基于最大熵深度強化學習的雙足機器人步態控制方法
2024-03-21 02:24:40李源潮陶重犇
計算機應用 2024年2期
李源潮,陶重犇,2*,王 琛
(1.蘇州科技大學 電子與信息工程學院,江蘇 蘇州 215009;2.清華大學 蘇州汽車研究院,江蘇 蘇州 215134)
0 引言
雙足機器人屬于仿人機器人。相較于輪式、履帶式機器人,雙足機器人具有復雜的腿部關節結構,不僅可以獲得更高的靈活度與適應性,而且能實現爬樓梯、非平整地面等復雜路面情況下的正常行走[1]。因此獲得快速、穩定的步態控制是雙足機器人的研究重點[2]。由于非線性和不穩定性因素,雙足機器人步態控制系統的設計比較困難[3]。傳統基于模型的步態控制已有大量研究[4-7]。針對特定的步態運動,通常采用開環控制方法預先設定各關節的位置軌跡,控制各關節位置,以實現運動。基于零力矩點(Zero Moment Point,ZMP)的方法是雙足機器人步態控制的常用方法[8-9]。這些傳統的方法依賴于復雜的動力學模型和數學工程,但是在自身和環境變化時,容易造成運動失效[10]。
傳統基于模型的步態控制方法很難適應多變的環境。相比之下,由于自適應學習的特性,端到端的深度強化學習(Deep Reinforcement Learning,DRL)算法越來越多地應用于機器人控制領域。端到端DRL 可以不假設任何步態或機器人動力學的先驗知識,應用于機器人系統[11]。如果成功應用,DRL 可以自動完成對控制器的設計。而基于模型的方法由于環境動力學模型復雜,無法得到準確的模型,給智能體訓練產生了誤差。無模型的方法無需構建環境模型,智能體直接與環境交互,它的策略更準確,對環境的適應性更好[12]。
本文提出一種基于最大熵深度強化學習方法對雙足機器人的步態控制方法,采用最大熵框架,可以讓策略盡可能隨機。雙足機器人可以更充分地探索狀態空間,避免策略過早落入局部最優點,充分發揮雙足機器人自主探索的能力[13],獲得適應環境的步態,提高抗干擾能力。本文的主要工作如下:
1)針對雙足機器人連續直線行走的步態穩定控制問題,提出一種基于柔性演員-評論家(Soft Actor-Critic,SAC)的DRL 步態控制方法。該方法無需事先建立動力學模型,使雙足機器人直接與環境交互,獲取經驗樣本優化策略函數。并且輸入神經網絡的參數來自機器人本身的關節角度,無需額外的傳感器,從而使該方法具有更好的移植性。
2)針對DRL 樣本效率低下,導致策略收斂緩慢的問題,提出了一種余弦相似度方法對經驗樣本分類,提高樣本使用效率,并且加快了訓練的收斂。
3)針對雙足機器人受髖關節擺動影響無法較好地實現直線行走的問題,利用知識和經驗設計獎勵函數,約束雙足機器人直線行走。
1 相關工作
在過去30 年里,許多學者使用不同的方案控制雙足機器人的步態,從基于模型的傳統控制方法到端到端的DRL方法;然而,設計機器人模型所需的專業知識以及精確的機器人動力學模型很難獲得。相反,無模型的DRL 方法無需環境動力學模型,機器人直接與環境進行交互,同時在和環境交互不斷試錯的過程中,觀察環境相關信息并利用反饋的獎勵信號不斷學習,尋找最優策略。
