基于改進ADASVM的不平衡財務困境動態(tài)預測模型
2024-03-16 13:39:14李乃文
統(tǒng)計與決策 2024年4期
李乃文,李 慧
(遼寧工程技術(shù)大學工商管理學院,遼寧 葫蘆島 125100)
0 引言
財務困境預測(Financial Distress Prediction,F(xiàn)DP)是財務分析和企業(yè)風險管理領(lǐng)域的重要研究方向。2008年全球金融危機爆發(fā)之后,很多公司都受到了沖擊,陷入了財務困境。因此,F(xiàn)DP 模型作為防范財務風險的有效工具,受到眾多學者的關(guān)注[1]。
FDP 問題的本質(zhì)是統(tǒng)計學中的二分類問題,解決該問題的方法包括數(shù)理統(tǒng)計理論與人工智能模型兩大類[1]。數(shù)理統(tǒng)計理論在FDP 問題常用的模型包括判別分析模型(DA)[2]、邏輯回歸模型(LRA)[3]、因子分析模型(FA)[4]等。其優(yōu)勢在于參數(shù)較少、結(jié)構(gòu)簡單且能提供概率估計。但當變量的正態(tài)性、獨立性等假設(shè)條件不能得到滿足時,模型的有效性會受到極大限制[5]。而人工智能模型不要求任何概率分布假設(shè)就能夠處理非線性系統(tǒng)問題,為財務困境預測領(lǐng)域提供了新的研究思路,已成為該領(lǐng)域的熱點研究方向。近年來,諸多人工智能模型廣泛應用于FDP 問題。包括決策樹模型(DT)[6]、神經(jīng)網(wǎng)絡(ANN)[7]、遺傳算法(GA)[8]、粗糙集(RST)[9]、支持向量機(SVM)[10]和最近鄰方法(KNN)[11]、模糊方法(FCM)[12]等。其中,支持向量機(SVM)在樣本數(shù)相對較小的情況下,也能產(chǎn)生良好的泛化性能,且對非線性和非平穩(wěn)數(shù)據(jù)的擬合表現(xiàn)良好,通常被認為是最有效的財務困境預測基礎(chǔ)算法。近年來,在單一模型的基礎(chǔ)上,越來越多的研究轉(zhuǎn)向FDP 模型的集成方法[13]。其中,Bagging 和Boosting 作為兩種最為流行集成算法,被廣泛應用于FDP 模型的構(gòu)建[10]。
以往國內(nèi)外學者對財務困境預測的研究已經(jīng)取得了豐富的成果,但仍存在許多不足。其中有兩個問題亟待解決:第一,以往的大多數(shù)研究都是基于靜態(tài)數(shù)據(jù)的靜態(tài)模型,忽略了財務數(shù)據(jù)流隨時間推移而引發(fā)的概念漂移問題;第二,雖然有少數(shù)學者研究了財務困境中的概念漂移現(xiàn)象,但大多數(shù)研究采用的是經(jīng)過處理的平衡數(shù)據(jù)集。事實上,財務困境公司占上市公司中的比重很小,數(shù)據(jù)呈現(xiàn)嚴重的不平衡特征,以前的基于靜態(tài)和類別平衡的財務困境預測模型無法與真實情況相吻合,難以對企業(yè)財務狀況作出準確判斷以達到預測預警的效果。
