融合梯度先驗與全局聚合的立體匹配算法
2024-04-22 02:30:40歐雙江周婉怡
小型微型計算機系統 2024年4期
陶 洋,歐雙江,唐 函,周婉怡
(重慶郵電大學 通信與信息工程學院,重慶 400065)
0 引 言
立體匹配,又稱為視差估計,指的是在極線校正后的立體圖像對中建立像素之間的緊密對應關系,從而得到視差,隨后還可根據相機系統的焦距和基線等參數轉換為深度.作為一種被動深度估計技術,它在許多計算機視覺應用領域中都扮演著重要的角色,如自動駕駛[1]、增強現實、目標檢測[2]和3D模型重建[3]等.
作為經典的視覺任務,立體匹配被研究多年,在傳統方法中誕生了很多較為經典的算法,如半全局匹配算法SGM[4]、AD-Census[5]、非局部代價聚合[6]等.一般來說,傳統的立體匹配算法由4個步驟組成:匹配代價計算、代價聚合、視差計算和視差優化[7].通常,傳統的立體方法側重于利用輸入圖像的一些先驗知識來提高匹配精度[5,8],但是其性能還是受到手工構建的匹配代價描述和后處理的限制.
隨著卷積神經網絡的不斷發展,立體匹配也被視為一項學習任務,基于深度學習的立體匹配在這一領域得到了學者們的廣泛研究,產生了許多高質量的模型[9-13]和規范化的數據集[14,15].基于學習的立體匹配主流方法通常也包含4個步驟:像素2D特征提取、匹配成本體構建、3D成本量聚合和視差回歸[10,13].Zbontar和Lecun首次嘗試將卷積神經網絡引入立體匹配來計算匹配代價,結果表明,卷積神經網絡可以從圖像中學習更穩健的特征,并產生可靠的匹配代價[16],在這項工作之后,許多研究人員通過改變成本體構建、代價聚合等方法來提高匹配精度[9,10,13].
盡管基于卷積神經網絡的立體匹配算法已經在多個基準上占據主導地位,但是傳統卷積更傾向于提取外觀信息,對于立體匹配這種存在圖形變換,并且可能存在左右圖像光亮不一致的場景任務來說效果欠佳,卷積核所提取的結構信息較少.由于圖像變換,物體的外觀可能發生改變從而引入誤差,但其相應的結構特征改變較少[17],傳統算法也早已注意到這一現象并加以應用,如AD-Census[5]中結合外觀信息和結構信息提升匹配精度.以往的工作也已經證明整合傳統的先驗知識有助于模型的性能提升[18].由此啟發,本文提出了一種將圖像的結構信息和強度信息結合的特征提取模塊,將中心差分卷積[19]融入特征提取主干形成差分卷積殘差組(CDC-ResBlock-Groups)以充分提取像素級的中心梯度信息(見圖1),與常規卷積相比,可以獲取更為豐富的結構語義,增強特征的表達能力.

圖1 融入差分卷積殘差組的特征提取網絡Fig.1 Feature extraction network incorporating differential convolutional residual sets
此外,本文還觀察到現有的深度學習方法[10,13]存在一定的局限性,良好的立體匹配網絡需要在捕獲局部信息的同時還能充分的理解全局上下文.如GC-Net[9]、PSMNet[10]及GwcNet[13]中使用3D CNN進行成本量聚合,通過堆疊類UNet[20]結構擴大卷積感受野.然而隨著卷積層的加深,來自底層或較遠像素的影響會迅速衰減,缺乏對場景上下文足夠的理解,導致模型在物體邊緣處丟失大量細節,在遮擋、重復紋理等需要全局理解的病態區域中表現很差.因此,本文針對上述問題提出全局代價聚合的沙漏網絡(Trans-Hrouglass),首次將Transformer[21]引入代價聚合并與3D Hrouglass融合,將成本代價體通過3D CNN,在提取局部信息的同時并進行下采樣,使得輸出結果能夠有效捕獲局部3D上下文信息,然后送入Transformer[21]進行全局特征建模以利用更多的全局上下文信息來進行代價聚合,在重復紋理、物體邊緣部分取得了更好的效果.
