一種基于隨機森林和Light GBM 的房產估價模型?
2024-04-17 07:29:02馮梓豪劉從軍
計算機與數字工程 2024年1期
馮梓豪 劉從軍,2
(1.江蘇科技大學計算機學院 鎮江 212000)(2.江蘇科大匯峰科技有限公司 鎮江 212000)
1 引言
隨著房地產市場化和市場經濟體制的發展,房產評估需求迅速增加,近年來國內外有大量學者對房地產評估問題展開了研究,例如:楊燦通過Light GBM 模型對二手房進行評估[15]。Lu等提出了一種基于Lasso和梯度提升回歸的組合模型用于評估房價[19]。陳敏等建立了一種神經網絡分級模型來對二手房價進行評估[7]。楊磊以特征價格為理論基礎構建了二手房價格評估模型,在其中應用了地理信息技術系統技術實現了房產估價[13]。但上述方法在特征選擇和運行效率方面還存在改進的空間。
本文的主要工作如下:基于學者Butler提出的房地產價格理論,提出時間特征作為房產價格評估的特征。通過隨機森林算法對特征重要性進行排序,剔除對預測值影響較小的特征,再通過網格搜索對模型進行優化,最后使用訓練好的模型對房產價值進行預測。
2 模型建立
2.1 隨機森林特征選擇算法
隨機森林算法是在傳統決策樹算法的基礎應用統計學采樣原理上構建的一種聚合算法,常用于回歸問題和分類問題。隨機森林具有高精度的特性,并且具有良好的魯棒性。它通過結合多個決策樹來構建模型,每個決策樹的建立都是基于獨立抽取的樣本。在分裂節點時,它依賴于不純度指標和袋外數據錯誤率來做出決策。
傳統的隨機森林重要特征性度量方法是對每一個特征隨即置換并由隨機森林對特征置換后生成新的袋外數據進行測試,當特征的重要程度越高,隨機森林的預測誤差率的變化就會越大,現假設隨機森林中的決策樹目為Ttree,原始數據集由N個特征,單特征Xi(i=1,2,3…,N)的基于OOB 誤差分析的特征重要性度量如下:
1)計算第i棵決策樹相應的袋外數據的錯誤樣本數ErrrorOOBi。

3)重復1)、2)步驟得到所有的錯誤樣本以及隨機調整順序后的錯誤樣本。
