面向語義增強與雙尺度功能注意力網絡的Web服務分類方法
2024-04-22 02:30:38綦浩泉渠連恩
小型微型計算機系統 2024年4期
綦浩泉,孫 羽,渠連恩,胡 強
(青島科技大學 信息科學技術學院,山東 青島 266061)
0 引 言
Web服務是當前網絡中主流的服務組織形式.它是一種采用標準化協議和接口封裝的具有特定業務功能的Web應用程序模塊,具有跨平臺、跨語言,易于調用和集成等特點,廣泛地應用于各類面向服務架構的軟件開發與部署[1].
網絡中發布了大量功能豐富的Web服務.例如,在ProgrammableWeb中已經注冊超過26000個Web服務和近8000個Mashup服務,涵蓋超過500個應用類型[2].數量眾多的Web服務為用戶提供了豐富的選擇機會,同時也增大了服務發現難度[3].
按類別實現Web服務注冊與組織,可有效地縮減服務查找空間,提升服務發現效率.合理的類別劃分,可以幫助用戶快速定位和篩選所需的Web服務.Web服務的類別推薦已經成為研究熱點[4].服務描述的功能語義特征是實現類別判定的主要依據[5].然而,服務描述多為非結構化短文本,且描述文本中重復詞語比例低,造成常用主題模型或神經網絡生成的服務功能向量語義特征稀疏、區分度不高,進而影響了分類質量.
通過分析Web服務描述文本的語義結構可知:占比較低的動詞通常表示服務所能執行的關鍵業務操作或步驟,因此,如果增強服務描述中動詞在功能向量中所對應的語義特征的密度,將更有利于構建高質量的服務功能向量.
近年來,服務協作在分類中的作用逐漸引起關注[6].研究者依據服務共同參與的業務場景或組合,構建服務協作網絡,利用圖神經網絡實現服務結點向量化,并將協作相似度融入到服務分類,提高了分類質量[7].然而,現實中具有協作關聯的Web服務數量非常少.據統計,在ProgrammableWeb中存在協作關聯的Web服務共1018個,約占服務總量的3.8%.因此,Web服務中存在協作的服務數量較少,服務協作關聯對分類質量的提升效果有限[8].
Web服務通常包含若干個標簽.標簽是服務功能與應用場景的標識.服務擁有相同標簽的數量越多,功能相似度越高,隸屬于同一類別的可能性越大[9].本文將擁有相同標簽的Web服務定性為具有功能關聯.相比協作關聯,服務之間的功能關聯數量非常巨大.在ProgrammableWeb平臺中,存在功能關聯的Web服務約占總量98.4%.因此,若將功能關聯融入到服務分類中,將能夠有效地提升分類的質量.
為此,本文提出一種基于語義增強與雙尺度功能注意力網絡的Web服務分類方法,主要工作與貢獻如下:
1)提出一種語義增強的服務功能向量生成方法.采取近義詞替換的方式構建服務描述的孿生樣本,強化表示服務業務操作的動詞語義特征信息,在SimCSE框架下生成高質量的服務功能向量.
2)構建服務功能關聯圖,設計了一種雙尺度功能注意力網絡.為服務功能關聯圖生成深度與廣度兩種尺度的結點游走序列,引入結點-序列的二階注意力機制,優化生成具有兩種尺度的特征信息的功能關聯向量.
3)將服務功能向量與功能關聯向量輸入softmax分類器中實現Web服務分類.實驗表明本文方法的分類質量優于當前流行分類方法.
1 相關工作
Web服務分類能夠提高服務發現效率,常用方法可以劃分為基于功能語義的服務分類與基于服務關聯的Web服務分類.
在基于功能語義的Web服務分類工作中,研究者多采用主題模型或神經網絡模型解析服務描述,生成功能向量用于分類任務.例如,Shi等將Word2Vec與LDA結合,設計了一種高質量的詞向量生成模型用于擴充服務的表征語義,提高服務類別區分度[10].Baskara等將Web服務結構建模為加權有向無環圖(WDAG),然后使用BTM主題模型在WDAG中挖掘主題特征,并通過計算主題相似度進行服務發現[11].