1 提出的方法
本文提出的融合梯度特征和全局聚合的立體匹配網絡GFGANet(Combines Gradient Features and Global Aggregation Stereo Matching Network)的具體實現,擴展了PSMNet[10],增加了可以提取結構信息的差分殘差組和改進的具有全局建模能力的3D沙漏網絡.具體的模型框架如圖2所示,具體來說,包含5個部分:特征提取,代價體構建,代價聚合,視差回歸和細化.首先,原始的RGB參考圖像和目標圖像輸入到特征提取網絡,提取到的特征用于構建4D代價體.然后,通過3D沙漏網絡對代價體進行聚合及正則化.最后,通過視差預測模塊輸出預測的視差圖.要說明的是構建代價體上,本文使用差分替換了原PSMNet[10]拼接建立的方式,以此增加匹配像素點之間的相似信息,而不用引入過多復雜的計算.

圖2 GFGANet模型框架圖Fig.2 GFGANet Model framework diagram
1.1 特征提取模塊
以往的立體匹配方法在特征提取部分往往只針對于如何更好的提取原始圖像的外在強度信息,忽視了對圖像結構信息的表征提取,本文在融合匹配代價算法的啟發下[5],將圖像的強度信息和梯度信息相融合.具體而言,GFGANet的特征提取部分采用了如其他立體匹配網絡中常使用的類ResNet網絡主干,但為了更好的引入梯度信息,在特征提取網絡的前段嵌入了差分卷積殘差組,實現了像素的中心梯度信息和強度信息的混合編碼,而為了提取豐富的多尺度信息編碼更多的上下文信息,本文參考RFBNet[22],在特征提取后段將RFB Module引入其中.
1.1.1 差分卷積殘差組
本文將中心差分卷積(CDC-Conv)[19]納入特征提取網絡中的殘差組,實現了像素中心梯度感知特征提取,可以利用空間顯著信息增強像素的局部結構特征表示.這一特性和傳統方法中的Census特征提取類似,針對傳統的立體匹配算法而言,多維度的特征表示以可以有效的增強立體匹配算法性能在業界收到一致認可.
特征提取部分的結構如圖2所示,具體而言,前3層均采用3×3的CDC-Conv[19],設置其卷積步長分別為2,1,1從而對原始圖像進行下采樣,然后跟隨4個步長分別為1,2,1,1的嵌入CDC-Conv殘差組(CDC-ResBlock-Groups),進一步提取原始圖像信息并進行下采樣,最后生成尺寸為原始輸入圖像1/4大小的特征圖,GFGANet在每個殘差組的初始階段使用差分卷積,隨后使用殘差主干生成具有大范圍和高密集采樣的特征,從而增強特征提取能力.
以3×3的CDC-Conv為例,其詳細運算過程如圖3所示.具體而言,分為兩個階段,在第1階段中3×3卷積區域的每個像素單獨與中心像素做差分計算獲得面向中心像素的梯度信息,而第2個階段則將原有的區域像素信息與一階段的梯度信息相加,并用可學習的卷積權重進行聚合獲得整體輸出.作為一種可學習的測度方式,其反映了像素點的空間局部顯著性先驗信息,數學表達如公式(1)所示:

圖3 中心差分卷積及其運算過程Fig.3 Central differential convolution and its operation process
(1)
其中,p0=(0,0)表示卷積的中心;y(p0)為其對應位置像素的卷積輸出;R是以p0對應像素為中心的3×3的像素區域;Pn則表示在R中的偏移位置;x(p0),x(p0+pn)表示對應位置像素的強度信息;w(p0+pn)為卷積核中對應位置的可學習權重;θ∈[0,1]為平衡梯度信息和強度信息的超參數,當為0時差分卷積退化為普通卷積,在本文算法中,θ被設置為0.7[19].
