基于服務質量的虛擬化云資源動態分配算法?
2024-04-17 07:28:32李凱鋒吳海燕賀莉娜
計算機與數字工程 2024年1期
李凱鋒 胡 泓 吳海燕 賀莉娜 胡 宇
(1.南瑞集團公司(國網電力科學研究院) 南京 211000)(2.國電南瑞科技股份有限公司 南京 211106)(3.北京市軌道交通運營管理有限公司 北京 100068)
1 引言
隨著互聯網和信息化技術的不斷進步,越來越多的應用由于其數據量指數級的增長,必須通過借助云資源來實現,云計算[1]的時代已經來臨。云服務提供者通過將數據中心的多種基礎資源進行深度整合,實現對計算資源、網絡資源、存儲資源的虛擬化和統一化調度管理[2],并通過調度中心為用戶申請的任務分配資源。
然而,云計算的動態特性決定了云資源分配時,既要滿足不同任務服務質量[3](quality of service,QoS)的需求,還要增加云平臺的吞吐量,提高資源利用率。經典的遺傳算法[4~7]、模擬退火算法[8~10]、蟻群算法[11~14]和粒子群算法[15~16]等云資源分配算法,主要將注意力集中在如何縮短任務的完成時間,而不注重任務的服務質量需求(包括時間、成本、安全性和可靠性等),這會導致用戶的滿意度降低。蟻群算法雖然可實現群體性的組合優化,但由于初期信息素的平均分配,存在過多的盲目搜索行為,影響算法效率。
針對以上不足,本文提出了一種基于服務質量的云資源動態分配算法,根據用戶的時間、成本、安全性和可靠性四種服務質量需求建立數學模型,對云資源動態分配算法進行約束。將遺傳算法與蟻群算法相結合,利用遺傳算法更新信息素矩陣后,再使用動態融合策略獲得兩種算法的最優融合時間,最后通過蟻群算法求出最優解,優化了虛擬資源負載,提高了用戶滿意度。
2 服務質量數學模型
虛擬化的云資源動態分配就是云服務提供者將計算資源按照用戶的需求分配給用戶的過程。進行虛擬云資源分配需要在符合用戶服務質量需求的前提下,將獨立的任務分配給有效的虛擬資源,讓虛擬資源被高效合理地利用。本文將用戶對服務質量的需求分為時間需求、成本需求、可靠性需求和安全性需求四個方面,并建立了服務質量數學模型。
設任務集合T={t1,t2,…,tn},表示當前有n個等待處理的任務在任務隊列中。云資源集合R={r1,r2,…,rm},表示當前有m個有效資源在資源池內,其中資源是云計算中處理任務的基礎運算單位。
時間歸屬函數TM(i,j)如式(1)所示:
式(1)中,RTij表示任務ti在資源rj中執行的預期執行時間,RT(i,j)表示任務ti在資源rj中執行的實際執行時間。
成本歸屬函數CM(i,j)如式(2)所示:
式(2)中,Cij表示任務ti在資源rj中生成的預期成本,C(i,j)表示任務ti在資源rj中生成的實際成本。
安全性歸屬函數SM(i,j)如式(3)所示:
式(3)中,TSij表示任務ti對資源rj的期望安全級別,Sij表示資源rj提供給任務ti的實際安全級別,Smax表示任務的最高安全級別。
可靠性歸屬函數RM(i,j)如式(4)所示:
式(4)中,TRij表示任務ti對資源rj的期望可靠性,SRij表示該資源rj提供給任務ti的實際可靠性。
服務質量目標函數如式(5)所示:
在(5)中,λ1、λ2、λ3、λ4分別表示服務質量目標函數中的時間,成本,安全性和可靠性權重。
3 服務質量約束的遺傳-蟻群資源分配算法
3.1 服務質量約束的遺傳-蟻群算法基本思想