Ye等通過Wide&Bi-LSTM模型,挖掘Web服務描述中的詞上下文信息提取出高質量的服務功能向量,實現Web服務類別的預測[3].Cao等提出通過注意力機制將Bi-LSTM與LDA主題模型結合,可以根據主題特征優化功能向量的上下文表示,提出一種基于主題注意力機制Bi-LSTM的Web服務分類方法[12].類似的,Chen等先利用LSA模型對移動應用服務描述文本進行全局主題建模,再通過BiLSTM對內容文本進行局部隱藏表征挖掘,結合主題模型與時序神經網絡獲取優化的文本特征,構建一種基于主題注意力機制增強的移動應用分類方法[13].Tang等構建帶有共同注意表征學習機制的CARL-Net進行服務特征提取,并應用到服務分類,分類效果相對CNN、LSTM、RCNN、C-LSTM等神經網絡模型有一定提升[14].Agarwal等構建了Sentence-BERT模型,并應用到服務空間的表示中,在語義分析層面對服務描述上下文生成表征向量,相比Word2vec模型大幅度提升了分類精度[15].
近年來,服務之間的協作關聯受到研究者越來越多的關注.例如,Hu等利用改進GSDMM模型生成服務表征向量,并通過構建服務協作圖來建模協作關系,計算服務協作相似度實現服務類別劃分[6].石敏等提出考慮服務協作關系的概率主題模型MR-LDA,對服務的相互組合關系進行建模[5].肖勇等針對Web服務之間的結構關系和自身屬性信息分別構建出多個相對應的結構關系圖和屬性二分圖.采用隨機游走算法生成Web服務的結構上下文和屬性上下文.利用skipgram模型對聯合上下文進行訓練,得到融合多維信息的表征向量,采用SVM模型實現Web服務的高精度分類預測[16].
Pan等提出TriDNR模型,根據結點間標簽重合關系最大化給定類別標簽的單詞序列概率對標簽關聯進行建模,結合服務描述內容實現圖結點嵌入表示,進行服務分類[17].Huang等提出了一種基于標簽的屬性網絡嵌入框架,將標簽信息合并到屬性網絡嵌入中,同時保持結點之間的相關性,在服務分類中取得一定效果[18].
綜上可知,采用先進的功能向量生成模型,結合服務關聯并引入注意力機制,能有效提升分類質量.但是,已有研究在服務功能向量的生成層面,缺乏對表示服務所能執行的關鍵業務操作或步驟的動詞特征的重點提取;在服務功能關聯融入層面,僅關注同類服務的特征聚合,忽視與非同類服務的特征區分;在結合注意力機制聚合服務的圖結點嵌入向量時,未能融入結點在不同序列中的上下文結構信息.為此,本文從孿生服務描述構建以及結合二階注意力機制的雙尺度功能關聯融入兩個角度研究Web服務分類.
2 研究框架
采取如圖1所示的研究框架.首先,從服務注冊平臺爬取Web服務.對獲得的服務進行數據清洗,構建適用于服務分類的數據集.
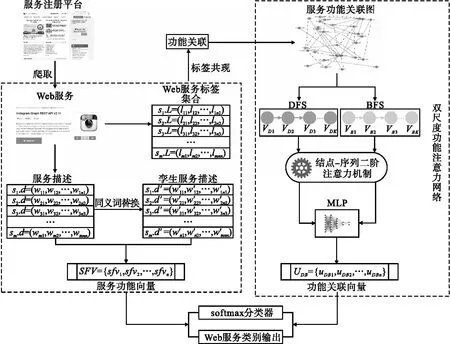
圖1 研究框架總覽Fig.1 Overview of research framework
其次,構建面向語義增強與對比學習的服務功能向量生成方法.將服務s描述文本d中的動詞進行同義詞替換,為每個服務生成孿生服務描述文本d′.然后,采取SimCSE框架,基于對比學習的方式分別為d和d′生成功能向量,將二者的功能向量的均值作為服務s的最終功能向量.
然后,根據服務標簽的共現關系,構建服務功能關聯圖.通過Node2vec對圖進行BFS(廣度優先遍歷)與DFS(深度優先遍歷)游走,生成包含結點特征相似度(BFS游走)與迥異度(DFS游走)的兩種不同尺度的訓練語料.引入結點-序列二階注意力機制,為服務結點分階聚合當前序列中鄰域結點的功能特征以及不同尺度序列的上下文結構特征,優化服務在各尺度語料中的嵌入向量.將兩類尺度語料中得到的嵌入向量進行訓練融合,得到功能關聯向量.
最后,將服務功能向量與功能關聯向量輸入softmax分類器實現分類預測,驗證方法的先進性.
3 基于語義增強的服務功能向量生成
圖2是一個Web服務示例,下面給出其定義.

圖2 Web服務示例Fig.2 Example of Web service
定義1.Web服務.
Web服務定義為一個三元組,s=(n,L,d),其中,n為服務的名稱,L為服務標簽集合,d為服務描述信息.
