基于自注意力機制與詞匯增強的中文醫(yī)學命名實體識別
2024-03-21 02:25:04羅歆然李天瑞
計算機應用 2024年2期
羅歆然,李天瑞,賈 真
(西南交通大學 計算機與人工智能學院,成都 611756)
0 引言
醫(yī)學命名實體識別(Medical Named Entity Recognition,MNER)是醫(yī)學知識抽取的一項基礎任務,旨在從醫(yī)學文本中識別特定的命名實體,如藥物、疾病、檢查和醫(yī)療設備等。MNER 技術對于醫(yī)學信息的自動化處理和分析具有重要意義,在許多醫(yī)學自然語言處理(Natural Language Processing,NLP)下游任務中發(fā)揮重要的作用,如醫(yī)療信息檢索[1]、醫(yī)學知識圖譜構建[2]和智能醫(yī)療問答系統(tǒng)[3]等。
相較于通用領域的命名實體識別(Named Entity Recognition,NER),MNER 任務存在醫(yī)學實體的復雜嵌套問題,例如:疾病實體“大腸桿菌腸炎”內(nèi)層嵌套了部位實體“大腸”、微生物實體“腸桿菌”“桿菌”,疾病實體“腸炎”,實體內(nèi)部嵌套的多層實體使MNER 在眾多序列標注文本中難以探測實體邊界信息。在將醫(yī)學實體映射到特征向量空間時,由于存在未登錄詞(Out-Of-Vocabulary,OOV)的問題,無法得到含有醫(yī)學語義信息的向量。比如,“十二指腸潰瘍”可能會被切分,其中“十二”被作為數(shù)字映射到數(shù)字特征向量空間,從而造成語義偏差。MNER 的實體嵌套和語義偏差問題來自實體邊界難以正確劃分和缺乏醫(yī)學相關的語義知識。因此,MNER 需要結合醫(yī)學領域的語言特點和先驗知識,采用合適算法提高實體識別的準確性。與英文不同,中文文本序列由單個字符構成,通過標點符號劃分句子語義,缺乏分割單詞的清晰邊界和帶有語義信息的單詞詞干。因此,從輸入表示的角度,中文NER 可分為基于分詞的方法、基于字的方法和基于字詞的方法。基于分詞的方法[4-5]先使用分詞工具將句子分割為單詞,再將這些序列進行實體識別,但分詞錯誤會積累大量噪聲,不適合中文MNER 任務高精度的需求;基于字的分割方法[6-7]雖然性能較好,但缺少單詞附帶的整體語義信息,當面對醫(yī)學領域的復雜嵌套實體和未登錄的專業(yè)術語時,該類方法的泛化能力還有待提升。
針對上述中文NER 的限制,Zhang 等[8]首次提出了將詞匯信息集成到字符序列中的柵格結構(Lattice-LSTM)。如圖1 所示,該結構將一個文本序列與一個單詞詞典匹配,通過拓展長短期記憶(Long Short-Term Memory,LSTM)網(wǎng)絡,使用額外的通路連接潛在單詞的開始與結尾字符之間的存儲單元。柵格結構為中文NER 帶來顯著的效果提升,在單個字符中融合與該字符有關的潛在單詞可以豐富字符的語義特征,有效緩解單詞邊界難以探測的問題,有利于醫(yī)學文本中復雜嵌套實體的識別。但也存在一些不足:1)柵格結構為有向無環(huán)圖的拓展,且不同字符之間添加單詞節(jié)點數(shù)不一致,限制了每次只能處理一個字符,模型無法在GPU(Graphics Processing Unit)中并行化計算。2)由于LSTM 的單向順序性,每個字符只能獲取以它作為結尾的單詞信息,對于單詞內(nèi)部的字符不具備詞匯信息的持續(xù)記憶能力,造成嚴重的信息損失。

圖1 Lattice-LSTM的結構Fig.1 Architecture of Lattice-LSTM
以圖1 為例,柵格結構將單詞信息“血栓栓塞”編碼到“塞”中,但是對于“血”“栓”“栓”這3 個內(nèi)部字符卻無法有效獲取單詞信息,而“血栓栓塞”的語義和邊界信息對這3 個字符正確識別為B-SYM、B-SYM 和M-SYM 標簽起到重要的輔助作用;同時,柵格結構中某些單詞對中文NER 任務無效,這些需要被抑制的單詞信息通常與上下文相關,如文本序列中的單詞“血栓栓塞”能區(qū)分“靜脈血”不是實體,而“靜脈”是標簽為PAR 的實體。3)柵格結構只適配于LSTM 結構,可遷移性差。
