基于可變尺度先驗(yàn)框的聲吶圖像目標(biāo)檢測(cè)
2024-03-05 10:21:26黃思佳宋純鋒
系統(tǒng)工程與電子技術(shù) 2024年3期
黃思佳, 宋純鋒, 李 璇,*
(1. 中國(guó)科學(xué)院聲學(xué)研究所水下航行器信息技術(shù)重點(diǎn)實(shí)驗(yàn)室, 北京 100190;2. 中國(guó)科學(xué)院大學(xué)電子電氣與通信工程學(xué)院, 北京 100049;3. 中國(guó)科學(xué)院自動(dòng)化研究所智能感知與計(jì)算研究中心, 北京 100190)
0 引 言
伴隨著計(jì)算機(jī)的普及以及互聯(lián)網(wǎng)的飛速發(fā)展,信息的傳遞變得更加方便快捷,人們的交流媒介逐漸從文字轉(zhuǎn)變成圖片以及視頻。相比傳統(tǒng)處理圖像的方法而言,深度學(xué)習(xí)方法憑借其強(qiáng)大的處理數(shù)據(jù)和提取信息的能力、較高的準(zhǔn)確率和快速計(jì)算等優(yōu)點(diǎn),脫穎而出成為圖像識(shí)別和目標(biāo)檢測(cè)領(lǐng)域的研究熱點(diǎn)[1]。
傳統(tǒng)的聲吶圖像目標(biāo)識(shí)別一般采用機(jī)器學(xué)習(xí)的方法,主要由候選區(qū)域生成、特征提取器以及分類器三部分組成。傳統(tǒng)的目標(biāo)識(shí)別方法對(duì)于目標(biāo)的先驗(yàn)信息,形狀等都有一定的要求,特征提取非常依賴人工的選擇,若圖像的像素太少或者特征不夠有代表性,識(shí)別目標(biāo)的效果就會(huì)比較差。然而,由于水下環(huán)境復(fù)雜,回波受到混響噪聲、環(huán)境噪聲的影響,導(dǎo)致聲吶圖像分辨率低,邊緣細(xì)節(jié)較為模糊,很難找到像素和具有代表性的良好特征。另外,由于水下環(huán)境的不確定性很大,人工獲取先驗(yàn)信息的代價(jià)也比較高,因此傳統(tǒng)的目標(biāo)檢測(cè)算法在聲吶圖像的目標(biāo)檢測(cè)中效果并不理想。
近些年,深度學(xué)習(xí)在人臉識(shí)別[2-4]、醫(yī)學(xué)圖像識(shí)別[5-7]、遙感圖像分類[8-10]等領(lǐng)域都有了廣泛應(yīng)用,許多學(xué)者開(kāi)始將深度學(xué)習(xí)的模型遷移到聲吶圖像的目標(biāo)檢測(cè)中進(jìn)行應(yīng)用,提高了水下聲吶圖像的識(shí)別精度和速度。文獻(xiàn)[11]提出利用輕量級(jí)的CPU卷積神經(jīng)網(wǎng)絡(luò)(lightweight CPU convolutional neural network, PP-LCNet)替換原Yolov5網(wǎng)絡(luò)中的跨階段局部網(wǎng)絡(luò)結(jié)構(gòu)(cross stage partial darkNet, CSPDarknet)主干網(wǎng)絡(luò),在不降低檢測(cè)精度的前提下減少了模型參數(shù)量和網(wǎng)絡(luò)計(jì)算量,能夠更好地滿足低功耗平臺(tái)的在航檢測(cè)要求。文獻(xiàn)[12]針對(duì)聲吶圖像數(shù)據(jù)量不足的情況,建立了水下目標(biāo)的仿真模型,并且利用仿真樣本與真實(shí)樣本相結(jié)合進(jìn)行實(shí)驗(yàn),在不同的模型下都有一定的提升效果,為聲吶圖像數(shù)據(jù)不足的問(wèn)題提供了解決思路。文獻(xiàn)[13]針對(duì)聲吶圖像像素空缺,成像效果不好的問(wèn)題,采用雙線性插值算法進(jìn)行像素填充,讓聲吶圖像變得更加清晰飽滿,并且在Yolov3模型上進(jìn)行實(shí)驗(yàn),取得了良好的效果。文獻(xiàn)[14]針對(duì)聲吶圖像散斑噪聲強(qiáng)、分辨率低、圖像質(zhì)量差等問(wèn)題,提出了一種基于快速曲線變換的去噪算法,有效提高了混響干擾下聲吶圖像的質(zhì)量。文獻(xiàn)[15]結(jié)合顯著性分割和金字塔池化的檢測(cè)模型,減小了輸入數(shù)據(jù)的維度并且減小了圖像背景對(duì)目標(biāo)提取的干擾,有效提高了水下目標(biāo)識(shí)別的準(zhǔn)確率。文獻(xiàn)[16]利用聲吶圖像模擬器來(lái)模擬聲吶傳感器的成像機(jī)制,結(jié)合各種退化效應(yīng)來(lái)合成訓(xùn)練圖像,一定程度上緩解了聲吶圖像數(shù)據(jù)量不足的問(wèn)題。