多模態交叉解耦的少樣本學習方法
2024-04-08 11:37:52王思迪于云龍
國防科技大學學報 2024年1期
冀 中,王思迪,于云龍
(1. 天津大學 電氣自動化與信息工程學院, 天津 300072; 2. 浙江大學 信息與電子工程學院, 浙江 杭州 310027)
近年來,深度學習技術在人工智能領域取得了令人矚目的成績,例如圖像分類[1-2]、目標檢測[3-4]和行人重識別[5-6]等。這些方法大多都依賴于大量的標注數據。然而,人類可以通過少量的樣本學習到新知識,這種“舉一反三”的能力極大地啟發了研究人員,少樣本學習[7-8]就是其中一類有代表性的技術,其目的是從有限數量的標注數據中快速學習類別知識。
本文針對圖像少樣本分類技術展開研究,現有方法通常通過有限樣本學習一個可遷移模型,利用少量視覺樣本識別新的類別[9-10]。然而,現有方法更多地關注樣本視覺表征較為單一的類別,當樣本視覺表征多樣化時,較難準確分類。
具體地,在少樣本學習中由于可用于訓練的標注樣本數量極為有限,因此這些樣本較難完全反映類別的多樣性視覺表征。這本質是由于一些類別具有多元屬性。例如“蘋果”同時具有“紅色”和“黃色”屬性。屬性多元化會造成視覺表征復雜度的提高,從而損害屬性無關視覺特征的提取,本文將這種問題稱為“多元屬性問題”。如圖1所示,當有限標注的樣本都是紅色蘋果時,該類別特征將會突顯其“紅色”視覺表征,而當測試樣本是黃色蘋果時,此時由于香蕉常帶有“黃色”表皮屬性,因此少見的“黃色”蘋果易被錯分為香蕉。
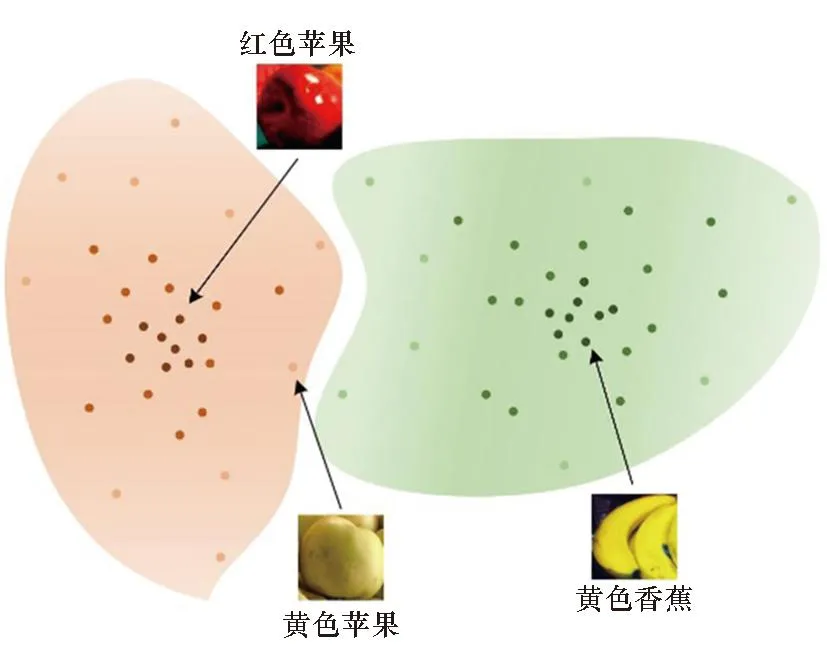
圖1 多元屬性樣本分布Fig.1 Distribution of diverse attribute samples
如何從有限樣本中提取到屬性無關的類別特征是解決上述問題的關鍵所在。在少樣本學習中,視覺特征往往受到對應屬性的影響,容易偏向學習表層屬性而忽略類別本質。相比之下,樣本的類別和屬性信息易于獲取,并能指導視覺特征的提取。因此,一些少樣本學習方法[11-12]借鑒多模態學習的思想,通過利用輔助模態如類別屬性、文本描述等來幫助分類,在一定程度上可緩解多元屬性問題的影響。例如,自適應跨模態(adaptive modality mixture mechanism, AM3)方法[11]自適應地將語義和視覺信息組合起來,通過語義中的類別信息指導視覺特征提取。屬性引導注意力模塊(attributes-guided attention module, AGAM)[12]使用類別語義信息引導特征提取,與視覺信息結合進行注意力對齊。然而,這些方法均側重于使用單一的類別語義信息促進視覺特征的提取,忽視了類別中存在屬性的多樣性以及不同屬性間的差異對正確識別樣本類別作用的不同[11-12]。
針對這一問題,本文提出一種多模態交叉解耦(multimodal cross-decoupling, MCD)的少樣本圖像分類方法,通過學習樣本的視覺特征、類別語義特征和屬性語義特征,解耦出樣本的多元屬性,來減少屬性多樣化帶來的分類差異,緩解多元屬性問題對分類的影響。
現有的少樣本學習方法大致可以分為三個類別:基于優化的方法、基于生成的方法和基于度量的方法。
基于優化的少樣本學習方法通過學習一個元學習器和調整優化算法的參數來適應少樣本分類任務。這些方法通常在基類樣本上進行訓練,得到一個學習模型,然后在新類樣本的少樣本任務中進行微調。與模型無關的元學習(model-agnostic meta-learning, MAML)方法[2]通過在元訓練階段讓模型學習一個較好的初始化參數,并在新類少樣本任務上經過幾步梯度更新優化模型參數。具有潛在嵌入優化(latent embedding optimization, LEO)的元學習方法[13]改進了MAML方法,通過編碼器將特征表達映射到低維隱空間,并使用解碼器將隱向量轉化為高維模型參數,通過優化隱向量來進行參數更新。
