基于無人駕駛配送實驗平臺的封閉園區內動態環境視覺SLAM研究
2024-05-10 02:57:50薄孟德
長春師范大學學報 2024年4期
薄孟德
(哈爾濱師范大學地理科學學院,黑龍江 哈爾濱 150025)
0 引言
SLAM(Simultaneous Localization And Mapping),即同時定位與建圖,是指主體搭載特定傳感器,在無環境先驗信息的前提下,于運動過程中建立環境模型并估計自身運動狀態[1]。在虛擬現實、自動駕駛和機器人技術等多個領域內,SLAM技術扮演了一個關鍵的角色。過去幾十年間,眾多研究人員不斷推進技術創新,提出了諸如LSD_SLAM,ORB_SLAM等卓越的算法。盡管許多視覺SLAM算法的性能十分優越,但大部分算法都基于靜態環境假設[2]。然而,靜態環境并不能完全反映現實使用情況,現實環境往往是動態變化的。在這些動態場景下,這些SLAM算法可能會面臨定位不精確和地圖構建存在誤差的問題。因此,優化SLAM系統在動態環境中的精準性和穩定性已成為研究的焦點。本研究提出的算法是,使用HRNet網絡提取人體關鍵點,從而進行人體姿態估計,通過分析連續30幀圖像來識別人體的實際行為狀態,從而更有效地去除動態特征點,并在TUM數據集的動態序列上驗證該算法的性能。
1 系統框架
ORB_SLAM2是一種為單目、雙目和深度攝像頭設計的高效SLAM系統,包含地圖重建、閉環檢測和重定位功能。此系統基于PTAM算法架構,采用了ORB特征來增強視角的不變性。ORB_SLAM2通過三個并行的主要線程實現功能:第一個線程利用局部地圖的匹配特征和運動BA重投影誤差最小化技術進行相機跟蹤;第二個線程負責管理和優化局部地圖,執行局部BA;第三個線程進行閉環檢測,以識別大范圍的循環并通過位姿圖優化來修正累積誤差。在位姿圖優化完成后,啟動第四個線程進行全局BA,以精確調整結構和運動參數。ORB_SLAM2作為一種基于特征的方法,對輸入進行預處理以提取顯著關鍵點位置的特征,并且所有系統操作都基于這些特征[3]。本研究提出的動態視覺SLAM以該系統為基礎進行改進,完整流程如圖1所示。首先,系統在接收到視覺相機捕獲的圖像之后,利用HRNet從場景中提取出人體的關鍵點。