基于關系挖掘和對抗訓練的多標簽文本分類?
2024-04-17 07:27:34楊冬菊程偉飛
計算機與數字工程 2024年1期
楊冬菊 程偉飛
(1.北方工業大學信息學院 北京 100144)
(2.大規模流數據集成與分析技術北京市重點實驗室(北方工業大學) 北京 100144)
1 引言
目前多標簽文本分類[1]被廣泛應用于文檔分類[2]、web 內容分類[3~4]和推薦系統[5~6]等各種應用。在運用產業鏈圖譜對資源的管理方面,多標簽文本分類發揮了重要作用。通過多標簽文本分類,將文本與產業鏈圖譜進行關聯,可以實現產業鏈節點和科技資源的綁定,從而幫助用戶在生產、投資和決策等方面更好地利用和管理資源[7]。
雖然多標簽文本分類在各個領域中被廣泛應用,但它依然是一個具有挑戰性的任務,總結如下:1)挖掘標簽之間的關聯關系;2)挖掘文本與標簽之間的關聯關系;3)文本數據中存在大量的標簽不平衡和標簽噪聲。這些存在的問題可能對最終的分類結果產生影響。
針對上面的提出的問題,本文融合了多種深度學習SOTA模塊,形成了R-BAGC深度語義模型。
2 相關工作
在多標簽文本分類中,比較經典的傳統方法有二元相關方法(Binary Relevance,BR)[15]、分類器鏈方法(Classifier Chain,CC)[16]等,這些方法在多標簽文本分類上取得了一些成果,但是這些傳統的方法也存在一些問題。首先,這些傳統方法在處理多標簽問題時不能充分挖掘文本的語義信息。其次,傳統方法將標簽視為一個無意思的符號,也不能充分地利用標簽之間的關系、簽與文本之間的關系。
為了彌補傳統方法的不足之處,近年來出現了一些基于深度學習的方法。Liu等利用可能的標簽差異和標簽相關性,提出了一種新的預訓練任務和模型,在做分類任務時利用這種差異能夠獲得好的效果[9]。You等針對每個標簽無法捕獲最重要的文本信息和大量label 缺少可擴展性兩個問題,提出了一種基于樹標簽的深度學習模型,該模型能捕獲輸入文本和每個標簽最相關的部分,同時針對長尾標簽,提出了概率標簽樹[10]。Xiao 等提出的LSAN模型提出標簽注意力機制學習特定于標簽的文本表示,將標簽語義信息引入到模型中[11]。任彥凝等[12]將標簽語義和標簽關系結合起來共同提取樣本中的信息,并且其內部設置了自適應融合單元。Xun 等[13]針對極端多標簽文本分類模型忽略了不同標簽之間有用的相關信息的問題,通過在深度模型的預測層添加額外的CorNet 模塊來解決這一限制。