基于深度學(xué)習(xí)的自然場(chǎng)景文本檢測(cè)綜述
2024-03-21 08:15:38連哲殷雁君云飛智敏
計(jì)算機(jī)工程 2024年3期
連哲,殷雁君,云飛,智敏
(內(nèi)蒙古師范大學(xué)計(jì)算機(jī)科學(xué)技術(shù)學(xué)院,內(nèi)蒙古 呼和浩特 010022)
0 引言
文字作為人類語言的書面形式,是人類獲取信息和傳遞信息的重要載體。在自然場(chǎng)景中拍攝的以文字為內(nèi)容的圖像,被稱為自然場(chǎng)景文本圖像或場(chǎng)景文本圖像,在自然場(chǎng)景中出現(xiàn)的大量文字信息對(duì)于描述和理解場(chǎng)景內(nèi)容具有積極作用。自然場(chǎng)景文本檢測(cè)作為場(chǎng)景內(nèi)容分析的基礎(chǔ)研究,旨在定位輸入圖像中文本內(nèi)容的位置,廣泛地應(yīng)用于圖像搜索[1]、機(jī)器翻譯[2]、機(jī)器人導(dǎo)航[3]、多媒體檢索[4]、工業(yè)自動(dòng)化[5]等場(chǎng)景理解任務(wù)。本文立足于深度學(xué)習(xí)背景下的自然場(chǎng)景文本檢測(cè)技術(shù),梳理概括目前文本檢測(cè)的主流方法,著重闡述和討論目前主流方法存在的優(yōu)缺點(diǎn)及仿真實(shí)驗(yàn)結(jié)果和環(huán)境設(shè)置。
1 基于深度學(xué)習(xí)的自然場(chǎng)景文本檢測(cè)
近年來,隨著深度學(xué)習(xí)技術(shù)的發(fā)展,基于深度學(xué)習(xí)的場(chǎng)景文本檢測(cè)方法逐漸成為主流。基于深度學(xué)習(xí)的自然場(chǎng)景文本檢測(cè)方法大致可以分為基于檢測(cè)框的文本檢測(cè)方法、基于分割的文本檢測(cè)方法、基于檢測(cè)框和分割的混合文本檢測(cè)方法和其他文本檢測(cè)方法。
1.1 基于檢測(cè)框的文本檢測(cè)方法
基于檢測(cè)框的文本檢測(cè)方法主要通過檢測(cè)包圍框?qū)ψ匀粓D像中文本所在區(qū)域進(jìn)行限定。文獻(xiàn)[6]提出的目標(biāo)檢測(cè)模型(Faster R-CNN)在目標(biāo)檢測(cè)領(lǐng)域取得了很好的結(jié)果,繼而給文本檢測(cè)領(lǐng)域帶來了巨大的突破。基于檢測(cè)框的文本檢測(cè)方法根據(jù)檢測(cè)框粒度的不同,分為基于文本區(qū)域建議的方法和基于文本組件建議的方法。
1.1.1 基于文本區(qū)域建議的文本檢測(cè)方法
受到目標(biāo)檢測(cè)算法的啟發(fā),許多研究人員將基于深度學(xué)習(xí)模型的目標(biāo)檢測(cè)方法用到文本檢測(cè)中,通過選擇性搜索算法[7]生成多個(gè)文本候選區(qū)域,通過篩選文本候選框并微調(diào)候選框位置以及大小,將候選區(qū)域分為文本區(qū)域和非文本區(qū)域。
文獻(xiàn)[8]提出一種基于文本傾斜角信息的旋轉(zhuǎn)區(qū)域建議網(wǎng)絡(luò)(RRPN),其中旋轉(zhuǎn)感興趣區(qū)域(RRoI)池化層為文本區(qū)域分類器設(shè)計(jì)特征圖提供了一個(gè)任意方向的方案,解決了文本檢測(cè)中檢測(cè)區(qū)域具有旋轉(zhuǎn)角度的問題。RRPN 候選框方向是通過旋轉(zhuǎn)角度參數(shù)控制,對(duì)旋轉(zhuǎn)候選框的邊框進(jìn)行回歸,增強(qiáng)了對(duì)于傾斜文本的檢測(cè)效果,但是RRPN 不能檢測(cè)彎曲文本,且RRoI 通過最大池化方式將旋轉(zhuǎn)區(qū)域轉(zhuǎn)換為固定大小區(qū)域,存在RoI 與提取特征之間未對(duì)準(zhǔn)的問題。為解決該問題,文獻(xiàn)[9]提出一種使用點(diǎn)代替錨的無錨區(qū)域建議網(wǎng)絡(luò)(AF-RPN)來代替Faster R-CNN 中傳統(tǒng)的區(qū)域建議網(wǎng)絡(luò)(RPN),擺脫了傳統(tǒng)復(fù)雜的候選框設(shè)計(jì),在水平和多方向的文本檢測(cè)任務(wù)中均有很高的召回率,然而使用點(diǎn)代替錨會(huì)出現(xiàn)檢測(cè)框未完全圍住文本區(qū)域的情況。
針對(duì)長(zhǎng)文本和任意方向文本的問題,研究人員也進(jìn)行了大量研究。文獻(xiàn)[10]提出旋轉(zhuǎn)敏感回歸探測(cè)器(RRD),調(diào)整了單步多框目標(biāo)檢測(cè)器(SSD)[11]的錨定比,以適應(yīng)非規(guī)則形狀的寬高比變化,主要解決了有方向的檢測(cè)框回歸問題。通常地,圖像文本檢測(cè)方法中文本分類和邊界矩形框(BBox)坐標(biāo)回歸兩個(gè)任務(wù)共享同一特征,采用同一特征解決兩個(gè)不同任務(wù),在一定程度上會(huì)導(dǎo)致系統(tǒng)性能下降。RRD 是用兩個(gè)不同設(shè)計(jì)的網(wǎng)絡(luò)分支來分別提取用于文本分類和BBox 坐標(biāo)回歸的任務(wù)特征,不僅減少了旋轉(zhuǎn)敏感特征對(duì)分類的影響,同時(shí)也減少了旋轉(zhuǎn)不變特征對(duì)回歸的影響,從而對(duì)長(zhǎng)文本的檢測(cè)更加準(zhǔn)確,但是對(duì)于字符間距較大的文本行存在無法檢測(cè)整個(gè)邊界且不能處理彎曲文本的問題。文獻(xiàn)[12]同樣基于SSD 模型提出TextBoxes++網(wǎng)絡(luò)以檢測(cè)任意方向的文本區(qū)域,通過四邊形或傾斜的矩形框來表示圖片中的文本區(qū)域,將卷積核大小由3×3 改為3×5的長(zhǎng)卷積核來更好地提取文本特征信息,TextBoxes++網(wǎng)絡(luò)結(jié)構(gòu)復(fù)雜,需要長(zhǎng)時(shí)間對(duì)模型進(jìn)行訓(xùn)練,且因低層特征表達(dá)能力較弱,對(duì)小尺度文本檢測(cè)的準(zhǔn)確率低。
