一種面向行人跌倒檢測的改進YOLOv5算法
2024-04-22 02:30:42沈國鑫劉力手尹天睿
小型微型計算機系統 2024年4期
沈國鑫,魏 怡,劉力手,尹天睿
(武漢理工大學 自動化學院,武漢 430070)
0 引 言
近年來,隨著我國快速發展,城市人口密度迅速增加,這也增加了公共場合發生擁擠跌倒的概率和一些安全隱患,尤其是在地鐵站、公交站等等場合,如果發生跌倒現象而沒有及時發現就會產生嚴重后果.因此,亟需提出一種檢測精度高、實時性的好的跌倒檢測模型.近年來,深度神經網絡在目標檢測領域取得了巨大的成就,如SSD[1]、R-CNN[2]、Fast RCNN[3]、Faster RCNN[4]、YOLO系列[5-8]等等目標檢測模型廣泛應用于無人駕駛、自動導航、姿態檢測等.至今為止,目標檢測算法分為one-stage以及two-stage兩種.two-stage算法的典型代表就是R-CNN、Fast RCNN以及Faster RCNN,而one-stage算法典型的代表是YOLO系列以及SSD算法.
對于復雜場景下的跌倒檢測,由于工作區范圍大,環境差,背景復雜,經常會出現目標互相遮擋難以檢測等問題,針對以上問題,許多學者對此進行了很多研究.周大可等[9]人提出一種結合雙重注意力機制的遮擋感知行人檢測算法,提升了遮擋目標的檢測準確性.王立輝[10]等人提出一種基于GhostNet與注意力機制結合的行人檢測與跟蹤算法,將其引入到YOLOv3中替換主干,來達到精確有效地跟蹤復雜場景下的多目標行人的目的.王璐[11]等人提出一種基于語義分割注意力和可見區域預測的行人檢測方法用于行人行為預測.錢惠敏[12]等人本文提出基于ResNet34_D的改進YOLOv3模型,對小目標和遮擋目標的誤檢率更低,速度更快.陳光喜[13]等人設計了一種基于YOLOv2的級聯網絡,對YOLOv2初步檢測出的行人位置進行再分類與回歸,以此降低誤檢,提高召回率.涂媛雅[14]等人提出了基于Lite-YOLOv3的行人與車輛檢測方法,采用改進后的深度可分離卷積塊,有效降低了網絡運算成本,加快網絡運算速度.Sweta Panigrahi[15]等人提出了一種改進的輕量級MS-ML-SNYOLOv3網絡,它可以提取分層特征表示,在擴展部分還增加了一個更大的感受野來提高檢測效果.Jing Wang[16]等人提出一種高質量的特征生成行人檢測算法來提高檢測表現.人類可以通過考慮圖像中所有可用實例的相互線索來更好地預測目標的存在,而多模態特征的融合可以表達這個過程,Yongjie Xue[17]等人提出一種新型多模態注意力融合MAF-YOLO的實時行人檢測方法來提高夜間檢測的精度,Yanpeng Cao[18]等人提出了一種新的多光譜行人檢測器,這是由執行局部引導的跨模態特征聚合和像素級檢測融合模型.但是上述網絡模型的精度仍然達不到跌倒檢測的要求,關鍵特征融合次數仍然較少,對于多重遮擋問題仍然沒有很好的解決.
針對上述問題,本文貢獻如下.首先本文提出了一個新的特征增強融合模塊FFEM來增強目標的特征表示和解決多重遮擋問題,其次提出一種新的特征金字塔網絡(AFEF-FPN)來提高特征自適應融合深度,最后引入Alpha IoU Loss和CARAFE代替CIoU Loss和Nearest Upsample來提高回歸精度和上采樣的語義信息.實驗表明,本文提出的基于AFEF-FPN的YOLOv5s網絡能夠準確的處理各種復雜的跌倒場景,在數據集上取得了優于其他網絡的結果.