然后,采用ST-GCN分析連續30幀圖像,從而識別場景中人的行為模式,判斷他們是否在移動。基于這個分析,可以有效地區分哪些動態特征點應該被剔除。最后,僅將剩余的靜態特征點送入ORB_SLAM2的后續處理流程,以進行進一步的優化和地圖構建。
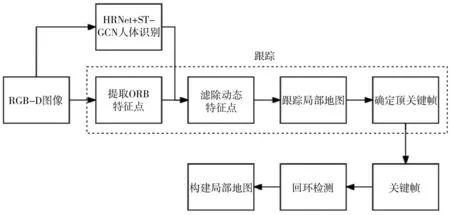
圖1 系統框架圖
1.1 基于HRNet的姿態估計
目前,大多數動態SLAM解決方案主要分為兩類:一類是依賴于相機自身運動模型來處理動態環境下的視覺SLAM;另一類則不需要基于相機的運動模型,同樣能夠應對動態環境下的視覺SLAM。而在基于前者的這一類解決方案中,都需先計算相機運動狀態再判斷動態區域,而在計算相機運動狀態這一過程中則需要濾除動態區域的靜態路標點,存在著“是雞生蛋,還是蛋生雞”問題[4]。因此,本研究采用深度學習方法來判斷封閉園區內動態目標的運動狀態。通過深度學習的方法可以直接針對動態目標進行濾除,但不論是目標檢測任務,還是分割類任務,都是通過對先驗信息提前訓練后得到的結果。此類任務只能判斷出目標是否處于真實的運動狀態,無法對目標的真實運動狀態進行合理的判斷。例如,場景中同時存在站立的人與運動的人,目標檢測類任務與分割類任務無法完成對場景中人的真實運動狀態的判斷。
本研究選擇通過行為識別任務完成對運動主體多為人的封閉園區的運動狀態的判斷,人體行為識別這類任務中,因為需要對人體關鍵點進行提取從而構建骨架,所以需要高分辨率的heatmap進行關鍵點檢測。這與一般的網絡結構要求不同,比如VGGNet,其最終得到的feature map分辨率較低,一定程度上損失了空間結構。為獲取高分辨率feature map,大部分網絡選擇先降分辨率,然后再提高分辨率的方法,如U-Net,SegNet,Hourglass等。而在HRNet中,在不同分辨率的feature map間采用了類似“并聯”的結構,并在此基礎上在feature map間進行了交互。這種做法保證了在整個網絡結構中高分辨率的表征都得以保持,并且以交互的形式提高了模型的性能。本研究在參數和計算量不增加的前提下使用COCO數據集中驗證集部分對HRNet與其他同類網絡人體關鍵點提取精度進行對比測試,結果顯示,HRNet對人體關鍵點提取精度效果更加優秀。綜合考慮,本研究使用HRNet進行人體關鍵點提取,使用ST-GCN進行人體行為識別。