以BERT為代表的預訓練神經網絡模型常用于Web服務功能向量的生成.然而,BERT的向量空間存在各向異性,一定程度上影響了功能向量的質量.Gao等提出的SimCSE可以有效緩解BERT生成向量空間的各向異性[19].SimCSE是一個采用對比學習進行句子嵌入表示的學習框架,適用于生成Web服務的功能向量.
除了采用高質量的文本向量生成框架SimCSE,語義增強也被應用到本文的服務功能向量生成.通過對服務描述文本的詞性分析得知,占比較低的動詞通常用于表示服務所能執行的業務操作,因此,如果增強服務描述中動詞在功能向量中所對應的功能特征的密度,將更有利于構建高質量的服務功能向量.
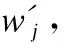
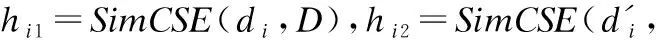
(1)
4 面向雙尺度功能注意力網絡的功能關聯向量生成
本節依據標簽共現關系構建服務功能關聯圖,并設計一種雙尺度功能注意力網絡DSFAN(Dual scale functional attention network),為Web服務生成功能關聯向量.
定義2.功能關聯.
若存在標簽l,使得l∈si.L∪sj.L,則稱服務si與服務sj存在功能關聯,記作:si~sj.
定義3.服務功能關聯圖.
服務功能關聯圖為一個無向加權圖SFCG=(V,E,W),其中:
1)V={v1,v2,…,vn}為服務結點集合,結點vi表示Web服務si;
2)E={e1,e2,…,em}為功能關聯邊集合,e=(vi,vj)結點vi與vj所對應的服務si和sj滿足si~sj.
3)W={wij}為邊的權值集合,權值為服務si與sj共同標簽的數量.
Node2vec是一種圖結點嵌入向量生成模型,通過參數設置,可以對圖進行BFS或者DFS游走采樣[20].在SFCG中,采用BFS和DFS兩種方式進行序列采樣,BFS遍歷優先將功能相似度高的結點納入結點序列,此類結點關聯特征有助于將相似的服務結點分為一類.DFS遍歷優先將功能迥異度高的結點納入結點序列,此類結點關聯特征有助于將相似度低的服務結點劃分不同的類別.因此,本文從結點特征的相似度與迥異度兩個尺度進行序列特征的提取.對于結點vi,分別為其生成其深度游走序列集合DFS(vi)與廣度游走序列集合BFS(vi).
在服務結點的圖嵌入向量生成過程中,已有研究多通過結點級注意力,聚合服務結點在采樣序列中鄰域結點功能的特征,忽視了Web服務結點在不同序列的上下文中結構特征聚合.對于Web服務分類而言,上下文結構特征反映了相互之間未直接相連、但存在相似功能特征的服務關聯的緊密程度,挖掘此類信息有助于提高服務分類的精確度.為此,本文提出序列級注意力,構建結點和序列二階注意力機制,提升分類精確度.圖3給出了雙尺度功能注意力網絡示意圖.
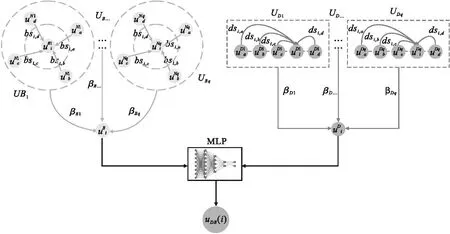
圖3 雙尺度功能注意力網絡圖Fig.3 Dual scale functional attention network
首先,通過結點級注意力層,優化vi在每個序列中的向量.對于DFS(vi)中的序列φ中的結點vj,計算vj對vi的注意力權重:
(2)
(3)
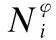
(4)
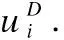
(5)
(6)
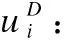
(7)
公式(7)中,UDq為序列向量,是序列內所有服務經結點級注意力優化后的向量均值.
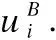
最后,設置一個MLP層,同時學習vi在兩種尺度的特征,得到vi的圖結點嵌入輸出,即功能關聯向量uDB(i):
(8)
其中,Wds1、Wds2與bds為可訓練參數,σ為Relu激活函數.
5 融合語義增強與雙尺度功能關聯的Web服務分類方法
利用前面章節中的方法,分別生成服務功能向量集合SFV和功能關聯向量集合UDB后,將它們輸入softmax分類器實現每個服務的類別概率輸出:
PV=softmax(Wpv1SFV+Wpv2UDB+bpv)
(9)
其中,Wpv1、Wpv2∈RK×(K×da)為可訓練權重矩陣,bpv∈RK為偏置向量,K為服務類別總數,da為功能向量與功能關聯向量嵌入維度.
