融合成對損失函數與分級圖卷積網絡的協同排名模型
2024-03-01 08:53:50鄭升旻胡林發漆鑫鑫
現代電子技術 2024年4期
鄭升旻,胡林發,漆鑫鑫
(昆明理工大學 信息工程與自動化學院,云南 昆明 650504)
0 引言
互聯網時代,用戶在網絡上經常面對海量的商品信息,但過量的數據使得用戶難以從中篩選出自己所需要的商品。推薦系統[1]通過估計用戶對商品的偏好,向用戶推薦可能喜歡的商品,以此緩解用戶面臨的信息過載問題。
實際應用中,眾多推薦系統以用戶對項目評分的分值表示用戶的偏好程度,分值越大表示用戶的偏好程度越高,因此傳統推薦模型通常采用均方根誤差(Root Mean Squared Error,RMSE)作為指標,將評分預測準確度作為優化方向。但是用戶獲取推薦項目時更關心推薦結果是否符合自己的喜好,而非模型預測的分值。實際應用中推薦系統為用戶推薦項目往往是返回給用戶一個top?k序列,即用戶未評分的項目中,模型預測的評分最高的k個項目。由此可見,相較于預測評分的準確度,項目的排名質量更加關鍵。而評分預測準確度與預測排名質量之間并不一致,準確度更高并不意味著偏好預測排序質量更好[2?3]。
為解決這一問題,出現了直接優化排序質量的協同排名模型(Collaborative Ranking),如List?MF(Listwise Matrix Factorization)[4]。List?MF 將訓練排名序列和模型預測排名序列中項目top?1 概率的交叉熵作為損失函數來訓練排名模型,直接優化預測排名質量。SQL?Rank(Stochastic Queuing Listwise Ranking)[3]則考慮具有相同評分的項目之間的位置關系,通過在訓練過程中對評分相同的項目隨機排序以解決評分相同造成的歧義。但這類直接優化排名的協同排名方法所采用的損失函數具有非凸性,因此只能得到局部最優解,導致預測效果較差[3?4]。
近年來,基于成對比較(Pairwise Comparison)的個性化協同排名算法取得了很大的進展。這類方法根據用戶評分數據為每個用戶構造項目之間的兩兩相互比較,借此將用戶的偏好序列轉化為不同項目之間的比較對,通過這種方式將用戶偏好排名的優化問題轉化為成對比較的分類問題。交替支持向量機(Alternating Support Vector Machine,AltSVM)[5]和Primal?CR(Primal Collaborative Ranking)[6]是成對比較類協同排名算法中極富代表性的方法。AltSVM 是一種非凸式協同排名算法,它顯式地以因子形式對低秩矩陣進行參數化,并最小化合頁損失函數。AltSVM 算法會交替更新用戶和項目的潛在因子,算法每一步都可以被表示為一個標準的SVM 對兩個因子中的一個進行更新。Primal?CR 算法則基于牛頓法快速計算損失函數梯度和Hessian 矩陣,之后利用坐標下降法交替更新用戶和服務的隱向量,有效地降低了算法的時間復雜度。在Primal?CR 的基礎上,Primal?CR++[6]基于用戶信息多為評分數據的特點,繼續改進梯度計算方法和Hessian 向量計算方法,進一步降低了算法的計算速度。