1.1.2 基于文本組件建議的文本檢測(cè)方法
當(dāng)前基于文本區(qū)域建議的文本檢測(cè)方法大多是由目標(biāo)檢測(cè)算法改進(jìn)而來,但是目標(biāo)檢測(cè)中所檢測(cè)的目標(biāo)一般是較大的物體。在文本檢測(cè)時(shí),因?yàn)樽匀粓?chǎng)景中文本、尺寸和寬高比不同,而且存在文本行彎曲的情況,所以候選框的尺寸大小很難完全接近文本,并且對(duì)候選框位置進(jìn)行微調(diào)的方法同樣很難達(dá)到預(yù)期結(jié)果。
基于文本組件建議的方法是將文本區(qū)域看作很多個(gè)連續(xù)文本組件,其中文本組件是字符或文本的一部分。文本組件建議的方法通過檢測(cè)文本組件區(qū)域,將文本組件連接成文本區(qū)域,實(shí)現(xiàn)文本檢測(cè)任務(wù)。
文獻(xiàn)[13]提出的DeepText 首次將目標(biāo)檢測(cè)算法成功應(yīng)用于自然場(chǎng)景文本檢測(cè),基于GoogleNet 中Inception 模塊的理念設(shè)計(jì)Inception RPN,通過并行使用不同尺度的卷積核和池化操作來提取多尺度的特征信息,以該方式生成的候選框能捕捉文本區(qū)域的形狀、紋理、上下文等特征,但是DeepText 主要針對(duì)英文文本進(jìn)行訓(xùn)練和設(shè)計(jì),且網(wǎng)絡(luò)性能在很大程度上依賴于大規(guī)模訓(xùn)練數(shù)據(jù)集,如果訓(xùn)練數(shù)據(jù)集不充分或不具代表性,則可能導(dǎo)致模型的泛化能力不佳。
文獻(xiàn)[14]提出連接文本建議網(wǎng)絡(luò)(CTPN),采用垂直錨檢測(cè)水平方向文本,并且網(wǎng)絡(luò)中加入了雙向長(zhǎng)短期記憶(LSTM)網(wǎng)絡(luò)[15]來學(xué)習(xí)文字序列特征,有利于獲得檢測(cè)框和置信度,但是CTPN 加入了LSTM 后,在訓(xùn)練階段容易導(dǎo)致梯度爆炸,并且沒有很好地對(duì)多方向文本進(jìn)行處理。為此,文獻(xiàn)[16]在特定環(huán)境下改進(jìn)了SSD 算法,提出SegLink 多方向文本檢測(cè)方法,檢測(cè)含有單詞或文本行的局部區(qū)域,將局部區(qū)域連接組成完整的文本檢測(cè)框,實(shí)驗(yàn)結(jié)果表明該方法可以檢測(cè)多方向和任意長(zhǎng)度的文本,但是存在單詞或文本行閾值α和β需要人工設(shè)置的缺陷,且無法檢測(cè)間隔很遠(yuǎn)或形變的文本。
從多方向文本檢測(cè)的角度出發(fā),文獻(xiàn)[17]提出深度關(guān)系推理圖(DRRG)網(wǎng)絡(luò),該網(wǎng)絡(luò)基于卷積神經(jīng)網(wǎng)絡(luò)(CNN)的文本組件建議網(wǎng)絡(luò)預(yù)測(cè)文本組件的幾何屬性,利用局部圖建立不同文本組件之間的連接,并最終采用圖卷積網(wǎng)絡(luò)進(jìn)行文本組件深度關(guān)系推理,實(shí)現(xiàn)文本組件聚合。DRRG 網(wǎng)絡(luò)拋棄了錨的思想,無需預(yù)先考慮文本框的大小,使用了新的文本組件連接方式,真正實(shí)現(xiàn)了對(duì)任意形狀文本的預(yù)測(cè),但是該網(wǎng)絡(luò)檢測(cè)結(jié)果過度依賴文本組件建議網(wǎng)絡(luò)所建議的單個(gè)詞檢測(cè)框。
基于檢測(cè)框的文本檢測(cè)方法的機(jī)制、適用場(chǎng)景、優(yōu)勢(shì)和局限性如表1 所示,實(shí)驗(yàn)條件和檢測(cè)結(jié)果對(duì)比如表2 所示。
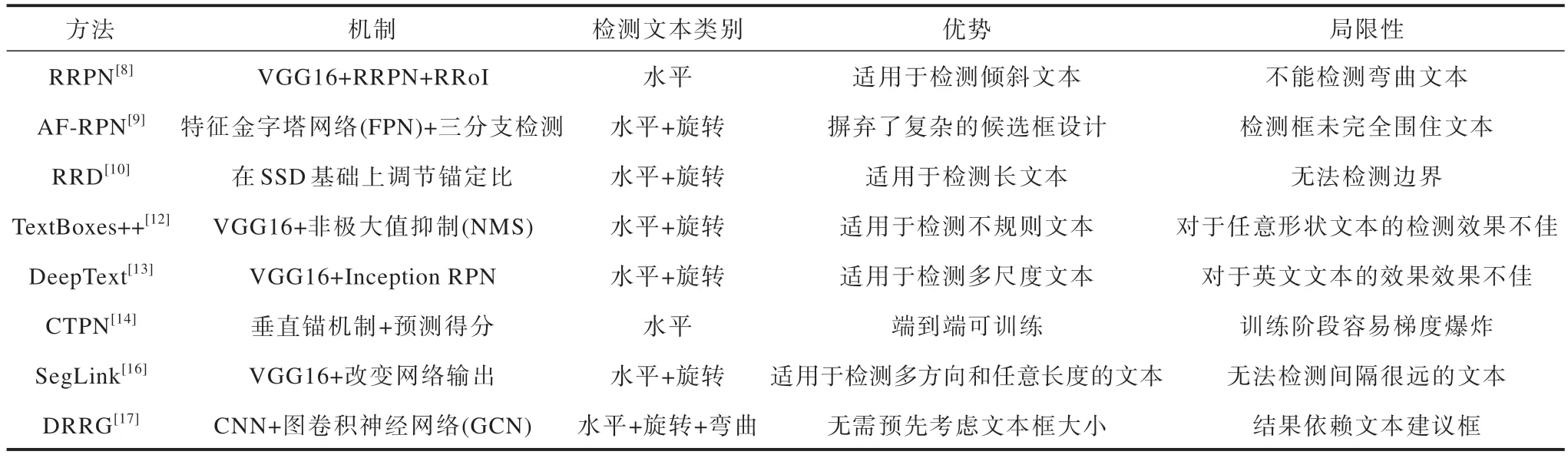
表1 基于檢測(cè)框的文本檢測(cè)方法的機(jī)制、適用場(chǎng)景、優(yōu)勢(shì)和局限性Table 1 Mechanisms,applicable scenarios,advantages,and limitations of text detection methods based on detection boxes
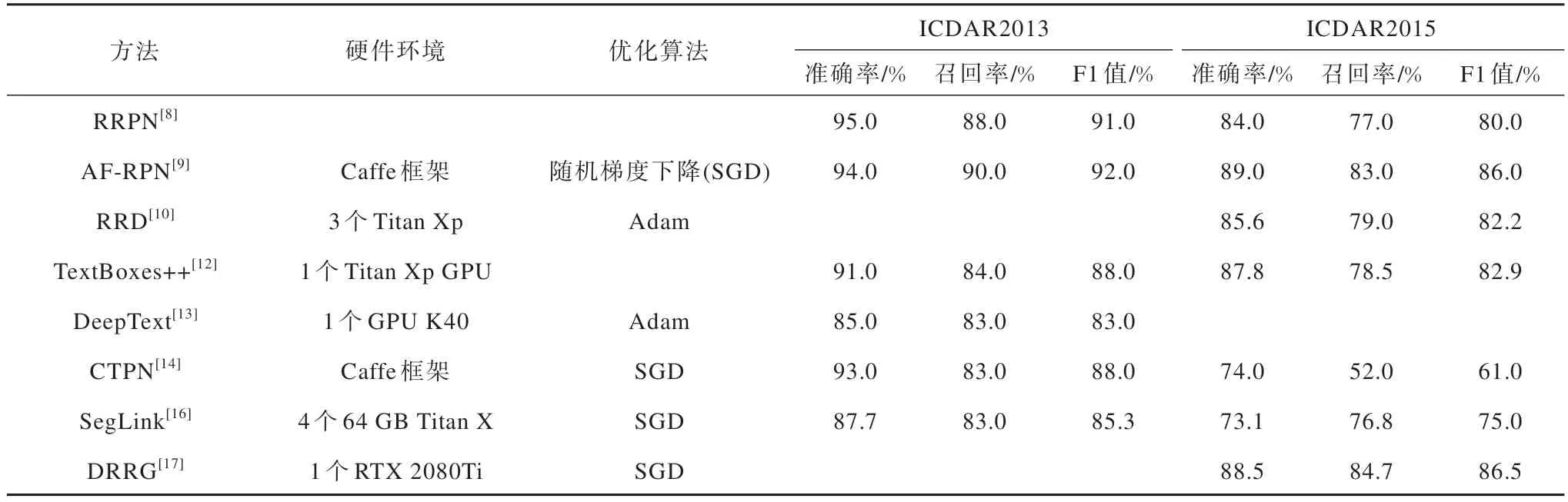
表2 基于檢測(cè)框的文本檢測(cè)方法的仿真實(shí)驗(yàn)結(jié)果Table 2 Simulation experimental results of text detection methods based on detection boxes
1.2 基于分割的文本檢測(cè)方法
該方法主要借鑒了經(jīng)典的語義分割算法的思路,例如全卷積網(wǎng)絡(luò)(FCN)、FPN[18]和全卷積實(shí)例感知(FCIS)[19]等。基于分割的自然場(chǎng)景文本檢測(cè)方法利用深度卷積和上采樣進(jìn)行特征提取和多級(jí)特征融合,通過對(duì)圖像中每個(gè)像素分類來判斷每個(gè)像素點(diǎn)是否屬于文本區(qū)域,達(dá)到精準(zhǔn)文本區(qū)域分割的目的。
