基于多尺度特征融合的YOLOv3 行人檢測算法?
2024-04-17 07:28:42黎國斌王等準扈健瑋林向會謝本亮
計算機與數字工程 2024年1期
黎國斌 王等準 張 劍 扈健瑋 林向會 謝本亮
(貴州大學大數據與信息工程學院半導體功率器件可靠性教育部工程研究中心 貴陽 550025)
1 引言
行人檢測技術以往是人工提取特征,例如SIFT[1]、LBP[2]、SURF[3]、HOG[4]以及Haar[5]等特征描述因子,提取行人特征后輸入分類器中進行學習,傳統的分類器有adboost[6]或者SVM[7],最后輸出分類的結果。YOLOv3[8]作為一階段檢測算法,略去區域候選框過程,在保證檢測性能的同時提升檢測速度,該算法摒棄以往僅僅利用最后檢測層進行單尺度輸出,而是同時輸出三種尺度的目標,更適合本文研究的內容,所以本文使用YOLOv3 作為基準算法。
行人檢測是一種特殊的目標檢測算法,只是檢測目標限定于行人。圖1 是Caltech[9]行人檢測數據集的統計圖。
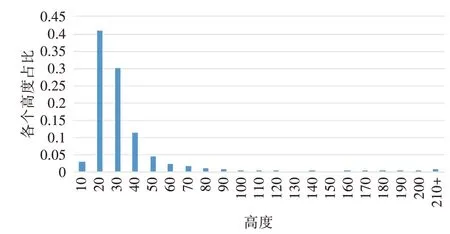
圖1 Caltech數據集行人尺度統計圖
由上可知,行人大小尺度分布不均勻,行人尺度主要分布在50 像素以下。在現實生活中,由于道路行人與車載成像設備之間的距離不同,成像后行人尺度差距十分顯著,因此,本文在YOLOv3 算法基礎上,改進特征提取網絡,引入多尺度特征融合模塊至殘差單元中,替換原來僅僅是兩個卷積層堆疊的殘差單元。改進后的殘差單元,可以將不同尺度的特征進行融合,那么多個殘差單元堆疊就可以進一步融合更多不同尺度的行人特征,提高網絡對不同尺度特征的提取能力。
2 相關工作
特征融合在目標檢測算法中是非常常見的,特征 融 合 有 很 多 種 方 式,例 如ResNet[10]的 跳 連 接(skip connection)、FPN[11]的長連接(long connection)、Inception[12]中同層不同分支間特征拼接或者按像素相加進行特征融合。
針對不同尺度不同語義的特征,Yimian Dai等[13]提出多尺度通道注意力模塊(MS-CAM)。多尺度通道注意力模塊結構圖如圖2所示。

圖2 多尺度通道注意模塊結構圖
輸入X分別通過全局和局部分支,全局分支依次通過全局平均池化層得到C×1×1 特征,接著輸入到深度可分離卷積得到C/r×1×1 特征,隨后輸入到批量歸一化(BN),非線性激活函數(Re-LU),再通過深度可分離卷積得到C×1×1 特征。同理,局部分支除去全局平均池化操作外,其他與全局分支相同。最后將全局的語義信息和局部的特征信息進行相加,通過激活函數(Sigmoid)將特征信息權重限定在[0,1],最后與原特征X相乘得到調整后的特征X′。MS-CAM 僅僅是單輸入,難以融合不同層的特征,因此將淺層特征X深層特征Y、多尺度通道注意力模塊結合一起,構造成多尺度特征融合模塊(AFF),AFF 網絡結構圖如圖3所示。
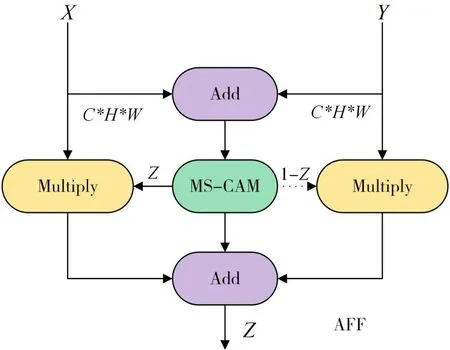
圖3 多尺度特征融合模塊
X為淺層特征,Y為深層的特征,特征圖的寬為W,高為H,通道數為C。X和Y相加得到的特征,繼續通過MS-CAM,得到兩個分支,左分支是特征融合后的權重,并且局限在0到1之間,而右分支是通過全1 矩陣減左分支的值得到的,右邊權重也是限定在[0,1],隨后左右分支分別與原特征進行矩陣乘法運算,得到的結果進行相加運算得到最后的輸出Z?RC×H×W,即得到的Z是淺層細粒化特征與深層語義信息融合后的特征。
3 本文算法
本文算法分三個小節進行闡述,首先簡述本文改進算法的結構設計、其次闡述改進算法的訓練過程、最后針對改進算法的實驗環境及結果做進一步的分析。
3.1 本文算法結構設計
為了實現不同尺度行人的檢測,本文在YOLOv3 算法的特征提取網絡中引入多尺度特征融合模塊,改進前的殘差單元結構圖如圖4。