上述協同排名方法一般基于矩陣分解,采用固定的線性函數(如內積)作為交互函數,而這類函數不能擬合非線性關系,但NCF(Neural Collaborative Filtering)[7]等方法已經證實,擬合非線性關系在建模用戶和項目交互時具有顯著效果。因此,基于生成對抗網絡的協同排名模 型(Collaborative Ranking Generative Adversarial Network,CRGAN)[7]選擇利用全連接網絡作為交互函數。CRGAN 通過生成對抗網絡擬合用戶的偏好分布,使用多層全連接神經網絡作為模型的生成器與判別器。NCPL(Neural Collaborative Preference Learning)[8]則設計了深層和淺層兩種交互函數,將兩種交互函數輸出的向量通過一層全連接層,得到預測得分。其中淺層的交互函數為Hadamard 積,深層的交互函數則包含多層的全連接神經網絡。但用戶和項目之間的多級鄰接關系中具有豐富的交互信息,而上述算法對這些交互信息的挖掘不夠充分[9]。
圖卷積網絡(Graph Convolutional Network,GCN)是一種圖結構數據上的特征提取方法,現在已經廣泛應用于推薦模型中,如圖卷積矩陣補全模型(Graph Convolutional Matrix Completion,GCMC)[10]通過聚合異質鄰接節點的信息,直接從二部圖中挖掘用戶和項目特征;輕量級圖卷積模型(Light Graph Convolution Network,LightGCN)[9]通過多層鄰接關系中的信息傳遞構建用戶和項目的嵌入表示,并且利用可學習的權重系數來近似實現自連接。相較于傳統方法,圖卷積網絡能夠獲取用戶和項目之間潛在的交互信息,由此得到質量更好的嵌入表[10]。
基于上述研究,本文提出一種融合成對損失函數與分級圖卷積網絡的協同排名模型(Hierarchical Graph Convolution Network with Pair?Wise Loss,HGCN?PW),通過分級圖卷積挖掘用戶?項目二部圖中異質節點之間的交互信息,再充分利用用戶評分數據中隱含的交互關系,提高嵌入向量的質量。
其次,將評分數據構造成項目間的成對比較,基于成對比較優化模型以直接提高模型預測排序的質量。針對分級圖卷積網絡設計了對應的自連接策略,實現對用戶和項目信息的充分利用;并結合內積與神經網絡以作為用戶與項目間的交互函數,使其得以擬合非線性關系。
1 融合成對損失函數與圖卷積網絡的協同排名
