融合詞性語義擴展信息的事件檢測模型
2024-03-21 08:15:38嚴海寧余正濤黃于欣宋燃楊溪
計算機工程 2024年3期
嚴海寧,余正濤*,黃于欣,宋燃,楊溪
(1.昆明理工大學信息工程與自動化學院,云南 昆明 650504;2.昆明理工大學云南省人工智能重點實驗室,云南 昆明 650504)
0 引言
事件檢測(ED)是事件抽取的關鍵步驟,目標是在給定句子中識別事件觸發詞并將其分類為預定義的事件類型。觸發詞是最能清楚表達事件核心含義的詞,通常是一個名詞或者動詞[1]。事件檢測作為自然語言處理領域的一項重要任務,被廣泛應用于知識圖譜[2]、自動內容抽取[3]等下游任務。
事件檢測任務依賴于識別出的觸發詞進行事件類型分類[4-5]。現有多數數據中觸發詞的標注嚴重不平衡,使模型過度擬合密集標注的觸發詞數據,而稀疏標記的觸發詞數據往往得不到有效訓練,導致觸發詞為稀疏標記或未出現過的詞時模型性能不佳。
在以下句子S1、S2 中有下劃線的詞語表示觸發詞:
S1:EU will release 20 million euros in emergency humanitarian aid to Iraq.
S2:EU will disburse 20 million euros in emergency humanitarian aid to Iraq.
可以看出,在句子S1 中,密集標注觸發詞數據“release”被模型正確識別后,句子被分類為正確的事件類型“Transaction:Transfer-Money”,而在將句子S2 中密集標注觸發詞“release”替換為稀疏標記的同義觸發詞“disburse”后,不改變句子原本表達的含義,模型卻不能識別出正確的事件類型。
針對以上問題,現有研究認為生成更多的訓練實例是一種解決方案。一些方法通過引導擴展出更多的訓練實例[6-8],另一些方法使用更多數據進行遠程監督[9-11]。但是這些方法要么生成同質的語料庫,要么受制于低覆蓋率的知識庫,導致數據本身分布不均,訓練的模型存在內置偏差[12],且在稀疏標記數據上性能仍然較差。筆者認為主要原因為稀疏標注數據的觸發詞難以識別,導致其事件類型不能被正確分類。為此,需要對詞粒度擴展信息進行探索,在不增加訓練實例的條件下,縮小候選觸發詞的范圍,并對候選觸發詞進行語義擴展,從而提升觸發詞識別能力。同時,融合不同粒度的語義信息,增強語義表征的魯棒性,以緩解標記數據稀疏的情況。
本文提出一種融合詞性語義擴展信息的事件檢測模型(FESPOS-ED)。首先,通過詞性篩選模塊尋找特定詞性的詞,確定候選觸發詞的位置。無論是稀疏標記還是未見過的觸發詞,都會以極大概率包含在特定詞性中,因此能更好地識別候選觸發詞且不受觸發詞樣本數量的限制。然后,對候選觸發詞位置進行語義擴展,挖掘候選觸發詞上下文豐富的詞粒度語義信息。最后,融合句子粒度語義信息,增強語義表征的魯棒性,進一步提升事件檢測準確性。
本文主要貢獻如下:
1)建立一種融合詞性語義擴展信息的事件檢測模型,結合詞粒度語義擴展信息及句子粒度語義信息,提升語義表征的魯棒性,從而緩解稀疏標記數據帶來的不良影響。
2)利用詞性語義擴展方法,在縮小候選觸發詞范圍的同時擴展候選觸發詞在當前語境下的語義信息,能更好地識別候選觸發詞且不受觸發詞樣本數量的限制。
3)在實驗數據集上的F1 值相較于基線模型有明顯的提升。
1 相關工作
在早期研究中,事件檢測任務被視作基于觸發詞的分類問題,重點在于收集全局統計特征作為知識來源或決策基礎[13-14]。隨著深度學習的發展,許多研究利用深度神經網絡來學習輸入序列的上下文表征信息。在將文本上下文信息嵌入低維空間后,再利用這些特征識別觸發詞和事件類型。根據上下文信息的不同,可以分為結構化上下文信息和非結構化上下文信息。引入結構化上下文信息通常是指引入事件參數信息[15-16],利用結構化文本描述事件信息。引入非結構化上下文信息通常是使用卷積 神經網 絡(CNN)[17-18]、圖卷積 神經網 絡(GCN)[19-21]、預訓練語言模型[10,22-23]等方法捕捉事件信息。
在針對不平衡數據標注的研究中,通常主要有兩類平衡思路:一類是從數據方面進行平衡;另一類是從分類損失上進行平衡。在數據方面的平衡策略中,研究者們利用半監督或弱監督的方法自動擴充訓練實例。文獻[6]依靠復雜的預定義規則從并行的新聞流中引導產生更多訓練實例。文獻[7]采用WordNet 和基于規則的方法來生成沒有事件類型標簽的開放域數據。文獻[10]利用遠程監督方法,基于觸發器的潛在實例發現策略和對抗性訓練方法來協同獲得更加多樣化和準確的訓練數據。文獻[11]利用遠程監督從知識庫中現有的結構化事件知識中生成大規模數據。在分類損失方面的平衡策略中,研究者們也進行了大量研究。文獻[21]提出一個帶有解耦分類重新平衡機制的語法增強型GCN 框架,根據樣本數量模擬負冪律分布重新調整分類器權重。文獻[24]提出的損失通過鼓勵少數類別擁有更大的邊際來擴展現有的軟邊際損失。文獻[25]利用貝葉斯不確定性估計計算樣本和類別的不確定性來度量最大邊距,以緩解類別不平衡造成的影響。
2 融合詞性語義擴展信息的事件檢測模型
針對標記數據不平衡導致稀疏標記數據不能得到有效訓練的問題,構建一種融合詞性語義擴展信息的事件檢測模型,結構如圖1 所示(彩色效果見《計算機工程》官網HTML 版),主要分為句子粒度語義編碼、詞粒度語義擴展、詞粒度-句子粒度語義融合3 個模塊。
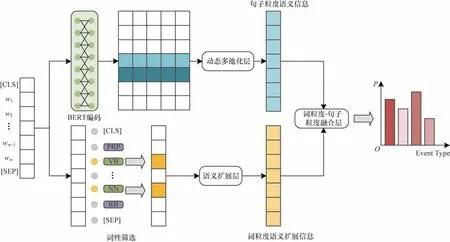
圖1 融合詞性語義擴展信息的事件檢測框架Fig.1 Framework of event detection integrating part of speech semantic extension information
2.1 句子粒度語義編碼
首先,利用Word Price Model 標記化獲得輸入文本序列中token 和位置嵌入的總和,這一做法可以確保為任意字符序列生成確定性的切分,具體計算過程如下:
其中:Sw表示輸入文本序列;m表示文本序列中包含的單詞數量;St表示輸入序列中token 序列;n表示序列中包含的token 數量。
然后,將文本序列Sw輸入BERT,進一步編碼得到隱藏狀態,具體表示如下:
其中:ht=(h1,h2,…,hn-1,hn)表示文本序列中每個token 對應的隱狀態;表示BERT 中的可學習參數。
接著,分別提取每個token 對應隱藏狀態左右兩端的上下文特征信息,并利用動態多池化保留每個token 左右兩部分的最大值。與傳統的最大池化相比,動態多池化可以在不丟失最大池化值的情況下保留更多有價值的信息[9],具體計算過程如下:
其中:[;]表示拼接 操作;max(?)表示最大池化操 作;E1表示第j個token 左邊部分上下文信息特征;E2表示第j個token 右邊部分上下文信息特征;Es表示句子粒度語義特征。
2.2 詞粒度語義擴展
2.2.1 詞性篩選
利用詞性標注工具Stanford CoreNLP 對輸入序列進行篩選,得到滿足詞性的詞語位置,具體表示如下:
其中:SSet,p表示詞性集,具體包括動詞詞性和名詞詞性;表示第i個單詞 的詞性;LLoc,i為0 表示該 位置的詞語不滿足詞性;LLoc,i為1 表示該位置的詞語滿足詞性,即候選觸發詞位置。
2.2.2 語義擴展
在得到候選觸發詞位置后,為了擴展候選觸發詞在當前語境下的語義信息,受到完形填空任務[26]的啟發,使用掩碼預訓練語言模型對每個候選觸發詞位置進行覆蓋。
首先,在輸入文本序列中加入占位符,每次只對一個滿足詞性的候選觸發詞位置進行覆蓋,具體計算過程如下:
然后,利用掩碼預訓練語言模型對帶有占位符[MASK]的文本序列Smask進行預測,具體表示如下:
其中:Hmask表示帶有占位符的文本序列Smask的隱藏狀態;Pmask表示預測單詞的概率分布。這里模型得到的預測單詞表征是固定的,不會跟隨模型一起進行訓練。如果預測單詞表征是動態的,那么每一次訓練得到的詞粒度語義特征都會出現變化,當遇到一些未被訓練的輸入序列時仍會使用之前產生的表征,這樣可能會導致錯誤的識別。
最后,取Top-k預測單詞的表征作為詞粒度語義擴展特征,具體表示如下:
其中:Largestk(?)返回候選詞中最大的k個元素,k是超參數;K=(Κ1,K2,…,Kk)表示Top-k預測單詞的表征;Ew表示詞粒度語義擴展特征。
2.3 詞粒度-句子粒度語義融合
在得到句子粒度語義特征Es和詞粒度語義特征Ew后將其進行融合,得到最終魯棒的語義表征,具體計算過程如下:
其中:[;]表示拼 接操作;MLP(?)表示多 層感知 機;代表多層感知機中的可學習參數;E表示最終魯棒的語義表征。
將最終的融合語義特征經過Softmax 操作得到最終的事件類型概率分布,并根據分布概率判斷輸入序列的事件類型,具體計算過程如下:
其中:P表示預測事件類型概率分布;L 表示損失函數;qi是真實標簽的One-hot 編碼。
3 實驗與結果分析
3.1 數據集
