面向機器學習應用的可解釋性需求分析框架
2024-04-29 05:35:48裴忠一王建民
計算機研究與發展 2024年4期
裴忠一 劉 璘 王 晨 王建民
(大數據系統軟件國家工程研究中心(清華大學) 北京 100084)
(清華大學軟件學院 北京 100084)
(peizhyi@tsinghua.edu.cn)
近年來,數據驅動的機器學習技術在多個行業領域得到了成功應用,包括圖像識別、語音識別、交通路況預測、自動駕駛、智能助手、用戶偏好預測和產品推薦等[1].在工業領域,如工業互聯網、工業大數據、工業機器學習等應用也在工業數字化轉型的過程中獲得長足發展.應用需求的持續驅動使智能軟件技術棧不斷發展、演變,形成了數據驅動的智能軟件方法與技術新分支,面向智能軟件需求分析方法的研究與實踐也得到了廣泛關注.一方面,軟件工程背景的系統開發人員習慣于沿用熟悉的開發方法,希望既有開發方式能適用于數據驅動的智能軟件開發;另一方面,機器學習算法開發人員傾向于基于個人經驗選擇開發所需的技術棧,導致智能軟件的開發質量和開發效率難以得到保證.上述原因使得我們在工業以及醫療等領域中運用內嵌機器學習模型的智能應用時,可解釋性和穩定性需求無法被滿足.
國內外相關研究工作聚焦于數據驅動智能系統的需求分析方法和工程應用案例,分別從研究與工程實踐角度,探討現有方法、流程、策略需要的改進,以支持智能軟件的研發效能提升[2].研究主題包括機器學習應用的功能性需求定義、非功能性需求定義、質量評價標準等.其中較為重要的非功能性指標包括機器學習模型的可解釋性[3]、預測分析結果的公平性[4]、數據密集型系統的合規性等,成為智能軟件工程領域的焦點.例如,歐盟委員會于2021 年提出了可信賴人工智能倫理導則[5].
可解釋性是智能軟件開發中重要的主題[6-8],一方面關注理解機器學習模型的工作原理,另一方面著重建立機器學習模型的行為與現有知識體系的關系.目前,對可解釋性的研究多以機器學習技術研究為主,分析機器學習模型與現有知識體系和數據特性的關聯,從需求分析中針對性地提取可解釋性的依據是一項需要系統化研究的任務.本文圍繞“可解釋性需求分析”所面臨的要點問題進行文獻調研,構建方法學框架.在本文中,“可解釋性需求”指對機器學習模型可解釋性的要求和理解機器學習模型的需求要素.“可解釋性需求分析”是對獲取機器學習模型可解釋性需求依據及設計決策依據的過程和方法.
智能軟件需求工程涉及人工智能、領域知識工程、軟件工程、數據科學及科學倫理等多方面的知識、方法和準則.為了彌合不同知識領域之間的語義差距,需要建立跨領域的協作機制,將跨學科方法、經驗和工具整合到可持續迭代的研發過程中,形成規范化、系統化的需求分析,系統設計、驗證與迭代優化方法論.其中,可解釋性貫穿始終,始于需求分析,落實于技術實現,最終反映在應用效果的驗證過程中.
本文采用綜述、歸納與案例分析相結合的研究方法.首先,從機器學習需求工程的文獻調研出發,對文獻的背景、問題與挑戰進行歸納,以及對其中的可解釋性需求的分析與處理加以總結,得到面向機器學習應用的需求工程研究路徑.在此基礎上,提出一種以可解釋性為核心的面向機器學習應用開發的需求工程過程框架,并通過該框架指導數據驅動智能軟件開發中的可解釋性需求分析.
1 可解釋性需求分析的相關工作
用戶對智能應用的可解釋性需要驅動我們在問題上下文、領域知識和機器學習模型間建立顯式的聯系.本文以工業領域應用場景為例,介紹智能應用需求分析的主要步驟和領域知識體系.例如如何通過人類可理解的建模方式來定義業務對象的屬性和相關關系,如狀態機、業務流程圖、自動機、實體關系圖等,以及如何用工業自動化和控制領域的模型來分析實時反應式系統等.在許多科學和工程相結合的領域中,有特定的數學、物理或化學反應過程模型,如機械工程中的力學模型、化工過程中的化學反應和工藝流程、建筑工程中的結構力學模型等.這些模型表示為數學方程、符號系統、因果網絡、結構或動態行為的3 維仿真建模等[9].領域知識的顯式表達是我們進行工業應用場景需求分析的重要基礎,也是對系統設計進行形式化需求驗證的工具[10].
在軟件需求工程中,分析師采用多種需求建模方法指導需求工程師完成需求的獲取,并用來描述與領域知識體系相關的系統結構和行為約束.例如,面向目標的需求建模方法以用戶和設計者的意圖和目標為起點,然后通過目標分解和逐級細化所需系統的成功條件和驗收標準[11].在充分理解目標后,需求工程師采用統一建模語言(UML)和系統建模語言的多種圖形化模型(SysML)[12]等工具,建立形式化、半形式化的業務模型,以此對領域知識體系所涉及的系統結構和行為模型等開展設計工作.跨行業數據挖掘標準流程CR?SP-DM[13]將業務理解、數據理解作為數據驅動開發過程中2 個獨立的步驟.當我們在系統解決方案中引入機器學習技術,尤其是大數據驅動的深度學習技術時,數據理解對于模型可解釋性有重要影響.在需求分析階段,數據模型的定義與可視化分析是獲取可解釋性依據的重要手段.例如,對時序數據的周期性分析、對多個數據特征的相關性分析等.
2 機器學習需求工程研究綜述
我們調研了面向機器學習的需求工程相關文獻163 篇,詳見表1.文獻研究主題包括智能應用軟件開發范式的演化、機器學習應用研發所涉及的干系人角色和關注點、干系人之間的依賴關系和可解釋性需求來源.