1 相關工作
1.1 YOLOv5網絡模型簡介
YOLOv5的網絡結構由Backbone、Neck、Head 3個部分組成,在6.0版本中,Backbone使用的是Darknet53作為特征提取網絡,Neck部分使用PAN+FPN的結構,一共有3個Prediction-head,分別用來檢測大、中、小目標.YOLOv5算法具有4個版本,具體包括:YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x 4種,本文重點講解YOLOv5s,s版本是YOLOv5系列中卷積深度最小、特征圖寬度最小的網絡.
對于一組圖片輸入,先是進行自適應的錨框的計算和數據增強,然后Backbone會對提取輸入圖片各個尺度下的特征,提取到的多尺度特征會在Neck部分進行融合,融合采用的是PAN+FPN的結構,最后分別在網絡的18層、21層、24層作為網絡的輸出端進行預測,在預測的過程中會隨機產生大量的預測框,通過非極大值抑制(Non-Maximum Supression,NMS)[19]來篩選目標框,最后預測篩選得到的目標框的類別.
PAN-FPN[20]是在原始FPN自上而下的特征融合通道的基礎上增加了一條自下而上的特征融合通道.除此之外,還有Mingxing Tan[21]等人提出的Bi-FPN、Golnaz Ghaisi[22]等人提出NAS-FPN.經過對多種基于YOLOv5的網絡模型的實驗發現,這些特征融合網絡在跌倒檢測數據集上并不能取得很好的效果,仍然會出現許多漏檢和錯檢的情況,尤其在多個跌倒的人高度重疊的場合,非常容易發生漏檢.Yiqi Jiang[23]等人提出GiraffeDet特征融合網絡,他們提出了一種目標檢測新范式:Heavy-Neck,Light-Backbone.他們指出Backbone已經提取到了豐富的信息,增加Neck層的融合次數比增加Backbone的卷積層數量得到的結果更好,本文受到此啟發提出了一種新的特征融合網絡.
1.2 注意力機制
近年來,注意力機制被廣泛應用于計算機視覺領域,常見的注意力機制有通道注意力和空間注意力兩種.Hu J[24]等人提出了一種通道注意力機制Sequee-and-excitation(SE),SE的出現是為了解決在池化過程中的特征圖不同通道的重要性不同的問題.Woo S等人將通道注意力和空間注意力進行級聯整合提出了Convolution block attention module[25](CABM),進一步加強了注意力感知.Qilong Wang等人為了進一步加強通道注意力而提出了ECA-Net[26].Qibin Hou等人提出了Coordinate Attention(CA)[27],該機制將位置信息嵌入到通道注意力中,它可以沿著一個空間方向捕捉長程的依賴,而另一個空間方向則可以保留精確的位置信息,從而捕捉特征圖上感興趣的區域.受到CA的啟發,本文設計了一個特征增強融合模塊,增強融合后得到的結果用CA捕捉感興趣的目標,以此來建模多尺度特征之間的長距離依賴關系.
2 本文工作
2.1 網絡模型的整體結構
本文網絡由Backbone、AFEF-FPN(Neck)、Head 3個部分組成,輸入一組圖片,輸出這組圖片中的檢測目標的類別、預測框、置信度等信息.首先本文提出一種新的特征增強融合模塊(FFEM),它是由一個Concat模塊、一個CA模塊、一個Receptive Field Block(RFB)[28]模塊、一個1*1的卷積層組合而成,FFEM可以解決感知域受限的問題,增強輸入特征的特征表示,同時在原始特征融合的基礎上將特征進一步融合,提高 Backbone特征信息的復用率.使用Adaptively Spatial Feature Fusion(ASFF)[29]模塊作為本文網絡的Neck的最后一部分,其作用是為了讓特征圖自適應的進行融合,FFEM輸出的特征圖用于Adaptively Spatial Feature Fusion(ASFF)融合,加權融合后會產生3個主成分,對這3個主成分分別進行回歸預測,其中FPN在加入FFEM和ASFF改進后稱其為Adaptivity Feature Enhance Fusion-FPN(AFEF-FPN).其次使用CARAFE[30]上采樣模塊代替Nearest Upsample,CARAFE 分為兩個部分,分別是上采樣核預測和特征重組,它是一種基于輸入特征圖信息并且引入參數量較小的上采樣模塊.然后使用Alpha IoU Loss代替CIoU Loss,Alpha IoU Loss可以根據IoU大小來自適應的加權目標損失和梯度,有利于提高bbox的回歸精度.為了檢測的實時性,本文刪除了FPN部分的CSP模塊的最后一層卷積層來減小模型參數,具體結構如圖1所示.