文獻(xiàn)[17]利用生成對(duì)抗網(wǎng)絡(luò)(generative adversarial networks, GAN)合成真實(shí)聲吶圖像作為目標(biāo)物體的訓(xùn)練圖像,該方法可以合成不同角度和不同環(huán)境的真實(shí)訓(xùn)練數(shù)據(jù),為其他基于聲吶圖像的算法提供了一定參考。 文獻(xiàn)[18]針對(duì)聲吶圖像噪聲干擾嚴(yán)重的問(wèn)題,提出了一種自適應(yīng)全局特征增強(qiáng)網(wǎng)絡(luò),能夠獲取聲吶圖像多尺度語(yǔ)義特征,在噪聲嚴(yán)重的情況下仍然能對(duì)目標(biāo)進(jìn)行準(zhǔn)確的檢測(cè)和定位。文獻(xiàn)[19]提出一種基于Yolov4改進(jìn)的聲吶圖像目標(biāo)檢測(cè)算法,將Yolov4中的路徑聚合網(wǎng)絡(luò)(path aggregation network, PANet)特征增強(qiáng)模塊替換為自適應(yīng)空間特征融合(adaptively spatial feature fusion, ASFF)模塊,來(lái)獲得了更好的特征融合效果。文獻(xiàn)[20]針對(duì)前視聲吶圖像中的小目標(biāo)檢測(cè)問(wèn)題提出了一種基于脈沖耦合神經(jīng)網(wǎng)絡(luò)和Fisher判別的實(shí)時(shí)目標(biāo)檢測(cè)方法,該算法結(jié)合模糊c均值聚類和K均值聚類獲得感興趣的區(qū)域,在低虛警概率下檢測(cè)誤差小,實(shí)時(shí)性好。文獻(xiàn)[21]根據(jù)實(shí)測(cè)過(guò)程中不同原因造成的成像差異進(jìn)行了數(shù)據(jù)的增強(qiáng)與擴(kuò)充,并改進(jìn)了池化方式,提升了檢測(cè)效果。
上述研究通過(guò)借鑒深度學(xué)習(xí)在計(jì)算機(jī)視覺(jué)領(lǐng)域的成果,提升了聲吶圖像目標(biāo)檢測(cè)的性能。然而,聲吶圖像的目標(biāo)檢測(cè)方法仍然存在數(shù)據(jù)獲取難、數(shù)據(jù)量少、目標(biāo)尺度分布集中、檢測(cè)性能不佳、模型實(shí)時(shí)性差的問(wèn)題,因此本文提出了一種基于輕量級(jí)目標(biāo)檢測(cè)模型Yolov5改進(jìn)的水下目標(biāo)檢測(cè)方法。針對(duì)聲吶數(shù)據(jù)集與COCO數(shù)據(jù)集在目標(biāo)大小上的差異,利用目標(biāo)尺度的先驗(yàn)信息,自適應(yīng)地生成可變尺度的先驗(yàn)錨框,有效提高了聲吶圖像中目標(biāo)的尺度適應(yīng)性。深度學(xué)習(xí)的模型訓(xùn)練需要大量的數(shù)據(jù)支撐,因此本文采用了數(shù)據(jù)增強(qiáng)的方法對(duì)訓(xùn)練集進(jìn)行有選擇性的擴(kuò)充,進(jìn)一步增強(qiáng)模型的魯棒性。此外,本文還探索了模型的輕量化,在不犧牲模型精度的前提下,通過(guò)刪減大目標(biāo)檢測(cè)層降低了模型復(fù)雜度,可更好地適應(yīng)實(shí)時(shí)檢測(cè)的要求。
1 基于可變尺度先驗(yàn)框的聲吶圖像目標(biāo)檢測(cè)方法
1.1 網(wǎng)絡(luò)結(jié)構(gòu)介紹
(1) 輕量化目標(biāo)檢測(cè)模型概述
相比于快速局部卷積神經(jīng)網(wǎng)絡(luò)(fast region-convolutional neural network, Fast R-CNN)[22]以及Faster R-CNN[23]等兩階段目標(biāo)檢測(cè)算法,Yolo系列作為單階段目標(biāo)檢測(cè)算法的代表,不需要生成候選區(qū)域,而是直接通過(guò)網(wǎng)格進(jìn)行坐標(biāo)回歸,大大提高了目標(biāo)檢測(cè)的速度。Yolov1[24]將圖像分成S×S個(gè)網(wǎng)格,如果物體的中心點(diǎn)落在某網(wǎng)格內(nèi),那么該網(wǎng)格就負(fù)責(zé)預(yù)測(cè)這個(gè)目標(biāo)。在Yolov1當(dāng)中,每個(gè)網(wǎng)格對(duì)應(yīng)兩個(gè)預(yù)測(cè)邊界框,并且每個(gè)網(wǎng)格只對(duì)應(yīng)一個(gè)類別,所以對(duì)于比較密集的小目標(biāo)檢測(cè)效果較差,會(huì)出現(xiàn)漏檢的情況。