文獻(xiàn)[20]提出端到端的高效和準(zhǔn)確的場(chǎng)景文本(EAST)檢測(cè)網(wǎng)絡(luò),該網(wǎng)絡(luò)利用FCN 和NMS[21]舍棄了中間不必要的步驟,有效減少了檢測(cè)時(shí)間,可以預(yù)測(cè)任何形狀的矩形,但是該網(wǎng)絡(luò)的局限性在于檢測(cè)器處理文本實(shí)例的大小和網(wǎng)絡(luò)的感受野成正比,限制了網(wǎng)絡(luò)預(yù)測(cè)長(zhǎng)文本的能力,同時(shí)該網(wǎng)絡(luò)在一定程度上對(duì)垂直文本實(shí)例存在預(yù)測(cè)遺漏或預(yù)測(cè)準(zhǔn)確率不高的問題。文獻(xiàn)[22]是在EAST 網(wǎng)絡(luò)的基礎(chǔ)上提出一種基于實(shí)例分割的自然場(chǎng)景文本檢測(cè)算法(PixelLink),與EAST 網(wǎng)絡(luò)技術(shù)的差異在于:EAST網(wǎng)絡(luò)基于檢測(cè)框回歸和圖像分割,而PixelLink 只使用圖像分割。因?yàn)槲谋緳z測(cè)需要更為精確的定位,只采用圖像分割不能準(zhǔn)確地定位距離較近的文本實(shí)例,所以PixelLink 還采用了Link 的思想,不僅預(yù)測(cè)像素是否為文本,并且預(yù)測(cè)文本的像素之間是否可以進(jìn)行連接組成一個(gè)文本框。然而,PixelLink 網(wǎng)絡(luò)在針對(duì)不同數(shù)據(jù)集進(jìn)行預(yù)測(cè)時(shí)需要調(diào)整Pixel 和Link 兩個(gè)閾值,并且設(shè)置的后處理方法有所不同,使模型檢測(cè)過程較為復(fù)雜。
后處理是基于分割的文本檢測(cè)方法的關(guān)鍵階段,但是后處理階段一般很耗時(shí)。文獻(xiàn)[23]基于可微二值化(DB)后處理機(jī)制提出DBNet。傳統(tǒng)的基于語義分割算法后處理通過一個(gè)固定的閾值對(duì)特征圖進(jìn)行二值化操作,而DBNet 添加了一個(gè)可學(xué)習(xí)的閾值映射,通過圖片特征學(xué)習(xí)像素閾值,這樣便無須計(jì)算二值化圖,減少了時(shí)間消耗,提高了網(wǎng)絡(luò)性能。但是,DBNet 網(wǎng)絡(luò)只關(guān)注預(yù)測(cè)文本區(qū)域的準(zhǔn)確性,無視其他非文本區(qū)域類別的差異,導(dǎo)致學(xué)習(xí)到的特征較為分散。
DBNet 一經(jīng)提出便引起眾多研究人員的關(guān)注,并在其基礎(chǔ)上進(jìn)行改進(jìn),以實(shí)現(xiàn)更好的檢測(cè)性能。文獻(xiàn)[24]引入殘差校正分支(RCB)使得輕量級(jí)網(wǎng)絡(luò)更準(zhǔn)確地定位文本區(qū)域的位置,設(shè)計(jì)一種基于FPN的雙分支注意力特征融合(TB-AFF)模塊結(jié)合局部注意力和全局注意力,提高文本特征信息表示能力。由于引入了兩個(gè)模塊,因此模型復(fù)雜度提高,訓(xùn)練時(shí)間有所增加。TB-AFF 模塊結(jié)構(gòu)如圖1 所示,其中,C4與C5表示網(wǎng)絡(luò)后兩層輸出,X表示合成特征,L(X)表示三維注意力權(quán)重,通過兩層深度可分離卷積得到,g(X)表示一維注意力權(quán)重,通過一層全局平均池化與兩層深度可分離卷積得到,X'表示合成權(quán)重,P5表示最終輸出特征。
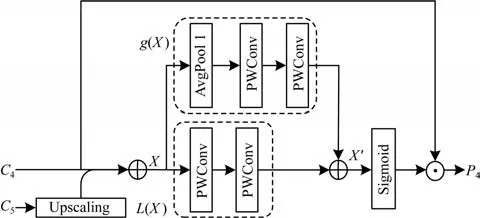
圖1 TB-AFF 模塊結(jié)構(gòu)Fig.1 Structure of TB-AFF module
文獻(xiàn)[25]引入多尺度池化(MP)模塊,通過不同高寬比窗口的空間池化操作來獲取場(chǎng)景文本圖片中不同層次的上下文信息,利用雙向特征融合(BiFF)結(jié)構(gòu)改善網(wǎng)絡(luò)的信息傳播路徑。由于池化窗口為正方形,因此無法很好地適應(yīng)彎曲文本。MP 模塊結(jié)構(gòu)如圖2 所示,其中,ConvBN 與ReLU 表示標(biāo)準(zhǔn)的卷積+歸一化+激活函數(shù)操作,4 個(gè)不同的AvgPool 表示不同池化核的平均池化,Concat 表示級(jí)聯(lián)。
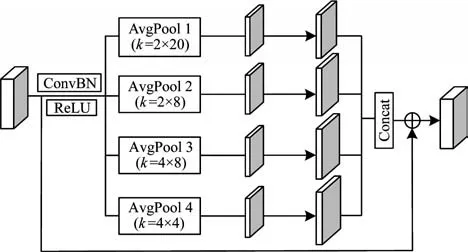
圖2 MP 模塊結(jié)構(gòu)Fig.2 Structure of MP module
文獻(xiàn)[26]在骨干網(wǎng)絡(luò)中嵌入注意力機(jī)制,增強(qiáng)特征提取能力,引入深度多尺度特征融合(DMFF)模塊充分挖掘并有效融合文本實(shí)例在不同尺度上的特征信息。由于特征提取過程中的信息丟失,因此DMFF 模塊在文本實(shí)例與背景具有較強(qiáng)相似性時(shí)表現(xiàn)出較差的檢測(cè)性能。DMFF 模塊結(jié)構(gòu)如圖3 所示,其中,P2、P3、P4、P5分別表示骨干網(wǎng)絡(luò)提取的4 層特征,f表示將4 層特征融合后的特征,F(xiàn)表示經(jīng)過增強(qiáng)的用于最終檢測(cè)任務(wù)的特征。
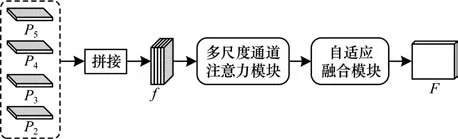
圖3 DMFF 模塊結(jié)構(gòu)Fig.3 Structure of DMFF module
LIAO等[27]對(duì)DBNet 進(jìn)行改進(jìn),提出DBNet++網(wǎng)絡(luò)模型,設(shè)計(jì)自適應(yīng)尺度融合(ASF)模塊,將一個(gè)空間注意力模塊集成到一個(gè)階段性的注意力模塊中,階段注意力模塊學(xué)習(xí)不同尺度特征圖的權(quán)重,空間注意力模塊學(xué)習(xí)跨空間維度的注意力,從而實(shí)現(xiàn)尺度魯棒的特征融合。雖然DBNet++在多個(gè)基準(zhǔn)測(cè)試上取得了最高精度,但還是很難處理文本中的文本的情況。
