基于麻雀搜索算法的GDP增長率預(yù)測模型研究
2024-03-07 05:57:56馬長發(fā)馬子薇
技術(shù)與市場 2024年2期
馬長發(fā),馬子薇
新疆財(cái)經(jīng)大學(xué)統(tǒng)計(jì)與數(shù)據(jù)科學(xué)學(xué)院,新疆 烏魯木齊 830012
0 引言
GDP增長率可以反映出一個(gè)國家的經(jīng)濟(jì)情況,它直接影響國家的宏觀調(diào)控政策,同時(shí)影響金融、非金融公司的有關(guān)決策。如何準(zhǔn)確、高效地對GDP增速進(jìn)行預(yù)測,是值得關(guān)注及深入探討的課題。因此,研究基于統(tǒng)計(jì)數(shù)據(jù)的季度GDP增速高精度預(yù)測方法,揭示其變化規(guī)律,對我國宏觀經(jīng)濟(jì)決策有著重要的現(xiàn)實(shí)意義。
一直以來,國內(nèi)外學(xué)者在對GDP進(jìn)行預(yù)測時(shí),主要采用的是灰色預(yù)測模型、自回歸預(yù)測模型、移動平均法等傳統(tǒng)的時(shí)間序列預(yù)測模型,國外學(xué)者Box et al.[1]在1976年所提出的自回歸移動平均(ARIMA)模型是時(shí)間序列線性預(yù)測的典型代表。國內(nèi)學(xué)者華鵬 等[2]確立ARIMA(1,1,0)模型對廣東省GDP進(jìn)行短期預(yù)測,為政府部門制定經(jīng)濟(jì)計(jì)劃提供了依據(jù)和參考。傳統(tǒng)時(shí)間序列方法要求時(shí)序數(shù)據(jù)穩(wěn)定,并對復(fù)雜的非線性系統(tǒng)擬合能力較差,且易發(fā)生多重共線性,導(dǎo)致預(yù)測精度不夠準(zhǔn)確。近年來,機(jī)器學(xué)習(xí)算法對于體量大、不確定性強(qiáng)的數(shù)據(jù)顯示出了比傳統(tǒng)模型更好的預(yù)測效果,因而被廣泛應(yīng)用于經(jīng)濟(jì)數(shù)據(jù)的預(yù)測。黃卿 等[3]利用機(jī)器學(xué)習(xí)方法中的BP神經(jīng)網(wǎng)絡(luò)、SVM、XGboost算法對滬深300股指期貨進(jìn)行預(yù)測,結(jié)果顯示:3種機(jī)器學(xué)習(xí)方法都有較好的預(yù)測能力,但XGboost的預(yù)測能力更優(yōu)。
傳統(tǒng)的線性建模方法僅僅是根據(jù)已有變量之間的關(guān)系來擬合,其結(jié)果通常與已有的設(shè)定值相差無幾。神經(jīng)網(wǎng)絡(luò)等機(jī)器學(xué)習(xí)算法可以抓住特征之間的非線性關(guān)系,處理特征之間的多重共線性問題,在經(jīng)濟(jì)預(yù)測研究方面有突出的表現(xiàn)。與此同時(shí),集成學(xué)習(xí)算法還有一個(gè)優(yōu)勢,可以對預(yù)測中各特征的重要性進(jìn)行計(jì)算,從而反映出哪些因素驅(qū)動了預(yù)測結(jié)果。故通過集成學(xué)習(xí)方法,從理論上為GDP增長和其他宏觀經(jīng)濟(jì)指標(biāo)的預(yù)測提供了一個(gè)切實(shí)可行的分析工具。