基于生成的少樣本學習方法,其思路是通過對樣本進行變換以達到數據增強的目的,或是使用生成對抗網絡來擴大樣本空間,從而彌補類別樣本數量少的不足。Chen等[14]提出的圖像變形元網絡(image deformation meta-networks, IDeMe-Net)使用網絡學習生成不同的變換圖形來擴充數據,并提取特征信息。Li等[15]提出的對抗性特征幻覺網絡(adversarial feature hallucination networks, AFHN)利用生成對抗網絡(generative adversarial networks, GAN)生成多樣性樣本,并引入分類和反崩潰正則項。
基于度量的少樣本學習方法通過將支持集和查詢集的特征映射到一個新的度量空間,并學習可遷移的距離度量來進行分類。原型網絡(prototypical networks, PN)[7]將同類別樣本特征均值作為類原型,并使用歐氏距離計算查詢樣本與類原型之間的距離來分類。關系網絡(relation network, RN)[8]通過神經網絡學習動態的度量模型,并利用該模型計算查詢樣本與支持樣本之間的相似度。Li等[16]提出的深度最近鄰網絡(deep nearest neighbor neural network, DN4)方法通過使用局部描述子來比較查詢圖像與支持集之間的相似度。
多模態學習研究不同模態數據的機器學習問題,通過挖掘模態間的互補性或獨立性來表征多模態數據。多模態表示學習應用于編碼不同模態數據中的語義信息,并學習各模態的特征與映射關系,其在跨模態檢索[17-18]、圖文匹配[19-20]、零樣本學習[21-22]等任務中都有著較為重要的作用。
多模態少樣本學習方法通過引入語義信息,聯合訓練文本和視覺特征,提升少樣本分類任務性能。例如,AM3方法[11]利用語義表征提供先驗知識來補充視覺信息,通過凸組合將視覺和語義表征結合起來進行分類。模態交替傳播網絡(modal-alternating propagation network, MAP-Net)[23]利用圖傳播指導語義圖更新,通過計算視覺特征相似性彌補缺失的語義特征。屬性指導特征學習(attribute-guided feature learning, AGFL)方法[24]通過屬性相關表示建立聯系,增強相同屬性在不同類別的表達。
本文所提方法是一種基于度量學習的多模態少樣本學習方法。與以往方法不同,本文方法針對少樣本多元屬性問題,能夠識別帶有相似屬性的同類樣本,同時還能夠具備識別出有不同屬性的該類樣本的能力。
1 方法實現
1.1 問題定義
假設存在一個給定數據集D={Dtrain,Dtest},其中訓練集Dtrain和測試集Dtest在樣本空間中不相交。訓練集樣本Dtrain包含了大量的類別,其標簽空間為Cbase={c1,c2,…,cn},n表示總類別數量。標準的少樣本分類任務(每一個任務包含N個類別、每個類別包含K個樣本)被稱作N-wayK-shot任務,一般K是比較小的整數,如1或5。
在少樣本分類任務中K值較小導致訓練樣本不足,元學習方法通過使用大量訓練集數據Dtrain合理解決這一問題。常見的基于度量學習的少樣本分類方法基于episode的形式實現元學習的訓練與測試,并通過episode隨機采樣形成上述的N-wayK-shot任務。通常情況下,每一個episode包含一個支持集XS和一個查詢集XQ。在支持集XS中所有樣本x都是標注數據,通過特征提取器f得到樣本特征f(x),同時可以利用原型網絡[7]計算類別原型P作為支持集類別的樣本特征。而在查詢集XQ中每個樣本都是無標注數據。
1.2 整體框架
針對多元屬性問題提出的多模態交叉解耦的少樣本分類方法整體框架如圖2所示。模型方法由多模態交叉解耦和特征重建兩個部分組成。在元訓練階段,多模態交叉解耦模塊將樣本的視覺特征、多種語義特征進行解耦,以得到解耦后的類別特征和屬性特征。為保證解耦出來的特征能夠準確地表示原樣本,利用特征重建模塊將解耦后的特征重新進行融合,并與原本的全局視覺特征進行約束。在元測試階段,因為查詢集沒有語義信息,所以使用自解耦來代替交叉解耦,并與支持集樣本解耦后的類別特征進行分類損失判別。