支港等[14]提出基于Transformer 解碼器的序列生成模型,使用標簽嵌入作為查詢,通過其多頭自注意力機制建立標簽之間的高階相關性,并利用多頭交叉注意力子層從文本信息中自適應地聚合標簽相關的關鍵特征,取得了不錯的效果。Ankit Pal等[22]提出了一種提出了一種基于圖注意力網絡的模型來捕捉標簽之間的注意力依賴結構,并將生成的分類器應用于從文本特征提取網絡(BiLSTM)獲得的句子特征向量,以實現端到端訓練。
3 R-BAGC模型

通過R-BAGC 模型架構,本文實現了文本向量化、標簽之間關系挖掘以及“文本-標簽”關系挖掘。具體的框架如圖1所示。

圖1 R-BAGC模型架構
3.1 文本向量化
Word2Vec[18]和Glove[19]能夠把詞語轉化為向量,但是這種向量是靜態的,無法解決歧義問題。為了更好地表示文本,本文使用BERT[8]預訓練模型把文本向量化。BERT能夠對文本進行上下文理解,可以生成更準確的向量表示,同時還可以解決歧義問題。
模型的輸入由三種嵌入層相加構成,分別是:詞嵌入、分段嵌入、位置嵌入,最終嵌入記為H,見式(1)。
其中:H?Rk×d,k 為文本的最大長度,d 為BERT模型隱藏層的大小。
3.2 挖掘標簽之間的關系
在多標簽文本分類中,標簽可以視為圖中的節點,標簽之間的共現關系可以表示為圖中的邊。利用GAT[20]模型,可以學習到每個標簽節點的向量表示,并考慮標簽之間的依賴關系,從而進行更準確的多標簽分類。
首先通過計算標簽的成對共現來構造鄰接矩陣,共現矩陣的計算如下:
其中:L為共現矩陣,NORM為歸一化操作。
然后就是利用GAT 挖掘標簽之間的關系。隨機生成的嵌入Qf={ }Q1,Q2,…,Qs作為標簽的初始狀態,其中標簽嵌入是一個隨模型迭代更新的Embedding[21],然 后 將 其 輸 入 進GAT 中,其 中Qi?Rd。因為GAT 模型引入了注意力機制,所以接下來需要計算注意力系數。首先對于頂點i,逐個計算它的鄰節點(j?si)和它自己之間的相似系數,如式(3)。
其中:W 是可訓練參數,a是前饋神經網絡的可訓練參數;eij表示節點j 對于節點i 的重要性。注意力系數計算公式為
其中:LeakyReLU為非線性激活函數;αij為標簽j相對于標簽i 的歸一化注意系數;k?si表示節點i 的所有鄰節點。
得到歸一化的注意力系數之后,根據計算好的注意力系數,把特征加權求和,見式(5)。
將經過k 頭注意力機制計算后的特征向量進行拼接,對應的輸出特征向量表達為

經過GAT 計算后S 個標簽的向量記作Qg?Rs×d。
