融合全局信息的多圖神經網絡會話推薦
2024-04-22 02:30:38黃濤,徐賢
小型微型計算機系統 2024年4期
黃 濤,徐 賢
(華東理工大學 計算機科學與工程系,上海 200237)
0 引 言
在互聯網搜索、電子商務、流媒體服務等在線應用中,推薦系統都扮演著關鍵角色,目的在于為用戶提供有用的信息,以減輕信息過載對用戶造成的沖擊.傳統方法主要依靠用戶的偏好文件或長期的歷史交互信息進行推薦.然而,在大多數情況下,由于用戶沒有任何可用的歷史會話交互記錄,可用于推薦的唯一資源就是當前會話的信息.因此,基于會話的推薦SBR(Session-based recommendation)引起了廣泛關注,它根據給定的匿名用戶會話序列按時間順序預測用戶下一個最有可能交互的物品[1].
早期對基于會話推薦的研究大多分為兩類,分別是基于馬爾科夫鏈[2,3]和協同過濾[4,5]的推薦方法.基于馬爾可夫鏈的會話推薦的主要思想是根據用戶之前的行為預測下一個行為.這種方法只考慮了相鄰物品之間的順序關系,而沒有考慮物品之間的其它關系.通過將矩陣分解和一階馬爾可夫鏈相結合,Rendle等人[6]提出了FPMC(Factorized Personalized Markov Chains)模型,該混合模型通過捕捉序列模式和用戶的長期偏好來實現推薦,但忽略了序列之間的潛在表示,因此不能達到滿意的效果.基于協同過濾的方法利用物品之間的相似性進行推薦,已經得到了廣泛應用.在協同過濾中,許多方法通過計算用戶和物品之間的相似矩陣來獲得推薦結果.Kabbur等人[7]使用結構方程方法將物品矩陣建模為兩個低維潛在因子矩陣的乘積,以完成Top-K推薦.近年來,基于神經網絡的方法也被應用于協同過濾.He等人[8]提出了一種基于神經網絡的協同過濾框架NCF(Neural Network-based Collaborative Filtering),該框架利用多層感知器來學習用戶物品交互功能.此外,Chen等人[9]提出了一種聯合神經協同過濾模型J-NCF(Joint Neural Network-based Collaborative Filtering),該模型通過充分挖掘用戶和物品的交互信息來學習物品的深層特征.雖然上述協同過濾方法被證明是有效的,但是忽略了用戶的最新偏好和整個點擊序列的時間相關性.
近年來,隨著深度學習技術的不斷發展,基于循環神經網絡RNN(Recurrent Neural Network)的會話推薦方法成為了研究熱點.Hochreiter等人[10]提出LSTM(Long Short Term Memory)的RNN變體網絡,以更好地建模序列.Hidasi等人[11]將RNN結合到會話推薦中,并利用多層門控循環單元(GRU)建模交互式物品序列.Jannach等人[12]將GRU4REC(Gated Recurrent Unit for Recommendation)與KNN(K-Nearest Neighbor)方法相結合,對會話序列進行采樣,提高了推薦效果.在此基礎上,Tan等人[13]通過數據增強改進了RNN,并考慮了會話數據分布的時間變化.Peng等人[14]提出了HARSAM(A Hybrid Model for Recommendation Supported by Self-Attention Mechanism)的深度學習模型,該模型使用自注意力機制對用戶交互數據進行建模,并學習用戶的潛在偏好表達.Jing等人[15]提出了NARM(Neural Attentive Recommendation Machine)注意力模型,將注意力機制應用于會話特征編碼器,以捕捉用戶在當前會話中的主要意圖.Qiao等人[16]提出了基于注意力機制的短期記憶網絡STAMP(Short-Term Attention/Memory priority)模型,有效的捕獲了用戶的偏好信息.Wang等人[17]提出CSRM(collaborative session-based recommendation machine)模型,將 RNN網絡和注意力機制結合,同時利用協同信息預測用戶偏好.Wang等人[18]指出,基于RNN的方法主要通過對給定歷史用戶物品交互的序列依賴性建模來實現推薦.雖然基于深度學習的方法(主要是基于RNN的方法)在會話推薦中取得了一定程度的成功,但是它們仍然存在一些不足,具體如下:1)它們也只考慮當前會話序列中相鄰交互項之間的依賴性,而忽略了交互項與其它位置項之間的依賴關系;2)它們只依賴于當前會話的信息,而不考慮其它交互會話信息.