圖2 所提多模態交叉解耦的少樣本分類方法框架Fig.2 Proposed framework of multimodal cross-decoupling few-shot classification
1.3 多模態交叉解耦
為了緩解多元屬性問題,提出利用信息交叉解耦的思想,從多模態信息中學習有效的類別信息,弱化屬性特征對分類效果的影響。


圖3 交叉解耦示意圖Fig.3 Illustration of cross-decoupling

(1)
(2)
(3)

(4)
(5)

(6)

通過上述過程,模型將重點關注視覺特征中與語義特征相關性較高的部分,通過交叉注意力機制提取視覺特征中與類別相關的特征和與屬性相關的特征,并分別與原類別語義特征和原屬性語義特征進行融合,從而進一步強化語義信息對視覺特征的指導作用,實現了視覺特征中類別與屬性的解耦。
與支持集樣本不同的是,查詢集樣本xq不具備語義信息,因此采用自解耦的方法對查詢集的視覺特征進行訓練得到解耦后的類別特征。具體地,在利用交叉注意力機制時對于計算查詢集樣本的Q′、K′和V′分別表示為:
(7)
(8)
(9)

(10)
(11)
1.4 特征重建
在此階段,為保證支持集解耦后的類別特征與屬性特征仍可準確表示原樣本,采用特征重建的方式,通過將解耦后的特征進行融合得到重建后的特征,與原樣本的全局特征進行約束。
(12)
式中,β=h(ZSA)同樣是一個可學習的參數。
同時,原樣本的全局特征由f(xi)池化得到:
(13)

(14)
因此模型學習特征信息時將繼續朝著貼近樣本本質的方向進行優化。
冬天,感冒幾乎是寶寶們最常得的疾病了。感冒的癥狀一般有流涕、咳嗽、發燒、喉嚨疼等,爸爸媽媽對癥做好家庭護理很重要。另外,如果病情較重,需要就醫用藥,爸爸媽媽也需要知道一些用藥誤區,以減輕對寶寶的傷害。
1.5 少樣本訓練
對于一個N-wayK-shot的少樣本分類任務,當K值不為1時,每個類別的支持集樣本均采用原型網絡[7]的方法,計算每個類別樣本視覺特征、解耦后的類別特征和屬性特征的向量均值作為對應的特征原型。以樣本解耦的類別特征為例,對于類別c,其解耦類別特征原型為:

(15)
式中,XSc表示支持集樣本中屬于類別c的數據,|XSc|代表屬于類別c的樣本數量。

(16)
這里,p(y=c|xq)表示查詢集樣本xq屬于類別c的概率值,c′表示任一類別,d(·)為歐氏距離的相似度度量。
利用交叉熵損失作為其分類損失函數進行訓練:
Lcls=-lgp(y=c|xq)
(17)
合并所有損失函數得到最終的目標函數:
Lobj=arg minLcls+γLrec
(18)
式中,γ為超參數,用來平衡最終的損失函數。
2 實驗
2.1 實驗設置
2.1.1 數據集
本文所提方法在MIT-States[25]和C-GQA[26]兩個數據集上進行實驗。MIT-States數據集[25]由53 155張現實世界圖像組成,其中每個圖像都包含它的形容詞屬性和名詞類別,例如“黃色的蘋果”。對該數據集按名詞進行劃分后,一共有243個名詞類別,其中160個名詞用作訓練、40個名詞用于驗證、43個名詞用來測試。此外,一共有115種形容詞屬性。同時,由屬性和類別組成的詞共1 761對,分別用在訓練集、驗證集和測試集的對數分別為1 179、271和311。
C-GQA[26]數據集源于Stanford GQA數據集[27],具備更清晰的標簽和更大的標簽空間,挑戰性更大。該數據集共有27 062張圖像,按名詞劃分后得到訓練集、驗證集和測試集的圖像數量分別為20 786、3 511和2 765。相應地,其名詞類別數量分別為120、30、31。C-GQA的訓練集包含153種形容詞屬性。這里,由屬性和類別組成的詞共931對。數據集MIT-States和C-GQA的具體信息見表1。

表1 數據集劃分
2.1.2 實驗細節
在實驗中,數據集MIT-States和C-GQA的圖像均調整為224×224的尺寸,其類別和屬性的語義向量通過word2vec[28]得到,維度為600。并且,在兩個數據集上訓練并測試了5-way 1-shot和5-way 5-shot任務的準確率。首先,使用Adam優化器進行預訓練,在訓練集樣本上訓練60個批次。這里初始學習率設置為0.001。之后,采用元訓練的方式進行微調。在微調時,利用隨機梯度下降(stochastic gradient descent, SGD)優化器[29]訓練30個批次,每個批次隨機采樣1 000個episode;初始學習率設置為0.000 1,并且每隔10個批次學習率減小至原來的1/10;此時動量參數設置為0.9,權重衰減率為0.001。在訓練和測試時,視覺特征的提取均采用ResNet18[30]作為主干網絡,特征提取器的輸出維度為512;語義特征的提取則采用多層感知機(multilayer perceptron,MLP),其輸出維度也為512。對于超參數γ,在5-way 1-shot的任務中取0.4,在5-way 5-shot任務中取0.3。所有對比方法都使用相同的視覺和語義特征,并且調整參數達到其最優性能。
2.2 實驗結果
與常見少樣本分類工作的測試設置不同,將測試集分成兩個部分:與支持集屬性相同的查詢集樣本和與支持集屬性不同的查詢集樣本。首先,在測試集中隨機采樣2 000個episode,每個episode中的每個類別包含2個無標注的查詢樣本用來測試,即與支持集屬性相同的測試樣本(same support attribute, SSA)和與支持集屬性不同的測試樣本(different support attribute, DSA)各一個。然后,對2 000個episode上的SSA和DSA分別求平均準確率。最后,求所提方法對多元屬性樣本準確率,即求兩種準確率的調和平均數(harmonic mean, HM)作為最終評價指標:
(19)
本文選取了7種對比方法,包括3種不使用語義信息的方法(ProtoNet[7]、RelationNet[8]和MatchingNet[31])以及4種使用語義信息的方法(AM3[11]、AGAM[12]、MAP-Net[23]和SGAP[32])。表2和表3為本文方法在2個數據集上的實驗結果。可以明顯地看出,本文方法性能均較為顯著地優于所有對比算法。另外,在SSA上的分類性能整體較DSA上的分類性能高,這表明多元屬性問題確實會影響模型的分類性能。