圖4 改進前的殘差單元結構圖
將原輸入x、x經過連續兩個DBL卷積層得到的特征y、x與y相加得到的特征w,x表示淺層特征,y表示深層特征,改進后的殘差單元結構如圖5所示。

圖5 改進后的殘差單元結構圖
淺層特征x與左分支權重z相乘得到淺層調整后的特征,深層特征y與右分支相乘得到深層調整后的特征,然后將調整后的特征相加得到最后輸出。將改進Res_unit 替換YOLOv3 中的Res_unit,其他網絡結構不變。
3.2 網絡模型訓練設計
由于兩個階段的學習率不一樣,模型更新步伐不同,第一階段將學習率調大,可以加快模型訓練,第二階段調小學習率,可以更好地找到全局最優解,所以模型訓練過程分為兩個階段,第一階段實驗超參數設計如表1所示。
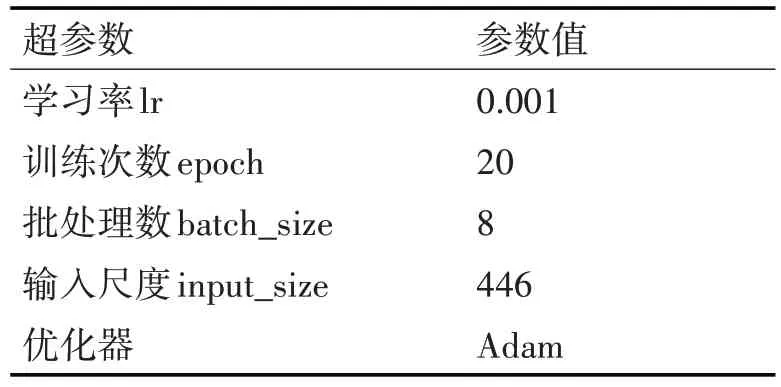
表1 第一階段實驗超參數表
第二階段學習率調整為0.0001,訓練次數epoch設置為10,其他參數與上相同。