HGCN?PW 包括嵌入傳播層和預測層。嵌入傳播層中的圖卷積層利用分級圖卷積直接挖掘異質圖上的交互信息,相比挖掘用戶與項目交互矩陣可利用更多信息;接著通過全連接層融入輔助信息,得到用戶和項目的嵌入向量。預測層根據嵌入向量,結合非線性變換與內積預測用戶對項目的偏好程度,再利用成對比較數據訓練模型。HGCN?PW 的模型框圖如圖1 所示。

圖1 融合成對損失函數與分級圖卷積網絡的協同排名模型框圖
1.1 符號及定義
給定用戶集合U和項目集合V,其中m=||U、n=|V|分別表示用戶數和項目數,并設定相應的評分信息,以構建相應的評分矩陣R∈Zm×n,評分取值范圍為Rij∈{1,2,…,L}。按照評分取值范圍,為每一類評分構建分級矩陣Rl∈Zm×n:
式中l∈{1,2,…,L},由分級矩陣可以得到對應的分級鄰接矩陣Al:
式中:Al∈Z(m+n)×(m+n),每一個分級鄰接矩陣都對應著一個分級交互圖。圖1 中包含用戶和項目兩種節點,每條邊連接著一個用戶節點和一個項目節點,表示用戶對項目給出的評分為l,所有分級鄰接矩陣集合A={Al|l=1,2,…,L}。用戶的特征信息為,項目特征信息為。為統一用戶和項目的特征向量維度,本文中將它們記為XU=[,0],XU∈Rm×d,XV=表示用戶和項目特征信息,xui和xvj分別表示用戶ui和項目vj的特征向量。
為解決協同過濾模型不能直接優化用戶偏好序列的問題,本文根據用戶評分數據為每個用戶構造項目之間非數值的成對比較,基于這些成對比較優化模型。傳統的RMSE 獨立計算每個預測評分與真實值之間的差距,本質是一種點比較損失函數,因此無法直接優化項目排序。成對比較(Pairwise Comparison)方法將排序轉化為項目間成對比較的分類問題:首先由U、V可以構造用戶和相應項目的成對比較三元組集合Ω={(i,j,k)|ui∈U;vj,vk∈V,j≠k},(i,j,k)表示用戶ui在項目vj、vk中更偏好vj,如果項目vj、vk的優劣關系正確則為正例,錯誤即為負例。成對比較方法相對于點比較方法考慮到了項目間的相對位置關系,更加符合優化用戶偏好排名的需要。具體的,可根據評分矩陣R為Ω中每個三元組賦予標簽:
式中:Ri,j>Ri,k表示用戶ui給項目vj的評分比項目vk高,即用戶ui在項目vj、vk中更偏好vj;為1 表示對應的三元組(i,j,k)為正例,反之為負例;Y={}表示Ω中所有成對比較的標簽。模型的優化目標是減少錯誤分類的成對比較數量。
1.2 嵌入傳播層
1.2.1 異質交互圖中的信息傳遞
GCMC 中所采用的圖卷積操作為:對圖中每個節點執行只考慮一階鄰域的局部圖卷積操作。這種局部圖卷積可以被看作是一種異質節點之間的消息傳遞[11],節點的特征向量作為節點信息,以向量形式在交互圖中沿著邊傳遞和轉換,這樣的卷積方式可以通過疊加圖卷積層簡便地將圖卷積范圍擴展到高階鄰域。因此本文采用同樣的圖卷積策略,根據邊類型構造不同的交互圖,為不同交互圖上分配不同的卷積權值參數矩陣,以實現不同的邊上具有不同的消息傳遞方式,即分級圖卷積。從項目節點vj到用戶節點ui,沿著評分為l的邊所傳遞的信息可表示為:
式中:cij是正則化常量,值為,Nui是用戶ui節點的鄰接節點集合,Nvj是項目vj節點的鄰接節點集合;Wl是分值l對應的卷積權值參數矩陣,表示鄰接矩陣Al對應的交互圖上的消息轉換規則。由用戶節點ui到項目節點vj的信息傳遞為:
在缺失節點特征或者節點特征不足以區分各個不同節點時,以節點序號獨熱編碼(one?hot encoding)作為節點特征,輸入圖卷積層就可獲得良好的效果[10]。但不同分級矩陣下的各用戶和項目相關的評分數量往往相差較多,而在以獨熱編碼為節點特征輸入圖卷積層時,會導致Wl的某些列被優化的頻率明顯低于其他列。因此,需要在不同l對應的Wl之間采取某種形式的權重共享,以緩解這一優化問題。本文采用文獻[12]所提出的權重共享方案:
1.2.2 節點的信息聚合與自連接
消息傳遞后,需要聚合節點收到的消息。對于用戶ui,首先將其在鄰接矩陣Al上所有鄰接點Nui,l的消息求和,得到該節點在Al對應的交互圖上的消息向量μui,l;接著將所有交互圖上的消息向量聚合為用戶的中間向量,具體為:
式中:accum(·)表示聚合操作,可以通過堆疊stack(·)實現,即將多個向量串聯成一個向量,或者通過sum(·)實現,即對所有向量求和;σ(·)則代表一個激活函數,可選擇ReLU=max(0,·)或其他形式。
GCMC 中直接用hui替換原節點信息,但是這種更新方式并未考慮節點自身信息的作用,當圖卷積層多于一層時,相當于丟棄上一層圖卷積所聚合的鄰接點信息。因此為保證節點自身信息充分表達,需要在聚合鄰接節點信息的同時考慮自連接信息。自連接信息的加入方式[9]是:將鄰接矩陣與單位矩陣相加,以在圖卷積操作中實現自連接,但是本文將評分矩陣轉化成多個分級矩陣,直接在每個分級鄰接矩陣中加入單位矩陣,這將會使得圖卷積過程中重復加入自身節點信息。因此本文不修改分級鄰接矩陣,直接對節點的特征向量執行一次特征變換,將其作為自連接信息加入圖卷積操作中,其中特征變換矩陣選擇權重共享矩陣TL。項目節點也執行同樣操作。
圖卷積層最終輸出的用戶中間向量為:
式中:μui?self為節點的特征向量經過一次特征變換后的自連接向量。給定用戶?項目評分矩陣R∈Zm×n,用戶和項目的特征信息為。嵌入傳播層的矩陣形式為:
1.3 預測層
預測層利用嵌入傳播層輸出的嵌入矩陣ZU、ZV,預測用戶?項目排名得分矩陣,即用戶和項目之間的交互函數。傳統的協同過濾方法中,通常使用內積作為交互函數,但內積作為交互函數有著無法擬合非線性關系的明顯缺陷。因此本文在內積的基礎上,通過增加非線性激活函數,使得預測層具有擬合非線性關系的能力。同時,由于本文方法只是利用預測分值來得到項目排序,不需要保證預測分值的準確度,因此加入Sigmoid 層控制分值預測范圍。預測層公式如下:
式中:f1是以ReLU 為激活函數的隱層;f2是以Sigmoid 為激活函數的隱層;是模型預測的排名得分矩陣,包括所有用戶對所有項目的預測得分,根據預測得分由高到低排序可得用戶的預測偏好排名。
1.4 模型訓練
與直接優化RMSE 不同,本文基于成對比較數據來優化每個用戶對不同項目的偏好排名。因此需要先計算同一用戶不同項目間預測得分的差值:
式中m為預定義的得分差值間距。
2 實驗及結果分析
為了驗證HGCN?PW 的性能,采用Pytorch 框架,在Ubuntu 20.04 64 位操作系統,PyCharm 2020,Intel?CoreTMi7?9700F CPU @3.0 GHz,8 GB 內存,RTX 2060 GPU,Python 3.8 的環境下進行對比實驗。
2.1 實驗數據集
本文在一些常見的協同過濾基準數據集上,將HGCN?PW 與其他模型相比較,所采用的數據集包含用戶對項目(如電影)的評分。實驗數據集情況如表1所示。
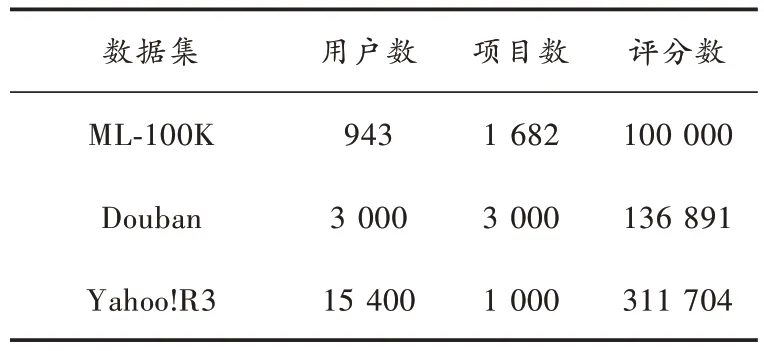
表1 數據集基本信息
表1 中:ML?100K 數據集[10]包含用戶和項目的輔助信息(如用戶的年齡、職業、項目的時間、類型等);Douban 數據集是由文獻[13]提供的Douban 數據集的子集,包括3 000 用戶和3 000 項目,并將用戶間的社交關系作為輔助信息;Yahoo!R3 為雅虎音樂的評分數據集,沒有輔助信息[3]。
2.2 評價指標及對比算法
本文采用的評價指標包括歸一化折損累計增益NDCG 和預測成對比較錯誤率(Pairwise Error)[6]。其中用戶ui的NDCG@K定義為:
式中:πi為用戶ui根據預測得分由高到低對項目排序得到的排名;πi(k)為πi中排第k位的項目序號;Rij表示用戶ui對項目vj的真實評分;表示根據用戶ui的真實評分最大化DCG@K的項目順序;NDCG@K以預測排名的DCG 值與理想的最大化DCG 之比表示預測排名的質量,數值越接近1,預測效果越好。這種方法只計算預測排名中的前K個項目,并且由于衰減項,排名越靠前的項目權重越大。
Pairwise Error 定義為:
式(18)表示在測試數據集Γ的所有成對比較中,模型預測錯誤的成對偏好比較的比例。
AltSVM、PrimalCR、PrimalCR++是近年來成對比較類協同排名算法中極富代表性的方法,三種方法憑借其優秀的推薦效果而常被作為協同排名的基線方法[3]。CRGAN、NCPL 是基于神經網絡的協同排名模型中的最新方法,因此本文選取這5 種方法為對比方法。
2.3 實驗設置