雙足步行控制可以被抽象為解決未處理的高維感官輸入復雜任務的一種方式。深度學習(Deep Learning,DL)已在解決高維復雜問題方面取得了許多成就。DRL 將DL 和強化學習(Reinforcement Learning,RL)相結合,既具有解決高維復雜問題的能力,也具有決策能力。Actor-Critic 框架法結合了價值函數和策略函數,解決了策略函數法收斂速度慢的問題。例如深度確定性策略梯度(Deep Deterministic Policy Gradient,DDPG)算法[14]和異步參與者批評家(Asynchronous Advantage Actor-Critic,A3C)[15]算法。A3C 算法通常獲得局部最優解,對策略的評估效率低下。Wu 等[16]引入了DRL 算法,為傳統步態控制方法解決了上述問題。DDPG 算法、近端策略優化(Proximal Policy Optimization,PPO)算法[17]和信賴域策略優化(Trust Region Policy Optimization,TRPO)算法[18]可以探索連續的動作空間,使深度強化學習算法成功應用于雙足機器人的步態控制問題[19]。趙玉婷等[20]將深度Q 學習(Deep Q-Network,DQN)算法應用于雙足機器人在非平整地面的步態控制,在V-Rep 平臺經過多回合訓練調整實現穩定的雙足機器人行走。Tao 等[21]將一種并行DDPG 算法用于雙足機器人步態控制,改進了經驗回放機制,提高了采樣效率和優化了策略函數,并在RoboCup 仿真環境中實現了穩定行走。Rodriguez 等[22]將深度強化學習算法用于雙足機器人全向行走控制。每一個運動是由單個控制策略網絡實現的,目標難度逐步增加,最終實現雙足機器人全向行走。
雖然DRL 算法在處理復雜的雙足機器人步態控制問題方面具有優勢,但仍會陷入探索困境。由于缺乏對環境的魯棒性,整體收益小,導致雙足機器人行走效果較差等。最大熵DRL 算法基于最大熵原理,旨在通過加權最大化期望收益和策略的期望熵。產生相對穩健的策略是最大熵強化學習的一個優點,由于在訓練期間注入結構化噪聲,使策略更廣泛地探索狀態空間,可以有效提高策略的魯棒性[23]。該算法直接讓雙足機器人與環境進行交互,并使用自身采樣的樣本數據提高策略性能,使它更好地適應環境。本文方法還優化經驗回放機制,使用余弦相似度對經驗分類,提高采樣效率;同時,還設計了一系列獎勵機制,以提高雙足機器人行走穩定性。本文的步態控制方法框架如圖1 所示。
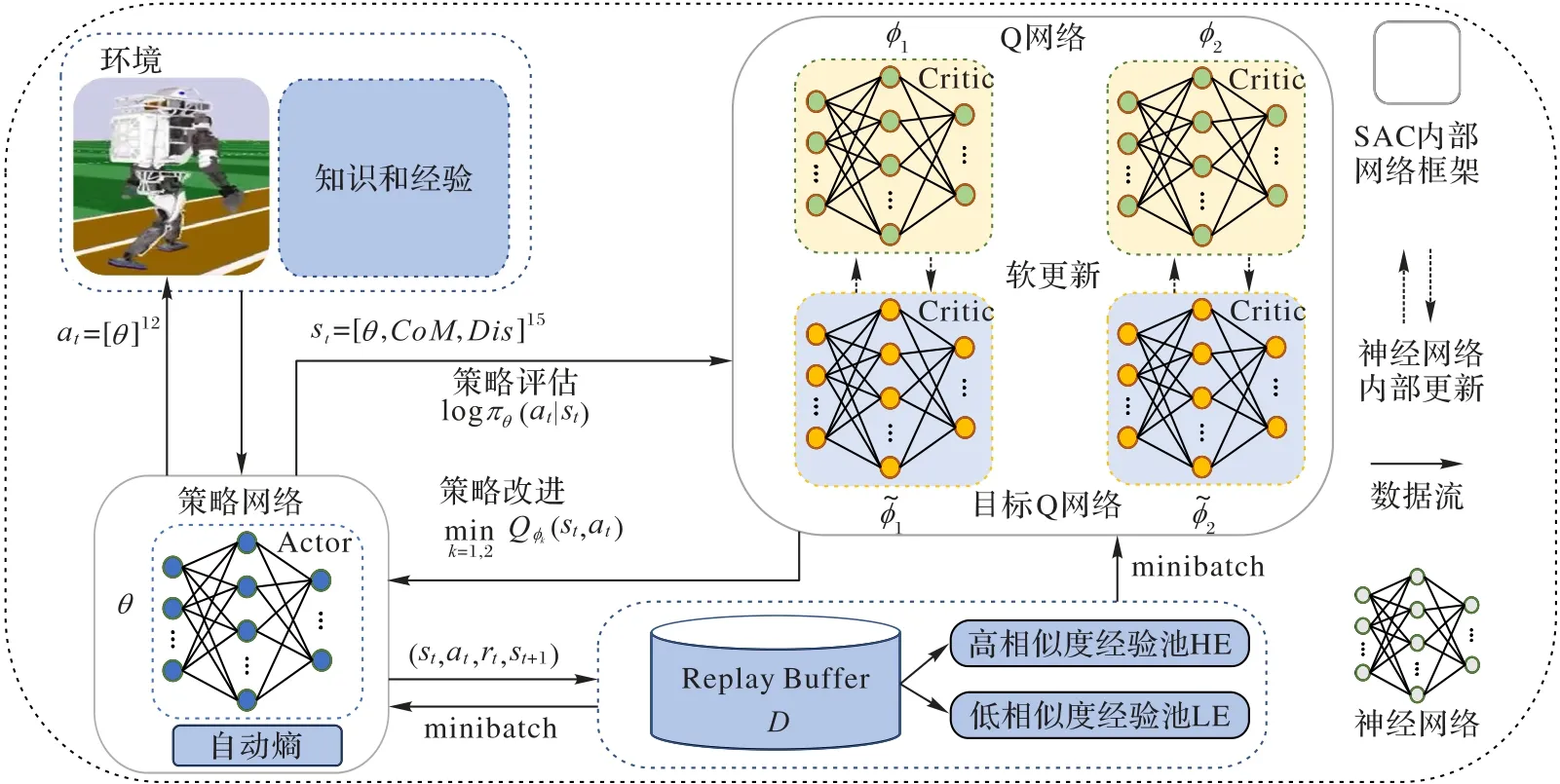
圖1 本文步態控制方法的總體框架Fig.1 Overall framework of the proposed gait control method
2 基于柔性演員-評論家的步態控制方法
2.1 深度強化學習