模型訓練,訓練與驗證集比例為7∶3,并隨機打亂訓練集。網絡訓練的最終目的是保存最佳的權重參數,而權重更新的方法很多,本文使用學習率自適應二階優化方法Adam(Daptive Moment Estimate)。該優化方法可以自適應地調整學習率,并且適合處理不平穩的目標函數,計算效率高且內存需求小,正好適用于行人檢測數據集。
3.3 本文實驗結果與分析
3.3.1 實驗配置與數據集
本文實驗環境分為兩部分,其一是本地調試程序使用的個人計算機運行平臺,其二是實驗室搭建的英偉達(NVIDIA)GPU 服務器。個人計算機運行平臺軟硬件環境配置如表2所示。
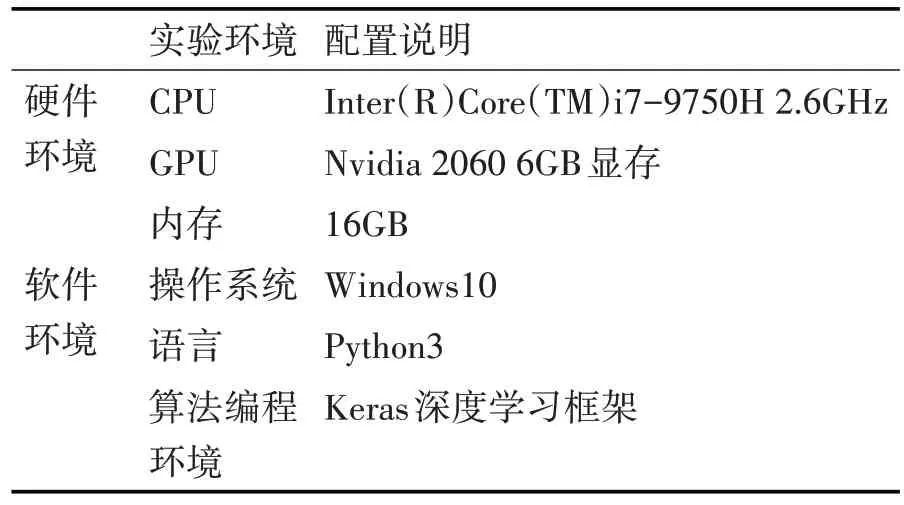
表2 本地調試程序個人計算機軟硬件環境
服務器軟硬件配置如表3所示。
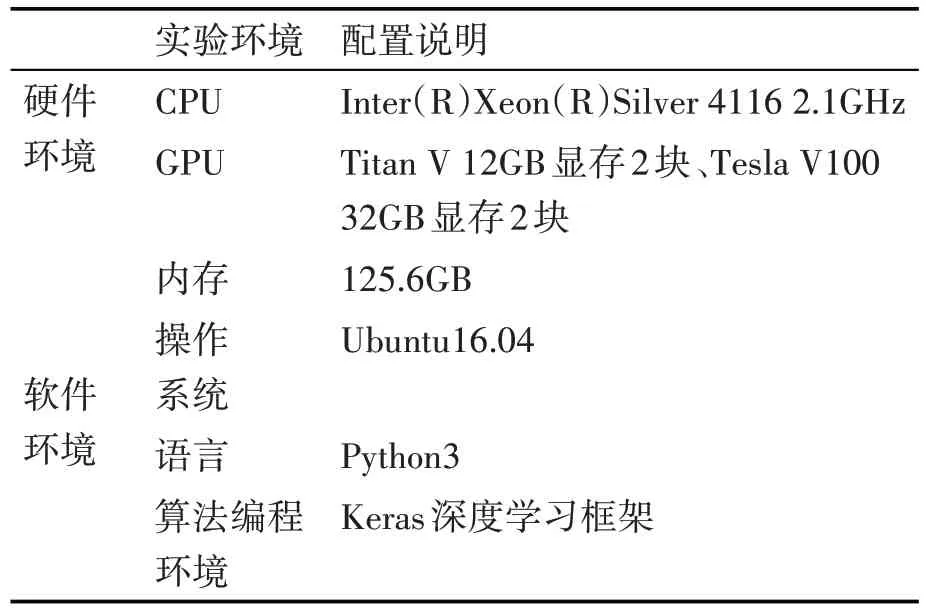
表3 服務器軟硬件環境配置