因此,本文建立了SVR、GBDT、RFR、Adaboost、XGBoost和LightGBM集成模型,并采用麻雀搜索優(yōu)化算法對模型的重要參數(shù)進(jìn)行調(diào)整,并選取MSE、MAE、可決系數(shù)R2作為模型評價(jià)指標(biāo),通過對比分析選出對于國內(nèi)生產(chǎn)總值增長率具有更好效果的預(yù)測模型。
1 相關(guān)算法原理
1.1 AdaBoost算法
AdaBoost是一種以Boosting算法為基礎(chǔ)的迭代式學(xué)習(xí)算法,最早由Freund和Schapire提出[4]。此算法對Boosting技術(shù)的思想進(jìn)行了很好的傳承,即在每一輪的訓(xùn)練中,AdaBoost會增加被分類錯(cuò)誤的樣本的權(quán)重,從而在下一輪的訓(xùn)練中,弱學(xué)習(xí)器會更加專注于被分類錯(cuò)誤的樣本,從而提高分類準(zhǔn)確率。當(dāng)所有的弱學(xué)習(xí)器集都被訓(xùn)練完畢后,AdaBoost通過加權(quán)多數(shù)票的方式,將多個(gè)弱學(xué)習(xí)器集成為一個(gè)強(qiáng)學(xué)習(xí)器集。
1.2 RFR算法
RFR算法的基本思想是從一組Boot strap sampling隨機(jī)樣本中選擇一組樣本,利用CART模型對每一個(gè)樣本進(jìn)行模型化,再將多個(gè)決策樹的預(yù)測結(jié)果進(jìn)行結(jié)合,得出最后的預(yù)測結(jié)果。該方法是將多個(gè)決策樹的預(yù)測值進(jìn)行簡化平均。可以使誤差均勻化,并明顯提高預(yù)測的準(zhǔn)確性。
1.3 GBDT算法
GBDT算法(gradient boosting decision tree)也被稱為梯度提升決策樹,是一種由多個(gè)決策樹組成的迭代算法,對AdaBoost算法進(jìn)行優(yōu)化和改進(jìn)[5]。GBDT算法可以用于數(shù)據(jù)的分類和數(shù)據(jù)的回歸。在使用GBDT算法進(jìn)行回歸預(yù)測時(shí),先對輸入的樣本數(shù)據(jù)進(jìn)行訓(xùn)練,然后每個(gè)決策樹(較小的,即較淺的樹深)被用來調(diào)整和修改預(yù)測結(jié)果。
1.4 SVR算法
支持向量機(jī)(SVM)是基于統(tǒng)計(jì)學(xué)習(xí)理論中的VC維度理論和經(jīng)驗(yàn)風(fēng)險(xiǎn)最小化原理的一種機(jī)器學(xué)習(xí)方法。支持向量機(jī)回歸(SVR)是在SVM的基礎(chǔ)上發(fā)展起來的,用于解決回歸預(yù)測問題。SVR繼承了SVM良好的泛化能力和泛化力,在很多領(lǐng)域都有很好的表現(xiàn)。
1.5 XGBoost算法