深度強化學習是通過智能體與環境交互學習。智能體選擇一個動作后,會從環境中得到相應的狀態和獎勵。通過這個持續交互過程的學習,最終獲得最優策略函數。智能體與環境之間的交互被建模為馬爾可夫決策過程(Markov Decision Process,MDP)。MDP 通常由一個五元組表示(S,A,P,R,γ),其中:S表示狀態集合;A表示可執行的動作集合;P:S×A×S→[0,1]表示狀態轉移函數;P(st+1|st,at)表示智能體在狀態st下采取行動at后轉移到下一個狀態st+1的概率;R:S×A×S→R表示獎勵函數;R:(st,at,st+1)表示智能體在狀態st下采取行動at后轉移到下一個狀態st+1的立即獎賞;γ是獎勵的折扣系數。智能體通過選擇使未來獎勵最大化的動作與環境交互。
傳統的DL 方法選擇最佳動作通常是基于查找表,而DRL 方法通過深度神經網絡決策動作,大幅提升了解決復雜高維問題的能力。Mnih 等[24]通過DQN 解決以原始像素作為輸入的高維復雜問題,這種方法在多個視頻游戲中取得了與人類相當的表現。DQN 在處理離散動作空間的問題中游刃有余。然而,在涉及連續動作空間的機器人控制問題時,DQN 無法獲得較好的結果。因此在應對連續動作的機器人控制問題就需要另外一種算法。
SAC 的核心理念是使用近似函數去學習連續動作空間的策略函數[25]。SAC 的目標是最大化智能體與環境交互中獲得的獎勵。為了實現這一目標,SAC 使用了軟策略迭代。軟策略迭代的過程在最大熵框架中交替進行,包括策略評估和策略改進兩個步驟:策略評估是根據最大熵框架為當前策略找到精確的價值函數;策略改進是將策略分布更新為當前Q 函數的指數分布。SAC 使用神經網絡作為近似函數,包括3 種神經網絡:策略網絡(用來表示策略函數)、價值網絡(用來表示狀態-價值函數)和軟Q 網絡(用來表示軟Q 函數)。SAC 的策略網絡訓練通過最大化熵和獎勵更新網絡參數,這3 個網絡的參數可以通過最小化誤差進行優化。本文SAC偽代碼如算法1 所示。
算法1 柔性演員-評論家(SAC)算法。
一般DRL 的目標是學習一個策略函數可以最大化有限范圍時間T內的期望累積折扣獎勵,即找到一個最大化的策略而本文的最大熵深度強化學習,除了上面的基本目標,還要求策略函數每次輸出的動作熵最大:
其中H(π(?|s′))=-Ealogπ(a′|s′)。加入熵相后,就意味著神經網絡需要探索所有可能的最優動作,而不是對于一種狀態只考慮一個最優動作。因此雙足機器人在面對干擾時可以更容易地作出調整。
令Q?(s,a)表示Q 值函數,πθ表示策略函數。這里考慮連續動作的設定,并假設πθ的輸出為一個正態分布的期望和方差。Q 值函數可以通過最小化柔性Bellman 殘差學習:
實際中,SAC 也使用了兩個Q 值函數(同時還有兩個目標Q 值函數)處理Q 值估計的偏差問題,即令Q?(s,a)=注意Jπ(θ)中的期望也依賴于策略πθ,可以使用似然比例梯度估計的方法優化Jπ(θ)。在連續動作空間的設定下,也可以用策略網絡的重參數化優化。這樣通常能減少梯度估計的方差。再參數化的做法將πθ表示成一個使用狀態s和標準正態樣本?作為其輸入的函數直接輸出動作a:
將式(4)代入式(3)中得到:
其中:N 表示標準正態分布,現在πθ被表示為fθ。
最后,SAC 還提供了自動調節正則化參數方法。該方法通過最小化以下損失函數實現:
其中k是一個可以理解為目標熵的超參數。這種更新α的方法稱為自動熵調節方法中。其背后的原理是在給定每一步平均熵至少為k的約束下,原來策略優化問題的對偶形式。
2.2 優化經驗回放機制
與文獻[26]中的經驗回放機制不同,本文設計了一種經驗分類單元和兩個經驗池。在經驗分類單元中,使用余弦相似度方法對經驗樣本進行分類。首先,將訓練產生經驗樣本存儲在經驗分類單元中;其次,在回合結束后利用余弦相似度方法計算經驗狀態與當前訓練狀態的相似度。相似度高的經驗樣本存儲在高相似度經驗池HE 中,相似度低的經驗樣本存儲在低相似度經驗池LE 中。給定兩個狀態s1和s2,對s1和s2的相似度計算規則如下:
狀態相似度通過測量兩個狀態內積空間角度的余弦值表示:如果兩個狀態方向相同,則它們的狀態相似度為1;如果兩個狀態方向垂直,則它們的狀態相似度為0。每個經驗樣本根據相似度分類法存儲于對應的經驗池。
注意,高相似度經驗池HE 的采樣概率為μ,低相似度經驗池LE 的采樣概率為1 -μ,其中μ>0.5。
2.3 神經網絡設計
在神經網絡設計部分,主要分為3 個部分:神經網絡結構、策略網絡的輸入和策略網絡的輸出。
2.3.1 神經網絡結構
在SAC 的神經網絡結構中,主要存在3 種神經網絡:價值網絡、軟Q 網絡和策略網絡。所有層均以全連接層的形式連接。本文中用于測試的Atlas 雙足機器人有30 個自由度,從中選取了影響Atlas 機器人行走的12 個重要參數作為策略網絡輸入的一部分;同時,還加入了質心的偏移作為影響雙足機器人平衡的重要參數。策略網絡的輸出是Atlas 機器人腿部關節角度,包括12 個參數,也是策略網絡的輸入參數。而價值網絡和軟Q 網絡的輸入是機器人的狀態參數,輸出是單個參數。因此,策略網絡的輸入為15 個參數,輸出為12 個參數,網絡結構如圖2 所示(CoM表示質心)。軟Q 網絡的輸入還包括策略網絡的輸出。因此軟Q 網絡的輸入為27 個參數,輸出為1 個參數。價值網絡的輸入為15 個參數,輸出為1 個參數。在隱藏層部分,策略網絡、軟Q 網絡和價值網絡使用的層數都是3。隱藏層的激活函數是ReLU(Rectified Linear Unit)。控制雙足機器人腿部關節需要正值和負值,因此策略網絡輸出層的激活函數選擇Tanh,Tanh 將輸出值控制在[-1,1]。
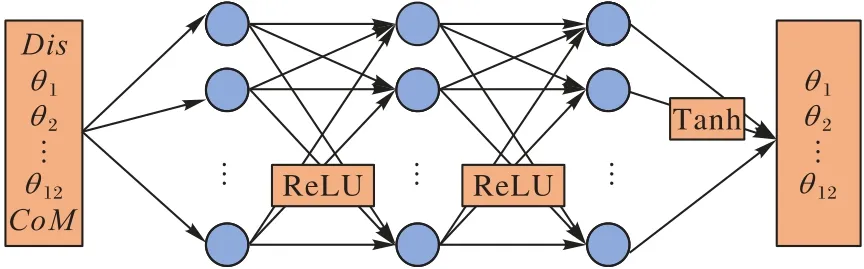
圖2 策略網絡結構Fig.2 Structure of policy network
2.3.2 策略網絡的輸入
策略網絡的輸入是雙足機器人的狀態空間。在構建狀態空間時,許多現有的基于強化學習的雙足運動方法使用機器人全部狀態作為神經網絡中策略網絡的輸入,顯著降低了訓練過程的采樣效率,從而導致不必要的大型神經網絡和延長訓練時間;然而,狀態空間還得考慮到變量的豐富性和必要性,因此,適當地選擇一些有用的信息,讓網絡有良好的學習效率和結果很重要。本文的目標是讓雙足機器人快速、穩定地行走到100 m 外的終點,在行走過程中減少雙腿自碰撞和摔倒。本文選取了影響雙足機器人速度和穩定性的重要參數作為狀態空間組成部分。狀態空間如表1 所示。
