融合XLnet與DMGAN的文本生成圖像方法
2024-03-05 08:15:28趙澤緯車進(jìn)呂文涵
液晶與顯示 2024年2期
趙澤緯, 車進(jìn), 呂文涵
(寧夏大學(xué) 物理與電子電氣工程學(xué)院, 寧夏 銀川 750021)
1 引言
文本生成圖像是一種跨模態(tài)的研究任務(wù),這中間主要應(yīng)用自然語言處理(NLP)和計(jì)算機(jī)視覺(CV)兩個(gè)研究領(lǐng)域。變分編碼器(VAE)[1]、自回歸模型[2]、生成對(duì)抗網(wǎng)絡(luò)(GANs)[3]等深度學(xué)習(xí)網(wǎng)絡(luò)的引入,為文本生成圖像奠定了基礎(chǔ)。盡管變分編碼器是第一個(gè)通過輸入信息的潛在表達(dá)生成樣本的深度圖像生成模型,但是由于注入噪聲和VAE模型重建不完整,生成的圖像模糊。自回歸生成模型如pixelRNN[4]、pixelCNN[5]和pixelCNN++[6]比VAE更加有效。由于沒有額外的噪聲,pixelRNN需要較長(zhǎng)的訓(xùn)練時(shí)間,并且由于像素值計(jì)算錯(cuò)誤,pixelCNN遺漏了某些像素。為了避免pixelCNN中的盲點(diǎn)問題,piexlCNN++使用層之間的殘留連接。盡管如此,由于圖像的順序(像素到像素)生成,自回歸生成模型缺乏可伸縮性[7]。此后,學(xué)者們使用生成對(duì)抗網(wǎng)絡(luò)GAN生成與真實(shí)圖片相似的圖片。GAN網(wǎng)絡(luò)由生成器和鑒別器兩部分組成。先用生成器生成新的圖片,然后用鑒別器鑒別生成的圖片是生成的圖像還是真實(shí)圖片[3]。在注釋良好的圖像數(shù)據(jù)集上訓(xùn)練的GAN可以生成接近非常真實(shí)的新圖像。GAN要學(xué)習(xí)高度復(fù)雜的數(shù)據(jù)分布,但由于不收斂和模態(tài)坍塌等原因,訓(xùn)練難度較大。Zhang等[8]提出了具有兩級(jí)GAN結(jié)構(gòu)的StackGAN。Stack-GAN中的第一階段是生成低分辨率的只能看出物體大體形狀和顏色的圖像;第二階段對(duì)此圖像進(jìn)行細(xì)化,生成高分辨率圖像。StackGAN++[9]使用多個(gè)生成器和判別器生成256×256的圖片。這兩種GAN網(wǎng)絡(luò)都不以全局句子向量為條件,因此圖像生成缺少細(xì)粒度的單詞級(jí)信息,生成的圖像不能令人滿意。為解決這一問題,Xu等[10]提出了AttnGAN,利用深度注意多模態(tài)相似度模型(DAMSM)和注意力機(jī)制來描繪圖像的局部區(qū)域。雖然這些方法取得了顯著進(jìn)展,但仍存在生成圖像質(zhì)量取決于初始圖像,以及無法細(xì)化輸入句子中每個(gè)單詞描述圖像內(nèi)容的不同層次信息兩個(gè)問題。為此,Zhu等[11]提出了DMGAN,增加一種內(nèi)存機(jī)制處理不良的初始圖片,引入內(nèi)存寫入門,動(dòng)態(tài)選擇與生成圖像相關(guān)的單詞。但是DMGAN的文本編碼器還是使用RNN編碼器,由于RNN的順序性質(zhì),在從單詞嵌入中提取文本語義時(shí),會(huì)忽略一些單詞,導(dǎo)致圖像屬性的損失,使重要信息被省略,最終生成的圖像和文本存在語義不一致的問題。
在圖像生成的同時(shí),文本編碼方法也在日新月異,從最初Uchida等[12]提出的word2vec,簡(jiǎn)單地生成詞向量,到經(jīng)典神經(jīng)網(wǎng)絡(luò)的RNN[13-14]的提出,此網(wǎng)絡(luò)擁有優(yōu)秀的并行能力和雙向提取文本特征能力。Ashish等[15]提出Transformer模型,使用自注意力機(jī)制對(duì)文本信息進(jìn)行編碼。隨后加強(qiáng)版的Transformer即BERT[16]出現(xiàn),將文本進(jìn)行雙向編碼,能夠更好地挖掘文本信息。但是BERT在建模時(shí),過度簡(jiǎn)化了一些高階特征及長(zhǎng)距離token語義依賴。針對(duì)這些問題,Yang等[17]提出XLnet(Generalized Autoregressive Pretraining for Language Understanding)模型,利用XLnet將自回歸模型固定的向前或者向后替換為最大序列的對(duì)數(shù)似然概率期望,使上下文的token都能被每個(gè)位置的token所使用,并使用一種乘積方式來分解預(yù)測(cè)tokens的聯(lián)合概率,繼而消除BERT的token之間的獨(dú)立假設(shè),實(shí)現(xiàn)對(duì)文本信息的進(jìn)一步挖掘。