在實驗中采用ACE2005[1]和KBP2015[27]語料庫作為數據集來評估所提模型。ACE2005 數據集是事件檢測任務廣泛使用的一個基準數據集,其中包括來自不同領域的文檔集合,例如文本新聞、廣播對話、博客等。該數據集包含599 個文檔并定義了34 種事件類型,同時提供對應的事件觸發詞、事件參數和事件類型注釋。為避免數據預處理對模型性能產生較大影響,采用與已有研究[17,22,28]相同的方式分割數據,訓練集、驗證集和測試集的文件數量分別為529、30 和40。KBP2015 數據集 是來自2015 年文本分析會議(TAC)的Nugget 事件檢測的評估數據。該數據集包含360 個文檔,定義了39 種事件類型。采用與官方[27]相同的數據分割方式,訓練集和測試集分別包括158 個文檔和202 個文檔,并將訓練集的一個子集作為驗證集,約占訓練集的20%。
以ACE2005 數據集為例,該數據集中數據標注情況存在不平衡現象,統計情況具體如圖2 所示。位于頭部的“Conflict:Attack”事件類型的觸發詞數量遠大于位于尾部的事件類型總和,其中尤為顯著的是數量排名最后5 類事件類型中的觸發詞數量僅為個位數。
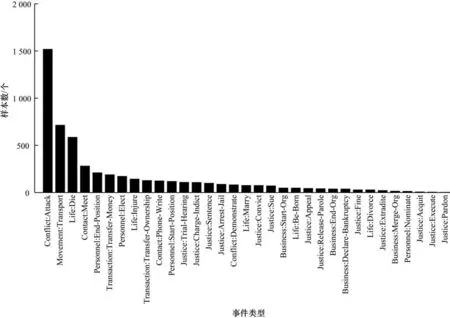
圖2 ACE2005 中事件類型樣本大小分布Fig.2 Sample size distribution of event type in the ACE2005 dataset
觸發詞是句子中最能清楚表達事件核心含義的詞,通常是一個名詞或動詞[1]。以ACE2005 數據集為例,對數據集中的觸發詞詞性進行統計,具體結果如圖3 所示,主要包括單數名詞形式(NN)、復數名詞形式(NNS)等名詞詞性,過去分詞(VBN)、動詞過去式(VBD)、動詞基本形式(VB)、動名詞和現在分詞(VBG)等動詞詞性以及形容詞(JJ)詞性。由統計結果可以看出,觸發詞中名詞和動詞約占總數的92%。因此,對動詞或名詞詞性的特定位置進行語義擴展可以縮小候選觸發詞范圍,并且不受數據集中樣本數量的影響。
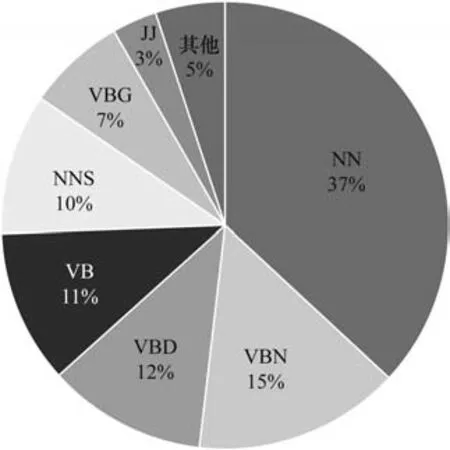
圖3 ACE2005 數據集觸發詞詞性統計Fig.3 Statistics of ACE2005 dataset trigger part of speech
3.2 參數設置
所提模型實現基于PyTorch 框架,利用兩個NVIDIA 3080Ti-12 GB GPU 進行訓練。在實驗中采用Adam 作為優化器,參數設置如表1 所示。
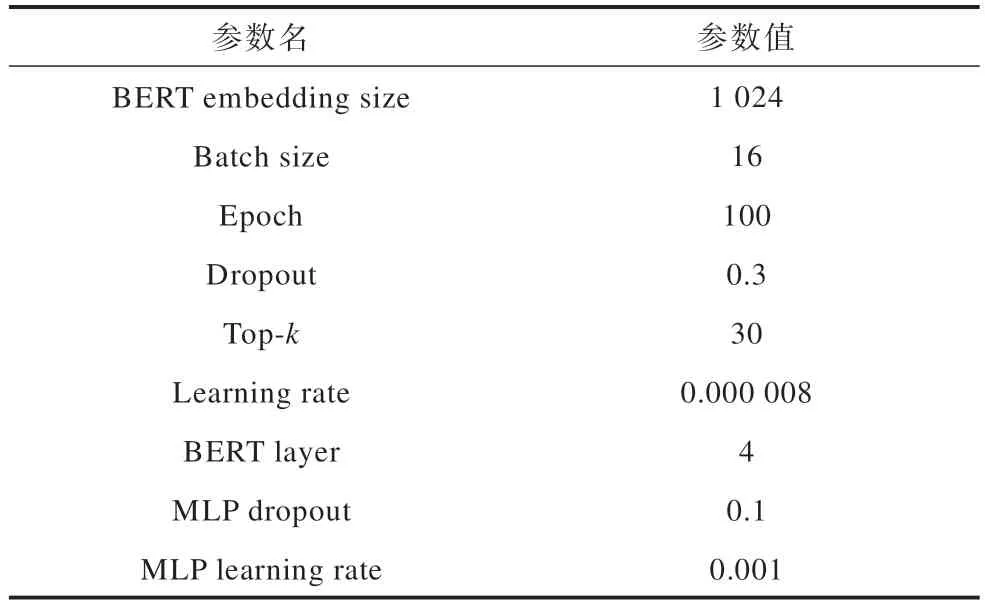
表1 實驗參數設置Table 1 Experimental parameter setting
如上文所述,所提模型分為句子粒度語義編碼、詞粒度語義擴展、詞粒度-句子粒度語義融合3 個模塊,只有詞粒度語義擴展模塊中的參數不參與更新,不具有梯度,其余模塊參數均具有梯度。詞粒度語義擴展模塊參數不具有梯度的原因為:詞粒度語義擴展信息旨在擴展符合當前輸入序列上下文語義信息的詞粒度信息表征,而不能受到其他輸入序列表征的干擾,否則會與當前語境產生偏差,導致錯誤的識別。