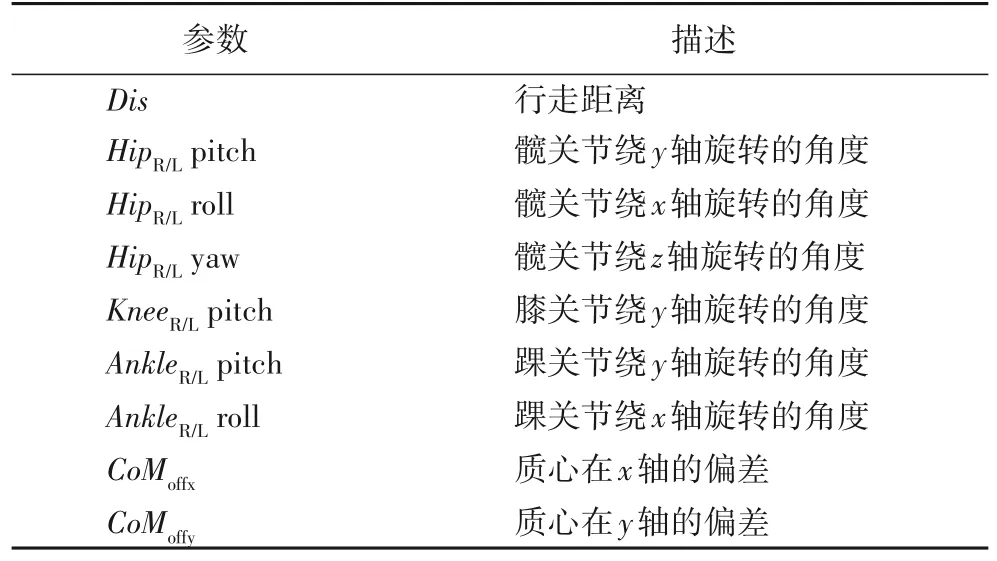
表1 狀態空間Tab.1 State space
2.3.3 策略網絡的輸出
策略網絡的輸出是雙足機器人的動作空間。動作空間是機器人與環境交互的方式。本文選取了影響Atlas 雙足機器人行走的12 個重要參數作為Atlas 機器人的動作空間,Atlas 機器人采用不同的動作與環境交互,會獲得不同的狀態和獎勵,因此策略網絡的目標是輸出使獎勵最大化的動作。動作空間的參數如表2 所示。

表2 動作空間Tab.2 Action space
2.4 獎勵函數
獎勵函數對于DRL 算法至關重要,它直接指導整個算法的收斂方向,也是算法中任務目標的直接體現。因此,獎勵函數的設計需要結合實際任務,明確最終目標。本文基于SAC 的步態控制方法的最終目標是控制雙足機器人減少自碰撞,并在平坦的地面上完成連續穩定的直線行走。因此,雙足機器人因自碰撞或其他問題而摔倒的次數可以作為獎勵函數的一項。雙足機器人在規定時間內連續穩定行走的距離也可以作為獎勵函數的判斷依據:雙足機器人摔倒的次數越多,獲得的懲罰越多;連續穩定行走的距離越遠,獲得的獎勵越多。
理想情況下,當雙足機器人能夠連續穩定行走時,每一輪行走的距離應該相近。然而,在雙足機器人訓練的前期,由于無法獲得連續穩定的步伐,在每一輪的訓練中,取最大距離作為獎勵函數的評定項。訓練結束后,通過分析雙足機器人摔倒次數和行走的距離判斷雙足機器人是否達到理想效果。還引入知識和經驗設計多種獎勵函數。該方法加速了DRL 算法的收斂,使雙足機器人行走更快、更穩定。
2.4.1 速度和穩定性獎勵
雙足機器人的目標是穩定地直線行走到100 m 外的終點。如果在行走過程中摔倒或超過1 000 步,則本回合結束,獲得一個值為-5+2.5 × (當前距離Dis/時間T)的懲罰獎勵分數,并且重新開始下一回合的訓練。如果雙足機器人順利完成100 m 距離的行走或者完成1 000 步,則會獲得一個值為(距離Dis/時間T)的獎勵分數,并且重新開始下一輪的訓練 。在摔倒那一項獎勵函數中加入 2.5 ×(當前距離Dis/時間T),為的是鼓勵雙足機器人走得更遠。而總體獎勵函數中都除以時間T項,為的是提高雙足機器人行走的速度。因此,速度獎勵定義為:
為了保持雙足機器人行走過程中的穩定性,本文考慮了雙足機器人因雙腿自碰撞,以及腿部零力矩點(Center of Mass,CoM)偏移過大而摔倒的問題。為了使雙足機器人獲得穩定的步態,必須對雙足機器人設計穩定性獎勵。
1)因雙腿自碰撞而摔倒的問題。
雙足機器人在行走時,髖關節容易帶動腿在冠狀面擺動,造成兩條腿往相反方向運動,從而導致雙腿發生碰撞而摔倒。穩定性獎勵R2如下:
其中HipZsum=|AnglehipZL+AnglehipZR|。
2)因CoM 不在兩腿坐標線中點而摔倒問題。
為了保持穩定性,本文采用游動腿的CoM 始終在兩腿坐標線中點的標準進行訓練。當CoM 不在中點時,該輪結束。穩定性獎勵R3為:
其中Pshake=CoMoffx+CoMoffy。