使用交叉熵損失函數對方法中所有參數進行訓練,并使用反向傳播算法優化損失函數:
(10)
其中,p為概率預測分布,y為真實類別的獨熱編碼表示,N為Web服務總數,yi,k表示第i個服務屬于第k個類別的真實標簽(若是第k個類別則為1,否則為0),pi,k為第i個服務屬于第k個類別的預測概率.將本文所提Web服務分類方法命名為SDNC,算法1給出方法的具體實施步驟.
算法1.SDNC算法
輸入:Web服務集合S
輸出:服務類別概率分布集合PV
1.SFV=UDB=PV=?
2.for each services∈S
3.sfv(s)=SE-SimCSE(s)
4.SFV=SFV∪sfv(s)
5. end for
6. SFCG←v:s∈S
7. for ?si,sj∈S
8. ifsi~sjthen
9. SFCG=SFCG.E∪(vi,vj)
10.wij=wij+1;
11. end if
12. end for
13.UDB=DSFAN(S,SFCG,SFV)
14. for eachsinS
15.pv(s)=softmax-classifier(sfv(s),uDB(s));
16.PV=PV∪pv(s);
17. end for
18.returnPV
算法第1行初始化3個空集合SFV、Uds和PV,分別用于存儲服務功能向量、功能關聯向量和服務類別概率分布;第3~5行使用文中提出的SE-SimCSE方法為服務集合S中的每個服務s生成功能向量sfv(s),并將sfv(s)加入到集合SFV中.
算法第6~12行用于構建服務功能關聯圖SFCG.第6行首先初始化圖SFCG,將服務集合S中服務s映射為SFCG中的結點v.第7~12行實現功能關聯邊的建立.如果服務集合S中的兩個服務si與sj存在功能關聯,則在對應結點vi與vj之間增加一條邊,邊權增加1.
在構建的功能關聯圖SFCG的基礎上,算法第13行以功能向量作為雙尺度功能注意力網絡的初始化結點嵌入向量,為服務集合S中的服務生成功能關聯向量集合UDB.算法第14~18行將服務功能向量與功能關聯向量輸入softmax分類器,得到每個服務s的類別概率分布pv(s),最高概率所對應的類別即為服務推薦類別.最后,算法返回概率分布集合PV.
6 實驗驗證
本節開展實驗驗證以下Web服務分類過程中涉及到的以下4個問題:
1) SE-SimCSE生成的服務功能向量質量是否優于其他流行的模型?
2) DSFAN的引入能否提升Web服務分類的質量?
3) SDNC方法是否優于最新的服務分類方法?
4) 實驗關鍵超參數(游走的步長與次數)的選擇?
6.1 實驗設置
6.1.1 數據集概述、數據預處理方式和實驗環境
實驗中的Web服務爬取自ProgrammableWeb服務注冊平臺.刪除服務描述過短、重復注冊或所屬類別中服務數目過少的部分數據后,最終保留19241個Web服務,從屬384個類別.如表1所示,按照已有研究文獻中常用實驗類別選取方式[12 ,16,18],選取數量最多的前10~50類服務進行實驗,表2給出Top 20類別的示例.采用五折交叉驗證法,進行10個輪次,取平均值作為實驗結果.