1.1.2 多尺度特征提取模塊
為了進一步獲得較大的接受域以便提取更加豐富的特征信息,PSMNet[10]中使用SPP來進行多層特征融合,并通過下采樣的方式來擴大感受野,但是上下采樣過程中會帶來一定的性能損失.因此,本文將學習到的局部信息特征通過RFB模塊[22]來進行聚合,如圖2使用4分支的輕量級RBF模塊,每一個分支由一個1×1的卷積,S×S 的等寬卷積和3×3的空洞卷積組成,進行局部信息擴展,最后將所有的分支進行拼接,不同與SPP等的是,通過RFB模塊的每個分支輸出的特征圖尺寸和輸入的相同,從而避免了上下采樣的信息損失,有效聚合了像素的局部周邊特征信息.
1.2 融合Transformer的代價聚合網絡
現有的高性能方法大多使用3D卷積來處理代價聚合階段的任務,而3D卷積可以視為對傳統SGM[4]算法中代價聚合階段的模擬構造,雖然可以有效地聚集局部上下文,但受限于接受域的有效范圍,其缺乏捕獲全局依賴的能力,然而局部特征和全局特征對密集預測任務而言都是至關重要的,因此,本文在立體匹配的代價聚合中融合Transformer[21],這一聚合全局上下文信息的架構,提出Trans-Hourglass模塊,將Transformer應用于立體匹配的代價聚合.
Trans-Hourglass的構造如圖4所示,使用基本的Transformer[21]構建,但由于其計算復雜度是Token數量的二次型,因此將輸入的4D代價體直接序列化后作為Transformer的輸入是不切實際的,而如果采用類似VIT直接將4D數據分割成一個一個3D塊,這種策略將阻礙Transformer跨空間、深度維度對代價體的相鄰區域建模.因此,結合卷積可以局部聚合而消除部分冗余信息和Transformer可以全局信息建模的特點,在淺層,局部信息較為豐富,Trans-Hourglass則先在一個小的3D鄰域中聚合上下文,編碼局部關系,濾除冗余信息,而在深層再進行長距離依賴關系的建模.具體而言,先使用多個3×3×3的三維卷積對4D代價體進行下采樣,逐步將原始代價體編碼為 256×D/32×H/32×W/32的4D代價體,得以使得在輸入Transformer前代價體中已經有效的嵌入豐富的局部3D上下文信息,并且大大節省比較Token的計算量,然后再將處理過的代價體輸入到Transformer中,進一步學習具有全局上下文的長程關系.最后再反復應用卷積層進行上采樣,產生高分辨率的代價聚合結果.

圖4 Trans-Hourglass模塊結構圖Fig.4 Trans-Hourglass module structure diagram
Trans-Hourglass的編碼器由多個Transformer[21]層組成,每一層都有一個標準的架構,如圖4,該架構主要由3個部分組成:位置嵌入編碼(PE),Multi-Head Attention(MHA)和前饋網絡(FFN).其數學表達式如公式(2)所示:
(2)
其中,Xin∈Rd×N,N=D×H×W表示輸入的Token序列;Norm(·)表示層歸一化,而FFN則由兩個線性層組成,每個線性層后使用GELU作為激活函數.
1.2.1 可學習的動態位置編碼
Trans-Hourglass首先使用3D卷積對4D代價體進行局部編碼與下采樣,處理后的結果作為Transformer[21]層的輸入,進行全局依賴信息的提取.但Transformer需要將空間維度和深度維度折疊成一維,為了對位置信息編碼,以往的顯式編碼方法通常使用絕對或者相對位置嵌入解決這一問題,如此一來必須顯式的指定Token序列的長度,受CPVT[23]中條件位置編碼的啟發,本文擴展其三維形式,使用一個三維卷積來隱式地編碼位置信息并嵌入到輸入的Token序列中,如公式(3)所示:
PE(Xin)=3DWConv(Xin)
(3)
其中,Xin∈Rd×N是輸入的Token序列;3DWConv是一個可學習的3×3×3深度3D卷積.在CPVT[23]中已有表明,由于卷積的參數共享和局部性,DWPE可以克服置換不變性,對任意輸入都較為友好,避免了顯式位置編碼需要指定Token序列長度的問題.