目前,研究人員提出可以對(duì)任意形狀的文本圖片進(jìn)行文本檢測(cè)的方法,但通常算法運(yùn)行時(shí)間較長(zhǎng)。基于算法運(yùn)行時(shí)間和效率的考量,文獻(xiàn)[28]提出一種高效準(zhǔn)確的任意形狀文本檢測(cè)器(PAN),由特征金字塔增強(qiáng)模塊(FPEM)和特征融合模塊(FFM)構(gòu)成,其中,F(xiàn)PEM 用于引入多級(jí)信息來指導(dǎo)分割,F(xiàn)FM 將不同深度的FPEM 特征融入最終分割特征,可學(xué)習(xí)的后處理方法應(yīng)用在像素聚合(PA)模塊,通過預(yù)測(cè)相似性向量對(duì)文本像素進(jìn)行準(zhǔn)確融合。實(shí)驗(yàn)結(jié)果表明,PAN 提升了文本檢測(cè)效率,對(duì)長(zhǎng)文本和密集文本檢測(cè)效果較好,但是PAN 使用輕量級(jí)CNN 進(jìn)行特征提取,導(dǎo)致所提取的特征感受野較小且表達(dá)能力較弱。
文獻(xiàn)[29]使用自適應(yīng)通道注意力(ACA)機(jī)制,通過局部跨通道交互獲得更具代表性的文本特征,利用FPEM 融合低層和高層信息進(jìn)一步增強(qiáng)不同尺度的特征,提出一種加權(quán)感知損失(WAL),通過調(diào)整文本實(shí)例的權(quán)重來增強(qiáng)魯棒性。實(shí)驗(yàn)結(jié)果表明,該方法可對(duì)任意形狀的文本實(shí)現(xiàn)檢測(cè),但是在復(fù)雜背景下容易將背景圖案檢測(cè)為文本。
分離相鄰文本實(shí)例是一項(xiàng)很難的挑戰(zhàn)。文獻(xiàn)[30]提出一個(gè)二維漸進(jìn)核,可滿足自然場(chǎng)景中各種四邊形文本和曲面文本檢測(cè)任務(wù)的要求,設(shè)計(jì)定向池化模塊,采用不同方向的集合來獲取更多的文本信息,并設(shè)計(jì)基于分水嶺算法的后處理方法。該方法能夠魯棒地檢測(cè)出文本尺度變化較大的文本,但是在處理一些針對(duì)稀有訓(xùn)練數(shù)據(jù)的文本嵌入時(shí)存在困難。
基于分割的文本檢測(cè)方法的機(jī)制、適用場(chǎng)景、優(yōu)勢(shì)和局限性如表3 所示,實(shí)驗(yàn)條件和檢測(cè)結(jié)果對(duì)比如表4 所示。
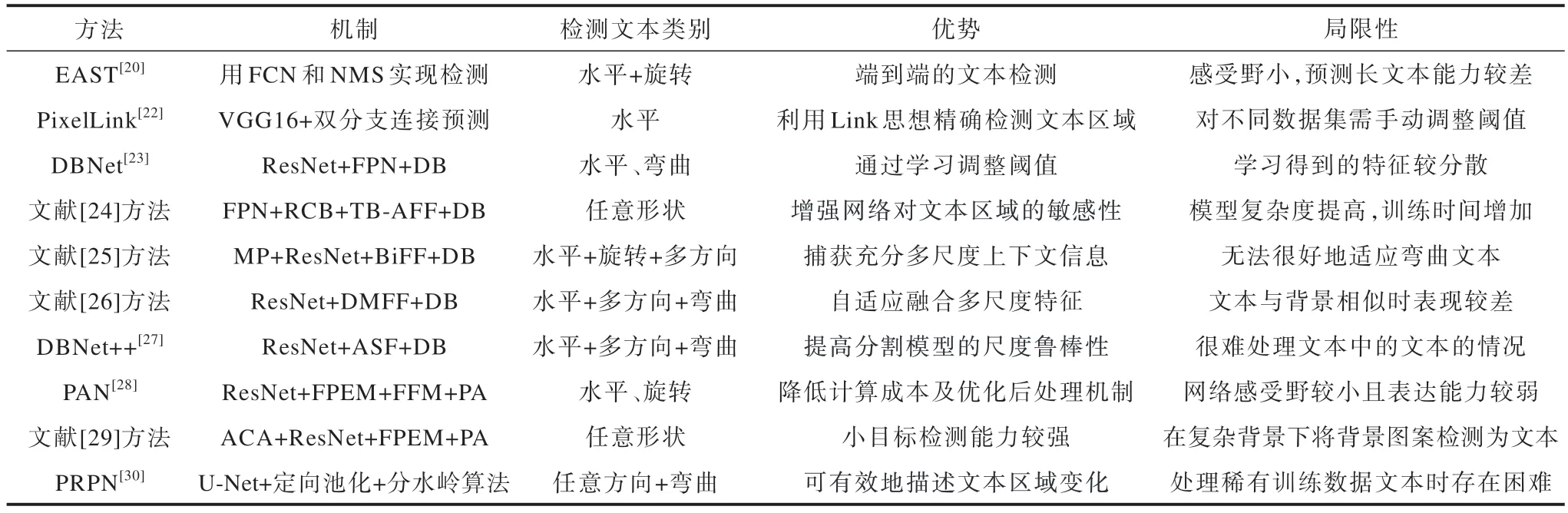
表3 基于分割的文本檢測(cè)方法的機(jī)制、適用場(chǎng)景、優(yōu)勢(shì)和局限性Table 3 Mechanisms,applicable scenarios,advantages,and limitations of segmentation-based text detection methods
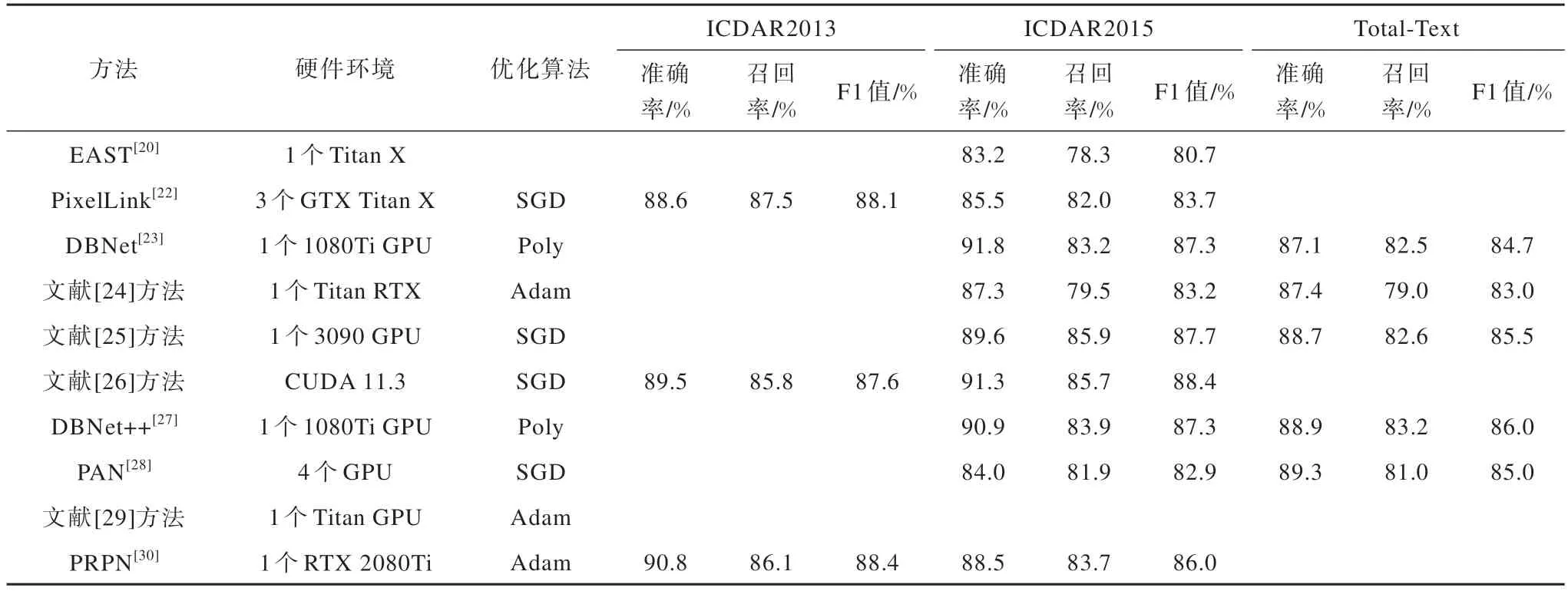
表4 基于分割的文本檢測(cè)方法的仿真實(shí)驗(yàn)結(jié)果Table 4 Simulation experimental results of segmentation-based text detection methods
1.3 基于檢測(cè)框和分割的混合文本檢測(cè)方法
基于分割的文本檢測(cè)方法適合不規(guī)則文本的檢測(cè),但對(duì)小文本區(qū)域的特征響應(yīng)信號(hào)弱。基于檢測(cè)框的方法能夠彌補(bǔ)小文本捕獲的缺陷,但是容易產(chǎn)生文本密集區(qū)域的錨點(diǎn)匹配困難的問題。針對(duì)上述問題,研究人員提出兩者混合的文本檢測(cè)方法。
文獻(xiàn)[31]提出融合文本分割網(wǎng)絡(luò)(FTSN),該網(wǎng)絡(luò)在提取特征過程中結(jié)合了多級(jí)特征,是FPN 和FCIS 的組合。在FTSN 中,位置敏感模塊用于提取文本分類特征和邊框回歸特征。文本分類特征主要包括像素屬于文本還是非文本的特征以及屬于檢測(cè)框K2 塊不同區(qū)域的特征。邊框回歸特征包含文本K2塊不同區(qū)域的坐標(biāo)位置特征。FTSN 模型利用語義分割和區(qū)域建議的文本檢測(cè)的優(yōu)點(diǎn),同時(shí)進(jìn)行檢測(cè)和分割文本實(shí)例。然而,F(xiàn)TSN 模型生成四邊形矩形框表示文本區(qū)域,在檢測(cè)不規(guī)則文本時(shí)效果欠佳。文獻(xiàn)[32]以FTSN 網(wǎng)絡(luò)為基礎(chǔ)提出IncepText網(wǎng)絡(luò),實(shí)質(zhì)是將GoogleNet 網(wǎng)絡(luò)中Inception 結(jié)構(gòu)融入FTSN 網(wǎng)絡(luò)。通過Inception 結(jié)構(gòu)中設(shè)計(jì)的多個(gè)不同尺度卷積核來達(dá)到檢測(cè)不同大小和高寬比文本的目的,同時(shí)使用可變形的RoI池化來代替RoI池化。因?yàn)橐肓丝勺冃蔚木矸e核以及在池化操作中加入了方向參數(shù),所以感受野能夠?qū)Σ灰?guī)則的興趣區(qū)域進(jìn)行自適應(yīng),使得對(duì)不規(guī)則文本特征有很好的提取效果,提高了文本檢測(cè)的性能,但是網(wǎng)絡(luò)模塊較多,訓(xùn)練時(shí)間較長(zhǎng)。
文獻(xiàn)[33]提出監(jiān)督金字塔上下文網(wǎng)絡(luò)(SPCNet),該網(wǎng)絡(luò)采用文本上下文模塊(TCM)提取全局上下文語義信息,對(duì)文本建議網(wǎng)絡(luò)提取的文本矩形框進(jìn)行再評(píng)分,以有效抑制文本建議網(wǎng)絡(luò)生成的文本區(qū)域矩形框中存有背景區(qū)域的假陽(yáng)性(FP)現(xiàn)象。同樣地,通過抑制FP 現(xiàn)象提高性能的有ContourNet 網(wǎng)絡(luò)[34],利用Adaptive-RPN 模塊來提升建議質(zhì)量,并且在分割階段利用再評(píng)分機(jī)制來抑制FP,降低最終檢測(cè)結(jié)果中出現(xiàn)的誤檢率。該方法在對(duì)比實(shí)驗(yàn)中并沒有和SPCNet 這類基于Mask R-CNN的Two-stage 方法進(jìn)行比較,但是在抑制假陽(yáng)性階段會(huì)產(chǎn)生較大計(jì)算量,影響訓(xùn)練速度。
