基于緩存訪問模式的C-AMAT 測量方法及其在圖計算中的應(yīng)用
2024-04-29 05:35:18陳炳彰于蕭鈺
計算機研究與發(fā)展 2024年4期
關(guān)鍵詞:測量
陳炳彰 劉 偉,2 于蕭鈺
1(武漢理工大學計算機與人工智能學院 武漢 430073)
2(交通物聯(lián)網(wǎng)技術(shù)湖北省重點實驗室(武漢理工大學) 武漢 430073)
(chenbingzhang@whut.edu.cn)
大數(shù)據(jù)時代下,人類社會中大規(guī)模與不規(guī)律數(shù)據(jù)信息快速增長,以圖結(jié)構(gòu)對這些數(shù)據(jù)進行存儲分析越來越普遍.基于圖結(jié)構(gòu)的信息存儲方式被廣泛應(yīng)用于人際關(guān)系、社交網(wǎng)絡(luò)分析、社會科學等各個領(lǐng)域,圖數(shù)據(jù)處理變得越來越重要.而目前圖應(yīng)用的主要性能瓶頸就在于其數(shù)據(jù)訪問層面[1],因此對于圖應(yīng)用在存儲器中性能的評估與分析對于相應(yīng)的硬件開發(fā)和算法設(shè)計都具有重要意義.
并發(fā)式平均存儲訪問時間(concurrent average memory access time,C-AMAT)模型通過同時考慮存儲器訪問的局部性和并發(fā)性[2],可以更準確地表征圖應(yīng)用的存儲器性能.但是C-AMAT 的計算模型認為數(shù)據(jù)訪問的命中時間總是固定的,存在一定的局限性,同時,又因為其測量裝置硬件開銷大,使得其在實際應(yīng)用中是不易實現(xiàn)的.
為了利用C-AMAT 準確地評估檢測圖應(yīng)用的存儲器性能,我們基于緩存的訪問模式將C-AMAT 的計算模型擴展為PC-AMAT(parallel C-AMAT)和SCAMAT(serial C-AMAT),并在此基礎(chǔ)上設(shè)計并實現(xiàn)了C-AMAT 中純粹缺失周期(pure miss cycle,PMC)的提取算法及所需各項參數(shù)的測量.最終利用CAMAT 在gem5[3]模擬器中對各類圖應(yīng)用在存儲器中的性能進行了實驗評估與分析,提出了相應(yīng)的訪存優(yōu)化策略.
本文的主要貢獻包括3 個方面:
1)基于緩存的數(shù)據(jù)訪問模式將C-AMAT 的計算模型擴展為PC-AMAT 和SC-AMAT,使C-AMAT 的計算模型與現(xiàn)代計算機中不同層次的存儲器訪問模式相匹配,從而為更準確地測量和計算應(yīng)用程序運行過程中對數(shù)據(jù)的并發(fā)式平均存儲訪問時間提供了理論依據(jù);
2)設(shè)計并實現(xiàn)了計算C-AMAT 所需的重要中間參數(shù)純粹缺失周期的提取算法,避免了直接測量所需要的巨大硬件開銷;
3)利用相關(guān)系數(shù)驗證了PC-AMAT 和SC-AMAT與?PC 之間的相關(guān)性比C-AMAT 更強,進一步設(shè)計了圖應(yīng)用的存儲器性能評估實驗,通過應(yīng)用各種規(guī)模的圖數(shù)據(jù)集對圖應(yīng)用的訪存性能進行了系統(tǒng)性地分析.
1 相關(guān)工作
圖處理是大數(shù)據(jù)領(lǐng)域中一類重要的計算方式,在機器學習、路徑規(guī)劃、傳染病學、神經(jīng)網(wǎng)絡(luò)等領(lǐng)域都有廣泛應(yīng)用.
現(xiàn)實世界的圖數(shù)據(jù)往往呈現(xiàn)出小世界性(smallworld)[4]和無尺度性(scale-free)[5],稀疏矩陣存儲格式是典型的圖數(shù)據(jù)存儲格式,盡管有研究表明基于稀疏矩陣的壓縮稀疏行(compressed sparse row,CSR)、對角線(diagonal,D?A)[6]等格式存儲效率很高,但仍然改變不了圖數(shù)據(jù)訪問的不規(guī)則性,存儲器性能效率低下已經(jīng)成為圖應(yīng)用發(fā)展中最大的性能瓶頸.目前學術(shù)界關(guān)于圖數(shù)據(jù)處理性能的研究有很多.Basak等人[1]通過分析亂序CPU 下圖數(shù)據(jù)的訪存行為發(fā)現(xiàn)不同數(shù)據(jù)類型加載指令之間的依賴鏈(load-load dependency chain,LLDC)是實現(xiàn)高內(nèi)存級并行(memory level parallelism,MLP)的主要瓶頸;Balaji 等人[7]在末級緩存(last level cache,LLC)更換不同的數(shù)據(jù)替換策略時發(fā)現(xiàn),即使是最先進的緩存數(shù)據(jù)替換策略,圖應(yīng)用在LLC 上的MPK?(misses per kilo instructions)依然沒有明顯下降;湯嘉武等人[8]通過實驗分析出通用高層次綜合(high level synthesis,HLS)系統(tǒng)缺乏對不規(guī)則圖算法有效支撐的問題,提出了一種面向圖計算的高效HLS 方法,實現(xiàn)了高效的并行流水執(zhí)行;Faldu等人[9]驗證了由于圖分析的高度不規(guī)則訪問模式,最先進的硬件緩存管理方案在利用其重用方面依然不盡人意,為此,他們引入了專門用于LLC 上對圖分析進行緩存管理的GRASP,GRASP 專用緩存策略利用了熱頂點固有的高重用,同時保留了捕獲其他緩存塊中圖數(shù)據(jù)重用的靈活性;Cooksey 等人[10]則從高速緩存行中獲取任何看似合理的地址作為數(shù)據(jù)加載,但是,只有觀察到數(shù)據(jù)結(jié)構(gòu)是一個指針列表時,這些指針才將被引用,否則此類方案將顯著超載,從而導致緩存污染和性能下降.