Yolov1在預(yù)測(cè)目標(biāo)位置的時(shí)候,是通過(guò)直接預(yù)測(cè)目標(biāo)的寬高以及中心點(diǎn)坐標(biāo),這種預(yù)測(cè)方法導(dǎo)致目標(biāo)框與物體的位置之間偏移量很大。針對(duì)Yolov1當(dāng)中定位不準(zhǔn)的問(wèn)題,Yolov2[25]開(kāi)始采用基于先驗(yàn)框進(jìn)行預(yù)測(cè),相比于直接預(yù)測(cè)目標(biāo)邊界框,采用先驗(yàn)框偏移的方式進(jìn)行預(yù)測(cè)使得網(wǎng)絡(luò)更容易學(xué)習(xí)且更快收斂。Yolov2中每個(gè)網(wǎng)格對(duì)應(yīng)5個(gè)先驗(yàn)框,且每個(gè)先驗(yàn)框可以預(yù)測(cè)不同類別,改善了較為密集物體的目標(biāo)檢測(cè)的問(wèn)題。除此之外,Yolov2還進(jìn)行了一些嘗試,例如多尺度訓(xùn)練、通過(guò)passthrough層更好地提取目標(biāo)的細(xì)粒度特征等,速度和精度相對(duì)Yolov1都有了一定的提升。Yolov3[26]采用Darknet-53作為骨干網(wǎng)絡(luò),引入了空間金字塔池化(spatial pyramid pooling, SPP)的思想。在頸部引入了特征金字塔池化(feature pyramid network, FPN)的思想,可以融合不同特征圖的信息,能夠更好地提取目標(biāo)的特征。與FPN不同的是,Yolov3是在深度方向上進(jìn)行拼接,可以更好地保留特征信息。Yolov3在3個(gè)預(yù)測(cè)特征層上進(jìn)行預(yù)測(cè),在每個(gè)預(yù)測(cè)特征層上分別使用3個(gè)不同大小的先驗(yàn)框,可以檢測(cè)不同大小的目標(biāo)。Yolov4[27]采用CSPDarknet53作為骨干網(wǎng)絡(luò),在Darknet53的基礎(chǔ)上引入了跨階段部分(cross stage partial, CSP)結(jié)構(gòu),增強(qiáng)了CNN學(xué)習(xí)的能力以及降低了顯存的使用。Yolov4將(rectified linear activation function, ReLU)激活函數(shù)改為Mish激活函數(shù),Mish激活函數(shù)的圖像更加平滑,還采用了一些優(yōu)化策略,例如Mosaic增強(qiáng),引入縮放因子來(lái)消除網(wǎng)格的敏感度等。與Yolov4相比,Yolov5在骨干網(wǎng)絡(luò)中增加了Focus層,在不影響算法精度的情況下提高了每秒浮點(diǎn)運(yùn)算量(floating-point operations per second, FLOPS),Yolov5還引入了C3模塊,促進(jìn)特征融合,與Yolov4相比性能更強(qiáng)。除此之外,Yolov5網(wǎng)絡(luò)還能通過(guò)改變參數(shù)來(lái)改變網(wǎng)絡(luò)的深度和寬度以更好地適應(yīng)不同數(shù)據(jù)量規(guī)模的需求,這種改進(jìn)對(duì)于聲吶圖像這類數(shù)量較少的數(shù)據(jù)集有一定作用,可以根據(jù)聲吶數(shù)據(jù)集的大小調(diào)整模型的參數(shù),實(shí)現(xiàn)更好的自適應(yīng)。
(2) 本文采用的骨干模型
Yolov5的網(wǎng)絡(luò)結(jié)構(gòu)可以分為Backbone和Head兩大部分。輸入通過(guò)骨干網(wǎng)絡(luò)下采樣5次,選取3個(gè)特征層作為Head部分的輸入。在骨干網(wǎng)絡(luò)部分,輸入首先經(jīng)過(guò)一個(gè)Focus層,將數(shù)據(jù)的寬度和高度減小為原來(lái)的一半,減少了參數(shù)量,同時(shí)也提高了網(wǎng)絡(luò)的前向傳播速度。然后,通過(guò)4個(gè)卷積層和C3層,C3層是在Yolov4網(wǎng)絡(luò)CSP層的基礎(chǔ)上提出的,C3層可以幫助骨干網(wǎng)絡(luò)更好地提取特征信息。Yolov5將激活函數(shù)改為Silu函數(shù),Silu函數(shù)更為光滑且處處可導(dǎo)。最后,Yolov5在最后一個(gè)卷積層和C3層中間增加了SPP模塊,SPP將輸入并行通過(guò)多個(gè)不同大小的最大池化,然后進(jìn)一步做融合,可以在一定程度上解決目標(biāo)多尺度的問(wèn)題。
