基于學習風格的個性化自適應資源推薦算法研究?
2024-04-17 07:28:26王浩暢潘俊輝MariusPetrescu
計算機與數字工程 2024年1期
王浩暢 王 輝 潘俊輝 Marius.Petrescu 張 強
(1.東北石油大學計算機與信息技術學院 大慶 163318)(2.普羅萊斯蒂石油天然氣大學 什蒂 100680)
1 引言
隨著數據時代的迅猛發展,海量數據蘊含著巨大的價值,大數據的分析、挖掘及運用已經滲透到社會生活的各個領域[1]。與國內電子商務領域知名平臺相比,如“淘寶”、“百度新聞”等平臺的個性化推薦服務已成功融入人們生活,然而大數據推薦服務在教育領域中的發展與應用滯后很多,顯得相對緩慢[2]。疫情期間,隨著移動互聯網應用技術和教育信息化的深度結合,各類在線教學平臺比比皆是,但在教育領域,一直以來都未能真正解決“因材施教”的問題,傳統教學平臺僅作為提供知識倉庫的載體,幾乎沒有關注到學習者個體的不同需求,不能保證及時調整教學策略[3]。
由于推薦算法設計單一且不到位,推薦內容往往不夠“精準”[4]。利用現代信息技術和大數據技術,注重個體特征的個性化自適應學習,實現智慧教育,已成為順應信息時代創新、培養具備應用能力合格人才的迫切需要[5]。本文結合已有的在線教學平臺實際資源,探索基于學習風格的混合式個性化自適應學習資源推薦算法的研究與實踐。
2 個性化自適應學習
個性化學習的概念,最早來源于孔子提出的“有教無類”教育思想。自適應學習是指通過動態調整學習資源,為學習者提供個性化服務的一種學習方式,能夠根據學習者表現的個性特征,進行動態預測及策略調整,保證推送學習資源及學習途徑的差異化、精準化,以期實現最優的學習效果。
國外較早開展了個性化自適應學習的研究。1959 年,美國開啟了自適應學習的先河,成功開發了第一個計算機輔助教學系統[6]。自21 世紀初以來,國外對于自適應學習的研究呈整體上升趨勢,研究范圍逐步擴寬,美國的Peter Brusilovsky、荷蘭DeBra 以及澳大利亞Wolf 等也陸續研發了諸多個性化教育系統,得到了研究界普遍認可,陸續涌現了諸如Knewton、Knowre等著名自適應學習平臺[7]。
自21 世紀以來,隨著科技的迅猛發展,個性化自適應學習也逐漸引起國內學者專家的重視,各種計算機技術層出不窮,語義網本體技術、文本挖掘、模糊邏輯、進化算法、貝葉斯網絡、推薦算法[8]等先進技術也陸續被應用于自適應學習系統[9]。例如,姜強等提出的個性化自適應在線學習分析模型,在國內一直處于領先水平[6]。
3 基于學習風格的個性化自適應資源推薦算法
個性化自適應學習模式,以學習者學習風格為中心,從學習者實際情況出發,運用大數據相關技術給出個性化動態調整,最終為學習者提供有效的資源推薦。
3.1 學習風格
學習風格是指學習者在學習時所表現出來的學習方式,簡言之,學習者在研究和解決某個學習任務時,所表現出來的具有個人特色的或偏愛的某種學習方式[10]。自1954 年,賽倫提出學習風格概念之后,陸續出現了很多有關學習風格模型的研究。其中,以Felder-Silverman 學習風格模型應用最為普遍,它將學習風格劃分成了四個維度八個屬性,如表1所示,分別為信息輸入(視覺型/言語型)、信息加工(感悟型/直覺型)、內容理解(活躍型/沉思型)、感知(綜合型/序列型)[11~12]。