表2 在MIT-States數據集上的測試結果

表3 在C-GQA數據集上的測試結果
具體地,在MIT-States數據集上,與結果第二高的比較方法AM3或MAP-Net相比,對于5-way 1-shot少樣本分類任務,本文方法在SSA的結果上提升了1.75%,在DSA上的測試結果提高了5.64%,并且調和平均數HM也有了4.31%的提升效果;在5-way 5-shot任務中,本文方法在SSA上比方法MAP-Net提高了1.34%,在DSA上比方法AM3提高了3.10%,在HM上也有3.12%的提升效果。在C-GQA數據集上,針對5-way 1-shot的分類結果,本文方法比結果第二高的方法AM3均有明顯的提高,在SSA上提高1.99%,在DSA上有3.44%的提升,并且在HM上也有2.80%的提升效果;而在5-way 5-shot任務中,本文方法仍比結果第二高的方法MAP-Net有較高的提升,其中在SSA上提升了2.01%,在DSA上提高了4.02%,在HM上也有3.20%的明顯提升。
通過實驗結果還可以發現,本文方法在DSA上較對比方法的提升效果明顯比在SSA上顯著,這說明對比方法難以很好地對具有未見屬性的同類樣本進行準確識別,本文方法在一定程度上有效地緩解了這一問題。同時,與5-way 5-shot提升結果相比,5-way 1-shot的分類任務中,DSA的提升效果在兩個數據集上都更為明顯。主要的原因在于當支持集樣本極少時,模型更難學習樣本的類別表示信息,并且當屬性差異較大時,更容易因屬性不同混淆本質的類別表征,加劇識別類別錯誤的情況。本文方法能夠有效地解耦出無關的屬性信息,保留樣本本質的類別特征,提高樣本極少情況下的分類性能。
2.3 消融實驗
如前所述,本文方法通過交叉解耦和特征重建兩個關鍵模塊提升多元屬性少樣本分類性能。接下來,為了探究每個模塊對實驗結果的影響,在MIT-States和C-GQA數據集上進行消融實驗研究,結果如表4和表5所示。采用原型網絡作為基準即第一行結果,第二行為僅增加支持集類別語義特征(support category features, SCF),第三行的結果為在此基礎上增加支持集屬性語義特征(support attribute features, SAF)形成交叉解耦模塊,第四行為繼續增加特征重建模塊形成本文最終方法。從表中結果可以發現交叉解耦與特征重建兩個模塊分別對少樣本的分類性能起到促進作用。

表4 在MIT-States數據集上的消融實驗結果
具體地,當僅引入類別語義信息時,與基準原型網絡方法相比,測試結果幾乎都有顯著的提升,這表明增加類別語義特征能夠彌補模型學習視覺特征的不足,對模型學習準確分類起到了積極的指導作用。
當加入屬性語義信息使用交叉融合模塊時,可以發現交叉融合的方法在SSA、DSA和HM上的分類性能大部分都比僅加入類別語義特征SCF時有較明顯的提升,其提升效果能達到0.84%~3.28%。特別地,當測試樣本的屬性特征與支持集樣本相同時,SSA的結果反映出交叉解耦模型可以更好學習出解耦后的類別特征和屬性特征,分離出正確的類別特征用以分類,有效地提高少樣本任務分類的準確率,其性能能夠達到0.84%~3.28%的提升。同時,即使在測試樣本的屬性特征與支持集樣本不同時,模型也能學習出未見屬性特征并解耦出類別特征。在此基礎上當繼續引入特征重建模塊時,SSA、DSA和HM的性能均存在進一步的提升。通過結果可以發現,在解耦過程中,可能會出現解耦出來的特征偏離原樣本真實特征的情況。因此,特征重建模塊將解耦后的類別特征和屬性特征重新融合,并利用原樣本視覺特征進行約束,使模型學習特征信息時沿著樣本類別內在特征的方向進行優化。
2.4 進一步分析
2.4.1 參數實驗
在此部分,研究超參數γ對模型性能的影響。不同γ值在MIT-States數據集和C-GQA數據集的結果如圖4所示,其中圖4(a)和圖4(c)表示MIT-States數據集的結果,圖4(b)和圖4(d)表示C-GQA數據集的結果。藍色和黃色折線分別代表5-way 1-shot和5-way 5-shot少樣本分類任務,采用調和平均數HM作為判別指標。

表5 在C-GQA數據集上的消融實驗結果

(a) MIT-States數據集在5-way 1-shot的結果(a) Results of 5-way 1-shot on the MIT-States dataset

(b) C-GQA數據集在5-way 1-shot的結果(b) Results of 5-way 1-shot on the C-GQA dataset

(c) MIT-States數據集在5-way 5-shot的結果(c) Results of 5-way 5-shot on the MIT-States dataset