多分支處理能獲得較好的檢測(cè)結(jié)果。文獻(xiàn)[35]提出基于Faster R-CNN 模型的改進(jìn)深度場(chǎng)景文本檢測(cè)(DSTD)模型。該模型使用雙分支對(duì)文本進(jìn)行檢測(cè):第一分支是對(duì)文本進(jìn)行像素分割預(yù)測(cè),即區(qū)分自然場(chǎng)景圖像中的文本像素與非文本像素,并且使用組件模塊將文本像素點(diǎn)連接生成候選框;第二分支對(duì)字符候選框進(jìn)行檢測(cè),輸出一組用于候選的字符。最終兩個(gè)分支所獲得的輸出結(jié)果進(jìn)行融合,通過保留字符區(qū)域的候選框得到最終的檢測(cè)結(jié)果。但是,DSTD網(wǎng)絡(luò)使用雙分支結(jié)構(gòu)導(dǎo)致網(wǎng)絡(luò)結(jié)構(gòu)復(fù)雜,訓(xùn)練成本較高。文獻(xiàn)[36]提出多方向場(chǎng)景文本(MOST)網(wǎng)絡(luò)。該網(wǎng)絡(luò)主要由文本/非文本分類分支、定位分支、位置敏感圖預(yù)測(cè)分支構(gòu)成。文本/非文本分類分支以像素級(jí)的方式區(qū)分文本和非文本區(qū)域。定位分支首先構(gòu)建粗略的文本建議框,隨后文本建議框經(jīng)過文本特征對(duì)齊與文本/非文本分類分支生成的特征圖進(jìn)行融合,對(duì)粗略文本建議框進(jìn)行細(xì)化。位置敏感圖預(yù)測(cè)分支主要用于生成四通道的位置敏感圖,并且將其與細(xì)化后文本建議框輸入位置感知非極大值抑制(PANMS)模塊,以融合所有網(wǎng)絡(luò)預(yù)測(cè)得到的正檢測(cè)框,最終得到文本實(shí)例區(qū)域。與標(biāo)準(zhǔn)NMS 相比,PANMS 能夠花費(fèi)更少的時(shí)間,產(chǎn)生更多的準(zhǔn)確結(jié)果,但由于三分支并行處理,因此計(jì)算量較大。
文獻(xiàn)[37]提出基于動(dòng)態(tài)卷積的文本檢測(cè)器(Dtext),該方法采用全卷積單階段(FCOS)策略,可以動(dòng)態(tài)地從多個(gè)特征中為每個(gè)文本實(shí)例生成獨(dú)立的文本實(shí)例感知卷積參數(shù),克服了固定卷積核集不能適應(yīng)所有分辨率的問題,同時(shí)防止了由于實(shí)例的多尺度而導(dǎo)致的信息丟失,但是對(duì)于銳化字體和實(shí)例中的形狀處理效果并不好。
基于檢測(cè)框和分割的混合文本檢測(cè)方法的機(jī)制、適用場(chǎng)景、優(yōu)勢(shì)和局限性如表5 所示,實(shí)驗(yàn)條件和檢測(cè)結(jié)果對(duì)比如表6 所示。

表5 基于檢測(cè)框和分割的混合文本檢測(cè)方法的機(jī)制、適用場(chǎng)景、優(yōu)勢(shì)和局限性Table 5 Mechanisms,applicable scenarios,advantages,and limitations of hybrid text detection methods based on detection boxes and segmentation
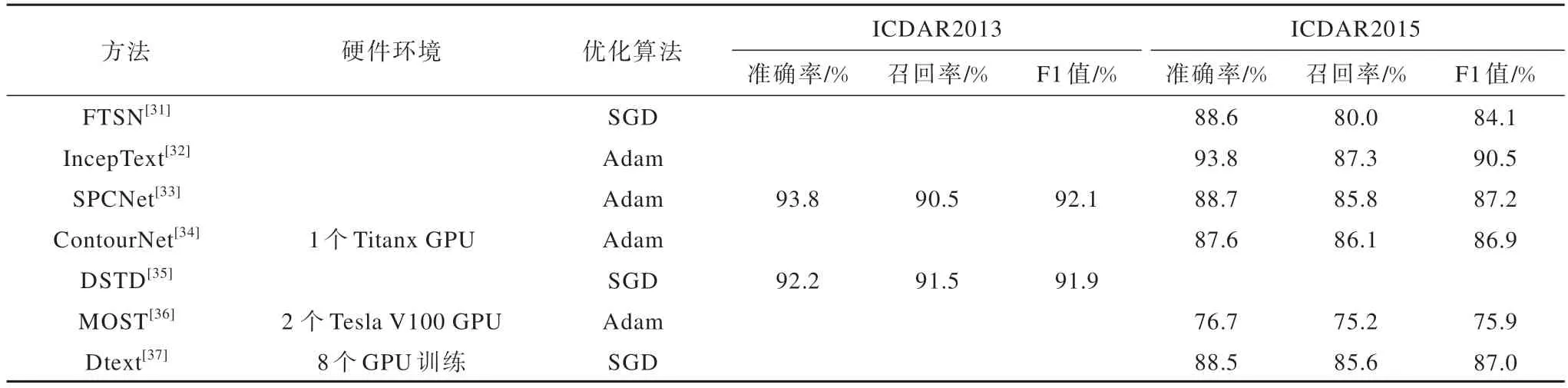
表6 基于檢測(cè)框和分割的混合文本檢測(cè)方法的仿真實(shí)驗(yàn)結(jié)果Table 6 Simulation experimental results of hybrid text detection methods based on detection boxes and segmentation
1.4 其他文本檢測(cè)方法
現(xiàn)有字符級(jí)別的用于文本檢測(cè)的樣本庫(kù)較少,且人工標(biāo)注成本高,而基于深度學(xué)習(xí)的文本檢測(cè)方法的性能在一定程度上取決于訓(xùn)練樣本集的規(guī)模。針對(duì)目前字符級(jí)注釋的文本數(shù)據(jù)集少的問題,文獻(xiàn)[38]提出一種弱監(jiān)督的訓(xùn)練框架(WordSup),構(gòu)建字符檢測(cè)器獲得字符對(duì)應(yīng)的輸出坐標(biāo),利用文本結(jié)構(gòu)分析部分獲得詞坐標(biāo),在弱監(jiān)督訓(xùn)練模塊中利用字符檢測(cè)模型自動(dòng)依據(jù)詞坐標(biāo)生成字符中心點(diǎn)掩碼以更新詞模型,但是WordSup 文本表示框是在矩形錨中形成的,容易受到攝像機(jī)視角變化引起的角色透視變形的影響,此外,還受主干結(jié)構(gòu)的性能限制,即受錨數(shù)量和大小的限制。文獻(xiàn)[39]提出一種基于弱監(jiān)督框架的字符區(qū)域注意力文本(CRAFT)檢測(cè)方法。該方法基于圖形分割思想,但是與圖形分割不同的是不進(jìn)行圖像的像素級(jí)分類,并且進(jìn)行了回歸處理,而且該方法基于字符區(qū)域得分和字符親和力得分將字符連接成文本,其中,字符區(qū)域得分表示該像素是字符中心點(diǎn)的概率,字符親和力得分表示該像素點(diǎn)是相鄰字符中間空白區(qū)域中心的概率,根據(jù)這兩個(gè)得分圖將字符連接成文本,但是CRAFT 使用字符級(jí)邊框生成字符區(qū)域得分和字符親和力得分作為標(biāo)簽,對(duì)單詞重疊區(qū)域檢測(cè)能力較差。
文獻(xiàn)[40]提出用于任意形狀文本檢測(cè)的自適應(yīng)邊界建議網(wǎng)絡(luò)(TextBPN),可以對(duì)任意形狀文本區(qū)域生成標(biāo)準(zhǔn)的邊界而且不需進(jìn)行后處理操作。該網(wǎng)絡(luò)采用多層空洞卷積構(gòu)建分類圖、距離場(chǎng)、方向場(chǎng)和粗略的邊界建議,并且由圖卷積網(wǎng)絡(luò)和循環(huán)神經(jīng)網(wǎng)絡(luò)構(gòu)成編碼-解碼器,通過迭代方式使邊界框逐漸貼合文本區(qū)域。然而,TextBPN 模型較為復(fù)雜,雖然去除了后處理操作,但是訓(xùn)練參數(shù)多,訓(xùn)練時(shí)間長(zhǎng)。