1.2.2 Transformer層和編解碼
Trans-Hourglass將4D代價體展開為通道為256維的Token序列,通過位置編碼后,再送入MHA進行全局區域相關性建模,最后通過一個FFN,將整體特征還原到輸入Transformer層前的維度.
MHA子層由Head_Nums個并行的Self-Attention(SA)模塊組成,具體來說,SA模塊可以看成是一個參數化學習的函數,它學習Token序列X中查詢q與對應的鍵k和值v表示之間的映射,通過將X中的兩個元素做查詢q和鍵k內積以計算相似性,然后對內積結果做SoftMax得到注意力權重,其數學描述如公式(4)所示:
(4)
其中,X∈Rd×N是Transformer中對MHA的輸入;head_nums為MHA劃分的子空間個數,本文算法中設置為8;Wq,Wk,Wv∈Rd×dh是MHA需要學習而將X進行線性變化得到q、k、v的權重矩陣,dh=d/head_nums;Wlinear∈Rd×d是MHA需要學習的多頭可訓練權重.
在解碼器部分,本文采用同編碼器一樣的設計,使用三級3D卷積上采樣逐步恢復特征圖的尺寸,同時在同級編解碼塊之間使用了1×1卷積的跳躍連接,以此來補充底層信息,獲得更加豐富的空間細節.
1.3 加窗視差回歸
本文算法采用經典立體匹配模型中的做法,使用Soft-Argmin[9]來獲取連續視差圖,作為傳統立體匹配算法中WTA[7]算法的可微實現,它可以利用反向傳播進行訓練,具體而言,首先使用SoftMax運算將匹配代價體中每個像素點的視差值Cd轉換為該像素點在該視差的概率,然后使用概率加權每個視差的總和得到最后該點的亞像素視差.
現有的立體匹配網絡模型中,一般設置視差的候選空間為192,在GFGANet中也是如此.但針對于具體的一個像素點的視差來說,其實際視差只接近192級視差中的一個,為了減輕類別不平衡而對亞像素視差回歸造成的影響,本文算法對正確類別進行加窗限制,具體而言,定義一個加窗半徑r,對于每個像素點,以其最后預測出的192個視差概率中最大值所在視差index為中心,以r為半徑的窗口中的概率為其最終的概率值分布,用于最后該點的亞像素值預測,如公式(5)所示:
(5)

為了進一步提升初始視差圖的細節,比如消除大感受野帶來的邊界平滑模糊,以及遮擋區域的視差值缺失等問題,本文使用了StereoDRNet[24]提出的視差后處理細化模塊,將初始化視差結果經過其后,得到模型最終預測的視差圖.
1.4 復合損失函數
GFGANet以真實的視差圖作為監督信息,并且執行端到端訓練.為了更好的監督訓練過程,本文對中間過程采用多級監督的策略,使用平滑L1損失(LSM)和交叉熵損失(LCE)分別監督最終的視差結果和視差概率分布,如公式(6)所示:
(6)
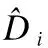
(7)
其中,x表示預測視差值和真實值的差值;Pi(d)是以真實視差構建的視差概率分布,為以視差地面Di為中心的歸一化高斯分布,如公式(8)所示:
(8)
其中,Vard表示方差,用來控制概率分布的離散程度,本文設置為2.結合兩個部分的損失計算,整體損失函數如公式(9)所示:
(9)
其中,對于GFGANet來說,整個損失函數監督代價聚合階段進入Trans-hourglass前、Trans-hourglass后及視差細化模塊后共3個部分的輸出結果;λi是對應的輸出權重,在本文實驗中取0.5,0.7,1[10].
2 實 驗
本文在公開數據集SceneFlow[15]以及KITTI 2012、KITTI 2015[14]上對所提出的立體匹配算法進行訓練和評估.首先展示了本文關于網絡設置和訓練方法的實現細節,然后在SceneFlow上進行了消融實驗,比較了GFGANet中不同組件對整體性能的貢獻,最后將其與KITTI 2012和KITTI 2015數據集上的其他前沿算法的性能進行了對比.