表1 學習風格維度及屬性
3.2 構建學習資源的學習風格模型
首先,需明確學習資源在每個維度分別屬于哪種類型。學習者完成挑選資源的學習后,須對學習資源進行“非常滿意、滿意、一般、不滿意、非常不滿意”的評價,系統根據所有學習者的評價結果,利用式(1)計算出某項資源在某維度某類型的概率P。
其中,Pi表示評價為“非常滿意”的某維度某類型的概率,m 表示“非常滿意”的人數;Pj表示評價為“滿意”的某維度某類型的概率,n 表示“滿意”的人數。可得到每項資源在所有維度及類型上的概率Pij矩陣,如式(2)與式(3)所示。
其中,i 表示維度,j 表示維度i 對應的類型,Pi3表示對Pi1和Pi2進行歸一化處理后的結果。依此,得到學習資源在各維度的風格數據,形成學習資源模型庫。
3.3 構建學習者的學習風格模型
每個維度都有對應的11 道測試題,形成了獲取學習風格數據的所羅門調查問卷(ILS)[13],系統會將回答結果以一個空間矩陣形式表示,如式(4)與式(5)所示。
其中,ILSi分別表示四個維度,ILSi1與ILSi2表示回答該維度的統計數據,ILSi3表示學習風格傾向。依此,得到學習者在各維度風格數據。
3.4 個性化資源推薦算法
3.4.1 基于學習風格過濾的個性化資源推薦算法
基于學習風格過濾的推薦算法,其核心思想是利用余弦相似性原理,根據式(6)計算選取學習資源與學習者學習風格相似度大的資源進行推薦[14]。
3.4.2 基于協同過濾的個性化資源推薦算法
基于協同過濾的推薦算法,其核心思想是根據式(7)計算學習者學習風格相似性來進行推薦操作,即向具有相似學習風格的學習者推薦其擁有的個性化學習資源[15]。
3.4.3 基于關聯規則的個性化資源推薦算法
基于關聯規則的推薦算法,其核心思想是根據學習資源中知識點內在關聯的特點,向學習者推薦一些關聯度較大的學習資源,進一步有效優化個性化資源推薦效果[16],如圖1所示。

圖1 基于關聯規則的推薦算法示意圖
學習資料中各知識點相互之間存在一定的關聯,知識點1 與2、3、4、5 之間存在相關性,知識點2與5、8 存在相關性,知識點7 與4、8 存在相關性。當學習者獲得了知識點2 的學習資源時,可通過計算知識點2 與其他知識點之間的相關性相似度,向其推薦關聯度較大的學習資源。
4 個性化自適應資源推薦系統
依據因材施教的原則,以“數據挖掘”課程為例,融合個性化自適應資源推薦算法,搭建了個性化自適應學習平臺。
4.1 推薦系統平臺架構
個性化自適應學習資源推薦系統平臺架構由三層線性架構組成,即表示層、業務邏輯層、數據訪問層,如圖2所示。
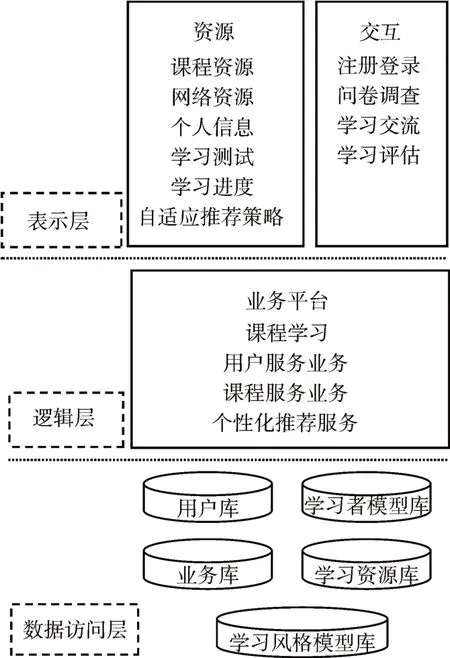
圖2 推薦系統平臺架構
整個平臺不斷采集學習者學習風格相關數據,利用大數據技術分析學習者學習行為數據,通過推薦算法分析,為學習者提供自適應學習路徑,推薦最佳學習資源。