圖神經網絡GNN[19-22](Graph Neural Network)能夠克服以往方法的局限性,逐漸成為主流的會話推薦方法.與基于RNN的推薦方法不同,基于GNN的方法大多首先將會話序列建模為會話圖,然后使用GNN在圖中聚合相關鄰居節點的信息.Wu等人[23]提出SR-GNN(Session-based Recommendation with Graph Neural Network)模型,使用注意力機制計算用戶的全局偏好,將最后一項作為用戶的當前偏好,并使用全局和當前偏好的線性組合生成會話的最終表示.Xu等人[24]提出圖上下文自注意力模型GC-SAN(Graph Contextual Self-Attention Model based on Graph Neural Network),該模型使用圖神經網絡和自注意力機制來學習會話序列中物品之間的長期依賴關系.Qiu 等人[25]提出加權注意網絡圖模型FGNN(Full Graph Neural Network),該模型利用多權重圖注意層(WGAT)來計算會話序列中物品之間的信息流,從而獲得物品表示,然后通過特征提取器聚合物品表示以捕獲會話特征.Wu等人[26]提出了GARG(Geographical Attentive Recommendation via Graph)模型,該模型將應卷積神經網絡和注意力機制相結合為用戶提供合適的新興趣點.當使用上述的GNN模型構建會話圖時,不同的會話序列可能具有相同的圖,或者相同的圖可能映射到不同的會話序列,將導致信息丟失并影響最終的推薦效果.Chen 等[27]提出LESSR(Lossless Edge-order preserving aggregation and Shortcut graph attention for Session-based Recommendation)模型,將會話序列建模為邊緣保序圖和快捷圖,并設計了邊緣保序聚合層和快捷圖注意力層,解決了無效的長期依賴問題,有效避免信息丟失.盡管上述方法在會話推薦中取得了可接受的推薦結果,但是存在兩個明顯的缺點:1)基于GNN的方法只考慮了當前會話序列,并沒有考慮其它會話對當前會話的影響;2)將會話序列建模為一個簡單的會話圖,GNN只能捕捉到物品之間的成對傳遞關系,但無法獲得物品之間復雜的高階關系.
對于普通圖,一條邊只能連接到兩個頂點,而超圖是一般圖的推廣,一條邊可以連接任意數量的頂點.在構造超圖時,將所有會話序列建模為超邊.超邊上的所有物品都是相互連接的,不同的超邊通過共享項連接.這樣構造的超圖既考慮了其它會話之間的交互信息又包含了物品之間復雜的高階信息.因此,本文提出一種融合全局信息的多圖神經網絡會話推薦模型(GIMGNN),該模型使用超圖卷積神經網絡(HGCN)和門控圖神經網絡(GGNN)分別捕捉物品之間復雜的高階關系和成對傳遞關系,從而有效學習物品全局會話級別和局部會話級別的特征表示,極大的提高了會話推薦的準確度.
本文的主要工作如下:
1)提出全局會話超圖和局部會話圖相結合的多圖神經網絡會話推薦模型,充分利用超圖神經網絡捕捉物品之間復雜的高階信息能力,提高會話推薦的性能.
2)使用求和池化操作融合物品的全局和局部級別上下文信息表示之后,通過使用注意力機制來處理融合的特征,學習會話序列的最終表示,從而得到更為準確的推薦結果.
3)在兩個真實數據集Yoochoose和Diginetica上進行了一系列實驗,實驗結果表明,對比性能最優的基準模型,GIMGNN模型在Yoochoose上P@20和MRR@20至少提升了2.42%和4.01%,在Diginetica上P@20和MRR@20至少提升了6.56%和9.11%,驗證了模型的有效性 .
1 GIMGNN模型
在本節中,首先介紹GIMGNN模型總體架構,其次對會話推薦問題進行描述,構造兩種類型的圖模型,分別是局部會話圖和全局會話超圖.接著分別使用門控圖神經網絡(GGNN)和超圖卷積神經網絡(HGCN)分別生成物品的局部會話特征表示和全局會話特征表示.然后通過注意力機制融合物品的局部會話特征表示和全局會話特征表示生成會話表示.最后將會話表示和物品全局特征表示進行線性組合得到最終表示,從而計算每個推薦候選項的排名分數.
1.1 模型整體架構
本節將超圖卷積神經網絡和門控圖神經網絡應用于基于會話的推薦方法中,提出了一種融合全局信息的多圖神經網絡會話推薦模型(GIMGNN),如圖1所示.