由于遺傳算法的后期運算效率較低,易導致許多的重復迭代。而蟻群算法每條路徑在初始時期的信息素都相同,盲目性較高,浪費了大量搜索時間。因此本文考慮了用戶對服務質量的多種需求指標,將遺傳算法與蟻群算法相結合,提出了服務質量約束的遺傳-蟻群資源分配算法。此算法分為如下三部分:
1)利用遺傳算法的全局快速搜索能力,并將所獲得的全局搜索信息轉化成蟻群算法的初始信息素。
2)判斷遺傳算法和蟻群算法融合的正確時間。
3)利用蟻群算法的正反饋和高效收斂的特性,完成滿足服務質量條件的云資源最優分配。
3.2 遺傳算子全局快速搜索
3.2.1 染色體編碼
本文將染色體的長度定義為任務的數量,并通過編碼處理任務。染色體內的基因值是與其位置相應任務所利用的資源數量。定義云環境中的初始系統規模是S,任務集內n個任務被隨機分發給m個空閑的資源,n表示染色體的長度,1 與m范圍內的隨機數則表示單個基因的值。
3.2.2 適應度函數
適應度主要用來評估群體中個體的質量,本文選擇服務質量目標函數的倒數作為適應度函數。服務質量目標函數的四個指標系數滿足λ1+λ2+λ3+λ4=1,可根據用戶需要設置相應的權重。
3.2.3 選擇、交叉和變異操作
選擇操作使用輪盤賭方式生成選擇算子,選擇概率通過任務調度適應度值占所有任務適應度值的比值進行計算。
使用戴維斯順序交叉法進行交叉操作,設常數Pc為交叉概率。變異操作則利用逆向變異法,設常數Pm為變異概率。
3.3 遺傳算法與蟻群算法的融合
遺傳算法和蟻群算法的融合非常困難,一般方法是把遺傳算法設成固定迭代運行,但是運算結束的太早或太晚都會影響算法的效率。因此本文使用動態的結合方式來保證蟻群算法和遺傳算法在最優的時間點進行結合。
1)設置最小遺傳迭代次數Genemin和最大遺傳迭代次數Genemax。
2)計算子代群體在遺傳迭代過程中的進化速率,并設置子代種群的最小進化速率為Genemin-impro-ratio。
3)如果后代種群的連續迭代Genedie(Genemin≤Genedie≤Genemax) 的 進 化 速 率 小 于Genemin-impro-ratio,則可以證明遺傳算法優化速度較低,那么系統就可終止遺傳算法流程并進入蟻群算法流程。
3.4 蟻群算子精確求解
3.4.1 初始化信息素

3.4.2 選擇操作
在t時刻,可以將資源j分配給任務i的概率表示為
在式(9)中,τj表示t時刻資源j上信息素的濃度。ηj表示資源的可見性,即啟發式信息。η=aP+bB,P表示CPU 的處理能力,B表示網絡帶寬,a和b分別表示處理能力和帶寬在資源可見性中的比例系數。α是信息素因子,體現運動軌跡的重要性;β是啟發式因子,體現期望值的重要性。
3.4.3 信息素更新
局部信息素更新:當螞蟻完成所有任務的資源分配時,將更新所有分配資源的信息素殘留量。假設τj(t)是t時刻上資源rj的信息素,那么在t+1 時刻,資源rj的信息素更新規則如下:
在式(10)中,1-ρ為信息素殘留因子,ρ表示信息素揮發因子(0<ρ<1)。?τ(t)可以從式(11)得到,其中L表示資源數量。
全局信息素更新:當全部的螞蟻都結束一次迭代時,根據式(5),可以在該次迭代中求解出全局最佳調度方案,并全局更新最佳調度方案中資源的信息素。

基于服務質量的遺傳-蟻群云資源分配算法流程如圖1所示。

圖1 遺傳-蟻群云資源分配算法流程圖
4 仿真實驗與分析