針對(duì)DMGAN文本編碼階段的不足,引入XLnet編碼器對(duì)文本進(jìn)行編碼,使DMGAN模型在初始階段獲取更多的文本信息,有利于生成更高質(zhì)量的圖片,并在圖像生成的初始階段和圖像細(xì)化階段均加入高效通道注意力[18](ECA)來進(jìn)一步提高生成圖像質(zhì)量。
2 相關(guān)知識(shí)
2.1 DMGAN
DMGAN在AttnGAN的基礎(chǔ)上進(jìn)行改進(jìn),用一種動(dòng)態(tài)記憶模塊替換AttnGAN中注意力機(jī)制,生成更加生動(dòng)形象的圖像。DMGAN體系結(jié)構(gòu)主要有深度注意多模態(tài)相似度網(wǎng)絡(luò)(DAMSM)和圖像生成網(wǎng)絡(luò)。
DAMSM計(jì)算DMGAN模型生成的圖像與輸入文本在單詞級(jí)別上的相似性。訓(xùn)練DAMSM使圖像文本相似度最大化。圖像生成網(wǎng)絡(luò)包含初始圖像生成和細(xì)化圖像兩部分。初始圖像生成階段是指文本通過文本編碼器獲得其語句特征,然后將語句特征和隨機(jī)噪聲融合,再通過一個(gè)全連接層和4個(gè)上采樣層生成初始圖像;圖像細(xì)化階段由記憶寫入、鍵尋址、鍵值讀取和鍵值響應(yīng)4個(gè)部分組成。每次細(xì)化后圖像像素值翻倍,本文最后實(shí)現(xiàn)像素值為256×256的圖像。
2.2 XLnet
XLnet是一種雙向捕獲上下文的自回歸模型。該模型訓(xùn)練句子中對(duì)所有可能的單詞排列,而不是默認(rèn)的從右到左或者從左向右排列。XLnet將BERT雙向編碼的優(yōu)點(diǎn)和LSTMs等序列模型的遞歸函數(shù)結(jié)合,解決了BERT固定句子大小的限制。XLnet將文本視為塊狀,概率預(yù)測(cè)信息在這些塊中傳遞,實(shí)現(xiàn)對(duì)每塊信息的內(nèi)容和位置的預(yù)測(cè)。
2.3 ECA通道注意力機(jī)制
ECA通道注意力機(jī)制是在SE通道注意力機(jī)制上的改進(jìn)。SE通道注意力機(jī)制會(huì)對(duì)輸入特征圖進(jìn)行壓縮,不利于學(xué)習(xí)通道之間的依賴關(guān)系。為了避免降維,ECA通道注意力機(jī)制用一維卷積實(shí)現(xiàn)了局部通道交互,具體操作分以下3步:(1)對(duì)輸入的特征圖進(jìn)行全局平均池化操作;(2)進(jìn)行一維卷積操作,然后用sigmoid函數(shù)進(jìn)行激活得到各個(gè)通道的權(quán)重;(3)將權(quán)重和原始輸入特征圖進(jìn)行相乘操作,得到輸出特征圖。ECA通道注意力機(jī)制示意圖如圖1所示。
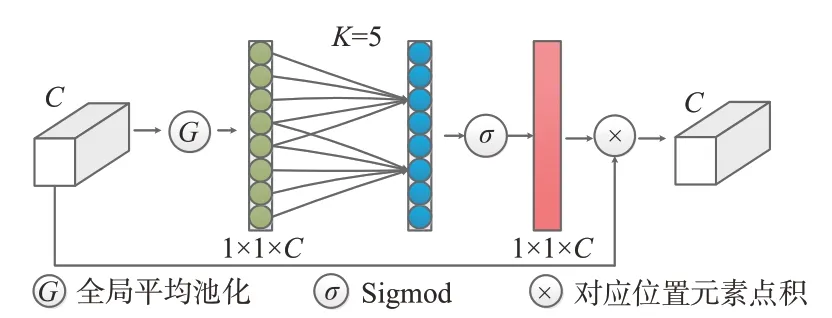
圖1 ECA通道注意力機(jī)制Fig.1 ECA channel attention mechanism
3 網(wǎng)絡(luò)模型
本文提出的XLnet與DMGAN融合模型的結(jié)構(gòu)如圖2所示,黃色區(qū)域?yàn)楦倪M(jìn)部分。首先應(yīng)用AttnGAN[16]模型中的深度注意多模態(tài)相似度網(wǎng)絡(luò)(DAMSM)計(jì)算細(xì)粒度圖像到文本的匹配損失。在訓(xùn)練DAMSM網(wǎng)絡(luò)時(shí),將其原有的編碼器替換為XLnet文本編碼器,圖像編碼器保持不變,計(jì)算DAMSM損失并加入到DMGAN模型的生成器損失中,后續(xù)使用生成對(duì)抗網(wǎng)絡(luò)生成像素為64×64的初始圖像,最后利用動(dòng)態(tài)內(nèi)存將圖像進(jìn)行兩次細(xì)化,分別生成像素為128×128和256×256的圖像。

圖2 XLnet-DMGAN融合網(wǎng)絡(luò)結(jié)構(gòu)Fig.2 Converged network architecture of XLnet-DMGAN