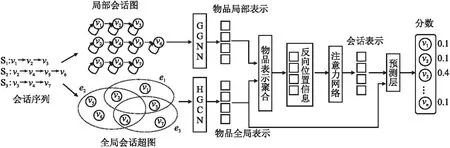
圖1 GIMGNN模型結構框架Fig.1 Model framework of GIMGNN
該模型主要模塊構成如下:
1)構圖模塊:根據當前會話序列構建局部會話圖,以及根據歷史會話序列構建全局會話超圖.
2)局部表示學習模塊:將構建的局部會話圖通過門控圖神經網絡(GGNN)生成物品局部會話特征表示.
3)全局表示學習模塊:將構建的全局會話超圖通過超圖卷積神經網絡(HGCN)生成物品全局會話特征表示.
4)聚合模塊:通過注意力機制將反向位置嵌入融合到物品局部會話特征表示和物品全局會話特征表示中得到會話表示.
5)預測模塊:根據聚合模塊得到的會話表示和物品全局會話特征表示線性組合得到最終表示預測下一個交互物品.
1.2 問題描述
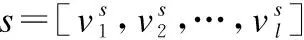

(1)
通過公式(1)最小化損失函數L(·).其中|St|是訓練集的大小,mi是序列si的長度.
1.3 構圖模塊
本節定義了兩個圖模型,局部會話圖和全局會話超圖,以表示當前序列中不同級別之間的物品傳遞信息.局部會話序列表示當前會話序列中成對物品-物品關系的傳遞信息,全局會話序列表示所有會話序列中物品-物品關系的復雜高階信息.
圖2中顯示了單個會話s={v1,v2,v3,v2,v4}的局部會話圖.在圖中每個節點都與自身有連接,因此可以在建模中融合自身的信息.局部會話圖由有向圖表示,可以很好地表示會話序列中物品之間的順序相關性.對于本文構造的局部圖的每一個節點,都可能有4種類型的邊與其相連,分別表示為rin,rout,rin-out和rself.rin表示其它節點傳遞信息到該節點.rout表示該節點將信息傳輸到其它節點.rin-out表示該節點和節點之間存在雙向傳輸信息,rself表示該節點自身的傳遞信息.
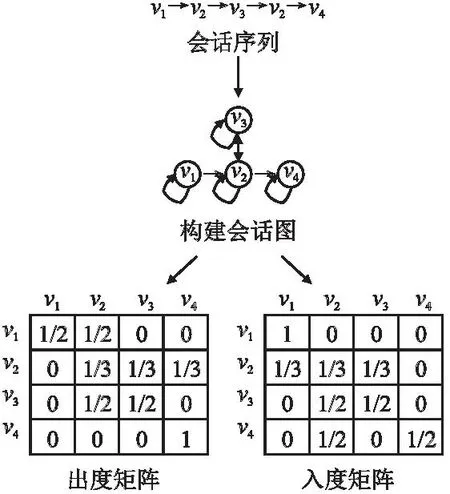
圖2 局部會話圖Fig.2 Local session graph
全局會話超圖用于表示物品的全局信息.全局會話超圖是一個連接任意多個頂點的超邊組成的無向超圖.超圖G可以表示為三元組G=(V,E,W),V,E和W分別是節點集,超邊和超邊的權重.V表示系統中的所有物品,每個v∈V代表一個物品.E表示所有歷史會話序列,每個e∈E表示會話序列.每個w(e)∈W是超邊e的權重.在代數中,W可以定義為對角矩陣W∈|E|×|E|,超圖可以用關聯矩陣H∈|V|×|E|表示,其條目h(v,e)定義為:
(2)
根據超圖的定義,可以計算超邊的度矩陣D=∑e∈Ew(e)h(v,e)和所有頂點的度矩陣為B=∑v∈Vh(v,e),其中D和B都是對角矩陣.
在超圖中,如果任意兩個超邊具有公共頂點,則它們是連通的.并且超邊內的所有頂點都是完全連接的,因此超圖包含物品之間的高階未配對關系,可用于物品全局級物品的特征表示.圖3中顯示了3個會話序列形成的超圖,虛線中的3個圓是超邊,由它們之間的公共頂點v2,v3和v4連接,并計算其對應的關聯矩陣.