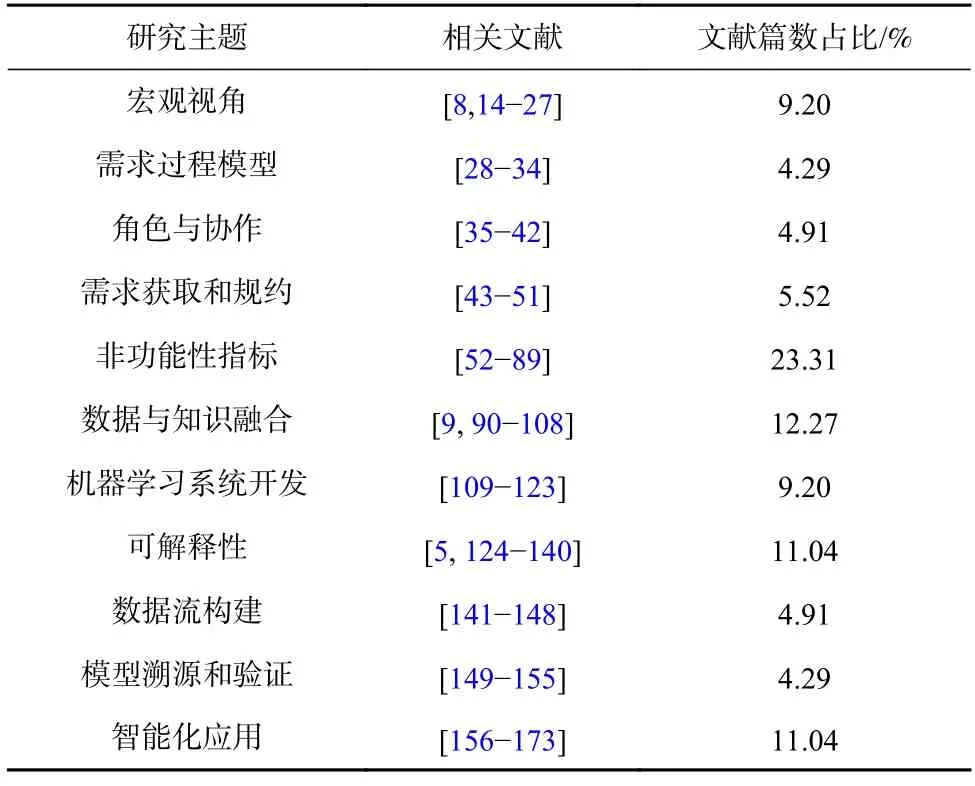
Table 1 Theme Statistics of Research Literature表1 調研文獻的主題統計
2.1 智能應用帶來的軟件開發范式演化
目前,軟件開發與管理的典型范式以敏捷開發過程和開發運維過程DevOps 為代表.作為數據驅動開發范式的早期里程碑,CR?SP-DM 將數據驅動的研發活動組織為6 個階段:業務理解、數據理解、數據準備、建模、評估和部署.CR?SP-DM 提出了一個規范的工作步驟,建立了數據準備、模型設計和評估的需求分析周期,形成了閉環迭代周期.CR?SP-ML(Q)擴展了CR?SP-DM 以支持機器學習應用程序的開發,其特別關注機器學習模型的質量評估,包括魯棒性、可擴展性、可解釋性、模型復雜性和資源需求[28].
Vogelsang 等人[14]嘗試從數據科學家的視角定義機器學習系統的需求工程特征和挑戰.他們指出了開發范式中的主要變化,包括新的機器學習的性能指標和質量要求等,如可解釋性、公平性和法律法規要求.Amershi 等人[15]研究了微軟公司的幾個典型機器學習項目,總結了人工智能(A?)應用的重要挑戰和成功要素,其包括:可持續的端到端通路;數據收集、清洗整理和可訪問性;模型評估、進化和部署等.然后,提出了一個9 階段的過程模型,以解決數據相關的問題,如數據收集、清洗和標記等,以及模型相關的問題,如模型需求、特征工程、模型訓練、模型評估、模型部署和模型監控.其中,從模型評估和模型監控可以向前反饋到最初的步驟,從模型訓練也可以反饋到特征工程,如在表示學習中構建反饋回路.
Nalchigar 等人[29]提出了一種目標驅動的需求建模方法,將典型機器學習目標與任務的匹配過程表示為業務分析的解決方案模式.該方法將業務決策目標映射為幾個不同抽象層次的問題,然后通過將機器學習算法應用于給定的數據集獲得洞察來回答這些問題.Washizaki 等人[110]回顧了機器學習系統的常用架構模式和設計模式,內容涵蓋多個機器學習子任務,例如用于數據存儲的“數據湖模式”、用于數據分析的“原始數據提取模式”“業務邏輯與機器學習工作流的解耦模式”“事件驅動的微服務架構模式”“機器學習模型的版本管理模式”等,是針對機器學習應用程序設計過程中特定問題的可復用的局部解決方案.例如,機器學習應用需要依從特定法律法規、特定領域的物理定律和化學反應等.因此,模型可解釋性、科學倫理、公平性、領域定律的依從性設定與評估已成為機器學習應用需求分析的重點.
有研究者提出將科學知識與端到端機器學習相結合用于工程和環境相關研究,以及將機器學習與仿真相結合的混合建模方法[92].知識與機器學習的整合可以雙向進行,可以使用機器學習增強因果關系不明顯的領域模型,也可以使用物理定律、專家規則和領域知識模型改善特定領域的學習模型[124].該方向也被稱為物理感知機器學習(physical-aware machine learning)[90]或者具有先驗知識的機器學習(informed machine learning)[91].
在軟件開發范式演化涉及到的系列相關研究工作中,我們將調研文獻梳理分為11 個大類,如表1 所示.其中,數量占比超過10%的有4 類,分別是非功能性指標、數據與知識融合、可解釋性、智能化應用.非功能性指標、數據與知識融合這2 個主題中包含大量可解釋性相關的具體研究議題.所以綜合來看,可解釋性是機器學習需求工程中非常重要的議題之一.