2.4.2 約束獎勵
強化學習訓練時,可能會獲得奇怪的行走姿勢。為了使雙足機器人行走更像人類,加入兩個循環時鐘,每個對應于機器人的一條腿:
其中:φt是一個相位變量,它從0 遞增到1,然后回滾到0,跟蹤步態的當前相位。恒定偏移0.0 和0.5 是相位偏移,用于確保左右腿在運動過程中的相位始終完全相反。
在雙足機器人訓練過程中,為了讓雙足機器人沿直線行走,必須控制雙足機器人髖關節的擺動。約束獎勵如下:
其中HipYsum=|AnglehipYL+AnglehipYR|。
綜上所述,最終的獎勵R定義為:
3 實驗與結果分析
本文在Roboschool 平臺使用SAC 步態控制方法對Atlas雙足機器人進行訓練,訓練的內容是在平整路面上沿著某一固定方向直線行走。本文使用另外兩種先進DRL 算法PPO和TRPO 進行對比實驗。在同一環境、相同參數下,對Atlas雙足機器人進行訓練,下面給出仿真結果和對結果的分析。
3.1 學習速度和獎勵值
本文用于訓練的電腦配置如下:硬件環境為Intel Core i9-9900K 處理器,內存32 GB,顯卡NVIDIA GTX 2080 Ti,軟件環境為OpenAI Gym、Roboschool 和Chainerrl。訓練過程中的獎勵值如圖3 所示(max 表示同一時間步下獎勵的最大值,min 表示同一時間步下獎勵的最小值)。從圖3 中可以得出,本文SAC 算法相較于另外三種算法有很大提升,不僅是智能體獎勵值的提升,而且還提高了收斂速度。
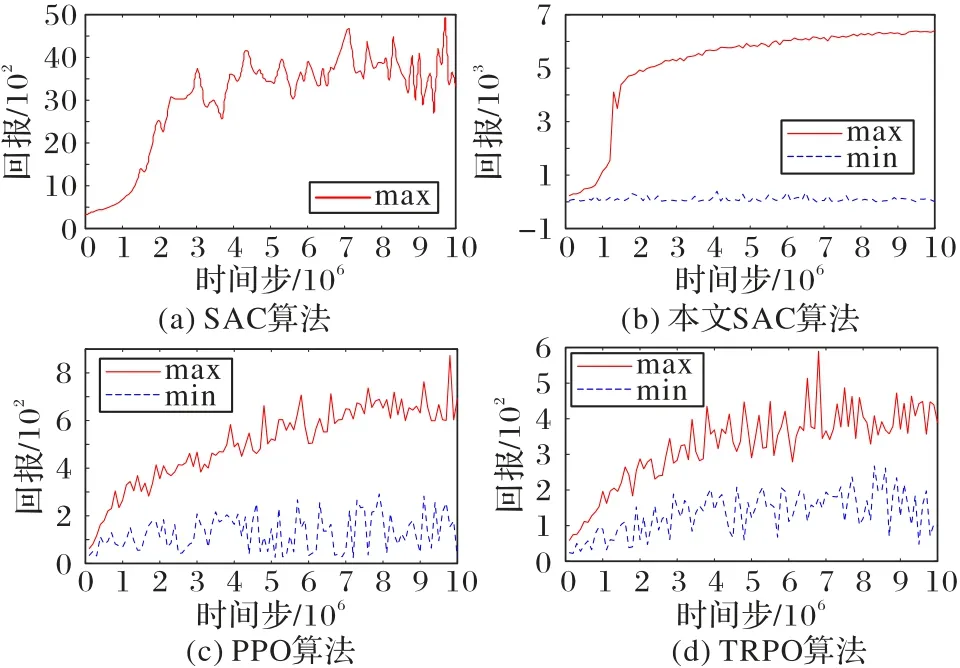
圖3 四種算法的獎勵值比較Fig.3 Comparison of reward values among four algorithms
在同一環境、相同的實驗參數,本文測試了chainerrl[27]原本的SAC 算法和優化后的SAC 算法,以及另外兩種先進的深度強化學習算法PPO 和TRPO。每一種算法,都在Roboschool 仿真環境里進行了1 000 萬個時間步的訓練。每10 萬個時間步,對每個算法進行20 回合的評估。在這20 回合里取獎勵值最大和最小回合的獎勵值,并做了記錄。最后繪制圖3 所示的獎勵值圖。
在相同時間步的情況下,算法訓練的智能體獎勵值越大,學習速度則越高。而曲線的平滑性則與步態控制方法的魯棒性密切相關,曲線越平滑,方法的魯棒性越好。由圖3可知,本文優化的SAC 與chainerrl 中原本的SAC 算法與其他兩種先進的深度強化學習算法相比,本文算法收斂速度明顯提高,并且實驗的獎勵值對比PPO 和TRPO 兩種算法有很大的提升。優化的SAC 和SAC 算法在200 萬時間步左右達到一個比較高的獎勵值,而PPO 和TRPO 算法在600 萬時間步左右才達到一個比較高的獎勵值。從整體曲線的平滑性來看,本文優化的SAC 步態控制方法,有更快的收斂速度,以及更好的魯棒性。
3.2 雙足機器人步態控制結果與分析
