改進YOLOv5的鋼材表面缺陷檢測網絡輕量化研究*
2024-04-12 00:29:36甄國涌趙林熔李文越儲成群
組合機床與自動化加工技術 2024年3期
甄國涌,趙林熔,李文越,儲成群,王 達,孫 妍
(1.中北大學儀器與電子學院,太原 030051;2.陸軍裝備部駐北京地區軍事代表局某軍代室,太原 030000;3.北京遙感設備研究所,北京 100005)
0 引言
近年來,鋼材表面缺陷檢測已成為工業生產中不可或缺的重要環節。傳統的鋼材表面缺陷檢測方法主要依靠人工肉眼觀察,嚴重依賴質檢人員的主觀判斷,通常需要耗費大量的人力資源和時間成本,且存在效率低,漏檢誤檢率高等問題。因此,基于深度學習的自動化檢測方法逐漸成為了鋼材表面缺陷檢測的研究熱點。其中,基于YOLO(you only look once)算法[1]的檢測網絡由于其高效、準確等特點而備受關注。
然而,在實際應用中,由于數據量較大、模型參數復雜等問題,傳統的YOLO模型在鋼材表面缺陷檢測任務中仍存在著一定的輕量化難題。曹義親等[2]改進YOLOv5網絡,加入多頭注意力機制和多層特征融合機制,提高網絡對鋼材表面缺陷的檢測精度,精度提高了3.4%,但是模型參數量隨之增加了大約3倍。GUO等[3]將YOLOv5中的特征融合網絡換成BiFPN,并將TRANS模塊添加到模型主干和檢測頭來提高模型檢測效果,改進后模型體積為90.8 MB,是原始v5的6.6倍,難以在硬件受限的邊緣設備上進行部署。
因此,本文針對YOLOv5的輕量化問題展開研究,采用一系列網絡結構優化等技術手段,提出一種更加高效、精準的鋼材表面缺陷檢測方法。主要研究內容包括:①在模型主干引入基于梯度路徑設計的ELAN模塊,它能在減少參數量的同時提高網絡對特征信息的學習能力;②在模型頸部引入深度可分離卷積和Ghostv2模塊,用來減少模型體積和參數量;③將v5原始的CIOU邊界框損失函數替換為SIOU邊界框損失函數,充分考慮真實框與預測框之間的回歸方向問題,提高模型定位精度和檢測速度。在公開數據集NEU-DET上驗證改進后模型對鋼材表面缺陷檢測的實際效果,改進后的YOLOv5模型,能夠在保證檢測精度和速度的前提下,達到輕量化的目的。
1 YOLOv5算法模型
YOLOv5的整體結構包括輸入端(Input)、主干網絡(Backbone)、頸部網絡(Neck)、預測頭(Prediction)4個部分[4]。