基于上述兩個問題在財務困境預測研究中的迫切需要,本文提出了一種新的面向不平衡數(shù)據(jù)的動態(tài)FDP 模型,即MS-ADASVM-ITW 模型。該模型引入了帶有信息保持期的時間權(quán)重函數(shù)并對ADASVM模型進行改進[14],建立了模型的動態(tài)更新機制,解決了財務困境動態(tài)變化引起的概念漂移問題;同時提出了一種混合采樣方法,與ADASVM 模型耦合,以解決數(shù)據(jù)不平衡問題。通過對1081 家滬深股市上市公司的財務數(shù)據(jù)進行實證分析,驗證本文提出的模型的有效性和穩(wěn)定性。
1 模型構(gòu)建及其改進
1.1 ADASVM-TW模型
Sun 等(2019)[11]提出的ADASVM-TW 模型以ADASVM模型為基礎(chǔ),引入時間權(quán)重函數(shù)用以解決概念漂移問題。其基本思想是數(shù)據(jù)批次的重要性隨時間單調(diào)增加。具體時間權(quán)重函數(shù)如式(1)所示。其中,t表示數(shù)據(jù)批次號,當前數(shù)據(jù)批次號為0,從新到舊,數(shù)據(jù)批次號依次增加;n為數(shù)據(jù)集批次的總數(shù);λ的取值范圍為[0,0.99]。
ADASVM-TW 模型改進了集成訓練分類器迭代過程中的樣本加權(quán)機制,改進的樣本權(quán)重函數(shù)如式(2)至式(5)所示。
其中,U代表ADASVM-TW算法中的迭代總次數(shù),m表示樣本總數(shù)。和分別表示第u+1 次和第u次迭代的第i個樣本的權(quán)重。用于控制樣本權(quán)重值改變方向,分類正確的賦值為1,分類錯誤的賦值為-1,以此降低正確分類樣本的權(quán)重,增加錯誤分類樣本的權(quán)重。此外,αu為由u基分類器的錯誤率eu確定的權(quán)重因子,它也是Adaboost集合的u基分類器的投票權(quán)重。
ADASVM的權(quán)重更新機制是基于誤分率的,而時間加權(quán)的引入則是在誤分率的基礎(chǔ)上加入了時間限制。它可以更加重視樣本的錯誤分類和更新分類,從而提高模型對動態(tài)數(shù)據(jù)流的適應能力,解決了財務困境中概念漂移的問題。
1.2 MS-ADASVM-ITW模型
本文提出的MS-ADASVM-ITW 模型在ADASVM-TW的基礎(chǔ)上引入了帶有信息保持期的時間權(quán)重函數(shù),使得時間權(quán)重的衰減呈梯度指數(shù)衰減,以適應概念漂移的真實變化情況。同時在模型中內(nèi)嵌混合采樣方法,以降低數(shù)據(jù)集的不平衡性。其中混合采樣方法并非直接對原始數(shù)據(jù)集進行采樣,而是在ADASVM 迭代過程中動態(tài)更新樣本。接下來對該模型的兩個重要改進進行詳細描述,并構(gòu)建了模型的整體框架。