(3) 可變尺度先驗(yàn)框模型
本文提出的可變尺度先驗(yàn)框模型如圖1所示,首先對(duì)聲吶圖像的訓(xùn)練集進(jìn)行分布統(tǒng)計(jì),獲取目標(biāo)的尺度信息,并利用(intersection over union, IoU)聚類的方法重新設(shè)定先驗(yàn)框;其次利用平移、旋轉(zhuǎn)、改變亮度、加噪聲、cutout、鏡像等方式選擇性的對(duì)數(shù)據(jù)集進(jìn)行增強(qiáng),將擴(kuò)增后的數(shù)據(jù)集輸入到Y(jié)olov5骨干網(wǎng)絡(luò)提取目標(biāo)特征信息;最后在兩個(gè)尺度的目標(biāo)檢測(cè)層進(jìn)行目標(biāo)定位以及類別判定。
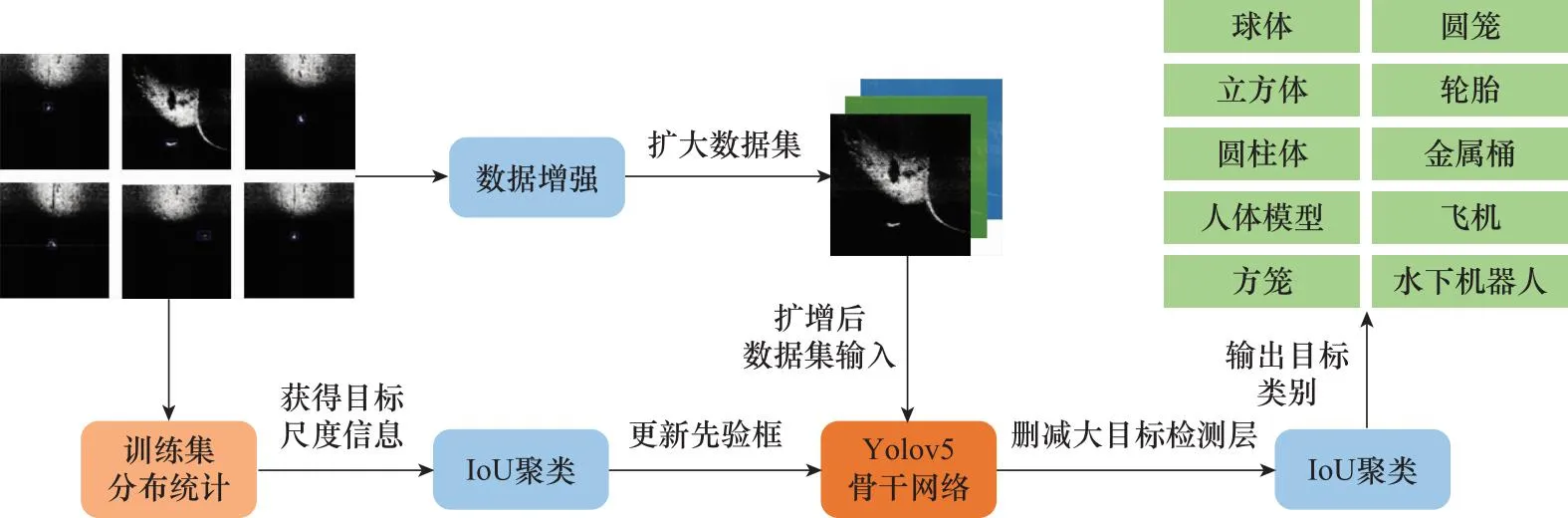
圖1 可變尺度先驗(yàn)框模型Fig.1 Variable scale prior box model
1.2 可變尺度先驗(yàn)框目標(biāo)檢測(cè)模型
1.2.1 基于數(shù)據(jù)統(tǒng)計(jì)的目標(biāo)尺度分布獲取
本文所使用的數(shù)據(jù)集來(lái)源于2022年全國(guó)水下機(jī)器人大賽(underwater robot professional contest, URPC)的比賽數(shù)據(jù)集[28],該數(shù)據(jù)集共有9 200張前視聲吶圖像,分別由人體模型、球體、圓籠、方籠、輪胎、金屬桶、立方體、圓柱體、飛機(jī)模型以及水下機(jī)器人10類目標(biāo)組成。
在進(jìn)行目標(biāo)檢測(cè)之前,需要先對(duì)數(shù)據(jù)集的目標(biāo)進(jìn)行分析。深度學(xué)習(xí)算法是以數(shù)據(jù)驅(qū)動(dòng)的, 雖然數(shù)據(jù)集有9 200張圖片,但對(duì)于深度學(xué)習(xí)而言,數(shù)據(jù)量還是偏少。針對(duì)數(shù)據(jù)量不足的問(wèn)題,本文根據(jù)聲吶圖像的特點(diǎn)進(jìn)行相應(yīng)的增強(qiáng)。在獲取水下目標(biāo)的聲吶圖像時(shí),由于聲吶檢測(cè)的角度不同、水底地形的干擾、水下深淺不一導(dǎo)致信號(hào)有偏差以及各種環(huán)境噪聲、混響噪聲的影響,導(dǎo)致水下目標(biāo)檢測(cè)困難。為增強(qiáng)圖像的魯棒性,本文采用旋轉(zhuǎn)、平移、改變亮度、加噪聲等圖像增強(qiáng)的方式對(duì)數(shù)據(jù)集進(jìn)行增強(qiáng),能夠有效的提高檢測(cè)目標(biāo)的精度。
目標(biāo)尺度的統(tǒng)計(jì)結(jié)果如圖2所示,圖2(a)給出了目標(biāo)框最長(zhǎng)邊與圖片邊長(zhǎng)的比例,可以看到大多集中在0.04~0.16左右,圖2(b)給出了所有目標(biāo)的面積與圖片面積的比例,大部分集中在0.002~0.008附近。通過(guò)各類比例可以發(fā)現(xiàn),該數(shù)據(jù)集的目標(biāo)基本上都是小目標(biāo),而Yolov5網(wǎng)絡(luò)的先驗(yàn)框是以COCO數(shù)據(jù)集聚類得到的,與本文所使用的數(shù)據(jù)集差異較大,所以本文根據(jù)該數(shù)據(jù)集的特點(diǎn)重新設(shè)定先驗(yàn)框。除此之外,Yolov5的head部分有3個(gè)不同尺寸的檢測(cè)頭,分別用來(lái)預(yù)測(cè)大目標(biāo)、中目標(biāo)以及小目標(biāo),由于本文所使用的數(shù)據(jù)集多為小目標(biāo),所以對(duì)Yolov5進(jìn)行剪枝操作,減少一個(gè)檢測(cè)頭,在參數(shù)量減少的基礎(chǔ)上保持精度不變且提升了檢測(cè)速度。
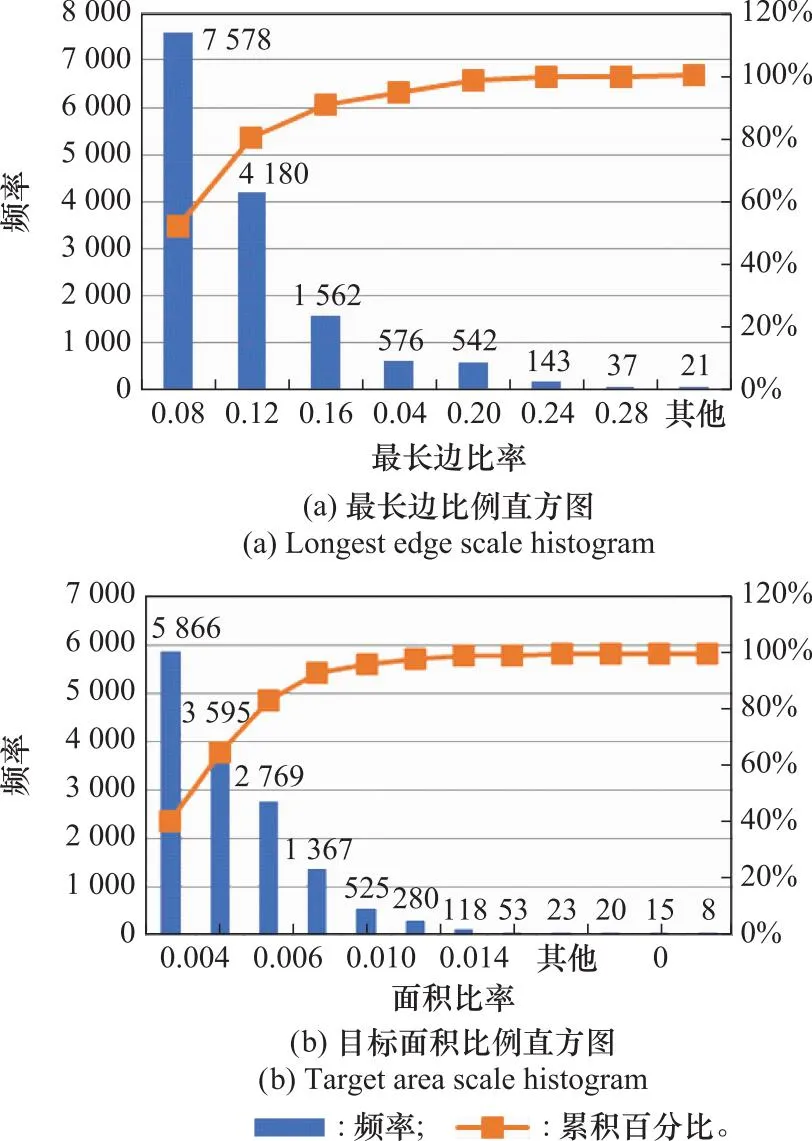
圖2 目標(biāo)尺度分析結(jié)果Fig.2 Target scale analysis results
1.2.2 先驗(yàn)框計(jì)算