4)計算所有決策樹特征簇Xji置換前后OOB分類誤差率的平均變化量:

2.2 Light GBM模型
Light GBM 是由微軟DMTK 團隊開源發布的,是一個輕量級的GB框架,基于決策樹的學習算法,支持分布式。其算法流程如下:
1)初始化n 課決策樹,每個訓練樣例的權重為1/n。
2)訓練弱分類器f(X)。
3)設置該弱分類器的話語權β。
4)更新權重。
5)得到最終分類器,表達式如下:
Light GBM 模型使用了直方圖做差加速和Leaf-wise 生長策略,降低了模型的運算速度和內存消耗,直方圖算法示意圖如圖1,Leaf-wise 生長策略如圖2所示。
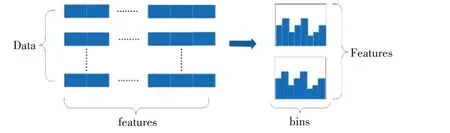
圖1 直方圖算法示意圖
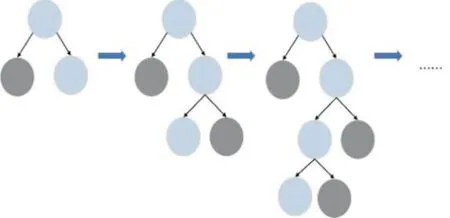
圖2 Leaf-wise生長策略
2.3 RF_lightGBM模型
基于Light GBM 的高效率和高準確率以及低內存消耗,選擇以Light GBM 建立房產價格預測模型,同時以混淆矩陣計算特征的準確度、精度等指標檢驗隨機森林選擇的特征是否有效,然后將經過特征選擇之后的數據輸入Light GBM 算法進行學習,采用網格搜索優化尋參過程,通過網格搜索得到模型的超參數,Python 提供的scikit-learn 庫可幫助找到最合適的超參數。模型如圖3所示。
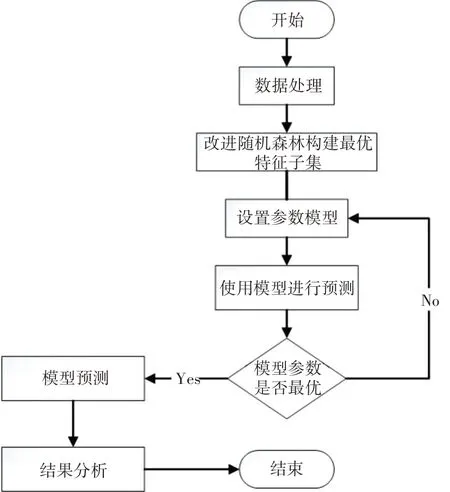
圖3 RF_Light預測模型流程圖
3 特征選擇與超參數調整
3.1 特征選擇
特征價格理論是房地產評估領域的重要理論之一,由Ridker 首次引入。該理論認為,房地產作為一種商品,其價格不僅僅取決于其地理位置、建筑質量等單一因素,而是所有特征屬性的效用之和。這些特征屬性包括房屋的面積、房齡、裝修程度、周邊設施等等。每一個特征屬性都會對房地產的總效用產生影響,從而影響其價格。學者Butler將影響房地產價格的因素進行了整合分類,提出了三類適用的特征變量,包括區位特征,結構特征以及鄰里環境。根據Butler 的理論,房產價格可以描述為P=f(L,S,N)。