1.2.1 基于信息保持期的時序賦權(quán)方法
在財務困境中實際的概念漂移并非是連續(xù)的[15],雖然總體遞減,但遞減的過程是階段性的,這一階段被稱為信息保持期,在這一期間,數(shù)據(jù)中蘊含的信息保持不變。由此,本文引入了基于信息保持期的時間權(quán)重函數(shù)式(6)、非線性指數(shù)遺忘函數(shù)來刻畫信息的衰減程度,其中T'表示信息保持期時間的長短。該函數(shù)能更好地描述財務困境預測中數(shù)據(jù)隨時間的階段性衰減特征。盡管信息整體呈非線性下降趨勢,但在一定時期內(nèi)的影響不會有明顯的改變。
當然,還可以定義其他類型的權(quán)重函數(shù)(如對數(shù)、指數(shù)等)。例如logistic 函數(shù)也常被作為權(quán)重函數(shù)引入,與上文常規(guī)的時間權(quán)重函數(shù)類似,時間權(quán)重的取值范圍為(0,1),衰減系數(shù)的取值范圍為[0,0.99]。圖1為Sun等(2019)[11]提出的時間權(quán)重函數(shù)、logistic時間權(quán)重函數(shù)和帶有信息保持期的時間權(quán)重函數(shù)的樣本加權(quán)機制。經(jīng)過比較發(fā)現(xiàn),在新的時間加權(quán)函數(shù)中增加了信息保持期的概念,相當于在原有的權(quán)重函數(shù)中增加了一個信息基本保持不變的時間窗,從而使其衰減呈指數(shù)梯度衰減,更接近于現(xiàn)實,利用漸進遺忘可以提高對漂移概念的預測精度。
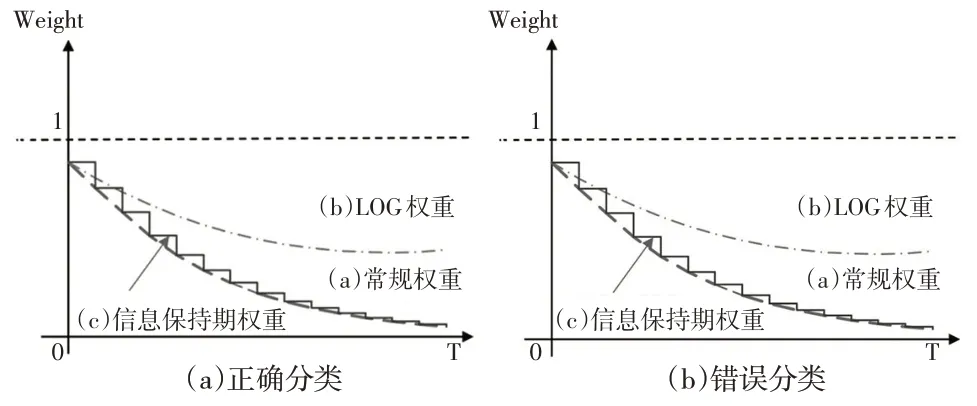
圖1 樣本權(quán)重
1.2.2 混合采樣方法
盡管不斷有新的欠采樣和過采樣方法被提出,但仍然存在相應的缺點。為了彌補兩者的缺點,同時面向財務困境的實際問題,本文基于ADASVM 提出了一種混合采樣方法,在每次迭代提升過程中融合過采樣與欠采樣技術(shù),使得參與訓練樣本的少數(shù)類與多數(shù)類達到平衡。
將采樣技術(shù)與集成技術(shù)相結(jié)合,對不平衡數(shù)據(jù)集進行處理,既保證了數(shù)據(jù)集在數(shù)據(jù)層面的平衡,又通過對集成學習算法的改進,提高了分類效果的可靠性。首先,刪除部分多數(shù)類,去除多數(shù)類中的異常值和邊緣樣本,減少多數(shù)類中的難分樣本。其次,某些類別難以分類的樣本所攜帶的類別信息不足以充分代表少數(shù)類別,采用過采樣方法,合成少數(shù)類樣本,增加少數(shù)類樣本的信息量。再次,將合成的樣本集添加到總體采樣的數(shù)據(jù)集中,通過弱分類器進一步訓練,并重復該過程以獲得最終分類器。最后,提高分類器的分類精度,既保證了少數(shù)類別的識別精度,又不降低多數(shù)類別的識別精度。
1.2.3 模型框架與算法