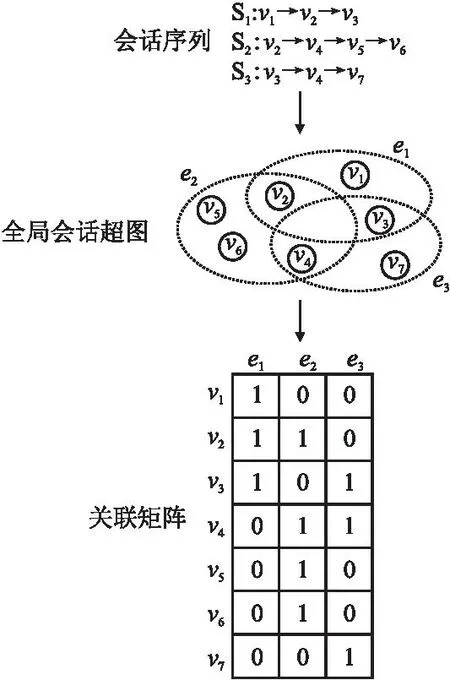
圖3 全局會話超圖Fig.3 Global session hypergraph
1.4 局部表示學習模塊
門控圖神經網絡(GGNN)用于獲取局部會話序列中成對物品-物品關系的傳遞信息.在局部會話圖中,節點向量表示的更新函數如下:
(3)
(4)
(5)
(6)
(7)
其中H∈d×2d,Wz,Wr,Wc∈2d×d,Gz,Gr,Gc∈d×d表示權重矩陣,和分別表示更新門和重置門,為會話s中的節點序列,σ(·)表示激活函數,⊙表示對應元素相乘.表示局部會話圖的出度矩陣,表示局部會話圖的入度矩陣.公式(3)用于不同節點之間的信息傳播,在鄰接矩陣的作用下提取鄰域的潛在向量,并將其作為輸入到圖神經網絡中.公式(4)和公式(5)通過更新門和重置門分別決定要保留和丟棄的信息.公式(6)根據前一狀態、當前狀態和重置門構造候選狀態.公式(7)表示在更新門的控制下,由前一個隱藏狀態和候選狀態得到最終狀態.通過對會話圖中的所有節點進行更新,達到收斂之后,便可以得到最終的節點向量.之后使用注意力機制計算不同鄰居節點對當前節點的影響,影響程度由注意力機制計算的權重表示.給定一個節點vi,可以通過元素乘積和非線性變換計算節點vj對其的影響權重:
(8)
eij表示節點vj對于節點vi的重要性,LeakyReLU(·)表示激活函數,rij表示節點vi和vj的關系,a*∈d是權重矩陣.通過權重矩陣來表示圖中所有節點對于節點vi的影響.為了使不同節點之間的權重具有可比性,使用softmax函數對其進行歸一化:
(9)
公式(9)注意力系數αij是不對稱的,因為節點的鄰居是不同的,意味著對每個節點的貢獻是不平等的.接下來,通過線性組合計算節點vi的特征表示:
(10)
通過上述計算,可以將其他節點對當前節點的影響信息和當前節點本身的信息融合在一起,以表達當前節點的局部特征表示.并且通過注意力機制,降低了噪聲對局部會話級別物品特征學習的影響.
1.5 全局表示學習模塊
超圖卷積神經網絡(HGCN)用于獲取所有會話序列中物品之間的高階關系.在超圖上定義卷積運算的主要挑戰是如何傳播相鄰節點的信息.參考Feng等人[28]提出的譜圖卷積,在本文的模型中,HGCN的定義如下:
(11)
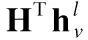
(12)
1.6 聚合模塊
對于每個物品,本文通過合并其局部表示和全局表示獲得物品的最終表示:
(13)
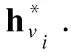
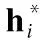
(14)
其中參數W1∈d×2d和b∈d是一組可訓練的參數,‖表示串聯操作.由于會話序列的長度不固定,所以選擇反向位置嵌入.相對于前向位置信息,預測物品和當前物品之間的距離包含更有效的信息.因此,反向位置信息可以更準確地表示每個物品的重要性.
會話的表示與學習到的物品信息密切相關.為了獲得會話的表示,本文平均了會話序列中涉及的物品信息:
(15)
基于位置嵌入信息zi和會話表示s*,本文采用軟注意機制來計算權重:
βi=qTσ(W2zi+W3s*+c)
(16)
其中,W2,W3∈d×d和q,c∈d都是可學習的參數.因此,通過線性組合操作獲得會話的最終表示:
(17)
前面的計算過程表明,會話表示S表示不僅融合了全局和局部級別上下文信息,而且還包含了所有物品的位置和順序信息,因此會話表示S可以很好地表示會話特征.