3.3 “文本-標簽”關系挖掘
為了捕捉文本中不同部分與標簽的關系,模型中利用了多頭自注意力機制(Multi-head Self-Attention,MSA)。
將文本向量H 作為Key 和Value,將標簽嵌入Qg作為Query,輸入進MSA 中,得到更新的標簽嵌入Qm,公式如下:
其中:Concat 表示拼接每一個頭部的注意力輸出。最后將Qm傳入前饋網絡(FFN)得到Ql作為輸出。計算過程如公式:
3.4 損失函數
模型訓練時使用二元交叉熵損失和Sigmoid函數的組合作為損失函數,公式如下:
其中:N 為文檔數量;l 為標簽數量;y?ij、yij分別為第i個實例的第j個標簽的預測值和真實值。
R-BAGC 模型中用到了傳統的Dropout 方法,可以防止模型過擬合。然而這種方法會導致模型訓練和推理過程的行為不一致。所以為了彌補傳統Dropout的缺點,研究人員們提出了R-Drop 來進一步對子模型的輸出預測進行了正則約束。

4 實驗
4.1 數據集
為驗證模型有效性,本文在兩個英文公開數據集上進行實驗。對數據集的介紹如下:
1)AAPD 訓練集中包含論文摘要55840 條,測試摘要1000 條,經過處理后的數據量在3.5KB 級別,共有54個類標簽;
2)RCV1 數據集包含訓練樣本23149 條,測試樣本781265 條。其數據量在80KB 級別,共有103個類標簽。
表1 中列出了這些數據集的統計信息,其中N是總實例數,W是數據集中每個文檔的平均字數,Q是標簽的總數,Qˉ是每個文檔的平均標簽數。
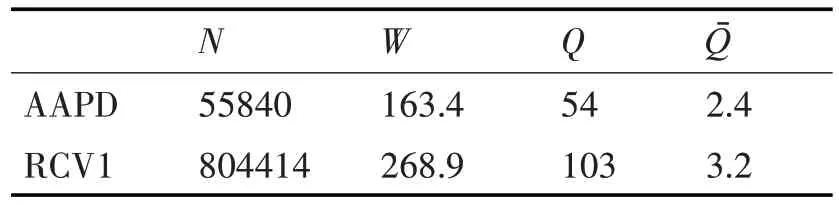
表1 兩個數據集的信息
4.2 評價指標
本文采用準確率(precision)、召回率(recall)和micro-F1 作為實驗的主要評估指標,見式(17)~(19),其中N為數據集中樣本的總數量。其中,TP、TN、FP、FN的具體含義可見表2混淆矩陣。

表2 混淆矩陣
4.3 實驗結果分析
為了充分驗證提出模型的有效性,選擇了7 種模型作為對比算法。7種模型的簡介如下:
BR[15]:該算法提出將多標簽分類任務轉換為多個二進制分類任務。
CC[16]:基于一系列二進制分類任務來解決多標簽分類任務。
TextCNN[17]:該方法基于Word2vec 進行詞嵌入,并首次使用CNN結構進行文本分類。
CNN-RNN[8]:使用CNN 和RNN 獲得局部和全局語義,并對標簽之間的關系進行建模。
LSAN[11]:利用標簽注意力機制建立特定于標簽的文本信息,同時使用自適應融合機制將標簽信息與文本信息融合。