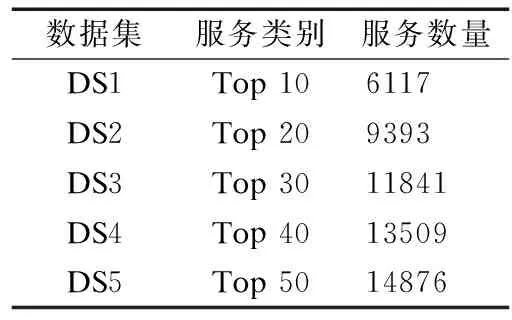
表1 數據集概述Table 1 Dataset overview
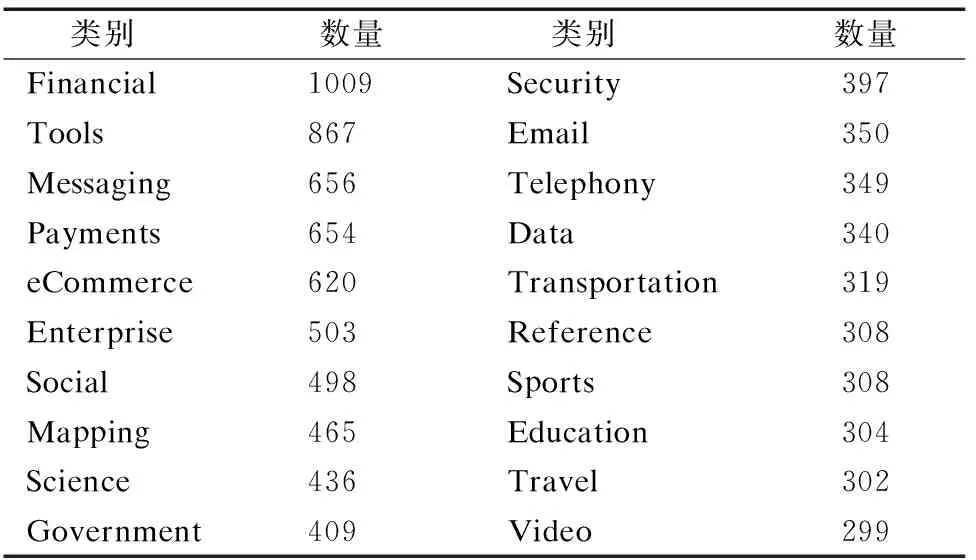
表2 Web服務類別Top 20示例Table 2 Examples of Web service category Top 20
實驗環境如下:CPU為RYZEN9-5900HS,內存16G,GPU為RTX3060(1張),顯存6GB.操作系統為Windows 11,編程語言為Python 3.8.采用常用評價指標準確率(后續稱為Accuracy)與F1-score(后續稱為F1)評估Web服務分類質量[14,17].
實驗過程如下:首先,對數據進行規范化,將實驗數據中的所有服務的描述文本分別進行大小寫轉化、分詞、去停用詞、詞干還原等處理.
然后,利用流行的主題模型、神經網絡模型以及本文所提出的SE-SimCSE為規范化后的服務描述文本生成服務功能向量,通過對比不同模型生成的服務功能向量對應的服務分類質量,驗證問題1.
其次,在SE-SimCSE生成服務功能向量的基礎上,探討引入DSFAN后服務分類質量的提升情況,以驗證問題2,同時,在調優DSFAN最佳性能時進行關鍵超參數的選擇,以回答問題4.最后,選取最新的服務分類方法,與本文所提出的分類方法SDNC進行對比,已驗證SDNC方法的先進性.
6.2 實驗結果與分析
6.2.1 服務功能向量生成模型的分類特征提取性能對比
本節對比文中提出的SE-SimCSE與當前流行的服務功能向量生成模型的性能優劣.選取LDA[21]、GSDMM[22]、RoBERTa[23]和SimCSE[19]模型,其中LDA和GSDMM為主題模型,RoBERTa和SimCSE為神經網絡模型.采用不同模型分別為DS1~DS5數據集中的服務描述生成的服務功能向量用于Web服務分類,各指標數據見表3.
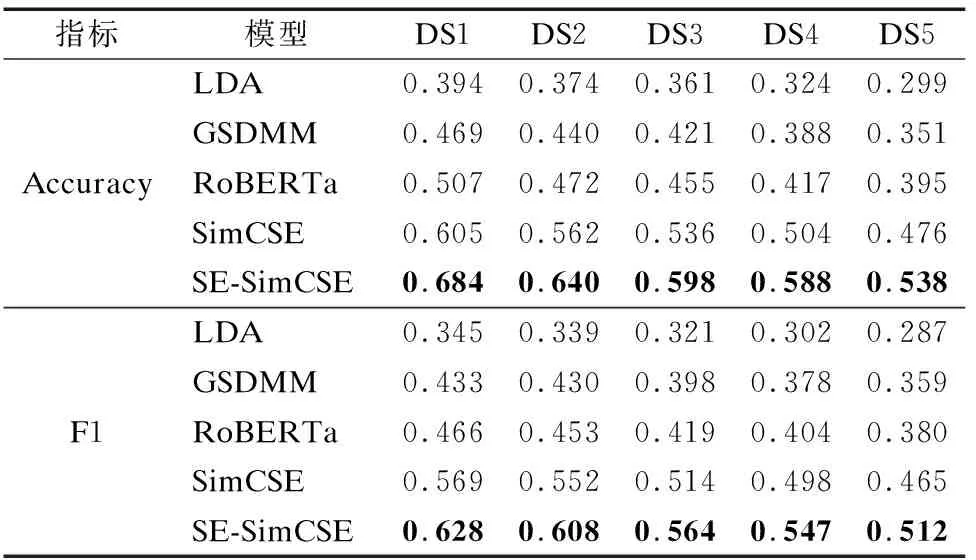
表3 服務功能向量生成模型性能對比Table 3 Performance comparison of service functionvector generation models
在表3中,LDA模型生成的服務功能向量對應的服務分類質量最差.GSDMM生成的功能向量的分類質量顯著優于LDA,這主要是因為GSDMM適用于短文本主題特征的提取.RoBERTa與GSDMM的性能相似,SimCSE生成服務功能向量能夠構建高質量的服務分類,從分類評價指標可以看出,分類質量均高于LDA、GSDMM以及RoBERTa.