2.1 數據集和實驗細節
2.1.1 數據集
1)SceneFlow[15]:SceneFlow是一個合成數據集,其包含35454個訓練圖片對和4370個測試圖片對,分辨率為960×540,并且都擁有密集的真實視差標簽.本文使用其作為GFGANet的預訓練數據集.
2)KITTI[14]:KITTI分為KITTI 2012和KITTI 2015兩個版本,是一個車載雙目拍攝的真實街景數據集,并通過Lidar獲取對應真實的稀疏視差標簽.其中KITTI 2012包含194個訓練圖片對和195個測試圖片對,分辨率為1226×370,KITTI 2015是對KITTI 2012的擴充,包含200對訓練圖像和200對測試圖像,分辨率為1242×375,這兩個版本都僅提供訓練集對應的真實視差標簽.對于KITTI數據集,在KITTI 2012上,本文隨機選取訓練集中的160個圖像對進行訓練,剩余的34個圖像對用于測試,同樣在KITTI 2015的訓練集上,隨機選擇160對用于訓練,剩余40對用于測試.
2.1.2 實驗細節
本文采用PyTorch進行整體算法實現,使用Adam(β1=0.9,β2=0.999)優化器,在3塊RTX2080Ti上進行了模型訓練,批量大小設置為6,每塊GPU上放置2個訓練樣本.在訓練過程中,GFGANet首先在SceneFlow[15]上進行了16個epoch的預訓練,初始學習率設置為0.001,在第10個epoch之后,下降為0.0001,最大視差值設置為192,并且為了有效評估GFGANet,本文刪除了測試集中所有有效像素少于10%的圖像,對于每個有效圖像,也僅使用有效像素進行指標評估.而在KITTI 2015和KITTI 2012數據集上,本文分別對在SceneFlow上完成預訓練的模型進行300個epoch的微調,初始學習率為0.001,200個epoch后調整為0.0001.
評估指標上,對于SceneFlow[15],本文使用慣例的端點誤差(EPE)和異常值百分比(D1)分數來作為評價標準,其中端點誤差是指以像素為單位的全圖平均誤差,而異常值定義為視差誤差大于max(3px,0.05×Di)的像素,Di表示具體i點的真實視差.在KITTI[14]中,主要報告KITTI官網測試給出的評價指標,對于KITTI 2012,主要是非遮擋區域(Noc)和所有像素(All)的誤匹配率,而對于KITTI 2015,則主要是針對于背景(bg)、前景區域(fg)和所有像素(all)的D1分數進行評估.
2.2 實驗與分析
2.2.1 SceneFlow數據集
GFGANet擴展了PSMNet[10],在它的基礎上,增加了提取結構信息的差分殘差組(CDC-ResBlock-Group),使用無損的多尺度提取模塊(RBF Module)避免了上下采樣的性能損失,用差分的方式(Dif)構建代價體,使用改進具有全局建模能力的3D沙漏網絡(Trans-hourglass),以及在視差回歸部分進行加窗設計(WR),最后還使用了StereoDRNet[24]的后處理模塊(RF).為了更好的評估GFGANet各個組件的有效性,本文首先使用不同設置進行實驗,并在SceneFlow上進行對應的性能評估,以展現不同組件對于GFGANet的性能影響,對比實驗結果如表1所示.