本文提出的MS-ADASVM-ITW模型,在ADASVM-TW的基礎(chǔ)上引入了帶有信息保持期的時間權(quán)重函數(shù),使得時間權(quán)重的衰減呈梯度指數(shù)衰減,以適應概念漂移的真實變化情況,同時在模型中內(nèi)嵌混合采樣方法,以降低數(shù)據(jù)集的不平衡。其中混合采樣方法并非直接對原始數(shù)據(jù)集進行采樣,而是在ADASVM 迭代過程中動態(tài)更新樣本。先使用欠采樣方法消除訓練集中的多數(shù)類樣本,在分類器的每一輪迭代中,使用上述樣本數(shù)據(jù)集形成弱分類器,再將合成樣本集添加到經(jīng)欠樣本后的數(shù)據(jù)集中,以訓練弱分類器。在樣本權(quán)重更新過程中,引入帶有信息保持期的時間權(quán)重函數(shù)更新樣本權(quán)重。重復該過程得到最終分類器。詳細算法步驟如算法1所示,算法流程圖如下頁圖2所示。
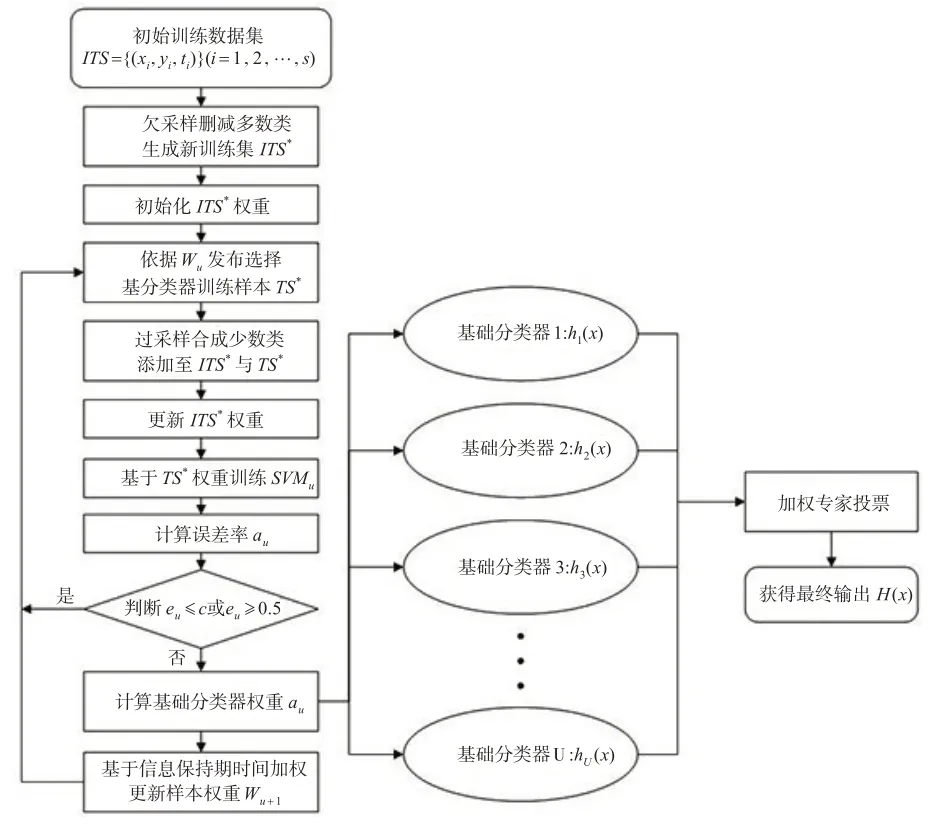
圖2 MS-ADASVM-ITW算法流程圖
算法1:MS-ADASVM-ITW算法。
輸入:帶有時間標簽的類不平衡訓練集ITS={(xi,yi,ti)}(i=1,2,…,S),其中yi?{-1,1}。
初始化:
(1)基于欠采樣方法對ITS訓練集多數(shù)類樣本進行刪減,得到新的訓練集ITS*,樣本數(shù)為N。
(2)初始化ITS*權(quán)重,W1=(w1,1,w1,2,…,w1,N)={1/N,1/N,…,1/N}。
(3)設(shè)定錯誤率閾值。
Foru=1,2,…,U:
(1)從ITS*中依據(jù)分布選擇基礎(chǔ)分類器的訓練集TS*。
(2)基于過采樣方法對TS*中的少數(shù)類樣本進行過采樣,合成m個少數(shù)類樣本,記為Bu,將Bu加入ITS*與TS*中,ITS*訓練集樣本數(shù)量為Nt。
(3)更新ITS*的樣本權(quán)重,更新后的權(quán)重為。
(4)基于TS*訓練一個SVM 基礎(chǔ)分類器SVMu,也可表示為hu(x)。
(5)計算SVMu在訓練樣本TS*的誤差率eu。
(6)判斷,若eu≤c或者eu≥0.5,則刪除結(jié)果返回到(1),u不變,否則到下一步。
(7)計算SVMu分類器的權(quán)重系數(shù)αu=0.5*ln[(1-eu)/eu]。
End
1.2.4 模型評價指標
為評價預測效果,本文選擇Precision、Recall、G值和F值4個評價指標。對于二分類問題,根據(jù)模型預測的結(jié)果與真實類別的對比,可組合劃分為4 種結(jié)果:TP(真陽性)、FP(假陽性)、TN(真陰性)、FN(假陰性)。這4項結(jié)果可以派生出相關(guān)的幾個評價指標。其中,Precision用于評價預測為正類的實例的可信度,Recall用于評價有多大比例的正類實例被正確預測,對于不平衡分類問題,僅使用總體精度來評估分類器的性能是不夠的,因此,本文選取G值與F值對分類性能進行評價。G值可以很好地評估模型對正類與負類樣本的總體分類性能。只有在準確率和召回率都較高時,F(xiàn)值才會較高,可以很好地反映少數(shù)類的分類性能。