受文獻[9-10]中將柵格結構的輸入集成到Transformer[11]結構的啟發(fā),針對中文醫(yī)學文本的語言特點和柵格結構的不足,本文提出一種融合注意力機制的自適應詞匯增強模型AMLEA(Attention-based Model of Lexicon Enhanced Adaptively),通過基于雙線性注意力(Bilinear Attention)機制的詞匯適配器(Lexicon Adapter,LA)將詞匯信息集成到文本序列中的每個字符中,并使用自注意力(Self-Attention)機制編碼詞匯適配器中不同單詞之間的信息交互。本文的主要工作如下:
1)將基于有向無環(huán)圖的柵格結構轉換為線性的字詞對序列(Charactor-Word Pair Sequence),并利用Transformer 結構中全連接的自注意力機制對序列中的不同詞匯輸入單元建立依賴關系,使每個字符所匹配的不同單詞之間直接交互信息,以抑制無效單詞并激活具有邊界和語義信息的單詞。
2)在詞匯適配器中設計雙線性注意力為每個字符動態(tài)計算不同潛在單詞的權重,提取相關程度高的匹配詞修正字符向量的語義偏差,提高中文醫(yī)學命名實體識別的性能。
3)設計AMLEA 與各基線模型的對比實驗,實驗結果表明,所提模型可以有效緩解中文MNER 中實體嵌套和未登錄詞識別歧義的問題,同時將預訓練模型BERT(Bidirectional Encoder Representation from Transformers)[12]用 于AMLEA 的字符編碼,顯著提高模型的識別精度。
1 相關工作
NER 的研究方法包括基于規(guī)則和字典的方法、基于傳統(tǒng)機器學習的方法和基于深度學習的方法。其中,基于深度學習的方法[13-14]是目前主流的研究方向。本文模型主要研究如何將詞匯信息高效、準確地作為先驗知識集成到字符中以緩解中文MNER 的實體嵌套和OOV 問題,所以分別介紹了基于字詞的中文NER 和MNER 的相關研究。
1.1 基于字詞的中文命名實體識別
單詞中的邊界和語義信息能有效增強基于字的中文NER 模型,將詞匯信息集成到字符信息的主流方法主要有兩類。
第一類方法是在動態(tài)的柵格結構中融合詞匯信息。Zhang 等[8]在LSTM 結構中增加了一個額外的詞匯存儲單元對潛在的單詞進行編碼,巧妙地將詞匯信息與字符嵌入兼容;Gui 等[15]提 出LR-CNN(CNN-based Chinese NER with Lexicon Rethinking)模型,采用卷積神經(jīng)網(wǎng)絡(Convolutional Neural Network,CNN)解決LSTM 無法并行計算的問題,通過Rethinking 機制緩解模型中高層詞匯沖突的情況;Li 等[10]設計了一種將相對位置編碼和詞匯信息融合至Lattice 的結構,并利用Transformer 實現(xiàn)了GPU 的并行計算。這類方法通常可遷移性較差,并且受制于柵格結構的特殊性,不能充分利用詞匯信息,導致大量詞匯表征損失。
第二類方法是將柵格結構轉換成圖結構,并使用圖神經(jīng)網(wǎng)絡(Graph Neural Network,GNN)編碼。Gui 等[16]提出了一種基于GNN 的詞級特征融合方法,利用圖網(wǎng)絡攜帶的全局信息捕獲字符之間的非順序依賴關系,采用遞歸聚合機制解決中文單詞識別歧義的問題;Sui 等[17]提出了基于協(xié)作的圖網(wǎng)絡(Collaborative Graph Network,CGN),結合三種模式的圖注意力網(wǎng)絡(Graph ATtention network,GAT)提取特征,解決Lattice-LSTM 無法獲取詞匯內(nèi)部信息而造成的特征損失問題。然而,序列結構對中文NER 任務有著重要的支撐作用,因此這類圖網(wǎng)絡通常需要LSTM 作為底層編碼器感應時序信息,模型結構較復雜,并且圖構建也需要耗費大量計算資源。