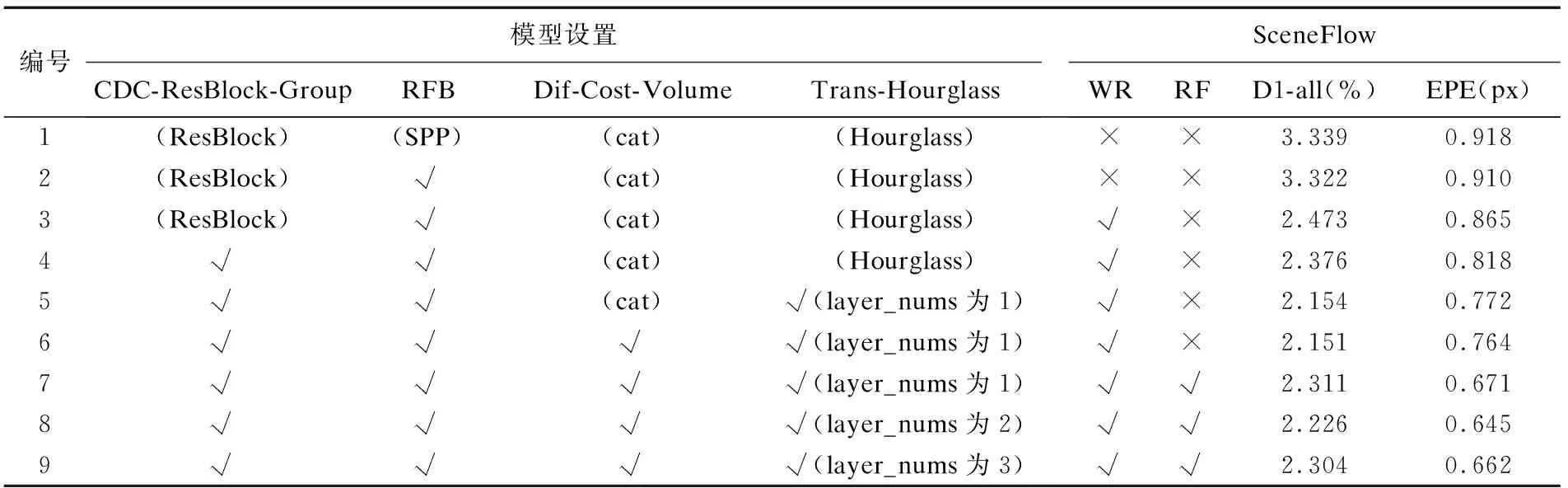
表1 SceneFlow[15]消融實驗分析Table 1 SceneFlow[15] ablation experiment analysis
由表1可知:引入RFB模塊與之前融合SPP的網絡相比EPE有所下降;而引入加窗視差回歸(WR)相比于沒有引入的模型,D1-all下降到2.473%,精度提升了25.6%,同時EPE降低了0.045px,表明對視差回歸進行加窗可以有效的減輕類別不平衡對亞像素視差回歸精度造成的影響,降低了視差異常率;而差分殘差組(CDC-ResBlock-Group)加入后,模型端點誤差EPE下降到0.818px,D1-all分數下降到2.376%,表明引入空間局部顯著性先驗信息對模型整體具有較大的收益,可以顯著提升模型的精度;而引入全局代價聚合(Trans-Hourglass)后,EPE進一步降低到0.772px,同時D1-al1下降到了2.154%,可以看到全局代價聚合的引入帶來了巨大收益,在使用差分構建代價體,并且加入StereoDRNet的視差細化模塊后,模型雖在D1-all上有一定的性能損失,但是EPE下降到了0.671px,而在實驗7、8、9中,本文測試了不同Layer_Nums的Trans-Houglass對于算法的影響,可以看到當Layer_Nums為2的時候算法性能最優.
對于加窗視差回歸的半徑設置,本文在SceneFlow數據集上進行了實驗,并在表2中展示了不同半徑r對算法性能的影響.隨著半徑r擴大,視差回歸范圍增加,類別不平衡的情況加劇,算法性能降低.而當設置半徑較小為3時,回歸的亞像素視差精度又會受到影響,結果表明r取5的時候最為合適,算法達到了最優性能.

表2 在SceneFlow[15]中對不同半徑r的消融分析Table 2 Ablation analysis in SceneFlow[15] for different radii r
同時本文將GFGANet分別與已有的一些性能方法在SceneFlow數據集上的誤差結果(EPE)進行了對比,如表3所示,大部分結果摘抄自原文,除此之外,在圖5給出了本文算法與PSMNet[10]、GwcNet[13]等性能算法在SceneFlow數據集上的可視化結果對比.

