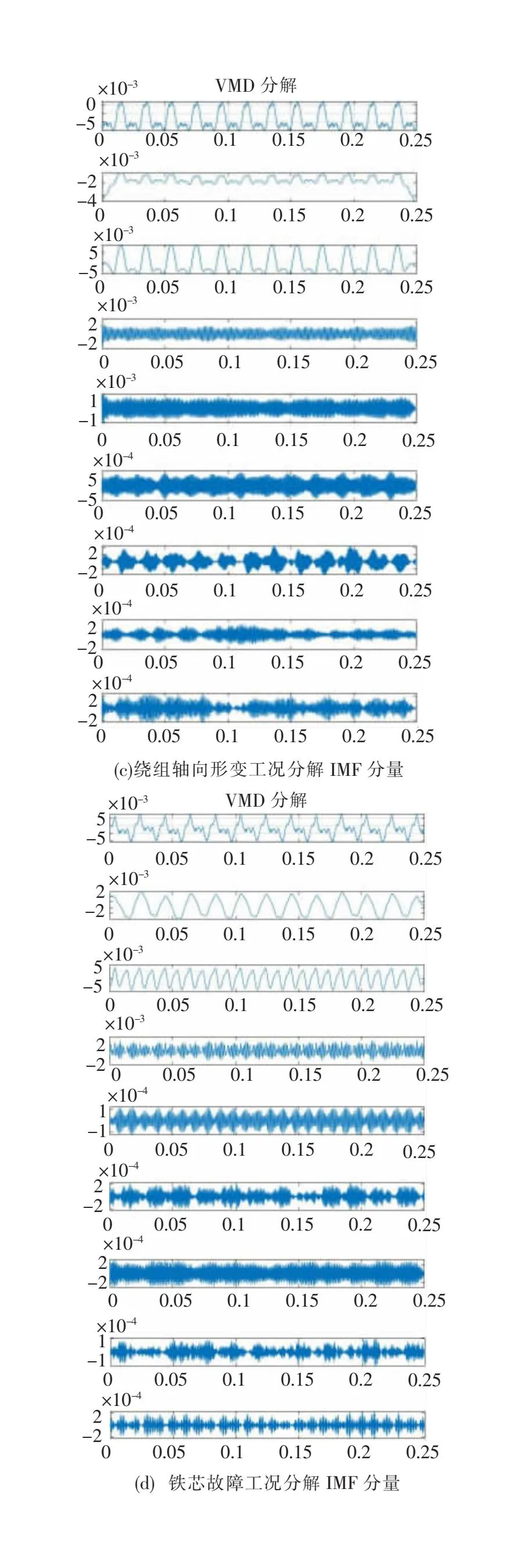
圖6 四種工況下變壓器振動信號分解IMF分量圖
表1中S1、S2、S3、S4分別對應變壓器的正常運行狀態、繞組輻向形變狀態、繞組軸向形變狀態和鐵芯故障狀態。每一個狀態S包含n個特征值(X1,X2,……,Xn),而每個特征值X即VMD分解后對應模態分量占總能量的能量標值。本實驗中通過優化分解最終分解為8個IMF分量,所以變壓器的工況特征由8個特征值組成的特征向量表示。
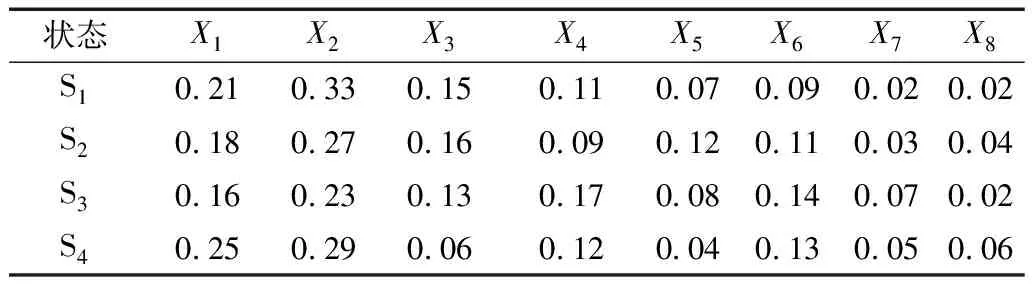
表1 四種工況下變壓器振動特征向量
5.4 深度置信網絡參數設計與狀態識別
深度置信網絡的參數設計對模型最終的故障識別率影響巨大,通過實驗對比研究,最終確定最佳參數。首先確定輸入層的節點數為8,由分類數確定輸出層的節點數為4。然后設置網絡的學習率是0.01,訓練批次是5,動量值為0.05,激活函數為sigmoid函數。最后將神經元設為兩層,每層的神經元個數由經驗公式[11]估算以及通過比較識別效果最終設為(7,6)。迭代次數綜合考慮識別能力和訓練時間等最終設為150次。
實驗總共采集了4*120=480組動數據作為訓練樣本,4*18=72組振動數據作為驗證樣本。文中所提方法在大量訓練學習后,形成了變壓器工況檢測模型。最終通過驗證樣本的測試,統計工況識別精確率如圖7所示。
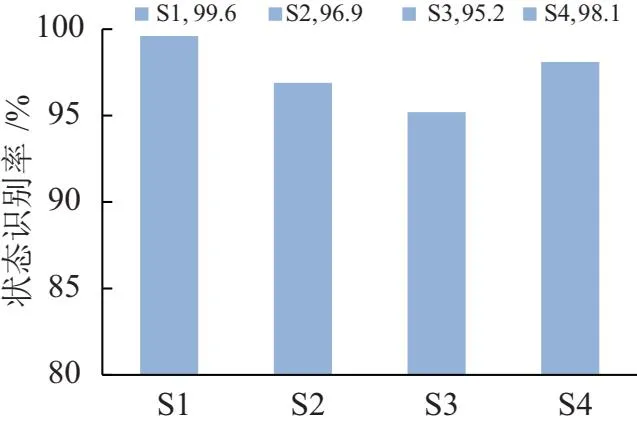
圖7 算法對測試樣本工況識別率
由圖7數據可知,本文所提出的加強灰狼優化VMD-DBN變壓器故障識別算法對變壓器運行狀態具有高度的靈敏性,對四種運行狀態:變壓器正常運行狀態、變壓器繞組輻向形變狀態、變壓器繞組軸向形變狀態和鐵芯故障狀態的識別的平均精準度更是達到了97.45%。能夠精確反饋變壓器的工況,發現潛在隱患,預防故障停運,提升電網運行的可靠性。
為驗證方法的適用性,在特征提取部分引入EEMD、灰狼優化VMD和本文加強灰狼優化參數的VMD作對比,在工況識別部分引入BP神經網絡和支持向量機SVM作對比,設置適當的參數對實驗數據進行學習和測試,重復測試十次計算平均精準度和均值誤差,最終得到的識別精確度如表2所示。