2.2 機器學習應用研發的干系人及關注點
Sothilingam 等人[174]對3 個機器學習軟件項目組織進行了基于案例的實證研究,并基于面向主體的i*框架建模分析了機器學習項目團隊組織關系的差異性.一般軟件應用需求分析涉及的主要角色有業務專家、需求分析師/產品經理、軟件研發工程師.需求流程從定義業務問題開始,通過確定軟件使用的范圍來識別利益相關者.需求分析師通過與利益相關者,特別是與業務專家的溝通,在需求獲取和識別之后,進一步建立需求規約.當涉及到機器學習功能的需求時,數據科學家將參與需求分析.同時,領域專家在工業智能應用研發中也發揮著不可替代的作用,因為領域知識對于理解應用場景和業務目標是必不可少的.
我們在表2 中總結了面向機器學習應用的需求工程中不同角色關注的主要問題.表2 中列舉了檢索文獻中提及的多個挑戰.其中,最受關注的需求問題包括可解釋性、可信度、風險評估和穩定性等.這4個問題中有相當一部分源于機器學習模型,尤其是深度學習模型的黑盒形態,再加上機器學習模型的使用中存在一定的不確定性,使得人們在安全攸關的場景中無法完全信賴機器學習模型的推理結果.除上述主要圍繞可解釋性的需求問題以外,業務專家的需求中還會考慮公平性問題,因為機器學習模型可以通過選擇有利于特定群體的訓練數據集而引入偏差.以上這些問題成為人們在科研方向上探索的2 個主要動機:一方面,研究如何突破機器學習技術瓶頸,讓技術本身具備可解釋性、穩定性等特性;另一方面,研究如何建立相對完備的數據驅動智能軟件的需求分析方法論,從需求分析的方法和規范、多角色合作機制、更全面的質量保障過程等出發,將機器學習技術和軟件工程方法與技術相融合.其中第1 個方面的研究以機器學習專家為主,第2 個方面則以軟件工程專家為主.

Table 2 Focus and Challenges of Different Roles表2 不同角色的關注焦點及挑戰
表2 所述的不同角色的關注點存在一些共性,但也存在明顯的差異,這說明每個角色有其獨特的視角,也代表著在工作中要應對不同的挑戰.例如,對于業務專家來說,建立對相關技術的合理預期有非常重要的意義.要為業務目標的設定提供更多依據,避免盲目夸大機器學習技術的作用,引入不必要的技術風險.對于需求工程師,除傳統的業務建模外,更關注隱私[186]、安全[187]、場景[51]和目標演化[179]等問題,并提出了面向機器學習應用的需求建模方法.軟件工程師要應對的挑戰是適應機器學習帶來的軟件組織和運行方式的變化,尤其是模型的使用和維護、數據合規使用的問題.領域專家則關注數據和知識的運用是否恰當.而數據科學家更關注機器學習問題的定義和求解、數據質量等問題.雖然關注重點不同,但問題的解決普遍依賴這些角色間的協同合作.
2.3 干系人依賴關系及可解釋需求
需求工程中有眾多關于如何獲取需求、對需求建模、規范需求、驗證需求的方法、工具和最佳實踐,它們為可解釋性需求的挖掘提供了重要基礎.例如:使用KAOS[187]進行面向目標的功能需求建模和分析,使用NFR[188]對非功能需求進行分析,使用i*[189]對組織結構進行分析,用交互場景來描述用例和系統行為等.這些方法在工業智能應用的需求分析過程中依舊發揮作用.例如,在早期需求分析階段,可以采用Volere 需求分析過程[190]進行業務上下文理解、形成系統設計思想并進行驗證.
雖然每個角色都有自己獨特的關注點和視角,但在可解釋性需求的分析過程中,干系人之間也存在依賴關系.業務專家和領域專家分別承擔著“業務信息挖掘”和“領域信息挖掘”的工作,挖掘結果可作為可解釋性評估的依據和來源.數據科學家產出的算法或者機器學習模型通常是黑盒的,往往會引入可解釋性風險.可解釋性的加強和減弱就體現在上述角色間的協作中,而傳統需求分析方法并沒有充分考慮相關問題.下面列舉在需求工程的多角色協作中關注的4 個焦點問題:
1)干系人共同設定合理的機器學習目標與期望.這個問題涵蓋了非常廣泛的領域和眾多熱點研究主題,其中最受關注的是可解釋人工智能(explainable A?,XA?)[81,191].在這個問題上,需要業務專家、需求工程師、領域專家、數據科學家等角色之間進行有效溝通[3,51].首先是在業務理解階段,需要多個角色共同來設定被業務專家認可的、達成可解釋性的最終目標.同時,需求工程師則會將可解釋性與可信性作為分析和評估候選模型的參照依據,保證可解釋性需求不會引入不可接受的負面影響,例如過高的成本、過低的性能需求等.然后,數據科學家則要負責對候選方案進行數據層面的可解釋性分析,尤其對于黑盒形態的機器學習模型,需要提供符合可解釋性標準的預測結果.最終,解釋的正確性需要領域專家參與研判.
2)運用領域知識提升機器學習模型的可解釋性.領域知識可以是物理規律、邏輯規則或知識圖譜,這些知識都為機器學習模型的可解釋性提供了依據.在需求分析階段,這些依據應該作為更細粒度的需求被提出,進而指導技術路線的決策.將這些約束、規則、關系等用于引導機器學習的特征工程、網絡架構設計、損失函數設計中,可以顯著增強機器學習與領域知識的聯系.但為了解決這個問題,需要業務專家、領域專家和數據科學家之間的密切合作[12,22,104].
3)結合領域特征設計適應機器學習應用的驗證過程.將可解釋性落實到技術路線中以后,就要考慮如何驗證可解釋性被正確地實現.由于軟件系統和機器學習系統之間的架構差異,現有的軟件驗證方法不足以保障機器學習應用的可解釋性需求的驗證.利用領域知識,可以將機器學習模型的驗證過程分為幾個階段,通過模型可視化、自動化測試、領域專家確認、用戶反饋等方式逐步展開驗證,在有效驗證可解釋性的同時降低驗證成本[20,159].