3.1 深度注意多模態(tài)相似度網(wǎng)絡(luò)
文本字詞特征用XLnet文本編碼器提取,圖像特征用inception-v3[19]圖像編碼器提取,將提取到的特征轉(zhuǎn)換到公共空間進(jìn)行訓(xùn)練,表達(dá)式如式(1)所示:
其中:f是局部特征提取矩陣,其維度為768×289,768是局部特征向量的維數(shù),289是圖像中子區(qū)域個(gè)數(shù)是全局特征提取矩陣,其維度為2 048;W是感知層,將圖像特征和文本特征轉(zhuǎn)換到共同語義空間;v和vˉ分別是圖像局部和全局特征向量轉(zhuǎn)化到公共區(qū)域的向量。
字詞特征維度為768×T,768是單詞特征向量維數(shù),T是文本單詞個(gè)數(shù)。首先計(jì)算句子中每個(gè)單詞和圖像中的子區(qū)域的相似矩陣,其表達(dá)式為:
式中:s∈RT×289和si,j是指句子的第i個(gè)單詞和圖像的第j個(gè)子區(qū)域點(diǎn)積相似度,v為圖像局部特征轉(zhuǎn)換到語義空間的向量,e是字詞特征向量。
接著建立一個(gè)注意力模型計(jì)算圖像相關(guān)區(qū)域和句子第i個(gè)單詞的動(dòng)態(tài)表示ci,其具體表達(dá)式如式(3)所示:
其中:vj和αj分別是第j個(gè)圖像子區(qū)域特征和針對(duì)第j個(gè)圖像子區(qū)域的注意力權(quán)重;ci為所有區(qū)域視覺向量的加權(quán)總和,也就是句子第i個(gè)單詞相關(guān)的圖像子區(qū)域的動(dòng)態(tài)特征;γ1為參數(shù)。
然后通過ci和字詞特征e的余弦相似確定第i個(gè)單詞和圖像之間的相關(guān)性,表達(dá)式如式(4)所示
一個(gè)圖像(Q)和其對(duì)應(yīng)的一個(gè)文本描述(D)之間的注意力驅(qū)動(dòng)的圖像-文本匹配得分定義為:
式中,γ2為參數(shù),決定最相關(guān)的單詞到區(qū)域上下文對(duì)的重要性放大多少。
因此,對(duì)于每一個(gè)batch的圖像Qi和文本Di組成的其相匹配的后驗(yàn)概率為:
式中,γ3為實(shí)驗(yàn)確定的平滑因子。在所有句子中,只有Di匹配圖像Qi,其余的M-1字詞都視為不匹配的描述。
字詞級(jí)別的文本匹配圖像損失函數(shù)采用負(fù)對(duì)數(shù)后驗(yàn)概率,其表達(dá)式如式(7)所示:
式中,w為word,即單詞。對(duì)應(yīng)可得P(Di|Qi)的損失函數(shù)如式(8)所示:
將式(5)重新定義為:
3.2 初始圖像生成階段
在初始圖像生成階段,由給定的文本通過文本編碼器生成語句特征向量和字詞特征向量。本文的文本編碼器使用的是新提出的XLnet文本編碼器。語句特征向量s是包含整個(gè)文本語句特征的向量,該向量用于初始圖像的生成。字詞特征是包含單詞個(gè)數(shù)的字詞特征向量,該向量用于提升初始生成圖像的分辨率。文本編碼器編碼得到的語句特征向量s需要先進(jìn)行條件增強(qiáng),首先從語句特征向量s的高斯分布中的到它的平均協(xié)方差矩陣μ(s)和對(duì)角協(xié)方差矩陣σ(s),然后計(jì)算特征向量c0.(c0=μ(s)⊕σ(s)?ε,ε~N(0,1)),再將c0和一個(gè)正態(tài)分布中隨機(jī)取樣的噪聲Z拼接得到進(jìn)行一次全連接操作和4次上采樣操作得到初始特征圖像R0,最后通過ECA通道注意力卷積模塊和一次3×3卷積塊生成初始圖像。
原始的RNN編碼器只能從左向右或者從右向左編碼,這使得從embedding層中提取文本語義的過程會(huì)忽略一些單詞和曲解語句信息,導(dǎo)致圖像屬性的損失。針對(duì)這些問題,提出一種基于XLnet的編碼器的文本編碼器,實(shí)現(xiàn)對(duì)文本信息的深度挖掘。融合XLnet編碼后,整體文本編碼結(jié)構(gòu)如圖3所示。整個(gè)圖像編碼器由5部分組成,分別是輸入、文本預(yù)處理、XLnet預(yù)訓(xùn)練編碼器和輸出。具體實(shí)現(xiàn)細(xì)節(jié)如下:
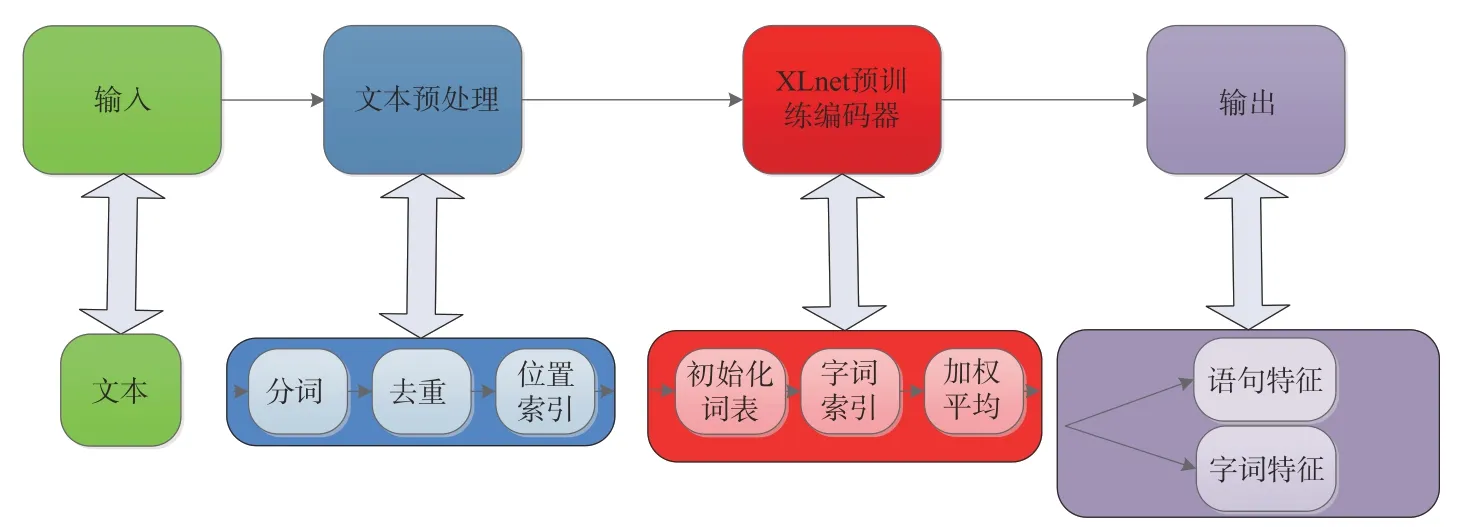
圖3 文本編碼器流程框圖Fig.3 Flow diagram of text encoder