1.7 預測模塊
(18)
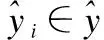
(19)
其中,yi表示為one-hot向量.
2 實驗與分析
在本節中,首先介紹實驗的數據集和預處理、評估指標、基準方法和實驗參數設置,然后設計了一些列對比實驗,以回答下列4個問題:
問題1.與現有的會話推薦基準方法相比,GIMGNN表現如何?
問題2.融合全局信息是否增強了會話推薦效果?GIMGNN模型中每個模塊的性能如何?
問題3.反向位置嵌入對GIMGNN的性能影響如何?
問題4.不同超參數(dropout)的設置對GIMGNN的性能影響如何?
2.1 數據集和預處理
本文實驗將基于兩個著名的基準數據集Yoochoose和Diginetica進行.其中Yoochoose數據集來自于2015年RecSys挑戰賽,通過http://2015.recsyschallenge.com/challege.html獲取,數據集包括一個網站的點擊歷史記錄.Diginetica數據集通過https://competitions.codalab.orgcompetitions11161獲取,來自2016年CIKM杯,數據集由典型交易數據組成.
對于兩個數據集的預處理工作參考了文獻[23],首先過濾掉長度為1的會話和兩個數據集中出現次數少于5次的物品,然后將上周的會話(最新數據)設置為測試數據集,剩余的歷史數據用于訓練集.由于Yoochoose數據集非常大,本文對Yoochoose數據集進行了額外的處理.此外,已有研究證明使用接近測試集的訓練集進行模型訓練可以提高推薦性能.因此,實驗中僅使用Yoochoose1/64作為數據集.表1列出了數據預處理后兩個數據集的統計信息.
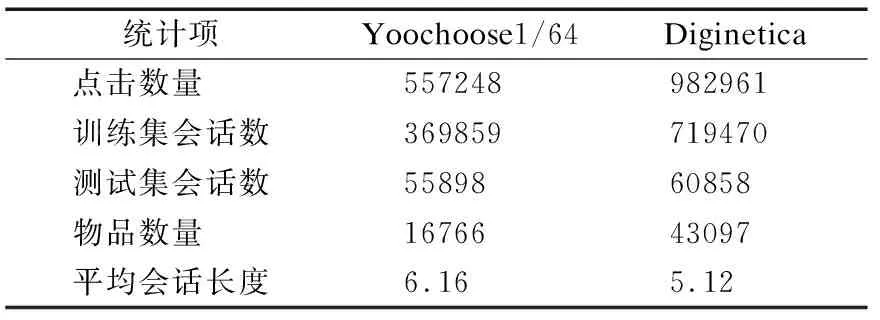
表1 預處理數據統計Table 1 Preprocessed data statistics
2.2 評價指標
為了便于與基線模型進行比較,本文選擇了常用的精度(P)和平均倒數排名(MRR)作為評估指標.在實際推薦中,系統通常同時推薦多個物品.為了評估不同物品數量的推薦效果,使用P@K和MRR@K以測量模型的性能,其中K表示推薦物品的數量.
P@K被計算為推薦排名列表中測試用例前K位的正確項目,并定義為:
(20)
其中N是測試集中的序列數,nhit是在排名列表中前K個物品中正確推薦的物品數.
MRR@K是對正確推薦的物品vt出現在包含K個物品的推薦列表I中的位置進行評分,其具體值等于vt在I中的排名倒數.如果vt位于I的第1位時MRR@K為1,當vt未出現在I中時MRR@K為0.假設測試集的大小為N,取平均值MRR@K作為評估的度量:
(21)
其中rank(vt)是vt在推薦列表中的排名.
2.3 對比模型
為了驗證GIMGNN模型的性能,實驗用以下9種推薦模型作為對比模型:
1)POP:推薦訓練數據集中頻率最高的前N項.
2)Item-KNN:通過余弦距離來衡量兩個物品之間的相似度,并根據相似度推薦物品.
3)FPMC[6]:同時考慮了矩陣分解和一階馬爾可夫鏈,是一種混合方法,但在計算推薦分數時,忽略了用戶的潛在表示.
4)GRU4REC[12]:通過門控神經網絡(GRU)將會話序列建模為最終會話表示,并使用排名損失來訓練模型.
5)NARM[15]:基于GRU4Rec的模型,該模型擴展了注意力層,并結合了RNN的編碼狀態,使模型能夠密切關注會話序列的重要特征.