在本文中,財務困境表示為正類,財務正常表示為負類。具體的公式如下:
2 實證分析
2.1 實驗設(shè)計
本文的數(shù)據(jù)來源于國泰安CSMAR數(shù)據(jù)庫,以1081家滬深股市的上市公司作為研究對象,以年為基本時間單位,時間跨度為2008—2020 年。選取1081 家上市公司的財務數(shù)據(jù)作為樣本。國內(nèi)學者傾向于將財務困境樣本定義為被進行ST 處理的公司,本文也采用了該定義。FDP的動態(tài)預測是一個增量學習的過程,選取2014 年為基準年,利用2008—2014 年的數(shù)據(jù)構(gòu)建基礎(chǔ)訓練集,考慮到“ST”的評價是由過去連續(xù)兩個會計年度的審計結(jié)果確定的,因此以樣本T-2 年(2008—2012 年)的財務數(shù)據(jù)構(gòu)建特征變量,以樣本第T 年(2014 年)的財務數(shù)據(jù)構(gòu)建標簽。然后以2015—2020 年的數(shù)據(jù)構(gòu)建測試集,隨著時間基準推移,不斷更新訓練集數(shù)據(jù)以構(gòu)建動態(tài)模型,并不斷評價模型的預測效果,動態(tài)預測流程詳見圖3。
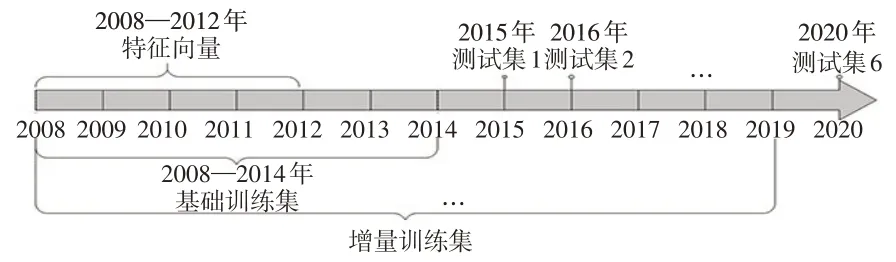
圖3 動態(tài)預測示意圖
本文共設(shè)計了兩個對比實驗,在第一個實驗中,將本文提出的MS-ADASVM-ITW模型與ADASVM經(jīng)典模型以及Sun 等(2019)[11]提出的ADASVM-TW 改進模型進行對比,通過6次移動預測驗證模型對處理不平衡財務數(shù)據(jù)動態(tài)預測的有效性與泛化能力。在第二個實驗中,對模型的混合采樣方式做進一步探索,通過對比不同的過/欠采樣組合,選取適合財務困境動態(tài)預測的采樣方法。本文利用Python編程實現(xiàn)了各類統(tǒng)計學計算、數(shù)據(jù)處理與模型建模以進行仿真實驗。
2.2 指標篩選
基于上市公司財務報表,采用定性選擇與定量相關(guān)分析相結(jié)合的方法對財務指標進行選取。首先,充分借鑒國內(nèi)外研究成果,從償債能力、發(fā)展能力、股東獲利能力、盈利能力、營運能力、現(xiàn)金流量能力6個方面,選取了45個財務指標作為備選原始財務指標,如表2所示。
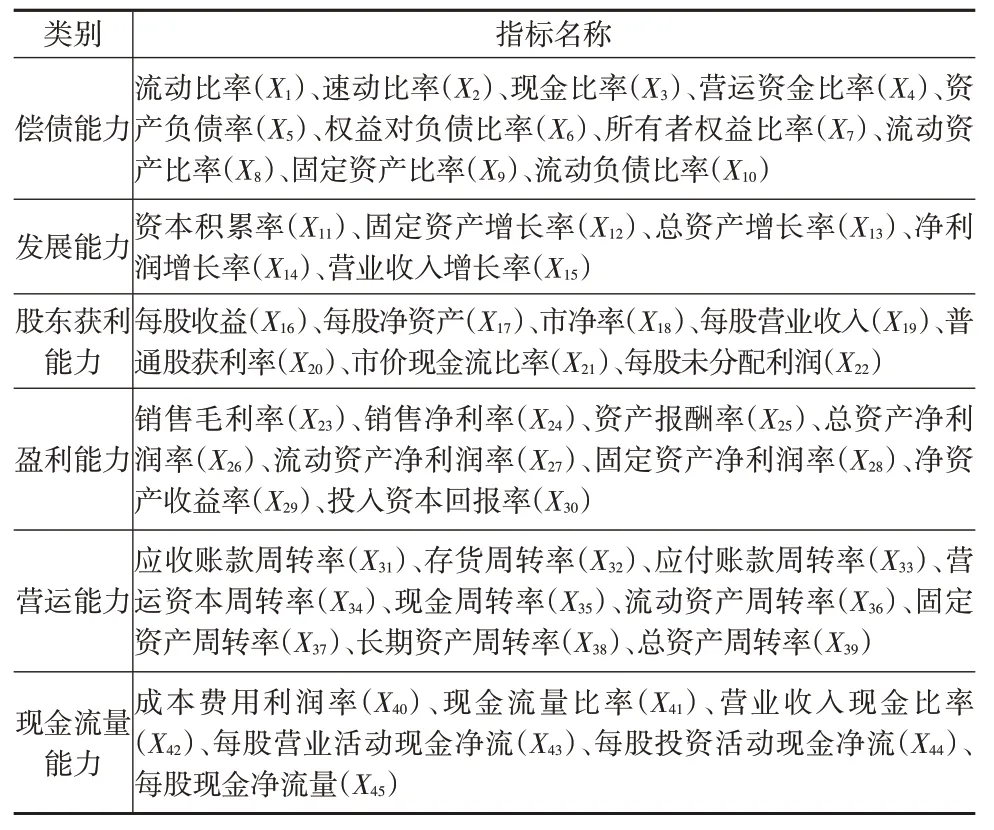
表2 備選原始財務指標