4)設計以數據流為核心的軟件架構,確保機器學習的數據需求被滿足.在數據驅動的機器學習模型開發中,架構設計必須考慮包括數據質量、數據處理、數據隱私等問題.其中,就需要建立對數據的正確認識.數據的可解釋性依據在這一過程中發揮著重要作用.數據從采集到標注,再到訓練和驗證,要經歷一系列加工流程,為處理大數據量需考慮自動化解決方案,但同時也增加了數據個性化特征處理、數據質量保障的難度.數據的不斷變化,也給正確理解數據、使用數據帶來挑戰.這需要軟件工程師和數據科學家協作,在不降低模型效果和可解釋性特點的前提下實現高質量、高效率的數據密集的應用軟件架構[181,192-193].
3 面向機器學習可解釋性的需求分析
基于文獻調研和綜述分析結果,本文歸納總結了2 種有助于機器學習應用需求分析的技術方向,并圍繞其涉及的可解釋性展開討論.
3.1 面向業務目標的機器學習方案映射
數據驅動的智能軟件需求工程需要跨越5 個知識領域:將給定用例映射到相應的機器學習任務,構建模型所需要的數據流,完成機器學習模型的訓練,評估模型以確認滿足業務需求,并將模型部署為軟件服務.此外,解決方案的設計原則被表示為一個上下文模型,模型中定義數據的狀態、動機和技術約束.解決方案模式提供了數據驅動的智能需求或設計決策的多視角綜合的視圖,但在使用中還需要設計一個引導需求工程師按步驟推進的過程指南.該方法提供了機器學習技術的選擇依據:首先,拆解后的具體業務問題可以較為直觀地映射為機器學習問題;其次,在問題分解中考慮機理知識和業務上下文的影響因素,可以將一些可解釋性信息融入到方案選擇中;再進一步,通過分析數據現狀,可以讓數據中蘊含的規律、分布特點等作為可解釋性信息輔助機器學習技術的選擇.
該方案適合業務邏輯較復雜、層次清晰、可拆分為多個具體業務問題的用例,并能夠針對各個業務問題提出明確的輸入和輸出.相反,如果業務邏輯較為簡單,或者難以拆分為輸入和輸出明確的子問題,則不適合采用該方案.但是機器學習應用程序的開發通常障礙重重,失敗的原因不勝枚舉.例如,較差的數據條件、不正確的超參數設置或算法選擇不合理等.因此,需要定義好解決方案的評估標準,包括性能指標、置信度、穩定性、訓練成本等.
圖1 概述了從用例到機器學習算法映射過程中需要考慮的業務規則、機理、數據、算法等問題.其中機理業務上下文背后蘊含了可解釋性的邏輯部分,表現為因果關系、規則約束和生活常識等.而數據現狀中蘊含了可解釋性的數據部分,包括數據的頻域特征、值域范圍以及特征之間的相關性等.上述可解釋性因素都將在選擇解決方案時發揮重要作用.從用例逐步分解到數據驅動的機器學習需求必須考慮邏輯和數據2 方面的多種可解釋性要素的影響,從而提供更多參考依據,使得機器學習模型可以按照預期發揮作用.
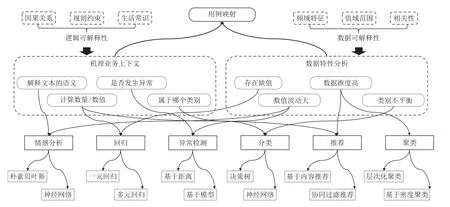
Fig.1 Examples of mapping from use cases to machine learning tasks圖1 從用例到機器學習任務的映射示例
3.2 知識、規則與機器學習模型的融合
在大多數工業應用的開發中,領域知識起著關鍵作用.當談到面向領域的需求工程案例時,領域知識對于需求工程師理解業務上下文和業務目標至關重要.例如,在安全工程領域,有多種用于評估潛在危害事件的方法和工具,如危險和可操作性分析(hazard and operability analysis,HAZOP)[194]、故障模式和影響分析(failure modes and effects analysis,FMEA)[195]、影響和關鍵性分析(effects and criticality analysis,FMECA)[196]、保護層分析(layer of protection analysis,LOPA)[197]、故障樹分析(fault-tree analysis,FTA)[198]和事件樹分析(event tree analysis,ETA)[199]等.這些方法被廣泛應用于化工、制藥和核電安全工程領域的研究與實踐,領域從業者依此構建信息系統來評估和管理潛在的事故風險.近年來,相關的領域分析工具開發商也在對現有功能進行智能化擴展.為構建可用的機器學習應用,機器學習與領域知識的融合必不可少,其中有些依靠領域中的數據特性,而更顯著的結合要依靠領域中的先驗知識.單純的機器學習模型開發過程,僅將數據輸入機器學習數據流,經過調參驗證等生成模型,未在方法論上給特定領域知識留出空間.因此,我們需要新的機器學習模型設計方法,將知識納入機器學習的開發過程中.Von Rueden 等人[91]完成了知識與機器學習融合的綜述,描述了不同的知識表示,如代數方程、邏輯規則和模擬結果如何用于機器學習.該工作提出了4 個集成方向,包括訓練數據生成、假設集定義、學習算法改進和最終假設檢查.該工作描述了30 多種不同知識和機器學習的整合策略.例如,科學知識可以作為深度學習模型損失函數的設計約束.基于圖拉普拉斯矩陣的正則化表示可以約束相關變量在模型預測中的表現.圖2 中給出知識與機器學習融合的可能方式.