由于Yolov1直接計(jì)算目標(biāo)框的方法效率和精度都很低,因此Yolov2基于Fast R-CNN的思想引入了錨框,能夠更好地匹配樣本的尺寸大小。Yolov3和Yolov4都使用了K均值聚類方法來(lái)計(jì)算錨框,而Yolov5將手動(dòng)計(jì)算錨框的方式改為自動(dòng)計(jì)算錨框,并將K均值聚類和遺傳算法相結(jié)合。Yolov5的初始錨框通過(guò)統(tǒng)計(jì)COCO數(shù)據(jù)集的目標(biāo)尺寸獲得,而本文所使用的數(shù)據(jù)集大多為小目標(biāo),與COCO數(shù)據(jù)集的寬高比有較大的差異,因此需要根據(jù)聚類結(jié)果重新設(shè)定初始錨框的大小。原始Yolov5中的聚類方式使用的是傳統(tǒng)的K均值聚類,以歐式距離函數(shù)作為判斷類別是否相近的標(biāo)準(zhǔn)。本文首先嘗試了Yolov5默認(rèn)的聚類方式,由于使用歐式距離函數(shù)會(huì)使得較大的目標(biāo)框比較小的目標(biāo)框具有更大的偏差,因此本文提出利用IoU替換歐氏距離函數(shù),利用IoU作為距離函數(shù)能夠更好地判斷錨框與目標(biāo)框的匹配程度,提高預(yù)測(cè)邊界框的準(zhǔn)確度和精度。
不同聚類方案的結(jié)果如圖3所示,不同的顏色代表訓(xùn)練集中真實(shí)框不同的寬度以及高度分布,五角星分別代表9個(gè)類的中心錨框的高度和寬度分布。從圖3(a)可以看到,IoU K均值聚類方法得到的錨框與訓(xùn)練集真實(shí)框大小的匹配度為85.39%,而圖3(b)中使用傳統(tǒng)的K均值聚類方法得到的錨框與訓(xùn)練集真實(shí)框大小之間的匹配程度為84.23%,平均IoU匹配度提高了1.16%左右。在最小的特征圖上,由于其感受野最大,所以用來(lái)檢測(cè)大目標(biāo),因此大尺度的先驗(yàn)框應(yīng)用在小特征圖上用來(lái)檢測(cè)大目標(biāo),而小尺度的先驗(yàn)框用在大特征圖上用來(lái)檢測(cè)小目標(biāo)。表1給出了特征圖與先驗(yàn)框的對(duì)應(yīng)關(guān)系。本文將傳統(tǒng)的K均值聚類方法替換成IoU-K均值聚類方法,可以有效提高錨框與目標(biāo)框之間的匹配程度,能夠更好的定位目標(biāo),減少損失。

圖3 聚類結(jié)果對(duì)比Fig.3 Comparison of clustering results

表1 先驗(yàn)框尺寸Table 1 Prior box size
1.2.3 選擇性聲吶數(shù)據(jù)擴(kuò)增
深度學(xué)習(xí)網(wǎng)絡(luò)訓(xùn)練過(guò)程中需要大量的數(shù)據(jù)支撐,模型樣本越多越充足,網(wǎng)絡(luò)模型的泛化性就越好,魯棒性越強(qiáng)。本文的數(shù)據(jù)集一共有9 200張,與經(jīng)典的COCO數(shù)據(jù)集以及VOC數(shù)據(jù)集相比,數(shù)據(jù)量遠(yuǎn)遠(yuǎn)不夠,所以本文針對(duì)該數(shù)據(jù)集的特點(diǎn),對(duì)圖像進(jìn)行有選擇性的增強(qiáng)。聲吶圖像通常會(huì)因?yàn)椴ɡ似鸱⑼萧~(yú)傾斜等原因造成回波強(qiáng)度的起伏,導(dǎo)致圖像出現(xiàn)灰度不均的情況[29]。在利用聲吶進(jìn)行水底探測(cè)的過(guò)程中,同一個(gè)目標(biāo)由于探測(cè)角度、船行方向等原因也會(huì)有一定差異,且水下環(huán)境復(fù)雜,聲陰影、混響噪聲以及環(huán)境噪聲等都會(huì)影響聲吶圖像的質(zhì)量。為了增加數(shù)據(jù)量和增強(qiáng)圖像的魯棒性,本文采用平移、旋轉(zhuǎn)、改變亮度、加噪聲、cutout、鏡像等方式隨機(jī)對(duì)圖像進(jìn)行增強(qiáng)。數(shù)據(jù)集按8∶2的比例劃分訓(xùn)練集和驗(yàn)證集,對(duì)訓(xùn)練集進(jìn)行數(shù)據(jù)增強(qiáng),將原訓(xùn)練集的每張圖片進(jìn)行兩次隨機(jī)增強(qiáng),得到新訓(xùn)練集,數(shù)量為原訓(xùn)練集的3倍。數(shù)據(jù)增強(qiáng)的效果如圖4所示。

圖4 數(shù)據(jù)增強(qiáng)Fig.4 Data enhancement
1.2.4 基于Yolov5的輸出分支裁剪