1.2 基于姿態估計的行為識別
在2D或3D坐標下,動態骨骼模態可以通過人體關節位置的時間順序表示,通過分析運動模式則可以做到行為識別。早期的動作識別技術主要通過在不同時間點捕捉關節位置,形成特征向量進行時序上的分析。但這種方法沒有利用人體關節之間的空間關系。雖然有學者嘗試利用關節間自然連接的方法進行行為識別,但大多數方法依賴手動設定規則來分析空間模式。因此模型泛用性較差,難以完成特定應用外的任務。ST-GCN是在骨骼圖序列上指定的,其中每個節點對應一個關節。圖中存在著符合關節的自然連接的空間邊和在連續時間步驟中連接相同關節的時間邊。在此基礎上構建多層的時空圖卷積,它使信息沿著空間和時間兩個維度進行整合。ST-GCN的層次性消除了手動劃分部分或遍歷規則的需要,這增強了模型的表達能力并且提高了模型性能,本研究使用ST-GCN對場景中人物進行行為識別。
本研究使用NTU-RGB+D數據集進行訓練,數據集由微軟Kinect v2傳感器采集,使用三個不同角度的攝像機采集數據深度信息、3D骨骼信息、RGB幀以及紅外序列,包括60個種類的動作,共56 880個樣本,其中包含日常行為動作40類,雙人互動動作11類,健康相關動作9類[5]。這些幾乎包括了封閉環境下所有常見的人體行為。本研究使用HRNet進行關鍵點提取后,利用ST-GCN進行人體行為識別,在HTU-RGB+D數據集上的cross-subject(X-Sub)與cross-view(X-View)兩個基準測試中準確性分別達到了85.3%與89.8%。
2 測試與分析
本研究通過TUM數據集的多個序列進行實驗分析。實驗首先通過行為識別算法測試其對動態對象的識別能力,并移除對象區域內的動態特征點,以展示該算法的有效性;其次評估所提算法在軌跡偏差精確度方面的表現;最后評估該算法的處理速度。