1.2 醫(yī)學命名實體識別
在MNER 領域中,Li 等[18]利用Lattice-LSTM 融合詞匯信息,并增加嵌入語言模型(Embeddings from Language Models,ELMo)學習電子病歷中的上下文信息;Ju 等[19]通過動態(tài)疊加扁平NER 層,用學習到的內(nèi)層實體信息更新外層實體的識別,以此解決醫(yī)學實體嵌套的復雜問題;羅凌等[20]將漢字的筆畫序列輸入ELMo 改進字符輸入特征單一的問題,然后構建基于多任務學習的網(wǎng)絡充分利用數(shù)據(jù)信息;Xu 等[21]采用一種有效的字符串匹配方式將疾病字典和疾病字符配對,提出了一種結合字典注意力層的BiLSTM-CRF(Bi-directional Long Short-Term Memory-Conditional Random Field)模型;吳炳潮等[22]利用BiLSTM-CRF 網(wǎng)絡識別跨領域共享的實體塊信息,再通過基于門機制的動態(tài)融合層將源領域的信息集成于目標領域的共享實體塊,并在CCKS 2017 數(shù)據(jù)集上驗證了模型的有效性;Li 等[23]提出了一種融合詞匯和字根特征的BERT-BiLSTM-CRF 模型,利用BERT 模型增強中文臨床記錄文本的上下文語義信息;文獻[24]中將字向量輸入雙向門控循環(huán)單元(Bi-directional Gated Recurrent Unit,BGRU),學習上下文特征,再利用注意力機制捕獲關鍵語義表征,與本文不同的是,該方法沒有引入詞匯信息等外部知識,注意力僅用于字向量的特征提取,沒有利用雙線性注意力賦予詞匯相應的權重。以上結合BiLSTM-CRF 的模型并沒有利用BiLSTM(Bi-directional Long Short-Term Memory)對字符編碼的上下文特征交互詞匯信息或是直接采用Lattice-LSTM 結構,融合詞匯的方式容易引入大量噪聲,降低了MNER 模型的識別性能。
本文提出的AMLEA 在不影響原字符序列結構的情況下,在充分利用詞匯信息的同時能抑制與字符無關的詞匯,很好地克服了現(xiàn)有詞匯融合模型中的不足,并且所提模型便于根據(jù)不同的醫(yī)學細分領域選擇合適的詞典進行自動匹配,與現(xiàn)有的預訓練模型BERT[12]也能很好地兼容,從而提升了模型面對海量復雜醫(yī)學文本的魯棒性。
2 模型構建
本文提出的中文醫(yī)學命名實體識別模型AMLEA 的總體架構如圖2 所示,該模型由特征表示、特征編碼和標簽解碼三部分組成。首先,將字嵌入輸入BiLSTM層學習醫(yī)學文本中字符序列的上下文特征;然后,將輸出的字符向量與經(jīng)過自注意力層的詞匯向量組成字詞對序列并輸入詞匯適配器,實現(xiàn)字詞信息的融合并得到隱藏層輸出;最后,將隱藏層的輸出輸入到CRF(Conditional Random Field)解碼層進行序列標注。

圖2 AMLEA的總體架構Fig.2 Overall architecture of AMLEA
2.1 字符編碼層
LSTM 是循環(huán)神經(jīng)網(wǎng)絡(Recurrent Neural Network,RNN)的一種變體,為了解決RNN 在反向傳播時帶來的梯度消失和梯度爆炸問題,以及難以建模句子中的長距離依賴關系的問題,在RNN 的基礎上增加了門控單元控制信息的更新、存儲和傳遞。
LSTM 由3 個門控單元和1 個記憶單元ct構成,門控單元分別為遺忘門ft、輸入門it和輸出門ot,具體的計算過程如式(1)~(6)所示:
其中:Wx、Wh、b是需要學習的網(wǎng)絡參數(shù),σ表示激活函數(shù)Sigmoid,Xt表示當前時刻的輸入向量,遺忘門ft控制上一時刻的記憶單元ct-1需要遺忘的信息總量,輸入門it控制當前時刻的候選狀態(tài)應該存儲的信息量,輸出門ot控制當前時刻的記憶單元ct需要向外界輸出多少信息。
但是LSTM 只能獲取句子單向的字符序列,即t時刻的字符能學到t-1 時刻字符攜帶的語義信息,但t-1 時刻的字符不能學習后文段落的信息。為了提取文本的上下文特征,本文采用BiLSTM 編碼字符向量,它由前后雙向的鏈式LSTM 結構組成,最后拼接兩個LSTM 單元的前向和后向隱藏層輸出信息。在t時刻BiLSTM 的隱藏層狀態(tài)為ht=,嵌入后的字向量經(jīng)過BiLSTM 編碼后可以得到維度為的輸出向量其中dm為單個LSTM 的隱藏層神經(jīng)元個數(shù)。
2.2 注意力機制
當一個滑動窗口包含多個單詞時,若采用全連接的神經(jīng)網(wǎng)絡學習它們的特征,會使參數(shù)的學習變得異常復雜。注意力機制可以將文本序列進行特征降維,然后編碼為固定長度的向量,以便輸入后續(xù)的全連接層。注意力機制通過計算句子中每個字符的權重給予模型針對性的學習指導,給出了3個計算參數(shù)查詢Q、鍵K和值V。這3 個參數(shù)由輸入向量X與矩陣W相乘得到,通過對X的線性變換加強模型的擬合能力,從而訓練矩陣W,使模型學到更多該文本序列的語義信息。
注意力函數(shù)的計算如式(7)所示,計算過程可以總結為3 步。首先,將嵌入層的輸出向量X分別與維度為dk的矩陣W做乘積運算,得到3 個參數(shù)Q、K和V。然后,將Q和K相乘計算兩者的相關性,經(jīng)過Softmax 歸一化處理后得到注意力矩陣;除以的目的是降低字符間的權重方差,避免訓練過程中因權重較小造成的梯度消失問題。最后,根據(jù)得到的權重對V加權求和,得到具有混合關系的向量表示。
詞匯間利用注意力機制進行信息交互的過程如圖3 所示,其中字母A、B、C 分別為單詞“甲肝”“肝病”“甲肝病”的向量表示,圖中計算以“甲肝”為例,展示了該單詞與匹配到字符“肝”的潛在單詞間的權重關系,從而建模詞與詞之間的依賴關系。多頭注意力機制(Multi-Head ATTention mechanism,MH-ATT)實質上是多次計算單頭注意力機制,然后將其結果進行拼接,目的是學習向量在不同語義空間的表示。面對復雜的醫(yī)學文本,需要對某一特征進行多維度的學習,不同的注意力矩陣使模型從多個角度理解文本信息,賦予模型更深層次的句意理解。

圖3 自注意力計算過程Fig.3 Computational process of self-attention
2.3 字詞對序列
由于中文的特殊性,一個句子通常由單個字符序列構成,為了給每個字符融入詞匯信息,本文將字符和它匹配的詞匯組成一個如圖4 所示的字詞對序列。

圖4 字詞對序列Fig.4 Character-word pair sequence
本文中字詞對序列的構建過程為給定一個字符數(shù)為n的中文句子sc={c1,c2,…,cn}以及中文詞典D,通過將字符序列與詞典D進行匹配,搜索句子中所有潛在單詞。具體地,本文利用詞典D構建了單詞前綴樹(TrieTree),然后遍歷句子中所有的字符子序列,通過前綴樹查找對應的字符子序列,將潛在的單詞歸納至每個字符。如圖4(a)所示,對于一個字符子序列“甲肝病毒”,可以匹配到4 個潛在單詞:“甲肝”“甲肝病”“肝病”和“病毒”。接著,將每個匹配到的單詞分配給它所包含的每個字符,如單詞“肝病”會被分配給組成該單詞的字符“肝”和“病”。本文將第i個字符ci匹配到的所有單詞構建成單詞序列wsi={wi1,wi2,…,wim},其中m=4 表示單詞序列的窗口大小,用特殊值“填充長度不滿m的單詞序列。最后,組合每個字符和其指定的單詞序列,將中文句子轉換為一個字詞對序列scw={(c1,ws1),(c2,ws2),…,(cn,wsn)}。
2.4 詞匯適配器