XGBoost(eXtreme gradient boosting)是一種用于監(jiān)督學(xué)習(xí)算法中分類和回歸的極端梯度提升樹算法,由Chen et al.[6-7]在2015年提出。由于GBDT的改進(jìn),XGBoost算法的運(yùn)行速度比傳統(tǒng)梯度算法至少快一個(gè)數(shù)量級,包括并行計(jì)算、近似樹構(gòu)建、內(nèi)存優(yōu)化和稀疏數(shù)據(jù)的有效處理。同時(shí),CPU多線程加速了樹的構(gòu)建,支持多平臺和分布式計(jì)算,并提供了出色的可擴(kuò)展性,以進(jìn)一步提高訓(xùn)練速度。
1.6 LightGBM算法
LightGBM(light weight gradient boosting machine)是一個(gè)常用于競賽的模型,由微軟在2017年首次開發(fā)[8]。它使用Boosting策略提升了模型,也是GBDT的改進(jìn)算法。
1.7 SSA麻雀搜索算法
SSA的靈感來源于麻雀的覓食和反捕食行為[9]。該算法基于仿生學(xué)原理,即麻雀種群在日常覓食中有發(fā)現(xiàn)者、跟隨者和偵察者3個(gè)主要角色。在目標(biāo)優(yōu)化問題中,擬合度的大小反映了每個(gè)麻雀位置所對應(yīng)的可行方案的優(yōu)勢程度。更新麻雀位置的規(guī)則根據(jù)麻雀的適應(yīng)度值而不同。
2 預(yù)測指標(biāo)選取與處理
2.1 指標(biāo)的選取及數(shù)據(jù)來源
本文通過參考相關(guān)文獻(xiàn)[10-12],以宏觀經(jīng)濟(jì)理論中凱恩斯ISLM模型為基本構(gòu)造基礎(chǔ)特征體系。凱恩斯ISLM模型構(gòu)建基礎(chǔ)特征體系從理論上來說,國民收入核算將GDP劃分成四大類。
Y=C+I+G+NX
(1)
其中Y、C、I、G、NX分別代表國內(nèi)生產(chǎn)總值、消費(fèi)、投資、政府購買和凈出口。
由此本文選取一般公共預(yù)算支出檔期同比增長率(X1)、工業(yè)增加值月度同比增長率(X2)、第三產(chǎn)業(yè)增加值當(dāng)期實(shí)際同比增速(X3)、出口額月度同比增長率(X4)、社會消費(fèi)品零售總額月度實(shí)際同比增長率(X5)、居民消費(fèi)價(jià)格指數(shù)(X6)、不變價(jià)國內(nèi)生產(chǎn)總值GDP季度同比增長率(X7)共7個(gè)指標(biāo),數(shù)據(jù)期間為2003年第1季度至2022年第4季度。數(shù)據(jù)均來源于中經(jīng)網(wǎng)統(tǒng)計(jì)數(shù)據(jù)庫。
2.2 特征選擇
在特征選擇中,根據(jù)特征集與目標(biāo)變量以及特征之間的相關(guān)性,從給定的特征集中刪除一些特征,從而選擇出相關(guān)的特征子集,該過程稱為“特征選擇”。
2.2.1 相關(guān)系數(shù)
在對指標(biāo)進(jìn)行相關(guān)分析時(shí),最常用的一種方法是計(jì)算相關(guān)系數(shù),它能夠反映出變量之間的線性相關(guān)程度。其計(jì)算方法如下。
(2)
式中:cov(x,y)表示變量x和y之間的協(xié)方差,δx表示變量x的標(biāo)準(zhǔn)差,δy表示變量y的標(biāo)準(zhǔn)差。