6)STAMP[16]:將先前工作中的RNN編碼器替換為多重注意力,并且將當前會話中最后一項的自我注意力作為用戶的短期興趣.
7)CSRM[17]:假設歷史會話中包含與目標會話相似的用戶偏好,并將這種協作信息應用于推薦任務.
8)SR-GNN[23]:使用GRU獲得物品的嵌入表示,與STAMP類似,它通過關注最后一個物品來計算會話的特征表示.
9)GC-SAN[24]:使用自注意力網絡來學習會話中物品之間的全局和局部依賴信息.
2.4 參數設置
在本文的實驗中,將隱向量維度大小設置為100,批處理大小設置為100.所有可學習參數均使用高斯分布初始化,平均值為0,標準偏差為0.1.學習率設置為0.001,并由Adam優化器優化.本文在兩個數據集上將epoch設置為20.對于GIMGNN的層數設置,不同的數據集對應不同的層數.通過實驗發現,對于數據集Yoochoose1/64和Diginetica,當層數設置為3時,該模型的性能最佳.對于基線,如果原始論文的實驗評估機制和數據集與本文相同,本文將采用最佳實驗結果進行比較.此外,為了公平起見,還將參數設置為模型性能最佳時的參數.
2.5 結果分析(問題1)
通過表2的實驗結果可以看出,與基線模型相比,本文提出的GIMGNN模型在兩個數據集的指標上都優于基線模型.
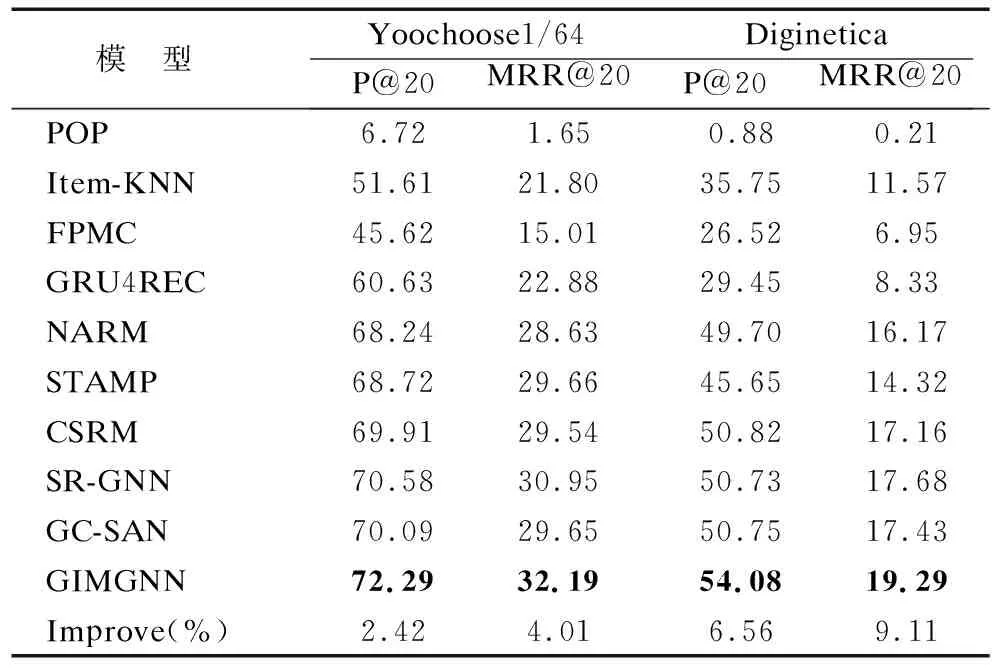
表2 不同模型在兩個數據集上性實驗結果%Table 2 Experimental results of different models on two datasets%
傳統的POP模型實驗結果最差,因為只考慮了訓練數據集中頻率最高的前N項,而沒有考慮其它交互信息.FPMC方法通過結合矩陣分解和一階馬爾可夫鏈來捕獲用戶偏好,表現出比POP更好的性能,證明了用戶偏好在推薦中的重要性.在傳統方法中,Item-KNN模型在Yoochoose1/64和Diginetica 數據集上顯示了最佳結果.該模型根據當前會話和其他會話之間的相似性推薦物品,證明了會話之間存在一定的依賴性.然而,由于傳統推薦模型無法捕捉同一會話中物品之間的順序關系或順序相關性,所以推薦的準確性明顯受到影響.