表4 改進算法在Caltech、On_merge數據集訓練的測試結果
本文實驗使用的數據集共2 個,分別為Caltech和On_merge數據集。選擇set00-set05 作為Caltech訓練集,共有67020張訓練圖片。On_merge數據集包含Caltech 訓練集、Cityperson[14]訓練集、驗證集,共有69663 張訓練圖片。由于Caltech 數據集中存在部分錯標漏標的情況,本次實驗的測試集選用set06 中部分數據集,測試集經過調整后,測試圖片數量為2059張。
3.3.2 實驗結果與分析
替換Darknet53為引入多尺度特征融合模塊的特征提取網絡,其他網絡結構與YOLOv3 一樣。經過實驗,得到如圖6~7所示PR曲線圖。

圖6 Caltech數據集精準率-召回率曲線圖

圖7 On_merge數據集精準率-召回率曲線圖
從圖6、7 知,改進算法(YOLOv3+mscam)的平均精準率比基準算法高,并且在On_merge 數據集的平均精準率都比基準算法高,進一步說明改進算法的有效性。On_merge 數據集包含Caltech 和Cityperson數據集,模型泛化能力更強。
YOLOv3+mscam 表示引入多尺度特征融合模塊的YOLOv3 算法,分別在Caltech、On_merge 數據集進行訓練,測試得到的結果;R 表示召回率,P 表示精準率。從表5、6 可知,對于Caltech 數據集,YOLOv3+mscam、YOLOv3 在置信度分別等于30.79%,26.4%取得上述F1系數、召回率、精準率以及平均精準率。YOLOv3+mscam 的平均精準率比基準算法高出其5.49%,F1調和系數比基準算法高出其3.42%,精準率比基準算法高出其14.1%。
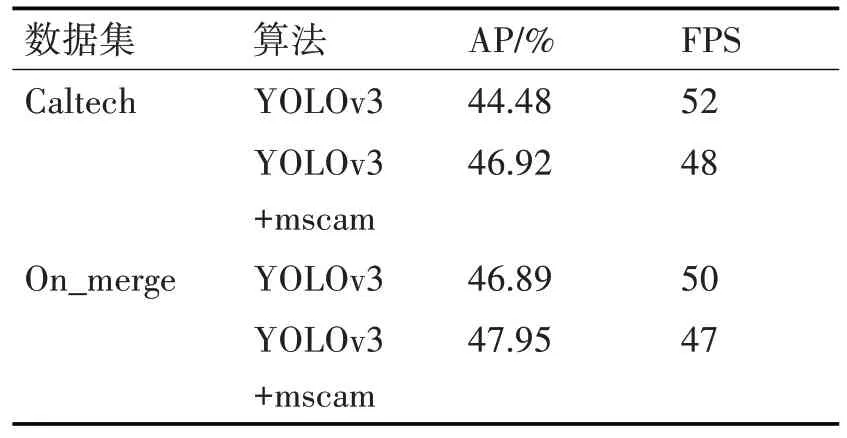
表5 改進算法在Caltech、On_merge數據集訓練的測試結果
取得上述性能提升的主要原因是引入了多尺度特征融合模塊,并且是引入到殘差單元(ResNet)內部,依然保持殘差連接特性,即增加網絡深度的同時不會引起梯度消失的問題。增加特征提取網絡的深度,進一步提升特征提取網絡的非線性表達能力,增強網絡對行人特征的提取能力。
此外,多尺度特征融合模塊內部融合通道域注意力機制,融合全局與局部的信息,可以更好判別行人特征信息,降低假陽性率,在通道域注意力機制的引導下,網絡增加行人特征對應通道的響應權重,降低背景等無關信息對應通道的響應比例,因此網絡可以更加傾向行人可見特征信息,降低行人特征信息以外等無關信息的干擾,更多有用行人特征信息參與網絡訓練,網絡對行人的識別能力也進一步加強。
由圖3 可知,多尺度特征融合模塊外部改變為雙輸入,一輸入為淺層的特征、另外一輸入為殘差學習后的特征,兩輸入相加后的特征信息輸入至多尺度通道注意力模塊,得到兩個特征比例權重,淺層特征、殘差學習后特征分別與各自比例權重相乘得到各自調整后的特征,最后將調整后的特征相加輸出,經過多級特征融合的殘差單元級聯,可以更好地融合不同尺度行人的特征信息,從而提高行人檢測的性能。
為了更直觀理解改進算法的模型參數,基準算法與改進算法的模型參數如表6。
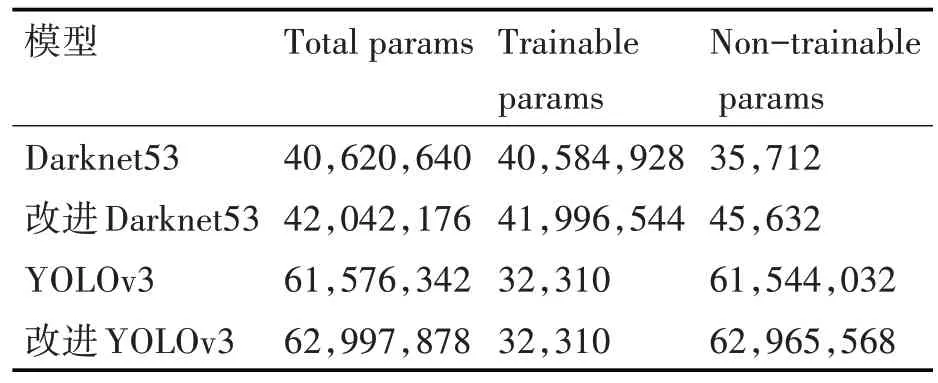
表6 模型參數對比表
雖然改進算法在特征提取網絡引入別的網絡層,但總體的計算量增加不大,改進算法在Tesla V100 的FPS 為48,基準算法的FPS 為52,都能滿足檢測實時性要求。
為了更直觀地理解改進算法的有效性,改進算法與基準算法的檢測效果圖如圖8~9所示。