對于字詞對序列scw,每個位置都包含字符級特征信息和單詞級特征信息。與現(xiàn)有的多信息融合模型一致,本文的目標是將詞匯信息融入字符。受近期關于對預訓練模型BERT[12]進行多模態(tài)信息融合研究[25-26]的啟發(fā),在中文大規(guī)模語義建模過程中,通過在字符編碼中設計一種適配器融入詞匯、字形、拼音和偏旁部首等多元特征,在預訓練過程中能對不同領域的文本進行有效的信息增強。本文利用詞匯適配器直接將每個單詞序列的詞匯信息注入它對應的字符。
詞匯適配器以一個字符和匹配的單詞序列作為輸入,對于下標位置為i的字詞對(ci,wsi),本文將字符和單詞序列中的每個單詞通過嵌入層獲取字向量和詞向量并記為其中表示詞向量的集合,字向量以及潛在單詞序列中第j個單詞的詞向量的計算如式(8)和式(9)所示:
其中ec(?)和ew(?)分別表示預訓練的字向量和詞向量查詢表。
如圖4(a)所示,對于一個字符,在特定的上下文環(huán)境中可能與多個單詞匹配,然而不同單詞提供的語義和邊界支持通常有著較大差異,如單詞“甲肝”和“病毒”的重要性更高,圖中標紅虛線框的單詞表示需要獲得更多的關注,因為它們是該子序列的正確分詞形式。而單詞“甲肝病”和“肝病”的優(yōu)先級較低,所以需要抑制這些單詞對字符增強特征的作用,以免指導模型學習很多錯誤的訓練參數(shù)。同時,如圖4(b)所示,對于同一個字符,在不同上下文語境中需要關注的單詞信息不同,這種差異性可以通過匹配的單詞序列中單詞的內(nèi)部交互較好地反映,如字符“病”和“毒”匹配的單詞序列在增加單詞“病毒量”后,需要關注的單詞就從“病毒”變?yōu)椤安《玖俊薄1疚氖紫韧ㄟ^自注意力機制進行單詞內(nèi)部的信息交互,將單詞向量映射到新的語義空間,隨后通過一個字到詞的雙線性注意力映射,從所有匹配的單詞中選出最相關的單詞。
如圖5 所示,本文使用與Transformer 編碼層相同的自注意力結構,對于第i個字符對應的單詞序列向量,通過使用多頭注意力機制實現(xiàn)不同單詞間的信息交互,然后使用逐位置的前饋網(wǎng)絡(Position-Wise FeedForward Network,PWFFN)對每個單詞信息編碼,同時引入兩層殘差網(wǎng)絡(Residual Network,ResNet)以防止模型退化,并使用層歸一化(Layer Normalization,LN)進行規(guī)范化處理,最終將單詞序列映射到一個新的語義空間主要計算過程如式(10)和式(11)所示:

圖5 Transformer編碼器結構Fig.5 Structure of Transformer encoder
其中多頭注意力機制中頭的數(shù)量Nhead=8。
本文將位置為i的字詞表示向量輸入到如圖6所示的詞匯適配器中,整個計算過程如式(12)~(15)所示,其中字向量每個詞向量為了對齊兩種表示向量的維度,引入非線性變化對詞向量進行維度對齊:

圖6 詞匯適配器結構Fig.6 Structure of lexicon adapter
為了從所有匹配的單詞中選出相關度最高的單詞,將位置為i的單詞表示定義為其中接著通過雙線性加權方式計算字符與每個單詞的相關性權重ai∈Rm:
最后,本文將加權得到的詞匯信息向量與字符序列拼接,得到最終的表示向量
2.5 CRF解碼層
在通過詞匯適配器結合詞匯信息和字符信息后,將序列的最終表示形式輸入到CRF 層進行序列標注。具體地,將經(jīng)過BiLSTM 層和注意力交互層的編碼向量輸入CRF 結構,計算每個標簽之間的轉移概率。如式(16)所示,對于標簽序列y={y1,y2,…,yn},概率分布定義為:
其中:第一項是交叉熵,第二項是正則化項,λ是L2正則化權重,Θ表示模型參數(shù)的集合。
3 實驗與結果分析
3.1 數(shù)據(jù)集