原Yolov5s網(wǎng)絡(luò)中存在3個(gè)目標(biāo)檢測(cè)層,分別對(duì)應(yīng)檢測(cè)大目標(biāo)、中目標(biāo)以及小目標(biāo)。而本文所使用的數(shù)據(jù)集小目標(biāo)居多且不存在大目標(biāo),如果保留大目標(biāo)檢測(cè)層,反而對(duì)小目標(biāo)的檢測(cè)有所干擾。所以本文對(duì)原Yolov5s網(wǎng)絡(luò)中的目標(biāo)層進(jìn)行了刪減,剔除了大目標(biāo)檢測(cè)層如圖5所示。每個(gè)特征檢測(cè)層的每個(gè)網(wǎng)格可以得到3×(5+num) 個(gè)檢測(cè)結(jié)果,其中num為目標(biāo)的類別數(shù)量。

圖5 大目標(biāo)層刪減示意圖Fig.5 Schematic diagram of deleting large target layers
由于20×20大小的特征層下采樣次數(shù)最多,感受野最大,所以用來(lái)檢測(cè)大目標(biāo)。而在不斷下采樣的過(guò)程中,很有可能會(huì)丟失小目標(biāo)的特征信息,因此20×20的檢測(cè)層對(duì)本文所采用的數(shù)據(jù)集檢測(cè)意義不大,所以本文選擇刪除20×20大小的大目標(biāo)檢測(cè)層,網(wǎng)絡(luò)模型的層數(shù)由原來(lái)的283層縮減為現(xiàn)在的201層,每秒10億次浮點(diǎn)運(yùn)算次數(shù)(giga FLOPs, GFLOPs)由16.5減少至14.9,在降低網(wǎng)絡(luò)模型復(fù)雜度的同時(shí),精度較原來(lái)有所提升。
2 實(shí)驗(yàn)與結(jié)果分析
2.1 數(shù)據(jù)集
本節(jié)基于各類模型對(duì)聲吶圖像進(jìn)行目標(biāo)檢測(cè),所使用的數(shù)據(jù)集為2022年全國(guó)水下機(jī)器人大賽的比賽數(shù)據(jù)集,共有9 200張前視聲吶圖像,分別由人體模型、球體、圓籠、方籠、輪胎、金屬桶、立方體、圓柱體、飛機(jī)模型以及水下機(jī)器人10類目標(biāo)組成。對(duì)于各算法的數(shù)據(jù)集劃分,通過(guò)隨機(jī)種子按8∶2的比例劃分為訓(xùn)練集和驗(yàn)證集,針對(duì)訓(xùn)練集的數(shù)據(jù),采用平移、旋轉(zhuǎn)、改變亮度、加噪等方式隨機(jī)增強(qiáng),將原訓(xùn)練集擴(kuò)大了3倍。為驗(yàn)證模型的有效性,本文選取了2021年URPC的比賽數(shù)據(jù)集[30]對(duì)模型進(jìn)行驗(yàn)證,該數(shù)據(jù)集有6 000張前視聲吶圖像,分別由人體模型、球體、圓籠、方籠、輪胎、金屬桶、立方體和圓柱體8類目標(biāo)組成。由于該數(shù)據(jù)集的目標(biāo)也大多為小目標(biāo),且有在航檢測(cè)的需求,所以本文提出的模型對(duì)于該數(shù)據(jù)集同樣適用。
2.2 實(shí)驗(yàn)環(huán)境與模型訓(xùn)練
實(shí)驗(yàn)環(huán)境配置使用Ubuntu16.04操作系統(tǒng),使用NVIDIA GeForce GTX 2080Ti 顯卡,CUDA版本為11.6,Pytorch版本為1.12.1,Python版本為3.8.15。本實(shí)驗(yàn)將epochs設(shè)置為150次,batch_size設(shè)置為8。在訓(xùn)練過(guò)程中,首先將圖像輸入到檢測(cè)器中,Backbone生成特征圖,然后利用Neck對(duì)特征進(jìn)行增強(qiáng)和融合,最后利用Head從特征空間映射到標(biāo)簽空間。計(jì)算預(yù)測(cè)的標(biāo)簽與真實(shí)標(biāo)簽之間的損失,采用隨機(jī)梯度下降(stochastic gradient descent, SGD)對(duì)參數(shù)進(jìn)行更新。
2.3 評(píng)價(jià)指標(biāo)