盡管學術(shù)界現(xiàn)有的研究工作從多個維度對圖應(yīng)用進行性能評測都發(fā)現(xiàn)了其性能瓶頸在訪存層面,但采用的系統(tǒng)性能評估指標更多地停留在以計算為中心的層面,最為廣泛使用的便是每周期完成指令數(shù)(instruction per clock,?PC),但?PC 是被設(shè)計用來測試CPU 性能的,并且由于?PC 受指令集、CPU 微架構(gòu)、存儲器層次結(jié)構(gòu)和編譯器技術(shù)等多方面的影響,無法直接用來反映存儲器系統(tǒng)的性能.另一方面,傳統(tǒng)的存儲器性能指標,如訪存缺失率(miss rate,MR)、平均缺失代價(average miss penalty,AMP)、平均存儲器訪問時間(average memory access time,AMAT),對于采用流水線緩存[11]、非阻塞緩存[12]等現(xiàn)代設(shè)計的存儲器系統(tǒng)來說是不合適的.我們在gem5 中對內(nèi)核數(shù)量進行了倍增,以此提高LLC 上的并發(fā)性,在對GAP[13]基準測試套件中典型的BFS(breadth first search),PR(PageRank),BC(betweenness centrality),CC(connected components)這4 個算法在LLC 上 的AMAT 進行了測量,其中實驗環(huán)境配置及工作負載見第4 節(jié).圖1 顯示了當并發(fā)性作為一個因素時,AMAT 作為衡量內(nèi)存性能的指標是失敗的,AMAT指標表明:隨著內(nèi)核數(shù)量的增加,LLC 上的總體性能會下降.這和系統(tǒng)性能提升的事實相違背,顯然是錯誤的.這也進一步表明AMAT 已無法準確反映現(xiàn)代處理器的內(nèi)存性能.
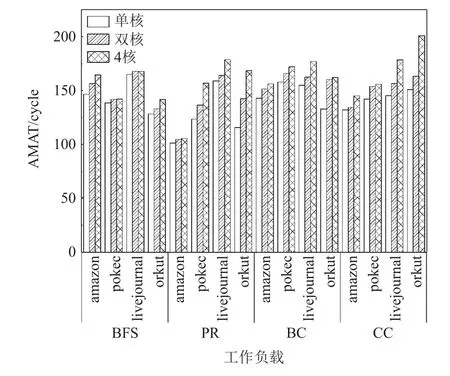
Fig.1 AMAT of LLC at different number of cores圖1 不同內(nèi)核數(shù)量下LLC 的AMAT
2013 年,Sun 等人[2]提出了新的存儲器性能度量標準C-AMAT,C-AMAT 通過給出嚴格規(guī)整的數(shù)學表達式和邏輯證明,將AMAT 進行了擴展,可以更準確、全面地評估現(xiàn)代存儲器系統(tǒng).
在定量上,C-AMAT 被定義為總的存儲訪問周期除以總的存儲訪問次數(shù)[2]:
其中TMemCycle代表總的存儲訪問周期,CMemAcc則代表總的存儲訪問次數(shù).需要注意的是,TMemCycle是以重疊模式計算的,換句話說,當同一周期內(nèi)存在多個內(nèi)存訪問時,TMemCycle僅增加1 個周期.此外,存儲訪問周期與CPU 周期不同,至少有1 次未完成內(nèi)存訪問的CPU 周期才能算作內(nèi)存訪問周期.
根據(jù)相關(guān)系數(shù)的定義,C-AMAT 應(yīng)該與?PC 呈負相關(guān)[14],即?PC 增加時,C-AMAT 減少.此外,當?PC 有很大程度的增加時,C-AMAT 也應(yīng)該有類似程度的變化.然而,當我們在對GAP 基準測試套件中圖應(yīng)用進行測量時發(fā)現(xiàn),圖應(yīng)用的?PC 并不總與C-AMAT呈負相關(guān).實驗結(jié)果如圖2 所示,其中實驗環(huán)境配置及工作負載見第4 節(jié).為了更直觀地表現(xiàn)?PC 和CAMAT 之間的關(guān)系變化,對圖算法在各個數(shù)據(jù)集中的?PC 和C-AMAT 的平均值進行了比較.在圖2(a)中我們看到,隨著內(nèi)核數(shù)量的增加,?PC 也隨之遞增.然而從圖2(b)~(d)中發(fā)現(xiàn),隨著內(nèi)核數(shù)量的增加,在各級cache 中的C-AMAT 僅BFS 算法在L1 和LLC中呈現(xiàn)出遞減的趨勢,其他算法在各級cache 中的變化則是無規(guī)律的,且變化幅度也是遠小于?PC 的.

Fig.2 ?PC and C-AMAT of each cache level圖2 ?PC 和各級cache 的C-AMAT
之所以出現(xiàn)圖2 中的現(xiàn)象,是因為C-AMAT 的計算模型總是認為數(shù)據(jù)訪問過程中的命中延時是固定的,忽略了cache 層中的數(shù)據(jù)訪問模式,使用固定的cache 訪問延時會導致測量出的總存儲訪問周期TMemCycle與其理論值有所偏差.
事實上,現(xiàn)代處理器多采用亂序執(zhí)行來提升CPU的處理效率,典型的如?ntel 在x86 體系中的Pentium Pro,為了提高時鐘頻率并降低cache 的缺失代價,對于cache 中的Tag SRAM 和Data SRAM 這2 部分的訪問模式,現(xiàn)代處理器往往在L1 cache 采用了并行訪問的結(jié)構(gòu),但其訪問命中時間并不是簡單的Tag 與Data 延時相加得到的.而L2 cache 以及下一級cache的數(shù)據(jù)訪問則通常采用的是串行訪問模式[15],即對于L2 cache 及下一級cache 而言,它們的命中延時在訪問命中和訪問缺失時不再是固定的,因此,CAMAT 的計算模型可能無法完全正確地表征存儲器系統(tǒng)的整體性能.其中的計算細節(jié)我們將在第2 節(jié)重點討論.
另一方面,與AMAT 相比,C-AMAT 的計算方法也更加復雜,并且需要額外的檢測邏輯和寄存器來測量C-AMAT 所需的參數(shù),盡管文獻[14]給出了每周期訪問(access per cycle,APC)的測量邏輯,但這種方法卻有著較大的硬件開銷和繁雜的計數(shù)邏輯,不易實現(xiàn).因此,如何準確獲取一段完整應(yīng)用程序中的純粹缺失周期和純粹缺失訪問仍然是測量C-AMAT的重點和難點.
為了準確度量圖應(yīng)用的存儲性能,本文通過分析前人研究成果,基于現(xiàn)代亂序處理器中不同層次cache 的不同訪問模式,將C-AMAT 的計算模型擴展為PC-AMAT 和SC-AMAT,完善了C-AMAT 的計算模型.同時提出并實現(xiàn)了純粹缺失周期和純粹缺失訪問的提取算法,最終基于PC-AMAT 和SC-AMAT 對圖應(yīng)用的存儲性能進行表征,這使得尋找到適用于圖應(yīng)用系統(tǒng)的整體最佳參數(shù)組合成為可能.
2 PC-AMAT 和SC-AMAT 的計算模型
由于我們的工作直接基于C-AMAT,因此在本節(jié)首先介紹了C-AMAT 的計算模型,然后通過分析不同層次cache 的數(shù)據(jù)訪問模式,引入了基于C-AMAT擴展的PC-AMAT 和SC-AMAT 的計算模型.