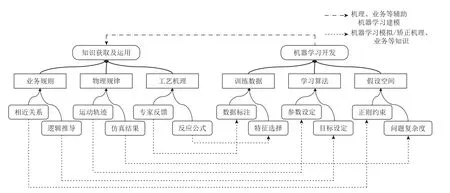
Fig.2 Examples of integration method of knowledge and machine learning圖2 知識與機器學習融合方式舉例
圖2 的方案適用于領域知識有多種表示形式,甚至其形式化程度也不同的場景.例如,數學方程表示足夠具體,因此可以直接用于需求分析和開發.有的機理知識雖然是明確的,但在分析應用需求時,需要業務專家與領域專家綜合考慮業務上下文和機理知識的關聯性.另外,業務規則也是極為常見的知識表達形式,廣泛存在于工業應用中.還有一些特殊形式的知識則以不同的方式發揮著各自的特殊作用.例如,知識圖用于表示因果關系,領域專家的經驗可以用于特征選擇和模型檢驗.同時,領域知識通常是不完備、有缺陷的.對于可靠性及實效性較差的領域知識或復雜多變的業務規則,則不建議與機器學習技術融合運用,以免引入更多不確定性,導致技術方案難以評價和改進.同樣地,可以通過機器學習模擬或者修正領域知識,持續提升對領域的認知,其可以看做通過機器學習技術實現的從數據中挖掘領域知識的方法.對于這種從數據加工得到的領域知識,其可解釋性較弱,在使用時并不能完全等同于原有的領域知識,但可以降低人工數據分析的難度.典型場景如機器學習輔助數據標注,以及機器學習輔助天氣預報等.
但同時知識與機器學習的融合過程需要建立知識、規則、數據間的平衡,通過該平衡降低機器學習技術的風險,加強技術方案的可解釋性.但如何達到高效、適度的平衡需要較多專家經驗,融合方案往往需要具體問題具體分析,尚無普適的經驗,過于偏重知識和規則會限制通用機器學習技術發揮價值.為實現更好的知識融合運用,機器學習技術的發展需要深入應用領域,在應用領域中定義新問題,從而形成面向特定領域的機器學習方法論,建立領域內的知識融合技術.
4 可解釋性需求分析過程框架
本節提出一種可解釋性需求分析過程框架,旨在明確機器學習應用開發中可解釋性需求分析的作用,并對其中涉及的重點問題展開討論.
通過對相關文獻的調研與分析,我們將可解釋性需求工程執行過程歸納為6 個階段及其對應的產出物,分別為業務上下文、技術方案、數據需求、技術指標、風險指標、業務目標等.每個階段通過前后步驟相互銜接,形成基于多主體協作的面向機器學習應用的需求工程分析過程,如圖3 所示.在本節框架中,可解釋性需求被拆分為邏輯、數據2 個方面,在每個方面上要通過需求分析得到相應的可解釋性依據,并用于業務建模、技術路線決策等后續工作.其中,業務上下文中包含了可解釋性需求的邏輯依據,通常體現為在問題描述中加入因果關系、邏輯約束等.在數據需求中包含了可解釋性需求的數據依據,其可能體現為根據機理知識對數據特性提出假設,也可體現為通過實際數據的觀測結果形成的一些數據特性的總結歸納.上述可解釋性依據會用于建立業務建模、增加需求約束條件、引導技術方案的設計等.
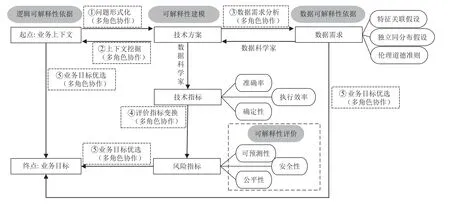
Fig.3 Process framework of collaborative requirements engineering for machine learning圖3 面向機器學習的協作需求工程過程框架
我們對框架中需要多角色協作的步驟做了標注,同時框架中也包含一些由單一角色獨立完成的工作.本文重點關注該框架中需要多角色協作的任務.
4.1 問題形式化
對問題的形式化描述是連接業務專家和數據科學家之間知識鴻溝的橋梁.不同領域的業務問題,通常有慣用的需求表示形式,例如文字描述、流程圖、用例集合、示意圖等.原始需求通常難以準確地轉化為標準的機器學習問題.
例如,在本文的案例中,需求可以簡單地表達為“通過計算機視覺技術識別視頻中的挖掘機完成了多少次裝載操作”.雖然語義上很清楚,但我們并不能找到一個直接解決這個問題的機器學習模型.究其原因包括2 方面:一方面在于實際應用中的業務問題千變萬化,很可能無法在輸入和輸出上適配已知的機器學習標準問題定義;另一方面,很多機器學習標準問題的求解技術尚未成熟,需要盡可能將業務問題轉化為相對成熟的技術可解決的問題.業務問題的形式化,就是一個從“泛泛而談”到“精準定位”的過程,不斷壓縮業務問題的不確定性空間,不斷提升機器學習技術應用的可行性.
業務專家首先提出一個完整的業務問題,盡可能全面地定義業務問題的上下文.數據科學家將試圖從業務問題中抽離出1 個或多個標準的技術問題.典型的技術問題表達形式包括數學方程、邏輯規則和機器學習范式等.一旦技術問題確定下來,數據科學家就可以利用機器學習、數據挖掘等技術設計問題的解決方案.然而,在復雜場景中,問題形式化面臨著諸多挑戰.因為在項目早期,對需求的認知和對領域知識的掌握通常是不完整的,這使得我們很難清楚地識別需求的邊界、技術的約束與局限、定性定量評價指標的選擇等.
4.2 上下文挖掘
一次問題形式化當然不能準確捕捉全部的需求細節,一旦該工作不到位,遺漏影響問題定義的關鍵因素,將很可能導致后續研發工作失敗.這就需要業務專家、領域專家和數據科學家充分溝通協作,在業務上下文中不斷挖掘,為問題形式化提供更多參考依據,包括問題的作用域、領域知識、業務規則、常識、功能目標和細節等.
通過引入機理知識、業務規則、常識等信息,作為需求的邏輯可解釋性依據,可以在更大程度上保證問題定義的完整性,降低問題定義出錯的風險.最終建立從用例到機器學習任務的映射,如圖1 所示,其中邏輯可解釋性依據往往與業務上下文緊密結合,輔助建立業務模型,加深對業務的理解.