TUM RGB-D數據集由慕尼黑工業大學(Technical University of Munich,TUM)的計算機視覺團隊提供,其中包含RGB(彩色)圖像和深度圖像等39個序列,圖像采集分辨率為640×480像素,頻率為30 Hz[6]。數據集通常用于訓練和評估計算機視覺算法,例如目標檢測、物體識別、三維重建和SLAM等任務。本研究選用walking_xyz、walking_static、walking_half、sitting_static四個序列作為實驗序列,其中因為拍攝時傳感器的移動方式不同,使得walking_xyz、walking_static和walking_half序列呈現高度的動態性,由于sitting_static序列主要捕捉兩個人坐在桌子前時手部的動態變化,因此sitting_static序列顯示較低的動態性。文獻[7-8]中關于動態場景下的視覺SLAM研究基本都建立在ORB_SLAM2的基礎框架之上。同時,ORB_SLAM2算法已經被廣泛應用,并且其內部參數經過了充分的優化。為了確保實驗的一致性和有效性,本研究在使用ORB_SLAM2框架時,參數設置保持不變,使用了該算法的默認參數。
本研究采用相對位姿誤差(Relative Pose Error,RPE)和絕對軌跡誤差(Absolute Trajectory Error,ATE)對SLAM系統的定位精度進行評估。RPE衡量特定時間段內估計運動與實際運動的姿態差異,而ATE通過對比估計和真實軌跡的絕對差距,以評價系統的全局定位一致性。
RPE同時評估了平移和旋轉誤差,而ATE僅衡量平移誤差。設時間步長為i,時間間隔為t,定義相對位姿誤差如下:
其中,Qi為第i幀的真實位姿,Pi為第i幀的估計位姿。
定義絕對位姿誤差為:
其中,S為估計位姿到真實位姿的轉換矩陣。
2.1 實驗平臺
本研究使用封閉園區內的無人駕駛配送實驗平臺(圖2)對所提算法進行測試。實驗平臺使用Apollo自動駕駛系統,該系統是國內應用廣泛的自動駕駛開源系統。平臺搭載輪式里程計、IMU、激光雷達、RGB-D攝像頭等多種傳感器。選用此平臺對本研究所提算法進行實地驗證,圖3為本研究所提算法使用實驗平臺在封閉園區內的應用。本研究中的算法測試環境配置包括:顯卡為NVIDIA RTX 3060,處理器為i7-10750H,操作系統為Ubuntu 18.04,使用了CUDA 11.0和Pytorch 1.8.0。