該方程在特征價格理論公式的基礎上將變量分為三類,分別是L-區域特征,S-結構特征,N-鄰里環境。
本文在Butler提出的價格理論上,提出假如T-時間特征,則房產價格可描述為P=f(L,S,N,T)。
本文共設定35 個量化指標,其中區域特征如表1所示。

表1 區域特征表
鄰里環境如表2所示。
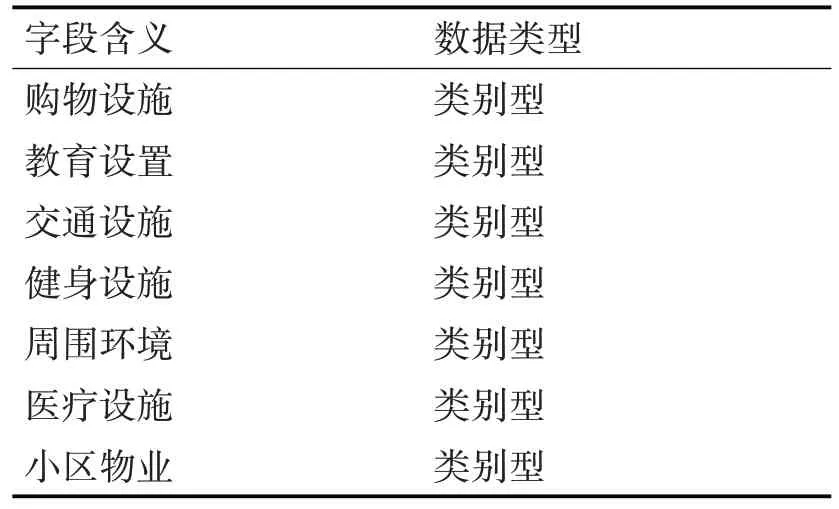
表2 鄰里環境表
結構特征如表3所示。
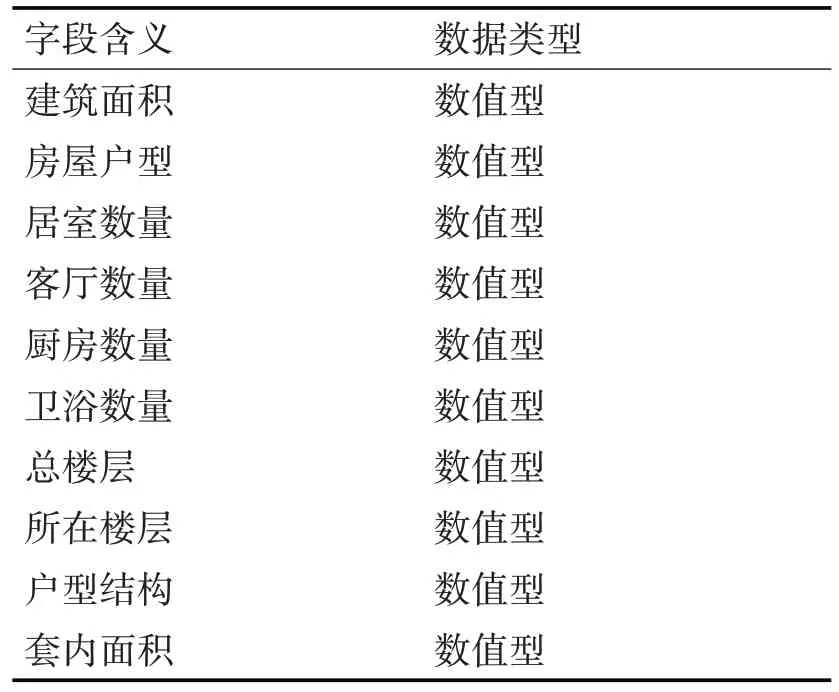
表3 結構特征表
時間特征如表4所示。

表4 時間特征表
將上述特征使用隨機森林進行重要度進行排序,得出的排序后的特征如圖4所示。
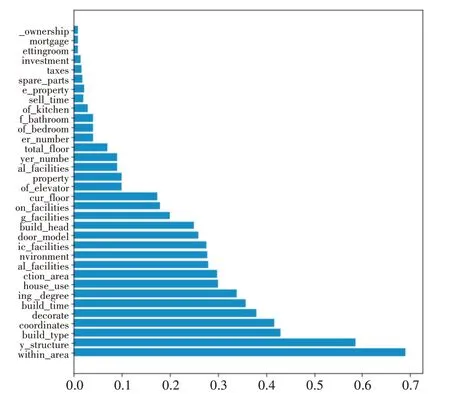
圖4 排序后特征
3.2 Light GBM超參數調整
模型的超參數是通過網格搜索和五折交叉驗證得到的,本文使用Python 庫scikit-learn 中的GridSearchCV 方法來搜索最優超參數。優化了增強迭代次數、梯度增強算法的步長、最大樹深、一棵樹中最大葉子數、葉子中最小樣本數、葉子中最小Hessian和。具體參數如表5所示。
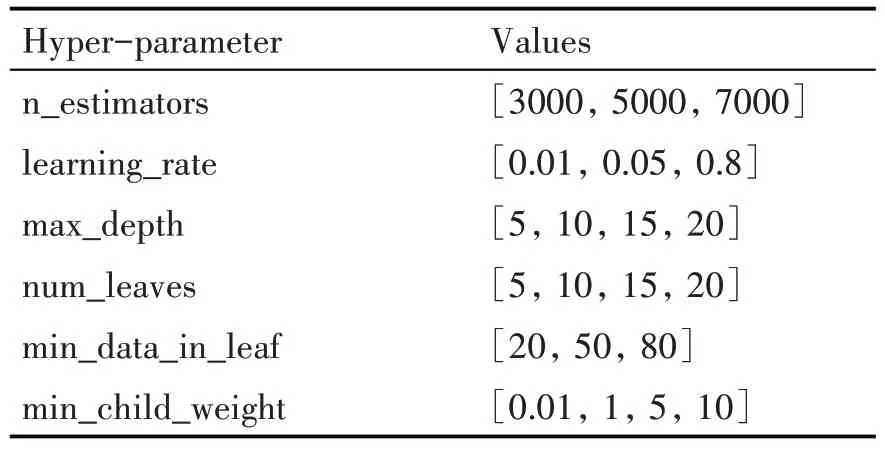
表5 Ligh GBM超參數表
4 實驗結果
為保證模型的普適性和在真實場景中的準確性,本次實驗使用的數據為公開的房產數據集。
將數據進行數據清理后,共得到63725 條數據,將其按照70%為訓練數據,30%為測試數據進行劃分。
使用RF_LightGBM 模型對準備好的數據進行了預測,得到了預測價格和實際價格的平均值為2566.7 元,平均相對誤差為4.28%。測試集中的大部分誤差在0%~15%之間,占比為98.72%。具體的相對誤差分布情況如表6所示。

