Scrapy框架輔助下的Python爬蟲系統研究
2024-05-19 14:36:42呂新超
電腦知識與技術 2024年7期
關鍵詞:數據采集
呂新超

摘要:為了解決傳統網絡爬蟲在大型網站上提取信息效率不高的問題,研究引入了Scrapy框架作為Python網絡爬蟲的提取方法。以某圖書網站為案例,文章深入分析了該網站的頁面結構,編寫了高效的爬蟲文件源碼,用于提取目標網站的關鍵信息,包括圖書名稱、價格、定價、作者和銷量排名等。研究結果表明,通過對主流網站的信息提取實驗,在實際應用中展示了該方法取得了良好的效果,可以成功提出需要的信息,并根據提取出的圖書價格和銷量排名信息可以分析出價格與銷量之間的關系,實現了對大型網站的信息提取任務。研究為爬蟲技術在數據采集和分析領域的應用提供了有力的支持,為信息爬取與處理提供了新的解決方案。
關鍵詞:網絡爬蟲;Scrapy框架;Python語言;數據采集
中圖分類號:TP393.09? ? ? ? 文獻標識碼:A
文章編號:1009-3044(2024)07-0049-04
開放科學(資源服務)標識碼(OSID)
0 引言
近年來,大數據信息技術的發展使全球范圍內的網站數量呈現指數性的增長,每個網站都蘊含著豐富的信息資源,這些信息資源具有巨大的潛力,可用于揭示某一行業的規律、預測未來趨勢,并滿足網絡終端用戶的個性化需求[1]。然而,從海量數據中提取有效信息并實現個性化信息傳遞,并非一項簡單的任務。為了應對這一挑戰,研究人員和企業界正在積極探索各種技術和方法。其中,Python爬蟲系統融合了Web抓取和數據挖掘技術,成為一個強大的工具[2]。
趙薔[3]發現,利用Python爬蟲可以在短時間內成功抓取大量有用的旅游數據,包括地區、購物、評價等信息,說明Python爬蟲系統對于高效數據的抓取非常有效,可以幫助旅游者和旅行規劃者更快地獲取和理解旅游相關信息。Rismawan[4]發現,利用Python編程語言的數據爬取技術創建的新聞高效網站可以系統地顯示來自各種來源的新聞在線網站,有效地從在線新聞中獲取信息。馬騰[5]發現,通過使用Python網絡爬蟲技術可以從房地產網站上抓取二手房信息,這表明數據爬取獲取技術在獲取大規模房地產市場數據方面非常有效,能夠深入了解大城市的二手房市場情況,為政府和購房者提供有價值的市場意見和信息。
Scrapy框架作為高度可定制的Web抓取框架,能夠采集、處理和分析Web上的數據信息。針對傳統網絡爬蟲在大型網站上信息提取效率不高的問題,本研究采用了Scrapy框架作為Python網絡爬蟲的核心工具。以某圖書網站為例,本研究深入分析了該網站的頁面結構,并編寫了高效的爬蟲文件源碼,用于提取目標網站的關鍵信息,包括圖書名稱、價格、定價、作者和銷量排名等。研究的創新性表現在引入Scrapy框架作為Python網絡爬蟲的核心工具,從而提高了數據采集、處理和分析的效率和靈活性,共同推動了網絡爬蟲技術在數據采集和分析領域的發展,為更高效和可靠的信息提供了新的解決方案。
1 網絡爬蟲相關理論
1.1 網絡爬蟲定義
網絡爬蟲,也被稱為網絡爬取器、網絡機器人或網絡蜘蛛,是一種自動化程序或腳本,用于自動地瀏覽互聯網上的網頁并從中收集信息[6]。網絡爬蟲的主要目的是收集互聯網上的數據,這些數據可以用于各種用途,包括搜索引擎索引、數據挖掘、信息檢索、價格比較、網站更新監測等[7]。
網絡爬蟲根據其功能、用途和行為特征有多種分類。通用網絡爬蟲廣泛抓取互聯網信息,如搜索引擎爬蟲;聚焦網絡爬蟲專注于特定主題或領域,如新聞聚合網站;增量式網絡爬蟲定期更新已抓取數據的索引;深層網絡爬蟲訪問難以到達的深層網頁;垂直網絡爬蟲針對特定垂直市場;協作網絡爬蟲則是多個爬蟲合作工作;爬蟲機器人具有自主學習能力,選擇爬蟲類型需根據具體需求[8]。網絡爬蟲基本的工作流程如圖1所示。
1.2 Python網絡爬蟲
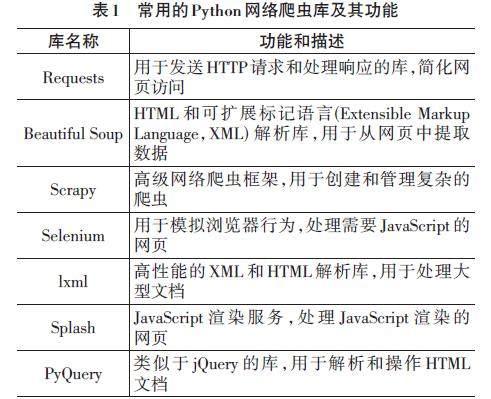