(1)導(dǎo)入pytorch_transformers庫中的XLNet-Model類和XLNetTokenizer類。XLNetModel是PyTorch提供的XLNet模型網(wǎng)絡(luò)結(jié)構(gòu),XLNet-Tokenizer是XLNet模型的分詞工具,存儲(chǔ)模型的詞匯表并提供用于編碼/解碼需要的token embedding。
(2)數(shù)據(jù)預(yù)處理階段:對(duì)讀取的文本進(jìn)行處理,需要用到XLNetTokenizer類中基于SentencePiece構(gòu)造的tokenizer方法,數(shù)據(jù)預(yù)處理方法見算法1。例如文本text=[‘這個(gè)鳥有白色翅膀和白色腹部’],用tokenizer對(duì)句子分詞后得到tokens=[‘這個(gè)’,‘鳥’,‘有’,‘白色’,‘翅膀’,‘和’,‘白色’,‘腹部’]。tokenizer將文本劃分成8個(gè)詞組成的序列,接著對(duì)tokens計(jì)數(shù),返回一個(gè)字典類型的數(shù)據(jù),鍵是元素,值是元素出現(xiàn)的次數(shù),即{‘這個(gè)’:1,‘鳥’:1,‘有’:1,‘白色’:2,‘翅膀’:1,‘和’:1,‘腹部’:1}。接著對(duì)照加載的token embedding詞表找到詞組索引。token embedding是包含實(shí)例化標(biāo)記程序所需的詞匯表,比如“這個(gè)”索引值為3 683,依次類推。

(3)構(gòu)建XLNetModel階段:對(duì)于階段(2)中獲取到的詞組索引token_index,構(gòu)建一個(gè)XLNet模型計(jì)算詞組的字詞向量表達(dá)。XLNetModel是PyTorch提供的XLNet模型網(wǎng)絡(luò)結(jié)構(gòu),構(gòu)建XLNet模型訓(xùn)練字詞向量方法如算法2所示。

對(duì)于構(gòu)造的XLNet模型,初始化其Embedding矩陣shape=(32 000,768),由32 000個(gè)維度為768的特征向量組成。對(duì)于由階段(2)得到的詞組索引,對(duì)照初始化的詞表,根據(jù)索引值查找到其對(duì)應(yīng)的特征向量,最終對(duì)其加權(quán)平均得到XLNet模型訓(xùn)練的字詞向量。
對(duì)于文本text,經(jīng)過XLNet模型對(duì)每個(gè)詞組的上下文內(nèi)容學(xué)習(xí),得到一個(gè)Word Embedding矩陣:shape=(8,768),簡(jiǎn)單理解為將每個(gè)詞語映射到一個(gè)768維的矩陣中。例如“翅膀”經(jīng)過XLNet模型對(duì)其上下文的學(xué)習(xí)得到的字詞特征向量為[-9.515 4e-02,-7.279 3e-02,-2.319 0e-01,…,-3.872 8e-05,-9.983 7e-02,-1.942 1e-04],通過學(xué)習(xí)字詞特征向量及字詞的位置,生成相應(yīng)的語句特征Sentence Embedding,矩陣shape=(1,768)。例如“這個(gè)鳥有白色翅膀和白色腹部”經(jīng)過XLNet模型對(duì)其上下文的學(xué)習(xí)得到語句特征向量為[-8.946 8e-01,-3.181 3e-01,-7.396 6e-01,…,-2.104 8e-02,-6.997 3e-01,-7.210 0e-01],[-9.401 6e-04,3.475 4e-02,1.271 4e-01,…,-4.303 3e-03,6.347 8e-01,-7.069 6e-01],[-2.299 2e-02,2.675 0e-04,-6.227 4e-03,…,-8.204 7e-04,2.669 5e-01,2.899 6e-20],…,[5.412 2e-01,-1.777 2e-11,9.400 5e-01,…,9.603 8e-01,3.736 8e-01,6.806 8e-06],[3.825 3e-04,5.585 0e-05,4.050 8e-01,…,7.618 3e-01,5.420 4e-01,8.125 2e-03],[-7.615 9e-01,-8.309 0e-09,5.942 4e-07,…,5.821 6e-01,4.719 8e-01,-5.940 6e-01]]。