一般的文本檢測(cè)方法是基于像素級(jí)或者文本組件的方法,而以上方法會(huì)對(duì)噪聲較為敏感,且依賴于復(fù)雜的后處理機(jī)制。對(duì)此,文獻(xiàn)[41]提出漸進(jìn)輪廓回歸(PCR)網(wǎng)絡(luò),該網(wǎng)絡(luò)首先構(gòu)建水平文本候選框,在水平框上均勻選擇N個(gè)點(diǎn)并將這N個(gè)點(diǎn)的位置和語義信息進(jìn)行聚合產(chǎn)生旋轉(zhuǎn)文本框,在旋轉(zhuǎn)文本框上均勻選擇N個(gè)點(diǎn)并逐漸將文本邊界框回歸為任意形狀,實(shí)驗(yàn)結(jié)果表明該網(wǎng)絡(luò)對(duì)任意形狀文本的檢測(cè)效率較高,但是最終檢測(cè)結(jié)果受選擇點(diǎn)數(shù)的影響較大。
針對(duì)多尺度文本檢測(cè)問題,文獻(xiàn)[42]提出門控多尺度輸入特征(GMIF)融合方法,該方法從縮小的輸入圖像中以全局文本特征生成模塊(GTFGB)生成局部特征,通過多路徑模塊(MPB)增加骨干網(wǎng)絡(luò)感受野,隨后通過門控循環(huán)單元將這些低分辨率局部特征轉(zhuǎn)換為高分辨率的全局特征,能夠檢測(cè)所有較小文本實(shí)例的淺層骨干網(wǎng)架構(gòu),減輕了為文本實(shí)例選擇最佳Mask 所需的后處理負(fù)擔(dān),但是后處理開銷較大。
針對(duì)文本特征不清晰問題,文獻(xiàn)[43]提出多尺度殘差正交通道注意力網(wǎng)絡(luò)(MS-ROCANet),該方法首先使用細(xì)節(jié)感知特征金字塔模塊(DAFM)捕獲更詳細(xì)的信息,然后使用殘差正交注意力模塊(ROAM)和殘差信道注意力模塊(RCAB)組成的共享復(fù)合關(guān)注頭(SCAH)在多尺度層次上增強(qiáng)文本特征區(qū)域,最后使用關(guān)鍵的全局上下文提取模塊(GCM)捕獲全局上下文信息,在得到分類圖后使用NMS 得到最終檢測(cè)文本框,由于模塊較多,因此訓(xùn)練時(shí)間較長(zhǎng)。
其他文本檢測(cè)方法的機(jī)制、適用場(chǎng)景、優(yōu)勢(shì)和局限性如表7 所示,實(shí)驗(yàn)條件和檢測(cè)結(jié)果對(duì)比如表8所示。

表7 其他文本檢測(cè)方法的機(jī)制、適用場(chǎng)景、優(yōu)勢(shì)和局限性Table 7 Mechanisms,applicable scenarios,advantages,and limitations of other text detection methods
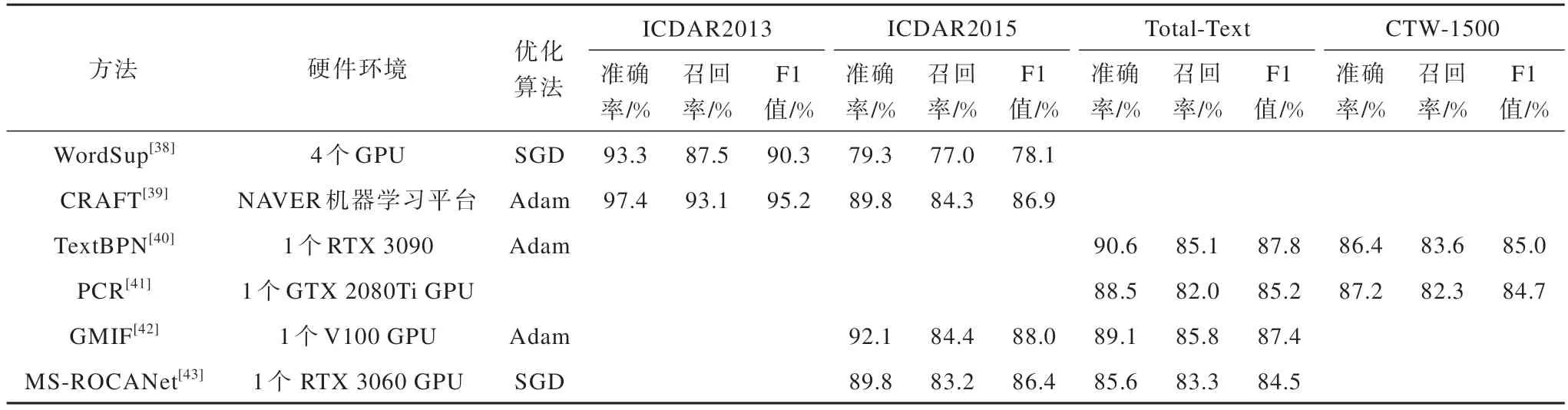
表8 其他文本檢測(cè)方法的仿真實(shí)驗(yàn)結(jié)果Table 8 Simulation ecperimental results of other text detection methods
1.5 總結(jié)與分析
1.5.1 實(shí)用性分析
基于檢測(cè)框的文本檢測(cè)方法通常首先生成多個(gè)候選框,通過對(duì)候選框打分得到包含整個(gè)文本區(qū)域的候選框;然后通過邊框回歸方法,校正候選框使其擬合文本實(shí)例區(qū)域,但是使用該方法后候選框尺寸很難完全接近彎曲文本,導(dǎo)致多數(shù)目標(biāo)檢測(cè)算法在處理不規(guī)則文本時(shí)難以得到較好的效果,其中,基于文本組件建議的文本檢測(cè)方法將檢測(cè)文本區(qū)域劃分為若干連續(xù)的文本組件,每個(gè)組件為文本區(qū)域的一部分,使用區(qū)域建議網(wǎng)絡(luò)檢測(cè)文本組件區(qū)域;最后將文本組件連接為文本檢測(cè)區(qū)域,達(dá)到檢測(cè)文本的目的。
基于檢測(cè)框的文本檢測(cè)方法在訓(xùn)練過程中對(duì)于候選框的預(yù)處理會(huì)導(dǎo)致檢測(cè)速度較慢,為了使候選框能夠更加貼合文本區(qū)域,基于分割的自然場(chǎng)景文本檢測(cè)方法通過語義分割算法,采用深度卷積網(wǎng)絡(luò)進(jìn)行特征提取,通過雙線性插值上采樣方式融合語義特征,通過特定的后處理算法預(yù)測(cè)自然場(chǎng)景圖像中每個(gè)像素是否為文本區(qū)域。由于獲得了像素級(jí)別的標(biāo)簽預(yù)測(cè),因此該類方法對(duì)任意形狀文本檢測(cè)表現(xiàn)出良好的魯棒性,成了文本檢測(cè)的主流方法。此外,該類方法的性能高度依賴于主干網(wǎng)絡(luò)的特征處理方式,且通常需要復(fù)雜的后處理方法以增強(qiáng)像素點(diǎn)之間的關(guān)聯(lián)性。大部分基于分割的方法對(duì)于文字重疊部分檢測(cè)效果較差。
基于檢測(cè)框和分割的混合文本檢測(cè)方法結(jié)合了檢測(cè)框和分割技術(shù),旨在兼顧準(zhǔn)確性和魯棒性。該類方法的主要思想是使用檢測(cè)框來粗略地定位文本區(qū)域。首先生成多個(gè)候選框進(jìn)行篩選和去重,保留可能包含文本的框;然后使用語義分割方法對(duì)候選框進(jìn)行像素級(jí)分割,從而得到精細(xì)的文本邊界,將兩類方法融合得到的分割結(jié)果進(jìn)行后處理;最后得到文本檢測(cè)區(qū)域。此類方法采用多分支結(jié)構(gòu),計(jì)算量較大,通常模型較為復(fù)雜。