Python網絡爬蟲是一種基于Python編程語言的自動化程序,用于在互聯網上瀏覽并抓取網頁內容[9]。其主要功能包括發送超文本傳輸協議(Hyper Text Transfer Protocol,HTTP) 請求獲取網頁、解析超文本標記語言(HyperText Markup Language,HTML) 文檔以提取所需信息以及存儲或分析抓取到的數據。網絡爬蟲通常用于各種用途,包括數據采集、搜索引擎索引、信息檢索、數據挖掘等,但在使用時需要遵守法律和道德規范,以確保合法和道德的數據采集行為[10],常用的Python網絡爬蟲庫及其功能如表1所示。
1.3 Scrapy框架
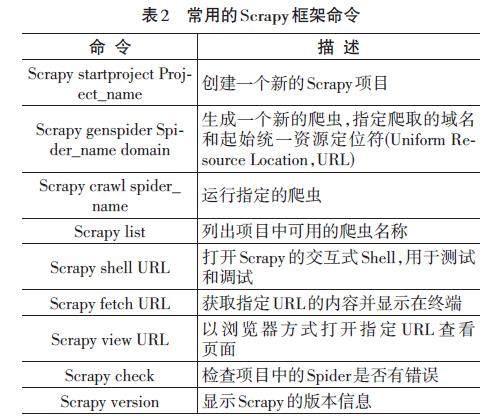
Scrapy是一個領先的Python網絡爬蟲框架,專注于高效且可擴展的大規模數據采集任務。其優勢在于提供了一套全面的工具,包括HTTP請求管理、數據解析、鏈接追蹤、異步處理等,以支持系統化的信息抓取工作。Scrapy允許開發者根據項目需求定制爬蟲規則,并提供多種數據存儲選項,使其廣泛應用于搜索引擎索引、數據挖掘、新聞聚合等多個領域。這一框架擁有堅實的社區支持和詳盡的文檔,是研究和實踐網絡爬取任務的首選工具之一[11]。常用的Scrapy框架命令如表2所示。
Scrapy框架結構如圖2所示,主要組件包括引擎(Engine)、調度器(Scheduler)、下載器(Downloader)、中間件(Middleware)、爬蟲(Spiders)、項目管道(Pipelines)、下載中間件(Downloader Middleware)、擴展(Extensions),這些組件共同協作,構成了Scrapy框架的核心結構,使其成為一個強大且高度可配置的網絡爬蟲工具[12]。
引擎是Scrapy的核心組件,負責協調整個爬蟲流程,包括處理請求、分發響應、觸發爬蟲中間件和管道等。調度器負責管理爬取請求的隊列,并確保它們以合適的方式被發送到引擎進行處理。下載器負責從互聯網下載網頁內容,并將響應返回給引擎,處理HTTP請求、處理Cookies和處理重定向等。中間件是可自定義的組件,用于在請求發送和響應接收的過程中進行處理。爬蟲是用戶定義的規則,用于指定如何抓取和解析網頁。每個爬蟲通常定義了起始URL、如何跟蹤鏈接以及如何解析網頁內容。項目管道是數據處理和存儲的組件,用于將爬取到的數據進行后續處理,如存儲到數據庫、寫入文件或進行其他自定義操作。下載中間件是特定于下載器的中間件,用于在HTTP請求和響應的發送和接收中進行處理。擴展允許開發者自定義和擴展Scrapy的功能,可以編寫擴展來添加新特性或修改現有功能的行為[13]。
Scrapy框架的數據流向[14]:首先,Scrapy引擎向Spider請求第一個要抓取的URL,然后Spider提供URL給引擎。接著,Scrapy引擎接收到URL并將其傳遞給調度器進行排隊和排序,隨后調度器將URL處理成請求(request)并將這些請求返回給Scrapy引擎。Scrapy引擎接收到這些請求后,使用下載器中間件將它們發送給下載器進行頁面下載。下載器下載完成后,將頁面內容封裝在響應(response)中,并將響應返回給Scrapy引擎。Scrapy引擎接著使用Spider中間件將響應傳遞給Spider進行處理,Spider提取網站數據并返回結構化的item給Scrapy引擎,如果有跟進的請求(request)也會返回給引擎。Scrapy引擎接收到item后,將其交給項目管道(Item Pipeline)進行進一步處理,同時如果有新的請求生成,它會再次經過調度器,循環直到調度器沒有更多請求。整個流程允許Scrapy框架高效地協調和處理網絡爬取任務,包括數據抓取和處理。
1.4 Xpath查詢語言
可擴展標記語言路徑語言(XML Path Language,XPath)是一種用于在XML文檔中定位和提取數據的查詢語言。XPath的主要原理是根據路徑表達式在XML文檔的節點樹中進行導航和篩選,以便精確定位所需的節點。它是XML文檔處理的重要工具,用于XML數據的查詢、轉換和提取,常用于Web爬蟲、XML文檔處理、XPath查詢引擎等各種應用領域[15]。XPath路徑表達式如表3所示。