2.1 C-AMAT 計算模型
式(1)給出了C-AMAT 的原始定量公式,但并沒有明顯體現(xiàn)出C-AMAT 的局部性和并發(fā)性,為了體現(xiàn)這2 種性質(zhì),給出了C-AMAT 的詳細計算公式[2]:
其中H代表命中延時,Ch和Cm分別代表命中存儲請求的并發(fā)度和缺失存儲請求的并發(fā)度,Ch和Cm是CAMAT 引入的2 個新參數(shù).此外,這個計算公式首次引入了“純粹缺失”的概念,即只有在缺失訪問中至少包括1 個純粹缺失周期,在這個周期中,整個存儲系統(tǒng)都沒有命中發(fā)生,這樣的缺失才稱為純粹缺失.pMR為純粹缺失率,即純粹缺失訪問的次數(shù)與全部存儲訪問次數(shù)之比.pAMP即純粹平均缺失代價,代表平均每個純粹缺失訪問中的純粹缺失周期的數(shù)量[2].
然而,在C-AMAT 中,無論當前層級存儲器中的數(shù)據(jù)是否命中,它的命中時延總被認為是固定的.事實上,現(xiàn)代處理器中cache 層的數(shù)據(jù)命中時間與其訪問模式息息相關(guān),因此,我們基于cache 訪問模式對C-AMAT 的計算模型進行了細粒度的擴展.
2.2 PC-AMAT 計算模型
現(xiàn)代處理器中的cache 由Tag 和Data 這2 部分組成,但在實際的實現(xiàn)當中,cache line 中的Tag 和Data 部分其實是分開放置的,稱為Tag SRAM 和Data SRAM,如果對這2 部分的內(nèi)容同時進行訪問,則稱為并行訪問[16],其結(jié)構(gòu)如圖3 所示;反之,如果先訪問Tag SRAM 部分,根據(jù)Tag 的比較結(jié)果再去訪問Data SRAM 部分,這種方式則稱為串行訪問[16],其結(jié)構(gòu)如圖4 所示.
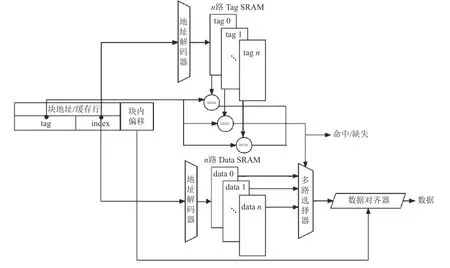
Fig.3 Parallel access mode in cache圖3 cache 中的并行訪問模式
當對圖3 這種結(jié)構(gòu)的cache 進行訪問時,在對某個Tag 部分的地址訪問的同時會對該地址對應(yīng)Data部分的數(shù)據(jù)也進行訪問,并將它們送到多路選擇器中選擇出指定的數(shù)據(jù)塊,最終經(jīng)過數(shù)據(jù)對齊便可完成數(shù)據(jù)訪問.由于現(xiàn)代超標量處理器使用的是流水線訪問,數(shù)據(jù)塊選擇時間和數(shù)據(jù)對齊部分的時間是可以忽略不計的,因此,在cache 的并行訪問結(jié)構(gòu)中完成一次數(shù)據(jù)訪問的時間其實是由Tag 和Data 中訪問延時較長的部分所決定的,此時如將Tag 與Data訪問延時之和作為cache 命中時間是錯誤的,因為這將會嚴重高估C-AMAT 的值.因此,并行結(jié)構(gòu)下基于C-AMAT的PC-AMAT 可以表示為式(3).
在PC-AMAT 中,PH代表了并發(fā)cache 命中時間,即在并行訪問結(jié)構(gòu)中,cache 的命中延時PH由Tag延時和Data 延時的較大者決定,因此PH可以表示為:
其中tag_latency和data_latency分別表示Tag 部分訪問和Data 部分訪問所需要的命中時間,一般情況下,現(xiàn)代處理器中L1 cache 在這2 部分的延遲都在2~5個周期之間,同一架構(gòu)處理器中的tag_latency和data_latency差距并不會太大[17],但文獻[18]中將命中時延統(tǒng)一成一個固定的參數(shù)顯然是與事實不符的,這會造成Cph和Cm的計算誤差,最終導致計算出來的CAMAT 值與實際值存在較大誤差.Cph和Cm的計算方式為:
其中access表示當前存儲器中總的數(shù)據(jù)訪問次數(shù),overlap_hitTime表示當前cache 訪問過程中的重疊命中時間,pMissTime表示所有數(shù)據(jù)訪問總的純粹缺失周期,而pMissTime_overlap則代表了所有數(shù)據(jù)訪問過程中總的重疊純粹缺失周期.我們將在第3 節(jié)詳細解讀上述變量的取值.
2.3 SC-AMAT 計算模型
圖4 展示了cache 的串行訪問結(jié)構(gòu),在對數(shù)據(jù)進行訪問時,首先需要對Tag SRAM 進行訪問,進行Tag 比對之后,若Tag 對應(yīng)的Data 部分中的數(shù)據(jù)在當前cache 層中存在,則對其進行選擇訪問,此時就不再需要進行數(shù)據(jù)對齊即可對指定的數(shù)據(jù)塊進行訪問,這樣的1 次數(shù)據(jù)訪問命中時間就是Tag 與Data 的訪問延時之和;但若對Tag 進行訪問后在當前cache 層中未檢測到對應(yīng)的數(shù)據(jù)部分,則進入下一級存儲器進行訪問,此時當前cache 層中數(shù)據(jù)訪問的命中時間只需將Tag 部分延時包含在內(nèi).
因此,串行訪問結(jié)構(gòu)是不需要多路選擇器進行數(shù)據(jù)選擇的,而只需要訪問數(shù)據(jù)部分指定的那個SRAM,其他的SRAM 由于都不需要被訪問,可以將它們的使能信號置為無效,這樣就可以節(jié)省很多功耗,串行訪問結(jié)構(gòu)也多被應(yīng)用于現(xiàn)代處理器的L2 cache 和LLC.即串行結(jié)構(gòu)下的cache 訪問,其命中時間是由數(shù)據(jù)是否命中所決定的.因此,串行結(jié)構(gòu)下基于C-AMAT 的SC-AMAT 可以表示為:
盡管在SC-AMAT 中,SH也代表著cache 的命中時間,但不同于式(2)中的PH,SH的大小是由數(shù)據(jù)是否命中決定的,因此,SH可表示為:
當數(shù)據(jù)訪問命中時,命中時間SH是tag_latency和data_latency相加,而當數(shù)據(jù)訪問缺失時,其命中時間SH則只由tag_latency決定.現(xiàn)代處理器中L2 cache 在這2 部分的延遲都在6~12 個周期,LLC 在這2 部分的延遲一般在32~64 個周期[17],當然,精確的訪問延時需要根據(jù)具體的CPU 架構(gòu)來確定.但顯而易見,此時命中延時SH不是固定值,使用式(2)中的H將會對并發(fā)式平均訪問時間的計算結(jié)果造成不可忽略的誤差.相應(yīng)地,串行訪問結(jié)構(gòu)下數(shù)據(jù)訪問的命中并發(fā)度Csh的表達式為:
其中hit代表當前存儲器中數(shù)據(jù)訪問的命中次數(shù),miss表示當前存儲器中數(shù)據(jù)訪問的缺失次數(shù),與Cph一樣,Csh的分母overlap_hitTime依然是當前cache 訪問過程中的重疊命中時間.