其他文本檢測(cè)方法針對(duì)特定問題提出解決方案。例如:通過弱監(jiān)督解決了字符級(jí)注釋的文本數(shù)據(jù)集少的問題;通過字符區(qū)域得分和字符親和力精細(xì)定位小文本;通過多層空洞卷積與圖卷積推理去除后處理過程;通過殘差正交注意力增強(qiáng)不清晰文本。這些方法針對(duì)特定數(shù)據(jù)集能夠取得很好的檢測(cè)結(jié)果,但是泛化能力較弱。
表9 總結(jié)了上述自然場(chǎng)景文本檢測(cè)方法的特性差異及適用場(chǎng)景。

表9 文本檢測(cè)方法的特性差異及適用場(chǎng)景Table 9 Differences in characteristics and applicable scenarios of text detection methods
1.5.2 輕量化分析
基于檢測(cè)框的文本檢測(cè)方法通常使用簡(jiǎn)單而緊湊 的主干 網(wǎng)絡(luò)結(jié) 構(gòu),例 如MobileNet[44]、EfficientNet[45]等,降低網(wǎng)絡(luò)的復(fù)雜性和參數(shù)量,同時(shí)共享卷積特征,減少計(jì)算開銷。但是,這類輕量化措施過于簡(jiǎn)易,僅能略微減少推理時(shí)間。
基于分割的文本檢測(cè)方法輕量化效果較好。為了降低計(jì)算復(fù)雜度和內(nèi)存消耗,基于分割的方法通常采用較小的感受野減少每個(gè)像素的計(jì)算量。后處理的輕量化策略對(duì)提高運(yùn)行速度效果顯著。例如:NMS 只對(duì)一組檢測(cè)框排序和遍歷,極大降低了計(jì)算復(fù)雜度;DB 將二值化過程納入可訓(xùn)練的分割網(wǎng)絡(luò),有效提升推理速度。
基于檢測(cè)框和分割的混合文本檢測(cè)方法和其他文本檢測(cè)方法實(shí)現(xiàn)輕量化的方式多樣。例如:CRAFT 基于密集預(yù)測(cè)的Anchor-Free 檢測(cè)方法,使用通道剪枝和結(jié)構(gòu)剪枝的組合策略,以減少網(wǎng)絡(luò)的參數(shù)和計(jì)算量;WordSup 引入字級(jí)別監(jiān)督減少標(biāo)注成本和模型復(fù)雜度,采用弱監(jiān)督訓(xùn)練策略減少了模型訓(xùn)練的計(jì)算負(fù)擔(dān)和時(shí)間成本;文獻(xiàn)[46]通過知識(shí)蒸餾,最小化教師網(wǎng)絡(luò)和學(xué)生網(wǎng)絡(luò)的預(yù)測(cè)結(jié)果之間的差異,使學(xué)生網(wǎng)絡(luò)學(xué)習(xí)到更豐富的信息,提高檢測(cè)性能。
2 數(shù)據(jù)集設(shè)置
目前,常用的文本檢測(cè)數(shù)據(jù)集有很多,其中文檔分析與識(shí)別國(guó)際會(huì)議(ICDAR)比賽中使用的數(shù)據(jù)集較為典型。文本檢測(cè)數(shù)據(jù)集隨著文本檢測(cè)要求的發(fā)展而發(fā)展,一開始線性文本數(shù)據(jù)集較多,后來漸漸出現(xiàn)了彎曲的文本數(shù)據(jù)集,目前出現(xiàn)了失真的文本數(shù)據(jù)集,即測(cè)試網(wǎng)絡(luò)模型基于弱監(jiān)督情況下的性能。本文整理了實(shí)驗(yàn)中常用的自然場(chǎng)景文本檢測(cè)數(shù)據(jù)集,如表10 所示。
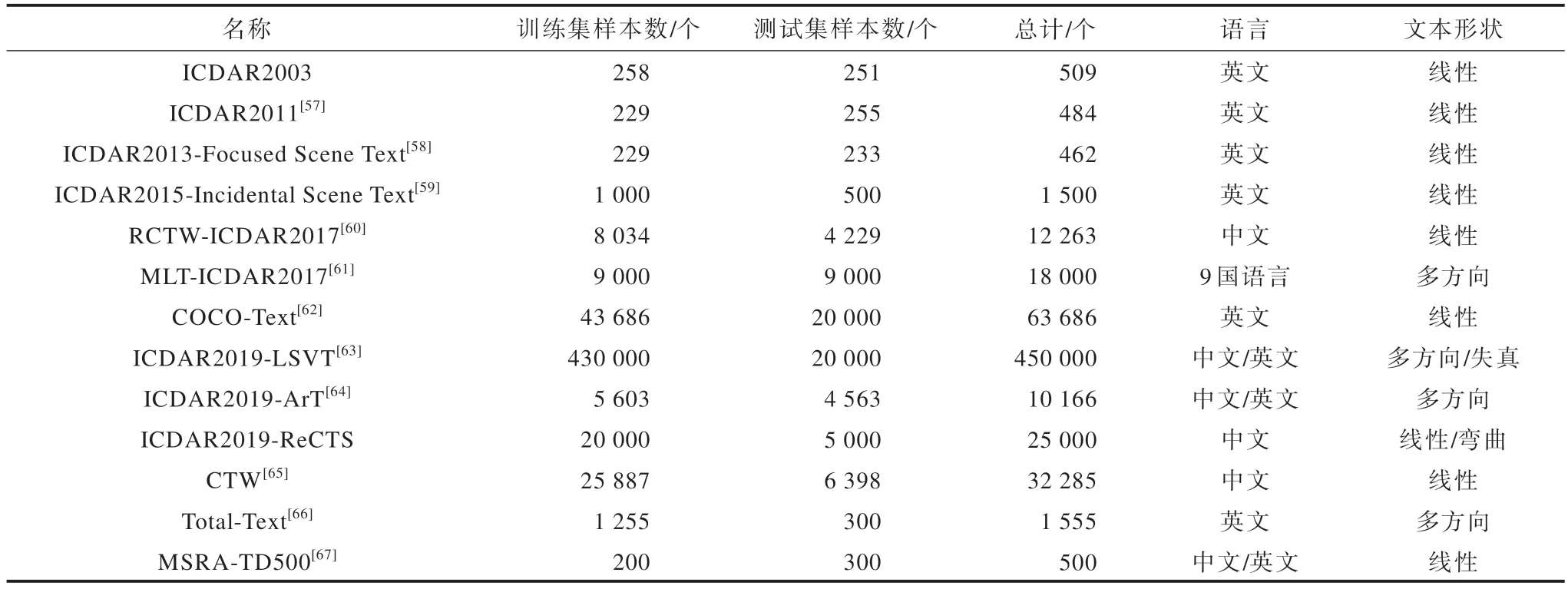
表10 常用的自然場(chǎng)景文本檢測(cè)數(shù)據(jù)集Table 10 Common datasets for natural scene text detection
3 文本檢測(cè)性能評(píng)估
目前,關(guān)于文本檢測(cè)性能評(píng)價(jià)指標(biāo)主要有準(zhǔn)確率(P)、召回率(R)和F1 值(F1)。在通常情況下,召回率是指所有實(shí)際為正例的樣本中被正確地預(yù)測(cè)為正例的樣本數(shù)所占的比例,計(jì)算公式如式(1)所示。準(zhǔn)確率是指預(yù)測(cè)為正例的樣本中實(shí)際為正例的樣本數(shù)所占的比例,計(jì)算公式如式(2)所示。F1 值是基于準(zhǔn)確率和召回率的調(diào)和均值,計(jì)算公式如式(3)所示。
其中:NTruePositives表示被正確地預(yù)測(cè)為正例的樣本數(shù)量;NGroundTruth表示數(shù)據(jù)集中實(shí)際為正例的樣本數(shù)量;NRetrievedItems表示數(shù)據(jù)集中檢索到的與NTruePositives相關(guān)的樣本數(shù)量。
4 未來展望
目前,自然場(chǎng)景文本檢測(cè)研究雖然取得了一定的進(jìn)展,但是仍有一些問題需要解決和思考:
1)在自然場(chǎng)景圖像文本分割時(shí),因自然場(chǎng)景圖像分辨率較高,在進(jìn)行卷積時(shí)參數(shù)量和計(jì)算量較大,而且卷積核的感受野有限,很難捕捉到更多的上下文信息。針對(duì)上述問題,目前主流的解決方法是空洞卷積與注意力機(jī)制相結(jié)合的方法,其中,使用空洞卷積來加大感受野[58],使用注意力機(jī)制來構(gòu)建時(shí)間、空間或時(shí)空兩個(gè)維度的關(guān)系,快速捕獲長(zhǎng)距離依賴,從而獲得更大的感受野。代表性的注意力機(jī)制有壓縮和激 勵(lì)網(wǎng)絡(luò)(SENet)[59]、卷積塊 注意力模塊(CBAM)[60]、選擇性內(nèi)核網(wǎng)絡(luò)(SKNet)[61]、高效通道注意力網(wǎng)絡(luò)(ECA-Net)[62]等。谷歌在2017 年提出基于自注意力機(jī)制的模型(Transformer)[63],通過直接獲取全局信息來避免感受野受限問題。目前,很多基于CNN 的文本檢測(cè)任務(wù)將CNN 替換為Transformer 來提取圖形文字特征,效果均有所改善。例如,文獻(xiàn)[64]提出的用于語義分割的Transformer(SETR)網(wǎng)絡(luò)將語義分割看作是序列到序列的預(yù)測(cè)任務(wù)來提供代替視角,雖然SETR 是針對(duì)目標(biāo)檢測(cè)提出的模型,但是也為自然場(chǎng)景文本檢測(cè)提供了可以借鑒的思路。目前,眾多的研究人員采用將注意力機(jī)制引入語義分割模型中增強(qiáng)語義信息的提取且得到了不錯(cuò)的效果。因此,將注意力機(jī)制應(yīng)用到基于分割的文本檢測(cè)領(lǐng)域有著廣闊的前景。