1.5 網頁爬蟲設計
為了搭建網頁爬蟲的環境,首先需要下載安裝Python 3.5,確保在安裝過程中選擇將Python 3.5添加到系統的環境變量(Path Environment Variable,PATH)中,以方便后續使用。接著,安裝JetBrains PyCharm Community Edition 2018.1.4 x64,這是一個Python編程的集成開發環境,用于編寫和管理爬蟲代碼。此外,還需要安裝phpStudy,它包含了Apache或Nginx等Web服務器、MySQL數據庫以及超文本預處理器(Hypertext Preprocessor,PHP) 環境,對于爬蟲的開發和測試非常有用。最后,通過使用pip工具安裝Scrapy框架,這是一個用于爬蟲開發的Python框架,它提供了強大的工具和庫來簡化數據爬取任務。安裝完成后,通過運行“scrapy version”命令來驗證Scrapy是否正確安裝。搭建環境后可以開始使用Scrapy進行數據爬取,以獲取所需的數據。基于Scrapy框架下的Python爬蟲系統流程如圖3所示。
研究以某圖書網站為例,基于Scrapy框架輔助下的Python爬蟲進行了信息提取,主要信息包括圖書名稱、價格、定價、作者、銷量排名等。基于Scrapy框架下的Python爬蟲系統信息提取流程如圖4所示。
2 基于Scrapy框架下的Python爬蟲系統信息提取示例分析
2.1 應用示例分析
基于Scrapy框架下的Python爬蟲系統信息提取應用示例如圖5所示。
如圖5所示,基于Scrapy框架下的Python爬蟲系統應用示例顯示了從某圖書網站上獲取有關圖書的關鍵信息,主要包括書名、作者、價格、描述、折扣、出版時間、定價、出版社和銷量排名等。這個系統成功提供了一個高效的數據采集工具,可以讓用戶能夠方便地獲取和比較各種圖書信息,無須手動瀏覽網頁,從而節省時間和精力。這對于圖書愛好者、圖書銷售商和評測網站等各種應用場景都具有實際的價值,同時也為數據分析和決策提供了有力支持。
2.2 圖書價格與銷量排名描述型分析
圖書價格與銷量排名描述型分析結果如圖6所示。
如圖6所示,銷量排名與價格之間存在明顯的負相關關系。具體而言,銷量排名靠前的產品通常表現出較低的價格水平,而銷量排名靠后的產品則傾向于具有排名靠前的價格。排名前五的產品平均價格為23.28元,而排名后五的產品平均價格為11.82元,這強烈暗示了價格對產品銷量排名的影響,反映了市場的競爭特點,消費者更傾向于購買價格相對較低的產品。該信息的分析結果為市場策略制定者提供了強有力的指導,強調了在競爭激烈的市場中,降低產品價格可能是提高銷售排名的方法有效。
3 結束語
研究基于Scrapy框架下的Python爬蟲系統,成功構建了一個高效的信息提取工具,以某圖書網站為例,實現了對圖書價格和銷量排名等關鍵信息的自動化采集和存儲。研究結果表明,基于Scrapy框架下的Python爬蟲系統在獲取、提取和分析數據方面表現出了強大的能力。通過分析圖書價格與銷量排名的關系,發現了一些有趣的趨勢。在價格方面,本研究觀察到圖書的價格分布比較廣泛,從低價到高價不等,但總體來看圖書都集中在較低的價格區間,這可能反映了市場對于價格敏感度的體現。研究證實了基于Scrapy框架下的Python爬蟲系統在信息采集和分析中的重要性和價值。通過自動化的方式獲取相關圖書的信息,能夠更好地理解市場趨勢、用戶偏好,并為相關領域的決策提供數據支持。該方法不僅提高了數據的準確性和效率,還為驅動決策提供了充足的數據工具,具有廣泛的應用前景。研究雖成功應用Scrapy框架下的Python爬蟲系統進行數據提取與分析,但未來需要進一步探索數據的深層挖掘和多維分析,以更全面地理解信息關聯性。
參考文獻:
[1] 唐文軍,隆承志.基于Python的聚焦網絡爬蟲的設計與實現[J].計算機與數字工程,2023,51(4):845-849.