從表2中不難發現,基于深度學習的模型優于傳統的推薦系統方法.在性能方面,GRU4REC首先使用RNN對會話序列進行建模獲取特征表示,其性能仍然低于NARM和STAMP模型.因為GRU4REC只考慮順序關系,而不考慮序列中的其余信息,因此很難獲得用戶偏好的變化.這意味著,雖然RNN非常適合序列建模,但很難解決基于會話推薦中的用戶意圖可能發生變化的問題.通過考慮會話中不同物品的重要性,NARM和STAMP使用注意機制更準確地表達用戶的意圖,在一定程度上提高了推薦效果,性能優于GRU4REC.通過比較RNN和注意機制相結合的NARM與完全使用注意機制的STAMP的性能,本文發現STAMP的性能明顯優于NARM.前一種方法通過迭代多個注意層來替換先前工作中的RNN編碼器,并將當前會話中的最后一項視為用戶的短期偏好,進一步證明了使用RNN學習用戶的表示可能會導致用戶意圖的偏離.與NARM和STAMP相比,CSRM方法在Diginetica數據集上表現出更好的性能.它使用內存網絡來研究最近的m個會話,以便更好地預測用戶在當前會話中的意圖.正如CSRM的性能所示,為了更好地進行會話推薦,需要考慮其他會話對當前會話的影響.
通過SR-GNN與GC-SAN實驗結果可知,基于GNN會話模型的推薦效果明顯好于傳統推薦方法與深度學習方法.因為將會話序列建模為會話圖以及使用GNN可以更好的捕獲物品之間的成對傳遞關系,表明了在做出推薦時考慮物品之間的獨立的重要性.與RNN相比,GNN可以捕獲會話序列中物品之間更復雜的依賴信息.兩種基于GNN的方法將會話序列建模為簡單的圖,不能夠充分捕捉物品的成對傳遞,也無法學習物品之間的復雜高階關系,這在一定程度上影響了推薦效果.
與基線模型不同,本文提出的GIMGNN模型將歷史會話序列建模為超圖,并使用超圖神經網絡(HGCN)學習物品之間的復雜高階關系.模型同時考慮了局部和全局會話級別的上下文信息,因此可以有效地表示當前會話序列中物品的特征,這也是GIMGNN具有優異性能的原因.
2.6 全局特征對性能的影響(問題2)
在兩個數據集上進行實驗,以評估全局級特征編碼器和會話級特征編碼器的有效性.本文設計了兩種對比模型:
1)GIMGNN-NL:刪除局部表示學習模塊(GGNN),只留下全局表示學習模塊(HGCN)來捕獲全局會話級別的上下文信息.
2)GIMGNN-NG:刪除全局表示學習模塊(HGCN),只留下局部表示學習模塊(GGNN)來捕獲局部會話級別的上下文信息.
表3在Yoochoose1/64和Diginetica兩個數據集上比較了3個模型的推薦結果,并分別給出了評估指標P@20和MRR@20.從表中可知,本文提出的GIMGNN方法在推薦性能方面顯示出最佳結果.在Diginetica數據集上,GIMGNN-NL的性能優于GIMGNN-NG,表明使用超圖神經網絡(HGCN)捕捉高階信息的有效性.在Yoochoose1/64數據集上,GIMGNN-NG的性能優于GIMGNN-NL,可能是因為Yoochoose1/64數據集中的會話平均長度比Diginetica數據集中的會話平均長度長,有助于門控圖神經網絡(GGNN)有效學習會話中物品之間的依賴關系.實驗結果表明,通過考慮物品之間復雜高階信息,可以有效提高會話推薦的性能.
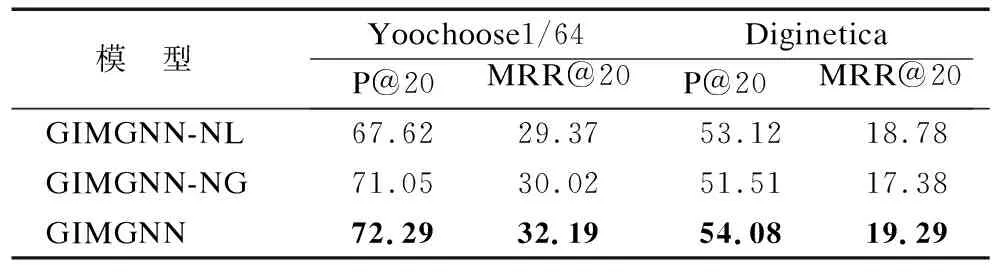
表3 對比模型在兩個數據集上性實驗結果%Table 3 Experimental results of contrast models on two datasets%
2.7 位置向量對性能的影響(問題3)
為了驗證位置向量對性能影響,并評估在GIMGNN中提出的反向位置向量的有效性,本節設計了一系列對比模型:
1)GIMGNN-NP:使用前向位置向量替換反向位置向量的GIMGNN模型.