模型在輸入端先對輸入圖片進行Mosaic數據增強豐富數據集,再通過自適應縮放技術將圖片縮放至統一大小后輸入網絡。主干網絡包括Conv、C3和SPPF模塊,主要用來實現對鋼材表面缺陷特征的提取。其中Conv是基本的卷積計算單元;C3在早期的BottleneckCSP基礎上去掉了Bottleneck輸出后的卷積塊演變而來,減少了模型參數,又降低了推理時間;SPPF結構能夠利用多級池化提取不同分辨率的特征信息。頸部采用特征金字塔網絡(feature pyramid networks,FPN)[5]和路徑聚合網絡(path aggregation networks,PAN)[6]進行特征融合,FPN自頂向下傳達頂層利于分類的強語義特征,PAN自底向上傳達利于定位的強位置信息,二者結合能夠有效融合不同深度的特征信息。最后為預測部分,YOLOv5一共有3個不同尺度的預測頭,分別對應檢測大、中、小目標,根據鋼材表面缺陷尺寸的大小,自主選擇預測頭,最終輸出預測信息[7]。
2 模型優化與改進
本文提出的算法主要做了4個方面的改進:①在模型主干,用ELAN替換C3來豐富梯度組合,能夠減少重復的梯度信息,使用更少的參數信息學習到更多有效的特征;②將頸部的標準卷積換成深度可分離卷積,解決標準卷積造成的參數量和計算題過多的問題;③在頸部最后用Ghostv2模塊替換最后一個C3,既不會影響主干網絡的特征提取能力,還能減少模型體積和參數量;④使用SIOU替換CIOU邊界框損失函數,解決預測框與真實框之間回歸方向不匹配的問題,提高模型穩定性,加速收斂,改進后的模型網絡結構圖如圖1所示。
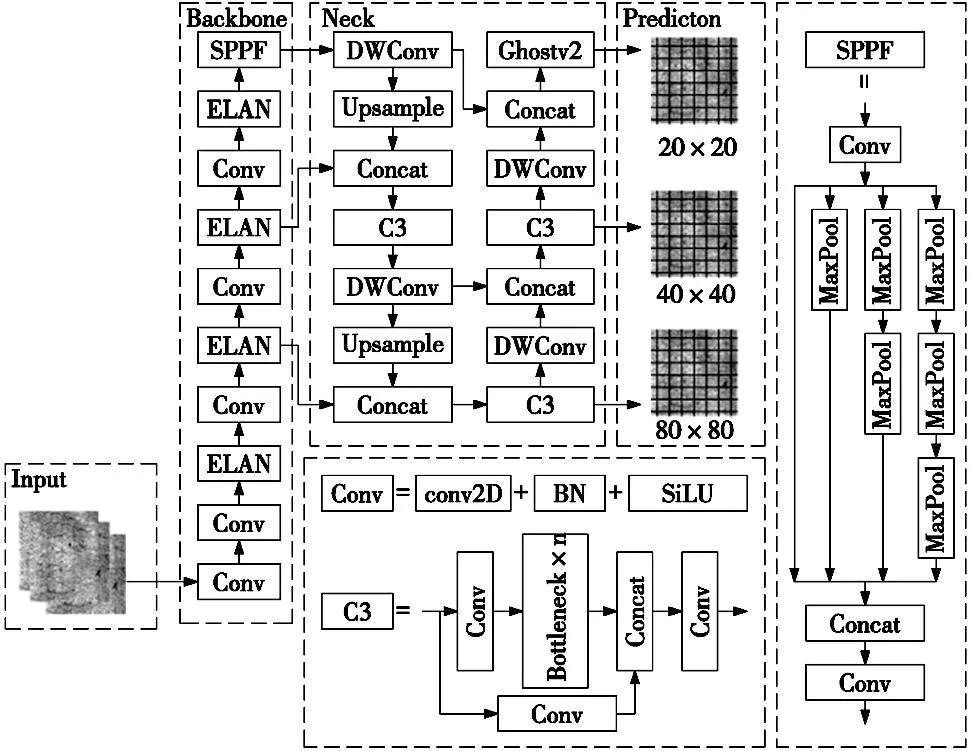
圖1 改進后YOLOv5結構圖
2.1 主干網絡改進
高效層聚合網絡(efficient layer aggregation networks,ELAN)[8]是基于梯度路徑分析設計的網絡結構。傳統的基于數據路徑分析設計的網絡結構,通常需要增加額外的參數或計算成本來達到更好的精度。基于梯度路徑分析設計的網絡可以通過對梯度傳播路徑進行重新規劃,豐富梯度組合,減少重復梯度信息,提高網絡的學習效果。同時可以通過調整梯度傳播路徑,使不同計算單元的權值可以學習到各種信息,提高參數利用率,在不引入額外參數和復雜結構的情況下學習到更多的有效信息,獲得精度更高,計算成本更低的網絡模型。
ELAN主要由VoVNet[9]結合CSPNet[10]組成,基本構成單元為Conv模塊,如圖2所示,它將輸入數據進行分流,其中一部分經過堆疊了計算單元的梯度路徑,該部分網絡能夠對輸入特征圖進行充分的特征提取,另一部分使用跨階段連接,直接跨越整個階段,再與經過計算單元的部分融合。這種分流設計結構豐富了信息處理的多樣性,能有效減少重復的參數信息,使網絡有效學習和收斂。

圖2 ELAN原理圖
2.2 深度可分離卷積