SE-SimCSE是本文提出的服務功能向量生成方法,在SimCSE框架的基礎上引入了語義增強機制,從5個數據集上分類評價數據可以得知,在Accuracy與F1兩個分類指標上,SE-SimCSE比SimCSE在所有數據集中平均提高了13.6%和10%.這說明采用SE-SimCSE生成服務功能向量進行服務分類時所獲得的分類質量顯著高于使用SimCSE生成的服務功能向量對應的分類質量.由此可見,在服務分類場景下,本文所提出SE-SimCSE方法在生成服務功能向量時的功能特征提取能力顯著優于對比模型.
6.2.2 DSFAN對服務分類質量的提升效能評估
在SE-SimCSE方法中,服務分類未考慮服務功能關聯.算法1中的SDNC為在SE-SimCSE的基礎上,引入DSFAN后構建的分類方法.表4為以上兩種方法生成的服務分類質量.
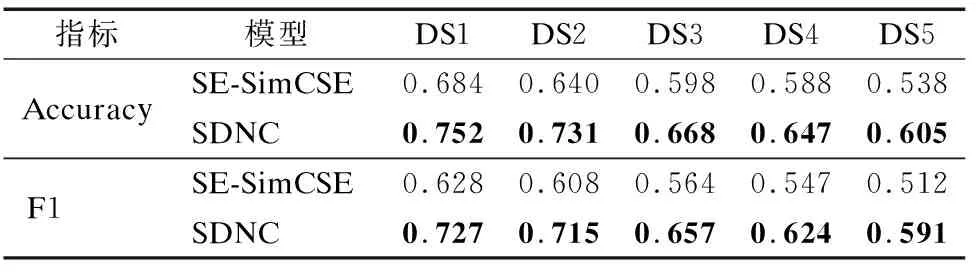
表4 DSFAN對服務分類質量的提升效能評估Table 4 Dsfan′s performance evaluation on improving service classification quality
在所有數據集中,引入功能關聯的方法在各個評價指標上均優于SE-SimCSE,說明在引入功能關聯后,服務分類的質量得到改善.5個數據集中分類評價指標的均值顯示,相比SE-SimCSE方法,SDNC方法在Accuracy提升11.65%,在F1提升15.91%,因此,引入Web服務功能關聯可以顯著提升服務分類質量.
其主要原因為:SDNC能夠同時發揮結點相似度與迥異度兩種尺度的功能關聯對分類質量提升的優勢,有助于使模型聚合相似功能服務的同時區分異類服務,有效提高服務分類精度.
6.2.3 SDNC方法與其他Web服務分類方法對比
選取近年來在國內外知名刊物發表的Web服務分類方法進行對比,以驗證本文方法的先進性,主要包含以下方法:
1)ServeNet[24]:構建了一種用于Web服務分類的神經網絡模型.使用BiLSTM獲取服務描述特征向量,使用BERT獲取服務名稱特征向量,通過訓練將以上兩種向量融合用于服務分類.
2)LAB-BiLSTM[12]:提出一種基于主題注意力的BiLSTM的Web服務分類方法.使用BiLSTM學習服務文本的特征表示,并利用注意力機制捕獲描述中不同單詞的主題相關性.通過訓練單詞-主題注意力層向量與BiLSTM層輸出的向量優化BiLSTM的描述向量表示,利用softmax分類器實現分類.
3)CARL-Net[14]:提出一種融合關鍵詞、服務名稱與共同注意力表示的深度神經網絡.利用關鍵詞與服務名稱構建數據增強向量,通過注意力機制在分別獲取詞語對服務描述向量和增強向量的重要度.最后將描述向量與增強向量通過softmax分類器得到類別概率輸出.
4)GWSC[16]:根據Web服務之間的結構關系和自身的屬性信息分別構建出多個相對應的結構關系圖和屬性二分圖.采用隨機游走算法生成Web服務的結構上下文和屬性上下文.利用skipgram模型對聯合上下文進行訓練,得到融合多維信息的表征向量,采用SVM模型實現Web服務的分類預測.