圖2 無人配送實驗平臺

圖3 本研究算法使用實驗平臺在封閉園區內的應用
2.2 效果對比
在TUM數據集的walking_xyz序列中選擇一組圖像進行比較,圖4(a)展示了ORB_SLAM2在該場景下捕獲的特征點,而圖4(b)展現了本研究算法捕獲的特征點。結果顯示,本研究所提出的算法能夠有效地識別兩個人的動作,并且能夠排除包含在人物上的動態特征點,僅保留靜態特征點。

圖4 動態特征點濾除效果
2.3 精度對比
實驗對比了walking_xyz、walking_static、walking_half、sitting_static四種序列的精度,采用ATE和RPE進行量化評估,并提供了均方根誤差(RMSE)和標準差(SD)兩種度量指標。使用如下公式描述精度的增強程度:
其中,α為ORB_SLAM2的運行結果,β為本文所提算法的運行結果。
表1至表3展示了ORB_SLAM2與本研究提出算法在walking_xyz、walking_static、walking_half、 sitting_static序列中的性能對比及精度改進情況。結果表明,在活動強度較高的序列中,本研究的算法明顯優于ORB_SLAM2,在各項指標上都有所提高。對于活動強度較低的序列,改進不太顯著,這主要是由于動態變化不明顯,而ORB_SLAM2能夠利用其噪聲消除算法較好地處理這些低動態環境。因此,在低動態場景中,本研究算法的性能改進并不突出。與DS_SLAM的比較結果見表4,DS_SLAM的相關性能數據可以在文獻[9]中找到。從表中可以看出,本研究算法在各個序列中均可達到與DS_SLAM類似的精度水平。
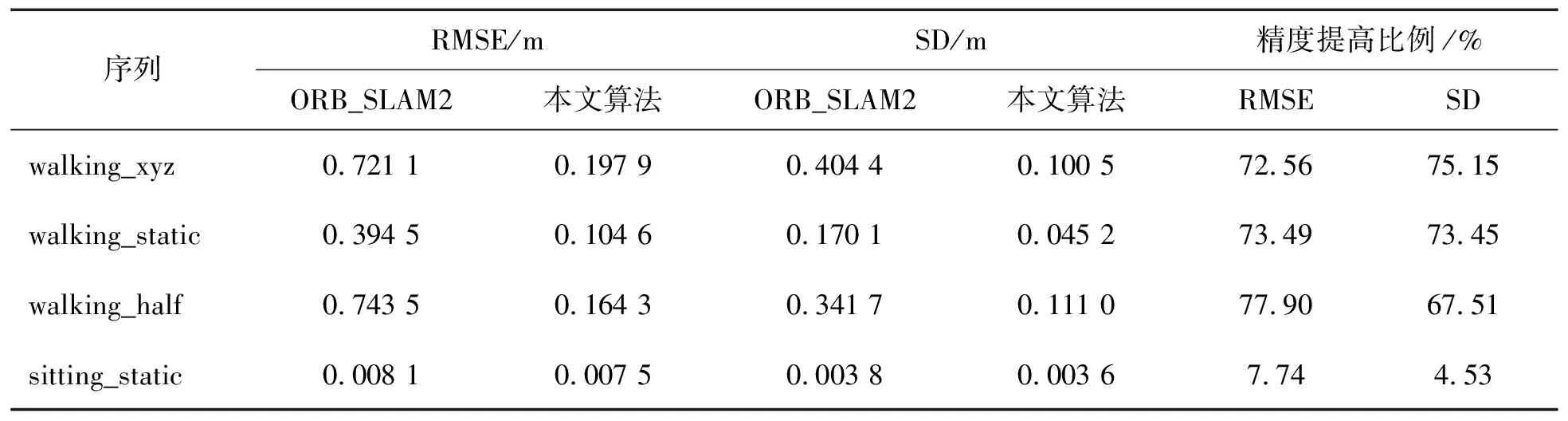
表1 ATE對比
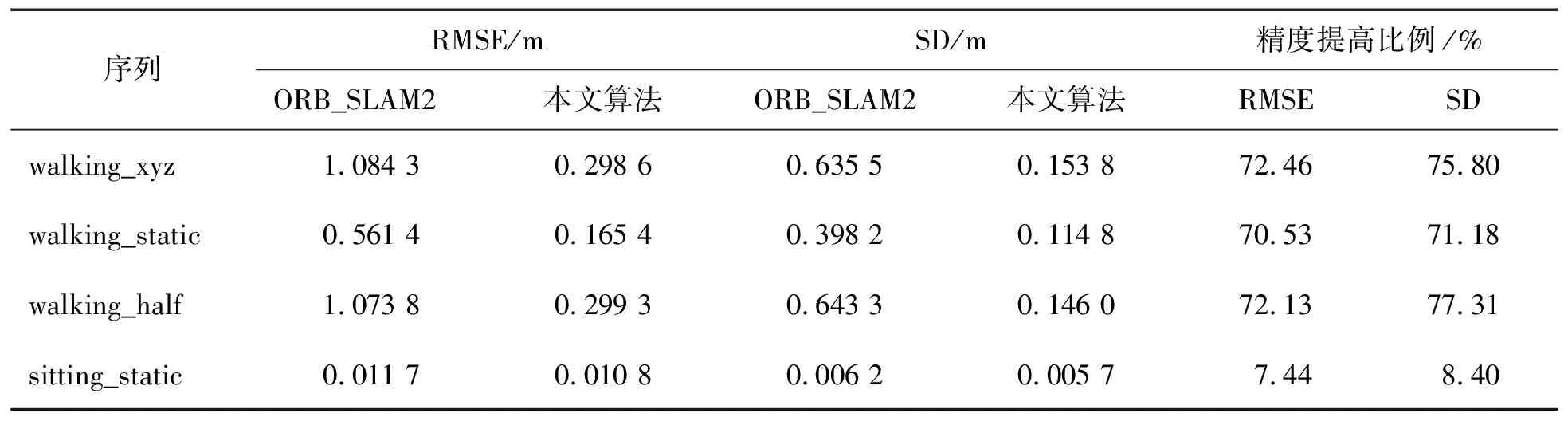
表2 RPE平移誤差對比
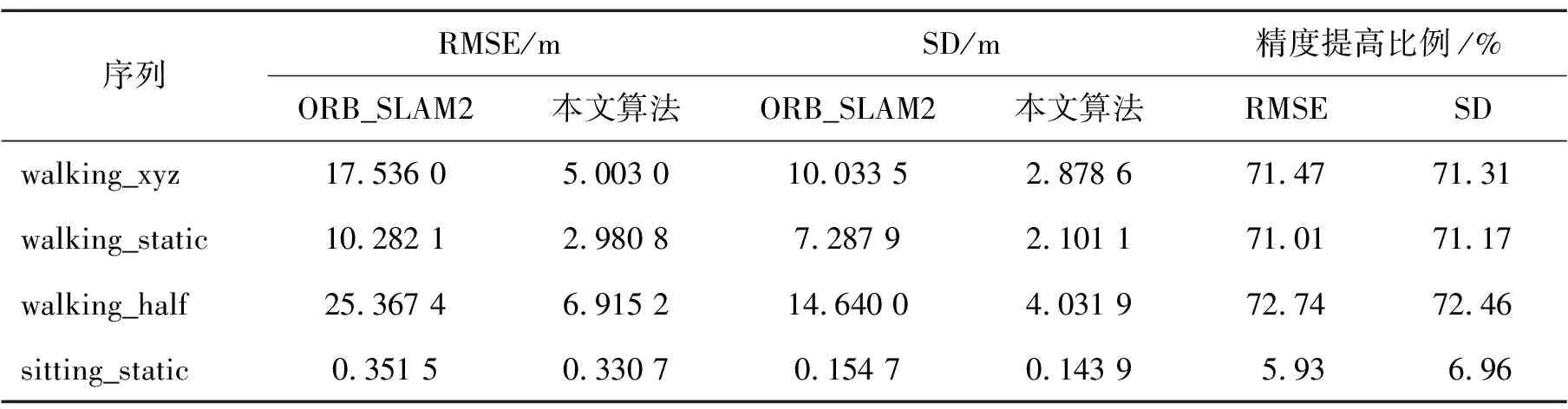
表3 RPE旋轉誤差對比