第4 節(jié)中我們將會根據(jù)?PC 與C-AMAT,PCAMAT,SC-AMAT 這3 個指標的相關(guān)系數(shù)來度量這3個指標的精確度,以驗證擴展C-AMAT 為PC-AMAT與SC-AMAT 的必要性與合理性.
3 純粹缺失周期提取算法
本節(jié)詳細介紹如何提取PC-AMAT 和SC-AMAT測量過程中所需的重要中間參數(shù)—純粹缺失周期,并據(jù)此計算出pMR,pAMP,Cm等依賴PMC 的計算參數(shù),進而計算出PC-AMAT和SC-AMAT.
根據(jù)式(2),我們知道想要計算C-AMAT 首先需要測量Ch和Cm.文獻[18]提供了Ch和Cm的計算方法,如圖5 所示.通過在原有的硬件結(jié)構(gòu)上增加了2個探測器,分別是命中并發(fā)度探測器和缺失并發(fā)度探測器,這2 個探測器都由檢測邏輯和寄存器組成,命中并發(fā)度探測器中的檢測邏輯用來監(jiān)控是否有緩存Tag 查詢活動.通過使用寄存器來統(tǒng)計總的命中周期和每個命中階段的同時命中情況,并計算平均命中并發(fā)度.因此,每個命中階段至少需要2 個寄存器,分別用來記錄開始周期和結(jié)束周期.缺失并發(fā)度探測器中的檢測邏輯監(jiān)控是否有新的請求到達MSHR(missing status holding register)[18],并通過寄存器來探測純粹缺失周期的數(shù)量和每個純粹缺失階段的并發(fā)度.缺失并發(fā)度探測器所需的寄存器數(shù)量計算和命中并發(fā)度探測器數(shù)量的計算方法是類似的,不同之處在于選擇的寄存器的數(shù)量需要考慮同一周期內(nèi)共存的最大缺失訪問數(shù),即MSHR 表項的數(shù)量乘以MSHR 表項中目標的數(shù)量.
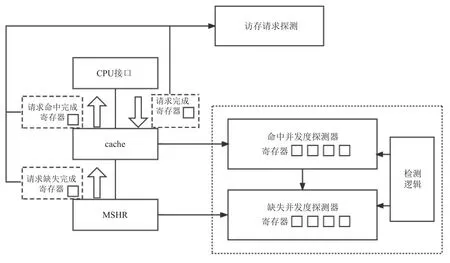
Fig.5 C-AMAT measuring device圖5 C-AMAT 測量裝置
基于上述分析,我們發(fā)現(xiàn)僅是測量C-AMAT 的Ch和Cm便會導致很大的硬件開銷,因此想要通過這種測量裝置直接測量出應(yīng)用程序的C-AMAT 是比較困難的.據(jù)此,我們在測量圖應(yīng)用的C-AMAT 時并沒有直接使用文獻[18]中的這種測量裝置.同樣如圖5 所示,我們并沒有在程序運行的過程中去監(jiān)測訪存的命中并發(fā)度與缺失并發(fā)度,對于每個命中與缺失階段,都只需要2 個寄存器分別用來記錄開始周期與結(jié)束周期,在一次訪存結(jié)束后,便可立即釋放當前寄存器,而無需一直保留用來計算訪問并發(fā)度.最后通過設(shè)計相應(yīng)的純粹缺失周期提取算法,計算出PC-AMAT和SC-AMAT 計算所需要的相關(guān)參數(shù).這種方法大大降低了C-AMAT 測量所需的硬件開銷,同時避免了程序運行階段探測并發(fā)度時繁雜的訪存檢測邏輯.
3.1 PC-AMAT 與SC-AMAT 實例
為了更好地解釋和理解純粹缺失周期等相關(guān)概念,我們基于PC-AMAT 舉了一個簡單的例子,如圖6 所示,圖6 中共存在5 個不同的存儲訪問.由于PC-AMAT 是針對并行訪問結(jié)構(gòu)的cache 而言的,我們假設(shè)當前cache 中Tag SRAM 部分的命中時間為2個周期,Data SRAM 部分的命中時間為3 個周期,因此,每次數(shù)據(jù)訪問都必須經(jīng)過3 個周期的命中階段.如果訪問沒有在當前cache 中命中,即訪問缺失時,則會產(chǎn)生1 個缺失代價,缺失代價的大小取決于最終該缺失的數(shù)據(jù)在哪一級存儲層次中被找到.圖6 中,訪問請求1,2,5 是命中訪問,訪問3 和4 是缺失訪問.訪問3 包含了4 個周期的缺失代價,其中有2 個周期與訪問5 的命中周期出現(xiàn)了重疊,因此,從并發(fā)存儲的角度來看,訪問3 只存在2 個純粹缺失周期.訪問4 有1 個缺失周期,但該周期也與訪問5 的命中周期重疊,因此不是純粹缺失周期.因此,訪問3 是純粹缺失訪問,訪問4 不是,所以這5 個訪問的缺失率為0.4,而純粹缺失率僅為0.2,純粹平均訪問缺失代價pAMP=1.同時,對于式(5)和式(9)中提到的命中重疊時間overlap_hitTime,我們將其定義為在所有訪問請求中,只要當前周期存在命中周期,那該周期則算作1 次重疊命中周期.類似地,純粹缺失重疊時間pMissTime_overlap為在所有請求訪問中,當前周期都是純粹缺失周期時視作1 次純粹缺失重疊周期.

Fig.6 An example of PC-AMAT principle圖6 PC-AMAT 原理示例
因此,從圖6 中我們可以觀察到這5 個訪問總的命中重疊時間為7,總的純粹缺失重疊時間為1,根據(jù)式(5)和式(6)計算可得Cph=15/7 和Cm=2,最后由式(3)得到PC-AMAT 的每次訪問周期個數(shù)為1.8.事實上,圖6 中5 個訪問請求總共經(jīng)歷了8 個時鐘周期,并且這8 個周期都屬于訪問周期,因此我們也可以直接將總重疊訪問周期除以訪問次數(shù)得到PCAMAT 的每次訪問周期個數(shù)為9/5=1.8.