由表5數據可知,SDNC在5個數據集的兩個分類評價指標中均獲得了最高分數,其分類質量明顯優于對比方法.與其他4個方法相比,Accuracy指標的提升區間為4.1%~8.65%,F1的提升區間為4.21%~10.69%,說明本文方法的分類結果與服務真實類別的吻合程度得到明顯提升.相比其他方法,本文方法在Accuracy與F1平均提升了6.19%與6.54%.在上述4種方法中,ServeNet方法的分類質量最差,原因是其僅僅通過不同的句向量與詞向量嵌入方法獲取了服務描述與服務名稱的向量做了向量融合,沒有區分不同特征詞對描述向量的影響,且缺失對服務標簽關聯信息的考慮.
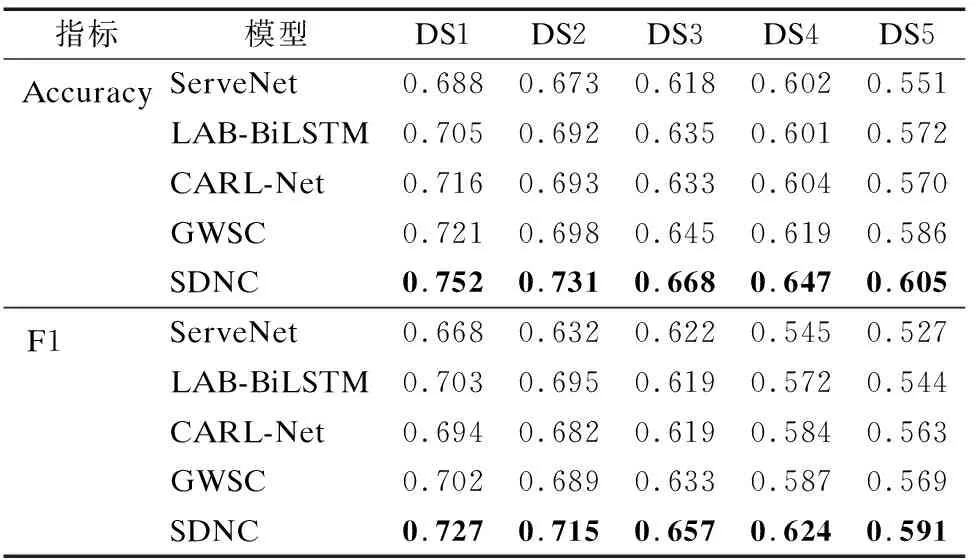
表5 SDNC分類方法橫向評估Table 5 Horizontal evaluation of SDNC classification method
相對于ServeNet,LAB-BiLSTM在提取服務描述信息過程中通過注意力機制,有效區分不同特征詞對句向量嵌入生成的影響,得以優化描述向量表示.同時,使用信息增益理論提取服務關鍵詞,并通過CNN獲取詞向量,在數據擴充層面有明顯進步.然而,其沒有針對Web服務特點對模型提出相應改進,相對于本文提出的語義增強方式,LAB-BiLSTM在3種向量生成質量上仍存在一定缺陷.例如,雖然其關注到服務關鍵詞,但是缺乏關鍵詞的詞性對特征影響的討論,會造成同一個描述中的特征重復,制約了其分類質量的提升.
CARL-Net在BiLSTM的向量生成過程提出改進,從數據擴充、數據質量兩個角度提升分類精度.然而無論服務名稱還是服務關鍵詞,都是以詞的形式存在.BERT等模型在提供整句時,在句向量與詞向量嵌入質量表現出優異性能,是因為可以兼顧上下文對詞向量進行優化.在單一詞向量生成中質量差于Word2vec、Glove等基于預訓練詞庫的靜態模型.另外,其沒有對服務之間的關聯特征進行提取,這導致其服務向量的質量仍存在提升空間,阻礙了分類精度的提升.
GWSC方法與本文方法最相似.相對于以上方法,先進之處在于關注到服務的屬性信息與結構信息.其從網絡中提取結構上下文和文本屬性上下文,有效捕獲到了文本間隱式語義關系的同時,也提取到一定的Web服務關聯特征.然而,其將服務關鍵詞作為屬性特征之一,而Web服務并沒有提供自身的關鍵詞信息,關鍵詞提取算法的性能在一定程度上對正確分類起到負面影響.此外,GWSC通過固定規則的隨機游走學習結點嵌入,沒有考慮使結點在同類服務序列與異類服務序列中學習不同特征,也未關注結點在不同序列中的上下文結構特征.