2)GIMGNN-SA:使用自注意機制取代位置感知注意力的GIMGNN模型.
表4顯示了不同對比度模型的性能.從表中可以看出GIMGNN-NP在兩個數據集上表現不佳,因為模型無法捕捉其它物品與預測物品之間的距離.GIMGNN-SA在Diginetica數據集上的表現優于GIMGNN-NP,表明會話中的最后一項包含最相關的推薦信息.然而,它在Yoochoose1/64數據集上表現不佳,因為它缺乏對每個物品貢獻的更全面的判斷.與這兩種變體相比,反向位置嵌入證明了模型的有效性,也驗證了反向位置信息可以更準確地表明每個物品的重要性.此外,通過注意力機制,有效過濾了當前會話中的噪聲,使得模型的性能更好.
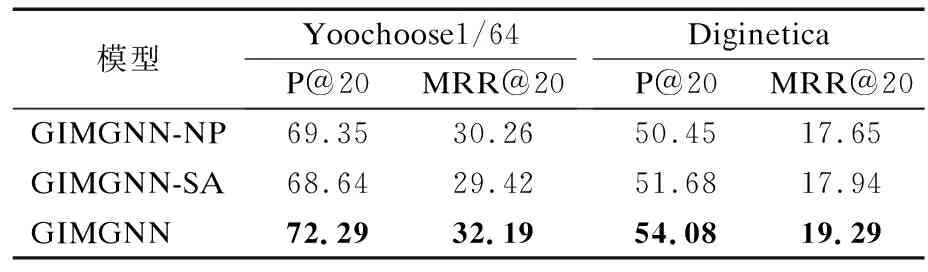
表4 對比模型在兩個數據集上性實驗結果%Table 4 Experimental results of contrast models on two datasets%
2.8 超參數對性能的影響(問題4)
Dropout作用是防止模型過擬合,原理是在訓練期間隨機丟棄具有給定可能性的神經元,但將所有神經元用于測試.在實驗中,神經元脫落的可能性在0.0~0.9范圍內變化,間隔為0.1,評估指標為P@20.圖4顯示了GIMGNN在兩個數據集不同dropout下的實驗性能,說明了模型在兩個數據集上的性能在開始時隨著dropout的增加而增加,當dropout增長到一定值時,模型性能開始下降.也就是說,模型的性能在曲線的拐點處最好.特別是在Yoochoose1/64和Diginetica數據集中,本文的GIMGNN模型在dropout分別為0.6和0.5時表現最佳.因此,本文在兩個數據集上的實驗中將dropout設置為相應的值.
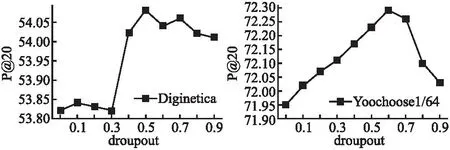
圖4 不同dropout對推薦性能的影響Fig.4 Impact of different dropout on recommended performance
3 結束語
基于圖神經網絡的會話推薦模型是當前學術研究的熱點,物品的高階交互信息可以提高基于圖神經網絡的會話模型的推薦效果.為了充分考慮物品的局部和全局會話上下文信息,本文的工作首先將當前會話序列轉換為局部會話圖,其次將所有會話序列轉換為全局會話超圖,然后使用超圖卷積神經網絡(HGCN)和門控圖神經網絡(GGNN)捕捉物品的全局會話特征表示和局部會話特征表示.并且,通過使用注意力機制處理融合特征來學習會話序列的最終表示.大量實驗結果表明,本文提出的GIMGNN模型始終優于最先進的方法.然而,使用超圖卷積神經網絡(HGCN)捕獲全局信息也有一個缺點,可能會將不相關的信息融合到當前會話中.因此,在未來的工作中,將研究如何構建基于超圖的模型,以緩解無關信息對會話推薦結果的影響.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中華手工(2017年2期)2017-06-06 23:00:31
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年5期)2015-02-27 07:53:25
中外會展(2014年4期)2014-11-27 07:46:46