由3.1 節可知本文SAC 步態控制方法具有良好的收斂速度和性能。3 種算法在同一臺電腦上運行相同實驗,PPO和TRPO 算法完成1 000 萬個時間步需要30 h,而本文SAC 算法需要60 h。本文在訓練Atlas 機器人直線行走時,并未實時渲染Atlas 機器人的訓練情況。在3 種算法完成1 000 萬個時間步后,本文使用3 種算法訓練出來的最優模型參數控制Atlas 機器人直線行走。然而,只有本文SAC 算法具有成功控制Atlas 機器人實現直線行走的能力。其他兩種算法對Atlas 機器人行走能力的控制的效果較差。
由圖4 可知,本文SAC 算法實現Atlas 機器人直線行走能力最好,PPO 和TRPO 算法對Atlas 機器人行走控制還存在直線行走能力較差、行走磕絆、摔倒等問題。

圖4 雙足機器人在Roboschool中行走的細節Fig.4 Detail of biped robot walking in Roboschool
本文算法在Atlas 機器人步態控制中的仿真結果表明,Atlas 機器人可以完成1 000 步的行走,整個過程非常穩定,沒有發生跌倒的情況;此外,Atlas 機器人實現了優異的直線行走能力。
踝關節控制雙足機器人游動腿在落地時是否與地面平行。當與地面平行時,Atlas 機器人行走穩定。由圖5 可知,Atlas 機器人在行走過程中,兩條游動腿踝關節的角度相互交替,穩定地控制雙足機器人在行走過程中啟動和落地。后文圖例中L/R 表示左/右,ak 表示踝關節,hip 表示髖關節,kn表示膝關節,x/y 表示x/y方向。

圖5 踝關節角度的變化Fig.5 Changes in ankle joint angle
髖關節控制游動腿向前向后擺動,從而影響Atlas 機器人步長的大小。當Atlas 機器人游動腿的擺動角越大,說明Atlas 機器人的步長越大,則Atlas 機器人行走越快。由圖6(a)所知,髖關節在Atlas 機器人前進方向上的擺動幅度足夠大,說明Atlas 機器人行走快。此外,Atlas 機器人雙腿前后擺動幅度相似,而且雙腿有規律地前后擺動,這說明Atlas機器人行走也更類人。Atlas 機器人在行走過程中,不僅需要完成直線行走,還需要在行走過程中穩定不摔倒。由圖6(b)(c)所知,髖關節還可以控制雙腿在冠狀面上擺動。而且左右腿的髖關節擺動有規律,控制Atlas 機器人的左右傾斜,從而影響Atlas 機器人行走的穩定性。本文提出的SAC 步態控制方法控制髖關節在影響Atlas 機器人直線行走和穩定性的方向上擺動幅度較小,而且左右腿的髖關節相互調節,控制Atlas 機器人直線行走的穩定性。最終,本文方法實現了Atlas 機器人穩定地直線行走。
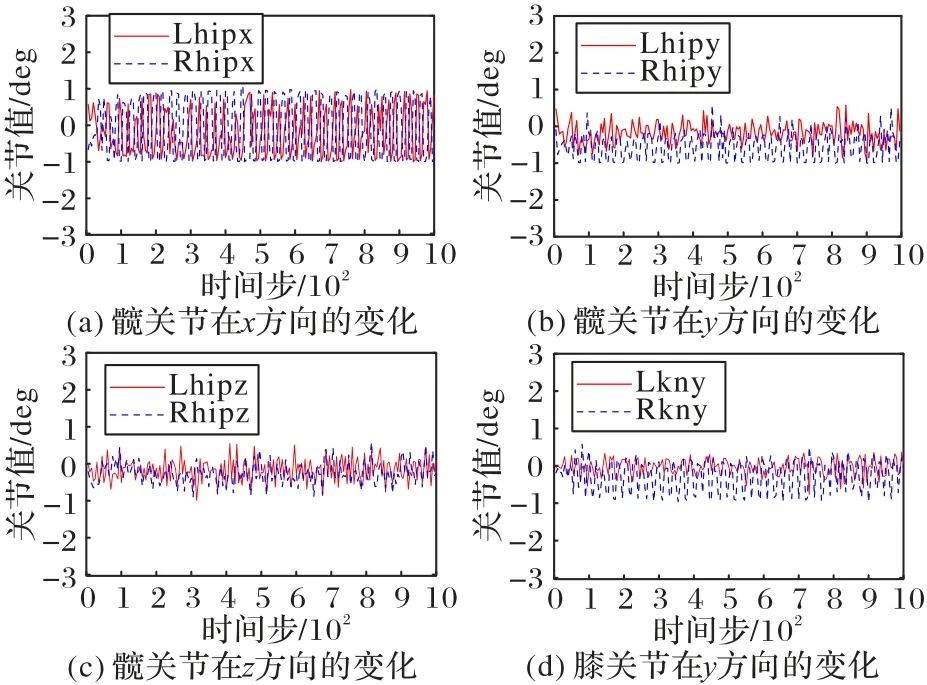
圖6 髖關節和膝關節的角度變化Fig.6 Changes in angles of hip and knee joints
3.3 雙足機器人干擾控制與魯棒性分析
為了評估雙足機器人直線行走的魯棒性,本文參考文獻[28]在兩種不同的情況下向機器人軀干施加外力:1)向前方向施加外力;2)向雙足機器人右側施加外力。
值得注意的是,在整個雙足機器人訓練過程中沒有向機器人軀干施加任何外力。在訓練完成后,使用學習到的策略控制雙足機器人在干擾情況下直線行走。