與文獻[6]相同,對于實驗中用到的數據集,首先篩選出評分數超過20的用戶,然后每個用戶隨機選取20個評分作為測試集,剩余的評分數據作為訓練集。在所有實驗中,用戶和項目的特征信息都用其序號對應的獨熱編碼表示,模型嵌入傳播層部分由兩層圖卷積層組成,第一層使用串聯聚合消息,第二層采用求和聚合消息,兩層網絡都加入自連接,失活率都設置為0.7,激活函數都采用LeakyReLU。優化器使用Adam[14],學習率為0.001。模型兩層圖卷積層的維度分別為64 和32,每一輪訓練隨機選取固定數量的成對比較數據,用于計算損失值。本文所有實驗中成對比較數據數量均設置為2 048,得分間距差值m設置為1.5。ML?100K 數據集運行500 輪迭代,Douban、Yahoo!R3 運行300 輪迭代。
2.4 性能對比
為了評估HGCN?PW 的性能,本文將其與目前成對比較類CR 算法中的AltSVM 和PrimalCR、PrimalCR++、CRGAN、NCPL 在相同環境下進行比較,NDCG@10 作為評價指標。在4 個數據集上分別進行10 次實驗,取其平均值作為實驗結果。NDCG@10 對比實驗結果如表2 所示,Pairwise Error 對比實驗結果如表3 所示。
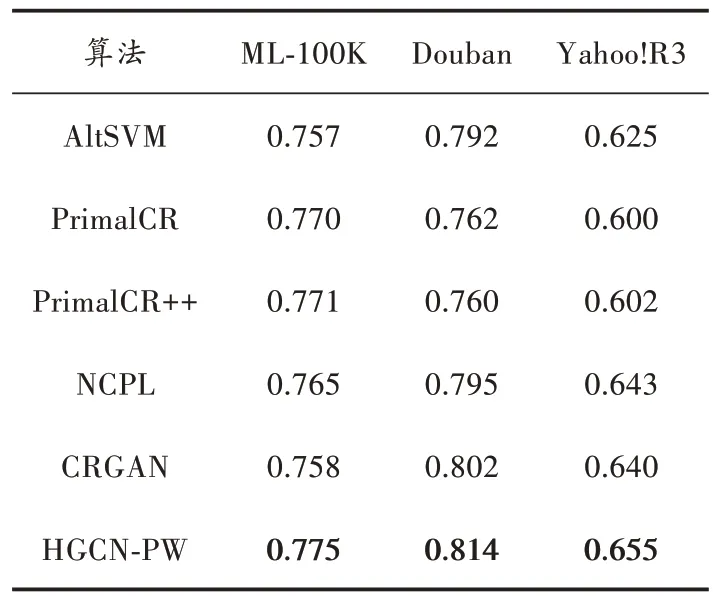
表2 NDCG@10 對比實驗結果

表3 Pairwise Error 對比試驗結果
由表2、表3 可知,本文所提出的HGCN?PW 算法相較其他方法有著顯著的優勢,在ML?100K、Douban、Yahoo!R3 數據集上都獲得了最佳的效果。HGCN?PW通過異質節點之間的消息傳遞挖掘用戶?項目交互,兩層卷積層增加了卷積范圍,使得模型對用戶和項目的潛在特征具有更強的表達能力;同時,在利用用戶和項目的嵌入向量計算內積之前,將兩者輸入帶非線性激活函數的全連接層,令模型的交互函數具有內積無法比擬的非線性擬合能力。正是由于這兩點,HGCN?PW 的性能顯著優于其他算法。
2.5 損失函數有效性
損失函數的優化以最小化損失為目標。過去的許多工作[5?6]已經表明,采用合頁損失函數,最小化損失能有效地優化模型,提高預測排名質量。不同于傳統的成對比較類協同排名算法,HGCN?PW 利用圖卷積獲取用戶與項目的嵌入,再通過神經網絡預測排名得分矩陣,并且每一輪訓練選取不同的成對比較數據,因此仍然需要討論最小化損失是否能夠優化HGCN?PW 模型,使其輸出一個好的排名。出于這個原因,在ML?100K 數據集上,本文在模型優化迭代過程中同時展示損失值和NDCG@10 的變化。為便于展示,對損失值進行歸一化(Min?Max Normalization)處理,結果如圖2 所示。
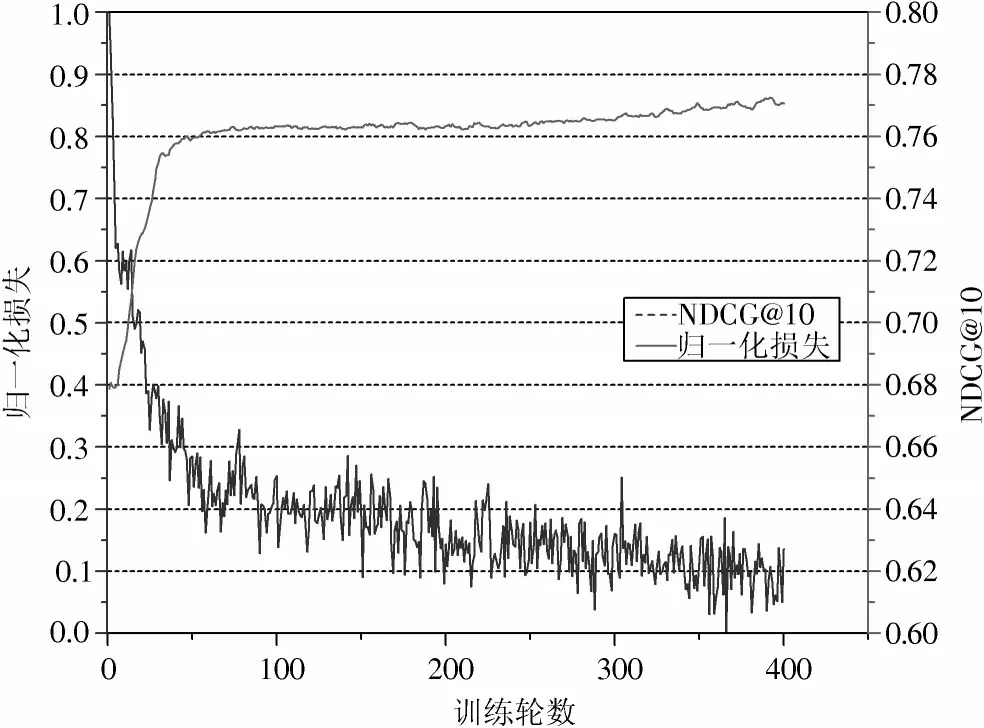
圖2 HGCN?PW 通過最小化合頁損失以優化NDCG@10 的有效性