該工作并不是單純依靠業務專家和領域專家不斷提供新的信息,更多地是需要數據科學家根據技術問題的不確定性定向地引導上下文的挖掘,才能讓需求分析過程更有針對性.該工作涉及到數據科學與多個其他學科知識的交叉運用,詳見圖2 所示的過程.
4.3 數據需求分析
上下文挖掘幫助我們更好地完成問題形式化,但要進一步選擇合適的機器學習技術解決方案,就必須對數據進行充分的需求分析.實際場景中所具備的數據條件是技術方案可行性的重要評判依據,典型的數據條件包括數據量大小、數據集完備程度、標注質量高低、數據分布假設是否滿足等.業界實踐表明,在機器學習應用研發過程中,約80%的時間用于數據準備過程.上述比例并不包括需求分析所需時間,而這部分時間通常占研發所需時間的10%~20%,但足以說明數據理解和需求分析的嚴謹性和充分性,是避免造成數據處理過程反復,甚至影響模型的效果,帶來的額外研發成本的重要保證.數據可解釋性需求的分析能夠在很大程度上排除對數據的錯誤認識,幫助深入理解數據和正確處理數據.典型數據可解釋性依據是對數據機理特性、統計特性的刻畫.
與上下文挖掘工作類似,數據需求分析也是一個多角色協同的過程.一方面,業務專家負責采集數據、標注數據,領域專家提供與數據相關的領域知識.另一方面,數據科學家要結合數據條件選擇適用的技術方案,并提出待驗證的數據假設.同時,領域專家和業務專家還需要配合數據科學家完成數據假設的驗證.更復雜的情形是,業務專家需要在數據假設中引入業務目標需要關心的倫理假設、公平性假設等.這些數據條件將共同制約技術方案的選擇.其中通過驗證的部分即可作為數據可解釋性依據,為最終成果的可解釋性評價提供支持.
在模型研發中,需要針對上述工作獲得的邏輯可解釋性依據、數據可解釋性依據進行設計,包括引入正則化約束、調整損失函數,甚至可能進一步拆解問題定義,形成由多個機器學習模型級聯組成的復雜解決方案.
4.4 評估指標定性定量轉化
機器學習模型與系統需要滿足的技術指標由數據科學家根據技術方案提出,用以定量化評估方案的性能表現、執行效率等.但技術指標常常不易被用戶理解,換言之,技術指標并不直接表達需求方關心的業務目標.同時,在缺少可解釋性依據的情況下,評估指標的可解釋性也無從談起,大大影響模型適應能力和用戶認可度.所以,從技術指標向用戶可以理解的風險指標進行轉化,從定量或者定性的角度呼應需求分析中得到的邏輯可解釋性依據和數據可解釋性依據,在生產實踐中具有重要意義.基于可解釋性依據定義評估指標,將為軟件帶來更大的可靠性,幫助最終用戶加深對需求內涵和應用效果的理解.
指標的轉換需要數據科學家和需求工程師雙向溝通合作.一方面,數據科學家從技術視角提供相關的標準技術指標,并根據需求工程師的建議加以補充和調整.另一方面,需求工程師從業務視角提出用戶期待的風險指標,并在數據科學家的幫助下建立風險指標和技術指標的關聯,進一步提出需要補充或調整的評估內容.尤其針對需求分析中的可解釋性依據的部分,應盡可能設立對應的評估指標,以全面地考量技術方案的可靠性.
4.5 業務目標優選
在需求工程師的主導下,根據4.1~4.4 節工作的結果得到最終業務目標.該工作的復雜程度取決于協同4.3 節工作中的需求分析結果,形成協調一致的、恰當的、滿足業務要求的完整需求定義.在這個過程中,既要根據業務需要調整風險指標及其驗證標準,又要根據技術的成熟度和作用域調整業務目標的預期范圍,在保持技術方案與業務需求一致的同時,合理評估技術現狀,以保證方案具有足夠高的可行性.其中的典型問題包括:“哪些業務目標不在機器學習范圍內”“風險指標支撐了哪些業務目標”“業務目標的數據條件有哪些”等.該工作由需求工程師主導,但仍需業務專家、領域專家、數據科學家、軟件工程師密切配合,使得相關角色明晰各自職責,建立互相支撐的協作關系,統一各方的工作目標.
4.6 可解釋性關注點
可解釋性需求分析過程框架可指導各個角色明確機器學習應用的需求分析中與可解釋性相關的工作.如表3 所示,框架涉及業務專家、領域專家、數據科學家之間的協作,但考慮到應用開發者和最終用戶在可解釋性上的重要作用,將這2 個角色一起列入表3 中.我們以工業、氣象領域的機器學習應用為參考,總結歸納出各個角色關注的邏輯可解釋性依據、數據可解釋依據,以及在可解釋性建模及評價上通常會關注的問題.其中,邏輯可解釋性依據、數據可解釋依據給建模階段提供了重要的參考,也可以作為可解釋性的評價要素.由此可見,可解釋性并不是單純的機器學習技術問題,而是涉及了業務規則、領域知識、數據特性、機器學習技術、應用開發等多個方面的需求分析對象.通過在需求分析中引入可解釋性需求要素,可以增強各個角色對智能軟件需求內容的理解,保障需求分析結果的完整性、可靠性.

Table 3 Interpretability Related Steps of Each Role’s Participation表3 各個角色參與的可解釋性相關步驟
4.7 框架各步驟產出的內容
我們進一步詳細列舉圖3 框架主要步驟的產出內容,并就產出內容的合規性提出若干要求,如表4所示.從表4 中可以看出,本文所提出的需求分析過程框架遵循機器學習軟件開發的基本過程,同時將邏輯可解釋性要素、數據可解釋性要素融入到需求分析的步驟中.其中,明確將可解釋性作為需求分析中的核心要素,以及作為需求分析的產出,并在最終的評價指標中要求以可解釋性依據作為必要的評價手段,為機器學習需求分析提供了可操作的參考依據.