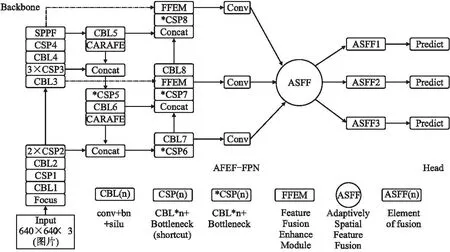
圖1 本文網絡結構圖Fig.1 Network structure diagram of this paper
2.2 特征融合增強模塊(FFEM)
在本小節中,主要介紹FFEM的具體結構,如圖2(a)所示.整體結構如下:Concat模塊將上一層的特征圖與Backbone主干中對應特征圖大小相同且未被FPN使用的特征圖進行通道上的疊加融合,圖1中的虛線為Backbone上特征的融合通道.融合之后的特征輸入到RFB模塊,RFB模塊對于輸入進來的特征圖進行特征增強后傳入1*1的卷積層來壓縮輸出通道數,最后傳入CA模塊來增加感興趣目標的特征表示.
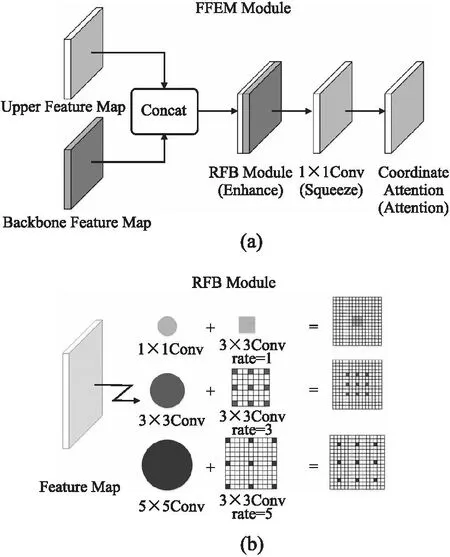
圖2 FFEM(a)和RFB模塊(b)結構圖Fig.2 Structure diagram of FFEM(a)and RFB module(b)
RFB主要是由不同膨脹率的膨脹卷積組成,膨脹率表示每個相鄰的卷積像素點之間非卷積像素點的個數.具體來說,普通的卷積核大小為3、步長為1的卷積覆蓋的空間范圍是3*3,即在一個3*3大小的特征圖上進行卷積操作,而一個卷積核大小為3*3、步長為1、膨脹率為1的膨脹卷積覆蓋的空間范圍是5*5,在卷積核大小相同、步長相同的條件下,一次膨脹卷積比一次普通卷積覆蓋的空間范圍更大,即感受野更大,具體示意圖如圖2(b)所示.
本文使用了3種膨脹卷積,它們的膨脹率分別為1、3、5,輸入RFB模塊的特征圖在進行3次膨脹卷積后再加入一條邊直接連接輸入輸出來構成殘差結構,有了這個殘差結構就能夠在一定程度上解決膨脹卷積核不連續的問題,并且能夠實現多層膨脹卷積的疊加而不損失信息的連續性,此模塊在本文中用于增大感知空間,提取更多的跌倒特征.