ρx,y絕對值越大,說明相關(guān)性越強(qiáng)。其優(yōu)點(diǎn)是計(jì)算簡單,缺點(diǎn)是只能用來判斷變量之間的線性相關(guān)程度,而無法描述變量間的非線性關(guān)系,即使它們之間的非線性關(guān)系很顯著,相關(guān)系數(shù)仍可能接近0。
圖1的熱力圖直觀地展示了特征之間以及各特征與目標(biāo)變量之間的相關(guān)系數(shù),可以初步分析特征的重要性。圖中顯示,GDP(Y)與工業(yè)增加值(X2)的相關(guān)系數(shù)為0.96,與第三產(chǎn)業(yè)增加值(X3)的相關(guān)系數(shù)為0.95,二者之間的線性相關(guān)程度非常高,說明工業(yè)增加值與第三產(chǎn)業(yè)增加值是影響GDP的重要因素。

圖1 相關(guān)系數(shù)熱力圖
2.2.2 互信息
互信息屬于特征選擇中過濾法方式的一種,它能夠被用來對變量之間的線性關(guān)系進(jìn)行描述,也能夠?qū)Ψ蔷€性關(guān)系進(jìn)行描述,通常既可以用于回歸也可以用于分類算法中。互信息的值越大,說明2個(gè)變量之間的相關(guān)性較強(qiáng)。隨機(jī)變量x與y之間的互信息I(x,y)定義為:
(3)
式中:p(x)、p(y)與p(x,y)分別為隨機(jī)變量x、y各自的邊像概率分布和聯(lián)合概率分布。
利用sklearn.feature_selection中mutual_info_regression函數(shù)可以得到各特征變量與目標(biāo)量的互信息值,對數(shù)據(jù)集中的特征運(yùn)用互信息過濾法篩選。觀察可以發(fā)現(xiàn),大多數(shù)互信息值大于0.1,因此,選取了互信息值大于0.1的特征,經(jīng)過篩選后,最終所選取的特征按互信息值從大到小排序如圖2所示。
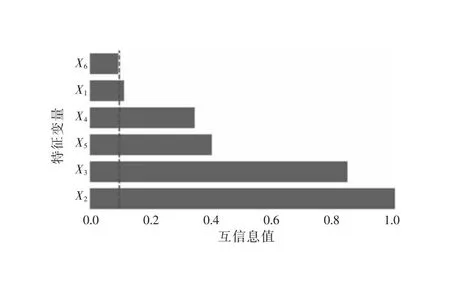
圖2 互信息值
由圖2可知,互信息值小于0.1的變量有居民消費(fèi)價(jià)格指數(shù),因此,在構(gòu)建模型時(shí),為避免特征冗余的情況發(fā)生,選擇將居民消費(fèi)價(jià)格指數(shù)特征剔除,僅將其他剩余變量用于構(gòu)建模型。
3 實(shí)證分析
3.1 數(shù)據(jù)準(zhǔn)備與試驗(yàn)環(huán)境
由本文2.2.2所選取,一般公共預(yù)算支出、工業(yè)增加值、第三產(chǎn)業(yè)增加值、出口總額(美元)、社會消費(fèi)品零售總額共5個(gè)指標(biāo)作為預(yù)測模型的輸入變量(影響因素),GDP作為預(yù)測指標(biāo)。數(shù)據(jù)分析試驗(yàn)在Python 3.8環(huán)境下完成。
3.2 回歸算法選取
本小節(jié)主要采用由Python程序語言設(shè)計(jì)的sklearn框架來構(gòu)建SVR、GBDT、RFR、Adaboost、XGBoost和LightGBM的預(yù)測模型。機(jī)器學(xué)習(xí)回歸算法預(yù)測模型的構(gòu)建大致流程為:特征工程—樣本集拆分—回歸算法選擇—模型參數(shù)調(diào)優(yōu)—模型驗(yàn)證與評估—模型預(yù)測。詳細(xì)步驟描述如下。