1)向前方向施加外力。
由圖7 可知,在時間t=4 s,t=6 s 和t=8 s 時對Atlas 雙足機器人軀干施加大小為15 N 的外力。圖7(a)展示了在施加外力時,雙足機器人速度對比之前的速度有小幅波動,但沒有摔倒。在對雙足機器人施加外力后,雙足機器人速度的穩定性很快恢復。由圖7(b)可知,在對雙足機器人軀干施加外力時,雙足機器人軀干向前傾斜角度增大。在下一時刻,雙足機器人軀干恢復了一定的向前傾斜角度。
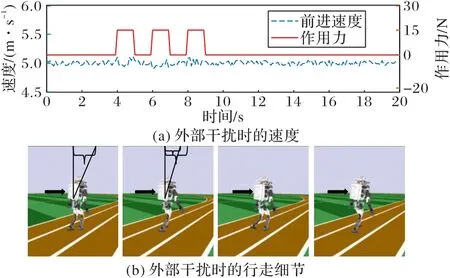
圖7 向前施加外力時的魯棒性控制Fig.7 Robust control when external forces being applied forward
2)向雙足機器人右側施加外力。
由圖8(a)、(b)可知,在向雙足機器人右側施加外力時,雙足機器人速度對比之前的速度有小幅波動,但是沒有摔倒;尤其注意的是,雙足機器人左右方向的移動速度。在向雙足機器人右側施加外力時,雙足機器人控制髖關節抑制其向左邊移動,可見雙足機器人左右移動速度波幅漸大。在對雙足機器人施加外力之后,雙足機器人速度的穩定性很快恢復。在圖8(c)中,本文在軀干中線添加一條指示線,當施加外力時,軀干向左扭轉,指示線發生一定位移。在下一時刻,雙足機器人很快恢復了軀干的扭轉。
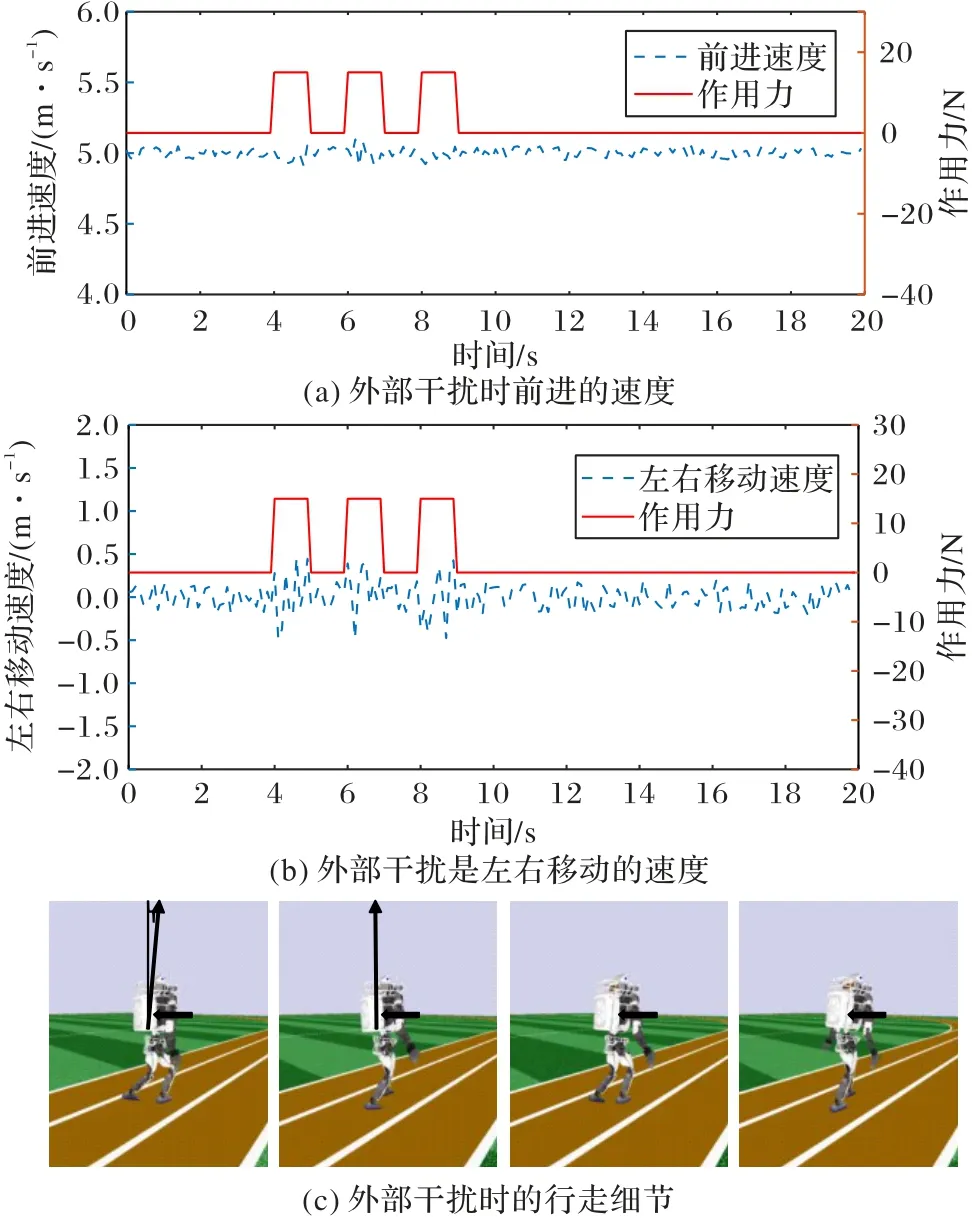
圖8 向雙足機器人右側施加外力時的魯棒性控制Fig.8 Robust control when external forces being applied to right side of biped robot
4 結語
本文針對雙足機器人連續直線行走的步態穩定控制問題,提出一種基于深度強化學習SAC 的步態控制方法,該方法是基于最大熵的DRL 算法。它讓策略盡可能隨機,增大智能體的探索空間,避免策略過早地落入局部最優點,并且可以探索到多個可行方案完成指定任務,提高抗干擾能力。本文還采用了余弦相似度方法對經驗樣本進行分類,優化經驗回放機制,提高樣本效率。通過知識和經驗來設計多種獎勵函數,提高了雙足機器人的訓練速度和雙足機器人快速穩定直線行走的能力。通過仿真實驗表明,雙足機器人完成了快速、穩定的直線行走,與其他深度強化學習算法相比具有較好的穩定性。未來工作將進一步優化步態控制方法,更好地控制雙足機器人直線行走的穩定性,以及實現雙足機器人在隨機起伏地面的行走。
猜你喜歡
教學考試(高考化學)(2021年2期)2021-05-30 06:15:52
中學生數理化·高一版(2020年3期)2020-04-21 08:03:20
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
兒童故事畫報(2019年5期)2019-05-26 14:26:14
數學大世界(2018年1期)2018-04-12 05:39:14
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