4.1 實驗仿真
為了測試本文設計的算法性能,選擇Cloudsim5.0.3 云仿真平臺對蟻群算法、遺傳算法、遺傳-蟻群算法進行了仿真和結果對比分析。在云仿真平臺Cloudsim5.0.3中配置云環境的初始條件,包括創建數據中心、初始化任務規模參數、配置輸入輸出數據文件大小及任務大小和創建虛擬機資源,包括CPU、帶寬和內存等。在DatacenterBroker 類中構造遺傳-蟻群算法、遺傳算法和蟻群算法三種算法。
設置服務質量目標函數權重:λ1=0.2 ,λ2=0.3,λ3=0.22,λ4=0.28。設置選擇參數的概率:α=0.7,β=0.3,ρ=0.4。表1 所示為遺傳蟻群算法相關仿真參數。

表1 遺傳-蟻群算法相關仿真參數
4.2 結果分析
本文的算法將用戶服務質量作為資源分配的約束函數,結合蟻群算法和遺傳算法的雙重優勢,提高了求解的收斂速度。比較分析了遺傳算法、蟻群算法和服務質量約束的遺傳-蟻群算法,并實現了仿真示例。資源負載計算公式如下所示。
式(14)中,Loadj是資源j 的負載,Loadavg是負載的平均值。仿真結果分別如圖2和圖3所示。
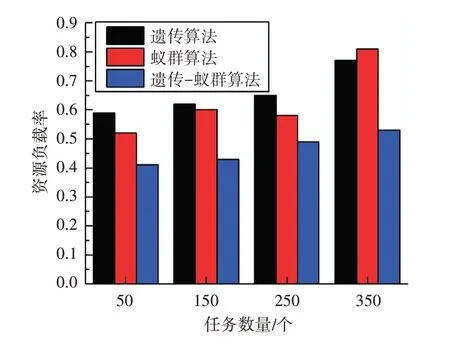
圖2 資源負載對比圖
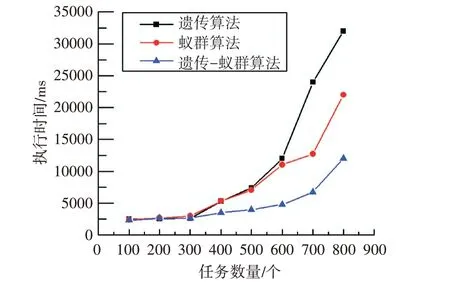
圖3 執行時間比較
分析圖2 結果可發現,隨著任務數量的增加,三種算法資源的負載率也隨之增加。但是與遺傳算法和蟻群算法相比,基于服務質量的遺傳-蟻群算法的資源負載率變化較小,并且始終保持較低的水平。與遺傳算法和蟻群算法相比,基于服務質量的遺傳-蟻群算法的資源負載率分別提高了28%和24.1%。因此,基于服務質量的遺傳-蟻群算法的虛擬資源分配結果更加趨于高效合理,云平臺的負載均衡度也在不斷提高。
根據圖3 可發現,三種算法的任務數量與執行時間之間都存在正相關的關系。當任務數量大于500 時,隨著任務數量的增加,三種算法的執行時間都有所增加,可見任務數量的增加會影響算法執行的效率。蟻群算法和遺傳算法的執行時間都遠多于服務質量約束的遺傳-蟻群算法的執行時間,并且執行時間保持在較低水平。因此,不論是運算的時間效率還是尋找最佳解的效率,基于服務質量的遺傳-蟻群算法均超過單個的遺傳算法與蟻群算法。
5 結語
本文提出了一種基于服務質量的虛擬云資源動態分配算法,該算法考慮了多種服務質量指標,通過將遺傳算法和蟻群算法融合并將服務質量指標轉換為歸屬函數作為遺傳算法的適應度函數,求得的最優解能夠滿足用戶的服務質量需求。在CloudSim云計算平臺進行的仿真結果表明,該算法在資源負載均衡角度和時間花費角度都好于單個遺傳算法與蟻群算法,在最大化云計算資源利用效率的同時,明顯提升了服務質量。
猜你喜歡
江蘇安全生產(2023年1期)2023-02-08 05:58:38
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
中華手工(2017年2期)2017-06-06 23:00:31
資源再生(2017年3期)2017-06-01 12:20:59
中外會展(2014年4期)2014-11-27 07:46:46
職場(2009年4期)2009-01-01 00:00:00
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