并不是所有財務指標都對財務困境預測模型的構(gòu)建具有現(xiàn)實意義,因此需要對備選財務指標進行降維處理。篩選前必須對數(shù)據(jù)進行預處理,包括補全缺失值和刪除異常值。本文采用序列平均法來填補缺失的數(shù)據(jù)。由于每個企業(yè)的發(fā)展都有所不同,一些公司的財務數(shù)據(jù)表現(xiàn)出極端現(xiàn)象,這種極端現(xiàn)象的財務數(shù)據(jù)的存在可能會影響模型的訓練,因此本文采用三倍標準差法檢測并排除了極值。
為了比較“ST”和非“ST”公司組間財務指標是否具有顯著性差異,要對財務指標進行顯著性檢驗。本文利用Kolmogorov-Smirnov 方法對財務數(shù)據(jù)指標進行了正態(tài)性檢驗。判斷正態(tài)分布的標準是P 值是否超過0.05。經(jīng)檢驗,除了營運資金比率(X4)、資產(chǎn)負債率(X5)、每股營業(yè)收入(X19)、銷售毛利率(X23)、固定資產(chǎn)凈利潤率(X28)、凈資產(chǎn)收益率(X29)、應付賬款周轉(zhuǎn)率(X33)、固定資產(chǎn)周轉(zhuǎn)率(X37)、營業(yè)收入現(xiàn)金比率(X42)和每股營業(yè)活動現(xiàn)金凈流(X43),其余指標都不服從正態(tài)分布。對于符合正態(tài)分布的指標采用Student-t 參數(shù)檢驗方法,不符合正態(tài)分布的指標采用Mann-Whitney U 非參數(shù)檢驗方法。
Mann-Whiney U非參數(shù)檢驗的結(jié)果(略)表明,備選原始財務指標中共12 個指標在不同公司間具有顯著性差異,予以保留,其余指標對財務困境狀態(tài)的敏感度較低,應當從研究范圍中刪去。t 檢驗結(jié)果顯示,在顯著性水平為5%時X5和X29存在明顯差異。根據(jù)以上顯著性檢驗篩選出的指標能夠較好地區(qū)分財務困境公司與正常公司,使得預測結(jié)果更具客觀性,可以進行下一步分析。
為避免出現(xiàn)多重共線性問題,本文采用容差系數(shù)(TOL)和方差膨脹系數(shù)(VIF)進行多重共線性檢驗,剔除容許度(TOL)小于0.1 或方差膨脹因子(VIF)大于10 的指標,最終保留9個對財務困境預測具有明顯統(tǒng)計學意義的指標作為模型的輸入,包括:流動比率、權(quán)益對負債比率、每股收益、每股凈資產(chǎn)、每股未分配利潤、資產(chǎn)報酬率、凈資產(chǎn)收益率、流動資產(chǎn)周轉(zhuǎn)率和總資產(chǎn)周轉(zhuǎn)率。
2.3 結(jié)果分析
基于上文構(gòu)建的評價指標體系,對逐年的預測結(jié)果進行評價。表3列出了各模型2015—2020年的測試精度,其中每個結(jié)果為計算50次試驗的平均值,最后一列為每個模型6 年精度指標的平均值。從Precision指標可以看出,MS-ADASVM-ITW在5個預測年份精度最高,1個預測年份精度居中;ADASVM在4個預測年份精度最低,2個預測年份精度居中,ADASVM-TW在3個預測年份精度居中,1個預測年份精度最高,1個預測年份精度最低,Recall指標也顯示了類似的趨勢。