其次是CA模塊,CA是一種輕量型注意力機制,不會給網絡帶來巨大的計算量.普通的通道注意力通常會忽略對生成空間選擇注意力圖非常重要的信息,圖3為CA 模塊的結構圖.
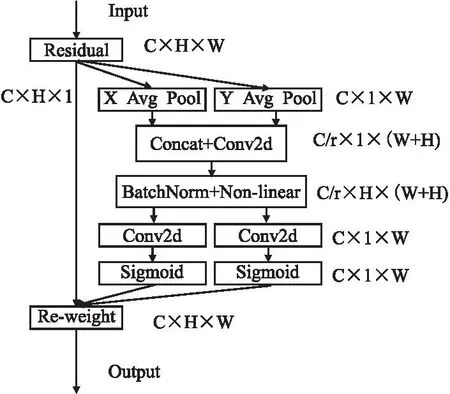
圖3 CA模塊結構圖Fig.3 Structure diagram of CA module
CA把位置上的信息嵌入到通道中,這種做法大大減少了計算量的同時有了感知位置的能力.對于一個給定的輸入x,每個通道分別在水平和垂直方向進行編碼,在深度為h的第c個通道的輸出可以表示為:
(1)
同理,寬度為w的第c個通道可以表示為:
(2)
上述的兩種方法分別在不同的方向進行特征的聚合,這樣做可以沿著一個空間方向捕捉長程的依賴,而另一個空間方向則可以保留精確的位置信息.為了利用捕捉到的信息表征同時降低模型的開銷,CA首先將兩個方向上的信息進行Concat操作后接一個1*1卷積來壓縮通道數,壓縮倍數為r,然后沿著空間維度將上述輸出切分為兩個單獨的張量:fh∈C/r×H和fw∈C/r×H,再使用兩個1*1卷積來變換成與輸入x同樣的大小,最后用Sigmoid激活輸出,這樣做可以顯著減小CA模塊參數量.其輸出可以表示為:
gh∈σ(Fh(fh)),gw∈σ(Fw(fw))
(3)
其中,σ為Sigmoid激活函數,Fh和Fw是這兩個1*1 卷積變換,gh和gw為兩個不同空間維度上的輸出.這時,整個CA的輸出y可以表示為:
(4)
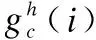
2.3 上采樣改進與ASFF
2.3.1 上采樣改進
常見的Nearest Upsample和Linear Upsample僅僅是根據像素的空間位置來確定上采樣內核,這些方法不能利用特征圖的語義信息,并且它們的感知域都非常的小.另一種自適應上采樣的方法是反卷積,它有兩個主要缺點,首先是反卷積算子在整個圖像中應用相同的核,而不考慮底層的內容,這限制了它響應局部變化的能力;其次,它配有一個大的參數量.對于一個理想的上采樣模塊,希望感知域越大越好、計算量越小越好、和語義信息的關聯性越大越好,為了解決模型的上采樣語義關聯性不高的問題,本文使用CARAFE代替Nearest Upsample.CARAFE的上采樣過程主要由上采樣核預測和特征重組兩個步驟組成,第1步主要是利用特征圖上的語義信息來預測上采樣核的形狀,第2步是將輸出特征圖中的每個位置映射回輸入特征圖,取出以之為中心的區域,和第一步得到的上采樣核作點積,得到輸出值.
2.3.2 ASFF
金字塔特征表示是解決目標檢測中目標尺度變化的常用手段.然而不同特征圖的大小不一致,通常的做法是將相同尺度的特征圖融合檢測,或者使用上采樣和下采樣來壓縮特征圖尺度保持一致后融合檢測.Adaptively Spatial Feature Fusion(ASFF)是一種新的特征融合策略,它通過學習空間濾波沖突信息來抑制特征圖的不一致性,對于輸入X個的特征圖,ASFF對它們進行加權處理,然后輸出X個自適應融合特征圖,其中每輸出一個特征圖都是輸入特征圖的加權,并且幾乎沒有引入推理開銷.