3.3 圖像細(xì)化階段
在圖像細(xì)化階段,將更多細(xì)粒度的信息添加到模糊初始圖像中,生成較上一階段逼真的圖像xi:xi=Gi(Ri-1,W),其中Ri-1為上一階段的圖像特征。細(xì)化階段主要由內(nèi)存寫入、鍵尋址、V值讀取、響應(yīng)和ECA通道注意力5個(gè)部分組成。首先內(nèi)存寫入功能將文本內(nèi)容存儲(chǔ)到鍵值結(jié)構(gòu)化存儲(chǔ)器內(nèi),以便檢索。通過鍵尋址和V讀取操作從內(nèi)存模塊中讀取特征,細(xì)化初始生成圖像質(zhì)量。再采用V響應(yīng)操作控制圖像特征的融合;最后將融合后的特征圖像通過ECA通道注意力加權(quán)融合。細(xì)化階段可以重復(fù)多次(本文重復(fù)兩次)以檢索更相關(guān)的信息,并生成具有更細(xì)粒度細(xì)節(jié)的高分辨率圖像。
3.3.1 動(dòng)態(tài)內(nèi)存
從給定的輸入詞W、圖像x和圖像特征Ri進(jìn)行計(jì)算:
其中:T為單詞數(shù),Nw為單詞特征的維數(shù),N為圖像像素?cái)?shù),圖像像素特征為Nr維向量。
細(xì)化階段包含內(nèi)存寫入、鍵尋址、V值讀取和響應(yīng)。內(nèi)存寫入主要是指對(duì)先驗(yàn)知識(shí)進(jìn)行編碼。內(nèi)存寫入將文本特征經(jīng)過一次1×1卷積運(yùn)算嵌入到n維的記憶特征空間中,具體表達(dá)公式如式(13)所示:
式中,M(· )表示1×1卷積。鍵尋址主要是使用鍵存儲(chǔ)器檢索相關(guān)的存儲(chǔ)器,計(jì)算每個(gè)內(nèi)存插槽的權(quán)重作為內(nèi)存插槽mi和圖像特征ri:
式中:αi,j為第i個(gè)記憶體與第j個(gè)圖像特征之間的相似概率,φK(· )為將記憶內(nèi)存特征映射到維數(shù)Nr的一個(gè)內(nèi)存訪問進(jìn)程,φK(· )表示1×1卷積。V值讀取是指輸出存儲(chǔ)器表示被定義為根據(jù)相似概率對(duì)值存儲(chǔ)器進(jìn)行加權(quán)求和,具體表達(dá)式如式(15)所示:
式中,φV(· )為將內(nèi)存特征映射到維度Nr的值內(nèi)存訪問過程。φV(· )實(shí)現(xiàn)為1×1卷積。在接收到輸出存儲(chǔ)器后,將當(dāng)前圖像和輸出圖像相結(jié)合以提供一個(gè)新的圖像特征。一種簡(jiǎn)單的方法就是單純地將圖像特征和輸出表示連接起來,得到全新的圖像特征,其表達(dá)式如式(16)所示:
式中,[· ,· ]表示拼接操作。然后,利用一個(gè)上采樣塊和幾個(gè)殘留塊,得到一個(gè)較高分辨率的圖像特征。上采樣塊由一個(gè)上采樣層和一個(gè)3×3卷積組成。最后,利用3×3卷積從新的圖像特征中得到細(xì)化的圖像x。
3.3.2 內(nèi)存寫入門
內(nèi)存寫入門允許DMGAN模型選擇相關(guān)的單詞來細(xì)化初始圖像,它將最后階段的圖像特征與單詞特征相結(jié)合,計(jì)算出單詞的重要性,其公式如式(17)所示:
式中:σ是sigmoid函數(shù),A是一個(gè)1×Nw矩陣,B是一個(gè)1×Nr矩陣。結(jié)合圖像和文本特征編寫內(nèi)存插槽mi∈RNm。Mw(· )和Mr(· )表示1×1卷積運(yùn)算。Mw(· )和Mr(· )將圖像特征和字詞特征拼接起來進(jìn)行輸入。
3.3.3 響應(yīng)門
利用自適應(yīng)門控機(jī)制動(dòng)態(tài)控制信息流,更新圖像特征,其表達(dá)式如式(18)所示:
3.3.4 生成器
生成器的目標(biāo)函數(shù)可以表示為:
式中:λ1和λ2分別為條件增強(qiáng)損失和DAMSM損失的權(quán)重,G0表示初始生成過程的生成器,Gi表示圖像細(xì)化階段第i次迭代的生成器。
對(duì)抗損失Gi的定義如式(20)所示:
式中第一項(xiàng)是無條件損失,使生成的偽圖像盡可能真實(shí);第二項(xiàng)是條件損失,使生成的偽圖像匹配輸入的句子。
每個(gè)鑒別器Di的對(duì)抗損失定義為:
式中上半部分為無條件損失,用于將生成的偽圖像與真實(shí)圖像區(qū)分開來;下半部分為條件損失,決定生成的偽圖像與輸入句子是否相符。
條件增強(qiáng)(CA)損失描述了訓(xùn)練數(shù)據(jù)的標(biāo)準(zhǔn)高斯分布和高斯分布之間的KL散度:
式中,μ(s)和∑(s)為句子特征的均值和對(duì)角協(xié)方差矩陣。μ(s)和∑(s)通過全連接層計(jì)算。
DAMSM損失用來衡量圖像和文本描述之間的匹配程度,其相關(guān)理論及公式在2.1節(jié)已詳細(xì)介紹,不再贅述。
4 實(shí)驗(yàn)與結(jié)果分析
4.1 實(shí)驗(yàn)環(huán)境及數(shù)據(jù)集
本文所做實(shí)驗(yàn)的軟硬件環(huán)境如下:系統(tǒng)為Ubuntu 20.04,CPU為Intel(R) Xeon(R) Platinum 8350C,GPU為 GeForce RTX 3090(24G),Cuda版本為11.3,Python版本為3.9,所用的深度學(xué)習(xí)框架為Pytorch。
為了驗(yàn)證DMGAN和XLnet融合的網(wǎng)絡(luò)圖像生成能力,選用CUB數(shù)據(jù)集進(jìn)行實(shí)驗(yàn)。CUB[20]數(shù)據(jù)集中鳥類包含了200個(gè)類別,每個(gè)類別平均約有60張鳥的圖片,共11 788張。使用其中的8 855張圖片進(jìn)行訓(xùn)練,余下的2 933張圖片用于測(cè)試。每張圖片均有10個(gè)描述語句。
4.2 實(shí)驗(yàn)設(shè)置
本文的文本編碼器選用的是xlnet-base-cased模型,設(shè)置其維度為768×300,與DMGAN模型的維度一致。
模型的訓(xùn)練分為兩步:先進(jìn)行DAMSM語義一致性網(wǎng)絡(luò)的訓(xùn)練,訓(xùn)練生成xlnet-rnn-encoder和cnn-encoder兩個(gè)編碼器權(quán)重;然后將訓(xùn)練好的兩個(gè)權(quán)重導(dǎo)入到DMGAN模型中,進(jìn)行DMGAN生成對(duì)抗網(wǎng)絡(luò)的訓(xùn)練。
具體參數(shù)選擇配置如下:優(yōu)化器方面選擇的是Adam優(yōu)化器,學(xué)習(xí)率α=0.000 2,輪數(shù)epochs=800,batchsize=20,參數(shù)λ=5。
4.3 評(píng)價(jià)指標(biāo)
本文采用IS[21](inception score)和FID[22](fréchet inception distance)兩種評(píng)價(jià)指標(biāo)對(duì)實(shí)驗(yàn)結(jié)果進(jìn)行量化評(píng)價(jià)。
IS通過預(yù)訓(xùn)練的inception_v3網(wǎng)絡(luò)表示條件類分布和邊緣類分布之間的KL散度,較高的IS值表示生成的圖像多樣性強(qiáng),圖像品質(zhì)好,而且能明顯鑒別出圖像所屬的類別,其具體的計(jì)算公式如式(23)所示:
式中:x為生成樣本的圖像,y為算法預(yù)測(cè)出的標(biāo)簽;DKL為計(jì)算(P(y|x)和P(y)的KL散度。
FID計(jì)算出生成圖像和真實(shí)圖像之間的Fréchet距離。FID越小,代表生成圖片越接近真實(shí)圖片。其具體的計(jì)算公式如式(24)所示:
式中:μr、μg分別為真實(shí)樣本特征均值和生成樣本特征均值,Tr建立了對(duì)真實(shí)數(shù)據(jù)和生成樣本數(shù)據(jù)之間的協(xié)方差矩陣的求跡。
4.4 結(jié)果分析
4.4.1 指標(biāo)對(duì)比
實(shí)驗(yàn)中,前期DAMSM語義一致性預(yù)訓(xùn)練損失變化曲線如圖4所示。本文可視化了預(yù)訓(xùn)練過程中式(11)的DAMSM loss。得益于XLnet文本編碼器,預(yù)訓(xùn)練的DAMSM語義一致性訓(xùn)練在進(jìn)行到50個(gè)epoch時(shí)已經(jīng)收斂,而原始的網(wǎng)絡(luò)需要到150個(gè)epoch才開始收斂。收斂后,融合XLnet文本編碼器的網(wǎng)絡(luò)損失波動(dòng)幅度小于原始網(wǎng)絡(luò)的損失,說明該網(wǎng)絡(luò)收斂速度快,并且穩(wěn)定性也優(yōu)于原始網(wǎng)絡(luò)。