1)使用經(jīng)過預(yù)處理后的樣本數(shù)據(jù)作為樣本集,首先將樣本集隨機(jī)劃分成8:2的比例,其中80%的樣本數(shù)據(jù)作為訓(xùn)練樣本集,20%作為測試樣本集,利用pyhton編程語言包sklearn.model_selection中KFlod交叉驗(yàn)證法將樣本集劃分為訓(xùn)練集和測試集,模型的評估指標(biāo)為MSE、MAE和R2。
2)使用缺失參數(shù)建立SVR、GBDT、RFR、Adaboost、XGBoost和LightGBM算法模型。
3)利用麻雀搜索算法對每個(gè)預(yù)測模型進(jìn)行相應(yīng)的參數(shù)尋優(yōu),對預(yù)測模型進(jìn)行優(yōu)化。
4)在此基礎(chǔ)上,對所提出的優(yōu)化算法所修正的模型進(jìn)行誤差分析,并與所修正的模型進(jìn)行比較,最終獲得具有較好預(yù)測效果的機(jī)器學(xué)習(xí)回歸算法。
3.3 麻雀搜索算法
在粒子群算法優(yōu)化過程中,通過群體內(nèi)個(gè)體的信息交換,整個(gè)群體的運(yùn)動在解決問題的空間中產(chǎn)生了從無序到有序的進(jìn)化過程,并由此得到一套參數(shù)最優(yōu)解。在SSA中,每個(gè)麻雀對應(yīng)的位置都可以成為優(yōu)化問題的最優(yōu)解。在目標(biāo)優(yōu)化問題中,擬合度的大小反映了每個(gè)麻雀位置所對應(yīng)的可行方案的優(yōu)勢程度。更新麻雀位置的規(guī)則根據(jù)麻雀的適應(yīng)度值而不同。最優(yōu)模型對應(yīng)的最優(yōu)參數(shù)組合如表1所示。

表1 SSA算法最優(yōu)參數(shù)取值
3.4 模型的優(yōu)選
本文建立了SVR、GBDT、RFR、Adaboost、XGBoost和LightGBM集成模型,并采用麻雀搜索優(yōu)化算法對模型的重要參數(shù)進(jìn)行調(diào)整,最終模型的預(yù)測效果以MSE、MAE和可決系數(shù)R2這3種評價(jià)指標(biāo)來評估。
3.4.1 模型的評價(jià)標(biāo)準(zhǔn)
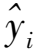
(4)
(5)
可決系數(shù)(R2):用來衡量回歸模型的擬合能力,R2值越接近于1,模型解釋因變量的能力越強(qiáng),即模型擬合效果越好。
(6)
3.4.2 模型優(yōu)選結(jié)果
本文建立SVR、GBDT、RFR、Adaboost、XGBoost和LightGBM集成模型引入麻雀搜索優(yōu)化算法(SSA)對模型的重要參數(shù)進(jìn)行調(diào)整后進(jìn)行GDP增長率預(yù)測,各預(yù)測模型真實(shí)值與預(yù)測值對比如圖3所示。
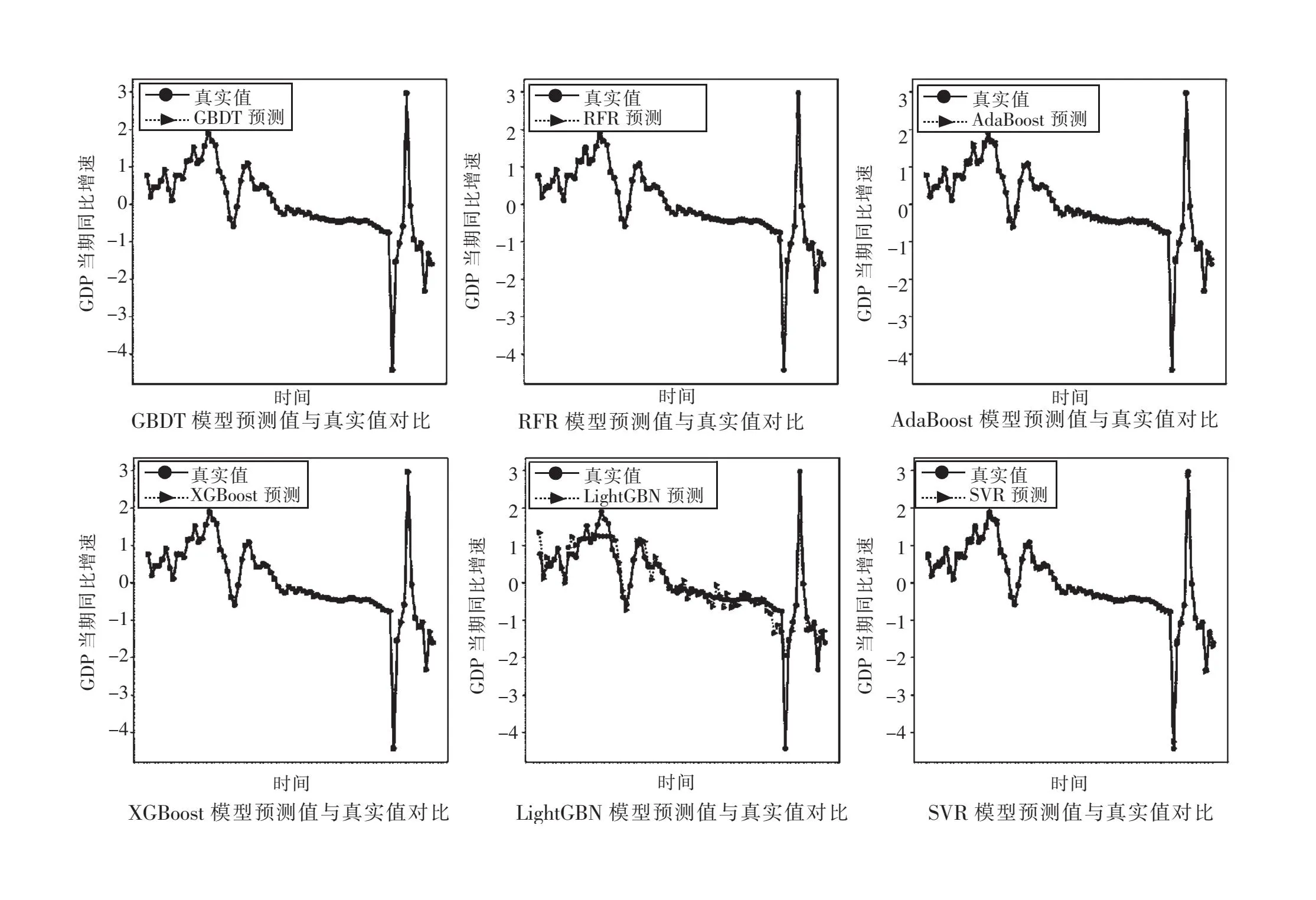
圖3 6種預(yù)測模型真實(shí)值與預(yù)測值對比