深度可分離卷積(depthwise separable convolution,DSC)[11]是一種因式分解形式的卷積,它將標準卷積分解為逐通道卷積(depthwise convolution,DWC)和逐點卷積(pointwise convolution,PWC)兩部分。DWC的每個卷積核只對輸入特征圖的一個通道做卷積運算,此過程與標準卷積相比能減少大量運算參數。為了避免通道之間在空間位置上的信息丟失,PWC將DWC得到的特征圖沿通道方向進行加權組合,得到輸出特征圖(如圖3所示),這樣一來,可以實現與標準卷積同樣的效果且不會損失過多的精度。
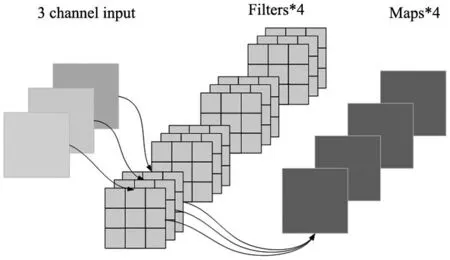
(a) 標準卷積
假設輸入層大小為H×W×M,標準卷積核大小為K×K×M,個數為N,輸出層為大小為H×W×N,標準卷積過程如圖3a所示,參數量P1=K×K×M×N,計算量C1=H×W×K×K×M×N。深度可分離卷積將標準卷積核拆分,得到M個大小K×K×1的逐通道卷積核和N個1×1×M逐點卷積核,總參數量P2=K×K×M+1×1×M×N,總計算量C2=K×K×M×H×W+1×1×M×N×H×W,卷積過程如圖3b所示。深度可分離卷積和標準卷積的參數量和計算量之比分別為:
(1)
(2)
由公式可知,在相同輸入輸出的情況下,深度可分離卷積可以有效減少模型的參數和計算量。
2.3 Ghostv2模塊
為了使模型能夠部署在計算資源有限的硬件設備上,前人在網絡中引入Ghost[12]模塊。Ghost模塊主要有兩個步驟,首先,通過1×1的普通卷積得到intrinsic特征圖;然后,在此基礎上通過一系列計算成本更低的線性變換生成更多的Ghost特征圖,將不同的特征圖拼接到一起,組合成新的輸出。特征圖中的冗余性是成功部署神經網絡的重要特性之一,Ghost模塊充分利用特征圖的冗余性,使用計算成本更低的操作產生更多特征圖而代替原始卷積。雖然Ghost模塊顯著降低了參數成本,但是不可避免的削弱了網絡的表示能力。Ghost特征圖和intrinsic特征圖僅僅是簡單的拼接,并沒有任何的像素信息進行交互,捕獲空間信息的能力較弱,會阻礙模型性能進一步的提高。因此,本文使用Ghostv2[13]模塊,它在Ghost模塊的基礎上加入解耦全連接注意力(decoupled fully connected attention,DFC)機制,將DFC注意力機制與Ghost模塊并聯,有效彌補Ghost模塊建模空間依賴能力的不足,原理圖如圖4所示。