本文采用平均精度均值mAP來(lái)評(píng)價(jià)各網(wǎng)絡(luò)模型在前視聲吶圖像目標(biāo)檢測(cè)中的性能。平均精度AP由精確率P和召回率R決定,指的是P-R曲線的面積,而mAP代表的是各類目標(biāo)P-R曲線面積的平均值。當(dāng)IoU大于或等于設(shè)置的閾值且類別判斷正確時(shí),那么該預(yù)測(cè)框?yàn)檎_檢測(cè)框TP,隨著IoU指標(biāo)的提升,目標(biāo)檢測(cè)的定位回歸標(biāo)準(zhǔn)就越嚴(yán)格。在本文中,分別采用0.5和0.75的IoU標(biāo)準(zhǔn)來(lái)評(píng)價(jià)網(wǎng)絡(luò)的性能。此外,結(jié)合IoU從0.5變化到0.95的平均mAP值,用以衡量每個(gè)模型的精度。
本文采用GFLOPs來(lái)衡量模型的復(fù)雜度。FLOPs為浮點(diǎn)運(yùn)算數(shù),可以用來(lái)衡量模型的計(jì)算量;而一個(gè)GFLOPs代表每秒十億次的浮點(diǎn)運(yùn)算。GFLOPs越大,模型越復(fù)雜。
2.4 實(shí)驗(yàn)結(jié)果及分析
2.4.1 模型消融實(shí)驗(yàn)
消融實(shí)驗(yàn)經(jīng)常用來(lái)探索某些網(wǎng)絡(luò)改進(jìn)或者訓(xùn)練策略對(duì)網(wǎng)絡(luò)模型性能的影響[31]。針對(duì)本文提出的簡(jiǎn)化網(wǎng)絡(luò)結(jié)構(gòu),基于目標(biāo)框進(jìn)行聚類得到先驗(yàn)框以及數(shù)據(jù)增強(qiáng)3部分改進(jìn)方案,為了驗(yàn)證其有效性,設(shè)置了多組消融實(shí)驗(yàn),實(shí)驗(yàn)結(jié)果如表2所示。

表2 消融實(shí)驗(yàn)結(jié)果Table 2 Results of ablation experiment
(1) 各項(xiàng)改進(jìn)對(duì)網(wǎng)絡(luò)模型的影響
表2第一行是以原Yolov5s網(wǎng)絡(luò)訓(xùn)練得到的結(jié)果,由于數(shù)據(jù)集中都為小目標(biāo),與COCO數(shù)據(jù)集的目標(biāo)大小有較大差異,所以在不改變先驗(yàn)框大小的時(shí)候,檢測(cè)效果一般。雖然本文數(shù)據(jù)集一共有9 200張圖片,但是對(duì)于以數(shù)據(jù)驅(qū)動(dòng)的深度學(xué)習(xí)模型而言,數(shù)據(jù)量還是偏少,所以在劃分完測(cè)試集與驗(yàn)證集以后,對(duì)測(cè)試集進(jìn)行擴(kuò)增,數(shù)量為原測(cè)試集的3倍,對(duì)精度有了一定提升。原Yolov5s網(wǎng)絡(luò)有3個(gè)目標(biāo)檢測(cè)層,分別檢測(cè)大目標(biāo)、中目標(biāo)以及小目標(biāo)。由于本文數(shù)據(jù)集大多為小目標(biāo),所以取消了大目標(biāo)的檢測(cè)層,在不影響網(wǎng)絡(luò)精度的前提下,降低了模型復(fù)雜度,提高了目標(biāo)檢測(cè)速度。
(2) 不同大小網(wǎng)絡(luò)模型的影響
本文還比較了幾種不同深度和寬度的YOLO網(wǎng)絡(luò)的性能,Yolov5m和Yolov5l在一定程度上提高了模型的檢測(cè)精度,但效果并不明顯。由于聲吶圖像的數(shù)據(jù)量有限,更深層次的網(wǎng)絡(luò)并沒(méi)有突出其優(yōu)越的檢測(cè)性能。同時(shí),由于模型的深度和寬度增加,GFLOPs大幅提升,網(wǎng)絡(luò)模型復(fù)雜度增加,檢測(cè)速度進(jìn)一步降低。
(3) 各類模型結(jié)果分析
通過(guò)比較各模型的訓(xùn)練和測(cè)試性能,發(fā)現(xiàn)本文提出的改進(jìn)方案在前視聲吶圖像的目標(biāo)檢測(cè)中表現(xiàn)最好,檢測(cè)精度mAP@0.5、mAP@0.75以及mAP@0.5:0.95分別達(dá)到了0.971、0.585和0.559,與原Yolov5s網(wǎng)絡(luò)模型相比,mAP@0.5提升了0.9%,mAP@0.75提升了5.8%,mAP@0.5:0.95提高了3.1%。由于減少了目標(biāo)檢測(cè)層,網(wǎng)絡(luò)模型復(fù)雜度降低,所以GFLOPs也有所下降。綜上,本文提出的改進(jìn)方案不僅有效提升了檢測(cè)精度,同時(shí)也降低了運(yùn)算量,為后續(xù)基于深度學(xué)習(xí)的聲吶圖像目標(biāo)檢測(cè)提供了一定的參考。
2.4.2 多數(shù)據(jù)集驗(yàn)證