表6 相對誤差分布情況表
表7 隨機森林超參數表
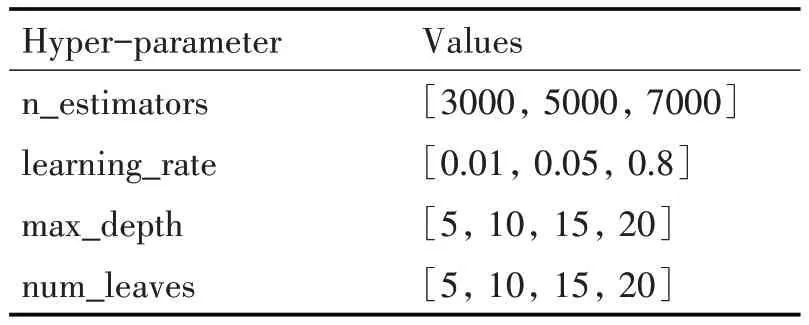
表8 XGBoost超參數表
本文比較了RF_LightGBM 模型的房產價值評估模型與目前研究或行業中常用的評估方法。本文選取了兩種方法進行比較,分別是隨機森林模型和XGBoost模型,并給出了這兩種模型的參數設定。
為了合理地評價模型的綜合性能,本文以平均絕對誤差(MALE)和隊數均方根差(RMSLE)作為模型的評價指標。MALE 能更好地反映觀測值誤差的實際情況,而RMSLE 則是用來衡量觀測值和真實值之間的偏差,其計算公式如下:
其中pi表示實際的房價,而pi表示模型預測的房價。各模型對比結果如表9所示。
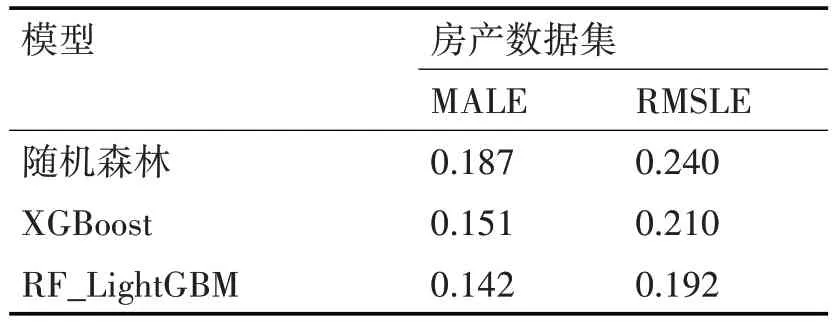
表9 模型結果比對表
三種預測模型得出的平均房價(元/m2)得出的柱狀圖如圖5所示。
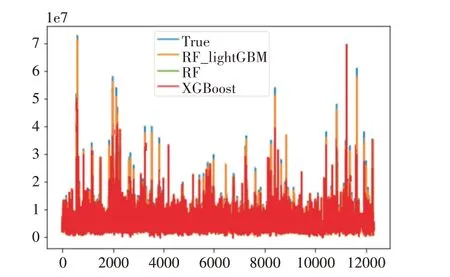
圖5 預測房屋均價比較圖
從表9 可以看出RF_LightGBM 模型性能明顯優于隨機森林,XGBoost 等深度學習模型。從圖5可以看出RF_LightGBM 模型預測的房屋均價相對于隨機森林和XGBoost 模型更加貼近真實數據,且存在偏差較小。
5 結語
隨著信息技術的飛速發展,大數據、人工智能等技術為企業和社會帶來了前所有的機遇,本文在傳統的預測模型上,提出了RF_LightGBM 模型,使用隨機森林對特征進行選取和重要度排序,將預測過后的特征數據使用Light GBM 模型進行預測。實驗表明,所提模型準確率優于隨機森林,XGBoost等學習模型,房產評估結果也更加貼近實際值。
在未來的工作中,結合我國基本國情與政策,通過人文因素,經濟環境因素等進一步提取和細化對房產產生影響的因子,提高評估結果的精度和模型的普適性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