由圖2 可知:在優化損失函數時,隨著損失值下降,模型的預測排名質量不斷上升,在開始的50 個輪次左右,模型所采樣的成對比較三元組之間區別較大,因此排名質量上升較快;隨著訓練的進行,模型采樣所得三元組中的用戶或項目開始與之前三元組中的用戶或項目產生重復,因此排名質量上升速度變慢。同時,實驗中NDCG@10 在大約450 次迭代后成為近似最優,表明HGCN?PW 基于成對比較數據優化排名質量是有效的。
2.6 預測層消融實驗
為驗證預測層中非線性激活層的作用,本文選取ML?100K、Douban、Yahoo!R3 數據集作為實驗數據集,設計了如下消融實驗:
1)PDT,僅使用內積預測排名得分矩陣。
2)PDT?R,嵌入表示經帶ReLU 激活函數的全連接層后計算內積。
3)PDT?S,嵌入表示經帶Sigmoid 激活函數的全連接層后計算內積。
4)PDT?RS,嵌入表示連續經過ReLU 和Sigmoid 作為激活函數的全連接層后計算內積。
HGCN?PW 的參數設置與前文保持一致,不同情況下的模型表現如表4 所示。
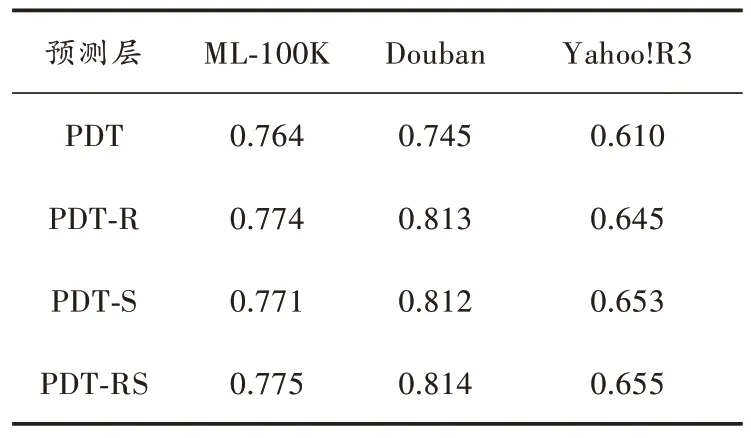
表4 預測層消融實驗結果
如表4 中所示,在所有數據集上僅使用內積的預測表現最差,加入帶非線性激活函數的全連接層后,模型預測效果有顯著提升。具體的,在實驗所用的3 個數據集上,PDT?R 相較于內積NDCG@10 分別提升1.3%、9.1%、5.7%,PDT?S 相較于內積分別提升0.9%、8.9%、7.0%。將兩種激活函數都加入預測層后,PDT?RS 相較于內積分別提升1.4%、9.2%、7.3%,預測質量達到最優。由此可以看出,加入非線性激活層之后,預測層得以擬合非線性關系,因此預測表現更好。結合不同的非線性激活函數便可以使得模型達到最佳預測效果。
3 結語
現有的協同排名算法對于用戶與項目間的交互信息挖掘不足且難以擬合非線性關系,針對這一問題,文中提出一種融合成對損失函數與圖卷積網絡的協同排名模型(HGCN?PW)。模型根據用戶評分信息構建分級評分矩陣和成對比較數據;接著通過分級圖卷積挖掘用戶?項目二部圖中節點的異質交互信息,并利用特殊的自連接策略,得到相應的用戶、項目嵌入矩陣;之后將2 個矩陣輸入神經網絡預測層得到預測排名得分矩陣;再基于成對比較數據,利用合頁損失函數訓練模型。HGCN?PW 在ML?100K、Douban、Yahoo!R3 數據集上相較于現有的同類方法均體現出明顯優勢。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中華手工(2017年2期)2017-06-06 23:00:31
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年5期)2015-02-27 07:53:25
中外會展(2014年4期)2014-11-27 07:46:46