圖8 改進算法檢測效果全圖

圖9 改進算法檢測局部放大圖
紅色框代表基準算法的檢測結果,綠色框代表改進算法的檢測結果,從圖8、9 知,基準算法對于距離較遠的小尺度行人存在漏檢,而改進算法可以完全框出圖像中的行人。
為了驗證改進算法的有效性,將改進的算法在On_merge 訓練集進行訓練,經測試得到表4 與表5結果。YOLOv3+mscam、YOLOv3 在置信度分別等于33.81%,34.28%取得上述F1 系數、召回率、精準率以及平均精準率。YOLOv3+mscam 的平均精準率比基準算法高出其2.26%。進一步說明改變原來特征提取方式,替換為帶多尺度特征融合模塊的特征提取網絡,可以提升不同尺度行人的檢測性能。
紅色框是基準算法,綠色框是改進算法,從圖10、11 得知,改進算法的檢測效果更佳。基準算法對較小尺度行人存在漏檢,改進算法可以很好地擬合小尺度行人。

圖10 改進算法檢測效果全圖

圖11 改進算法檢測局部放大圖
4 結語
在行人檢測技術中,行人大小尺度問題比較常見,一直也是行人檢測的難點。由于行人與成像設備間的距離不同,導致行人大小尺度不一問題尤為顯著,本文針對行人大小尺度問題,提出基于多尺度特征融合的YOLOv3 行人檢測算法。由于YOLOv3 的特征提取網絡Darknet53 引入了殘差連接,那么在殘差單元里引入多尺度特征融合模塊,改變特征的提取方式,將淺層特征和經過殘差學習的深層特征進行融合,融合后輸入多尺度通道注意力模塊,可以同時關注行人的全局信息和局部信息,并更加關注行人的有用信息,降低無用信息對網絡的干擾。最后在Caltech 數據集和Cityperson 數據集上進行消融實驗,上文也統計Caltech 數據集中的行人尺度,行人尺度分布廣泛,小尺度行人尤為顯著,提高不同尺度行人檢測性能,為后續行人重識別[15]、行人跟蹤等領域的研究奠定堅實的基礎。
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