Table 4 Output Content of Each Step of the Demand Analysis Framework表4 需求分析框架各步驟的產出內容
5 面向機器學習應用需求的相關問題
面向機器學習應用的需求分析在不同的項目上下文環境中回答不同的重點問題.根據分析角色和視角的不同,需要獲取和分析的需求是不同的.數據科學家的主要目標是為給定任務準備合適的算法和模型,設計一個能夠適應場景的解決方案,并圍繞這一目標挖掘可解釋性依據.而需求工程師更關注整體需求與業務目標的一致性,以及可行性、可靠性等問題.領域專家則更傾向于找到更準確的領域知識表達形式,積累可復用的領域知識和經驗,以及挖掘更嚴格的可解釋性驗證手段.上述不同角色所面對的問題中,仍然有很多場景沒有被充分討論,還潛藏一些重要問題需要研究者們展開更深入的研究.當然,很多項目中,上述角色可由一人擔當或多人同時擔任.下面列舉3 個典型的多角色協同解決的需求分析難題:
1)需求模型如何適應場景動態變化,建立可持續的機器學習范式.因為實際生產活動處于動態變化的場景中,數據現狀會發生變化,甚至機理知識和業務規則也會發生演化.這將影響可解釋性依據的可靠性.在這種情況下,各個角色的協作需要考慮更多因素,尤其是環境變化帶來的不確定性因素.
2)如何有效地對項目進行可靠的成本估算.在傳統的軟件開發中,成本估算是必不可少的.然而,機器學習技術給這項工作帶來了很多挑戰.意外引入的成本可能來自過程中的任何步驟,包括數據收集、訓練、模型部署和服務,以及模型的頻繁更新等.在成本估算中,可解釋性依據由于其對技術選型的支撐作用,能夠有效幫助降低技術成本的評估難度.
3)如何實現基于仿真原型的設計以提高方案設計效率.仿真模擬是分析復雜場景的重要手段,有助于完成可解釋性依據的驗證,進一步提高機器學習方案的設計效率.在游戲、仿真實驗等領域的推動下,物理引擎技術已經較為成熟.但面對復雜的工業場景,在涉及化學、機械等一系列學科交叉的應用需求中,仿真技術面臨著巨大挑戰.
6 案例研究
結合前面綜述研究和歸納的結果,尤其是表2 和表3 的框架,我們對一個基于視覺信息的挖掘機監控應用進行回顧性分析.在這個案例中,我們需要開發一個基于智能設備的自動化工作量計數解決方案,以取代挖掘機現場的人工監督.主要任務是統計挖掘機操作員的工作量,將一斗物料從地面拾起并裝入卡車,即為1 次挖掘裝載動作,如圖4 所示.對于挖掘機租賃公司來說,跟蹤每臺租賃挖掘機的工作量非常重要,在過去幾年中,這項任務帶來了高昂的人工成本,亟需自動化解決方案.我們將在該案例中說明如何利用可解釋性需求分析手段挖掘邏輯和數據2 方面的可解釋性依據,以構建更具魯棒性的技術路線.

Fig.4 ?ntelligent monitoring case of construction equipment based on vision圖4 基于視覺的施工設備智能監控案例
問題需求描述和上下文挖掘考慮到機器學習在計算機視覺任務中的出色性能表現,我們嘗試通過分析安裝在挖掘機擋風前攝像頭所采集的圖像來分析挖斗動作.挖斗的操作按照視頻幀的順序記錄下來,從中可以自動識別出挖斗和卡車,并完成計數.但挖掘機的工作過程不穩定,涉及到多種動作組合的可能性和異常情況,導致機器學習模型的運用存在較高的魯棒性風險.這就需要通過可解釋性需求分析手段,挖掘更多的可解釋性依據,以加強技術路線的可解釋性,降低魯棒性風險.
在此案例中,我們從業務上下文中挖掘出挖斗的變化規律作為可解釋性依據.在施工過程中,挖斗會在有限的幾種狀態之間按一定的順序進行切換.為了建立這一可解釋性依據與問題定義之間的聯系,以狀態圖作為可解釋性依據的形式化方法挖掘過程的業務邏輯,定義業務狀態;以挖斗和卡車的識別作為觸發狀態變化的事件輔助機器學習模型的使用.
如圖5 所示,我們將挖掘機的工作過程分為7 個狀態,分別為“挖掘中”“運送中”“裝車預備”“卸貨”“正在裝車”“卸貨完畢”“裝車完畢”等.狀態轉移事件則是依靠機器學習模型檢測的具體事件,如“發現豎斗”“發現平斗”“發現卡車”“卡車離開”等.挖掘機在工作過程中,會在機器學習模型的幫助下,按照既定的狀態轉移關系在上述狀態之間切換.
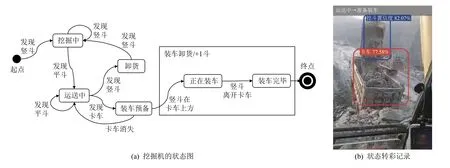
Fig.5 The state diagram is used as an interpretable basis圖5 以狀態圖作為可解釋性依據
上述工作中,我們定義了機器學習的標準問題,明確了機器學習模型的作用域,并基于機器學習模型構建了上層的業務邏輯實現方案.可解釋性需求被提煉為2 個具體內容:圖像中的可識別狀態的語義表示和描述業務推理過程的狀態圖.
我們通過狀態機模型,將業務理解和技術路線更緊密地聯系在一起.一方面通過可解釋性依據建立業務模型,可以更準確地表達業務的可解釋性需求,排除掉原有需求描述中不符合可解釋性的矛盾點,加強需求的邏輯性和可解釋性的邏輯依據;另一方面可以在更細的粒度上比較需求與技術是否匹配,通過持續跟蹤當前的業務狀態對機器學習模型的運行加以調試,及時發現機器學習模型的誤判帶來的業務狀態偏差.
同時,這種基于可解釋性的需求建模可以顯著增強技術方案的魯棒性.由于在每個業務狀態下,機器學習模型僅考慮該業務狀態可能發生的幾種狀態轉移事件,而不是所有事件,從而降低了誤判的可能性,提升模型預測結果的魯棒性.需求分析的具體步驟如下.