而對于SC-AMAT,其與PC-AMAT 最大的區(qū)別就在于當前存儲器中的命中訪問與缺失訪問的命中時間是不一致的,為了更好地解釋SC-AMAT,我們同樣舉了一個簡單的例子,如圖7 所示,圖7 中也存在5 個不同的存儲訪問.我們假設(shè)當前cache 中Tag SRAM 和Data SRAM 的命中時間都為3 個周期,因此,每次數(shù)據(jù)訪問若是在當前cache 中命中,則其命中時間為6 個周期.若是訪問缺失,則只會經(jīng)歷3 個周期的Tag 訪問命中時間,接下來該缺失訪問同樣會根據(jù)數(shù)據(jù)最終查找到位置,產(chǎn)生相應(yīng)的缺失代價.圖7 中,由于訪問請求1,2,5 的命中時間都為6 個周期,因此都屬于命中訪問;而訪問3,4 則屬于缺失訪問,它們在當前cache 上的命中時間都僅為3 個周期,訪問3 包含了8 個周期的缺失代價,其中有5 個周期與訪問5 的命中周期重疊,因此訪問3 存在3 個純粹缺失周期.與訪問3 類似,訪問4 的缺失代價為5 個周期,其中有2 個周期為純粹缺失周期.通過以上分析,我們可以計算出圖7 示例中5 個訪問的純粹缺失率為0.4,純粹平均訪問缺失代價pAMP=2.5,同時將命中重疊時間和純粹缺失重疊時間分別等于9 和3時代入式(9)和式(6),可以計算出Csh=8/3 和Cm=5/3,最后由式(7)計算得到SC-AMAT 每次訪問2.4 個周期.同樣,由于這5 個訪問所經(jīng)歷的總重疊時間為12個周期,我們也可以得到SC-AMAT 每次訪問2.4 個周期(12/5).
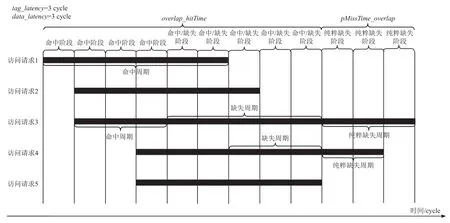
Fig.7 An example of SC-AMAT principle圖7 SC-AMAT 原理示例
3.2 純粹缺失周期提取算法
在實際應(yīng)用程序中,并不是所有周期都屬于訪問周期,數(shù)據(jù)訪問過程中存在著停滯周期,因此3.1節(jié)中的計算示例的計算方法并不適用于實際應(yīng)用程序中C-AMAT 的測量.準確測量PC-AMAT 和SCAMAT 的值的難點就在于如何準確地判斷每個缺失周期是命中、失效重疊,還是純失效.據(jù)此,我們設(shè)計了純粹缺失周期PMC 提取方法,具體過程如圖8所示.
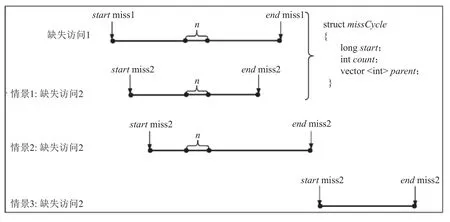
Fig.8 An example of missing cost scenario in missing access圖8 缺失訪問中的缺失代價情景示例
為了獲取每個缺失周期的屬性值,我們首先將缺失訪問進行了合并.我們將所有缺失訪問的缺失代價按照它們的開始周期進行遞增排序,然后通過一個結(jié)構(gòu)體missCycle記錄每一個缺失周期的絕對時間start、該缺失周期被缺失訪問占有的次數(shù)count以及該缺失周期所在的缺失訪問請求parent.我們通過分類和迭代便可獲取到每個缺失周期的屬性值,包括該缺失周期總共被占有的缺失訪問的次數(shù)以及存在于哪些缺失訪問中.算法描述如算法1 所示.
算法1.缺失周期合并算法.
對于圖8 中的缺失訪問1 和情景1 下的缺失訪問2,第n個缺失周期的絕對時間即為n,該缺失周期當前被缺失訪問占有的次數(shù)為2,其所在的缺失訪問請求為缺失訪問1,2.在經(jīng)過上述處理時,缺失訪問2 相對于缺失訪問1 可能會出現(xiàn)圖8 所示的3 種情況.其中行④~?是當缺失訪問2 出現(xiàn)如圖8 中的情景1 和情景2 時,需要將每個curr_cycle屬性進行更新,根據(jù)缺失訪問2 的結(jié)束時間是否大于缺失訪問1來決定是否需要將其進行缺失訪問合并操作,而行?~?則是當缺失訪問2 的開始時間大于缺失訪問1 時,此時這2 次的缺失訪問無法進行合并,則對缺失訪問2 的每個缺失周期進行初始化后開始新一輪的合并迭代操作.通過對缺失訪問的合并操作,我們便可以清晰地獲取到每個缺失周期的信息,包括該缺失周期所處的缺失訪問位置及出現(xiàn)次數(shù).同樣,為了更快速地判斷每個缺失周期是否是純粹缺失周期,我們對命中階段的周期也進行了合并操作,需要注意的是,此處命中階段的含義不僅代表命中訪問所經(jīng)歷的時間,而且缺失訪問的命中時間也應(yīng)該算作命中階段,具體算法描述如算法2 所示.
算法2.命中周期合并算法.
我們在對命中階段按開始周期以遞增方式進行排序后,根據(jù)下一命中階段的開始周期是否大于當前命中階段的結(jié)束周期來決定是否將當前2 個命中階段進行合并.通過這樣的預處理,我們可以最小化每個缺失周期與命中周期的比較次數(shù),從而快速判斷該周期是否是純粹缺失周期.具體算法如算法3 所示.
算法3.純粹缺失周期的提取算法.
該PMC 的判斷算法通過將經(jīng)過缺失訪問合并后的每個缺失訪問的每個缺失周期與每個命中周期進行start屬性比較,若當前缺失周期的start屬性與某個命中周期的start相同,則該缺失周期不是純粹缺失周期,反之則是.
4 實驗評估
由于本文研究C-AMAT 的目的是為了度量圖應(yīng)用的存儲器性能,發(fā)掘圖應(yīng)用在存儲器中的性能優(yōu)化方向,因此,本節(jié)將通過PC-AMAT 和SC-AMAT 對大規(guī)模圖數(shù)據(jù)集進行存儲器性能測試和評估,并分析其內(nèi)存性能表現(xiàn).
4.1 實驗環(huán)境
我們在gem5 模擬器中采用了亂序超標量CPU模型,該模型支持單核模式下的分支預測和多線程執(zhí)行.為了更準確地測量緩存/內(nèi)存架構(gòu)設(shè)計下圖應(yīng)用的PC-AMAT 和SC-AMAT,我們參考了WikiChip[17]和丹麥技術(shù)大學[19]最新整理的?ceLake CPU 架構(gòu)及其參數(shù),在gem5 中增加了3 級共享緩存的架構(gòu),并重新進行了緩存參數(shù)配置,以使緩存架構(gòu)及其對應(yīng)的Tag 延時與Data 延時更加接近真實的硬件環(huán)境.對于每個圖應(yīng)用的測量點,我們都根據(jù)4×108個模擬指令收集了圖應(yīng)用的訪問數(shù)據(jù),PC-AMAT 和SCAMAT 的計算及其參數(shù)都來源于對這些訪問數(shù)據(jù)的處理.具體配置情況如表1 所示.