本文實驗數(shù)據(jù)來自CHIP2020 發(fā)布的中文醫(yī)學文本實體關系抽取數(shù)據(jù)集,該數(shù)據(jù)集共有實體11 類,分別為疾病、藥物、檢查、部位、預后、癥狀、流行病學、社會學、手術治療、其他治療和其他,其中“其他”類實體用于“疾病”和“其他”類實體進行就診科室、階段和預防三類關系的抽取。本文將提供的用于訓練的數(shù)據(jù)按照7∶1.5∶1.5 劃分為訓練集、驗證集和測試集,其中訓練集用于迭代訓練過程中的各種模型參數(shù);驗證集用于超參數(shù)的調優(yōu),以進一步提高模型的整體性能;測試集用于衡量模型訓練的效果,判斷預測標簽與真實標簽的出入。經(jīng)過數(shù)據(jù)預處理后,共計得到14 339 條數(shù)據(jù),數(shù)據(jù)集的劃分情況及各實體種類的統(tǒng)計信息如表1 所示。
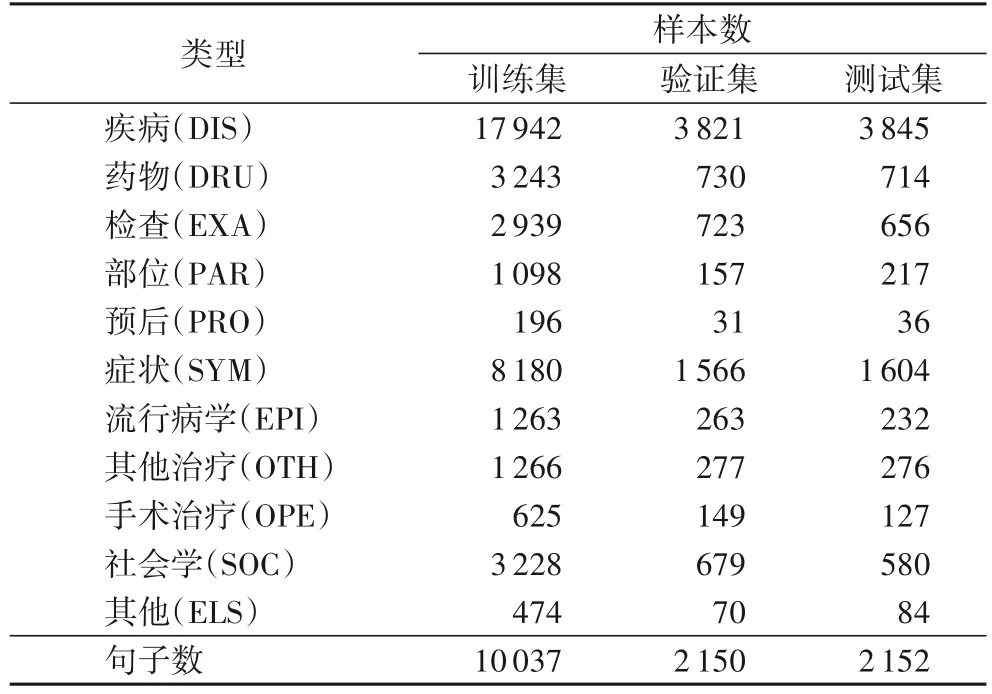
表1 數(shù)據(jù)集統(tǒng)計結果Tab.1 Dataset statistical results
3.2 實驗方案
3.2.1 評價指標
本文采用命名實體識別任務常用的評價指標精確率P(Precision)、召回率R(Recall)及F1 值(F1)作為本次評估模型的標準。其中精確率表示在所有被預測的醫(yī)學實體中正確預測出的實體占比,召回率表示在已標注的醫(yī)學實體中被正確預測出的實體占比,F(xiàn)1 值是為了兼顧這兩種評價指標提出的衡量標準,是兩者的調和平均。一般地,設E={e1,e2,…,em} 為擁有正確標簽的實體集合,E'={e'1,e'2,…,e'm}為被模型預測出的實體集合,NT=|E∩E'|代表預測正確的實體數(shù),|E|代表標注實體的總數(shù),|E'|代表預測實體的總數(shù),則P、R、F1的計算過程如式(18)~(20)所示:
3.2.2 實驗設置
本文字向量和詞向量的維度設置為200,字向量使用均勻分布初始化,在下游任務的訓練過程中,字向量和詞向量與模型參數(shù)一起更新。詞向量使用騰訊中文詞向量,共計包含200 萬預訓練詞向量,設置每個字符最多融合3 個詞向量,與字符進行適配后,自動構建了一個含有58 621 個單詞的詞典。
在超參數(shù)的選擇上,采用Adam 優(yōu)化器進行訓練,其中CRF 層的初始學習率為3 × 10-4,模型其余參數(shù)的初始學習率為6 × 10-5。為了防止訓練過擬合,將權重正則系數(shù)λ設置為0.05,在BiLSTM 層設置比例為0.15 的Dropout,在詞匯適配器和自注意編碼層中設置比例為0.25 的Dropout,batchsize 設為16,文本序列的最大長度設置為256。
3.2.3 基準模型
本文選取Lattice-LSTM 作為實驗對比的基準模型,另外選取FLAT(Flat-LAttice Transformer for Chinese NER)和基于字符的模型BiLSTM-CRF、ATT-BiLSTM-CRF、BGRU-att-CRF、CAN-NER(Convolutional Attention Network for Chinese Named Entity Recognition)驗證本文方法的有效性,6 個對比模型的如下所示。
1)Lattice-LSTM[8]:該方法在LSTM 基礎上增加用于存儲詞匯的結構,通過門控循環(huán)單元利用字符序列中的詞匯信息減少分詞錯誤。
2)BiLSTM-CRF[6]:命名實體識別中效果較好的一種通用框架,BiLSTM 能很好地學習序列結構和上下文信息。
3)ATT-BiLSTM-CRF[27]:在BiLSTM 隱藏層之后引入自注意力機制,有利于提取字符的重要特征。
4)BGRU-att-CRF[24]:將字向量輸入雙向門控循環(huán)單元,然后將隱藏層向量輸入注意力層提取有效信息,沒有引入詞匯信息。
5)FLAT[10]:通過Transformer 結構將Lattice 結構平鋪至字符序列,并引入了字符和詞匯的位置信息。