(5)
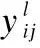
(6)
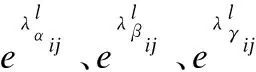
2.4 IoU Loss改進
2.4.1 IoU、GIoU、CIoU和DIou Loss
傳統的損失回歸都是基于可以表征一個矩形的4個頂點變量,但是這種做法過于簡單,不能完整的表示出4個頂點變量之間的內部關系,并且會導致模型在訓練過程中更加傾向于尺寸更大的目標.為了解決這個問題,Jiahui Yu[31]等人提出IoU Loss將4個點構成的bbox看成一個整體做回歸,這樣做的好處是統一了4個變量之間的關聯性.其中IoU和IoU Loss定義如下.
(7)
IoU Loss=1-IoU
(8)
其中,A和B分別表示真實框和預測框,A∩B和A∪B分別表示為真實框與預測框并集的部分和交集的部分.并且IoU滿足非負性和歸一性,所以能夠較好的反映預測框與真實框的檢測效果.
為了解決當IoU Loss恒等于0時梯度恒為0無法反向傳播的問題,Hamid Rezatofighi[32]等人提出了GIoU Loss.Zhaohui Zheng[33]等人提出衡量一個預測框好壞,應該從預測框與真實框的中心點距離以及長寬比之間的差異這3個方面考慮,于是他們提出了DIoU和CIoU,在GIoU的基礎上引入中心點距離作為DIoU,在DIoU的基礎上再引入長寬比之間的差異作為CIoU.
(9)
ρ2(b,bGT)表示真實框與預測框中心點距離的平方,c2是兩個框的最小包絡的對角線長度.
DIoU Loss=1-DIoU
(10)
CIoU Loss=DIoU Loss+η×υ
(11)
(12)
(13)
υ表征長寬比的一致性,η是調節因子,wGT、hGT和w、h分別表示為真實框的寬、高和預測框的寬、高,DIoU可以精細的指導預測框的中心,CIoU不僅可以指導預測框中心而且還能使得預測框長寬比更加接近真實框.
2.4.2 Alpha IoU Loss
但是CIoU和DIoU對于每個IoU目標都是平等對待的,因此對于High IoU的目標無法做到高精度回歸.于是本文用Alpha IoU Loss[34]代替CIoU Loss,Alpha IoU Loss可以根據IoU大小來自適應的加權目標損失和梯度,有利于提CIoU Loss目標的回歸精度.Alpha IoU Loss定義為:
(14)
其中,α是一個可調節參數,當α→0時,lα-IoU=-log(IoU),當α→/0時,lα-IoU=1-IoUα.
在上述公式中加入懲罰項,可以擴展到更加一般的形式:
lα-IoU=1-IoUα1+pα2(B,Bgt)
(15)
這時,α-IoU 可以通過壓縮表示出GIoU、DIoU、CIoU.它還有一個重要的性質,由于α是一個可調節的指數參數,那么當α大于1的時候,就會對High IoU目標的損失權重有放大的作用,有利于檢測器更加關注High IoU的目標,對High IoU損失的目標更加敏感.為了提高High IoU目標的回歸精度,本文使用Alpha IoU Loss代替CIoU Loss,經過實驗測試,α參數為3可以取得最好的效果.
3 實 驗
3.1 實驗環境和數據集
本實驗的深度學習環境和使用的框架如表1所示,并以相同的配置應用于Faster RCNN、未改進的YOLOv5、Mobilenet-YOLOv5等網絡.

表1 實驗環境配置表Table 1 Experimental environment configuration table
本文實驗中使用的數據集標簽屬于獨立制做,總共有8000張圖片.其中,6875張圖片來自于公共跌倒檢測數據集[35],1125張圖像來自于跌倒視頻截幀.本文選取5600張圖片用作訓練集和驗證集,2400張圖片用于測試集,訓練開始前使用了馬賽克的數據增強方法.