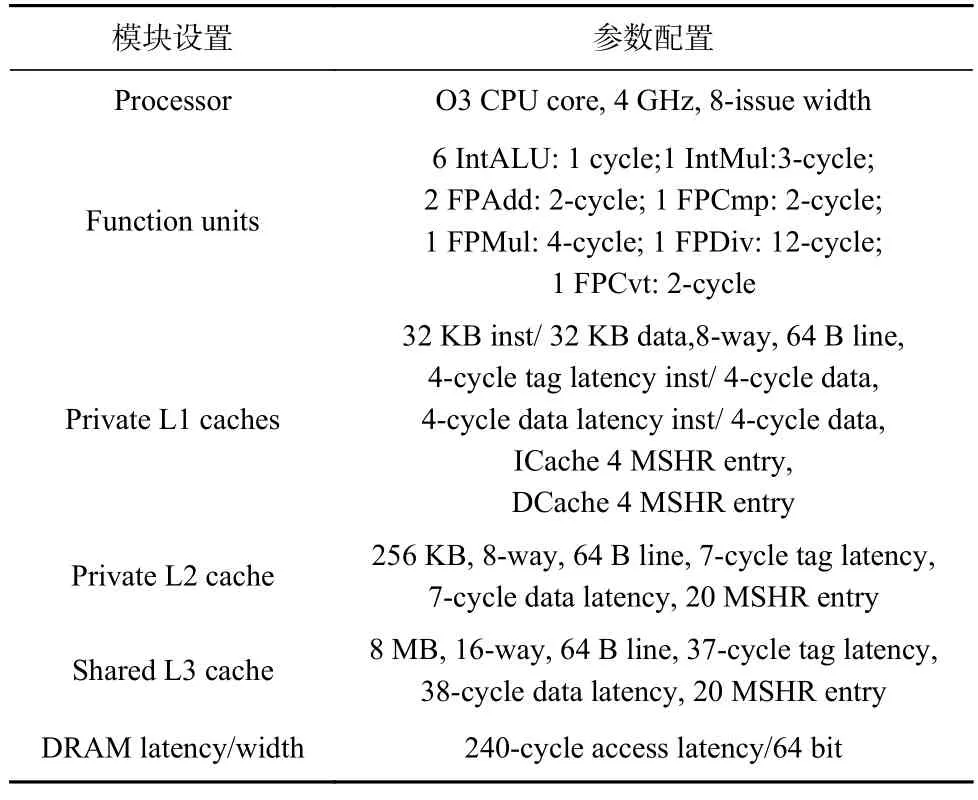
Table 1 Simulator Configuration表1 模擬器配置
4.2 工作負載
本文使用GAP 基準套件[13],它是典型的圖處理基準套件,能夠有效標準化圖應(yīng)用的指標評估.GAP之中的圖算法均使用C++編寫,并使用了優(yōu)化多線程技術(shù),我們之所以選擇GAP 是因為它可以排除任何與框架相關(guān)的性能開銷,從而真正發(fā)現(xiàn)圖應(yīng)用在存儲器中的性能瓶頸.我們選取了其中最具代表性的BFS[20],PR[21],BC[22],CC[23]4 種算法作為工作負載進行測試,具體算法介紹如表2 所示.

Table 2 Graph Algorithm List表2 圖算法列表
表2 中的圖算法分別代表了社交網(wǎng)絡(luò)中心、工程應(yīng)用領(lǐng)域和科學中的諸多應(yīng)用,由于不同的圖算法計算方式是不同的,主要以遍歷為中心和以計算為中心,并且它們對于圖的屬性考慮也各有側(cè)重,因此為了更全面地評估各類圖應(yīng)用的存儲器性能,我們采用的圖數(shù)據(jù)集如表3 所示.

Table 3 Experimental Datasets表3 實驗數(shù)據(jù)集
4.3 負載性能測試
由于存儲器系統(tǒng)的性能對整體性能有很大的影響,因此應(yīng)該選擇一個適當?shù)闹笜藖矸从乘鼈冎g的關(guān)系.我們使用相關(guān)系數(shù)(correlation coefficient)[15]來描述內(nèi)存指標PC-AMAT,SC-AMAT,C-AMAT 與?PC 之間的變化相似度,并作為它們的評價精度.相關(guān)系數(shù)的取值范圍為-1~1.相關(guān)系數(shù)的絕對值越高,代表內(nèi)存指標和?PC 這2 個變量之間的關(guān)系就越密切[25].相關(guān)系數(shù)的數(shù)學定義為:
相關(guān)系數(shù)是通過積差方法進行計算的,通過以2 個變量與各自平均值的離差為基礎(chǔ),將2 個變量的離差相乘來反映2 個變量之間的相關(guān)程度.其中數(shù)組X和Y是2 個變量的采樣點.
我們首先分別計算了當內(nèi)核數(shù)量為1,2,4 時對應(yīng)各級cache 的相關(guān)系數(shù).對于各級cache,這2 種存儲器性能指標的相關(guān)系數(shù),如圖9 所示.圖9(a)顯示了L1 cache 上C-AMAT 與PC-AMAT 的相關(guān)系數(shù)的對比,我們發(fā)現(xiàn)隨著內(nèi)核數(shù)量的增加,C-AMAT 的相關(guān)系數(shù)并未出現(xiàn)明顯變化,PC-AMAT 在相關(guān)系數(shù)上則始終高于C-AMAT,并且內(nèi)核數(shù)量并未明顯影響其相關(guān)系數(shù)變化,之所以出現(xiàn)這樣的原因,是因為L1 cache 中的數(shù)據(jù)訪問命中時間是固定的,內(nèi)核數(shù)量的增加對于總的數(shù)據(jù)訪問周期的測量誤差并沒有表現(xiàn)出比較明顯的影響,但由于PC-AMAT 在數(shù)據(jù)訪問時的命中時間參數(shù)選取更加準確,因此其相關(guān)系數(shù)相比C-AMAT 也更高.圖9(b)(c)分別代表了L2 cache和LLC 上C-AMAT 和SC-AMAT 的相關(guān)系數(shù)對比,隨著內(nèi)核數(shù)量的增加,C-AMAT 的相關(guān)系數(shù)都有小幅度提升,我們分析這是由于內(nèi)核數(shù)量的增加,導致數(shù)據(jù)訪問并發(fā)度也隨之增加,盡管L2 cache 和LLC 上的數(shù)據(jù)訪問命中時間存在不一致性,但并發(fā)度的提升導致數(shù)據(jù)訪問重疊周期也更多,掩蓋了一部分數(shù)據(jù)訪問周期計算過程中的誤差,但其相關(guān)系數(shù)始終與SC-AMAT 有一段距離.