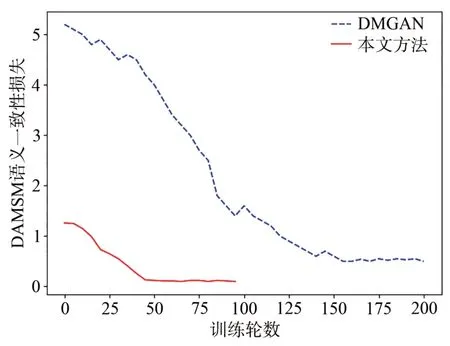
圖4 DAMSM語義一致性訓(xùn)練損失變化圖Fig.4 Loss change graph of DAMSM semantic consistency training
生成網(wǎng)絡(luò)在CUB數(shù)據(jù)集上訓(xùn)練了800個(gè)epoch,生成約3 000張測(cè)試集圖片,量化評(píng)價(jià)指標(biāo)對(duì)比見表1。如表1所示,融合后網(wǎng)絡(luò)模型得到的IS值達(dá)到5.22±0.18,較最初DMGAN模型的IS值4.75±0.07提升了0.47,與其他具有代表性的模型相比,效果也最好。本文所提模型的FID僅為13.31,較最初DMGAN模型的FID值16.09下降了2.78,說明融合后模型生成的圖像在視覺上更加貼近真實(shí)圖片,細(xì)節(jié)處處理得更好。

表1 各項(xiàng)評(píng)價(jià)指標(biāo)對(duì)比Tab.1 Comparison of evaluation indicators
IS值的變化曲線如圖5所示。可以看出在200輪之后,本文所提方法明顯優(yōu)于原始DMGAN模型。FID值的變化曲線如圖6所示,可以看出在520輪之后,本文所提方法明顯優(yōu)于原始DMGAN模型。

圖5 IS值的變化曲線Fig.5 Variation curves of IS value
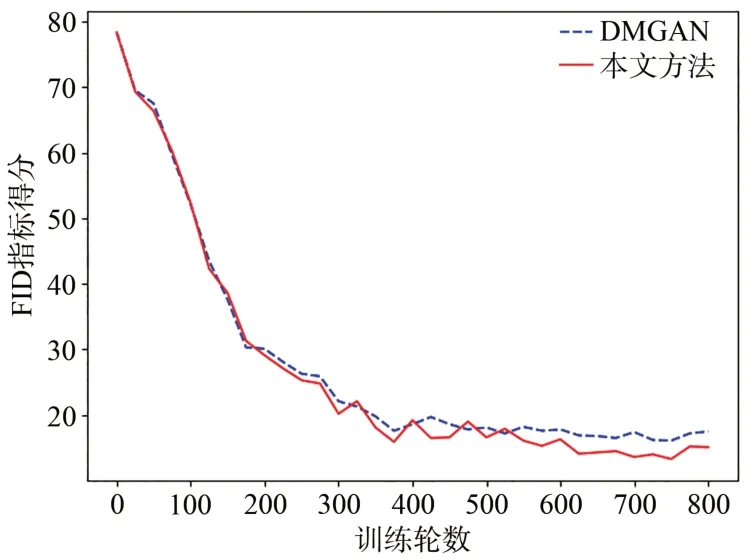
圖6 FID值的變化曲線Fig.6 Variation curves of FID value
由表1、圖5、圖6可以看出,本文利用XLnet編碼器進(jìn)行文本編碼,深度理解文本信息,使得初始階段生成的圖像特征融合了更多的語義信息,后續(xù)模型生成了高保真、高質(zhì)量且語義一致性的圖像。
4.4.2 生成圖像對(duì)比
將本文與幾種具有代表性的文本生成圖像的實(shí)驗(yàn)效果進(jìn)行對(duì)比,參與對(duì)比的網(wǎng)絡(luò)有Stack-GAN、AttnGAN、DMGAN,均使用公開模型且在同一環(huán)境下訓(xùn)練所得結(jié)果。訓(xùn)練測(cè)試結(jié)果如圖7所示。在生成的圖像中,從第一、二列中的測(cè)試結(jié)果可以看出,原始DMGAN模型生成的鳥存在整體、尾部、腳爪的失真;從第三、四列中測(cè)試結(jié)果可以看出,原始DMGAN模型生成的鳥存在空間結(jié)構(gòu)不合理的問題,第三列中的翅膀和第四列中的脖頸均不符合正常鳥的結(jié)構(gòu)。上述問題已用白色橢圓框標(biāo)出。融合XLnet的編碼器后,圖像的語義一致性和整體形態(tài)都有明顯提升。ECA通道注意力專注于生成圖像的空間結(jié)構(gòu)和具體細(xì)節(jié)之處,使得生成的圖像更加符合真實(shí)圖像,圖像的美感也得到了提升,定性地表明了本文所融合模型優(yōu)于原始模型。

圖7 生成圖像對(duì)比Fig.7 Comparison of generated images
為了詳細(xì)分析文本生成圖像的過程,例如文本text=[‘這種鳥是白色和黃色的,有一個(gè)非常短的喙。’],從開始生成的噪聲圖像到第一階段結(jié)束時(shí)的64×64圖像進(jìn)行逐步展示,如圖8所示。圖像細(xì)化工作如圖9所示。為了驗(yàn)證生成圖像的多樣性,圖10使用相同文本描述和多個(gè)噪聲向量生成多個(gè)現(xiàn)狀和背景不同的圖像。

圖8 初始圖像生成細(xì)節(jié)。(a)初始噪聲圖像;(b)經(jīng)過全連接和4個(gè)上采樣之后的圖像;(c)經(jīng)過ECA通道注意力和3×3卷積的初始圖像。Fig.8 Generated details of initial image. (a) Initial noise image; (b) Image after full connection and four upsampling; (c) Initial image after ECA channel attention and 3×3 convolution.