就Precision和Recall的結(jié)果而言,ADASVM 模型整體精度較低,ADASSVM-TW的動態(tài)預測效果明顯優(yōu)于ADASVM 靜態(tài)模型,然而ADASSVM-TW模型穩(wěn)定性較差,MS-ADASVM-ITW 明顯優(yōu)于其他兩個模型。就G值和F值的結(jié)果而言,ADASVM 的精度幾乎都是最低的,顯示其對非均衡數(shù)據(jù)的處理能力較低,MS-ADASVM-ITW 幾乎都是最高的,體現(xiàn)其對非均衡數(shù)據(jù)特別是少數(shù)類的良好預測效果。同時需要注意的是,一般基于不平衡數(shù)據(jù)的采樣方法會在一定程度上犧牲多數(shù)類財務正常樣本的識別能力,以提高對少數(shù)類財務困境樣本的識別能力,而本文提出的混合采樣方法,迭代更新樣本,對多數(shù)類財務正常樣本仍保持較高的識別能力。

表3 逐年預測結(jié)果評價
將三個模型6年的指標均值繪制成柱狀圖(如下頁圖4 所示)。總體來看,本文提出的MS-ADASVM-ITW 模型在四個指標上都是最優(yōu)的,ADASVM 模型的預測效果最差。ADASVM 模型在Precision、Recall、G值三個精度指標上與本文提出的模型相差不大,而在F值上具有較大差異,只有當少數(shù)類別的Precision和Recall較大時,少數(shù)類別的F值才較大,所以它可以準確地反映少數(shù)類別的分類效果,把一個財務困境公司錯分類為財務正常公司的成本,遠比把財務正常公司錯分類為財務困境公司的成本要大得多,本文提出的模型在解決數(shù)據(jù)不平衡問題上具有較大優(yōu)勢。
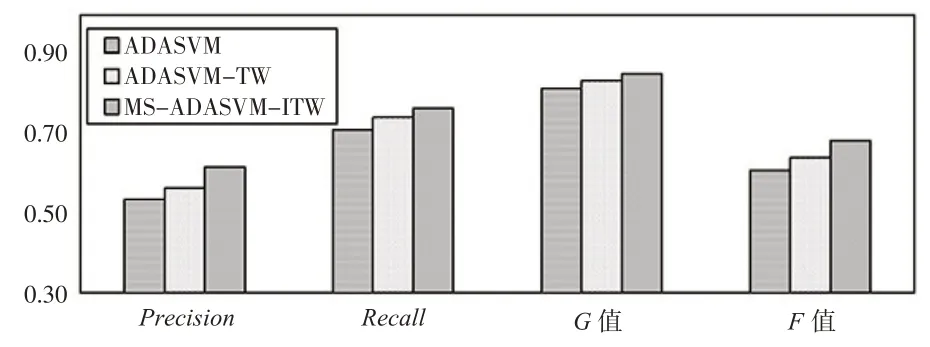
圖4 評價指標均值對比
進一步驗證不同采樣方式組合對改進模型的提升效果。其中欠采樣技術(shù)包括EasyEnsemble、BalanceCascade、Tomek Link 和ENN 四種方法,過采樣技術(shù)包括SMOTE、DBSMOTE、Border-line SMOTE 和ADASYN 四種方法,兩兩組合應用于本文提出的MS-ADASVM-ITW 模型,其中SMOTE+Tomek Link 是上文實驗的基礎(chǔ)組合。表4 和表5為不同組合G值和F值的均值比較結(jié)果。
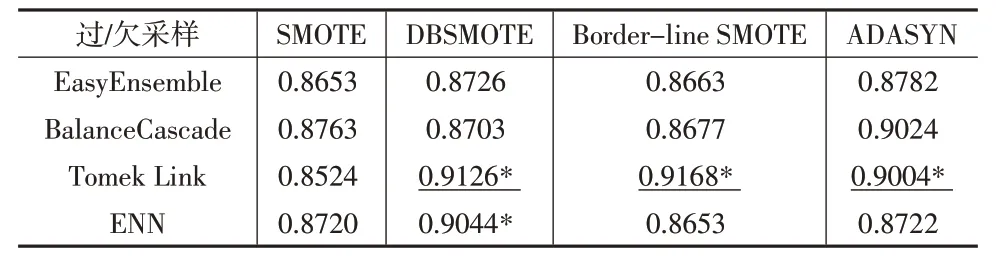
表4 不同采樣組合方式的G 均值
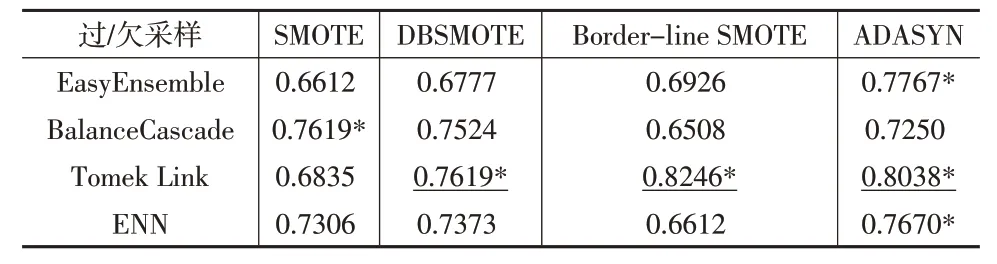
表5 不同采樣組合方式的F均值