3.3 評價指標
實驗選取事件檢測研究中常用的3 個評價指標:
1)準確率(P)表示正確預測的事件在總預測的事件中的比例。
2)召回率(R)表示正確預測的事件在所有事件中的比例。
3)F1 值(F1)根據準確率和召回率計算得來,計算公式為F1=2RP/(R+P)。
3.4 基線模型
為了充分驗證所提模型的性能,選取上述3 種評價指標將近年來主流的事件檢測模型與FESPOSED 進行比較。對比模型具體如下:
1)DMCNN[17]模型:在事件檢測任務中引入動態多池化層作為特征提取器,該特征提取器更加關注事件觸發詞與事件要素信息,從而保留更重要的信息。
2)JRNN[29]模型:為了避免管道模型中的誤差傳播問題,采用雙向RNN 來學習更加豐富的句子表示,同時也考慮了事件觸發詞與事件要素信息之間的聯系。
3)dbRNN[30]模型:在使用RNN 方法的同時應用樹結構與序列結構來提高事件檢測模型的性能,豐富了每個token 的信息表示。
4)GCN-ED[31]模型:采用基于依賴樹的卷積神經網絡模型來改進事件檢測,并且提出一種新穎的基于實體提及的卷積向量聚合方法。
5)JMEE[19]模型:引入依存句法樹方法并使用基于注意力機制的卷積神經網絡對圖信息進行建模,從而解決事件觸發詞歧義的問題并提升事件檢測效果。
6)EE-GCN[32]模型:通過融 合句法 結構和類型依賴標簽并且以上下文相關的方式更新關系表示來改進卷積神經網絡模型。
7)GatedGCN[20]模型:采 用BERT 進行編碼,并利用門控機制根據候選觸發詞的信息過濾圖卷積神經網絡模型中的噪聲信息。
8)Adv-DMBERT[10]模型:采用一種對抗訓練機制,不僅可以從候選集中提取實例信息,而且可以提高事件檢測模型在嘈雜環境中的性能。
9)EKD[12]模型:引入開放域觸發知識,為未見過/稀疏標記的觸發詞提供額外的語義支持,并改進觸發識別性能。
10)SEGCN-DCR[21]模型:采用一種帶有解耦分類重新平衡機制的語法增強型卷積神經網絡,提升在數據分布不均衡的情況下事件檢測模型的性能。
3.5 對比實驗
為了充分驗證所提模型的性能,利用上述基線在相同的實驗條件下進行對比。在ACE2005 數據集上的實驗結果如表2 所示,其中:★表示擴充訓練實例的模型;▼表示基于循環神經網絡的模型;△表示基于圖神經網絡的模型;※表示引入動態多池化層的模型;加粗數據表示最優指標值,下同。
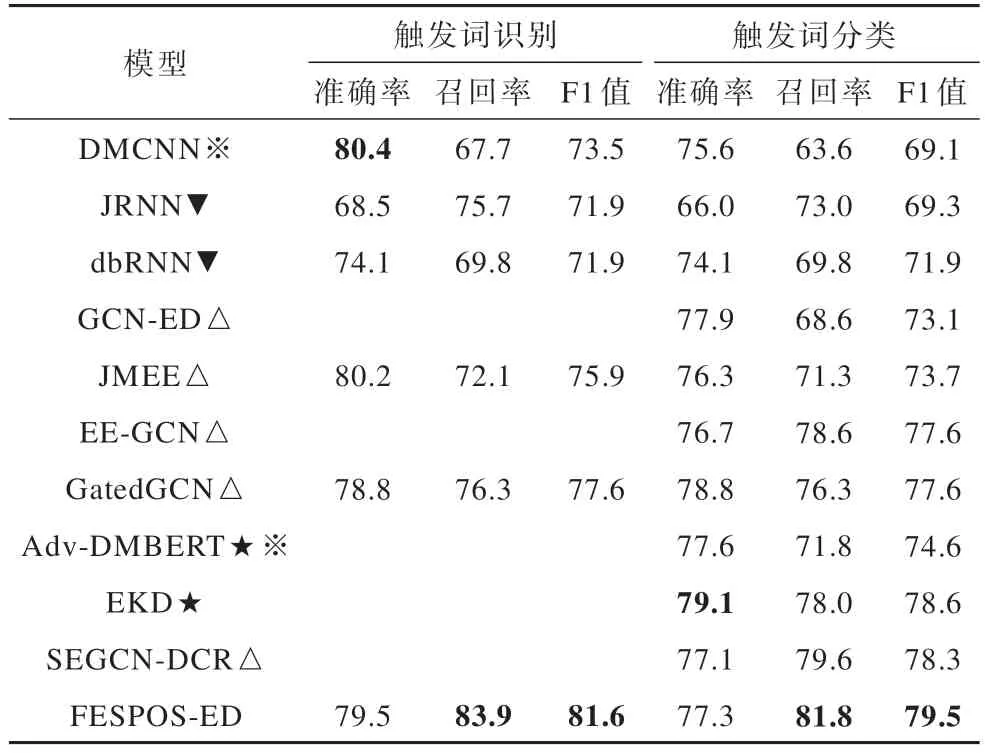
表2 ACE2005 數據集上的實驗結果Table 2 Experimental results on the ACE2005 dataset %