(d) C-GQA數據集在5-way 5-shot的結果(d) Results of 5-way 5-shot on the C-GQA dataset
通過實驗發現,兩種數據集上的超參數γ均是先升后降。在5-way 1-shot分類任務中,當γ=0.4時,網絡性能達到最優,HM的結果最佳;而在5-way 5-shot少樣本任務中,當γ=0.3時,模型能達到最佳性能,此時HM的值為最高。這表明特征重建模塊能夠在一定程度上有效地提升分類性能,但是當參數γ的值過大時,分類性能反而會下降,其原因可能在于重建約束較強時會影響屬性解耦的效果,加重了屬性對類別特征的影響。
2.4.2 可視化實驗
為了驗證本文方法的效果,采用t-SNE[33]方法在MIT-States數據集的嵌入空間進行可視化實驗,結果如圖5所示。隨機可視化一個測試任務,這個任務包含5個類別共60個樣本,每個類別的樣本數為12。不同顏色的圓點代表不同的類別。這里,選用原型網絡(ProtoNet)作為基準方法進行比較,結果如圖5(a)所示;為了驗證本文方法的可行性,圖5(b)為僅引入類別語義信息的方法結果,圖5(c)為本文方法結果。
從t-SNE的可視化結果可以看出,增加類別語義信息,能夠有效地提高類別辨識的能力,使測試樣本按照預測類別整齊規則分布。本文方法進一步增強了同類別樣本的分布密度,使類內樣本分布更加緊湊,同時提高類別間的距離,可降低多元屬性問題帶來的識別誤差。

(a) ProtoNet
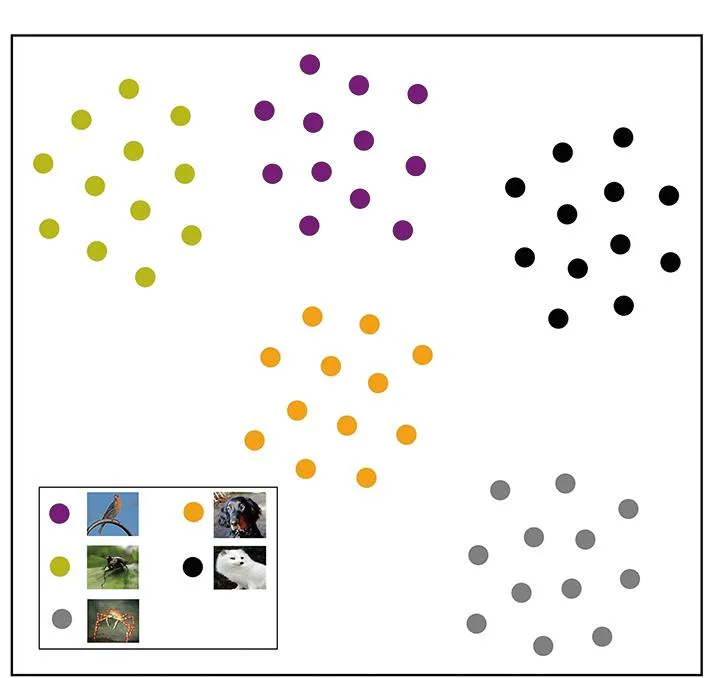
(b) ProtoNet+SCF

(c) MCD
3 結論
本文針對少樣本學習中的多元屬性問題,提出一種多模態交叉解耦的方法,可有效解耦出樣本類別特征和類別屬性語義特征,并能利用特征重建保留樣本內在的類別特征信息,極大地緩解了多元屬性問題對少樣本分類造成的識別錯誤。所提方法也提出一種特征重建方法,將解耦后的類別特征和屬性特征重新融合,通過原樣本的視覺特征進行約束,使模型學習特征信息時沿著貼近樣本本質類別的方向進行優化。在兩個類內屬性差異較大的標準數據集上的大量實驗驗證了所提方法的有效性和先進性,結果顯示本文方法能夠有效提升少樣本分類任務的準確性,即使在屬性未知的待測樣本中也具有良好的分類性能。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
開放教育研究(2020年2期)2020-03-31 01:54:14
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
現代語文(2016年21期)2016-05-25 13:13:44
湖北經濟學院學報·人文社科版(2015年8期)2015-12-29 05:53:07
上海電機學院學報(2015年4期)2015-02-28 14:30:00
大連民族大學學報(2015年2期)2015-02-27 08:28:11
計算物理(2014年2期)2014-03-11 17:01:39