AttentionXML[10]:利用多標簽注意力機制捕獲每個標簽最相關的文本。
MAGNET[22]:利用圖注意力網絡來捕捉和探索標簽之間的關鍵依賴關系,利用BiLSTM 獲得文本的特征向量。
從表3 和表4 中的實驗結果來看,BR、CC、TextCNN 的性能明顯差于剩下的五種模型。因為BR、CC、TextCNN 傳統的方法只考慮去挖掘文本中蘊含的特征,而忽略了標簽的作用,反觀其余五種模型都采用了不同的方法去發揮文本和標簽的作用,極大地提高了模型的性能。
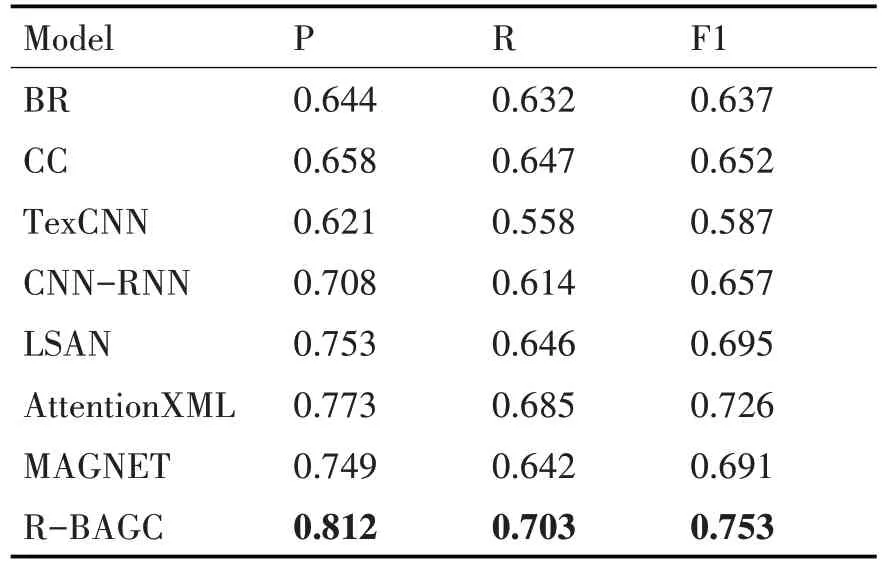
表3 在AAPD數據集上的實驗結果
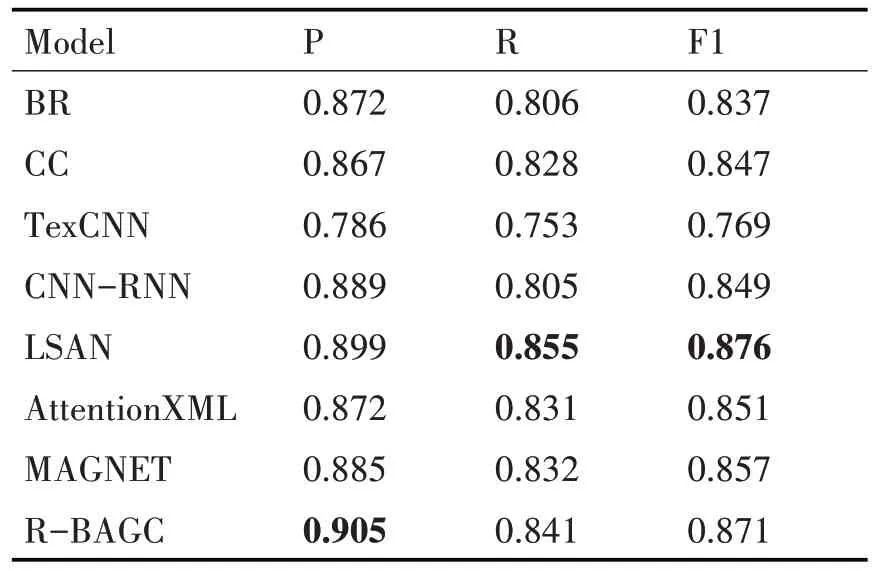
表4 在RCV1數據集上的實驗結果
在AAPD 數據集上的實驗結果表明本文提出的模型在性能上優于其他模型。本文所提出模型除了考慮到了標簽與文本之間的關系,還考慮到了標簽之間的關系,而其他的對比模型,除LSAN、CNN-RNN、MAGNET模型外,其余模型僅僅考慮了文本與標簽之間的關系,而忽略標簽內部之間的關系,這說明科學的利用標簽內部的關系能在一定程度上提高模型分類的性能。
本文提出的模型在RCV1 數據集上的實驗結果稍微差一點,比起LSAN 模型,在召回率上低了1.4%,在F1 上低了0.5%。因為LSAN 為每個標簽學習一個特定的文檔表示,并將這些標簽特定的表示合并成一個全局的文檔表示,這樣能夠更好地捕捉每個標簽與文本之間的關系,并減輕了不同標簽之間的相互干擾。通過計算標簽的成對共現來構造的鄰接矩陣是對稱的,即假設標簽之間的相關性是對稱的,但實際上標簽之間的相關性可能是非對稱的。這樣會導致鄰接矩陣中的權重不能準確反映標簽之間的關系,從而影響分類性能。而RCV1數據集的共現矩陣在維度上比AAPD 數據集的共現矩陣大三倍,在利用GAT 去挖掘標簽之間的關系時,不僅會消耗更多的內存資源,而且模型可能需要更多的參數和計算資源來處理這個矩陣。這可能導致模型的學習效率下降,需要更多的數據和更長的訓練時間才能達到較好的性能,如果epoch過小或者數據過少,就會降低了模型的性能,所以這可能是R-BAGC 在RCV1 數據集上表現出來的性能弱于LSAN的原因。
為了進一步驗證模型各組件的有效性,本文在兩個數據集上進行了兩組消融實驗,實驗結果如表5、表6所示。
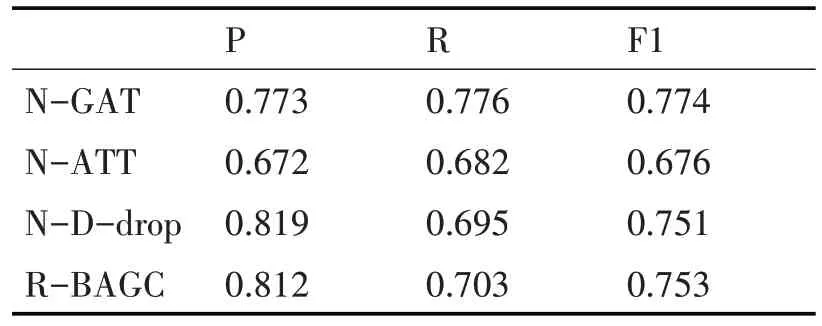