表2 不同算法對變壓器工況識別的精確度
由表2對比可知,采用加強灰狼優化VMD比采用EEMD和灰狼優化VMD分解振動信號提取各IMF能量標值的方法更能提取振動信號中的有效特征信息,提高狀態識別率,降低均值誤差。對比三種識別方法可知,DBN比SVM和BP神經網絡的精準度要高,且均方誤差要小。以上說明采用加強灰狼優化VMD-DBN的變壓器狀態識別算法準確度高,穩定性好。能夠精準、可靠地識別出變壓器正常、繞組輻向形變、繞組軸向形變、鐵芯故障四種工況。
6 結束語
文章針對在變壓器箱壁上采集的振動信號,提出加強灰狼優化VMD-DBN的故障識別方法。通過實驗對比分析得出以下結論:
(1)采用加強灰狼算法優化VMD的重要參數[k,α],可以避免人工依靠經驗賦值帶來分解效果的隨機性。并且較灰狼優化VMD,最終狀態識別效果更佳;
(2)對比EEMD與VMD提取特征向量結合任意的識別方法最終得到的識別精準度可知,VMD更能提取變壓器振動信號中的特征信息。提取有效、準確的特征信息能夠提升故障的識別精準度;
(3)相較于經典識別方法BP神經網絡、SVM;DBN具有多層結構,對特征向量的抽象能力更好,學習能力更佳。它結合優化VMD能量標值對變壓器狀態識別的平均百分比達到了97.45%,均值誤差為0.37,精準度最高,穩定性最好。因此本方法具有一定的實用價值。
猜你喜歡
科學大眾(2023年17期)2023-10-26 07:39:14
中學生數理化(高中版.高考理化)(2020年11期)2020-12-14 07:36:08
天天愛科學(2020年6期)2020-09-10 07:22:44
通信電源技術(2018年3期)2018-06-26 06:33:30
數學物理學報(2017年6期)2018-01-22 02:26:40
現代工業經濟和信息化(2016年4期)2016-05-17 05:35:38
通信電源技術(2016年3期)2016-03-26 07:13:46
湖北經濟學院學報·人文社科版(2015年8期)2015-12-29 05:53:07
上海電機學院學報(2015年4期)2015-02-28 14:30:00
計算物理(2014年2期)2014-03-11 17:01:44