從對比實驗可以看出,所提出的SDNC分類方法,不僅通過語義增強構建了高質量的服務功能向量生成模型,而且引入的雙尺度功能向量生成方法能夠通過二階注意力機制聚合結點在游走序列中的鄰居結點功能特征以及上下文結構特征,從結點特征相似度與迥異度兩個尺度共同優化服務表征向量,提升服務分類的質量,方法的整體性能優于當前流行的服務分類方法.
6.3 實驗關鍵超參數的選擇
在生成DSFAN的訓練語料過程中,隨機游走的步長與游走次數對結點表征聚合產生不同影響.更多的游走次數或步長可以獲取兩種尺度下更多的序列信息,增強模型學習能力.但是,當游走次數與步長增加到一定數量,可能會使模型重復訓練相似路徑或者鄰域信息,造成資源浪費、引入噪聲.
由此,本節設置不同的隨機游走次數λ與步長θ,其中λ=(10,20,30,40,50,60,70,80),θ=(30,60,90,120,150)展開消融實驗,確定最合適實驗效果的超參數.5個數據集的實驗數據三維曲面趨勢見圖4.
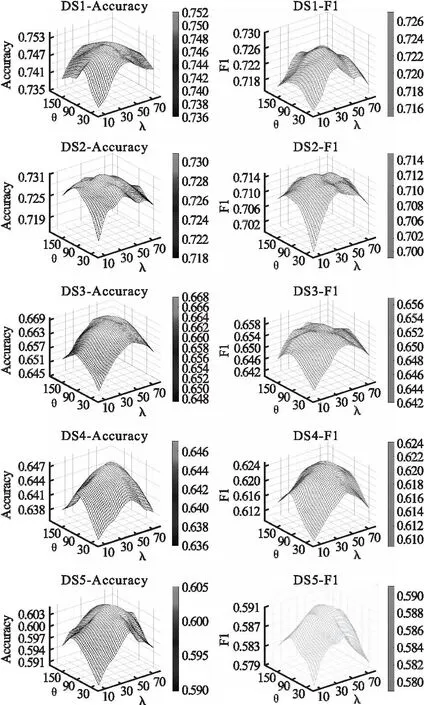
圖4 隨機游走與步長三維曲面圖Fig.4 Three dimensional surface diagram of random walk and step size
在DS1~DS5數據集中,(λ,θ)分別為(40,90)、(40,120)、(50,120)、(50,120)與(50,120)時,分類質量最高.在DS1與DS2中,數據變化幅度較小.此時類內服務量較大,服務分布較為均衡,受隨機游走語料步長與次數的影響較小.在DS3~DS5中,因服務類別增多且類內服務數量分布不均衡,導致分類質量受訓練語料影響較大.
其中,分類質量皆存在先上升,然后緩慢下降的趨勢.說明隨游走次數與步長提升,模型分別可以獲取到更多的訓練語料,從而在注意力計算時獲取更多序列級與結點級特征.但是超過一定數量,會引入噪聲,實驗效果隨之下降.在高游走次數與步長中因噪聲與計算冗余問題,分類精度略微下降,但是仍強于低游走次數與步長的分類精度.
綜上所述,本文在10~50分類問題中,將(λ,θ)分別設置為(40,90)、(40,120)、(50,120)、(50,120)與(50,120)模型效果最優.
7 結束語
為提升Web服務的分類質量,本文提出一種基于語義增強與雙尺度功能注意力網絡的Web服務分類方法.借助SimCSE框架構建了語義增強的服務功能向量生成模型SE-SimCSE.建立服務功能關聯圖,設計了雙尺度功能注意力網絡DSFAN,生成功能關聯向量.基于服務功能向量與功能關聯向量,利用softmax分類器實現Web服務分類.實驗表明,在服務功能向量生成質量方面,SE-SimCSE優于常用主題模型和神經網絡模型.此外,雙尺度功能關聯的引入使得服務分類效果在各個評價指標上均得到提升,所提出的方法在分類質量方面顯著優于對比方法.
未來研究工作主要是拓展服務關聯的范疇,如服務供應商關聯、地理位置關聯等信息,以進一步改善服務關聯對分類質量的提升效果.
猜你喜歡
中華詩詞(2022年6期)2022-12-31 06:41:24
當代陜西(2021年17期)2021-11-06 03:21:36
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
學苑創造·A版(2018年11期)2018-02-01 06:29:20
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
中國科技論壇(2017年7期)2017-07-25 08:49:53
讀者(2017年5期)2017-02-15 18:04:18
中國中醫藥現代遠程教育(2014年22期)2014-03-01 04:32:55