在船舶減速過程進行理論分析與數學計算基礎上,建立船舶減速概率模型,實現對航道內船舶減速過程的定量描述,通過仿真試驗對船舶減速概率模型進行驗證。試驗結果表明,概率模型能反映航道內船舶的減速概率。比較模型計算的結果與仿真結果,找出航道船舶減速產生連鎖過程的臨界點,而船舶減速連鎖過程嚴重影響航道的通航能力。根據結果圖中的臨界點,可控制船舶到達率及船舶速度分布標準差,在臨界范圍內來降低船舶減速連鎖效應的影響。
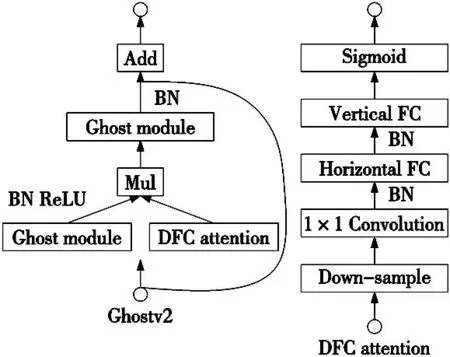
圖4 Ghostv2原理圖
在DFC中,只有全連接層參與注意力圖的生成,它不僅可以在普通硬件上快速執行,還可以捕獲遠程像素之間的依賴關系,提高模型的檢測精度。DFC將全連接層分別沿水平方向和垂直方向進行分解,并分別沿水平全連接層和垂直全連接層兩個方向聚合2D特征圖中的像素特征,計算過程可以表示為:
(3)
(4)
式中:FH和FW是變換權重,z是原始特征輸入,式(3)和式(4)依次作用于輸入特征圖,分別捕獲兩個方向上的遠程依賴關系,由于水平方向和垂直方向的解耦操作可以大大降低模塊的計算復雜度。在運算過程中通過共享部分變換權重,可以省去耗時的張量重塑和轉置操作。在相同的輸入下,Ghost模塊和DFC注意力是兩個分支,從不同的角度提取信息,輸出是它們逐元素乘積的結果。
2.4 損失函數的改進
模型在迭代的過程中,損失函數通過計算預測值與真實值的差值反向更新參數,使模型不斷優化。鋼材表面缺陷分布密集,且小目標占比多,預測框的少量偏移都會對模型的檢測效果造成不好的影響。YOLOv5原模型使用CIOU作為邊框損失函數,它考慮了邊框中心點損失和高寬比損失,但是沒考慮到真實框與預測框之間回歸方向不匹配的問題,忽略回歸方向帶來的誤差,會導致訓練過程中預測框“四處游蕩”,使模型收斂速度慢,精度低,從而產生檢測效果更差的模型。將真實框與預測框之間方向的影響作為損失函數的懲罰因子能夠有效解決上述問題。
本文采用SIOU[14]作為損失函數,它在CIOU的基礎上充分考慮回歸之間的方向角度,使預測框朝著更精確的方向移動,能夠提高模型檢測速度和精度。它由4個部分組成:角度成本、距離成本、形狀成本和IOU成本。
預測框回歸方向由預測框與真實框中心點之間的角度決定,角度損失Λ如式(5)所示。
(5)


圖5 SIOU示意圖
角度損失主要是方便計算真實框與預測框之間的距離,結合重新定義的Λ,距離損失Δ如式(6)所示。
(6)
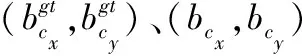
形狀損失Ω公式為:
(7)