在ACE2005 數據集上的實驗結果表明,所提模型在觸發詞識別任務中的性能有明顯提升,且在事件檢測任務上的性能優于其他對比模型,召回率和F1 值都有所提升,尤其是對比先進的SEGCNDCR[24]模型,召回率和F1 值分別提升了2.2 和1.2 個百分點。這充分說明了所提模型在事件檢測任務上的有效性和先進性。在ACE2005 數據集上,EKD[12]模型的觸發詞分類準確率最高,這是因為其引入了豐富的開放域觸發詞知識并利用師生模型減少注釋中的內在偏差,但召回率較低。由表2 實驗結果可以看出:
1)與擴充 訓練實 例的模 型Adv-DMBERT[10]和EKD[12]相比,所提模型在F1 值上均有所提升,分別提升了4.9 和0.9 個百分點。這可能是因為它們生成的語料庫都是同質的,仍然存在內置偏差,并且在一定程度上受限于知識庫的低覆蓋情況,而所提模型不擴充句子級訓練實例,在詞粒度上進行語義擴展,避免了引入噪聲干擾模型訓練,且可以挖掘候選觸發詞上下文中的豐富語義。
2)與基于 循環神 經網絡 的模型JRNN[29]、dbRNN[30]相比,所提模型性能更加優越,在F1 值上分別提升了10.2 和7.6 個百分點。這可能是因為循環神經網絡無法解決句子長距離依賴問題,而所提模型同時利用詞粒度和句子粒度語義信息有效地避免了此問題。
3)與基于 圖神經 網絡的模型GCN-ED[31]、JMEE[19]、EE-GCN[32]、GatedGCN[20]、SEGCN-DCR[21]相比,所提模型性能均有所提升,在F1 值上分別提高了6.4、5.8、1.9、1.9、1.2 個百分點。這可能是因為GCN 在卷積時對所有鄰居賦予同等的重要性,不能根據節點重要性分配不同的權重,并且GCN 將特征編碼為高階向量,會引入過多額外參數,而所提模型著重對符合觸發詞詞性的候選觸發詞進行語義擴展,關注特定位置符合語境的上下文信息預測,且沒有引入過多參數。
4)與引入 動態多 池化層 的模型DMCNN[17]和Adv-DMBERT[10]相比,所提模型在F1 值上分別提升了10.4 和4.9 個百分點。這可能是因為引入動態多池化層的模型僅關注句子粒度語義信息,沒有重視與觸發詞相關的詞粒度語義擴展信息。
綜上所述,所提模型僅在詞粒度上進行語義擴展,利用詞性篩選縮小候選觸發詞范圍并擴展特定位置的語義信息,不僅考慮了候選觸發詞信息,而且還充分考慮了候選觸發詞與當前語境的關聯關系,同時融合詞粒度語義擴展信息和句子粒度語義信息增強了分類能力,因此性能優于對比模型。
為了進一步驗證所提模型的有效性,在KBP2015數據集上進行實驗,實驗結果如表3 所示。在KBP2015 數據集上的實驗結果表明,所提模型在觸發詞識別與觸發詞分類任務上的性能都有不同程度的提升,其中在觸發詞識別任務上,準確率、召回率和F1 值分別達到了83.5%、65.3%和73.3%,在觸發詞分類任務上準確率、召回率和F1 值分別達到了77.8%、59.6% 和67.5%。TAC Top[27]是在TAC KBP2015 事件檢測中獲得排名第1 的結果,與之相比,所提模型也表現出優異的性能。
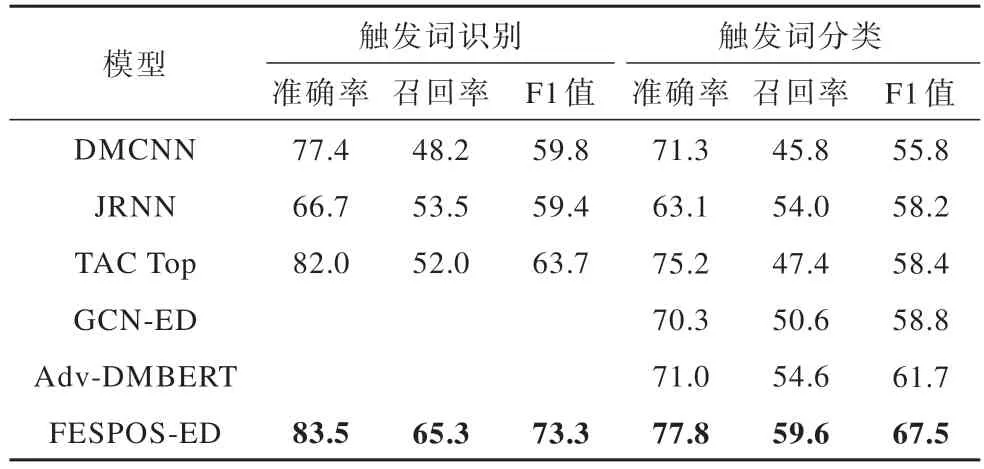
