呼吸系統疾病知識圖譜的構建?
2024-04-17 07:29:24陳雪松張明磊王浩暢
計算機與數字工程 2024年1期
關鍵詞:藥品
陳雪松 張明磊 王浩暢
(東北石油大學電氣信息工程學院 大慶 163318)
1 引言
知識圖譜,是谷歌2012年提出[2]的一種新型的數據表示方式,其目的是為了改善其下一代的搜索引擎。知識圖譜以實體為節點、關系為邊組成網狀結構,能夠清晰的表示數據之間的關聯信息,在智能問答等多方面展示出豐富的應用價值[14]。國內的搜狗和百度首先建立了通用領域知識圖。隨后,金融[3]、法律等垂直領域也開始構建領域圖譜。在醫療領域,文獻[4]參考萬方乙肝領域文獻,構建了乙肝疾病的知識圖譜,文獻[5]利用文本抽取等技術,構建了中醫藥知識圖譜,文獻[6]以人機結合的方式構建了中文醫學知識圖譜。近年來,國內科研人員紛紛致力于醫療知識圖譜的研究,但與國外相比,仍處于初步階段[7]。
呼吸系統疾病是一種常見的多發疾病,對人體危害極大,是中國十大死亡率疾病之一。本文根據自身需求,爬取了相關呼吸疾病數據,構建呼吸系統疾病知識圖譜,為患者提供自助查詢以及輔助醫療人員診斷治療。
2 知識圖譜的構建
2.1 體系架構
知識圖譜以圖結構的形式表示知識信息,描述了客觀世界的事物以及關系[11]。主要分為數據層和模式層[8],有自頂向下和自底向上兩種構建方法[9]。為了保證醫療數據的準確性和規范性,本文采用自頂向下的方法構建呼吸系統疾病知識圖譜。首先參考醫學文獻構建了呼吸疾病詞典,然后通過該詞典從不同醫學網站爬取疾病數據,并根據實際需求構建了呼吸系統疾病本體,最后經過知識融合實現多源異構數據的鏈接,完成呼吸系統疾病中文知識圖譜的構建。知識圖譜構建架構如圖1 所示,共分為四個步驟,通過循環迭代實現知識圖譜的持續更新。

圖1 呼吸系統疾病知識圖譜構建架構
2.2 本體構建
本體構建的主要目的是構建完整的呼吸系統疾病知識體系,主要分為人工構建、自動構建、半自動構建三種[10]。由于呼吸系統疾病數據規模不大,為了得到高質量、高準確度的本體,本文采用人工構建的方法構建呼吸疾病本體。首先參考了百度百科以及相關醫學文獻[15],根據實際的應用需求定義了七種實體類型:疾病、科室、癥狀、診斷檢查、飲食、藥品、在售藥品;九種實體之間關系:在售、宜吃、忌吃、屬于、常用藥品、推薦藥品、推薦食物、疾病癥狀、疾病并發癥;以及各實體的屬性,例如疾病屬性有病因、簡介、治療周期、別名、易感染人群、傳播方式、預防、治療方法等。本文采用Protégé軟件構建呼吸系統疾病本體,如圖2為呼吸疾病本體。
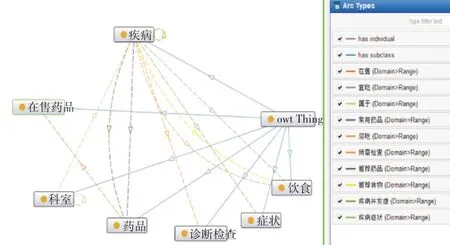
圖2 呼吸系統疾病本體
2.3 數據獲取
在醫療領域缺少開源的數據庫,本文采用分布式爬蟲技術爬取垂直型醫療網,如39 健康網、尋醫問藥網等網站的醫療數據。共爬取了478 條呼吸疾病數據,包含了所有的呼吸疾病數據以及相關藥品屬性信息。爬取到的疾病數據以JSON 格式保存,并進行了初步清洗,對數據重新審查和校驗,目的在于刪除非法字符,糾正存在的錯誤,保證數據的一致性。
2.4 知識融合
知識融合[16]是將同源異構數據相連接。主要分為實體對齊和實體鏈接[12]兩個方面。因為呼吸疾病數據是根據疾病詞典獲得,所以實體對齊部分可省略,采用屬性對齊替換。首先根據構建好的本體進行屬性對齊,然后計算各屬性的相似度,最后根據屬性相似度計算實體相似度,完成知識融合。
2.4.1 屬性對齊
在呼吸系統疾病中,屬性種類不多,可以根據呼吸疾病本體來構建屬性映射表,將同一類實體的同一屬性的不同表達方式對齊。表1 是不同來源數據的屬性對齊映射。再通過本體定義的屬性類型將各屬性值規范化處理,主要規則有:1)統一所有數值型屬性值的度量單位;2)保留區間型屬性值的上限和下限;3)去除字符串屬性和文本類屬性中的錯誤字符;4)對于所有的屬性值的缺失值均以NAN表示。

表1 部分屬性對齊映射
2.4.2 屬性相似度
完成屬性對齊后,計算不同類型屬性相似度。由于疾病實體包含了大量的別名信息,可將實體名稱與別名合并成集合來計算相似度。假設有x和y兩個實體,實體的名稱集合為S和T。
1)實體名稱集相似度
通過計算集合S和T的交集元素在S,T的并集中所占的比例、衡量兩個集合的相似度。len(x,y)表示字符串屬性xattr、yattr最大公共子序列長度。