式中:(wgt,hgt)表示真實框的寬高值,(w,h)表示預測框的寬高值,θ值用來控制在形狀損失中應該給予多少關注度,它的范圍從2~6,本文在實驗中將它設置為4。形狀損失分別考慮了高度損失和寬度損失,CIOU同時考慮高寬比,容易出現兩個預測框中心點保持一致,高寬比相同但是值不相同而造成回歸誤差的情況,SIOU避免上述情況的發生使邊界框回歸更準確,有助于提高模型檢測精度。
綜上所述,SIOU總損失函數定義為:
(8)
(9)
式中:B表示預測框,Bgt表示真實框。
3 實驗部分
3.1 實驗環境
本文實驗環境基于Ubuntu18.04,CPU型號為Intel(R)Xeon(R)Platinum8350C CPU@2.60 GHz,運行內存為45 GB,GPU型號為NVIDIA GeForce RTX 3080 Ti,顯存大小為12 GB。該模型基于深度學習框架PyTorch 1.9.0,運行環境為python 3.8,集成開發環境為PyCharm,使用CUDA 11.1進行加速。
3.2 數據集介紹
本次實驗使用某大學發布的鋼材表面缺陷數據集NEU-DET,該數據集覆蓋了6種典型的鋼材表面缺陷灰度圖,每種缺陷300張圖片。6種缺陷分別為:裂紋(crazing,Cr)、夾雜物(inclusion,In)、斑塊(patches,Pa)、點蝕面(pitted surface,PS)、氧化鐵皮壓入(rolled-in scale,RS)、劃痕(scratches,Sc),數據集部分示例如圖6所示,可以發現缺陷與背景顏色相近,且不同缺陷之間尺度變化多樣,小目標占比多。
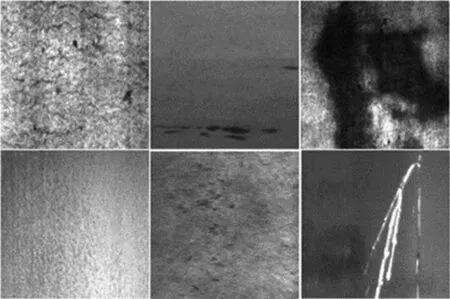
圖6 數據集部分示例
實驗過程中將數據集以6∶2∶2的比例劃分為訓練集、驗證集和測試集。為體現本文算法的魯棒性,更加貼近實際生活應用,實驗所用數據集沒有經過任何清晰化等預處理,均為原始圖像。
3.3 評價指標
本文的目的是在保證檢測精度的情況下,實現模型輕量化。本實驗主要通過平均精度(average precision,AP)、平均精度均值(mean average presicion,mAP)、單張圖片所用推理時間(t)、模型體積(Weight)、網絡參數量(Params)作為評價指標來衡量模型的性能。
3.4 消融實驗
我們在YOLOv5 v6.0模型的基礎上,進行各類優化策略的消融實驗,以測試不同優化策略對于鋼材表面缺陷數據集在模型性能上的提升效果。共做8組實驗,均保持相同的參數設置和實驗環境,實驗結果如表1和表2所示,其中表1和表2的實驗序號相互對應。
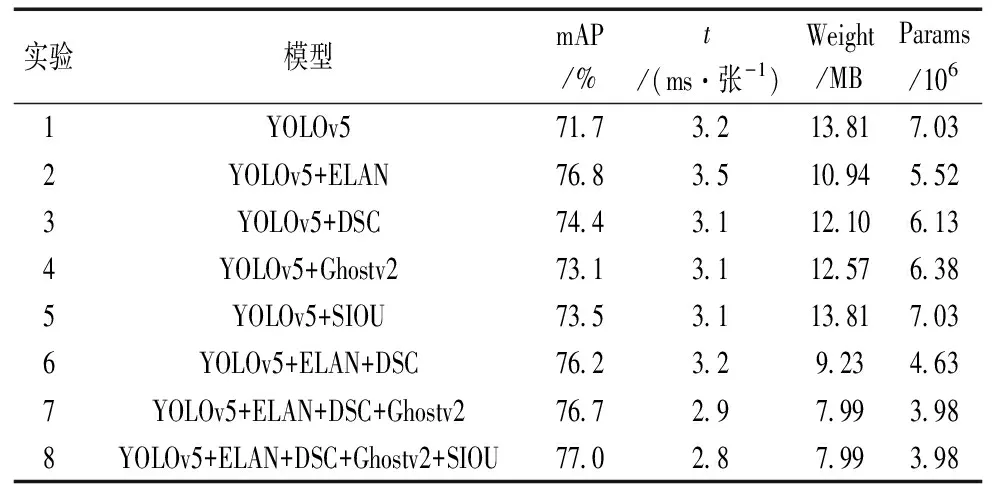
表1 消融實驗模型性能指標對比

表2 消融實驗模型的AP值 (%)