1)數據需求分析.數據驅動的機器學習應用研發中,數據的理解、數據可獲得性及質量的分析是重要的步驟.本文案例中的圖像數據是通過固定在機械臂上的數字攝像機收集的.由于采用有監督學習方法,數據需求分析的挑戰之一是定義訓練數據的標注規則.不同人對圖像數據中挖斗的標注有不同的理解.例如,有人將挖斗整體和突出物料全部放入標注框內,也有人更傾向標注挖斗的主體部分.人工標注的差異可能會忽略重要的細節,也可能引入干擾信息,嚴重影響機器學習模型的訓練效果.因此,需要約束數據打標質量,建立符合業務目標的標注要求的可解釋性依據,為機器學習模型訓練提供可信的數據基礎.例如,案例業務目標的實現關注挖斗的姿態而非挖斗中的物料,所以打標工作中應該忽視物料,但突出挖斗尖端鋸齒的位置.通過在數據打標中引入這種可解釋性需求的約束,可以使得技術層面所需考慮的問題更加準確,減少“模糊地帶”引入的需求與技術認知不一致.
另一個常見的數據需求是樣本在數據類間分布的均衡性.樣本數較少的目標識別準確性不高.本案例中,挖斗數據樣本量相對大,但卡車數據樣本量相對少,導致卡車的識別準確率偏低.類別不平衡也是一項常見的數據可解釋性依據,通過在需求中補充這種可解釋性依據,可以幫助技術人員更好地理解需求細節,減少錯誤假設帶來的技術與需求的偏差.數據的多樣性和圖像的清晰度是圖像數據的重要需求維度.這項工作由業務專家、需求工程師、數據科學家承擔,有些場景中也需要領域專家的指導.
對于成熟的機器學習技術,如應用場景是較為固定的,則數據需求通常比較明確.但現實世界的開放性和復雜性導致我們通常只能應對部分典型場景,許多特殊長尾場景無法在早期的訓練數據中獲得.當面對新出現的場景時,模型的表現不夠好,影響用戶對機器學習技術的信任度,但背后的根本原因是需求發生了變化,需求中的問題范圍超出了技術路線做出的假設.可見,可解釋性需求,尤其是數據的理解與可解釋性,是一個持續提升的認知過程,詳見表3和表4 中關于數據需求的分析和可解釋性.在應用驗證中,需要將需求分析階段較為確定的可解釋性依據作為驗證手段和前提,對于超出原有目標場景的情況,要讓用戶知悉其不在評價范圍內.此外,數據處理和數據質量改進所需的投入也是至關重要的.數據可用性、真實世界情況的復雜性和機器學習模型的通用性都可能會限制基于機器學習解決方案的表現.
2)評價指標變換.本案例中,在比較檢測挖斗和卡車的多種候選機器學習算法時,一個關鍵的量化評估指標是物體檢測算法的聯合交集(intersection over union,?oU)指標.然而,該指標并非反映應用效果的“工作量計數準確率”.用戶需要真陽性率和假陽性率等指標.模型的技術規范和業務最終目標的差異給技術方案的綜合評價帶來了挑戰.本案例中,每種狀態的誤判率是用戶關注的評價指標,也是用戶可理解的反映技術方案優劣的指標,同時在技術上也具有可實現性.在可解釋性需求的基礎上對技術指標進行評價,可以增強技術評價與原始需求的關聯性,增加用戶對技術方案的認可度.
3)業務目標定義.考慮到現實應用場景的變化性需求,在設定業務目標時,我們應該以訓練集來約束機器學習模型的使用場景,盡可能降低未知場景帶來的潛在風險.在訓練集已經出現的場景中,同時采用真陽性率和假陽性率作為評判指標,并支持通過跟蹤挖斗的狀態變化調試模型預測錯誤.此外,應保留物體檢測和計數記錄,以備隨機的人工檢查.經過訓練和驗證的模型在部署后仍然可能失敗,因為在現實世界的應用程序中經常會發生數據轉移,例如光線影響、天氣影響、角度影響等.為了保持滿意的計數效果,需要持續補充訓練數據,增加數據的豐富程度.
7 結論與未來工作
在機器學習應用的需求工程中,數據描述、性能指標、數據質量和候選解決方案必須圍繞業務場景和技術可行性統一考慮,其中可解釋性在多個環節起重要作用.為應對復雜的決策與預測分析任務,任何一個步驟的缺失都可能導致整個項目的失敗.
本文從機器學習應用的需求工程中涉及的不同角色和視角進行了綜述和分析.重點分析了業務專家、軟件需求工程師、軟件研發工程師、領域專家和數據科學家之間的依賴關系和協作任務,包括領域知識和機器學習模型的集成,以及如何按預期使用機器學習模型等,著重闡述了可解釋性相關的問題.進一步總結了可用于支持需求活動的工具,例如從業務用例到機器學習任務的映射,以及融合先驗知識和機器學習工作流的參考模式,還給出了數據驅動智能應用的案例.
未來研究工作主要是在工業領域,面向數據驅動的智能應用項目開展工程實踐,基于成功和失敗案例,對目前的方法框架開展廣泛的實證研究;總結需求階段要解決的關鍵問題,包括可解釋性依據的構造方法、驗證方法,并開展更深入的案例分析和共性問題研究;進一步完善和評估可解釋型需求分析的過程和知識框架體系,并形成具有實際指導意義的方法指南,用于指導項目的需求定義和備選方案進行有效的協同決策.
作者貢獻聲明:裴忠一和劉璘為本文共同第一作者.裴忠一完成了主要調研工作和論文撰寫;劉璘提出調研思路并完成了部分調研工作和論文撰寫;王晨參與文獻整理和案例分析;王建民提出指導意見并修改論文.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
電子制作(2018年18期)2018-11-14 01:48:24
山東工業技術(2016年15期)2016-12-01 05:31:22
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
中國中醫藥現代遠程教育(2014年11期)2014-08-08 13:23:44
終身教育研究(2014年5期)2014-02-28 01:23:06