表3 與其他算法在SceneFlow[15]上的端點誤差(EPE)對比Table 3 Endpoint Error(EPE)comparison with other algorithms on SceneFlow[15]
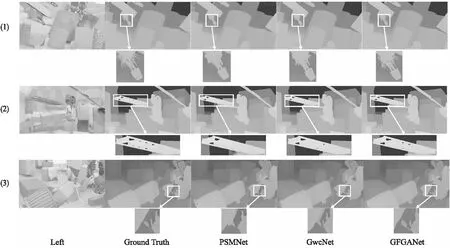
圖5 在SceneFlow[15]上與PSMNet[10]、GwcNet[13]的可視化對比Fig.5 Visualization comparison with PSMNet[10] and GwcNet[13] on SceneFlow[15]
可以看到,得益于Trans-Hourglass的全局聚合能力,GFGANet對于場景的細薄結構部分表現非常優秀,在圖5(1)中GFGANet預測的視差圖中盆栽的枝葉結構清晰可見,而且可以看到GFGANet對于重復紋理區域也表現出強大的性能,在圖5(2)GFGANet在架子的重復部分也能做到很好的細節展現,而在圖5(3)在摩托車的后視鏡與其余位置接連處,本文算法也取得了比其他兩種主流算法更好的結果.
2.2.2 KITTI數據集
本文給出了KITTI 2012和KITTI 2015測試集上傳到KITTI官網后的結果,在KITTI 2015數據集上的測試結果及排序如表4所示,其中“All”表示視差圖所有區域的像素,而“Noc”表示只考慮測試圖像的非遮擋區域,同時本文也在圖6給出了在KITTI 2015上GFGANet與PSMNet[10]、GwcNet[13]預測結果的可視化對比.

表4 KITTI 2015數據集實驗結果Table 4 Experimental results of KITTI 2015 dataset

圖6 在KITTI 2015上與PSMNet[10]、GwcNet[13]的可視化結果和誤差圖對比Fig.6 Comparison of visualization results and error plots with PSMNet[10] and GwcNet[13] at KITTI 2015
由表4可知,相比于基準算法PSMNet[10]來說,GFGANet有明顯的提升,整體像素(All)部分的D1-all分數從2.32%下降到2.04%,而非遮擋區域(Noc)則從2.14%下降到1.86%.值得關注的是,GFGANet在All和Noc的D1-fg(前景區域)上相比PSMNet[10]算法提升巨大,本文分析這是因為全局代價聚合能有效聚合全局上下文信息為前景區域提供支撐.
同時,由圖6所示,本文展示了KITTI 2015測試集上“Test Image 3”和“Test Image 4”這兩張圖片與PSMNet、GwcNet對比的可視化結果,從上到下,分別是每個網絡對應的視差圖和error圖.對于“Test Image 3”,由于角度關系,其左圖中存在迎面汽車擋風玻璃造成的反光,而對應的右圖沒有相應的反光存在,該區域在左右兩圖中存在光線不一致的情況,屬于病態區域,從結果中可以看到,在PSMNet[10]、GwcNet[13]中該區域均出現預測出錯的情況,而由于本文在特征提取階段引入了差分卷積殘差組,顯式提取結構信息,對強度信息進行相應補充,增大了匹配特征的抗干擾能力,使得GFGANet得以在該區域獲得更加準確的描述信息,從而在該區域的結果得到了改善;對于“Test Image 4”,可以看到對于圍欄處這種重復區域,GFGANet取得了比PSMNet[10]、GwcNet[13]都要好的結果,也說明了全局代價聚合針對于這種重復區域的有效性.