3.2 網絡參數設置
首先將網絡輸入的圖片大小統一resize為640×640,bacthsize設置為16,使用隨機梯度下降法作為本文網絡的優化器.為了獲取適合本文網絡的最優超參數,本文使用基于遺傳算法的超參數進化算法對網絡超參數進行優化.為了減少進化時間,僅挑選800張圖片作為進化過程中的數據集,evolve設置為50,epoch設置為50,每一代的進化都取最大值的點表示為本代超參數下的輸出的mAP值.訓練過程中的mAP的變化曲線如圖4(a)所示,從第2次迭代開始逐漸收斂,在第25代之后收斂于最大值,而后僅僅在小范圍內波動.最終得到的mAP值最大值為98.24%,并選擇這組超參數設置為本文網絡超參數,具體超參數設置如下:初始學習率設置為0.01282,學習率動量設置為0.97676,權重衰減系數設置為0.002,IoU訓練時的閾值設置為0.40,圖像Mosaic的概率設置為1.0.
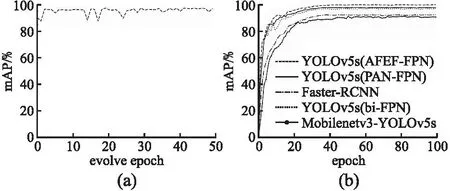
圖4 超參數進化曲線(a)和mAP上升曲線(b)Fig.4 Hyperparameter evolution curve(a)and mAP rising curve(b)
3.3 實驗結果對比和可視化
首先將本文提出的算法與現有算法在數據集上進行比較,為了客觀評價本文網絡模型的性能,使用精確率(Precision,P)、召回率(Recall,R)、平均精度(Average Precision,AP)、平均精度均值(mAP0.5)以及平均精度均值(mAP0.5-0.95)指標衡量,計算公式如下.
(16)
(17)
其中,TP(True positives)為正樣本被正確識別為正樣本的數量,FP(False positives)為負樣本被錯誤識別為正樣本的數量,FN(False negatives)為正樣本被錯誤識別為負樣本的數量,N為目標的類別數.AP的意義是P-R曲線所包絡的面積,mAP越大網絡性能越好.保持數據集、運行環境一致,在超參數為最優的前提下,本文使用了Mobilenetv3-YOLOv5、Faster-RCNN、YOLOv5(PA-FPN)、YOLOv5(bi-FPN)以及本文的YOLOv5(AFEF-FPN)分別進行訓練.
如圖4(b)所示,可以看出本文的網絡模型在訓練初期就可以快速穩定的收斂,曲線于40次迭代時達到最大值附近,而后在小范圍內波動,并且本文網絡的mAP 包絡線包圍了其 他網絡的 mAP 曲線.YOLOv5s(AFEF-FPN)最高mAP達到了98.62%,而Faster-RCNN、Mobilenetv3-YOLOv5、YOLOv5s(bi-FPN)、YOLOv5s(PAN-FPN)的最高mAP分別是90.12%、89.85%、96.67%、96.98%,比YOLOv5s(bi-FPN)提升了1.95%,比YOLOv5s(PAN-FPN)提升了1.64%,比Faster-RCNN、Mobilenetv3-YOLOv5提升了8%以上.為了更加深刻的體現本文網絡的優越性,本文分別用mAP0.5、mAP0.55、mAP0.6、mAP0.65、mAP0.7、mAP0.75這些數值較大的指標評價網絡.