表3 KBP2015 數據集實驗結果Table 3 Experimental results on the KBP2015 dataset %
3.6 稀疏標記數據實驗
當數據標記不平衡時,模型在稀疏標記數據上的表現無法通過整體性能進行衡量。在實驗中根據訓練數據的分布拆分測試集,對ACE2005 數據集中數量小于10 條數據的類別進行測試,并與對比模型在相同實驗條件下進行比較。實驗結果如表4 所示。
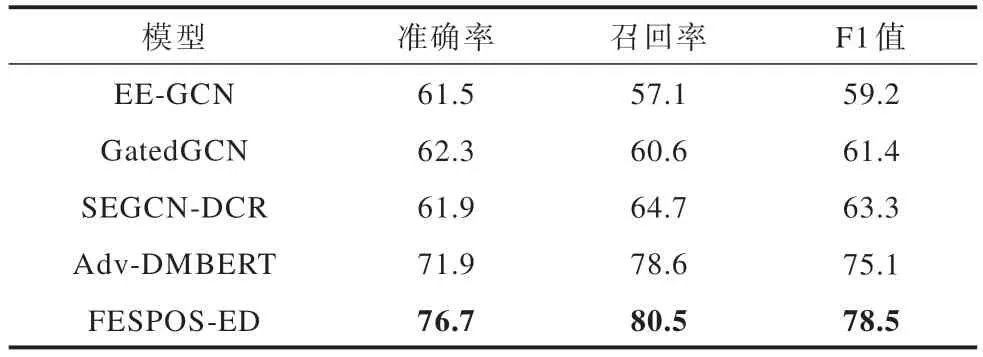
表4 稀疏標記數據實驗結果Table 4 Experimental results of sparse labeled data %
由表4 可知,隨著實驗數據的減少,所提模型的性能會顯著下降,但是在稀疏標記數據上所提模型在各項指標上均有所改善,與擴充訓練實例的模型Adv-DMBERT[10]和在分類損失上進行平衡的模型SEGCN-DCR[21]相比,在3 個指標上均有不同程度的提升,在F1 值上分別提高了3.4 和15.2 個百分點。所提模型在召回率上的改善最為顯著的可能原因為詞性篩選機制可以縮小候選觸發詞范圍,在這些候選觸發詞中極大概率包含真正的觸發詞,從而使更多稀疏標記的觸發詞被模型識別,并且擴充候選觸發詞語義信息,挖掘觸發詞上下文中蘊含的豐富語義信息進行訓練,進而提升事件類型的分類性能。實驗結果表明,所提模型能夠緩解稀疏標記數據得不到有效訓練對模型性能造成的不良影響。
3.7 消融實驗
為了進一步探究模型中各個子網絡的具體作用及其對最終結果的影響,進行消融實驗。在實驗中使用ACE2005 數據集,具體結果如表5 所示。
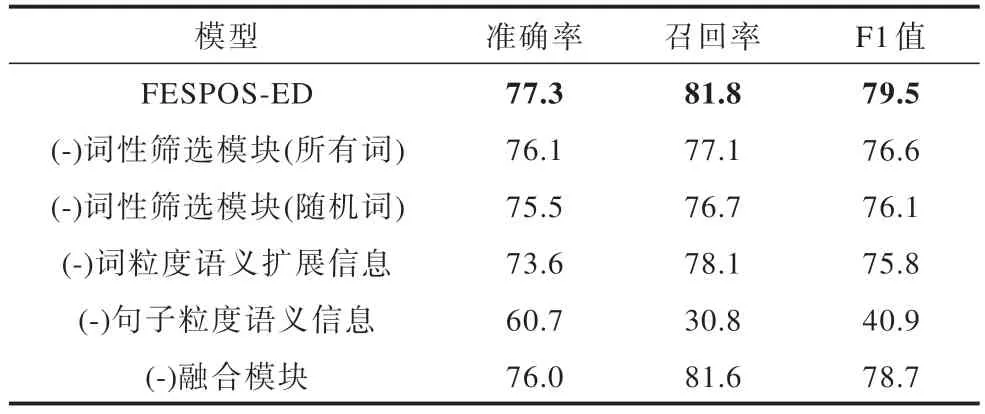
表5 ACE2005 數據集消融實驗結果Table 5 Ablation experimental results on the ACE2005 dataset %
1)對詞性篩選模塊的消融
(-)詞性篩選模塊(所有詞)表示消除詞性篩選模塊,對輸入序列的每個詞進行語義擴展;(-)詞性篩選模塊(隨機詞)表示消除詞性篩選模塊,對輸入序列進行隨機語義擴展。
實驗結果表明,在消除詞性篩選模塊后,模型性能受到影響,原因為無論是對整個輸入序列進行語義擴展,還是對輸入序列進行隨機語義擴展,均有可能引入與觸發詞無關的噪聲,從而降低模型性能。
2)對語義信息模塊的消融
(-)詞粒度語義擴展信息表示消除詞粒度語義擴展信息模塊,僅使用句子粒度語義信息進行事件檢測;(-)句子粒度語義信息表示消除句子粒度語義信息,僅使用詞粒度語義擴展信息進行事件檢測。
實驗結果表明,所提模型在F1 值上有不同程度的下降,分別降低了3.7 和38.6 個百分點,這表明在所提模型中句子粒度語義信息和詞粒度語義擴展信息都是不可或缺的。詞粒度語義擴展信息能夠提供候選觸發詞的語義擴展信息,句子粒度語義信息能夠提供輸入序列的上下文信息,兩種粒度的語義信息融合生成魯棒的語義表征對事件檢測更加有效。
3)對融合模塊的消融