在表1和表2中,實驗1使用未改進的原始YOLOv5作為對照試驗,mAP值為71.1%,對比實驗2、3、4、5分別添加ELAN、DSC、Ghostv2和SIOU模塊,mAP值均有提升,模型體積和參數量也有不同程度的減少,說明所改進模塊對于鋼材表面缺陷檢測效果以及實現模型輕量化均有幫助。實驗2在模型主干將C3模塊替換成ELAN模塊,改進后模型mAP值為76.8%,與YOLOv5相比提高了5.1%,雖然檢測時間增加了0.3 ms,但是模型體積減少了20.8%,參數量減少了21.5%,說明ELAN模塊通過優化網絡路徑,能夠使模型以更少的參數量學習到更多的特征信息,既簡化了網絡,同時對鋼材表面缺陷檢測性能顯著提高。實驗6在實驗2的基礎上,將頸部的標準卷積換成DSC,mAP值為76.2%,降低了0.6%,檢測時間縮短了0.3 ms,雖然損失了少量精度,但是DSC結構使得模型體積減少了33.2%,參數量減少了34.1%。實驗7在頸部最后使用Ghostv2模塊,模型處理單張圖片所用時間縮短到2.9 ms,mAP值提升到76.7%,模型體積從原來的13.81 MB降低到7.99 MB,參數量從原來的7.03減少到3.98,驗證了DFC機制不僅能使模型快速運行,還能很好的捕捉遠程像素之間的依賴關系,彌補網絡在訓練過程中由于過度減少模型體積和參數量導致重要信息丟失的現象,提升了網絡對鋼材表面缺陷的檢測能力。實驗8使用SIOU邊框損失函數代替原有的CIOU,并沒有帶來任何模型體積和參數量的增加,SIOU在CIOU的基礎上充分考慮了真實框與預測框之間回歸方向不匹配的問題,加入角度影響因子,提高模型定位精度以及檢測速度,使邊界框能夠更快速精準的回歸,mAP值提高到77.0%,處理時間縮短到2.8 ms。
通過上述分析,我們最終模型為實驗8所用模型,在ELAN、DSC、Ghostv2和SIOU 4個模塊的共同作用下,改進后模型的輕量化效果明顯,模型體積較原始YOLOv5縮小了42.1%,模型參數量減少了43.4%,約降低到原始模型的一半。改進后模型對鋼材表面缺陷檢測效果也大大提高,mAP值達到77.0%,在YOLOv5的基礎上提高了5.3%,裂紋、夾雜物、斑塊、點蝕面、氧化鐵皮壓入和劃痕6種缺陷AP值分別提高了5.0%、5.2%、2.4%、4.5%、12.0%、3.0%,說明改進后的網絡能夠很好的解決目標與背景相似度高,尺度變化多樣,小目標占比多的問題,很好的實現了輕量化和檢測準確率的平衡。
3.5 算法對比與分析
為進一步驗證本文所提模型的有效性和優越性,現將改進后模型與目前主流YOLO系列算法和其他論文中提出的鋼材表面缺陷檢測算法進行對比,實驗結果如表3所示。