圖9 細(xì)化圖像細(xì)節(jié)。(a)64×64圖像;(b)128×128圖像;(c)256×256圖像;(d)注意力權(quán)重。Fig.9 Refined details of the image.(a) 64×64 image;(b) 128×128 image; (c) 256×256 image; (d)Attention weights.

圖10 相同文本生成圖像展示Fig.10 Generated images from the same text
4.5 消融實(shí)驗(yàn)
為了驗(yàn)證本文所提出的融合模型在文本生成圖像的出色表現(xiàn),本文進(jìn)行了XLnet編碼器模塊和高效通道注意力的消融實(shí)驗(yàn),結(jié)果如表2所示,其中,ECA為圖像生成過程中添加的通道注意力模塊。從表2可以看出,兩個(gè)模塊的結(jié)合得到了最優(yōu)的實(shí)驗(yàn)結(jié)果,驗(yàn)證了兩個(gè)模塊的有效性。

表2 消融實(shí)驗(yàn)結(jié)果Tab.2 Results of ablation experiments
5 結(jié)論
針對(duì)文本生成圖像任務(wù)中語義不匹配、圖像細(xì)節(jié)損失、圖像空間結(jié)構(gòu)不合理等問題,本文提出了一種改進(jìn)的DMGAN模型。首先引入NLP領(lǐng)域中的XLnet模型對(duì)文本進(jìn)行編碼,捕獲上下文內(nèi)容,實(shí)現(xiàn)了對(duì)文本信息的深度挖掘;其次在DMGAN模型的初始圖像生成和圖像細(xì)化兩個(gè)階段均加入高效通道注意力機(jī)制,提高了模型的泛化能力,模型的收斂速度和穩(wěn)定性也得到了大幅提升。最后在公開數(shù)據(jù)集CUB上進(jìn)行了實(shí)驗(yàn)驗(yàn)證,對(duì)比原始DMGAN模型,本文所提模型的IS指標(biāo)提升了0.47,F(xiàn)ID指標(biāo)降低了2.78。結(jié)果表明,改進(jìn)后的DMGAN模型提高了生成圖像的質(zhì)量、增強(qiáng)了生成圖像的多樣性,在文本生成圖像領(lǐng)域具有一定的實(shí)際應(yīng)用價(jià)值,如在行人重識(shí)別方面的應(yīng)用[25]。
在未來的實(shí)驗(yàn)中,可以選擇Transformer中的其他預(yù)訓(xùn)練模型,如預(yù)訓(xùn)練模型超大且擁有1 750億預(yù)訓(xùn)練參數(shù)的GPT-3、輕量化的預(yù)訓(xùn)練模型ALBERT等;選擇更好的生成對(duì)抗網(wǎng)絡(luò),如DFGAN,ManiGAN等做相應(yīng)的融合實(shí)驗(yàn)。上述只是針對(duì)文本編碼器的融合,也可以做圖像編碼器的融合,如將VIT(Vision Transformer)的預(yù)訓(xùn)練模型融合到生成對(duì)抗網(wǎng)絡(luò)中的圖像編碼器中,驗(yàn)證VIT在文本生成圖像這個(gè)下游任務(wù)中是否具有良好的表現(xiàn),也可以同時(shí)將自然語言處理處理中的Transformer預(yù)訓(xùn)練模型和計(jì)算機(jī)視覺中的Transformer預(yù)訓(xùn)練模型一起融合到生成對(duì)抗網(wǎng)絡(luò)中。
猜你喜歡
閱讀(快樂英語高年級(jí))(2020年8期)2020-01-08 02:21:16
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
智慧少年·故事叮當(dāng)(2018年11期)2018-05-14 11:48:18
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
語文知識(shí)(2014年1期)2014-02-28 21:59:13
河南科技(2014年23期)2014-02-27 14:19:15