如表2所示,YOLOv5s(AFEF-FPN)在mAP0.5~0.75所有的指標都高于其他網絡模型.不僅如此,本文在2400張圖片的測試集上進行測試,YOLOv5s(AFEF-FPN)的mAP0.5的值達到了96.21%,而其他網絡分別是YOLOv5s(PAN-FPN)93.35%,YOLOv5s(bi-FPN)93.12%,Mobilenetv3-YOLOv5 78.89%,Faster-RCNN 79.37%,其中YOLOv5s(AFEF-FPN)相比于原始YOLOv5s網絡在測試集上提高了2.86%的mAP.由此可以得出,YOLOv5s(AFEF-FPN)在訓練集和訓練集上都取得了優于其他網絡的結果,這也體現出它的強大的泛化能力.

表2 不同模型mAP(0.5-0.75)的對比Table 2 Comparison of mAP(0.5-0.75)of different models
為了體現出FFEM的優勢,本文對特征圖可視化分析.如圖5所示,左邊的3張圖片為輸入原圖,中間的3張圖片為YOLOv5(PAN-FPN)提取的深度圖片,右邊3張圖片是在FFEM作用之后的深度圖片,通過對比可以發現,FFEM模塊不僅可以注意到有人跌倒的區域.相比起其他YOLOv5網絡,注意區域不僅更加準確,還可以增強對感興趣區域表征.在第1組的3張圖片中,FFEM注意到了跌倒特征區域,而YOLOv5(PAN-FPN)沒有捕捉到跌倒特征區域.在第2組的3張圖片中,FFEM增強了跌倒特征區域的表征.在第3組圖片中,YOLOv5(PAN-FPN)沒有將注意力覆蓋跌倒區域,而FFEM成功感知到了跌倒區域.

圖5 特征圖可視化分析Fig.5 Feature map visualization analysis
為了更加有說服力的體現AFEF-FPN的有效性,本文設計消融實驗對影響因素進行分析,第1組實驗是單獨使用AFEF-FPN與原始網絡的對比實驗,第2組實驗是在網絡中單獨使用CARAFE與原始上采樣的對比實驗,第3組實驗是單獨使用Alpha IoU Loss與原始的CIoU Loss進行對比實驗,第4組實驗是在模型中使用AFEF-FPN和CARAFE與單獨使用CARAFE進行對比實驗,第五組實驗是使用AFEF-FPN和Alpha IoU Loss與單獨使用Alpha IoU Loss進行對比實驗,以mAP0.5、mAP0.5~0.95、Params(參數量)、Precision(準確率)作為評價指標,實驗時保持參數一致,環境一致.具體實驗結果如表3所示.
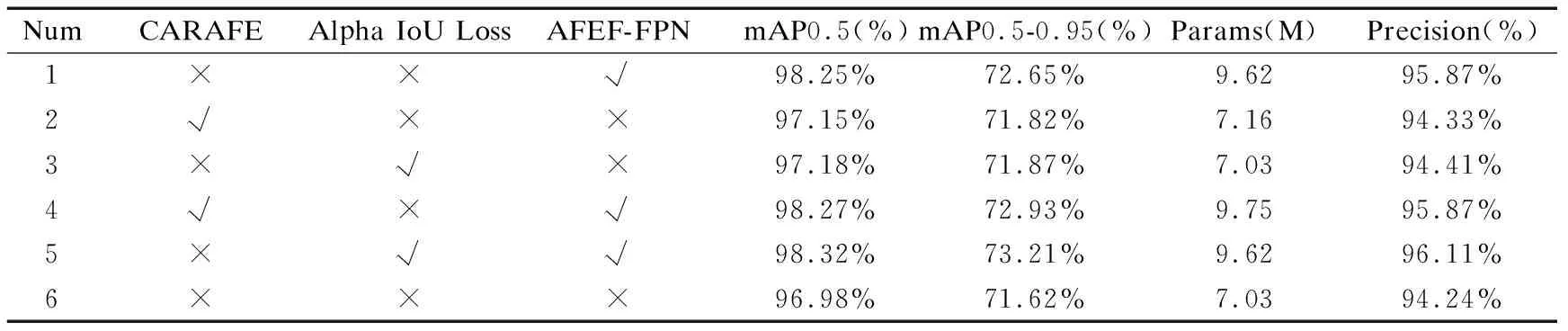
表3 消融實驗結果表Table 3 Ablation experiment result table