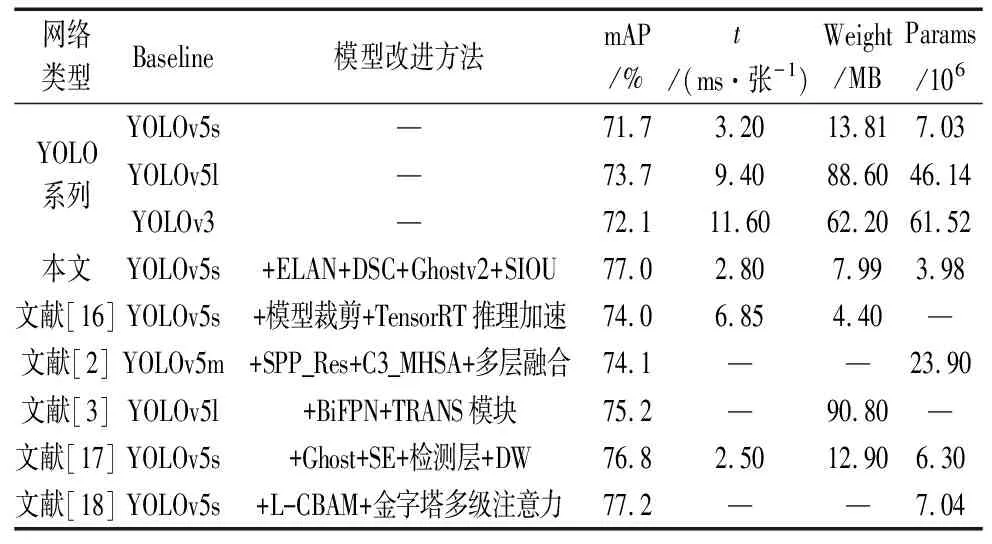
表3 本文提出算法與其他網絡模型的對比
分析表3,綜合考慮模型的檢測效果和模型的輕量化實現,本文所提模型表現最佳。本文模型mAP值為77.0%,相較于YOLOv5l和YOLOv3分別提高了3.3%和4.9%,YOLOv5l和YOLOv3的檢測速度也遠比不上我們的模型,網絡參數量也極大,不僅會占用大量的計算資源,而且部署到移動端比較困難,應用起來耗時耗力,難以推廣。相比于YOLOv5原模型,本文模型mAP值提高了5.3%,說明我們的模型對鋼材表面缺陷具備更強的檢測能力,同時,處理每張圖片的時間從3.2 ms提升到2.8 ms,完全滿足工業生產中實時性的需求,除此之外,模型體積縮小了42.1%,參數量減少了43.4%,大大降低了模型的復雜度。
現有的鋼材表面缺陷檢測算法主要以YOLOv5作為模型基線,再結合各種改進方法設計網絡體系。與現有的5種模型相比,本文模型的綜合性能具有更高的優勢。文獻[15]的模型體積雖然縮小到4.40,但是以犧牲檢測精度和速度為代價,本文模型每張圖片處理時間只需2.8 ms,比6.85 ms快了兩倍多。文獻[2]和文獻[3]的模型分別基于v5m和v5l,雖然使用更龐大的基線模型,但是模型參數和體積的大量增加并沒有帶來檢測精度的提高,檢測精度比本文模型分別低了2.9%和1.8%。與文獻[16]相比,本文模型處理時間慢了0.3 ms,但是模型體積小了38.1%,參數量減少了36.8%,在保證能過做到實時處理的同時,節省算力。文獻[17]檢測精度只比本文模型高0.2%,但是模型參數量仍比YOLOv5改進前更高,不利于模型的輕量化部署。
綜上所述,我們所提模型能更好的完成鋼材表面缺陷檢測任務,在檢測速度滿足實時性的情況下,實現了模型輕量化和檢測準確率的平衡,為后續投入工業應用奠定了基礎。
4 結束語
本文通過引入ELAN、DSC、Ghostv2和SIOU 4個模塊,在YOLOv5模型的基礎上提出了一種改進的鋼材表面缺陷檢測輕量化模型。實驗結果表明,改進后的網絡mAP值為77.0%,較原始模型提高了5.3%,網絡在參數量和模型大小等方面都得到了有效減少,參數量降低了43.1%,模型體積縮小了42.1%,每張圖片的處理速度從原來的3.2 ms提升到2.8 ms。改進后的模型在符合實時性檢測要求的同時,能夠很好地實現模型檢測精度和輕量化的平衡。下一步工作將驗證該模型在不同鋼材表面缺陷數據集上的檢測效果,并研究如何將模型部署到移動端,結合實際應用對模型加以完善和改進。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