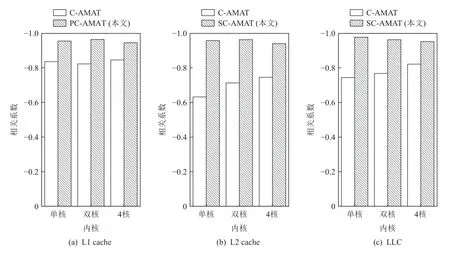
Fig.9 The correlations coefficients of performance indicators in each cache level with different number of cores圖9 各級cache 在不同內(nèi)核數(shù)量中性能指標的相關(guān)系數(shù)
以內(nèi)核數(shù)量為4 時各個圖應(yīng)用中?PC 與C-AMAT,PC-AMAT 和SC-AMAT 的相關(guān)系數(shù)為例,進一步驗證了將C-AMAT 的計算模型擴展為PC-AMAT 和SCAMAT 的有效性與合理性,實驗結(jié)果如圖10 所示.從圖10(a)可以看出,在幾乎所有的圖應(yīng)用中,L1 cache中PC-AMAT 的相關(guān)系數(shù)都高于C-AMAT,相比CAMAT,PC-AMAT 的相關(guān)系數(shù)提升了11.7%.從圖10(b)(c)中我們觀察到,在L2 cache 與LLC 中,SC-AMAT在L2 cache 和LLC 上的相關(guān)系數(shù)分別提升了26.1%和15.8%.
由于PC-AMAT 和SC-AMAT 只是在計算與測量過程中對C-AMAT 進行的擴展,因此在接下來的結(jié)果評估中將不再對PC-AMAT 和SC-AMAT 進行區(qū)分.我們首先將圖應(yīng)用運行在單核模式下,我們計算了各級cache 的C-AMAT 和相關(guān)的內(nèi)存性能參數(shù),整體性能表現(xiàn)如圖11 所示.
由圖11 可以看出,PR 算法的整體內(nèi)存性能表現(xiàn)是優(yōu)于其他算法的,同時對于L1 data cache 來說,各類圖應(yīng)用程序性能表現(xiàn)類似,但值得注意的是,在絕大部分算法中,L2 cache 的C-AMAT 都明顯高于LLC,這個現(xiàn)象直接暴露出了L2 cache 的存在對于圖數(shù)據(jù)訪問而言是負收益的,而導致這種現(xiàn)象的本質(zhì)還是圖計算運行過程中不規(guī)則的細粒度訪存導致CPU的L2 cache 和LLC 的命中率極低[26].
這些圖應(yīng)用負載的命中并發(fā)度和缺失并發(fā)度如圖12 和圖13 所示.命中并發(fā)度與缺失并發(fā)度是影響C-AMAT 的關(guān)鍵因素,可以看出,單核模式下,所有圖應(yīng)用在L2 cache 的命中并發(fā)度表現(xiàn)都是最低的且其值都徘徊在1 附近,這進一步表明了傳統(tǒng)L2 cache 的存在對于圖應(yīng)用并沒有多大意義,甚至影響到了整體的圖應(yīng)用訪存時間,現(xiàn)代處理器中的3 級緩存存儲器層次結(jié)構(gòu)的設(shè)計對于圖應(yīng)用而言負面影響較大.為了提高圖應(yīng)用的命中并發(fā)度,我們可以采用多端口緩存、多bank 緩存來提高命中時間的重疊;同時,為了提高缺失并發(fā)度,我們也可以通過設(shè)置合理的MSHR 數(shù)量來允許更多的缺失訪問相互重疊.
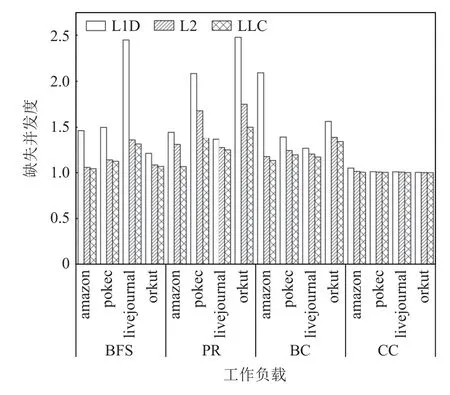
Fig.13 Miss concurrency in each level of cache圖13 各級cache 中的缺失并發(fā)度
這些圖應(yīng)用的純粹平均缺失代價如圖14 所示.與命中并發(fā)度和缺失并發(fā)度類似,各類圖應(yīng)用在在L2 cache 上所表現(xiàn)出來的純粹平均缺失代價都是最高的,這也從側(cè)面反映了L2 cache 中圖數(shù)據(jù)訪問缺失率高,而為了避免這種現(xiàn)象,最簡單的方式就是在L2 cache 上進行旁路策略,可以有效降低總體的圖數(shù)據(jù)訪問時間.
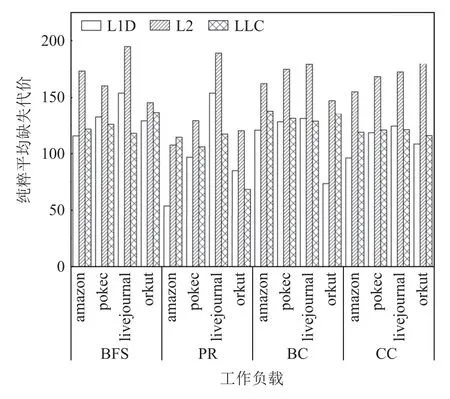
Fig.14 Pure average miss penalty in each level of cache圖14 各級cache 中的純粹平均缺失代價
多發(fā)射流水線技術(shù)是處理器微體系結(jié)構(gòu)設(shè)計的一個重要改進,它允許在同一周期內(nèi)取指、解碼、發(fā)射、執(zhí)行和提交多個指令,大幅度提高了指令集并行度.由于算法數(shù)據(jù)依賴、分支錯誤預測的高額代價、負載數(shù)據(jù)約束,以及一般的功率墻限制,增加發(fā)射帶寬不是一個可行的選擇,所以大多數(shù)商業(yè)處理器在不同的處理階段對每個內(nèi)核采用4~8 大小的帶寬[27].為了探究發(fā)射帶寬對圖應(yīng)用的影響,我們通過設(shè)置不同大小的發(fā)射帶寬,觀察了其對圖數(shù)據(jù)在各級cache中訪存時間的影響.由于L1 data cache 的數(shù)據(jù)訪問時間最能表現(xiàn)圖應(yīng)用的存儲器性能,因此這里我們只統(tǒng)計了不同發(fā)射帶寬下L1 data cache 的C-AMAT,其結(jié)果如圖15 所示.可以看到,當發(fā)射帶寬設(shè)置為4 時,圖應(yīng)用的C-AMAT 相較于其他數(shù)值的發(fā)射帶寬都呈現(xiàn)出下降的趨勢,訪存速度最快.