由圖3可知,經(jīng)過麻雀搜索算法(SSA)參數(shù)優(yōu)化后的6種模型中,SSA-GBDT模型和SSA-XGBoost模型相較于其他幾種模型預(yù)測更準(zhǔn)確,而SSA-LightGBM模型預(yù)測相對不準(zhǔn)確。為更加清楚地看出各模型預(yù)測結(jié)果,計(jì)算各模型均方誤差(MSE)、平均絕對誤差(MAE)與可決系數(shù)R2,結(jié)果如表2所示。

表2 模型指標(biāo)對比表
結(jié)果顯示:對麻雀算法優(yōu)化后的模型指標(biāo),依據(jù)模型預(yù)測性能的優(yōu)劣情況將其按降序排列:SSA-GBDT、SSA-XGBoost、SSA-RFR、SSA-Adaboost、SSA-SVR、SSA-LightGBM。顯然,與其他模型相比,SSA-GBDT模型具有更優(yōu)的預(yù)測性能,MSE、MAE、R2分別為0.148 6、0.196 3、0.975 1。綜上所述,基于麻雀搜索優(yōu)化算法的GBDT模型預(yù)測性能顯著優(yōu)于其他模型,對于國內(nèi)生產(chǎn)總值增長率預(yù)測具有更好的效果。
4 結(jié)束語
本文以探索季度GDP增長率變化的規(guī)律、尋求高精度預(yù)測季度GDP增長率的方法為目的,基于中經(jīng)網(wǎng)統(tǒng)計(jì)數(shù)據(jù)庫2003年第1季度至2022年第4季度的指標(biāo)數(shù)據(jù),分析我國GDP增長率預(yù)測模型。建立了SVR、GBDT、RFR、Adaboost、XGBoost和LightGBM集成模型,引入麻雀搜索優(yōu)化算法(SSA)對模型的重要參數(shù)進(jìn)行調(diào)整,以MSE、MAE、可決系數(shù)R2作為模型評價(jià)指標(biāo),比較多個(gè)模型的效果,選取具有更高預(yù)測精度的模型,能夠更準(zhǔn)確地預(yù)測GDP增長率。依據(jù)模型預(yù)測性能的優(yōu)劣情況將其按降序排列為SSA-GBDT、SSA-XGBoost、SSA-RFR、SSA-Adaboost、SSA-SVR、SSA-LightGBM,其中,SSA-GBDT模型具有更優(yōu)的預(yù)測性能,MSE、MAE、可決系數(shù)R2分別為0.148 6、0.196 3、0.975 1,說明基于麻雀搜索優(yōu)化算法的GBDT模型預(yù)測對于國內(nèi)生產(chǎn)總值增長率預(yù)測具有更好的效果。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
房地產(chǎn)導(dǎo)刊(2022年5期)2022-06-01 06:20:14
建材發(fā)展導(dǎo)向(2021年12期)2021-07-22 08:06:48
建材發(fā)展導(dǎo)向(2021年7期)2021-07-16 07:07:52
中學(xué)生數(shù)理化(高中版.高二數(shù)學(xué))(2021年12期)2021-04-26 07:43:48
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(bào)(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