6)CAN-NER[7]:使用具有局部注意力機制的CNN 和具有全局注意力機制的BiGRU 編碼文本信息,沒有引入其他外部表征。
3.3 實驗結果與分析
3.3.1 模型對比實驗結果分析
將本文提出的AMLEA 與6 個對比模型進行比較分析,實驗結果表明,本文提出的自適應詞匯增強模型具有較好的性能。
實驗結果如表2 所示,比起引入了詞匯信息的基線模型Lattice-LSTM 和FLAT,本文模型在精確率、召回率和F1 值上都有較大幅度的提升,F(xiàn)1 值達到67.96%。說明詞匯適配器的引入能使字符充分利用與它相關性高的單詞表征,并且BiLSTM 結構學習的上下文語義信息也能促使子詞序列的正確表示,例如詞匯“竇性心動過速”會將子序列“心動”的向量映射到接近“竇性”詞匯向量的醫(yī)學語義空間中,而不表示為其他語境中的“心動”向量。另外,本文模型與其他沒有融合詞匯信息的模型對比,F(xiàn)1 值提升了1.37~2.38 個百分點,說明本文模型能有效引入醫(yī)學領域的詞匯信息,相較于其他模型的詞匯融合方式,可以抑制噪聲詞匯,避免無效單詞的錯誤傳播,進而使每個字符融合正確的詞匯邊界信息。最后,在兼容BERT 模型的實驗中,本文使用BERT 的預訓練嵌入層初始化字符向量,比較了配備BERT[12]之后的AMLEA 與普通的BERT+BiLSTM-CRF 標注模型的結果,F(xiàn)1 值提升了1.62 個百分點。實驗結果表明,本文模型使用BERT 的預訓練嵌入層有著可觀的語義信息增強效果,對底層嵌入信息的利用更全面。推測原因可能是將單詞與字符信息集成在同一平面上,在有效利用詞匯信息的同時保留了字符序列模型中上下文依賴建立的方式,使得模型具備強大的遷移能力和擁有輕量級的參數(shù)。

表2 不同模型的實驗結果 單位:%Tab.2 Experimental results of different models unit:%
3.3.2 細粒度實體實驗結果分析
為分析AMLEA 在不同實體粒度上的實驗效果,本文在該數(shù)據(jù)集上列出了11 類實體的識別標簽,最終細粒度實驗結果如表3 所示。
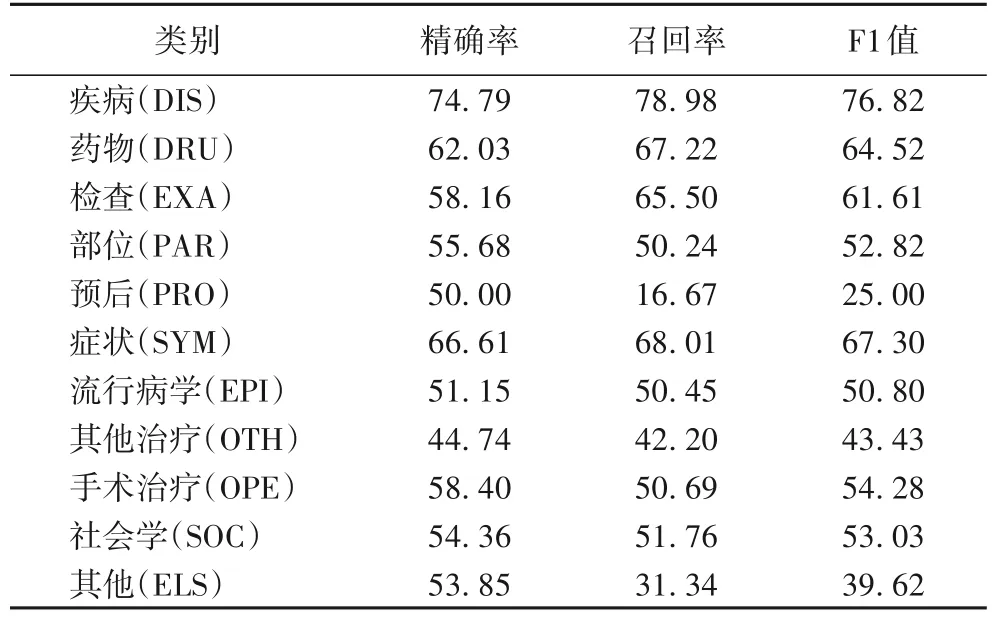
表3 細粒度實體識別實驗結果 單位:%Tab.3 Experimental results of fine-grained entity recognition unit:%
可以看到,“疾病(DIS)”的F1 值遠高于其余類別的實體。推測這是因為該類別實體數(shù)量占比約44%,數(shù)量較充足,字符能夠匹配的詞匯覆蓋范圍更全面,使得詞匯適配器和自注意力結構能夠充分訓練。這一原因也體現(xiàn)在訓練過程中“疾病”類別的擬合能力和訓練速度優(yōu)于其余實體類別。反觀“癥狀”“藥物”“社會學”和“檢查”的實體占比約為20%、8%、8% 和7%,F(xiàn)1 值分別為67.30%、64.52%、53.03% 和61.61%,說明較少的數(shù)據(jù)量會導致匹配的詞匯信息較少,在字詞交互階段訓練不充分,因此性能沒有“疾病”類別的效果好。但“社會學”的F1 值遠低于同等數(shù)量級的實體類別,甚至持平數(shù)量占比分別為3%和2%的“部位”和“手術治療”這兩類實體。經(jīng)過研究發(fā)現(xiàn),“社會學”這類實體涵蓋范圍較為廣泛,包括“纖維蛋白的沉積”這類的發(fā)病機制和“自主神經(jīng)調節(jié)功能差”這樣的病理生理,模型容易將這類實體歸類到“癥狀”之類的實體,通過查看“社會學”的召回率和精確率發(fā)現(xiàn),它的召回率比精確率要低些,但“癥狀”“藥物”和“檢查”的召回率比精確率高1.4~7.34 個百分點,充分說明了“社會學”這類實體的多樣性及所在語境的復雜情況。同樣,“手術治療”“其他治療”“流行病學”和“部位”的數(shù)占比分別約為2%、3%、3%和3%,所以在相同的參數(shù)設置中,這4 類的實體識別效果欠佳,數(shù)量分布不均容易導致模型欠擬合,從而不能充分的融合詞匯信息。