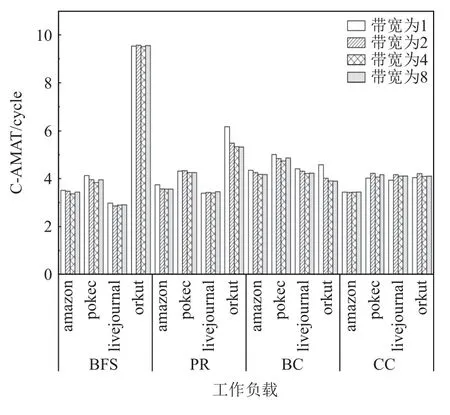
Fig.15 C-AMAT of L1 data cache at different issue widths圖15 不同發(fā)射帶寬下L1 data cache 的C-AMAT
現(xiàn)代處理器中的非阻塞緩存為了在緩存缺失時依然能夠提供數(shù)據(jù),往往采用了失效狀態(tài)保存寄存器MSHR.對于LLC,當其MSHR 表為空時,表示沒有未完成的主存訪問,而當MSHR 表為滿時,則表示緩存無法提供更多的緩存訪問,將阻塞CPU 對內(nèi)存或下一級內(nèi)存的訪問.因此,MSHR 表項的數(shù)量可以直接決定缺失并發(fā)度,進而影響到C-AMAT.我們將LLC 的MSHR 表項的數(shù)量分別設(shè)置為4,8,16,并對圖應(yīng)用的C-AMAT 進行了測量,結(jié)果如圖16 所示.不難發(fā)現(xiàn),當MSHR 表項的數(shù)量設(shè)置為8 時,就已經(jīng)對圖應(yīng)用的數(shù)據(jù)訪問不再產(chǎn)生影響,因此盡管圖數(shù)據(jù)在LLC 上的缺失率很高,但圖應(yīng)用在LLC 數(shù)據(jù)訪問總占比是極低的,尤其是單核模式下,MSHR 表項的數(shù)量的設(shè)置越大對于圖應(yīng)用而言意義不大,對于圖應(yīng)用而言LLC 的MSHR 表項的數(shù)量設(shè)置在4~8 已足夠使用,不必再浪費額外的硬件資源.

Fig.16 C-AMAT of LLC at different sizes of MSHR圖16 不同MSHR 大小下LLC 的C-AMAT
指令集并行技術(shù)帶來的圖應(yīng)用訪存性能的提升仍存在很大的限制,增加每個CPU 內(nèi)核數(shù)量是提高系統(tǒng)總體性能的最直接和最高效的手段.我們將內(nèi)核數(shù)量進行了倍增,將圖應(yīng)用在L1 data cache 的CAMAT 進行了統(tǒng)計分析,實驗結(jié)果如圖17 所示.內(nèi)核數(shù)量的增加明顯降低了圖應(yīng)用的C-AMAT,但并不總是如此,尤其對于PR 算法而言,在其中3 個數(shù)據(jù)集中雙核CPU 下的L1 data cache 的C-AMAT 相對于單核反而出現(xiàn)上升,我們推測產(chǎn)生這種現(xiàn)象是由于圖應(yīng)用中加載指令之間的依賴鏈過短,從而導致了流水線的斷流和低內(nèi)存級并行.但總的來說,多核CPU 在處理圖應(yīng)用過程中所表現(xiàn)的存儲器性能依然是要高于單核CPU 的.
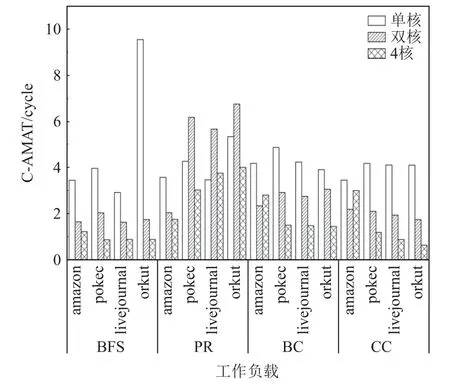
Fig.17 C-AMAT of L1 data dcache at different number of cores圖17 不同內(nèi)核數(shù)量下L1 data cache 的C-AMAT
5 總結(jié)
圖計算應(yīng)用擁有特有的不規(guī)則執(zhí)行行為,其引發(fā)的不規(guī)則負載和不規(guī)則訪問是加速圖應(yīng)用面臨的主要挑戰(zhàn)之一.認識圖應(yīng)用高度復雜的存儲系統(tǒng)的局部性信息和并發(fā)性信息對于加速圖計算架構(gòu)設(shè)計至關(guān)重要.C-AMAT 可以有效表征應(yīng)用程序運行過程中高度復雜的存儲系統(tǒng)的局部性和并發(fā)性的信息,但是其計算模型沒有考慮cache 層的訪問方式,原始測量裝置硬件開銷巨大.因此本文基于不同cache 層的訪問結(jié)構(gòu),對C-AMAT 的計算模型擴展為PCAMAT 和SC-AMAT,并在此基礎(chǔ)上設(shè)計并實現(xiàn)了純粹缺失周期提取算法及各參數(shù)的測量與計算,能夠有效實現(xiàn)C-AMAT 的測量.實驗結(jié)果表明,在單核和多核模式下,PC-AMAT 和SC-AMAT 與?PC 之間的相關(guān)性比C-AMAT 與?PC 的相關(guān)性更強,在4 核模式下,L1 cache 中PC-AMAT 相比C-AMAT 的相關(guān)系數(shù)提升了11.7%,SC-AMAT 在L2 cache 和LLC 上的相關(guān)系數(shù)分別提升了26.1%和15.8%.最終,我們通過更改相關(guān)的硬件配置利用C-AMAT 評估和分析了圖應(yīng)用在存儲器中的訪存性能,并提出了相應(yīng)的訪存優(yōu)化策略.我們的下一步工作將根據(jù)如何提高圖應(yīng)用的命中并發(fā)度和缺失并發(fā)度,以及如何降低圖應(yīng)用的純粹缺失率展開,擬從cache 層面優(yōu)化圖應(yīng)用的存儲器性能.
作者貢獻聲明:陳炳彰提出算法思路和實驗方案,并完成實驗與論文撰寫;劉偉指導方案設(shè)計并修改論文;于蕭鈺協(xié)助論文修改.
猜你喜歡
小學科學(學生版)(2021年5期)2021-07-22 02:40:06
中學生數(shù)理化·八年級物理人教版(2019年9期)2019-11-25 07:33:02
中學生數(shù)理化·八年級物理人教版(2019年3期)2019-04-25 06:20:54
中學生數(shù)理化·八年級物理人教版(2018年3期)2018-05-31 08:52:45
數(shù)學小靈通(1-2年級)(2017年10期)2017-11-08 08:39:45
軍事文摘·科學少年(2017年4期)2017-06-20 23:25:16
軍事文摘·科學少年(2017年2期)2017-04-26 21:58:43
中學生數(shù)理化·八年級物理人教版(2016年3期)2016-04-07 04:49:32
少兒科學周刊·兒童版(2016年1期)2016-03-14 03:52:21
閱讀與作文(小學低年級版)(2015年4期)2015-04-29 00:00:00