表5 在AAPD數據集上的消融實驗
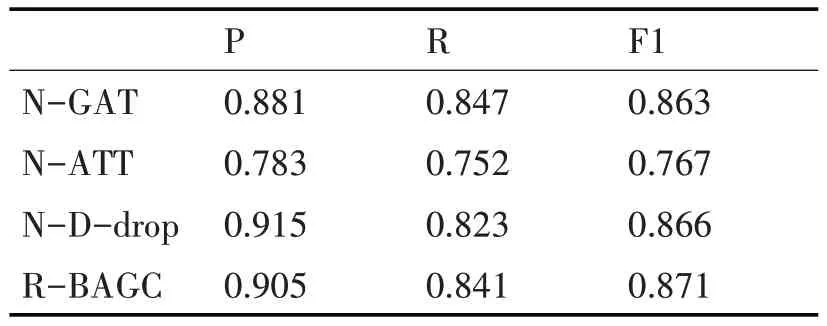
表6 在RCV1數據集上的消融實驗
1)N-GAT 表示沒有使用GAT 建立標簽之間的關系,直接使用標簽嵌入作為多頭注意力機制的Query;
2)N-ATT 表示沒有使用多頭自注意力機制來建立文本與標簽的關系,只是簡單把經過GAT 后的文本嵌入和標簽嵌入在第二個維度上進行拼接;
3)N-D-drop表示沒有使用D-drop策略進行訓練,直接采用式(13)作為損失函數進行訓練。
在兩個數據集上的消融實驗結果顯示,去掉GAT、多頭自注意力機制兩個模塊,會降低模型整體的分類性能,這說明這兩個模塊會提升模型整體效果。其中去掉多頭自注意力的模型性能下降最為顯著,可能是簡單地將文本嵌入和標簽嵌入拼接在一起,對于原本的文本特征添加了一定程度的干擾,從而影響了最終的性能,需要使用更加科學的和更深層次的“文本-標簽”交互方案。在沒有使用R-drop 策略訓練模型時,準確率提高而召回率降低的情況表明模型可能過于嚴格,對于模型認為不確定或較為復雜的樣本,模型更傾向于將其劃分為負例,從而導致漏檢率較高。然而,在使用R-drop策略訓練模型后,雖然準確率略有下降,但召回率和F1值均提高了。這說明R-drop策略有助于提高模型的魯棒性從整體消融實驗結果來看,R-BAGC模型能夠有效地融合各個組件的優勢,提升模型整體效果。
5 結語
本文提出了一種多標簽文本分類模型R-BAGC,該模型充分挖掘并利用了文本與標簽之間、標簽與標簽之間的關系。實驗結果表明,該方法在兩個標準多標簽文本分類數據集上的性能優于當前先進的多標簽文本分類算法。然而,R-BAGC 對于具有大量標簽的數據集,計算標簽的成對共現會得到一個高維度、多數元素為零的鄰接矩陣,會導致矩陣稀疏,增加計算的復雜度。而且所有標簽都被等價看待,會忽略標簽的重要性差異。在多標簽分類中,不同的標簽對于預測的重要性可能是不同的,因此這種方法可能無法很好地區分不同的標簽。另外,基于R-drop 的對抗訓練雖然可以提高模型的魯棒性,但是也在一定程度上增加了模型訓練所需的資源和訓練時間。下一階段將針對以上問題進行更深一步的研究。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
制造技術與機床(2019年10期)2019-10-26 02:48:08
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