2)任意形狀文本檢測(cè)較為困難。針對(duì)上述問題,研究人員進(jìn)行了很多嘗試,提出了TextBPN、DRRG 等模型。以上模型借鑒了基于圖像語義分割任務(wù)的圖模型(Graph-FCN)[65]。Graph-FCN 模型將圖卷積引入語義分割任務(wù),將圖像語義分割中的像素分類問題轉(zhuǎn)換為圖節(jié)點(diǎn)分類問題,并且相關(guān)研究已證明通過圖卷積的關(guān)系推理可以更好地檢測(cè)任意形狀的文本實(shí)例。但是,如何通過圖片語義特征來構(gòu)建節(jié)點(diǎn)圖關(guān)系輔助自然場(chǎng)景文本檢測(cè)任務(wù)仍是一個(gè)值得深入研究的課題。
3)字符級(jí)和像素級(jí)標(biāo)注的公開數(shù)據(jù)集很少,且人工標(biāo)記的方法耗時(shí)耗力。針對(duì)數(shù)據(jù)集規(guī)模較小的問題,通常使用數(shù)據(jù)增強(qiáng)的方法進(jìn)行數(shù)據(jù)集擴(kuò)容,但是會(huì)導(dǎo)致模型泛化能力較弱。弱監(jiān)督學(xué)習(xí)和半監(jiān)督學(xué)習(xí)在一定程度上解決了數(shù)據(jù)集少的問題。研究人員通過生成對(duì)抗網(wǎng)絡(luò)(GAN)[66]和去噪擴(kuò)散概率模型(DDPM)[67]生成的偽標(biāo)簽實(shí)現(xiàn)樣本的多樣性生成,以滿足基于深度學(xué)習(xí)的文本分割模型對(duì)數(shù)據(jù)集規(guī)模的需求。文獻(xiàn)[68-72]展示了近年來基于生成對(duì)抗網(wǎng)絡(luò)和去噪擴(kuò)散概率模型應(yīng)用到語義分割和目標(biāo)檢測(cè)任務(wù)中所取得的成果。可見,已有越來越多的研究人員開始關(guān)注基于生成對(duì)抗網(wǎng)絡(luò)和去噪擴(kuò)散概率模型的文本分割技術(shù)的研究。
4)在復(fù)雜自然場(chǎng)景下的文本檢測(cè)。由于公開數(shù)據(jù)集通常選擇拍攝角度較好的圖像,因此在此基礎(chǔ)上多數(shù)文本檢測(cè)模型都展現(xiàn)出良好的檢測(cè)性能,但是自然場(chǎng)景中往往存在許多干擾因素,例如強(qiáng)烈的光照、遮擋等,對(duì)這類復(fù)雜場(chǎng)景文本:基于檢測(cè)框的文本檢測(cè)模型多數(shù)預(yù)先設(shè)置候選框,文本表現(xiàn)形式受限,檢測(cè)時(shí)效果不佳;基于分割的文本檢測(cè)方法將文本區(qū)域視為像素級(jí)別的分割任務(wù),能夠更準(zhǔn)確地捕捉到文本的形狀和邊界。但是,由于復(fù)雜場(chǎng)景中文本的遮擋、重疊、模糊和小尺寸等情況,因此仍然存在誤分割和漏分割現(xiàn)象,基于檢測(cè)框和分割的混合文本檢測(cè)方法在復(fù)雜場(chǎng)景中文本分割邊界可能比較模糊或不規(guī)則,這會(huì)提高對(duì)邊界處理算法的要求。目前,較普遍的解決措施是在模型訓(xùn)練階段穿插環(huán)境較為復(fù)雜的樣本,提高模型對(duì)復(fù)雜環(huán)境中文本檢測(cè)的能力。因此,后續(xù)可以采用數(shù)據(jù)增強(qiáng)等技術(shù)來擴(kuò)充數(shù)據(jù)集,從而進(jìn)一步增強(qiáng)模型對(duì)不同環(huán)境的適應(yīng)能力。
5 結(jié)束語
自然場(chǎng)景文本檢測(cè)是計(jì)算機(jī)視覺領(lǐng)域的研究熱點(diǎn),越來越多的研究人員在國(guó)際計(jì)算機(jī)視覺大會(huì)、歐洲計(jì)算機(jī)視覺國(guó)際會(huì)議、IEEE 國(guó)際計(jì)算機(jī)視覺與模式識(shí)別會(huì)議、國(guó)際文檔分析與識(shí)別國(guó)際會(huì)議等重要的國(guó)際性會(huì)議上展示了該領(lǐng)域最新的研究成果。本文對(duì)自然場(chǎng)景文本檢測(cè)的相關(guān)研究進(jìn)行闡述,對(duì)自然場(chǎng)景文本檢測(cè)技術(shù)進(jìn)行分類介紹和分析對(duì)比,歸納目前主流技術(shù)在主要公開數(shù)據(jù)集上的測(cè)試性能和實(shí)驗(yàn)條件,并對(duì)文本檢測(cè)未來的發(fā)展趨勢(shì)進(jìn)行分析展望,指出未來可引入更強(qiáng)大的特征表示、增強(qiáng)學(xué)習(xí)和領(lǐng)域自適應(yīng)等方法,提高算法魯棒性和通用性。
猜你喜歡
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
中國(guó)科技博覽(2016年2期)2016-04-25 20:32:39
小學(xué)生導(dǎo)刊(2016年34期)2016-04-11 00:49:44
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
電測(cè)與儀表(2015年5期)2015-04-09 11:30:52
語文知識(shí)(2014年1期)2014-02-28 21:59:13