對于KITTI 2012,在表5中給出了其測試集提交結果中的“2-px”、“3-px”相應指標和排序情況,其中“Noc”表示非遮擋區域的像素,“All”表示圖像的全部像素,可以看到相對于基準算法PSMNet[10],GFGANet在各方面指標上的獲得了巨大提升,尤其在“2-px”下“Noc”區域誤匹配率下降了17.6%,“All”區域中誤匹配率下降了14.3%,展示了本文算法在于細節部分的強有力的性能提升.
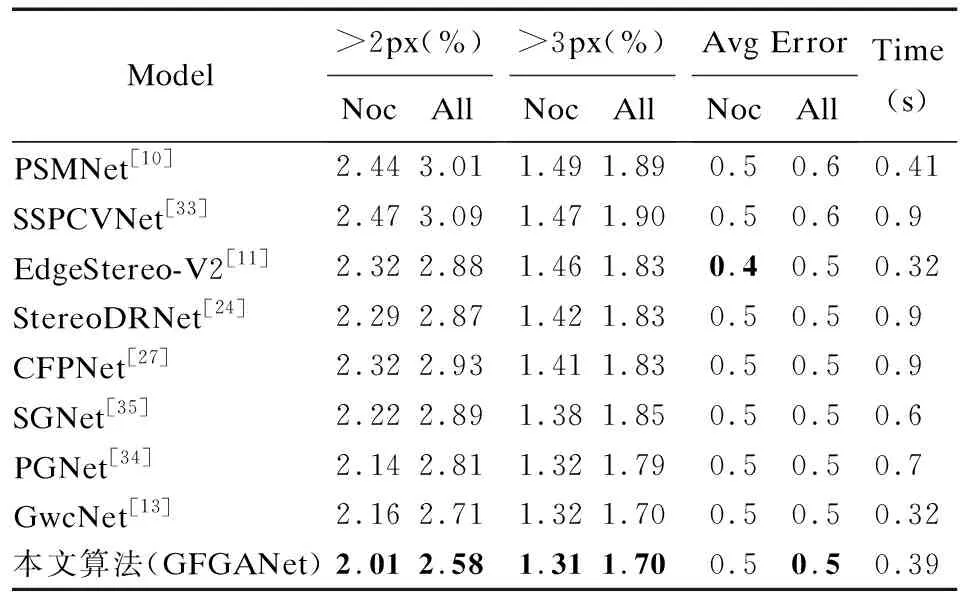
表5 KITTI 2012數據集實驗結果Table 5 Experimental results of KITTI 2012 dataset
3 總 結
本文研究了當前基于深度學習的立體匹配算法的一些局限性,提出了一種融合梯度信息,并能建模全局上下文的立體匹配方法.在特征提取部分,差分卷積殘差組(CDC-ResBlock-Groups)融合強度和梯度信息,增強了匹配特征表達能力;在代價聚合階段,Trans-Hourglass顯著增強了場景理解的能力,以提高在具有挑戰性的區域中的準確性,在視差回歸階段,使用加窗操作,改善了回歸標簽不平衡的情況.本文在SceneFlow和KITTI數據集上分別進行實驗,與基準算法和部分基于學習的性能算法相比,本文算法在光亮不一致的區域具有更好的抗干擾能力,對細小物體和薄結構的邊緣保留較好,在重復紋理和弱紋理區域等病態區域的視差預測有較大的性能提升,并在KITTI 2012和KITTI 2015數據集的誤匹配率可以達到1.31%和2.04%,對立體匹配算法在特征提取和病態區域進行性能提升都有很大的研究價值.當然本文使用固定的加窗半徑忽略了不同紋理區域的自適應問題,下一步的工作將探索多模態和自適應加窗視差回歸增強立體匹配算法域泛化的研究.
猜你喜歡
艦船科學技術(2022年15期)2022-09-14 09:21:50
電子制作(2019年15期)2019-08-27 01:12:00
電子制作(2018年19期)2018-11-14 02:37:08
中華手工(2017年2期)2017-06-06 23:00:31
自動化學報(2017年11期)2017-04-04 02:52:58
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
中外會展(2014年4期)2014-11-27 07:46:46
軸承(2010年2期)2010-07-28 02:26:12
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