從表4和表5的實驗結(jié)果可以看出,本文不同的采樣組合方式對模型性能的提升效果各異。G均值較優(yōu)的組合方式包括DBSMOTE+Tomek Link 組合、Border-line SMOTE+Tomek Link組合、ADASYN+Tomek Link組合、DBSMOTE+ENN 組合和ADASYN+BalanceCascade 組合;F均值較優(yōu)的組合方式包括SMOTE+ BalanceCascade 組合、DBSMOTE+Tomek Link組合、Border-line SMOTE+Tomek Link組合、ADASYN+EasyEnsemble組合、ADASYN+Tomek Link組合、ADASYN+ENN組合;兩個評價指標均高的組合方式包括DBSMOTE+ Tomek Link 組合、Border-line SMOTE+Tomek Link組合和ADASYN+Tomek Link組合,這三種組合方式的欠采樣技術(shù)都包含Tomek Link 方法,可見Tomek Link欠采樣方法對模型性能提升具有較大影響。同時三種組合方式中,Border-line SMOTE+Tomek Link 的組合相對最優(yōu),其G均值為0.9168,F(xiàn)均值為0.8246,相比上文實驗中的基礎(chǔ)組合SMOTE+Tomek Link,G均值提高了7.6%,F(xiàn)均值提高了20.6%,為財務困境預測不平衡數(shù)據(jù)的建模提供了較優(yōu)的解決方案。
3 結(jié)束語
本文考慮到FDP 中數(shù)據(jù)不平衡和概念漂移同時存在的問題,以ADASVM模型為基礎(chǔ),提出了一種新的動態(tài)集成模型MS-ADASVM- ITW。以我國滬深股市1081 家上市公司作為研究對象,通過實驗對比,結(jié)果表明,本文提出的模型具有較高的精度。基于信息保持期的時間權(quán)重函數(shù)動態(tài)更新模型,解決了財務困境中的概念漂移問題,使企業(yè)財務困境建模從靜態(tài)向動態(tài)更新。同時針對不同混合采樣組合方式進行對比,得到Border-line SMOTE+Tomek Link為最優(yōu)組合方式。這表明,分類不均衡導致少數(shù)類型的財務困境樣本缺少足夠的財務信息,使得財務困境預測模型對少數(shù)類型的財務困境樣本的判正率較低,而采用混合采樣的方法可以有效地平衡財務困境和非財務困境的樣本,提高了模型的預測效果。
猜你喜歡
現(xiàn)代企業(yè)(2021年2期)2021-07-20 07:57:18
現(xiàn)代經(jīng)濟信息(2020年34期)2020-06-08 06:02:40
文苑(2020年12期)2020-04-13 00:54:08
意林·全彩Color(2019年9期)2019-10-17 02:25:48
河南水利年鑒(2017年0期)2017-05-19 02:29:27
環(huán)境保護與循環(huán)經(jīng)濟(2017年8期)2017-03-22 01:28:58
環(huán)境科技(2016年3期)2016-11-08 12:14:20
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