3.3.3 詞匯注意力效果分析
本文對字符和與它匹配的潛在單詞進行了注意力權重可視化分析,本文選取了測試集中的一句話,“3.大腸桿菌腸炎常發(fā)生于5~8 月,病情輕重不一”作為案例分析。其中疾病命名實體為“大腸桿菌腸炎”,與它對應的子序列有“大腸”“腸桿菌”“桿菌”“大腸桿菌”和“腸炎”。如圖7 所示,可以直觀地看出經(jīng)過詞匯適配結構的交互后,前4 個字符與“大腸桿菌”的關聯(lián)性更強,后2 個字符與“腸炎”的關聯(lián)性更強。由于本文的詞典中并沒有“大腸桿菌腸炎”的完整詞匯與它對應的詞向量,所以不能直接將該詞標記為疾病實體,但“大腸桿菌”和“腸炎”的融入,能使字符邊界的劃分更加明確,并且抑制類似“腸桿菌”這樣的無關詞匯。
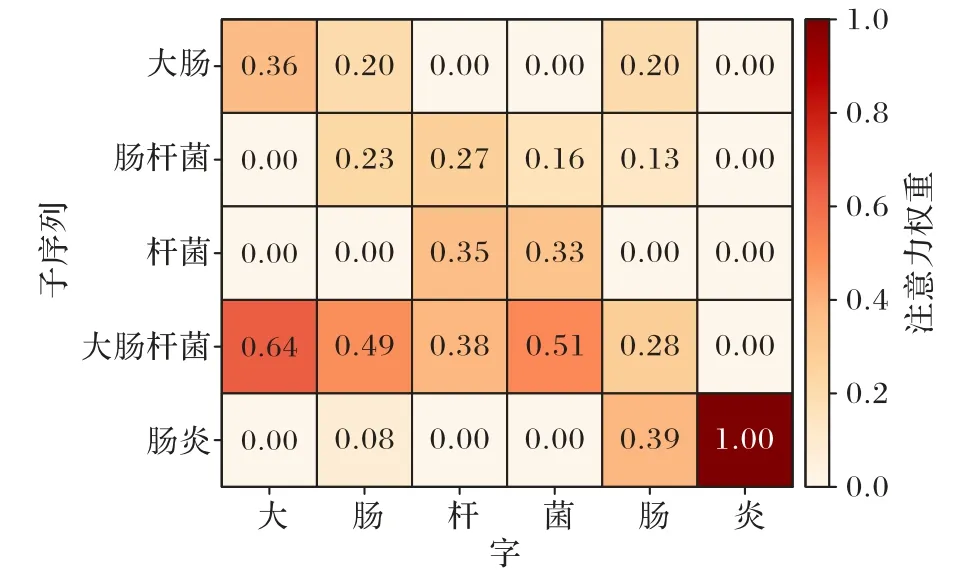
圖7 注意力可視化示例Fig.7 Example of attention visualization
3.3.4 消融實驗
為了探究AMLEA 中每個結構的有效性,本文對模型進行消融實驗,結果如表4 所示。可以發(fā)現(xiàn),在移除掉自注意結構后(w/o self-attn),模型F1 值下降0.49 個百分點,這表明通過自注意結構進行單詞信息內(nèi)部交互的有效性;在移除掉詞匯適配器的實驗中(w/o LA),每個字符匹配到的單詞序列在經(jīng)過自注意結構后,本文將多個單詞向量逐元素相加并求平均值后,得到的詞匯向量作為最終詞匯表示,并與字符最終表示拼接后輸入解碼層,結果表明模型的性能損失為2.29 個百分點,這表明詞匯適配器在本文模型中發(fā)揮了關鍵的作用;將詞匯適配器中字符與詞匯信息的結合方式從拼接變?yōu)橹鹪叵嗉硬⑶笃骄岛螅╮epl concat),模型的總體性能輕微下降,這表明拼接方式是最終結合兩種信息更有效的手段,比起逐元素相加,它使得字符向量與詞匯向量之間能保持一定的信息獨立性。

表4 消融實驗結果 單位:%Tab.4 Results of ablation study unit:%
4 結語
本文提出了一種基于注意力機制與詞匯融合的中文醫(yī)學命名實體識別模型,將編碼后的字符序列與經(jīng)過自注意力層的詞匯向量進行匹配,通過詞匯適配器的融合后,字符被注入潛在單詞中與實體最相關的單詞語義信息,增強了字符的邊界信息和上下文語義信息,緩解了中文醫(yī)學實體識別中嵌套實體邊界檢測模糊化和未登錄詞識別歧義的問題。但本文方法也存在一定的局限性:一方面,細粒度實驗表明該方法的模型效果很大程度取決于數(shù)據(jù)量的大小和標注的準確性;另一方面,該方法選取的是醫(yī)學領域的數(shù)據(jù)集進行測試,構建一個高質量的醫(yī)學領域詞典是模型性能提高的關鍵。后續(xù)的工作會收集大量醫(yī)學語料和已有的中文醫(yī)學預訓練模型,構建專業(yè)性的醫(yī)學詞典來提高領域實體識別的精確率。
猜你喜歡
中華胰腺病雜志(2021年1期)2021-02-26 11:28:36
山東醫(yī)藥(2020年34期)2020-12-09 01:22:24
開放教育研究(2020年2期)2020-03-31 01:54:14
閱讀(快樂英語高年級)(2020年8期)2020-01-08 02:21:16
中華胰腺病雜志(2019年4期)2019-08-29 08:52:20
智慧少年·故事叮當(2018年11期)2018-05-14 11:48:18
現(xiàn)代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
中華胰腺病雜志(2012年3期)2012-11-07 05:18:45
七彩語文·低年級(2011年19期)2011-04-12 00:00:00