(-)融合模塊表示消除融合模塊,僅將詞粒度語義擴展信息和句子粒度語義信息進行拼接。
實驗結果表明,拼接操作缺少句子粒度語義信息和詞粒度語義擴展信息的交互過程,不能有效融合兩種語義信息。
3.8 實例分析
為了更好地驗證所提模型性能,本節從ACE2005 數據集中挑選了若干條數據。在第1 組數據中,為了驗證所提模型的魯棒性,將2 條數據中的觸發詞換為同義的未見過的觸發詞進行測試。第2 組數據來源于ACE2005 數據集中的稀疏標記數據,為了驗證所提模型的有效性,對2 條稀疏標記數據進行測試。由表6 可以看出:

表6 ACE2005 數據集實例分析Table 6 Case analysis of the ACE2005 dataset
在第1 組數據中,a 句的原始觸發詞是“Bankrupt”,將其替換為數據集中未見過的同義詞“Insolvent”;b 句的原始觸發詞是“fallen”,將其替換為未見過的同義詞“deceased”。由于觸發詞在極大概率上是動詞或名詞,所提模型利用詞性篩選縮小候選觸發詞范圍,在未見過的觸發詞識別及分類上有天然的優勢,并且無論是什么觸發詞都有極大概率包括在特定詞性內,因此在未見過的樣本測試中依舊能夠正確識別,說明了所提模型具有良好的泛化性。
在第2 組數據中,c 句對應的觸發詞是“fined”,事件類型為“Justice:Fine”,該類型在數據集中僅有5 條樣本;d 句對應的觸發詞是“amnesty”,事件類型為“Justice:Pardon”,該類型在數據集中僅有1 條樣本,所提模型能夠正確識別觸發詞和事件類型。實驗結果表明,所提模型在稀疏標記數據中不僅能夠利用特定詞性的詞粒度語義擴展信息正確識別觸發詞,而且能有效利用輸入序列的詞粒度-句子粒度語義信息正確識別事件類型,充分說明了所提模型的有效性和先進性。
4 結束語
針對數據標注不平衡導致稀疏標記數據得不到有效訓練的問題,本文提出融合詞性語義擴展信息的事件檢測模型。通過詞性語義擴展,縮小候選觸發詞范圍的同時挖掘候選觸發詞的上下文中的豐富語義,并融合句子粒度語義信息進行識別和分類,避免訓練受到樣本數量的限制,緩解了稀疏標記數據帶來的影響。實驗結果表明,所提模型在ACE2005和KBP2015 數據集上均具有良好性能,在稀疏標記數據上也取得了具有競爭性的結果。在未來工作中,將對無觸發詞的事件檢測任務進行探索和研究。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
開放教育研究(2020年2期)2020-03-31 01:54:14
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
中華手工(2017年2期)2017-06-06 23:00:31
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
中外會展(2014年4期)2014-11-27 07:46:46
外語學刊(2011年1期)2011-01-22 03:38:33