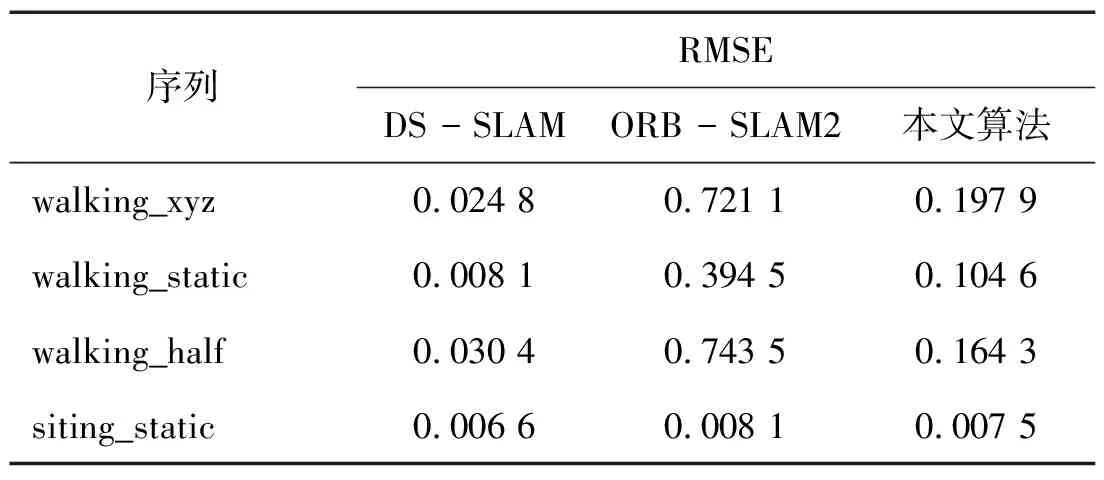
表4 動態環境下的SLAM算法RMSE對比
2.4 速度對比
在探討動態環境下的視覺SLAM問題時,不能忽視算法運行速度的重要性。表5對本研究提出的算法、ORB_SLAM2以及DS_SLAM在同一硬件條件下的執行時間進行了比較。本研究算法在保持ORB_SLAM2架構的基礎上,額外加入了一個識別人體行為的線程,因此其追蹤處理時間略高于ORB_SLAM2。然而,與DS_SLAM相比較,本研究算法在執行速度上展現出了優勢。
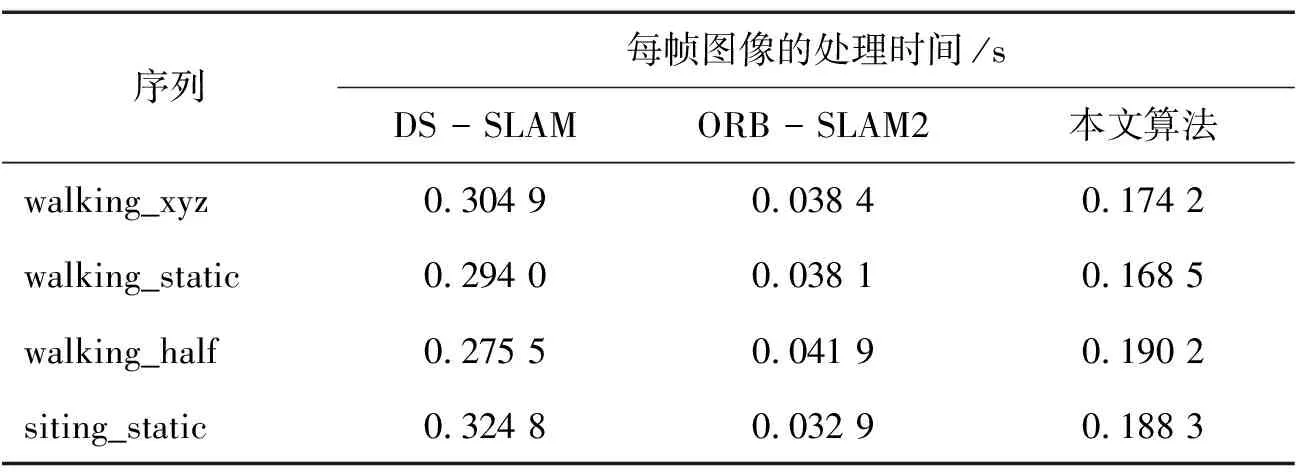
表5 動態環境SLAM算法速度對比
綜上,綜合各方面的對比數據,本研究提出的算法在保證性能的同時,也實現了速度與精度之間的有效平衡。
3 結論
本研究開發了一套針對封閉區域中動態環境的視覺SLAM系統,該系統在ORB_SLAM2框架上集成了一個人體動作識別模塊。通過識別圖像中人體的實際動作,該系統能夠有效識別并去除動態特征點,確保了特征點的靜態屬性。
通過與其他主流SLAM算法進行比對,結果顯示,本文算法對位姿估計的精度有所提高并保證了算法運行速度,實現了速度與效果的平衡。
本研究提出的方法在處理占較大比例的動態區域圖像時,可能會導致過濾后剩余的特征點數量不足。接下來需著手解決如何平衡算法的速度和性能,并拓展其在不同應用場景中的適應性。
猜你喜歡
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
中學生數理化·中考版(2022年12期)2022-02-16 07:36:56
今日農業(2021年8期)2021-11-28 05:07:50
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
科技傳播(2019年22期)2020-01-14 03:06:54
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國衛生(2014年2期)2014-11-12 13:00:16