[2] WAN B.Exploring the effectiveness of web crawlers in detecting security vulnerabilities in computer software applications[J].IJIIS:International Journal of Informatics and Information Systems,2023,6(2):56-65.
[3] 趙薔.基于Python爬蟲的旅游網站數據分析與可視化[J].電子設計工程,2022,30(16):152-155.
[4] RISMAWAN S A.Implementasi Website Berita Online Menggunakan Metode Crawling Data dengan Bahasa Pemrograman Python[J].Jurnal Teknik Informatika dan Sistem Informasi,2023,10(3): 167-178.
[5] 馬騰,余粟.基于Python爬蟲的二手房信息數據可視化分析[J].軟件,2023,44(7):29-31.
[6] LUO K.A Study and Implementation of an Optimized University Library Book Recommendation System Based on Artificial Intelligence and Python Crawler Scraping Technology[J].Journal of Artificial Intelligence Practice,2023,6(2): 9-17.
[7] 劉萍.基于Python爬蟲技術的網頁數據抓取方法[J].信息與電腦(理論版),2022,34(14):169-171.
[8] KHAN N,HAROON M.A Personalized Tour Recommender in Python using Decision Tree[J]. International Journal of Engineering and Management Research, 2023, 13(3): 168-174.
[9] 孫握瑜.基于Python的新浪微博爬蟲程序設計與實現[J].科技資訊,2022,20(12):34-37. (下轉第56頁)
(上接第52頁)
[10] WU L,CHEN J S,ZHOU J.Teaching case design of python data analysis course for non-computer majors[J].Journal of Education and Educational Research,2023,3(1):97-99.
[11] 時春波,李衛東,秦丹陽,等.Python環境下利用Selenium與JavaScript逆向技術爬蟲研究[J].河南科技,2022,41(10):20-23.
[12] LI C Y.Study based on SNOWNLP model mining of stock bar investors emotions on stock prices[J].Modern Economy,2023,14(6):778-795.
[13] 李通,姚新強.Scrapy框架下區域人口數據爬蟲的設計與實現[J].軟件導刊,2021,20(11):152-157.
[14] ZHANG X Y,QUAH C H,NAZRI BIN MOHD NOR M.Deep neural network-based analysis of the impact of ambidextrous innovation and social networks on firm performance[J].Scientific Reports,2023,13(1):10301.
[15] 黎妍,肖卓宇.引入Scrapy框架的Python網絡爬蟲應用研究[J].福建電腦,2021,37(10):58-60.
【通聯編輯:代影】
猜你喜歡
現代電子技術(2016年22期)2016-12-26 12:36:15
電子技術與軟件工程(2016年22期)2016-12-26 11:11:30
現代電子技術(2016年22期)2016-12-26 09:44:35
電子技術與軟件工程(2016年19期)2016-12-19 19:59:14
電腦知識與技術(2016年27期)2016-12-15 20:42:01
農業與技術(2016年15期)2016-11-09 17:43:03
科技視界(2016年18期)2016-11-03 22:51:40
中國科技博覽(2016年22期)2016-11-01 16:58:26
軟件工程(2016年8期)2016-10-25 15:54:18
軟件工程(2016年8期)2016-10-25 15:52:53