通過1、6實驗進行對比,可知AFEF-FPN給網絡帶來了1.27%的mAP指標提升,通過2、6實驗進行對比,可知CARAFE給網絡帶來了0.17%的mAP指標提升.通過3、6實驗進行對比,可知Alpha IoU Loss給網絡帶來了0.2%的mAP指標提升.通過2、4實驗進行對比,可知AFEF-FPN給都使用CARAFE算子的網絡帶來了1.12%的mAP指標提升,通過3、5實驗進行對比,可知AFEF-FPN給都使用Alpha IoU Loss的網絡帶來了1.14%的mAP指標提升.綜上分析可知,AFEF-FPN是給網絡帶來提升的主要影響因素.在AFEF-FPN中,FFEM是最為主要且關鍵的模塊,AFEF-FPN能夠提高網絡性能得益于FFEM,它可以提高網絡的感受野并且能夠捕捉到特征圖上的跌倒區域的信息.其中,FFEM模塊中的RFB模塊,它是一由多個不同膨脹率的膨脹卷積組合而成.在多個摔倒人物重疊的場景下,它能通過間隔取卷積點的方式來減小人物互相遮擋的問題,盡量使每個卷積點都能夠捕捉到同一個人的特征,因此在互相遮擋的場景下可以更加準確的捕捉摔倒人物的特征.而FFEM中的CA模塊是一種輕量級注意力機制,它可以使模型能夠關注到跌倒區域并且捕捉到跌倒特征.RFB與CA的結合可以讓模型實現多重遮擋的跌倒檢測,提高邊界框回歸的精度.
本文網絡YOLOv5s(AFEF-FPN)取得了優于其它網絡的效果,不僅僅體現在mAP的漲點上,如圖6所示,上圖為YOLOv5s(PAN-FPN),下圖為本文網絡,可以看出,在多個目標互相遮擋的場景下,本文網絡的檢測框定位相比于YOLOv5s(PAN-FPN)更加精準.特別在第2組圖中,本文網絡的每個檢測框都精準檢測到了目標,而YOLOv5s(PAN-FPN)出現了檢測框不準確的情況.

圖6 YOLOv5(PAN-FPN)和YOLOv5s(AFEF-FPN)效果對比(上圖為PAN-FPN,下圖為AFEF-FPN)Fig.6 YOLOv5(PAN-FPN)and YOLOv5s(AFEF-FPN)effect comparison(the picture above is PAN-FPN,the picture below is AFEF-FPN)
4 結束語
本文提出了一個新的特征增強融合模塊FFEM,其中包含了RFB模塊,1*1卷積和CA注意力模塊.本文將ASFF算法引入YOLOv5網絡模型中,同時將FFEM加入網絡的FPN中,提出了一種新的網絡YOLOv5s(AFEF-FPN);其中CA注意力模塊提高了感興趣區域的特征表示,RFB模塊增大了感知空間,同時提高了在多個跌倒人物重疊時的特征提取能力,ASFF模塊則進一步加強了多尺度的特征融合,提高了網絡檢測能力;然后本文使用基于全局語義信息的上采樣算子CARAFE代替Nearest Upsample來建模全局上采樣信息,使用Alpha IoU Loss代替CIoU Loss,有效的提高了遮擋場景下跌倒檢測的精度.但是本文網絡檢測速度仍然低于一些輕量級檢測模型,因此,接下來對于檢測速度以及檢測實時性還有待提升.后續的研究將從以下兩個方面展開:一是采集更多場景下的跌倒圖片,從而擴充數據集,使得訓練出來的模型具備更強的泛化能力;二是進一步改進網絡結構,減小模型參數,提高檢測速度.
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
發明與創新(2016年38期)2016-08-22 03:02:52