為驗(yàn)證本文算法的有效性,在其他的前視聲吶數(shù)據(jù)集上也進(jìn)行了相應(yīng)的驗(yàn)證,數(shù)據(jù)集來(lái)源于2021年的URPC比賽數(shù)據(jù)集,針對(duì)該數(shù)據(jù)集,以8∶2的比例隨機(jī)劃分訓(xùn)練集與驗(yàn)證集進(jìn)行實(shí)驗(yàn)。各模型的測(cè)試結(jié)果如表3所示。

表3 URPC(2021)數(shù)據(jù)集實(shí)驗(yàn)結(jié)果Table 3 URPC(2021) dataset experimental results
(1) 各類方法對(duì)比
表3第一行是以原Yolov5s網(wǎng)絡(luò)模型訓(xùn)練得到的結(jié)果,與兩級(jí)檢測(cè)模型的代表Faster R-CNN相比有明顯的優(yōu)勢(shì),準(zhǔn)確率比Faster R-CNN高,GFLOPs僅為Faster R-CNN的1/4。由于Faster R-CNN需要先提取候選區(qū)域,所以模型更為復(fù)雜。文獻(xiàn)[32]提出了一種基于Yolov5模型改進(jìn)的聲吶圖像檢測(cè)方法,通過(guò)實(shí)驗(yàn)表明,本文提出的可變尺度先驗(yàn)框模型優(yōu)于文獻(xiàn)[32]的方法。
(2) 各部分改進(jìn)對(duì)比
針對(duì)該數(shù)據(jù)集的目標(biāo)重新進(jìn)行聚類得到先驗(yàn)框,與原Yolov5s網(wǎng)絡(luò)相比,mAP@0.75和mAP@0.5:0.95都有了一定提升,由于mAP@0.5的值已經(jīng)非常高了,所以有一定的波動(dòng)是正常現(xiàn)象。該數(shù)據(jù)集也大多為小目標(biāo),所以針對(duì)網(wǎng)絡(luò)結(jié)構(gòu)部分,也刪減了大目標(biāo)檢測(cè)層。雖然檢測(cè)精度有所下降,但是降低了模型復(fù)雜度,提升了檢測(cè)速度。結(jié)合先驗(yàn)框和網(wǎng)絡(luò)簡(jiǎn)化兩部分的改進(jìn),mAP@0.5達(dá)到了0.979,GFLOPs下降到14.9,與原Yolov5網(wǎng)絡(luò)相比都有了一定提升。實(shí)驗(yàn)結(jié)果表明,針對(duì)類似的數(shù)據(jù)集,本文的改進(jìn)方案具有一定的參考價(jià)值,有良好的泛化性。
3 結(jié)束語(yǔ)
本文根據(jù)聲吶圖像目標(biāo)檢測(cè)的特點(diǎn)以及使用場(chǎng)景,提出了一種基于可變尺度先驗(yàn)框的目標(biāo)檢測(cè)方法。首先,對(duì)于聲吶圖像目標(biāo)較小的問(wèn)題,利用先驗(yàn)統(tǒng)計(jì)重新設(shè)定錨框的大小,有效提高目標(biāo)物的尺度適應(yīng)性,加快訓(xùn)練速度。其次,針對(duì)聲吶圖像數(shù)據(jù)量不足的問(wèn)題,對(duì)圖像進(jìn)行有選擇性的增強(qiáng),豐富訓(xùn)練數(shù)據(jù)集,增強(qiáng)模型魯棒性。最后,為滿足聲吶圖像在航檢測(cè)的需求,通過(guò)刪減大目標(biāo)檢測(cè)層簡(jiǎn)化模型結(jié)構(gòu),在不降低模型精度的條件下加快檢測(cè)速度。
實(shí)驗(yàn)結(jié)果表明,本文提出的改進(jìn)方案檢測(cè)精度最高且模型復(fù)雜度最低,對(duì)聲吶圖像的目標(biāo)檢測(cè)有一定的參考意義。然而由于水下環(huán)境復(fù)雜、噪聲嚴(yán)重,導(dǎo)致聲吶圖像質(zhì)量不高,目標(biāo)邊緣模糊,且存在部分目標(biāo)樣本稀少等問(wèn)題,嚴(yán)重影響了目標(biāo)檢測(cè)準(zhǔn)確率。為了獲得更好的檢測(cè)性能,下一步將開(kāi)展邊緣檢測(cè)、模型壓縮和少樣本學(xué)習(xí)等研究。
猜你喜歡
童話王國(guó)·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2021年6期)2021-11-22 07:50:58
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年12期)2021-01-18 06:57:46
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產(chǎn)業(yè)(2016年3期)2016-05-17 04:32:12