4.2 個性化自適應學習資源推薦流程
個性化自適應學習資源推薦系統以微信小程序作為網絡教學平臺,應用基于學習風格的資源過濾、協同過濾、關聯規則的個性化資源推薦算法,構建了如圖3所示的學習資源推薦模型。
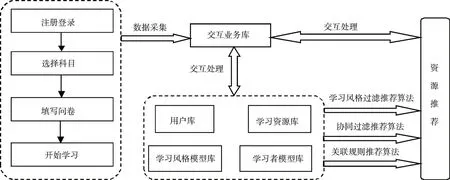
圖3 個性化自適應學習資源推薦模型
學習者經過“注冊-登錄”、選擇所學科目、填寫所羅門調查問卷等一系列操作,將所產生的相關教育數據,即學習者學習風格、學習者基本信息等,逐一提交給用戶庫、學習風格模型庫及學習者模型庫等數據庫。
推薦系統根據學習者產生的學習風格,采用大數據分析技術,依據基于學習風格過濾、基于協同過濾、基于關聯規則的個性化資源推薦算法并行處理,確定學習需求,生成個性化學習路徑,給出推薦資源,達到自建學習資源的目的。
同時,結合學習者學習行為不斷產生的操作日志數據及學習者特征數據,系統可適時更新推薦算法得到的資源推薦。系統平臺的操縱者,也可為學生推薦學習資源,避免“信息孤島化”。
4.3 個性化自適應學習資源推薦效果
資源推薦服務水平的高低,取決于推薦系統關聯的數據。如表2 所示,針對不同學習者,當學習同一資源時,不同算法給出了不同推薦結果。
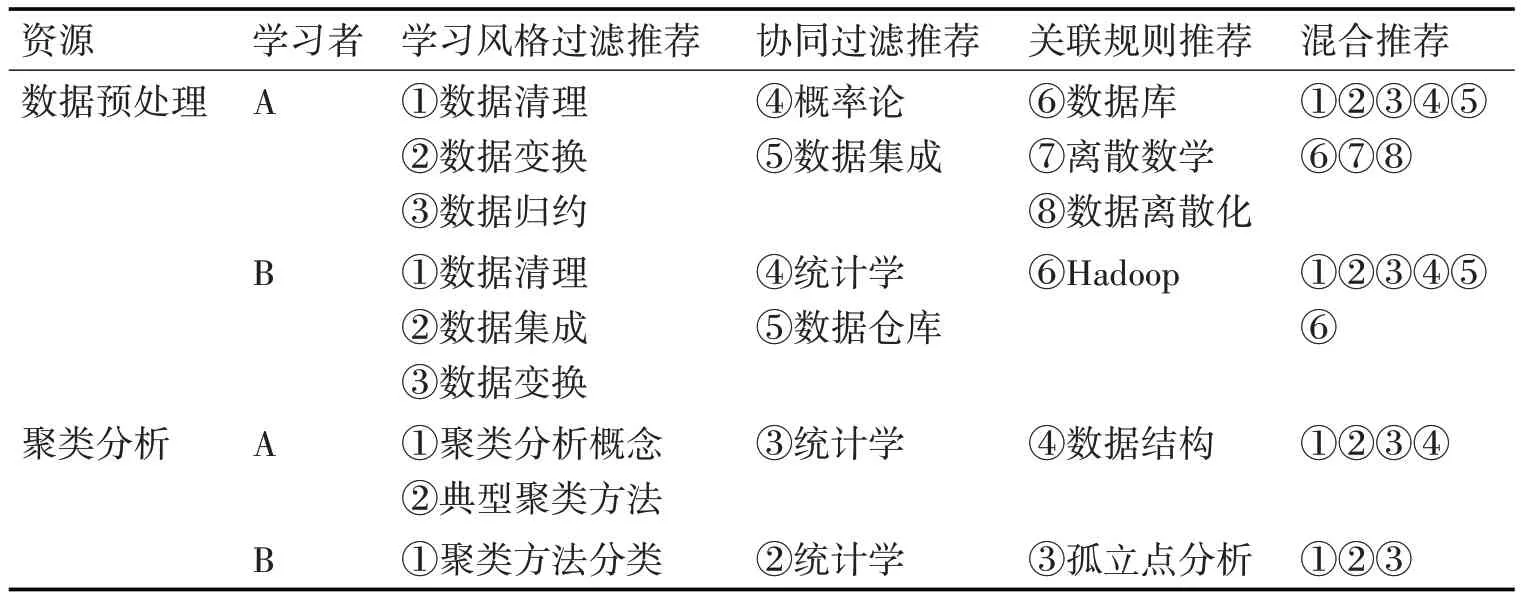
表2 資源推薦結果對比
表2 中,學習者A 為非計算機相關專業學生,學習者B為計算機相關專業學生。當學習者A與B學習同一資源時,推薦系統根據學習者學習風格得到學習風格相似度較大的資源過濾結果,再根據相似學習風格學習者曾經的學習資源得到協同過濾推薦資源,又根據學習資源關聯規則得到推薦資源,最終將三類算法推薦結果綜合,得出混合推薦資源。研究結果表明,通過學習風格的分析,根據得到的資源推薦結果可以看出,系統對學習者的前期知識掌握程度進行了明顯的區分,將一些前期應該掌握的專業知識推薦給了非專業學習者,而對專業學習者推薦更多的是深層次的學習資源。隨著推薦系統在各類在線教學中的廣泛應用,系統數據庫的不斷完善,推薦系統逐步實現多種方式并行的混合推薦,推薦資源精準度必定明顯提升,成為必備的教學助手。
5 結語
本文針對個性化自適應資源推薦算法進行了深入的研究與分析,將基于學習風格過濾、協同過濾及關聯規則過濾算法綜合應用于個性化自適應資源推薦系統。研究表明,推薦系統能夠為學習者提供精準的個性化資源,形成了完整的學習資源推薦生態圈。在未來的工作中,將進一步研究學習者更多個性特征,如心理特征等,并嘗試更多領域的研究對比。
猜你喜歡
江蘇安全生產(2023年1期)2023-02-08 05:58:38
工業設計(2022年8期)2022-09-09 07:43:20
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
裝備制造技術(2019年12期)2019-12-25 03:06:46
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
家庭影院技術(2017年9期)2017-09-26 03:41:45