3)文本類型相似度
首先通過呼吸系統疾病詞典以及結巴分詞對文本類屬性進行分詞,然后根據TF-IDF(Term Frequency-Inverse Document Frequency,詞頻-逆文件頻率)找出文本的關鍵詞。最后,通過余弦相似度計算關鍵詞集合的相似度:

4)區間型屬性相似度
數值區間和時間區間屬性都可采用Dice 系數計算相似度,取值范圍在[0,1]:
其中|xattr∩yattr|是x和y區間屬性的交集,|xattr|和|yattr|分別表示x和y屬性中元素的長度。
2.4.3 實體相似度
根據得到的屬性相似度,采用加權平均的方法,得到最終的實體相似度[1]:

實驗結果采用準確率、召回率、F1 值進行評判,實驗結果:準確率為81.4%,召回率為61.5%,F1值70.1%。
至此,完成多源異構數據的知識融合。
3 圖譜的可視化與應用
3.1 可視化展示
本文采用Neo4j圖數據庫存儲[17]呼吸系統疾病三元組數據以及可視化展示,Neo4j 以屬性圖的的形式存儲數據節點,具有訪問速度快、性能高、輕量級等特點[18]。呼吸系統疾病中文知識圖譜存儲了共15763 條呼吸疾病三元組數據,包括疾病的簡介、癥狀、科室、治療周期、藥品以及檢查等關鍵數據信息。表2為主要實體類別統計數據表。
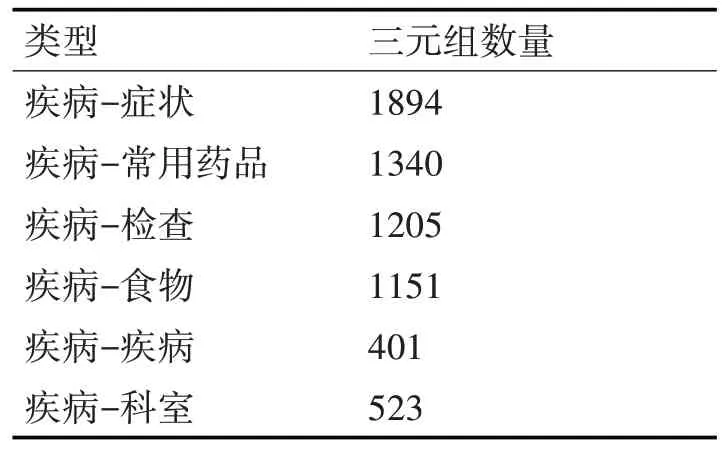
表2 主要實體類別統計數據表
呼吸系統疾病知識圖譜提供自助查詢。圖3是肺炎部分屬性查詢圖。患者通過圖譜查詢的肺炎常用藥品,包括阿莫西林顆粒,羅紅霉素膠囊等好評藥品。

圖3 肺炎部分屬性查詢圖
此外,呼吸疾病知識圖譜還可以根據患者的臨床表現,輔助醫生決策。例如,根據圖譜信息,為一位有“呼吸困難”“咳嗽”“發熱”等癥狀的患者,進行“血常規”“胸部平片”“支氣管舒張試驗”等檢查,判斷此患者是否患有“哮喘”疾病。
3.2 主要應用
醫療知識圖譜的構建形成了相應的醫療知識體系,解決了醫療領域數據爆炸的問題,使得人們面對大量數據時,能夠快速準確地獲取關鍵信息。醫療問答系統[13]是呼吸疾病知識圖譜的主要應用之一,將構建好的知識圖譜上的關系要素引入到問答過程中,解決了傳統問答模型對醫療領域知識利用不足的問題,方便患者了解自身病情、存儲藥物、調理身體。第二個應用是醫療決策支持系統,通過患者的臨床表現、病歷單、化驗報告等數據信息,為醫療人員提供智能診斷,分析醫生診斷方案,提升醫療質量、降低醫療風險。
4 結語
本文針對呼吸疾病醫療數據數據分布龐雜、難以深層次應用的問題。爬取了呼吸疾病醫療數據,通過計算不同屬性的相似度得出實體相似度,鏈接相同實體,完成知識融合。最后利用Neo4j 圖數據庫存儲呼吸疾病數據以及可視化展示,完成了呼吸疾病知識圖譜的構建。未來工作將繼續完善知識圖譜,以及研發基于呼吸疾病知識圖的問答系統等輔助診治系統。
猜你喜歡
中國合理用藥探索(2022年1期)2022-11-26 00:22:32
世界最新醫學信息文摘(2021年12期)2021-06-09 08:36:56
小學生優秀作文(低年級)(2018年6期)2018-05-19 01:54:28
消費導刊(2017年20期)2018-01-03 06:27:16
中國衛生(2016年6期)2016-11-23 01:09:08
中國衛生(2016年5期)2016-11-12 13:25:28
中國藥物應用與監測(2015年5期)2015-12-11 03:15:54
中國衛生(2015年9期)2015-11-10 03:11:14
中國衛生(2015年5期)2015-11-08 12:09:48
中國衛生(2015年4期)2015-11-08 11:15:58
