基于Python爬蟲技術的招聘信息數據可視化分析
2024-05-19 04:10:23付騰達李衛勇王士信許佳魯春燕
電腦知識與技術
2024年7期
付騰達 李衛勇 王士信 許佳 魯春燕
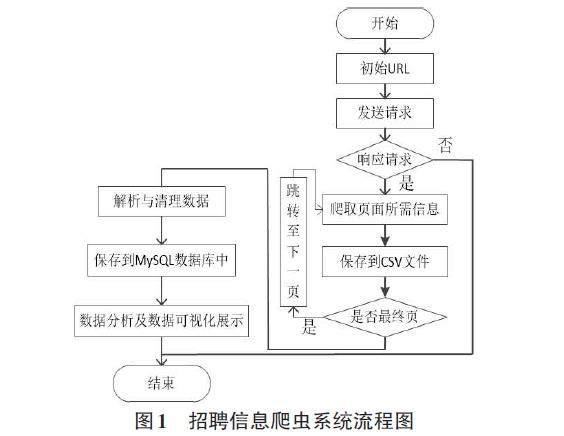
摘要:基于Python爬蟲技術,實現了從BOSS直聘網爬取南昌市與IT行業相關招聘信息的過程。爬蟲程序對BOSS直聘網爬取所需信息,并對爬取的數據進行清洗、整理、分析等操作,確保數據的準確性和一致性,隨后將數據存儲至MySQL數據庫中,供后續分析與使用。該系統后端采用基于Python的輕量級Flask框架,前端使用HTML5、CSS3、JQuery、Bootstrap5等技術,此外,還結合了基于JavaScript的Echarts數據可視化圖表庫,以實現數據到可視化效果的轉換。系統可以為廣大應聘人員提供有利的決策支持,以幫助他們更輕松地找到合適的崗位信息。
關鍵詞:BOSS直聘;網絡爬蟲;Flask;數據可視化;Echarts
中圖分類號:TP393.09? ? ? 文獻標識碼:A
文章編號:1009-3044(2024)07-0077-06
開放科學(資源服務)標識碼(OSID)
0 引言
隨著互聯網進入大數據時代,數據呈指數級增長,由于數據量龐大使查找信息時間周期長、精準度差、效率低,以致想通過網絡快速找到符合自己的崗位信息尤為困難。為此,很多研究者開始對招聘數據進行了相關研究,其中毛遂[1]以51job網為例對崗位占比和企業類型、薪資同學歷與地區之間的關系進行了分析。丁文浩[2]以前程無憂網為例對城市和崗位平均薪資水平、工作經驗、學歷情況等進行了分析。王福成[3]以拉勾網為例對高校程序設計語言類的招聘職位地域分布、職位與薪資、學歷與技能要求等進行了分析;羅燕[4]對人工智能類的招聘崗位、招聘行業、招聘城市等進行了分析。
本文基于Python爬蟲技術,從BOSS直聘網采集南昌市IT行業相關的招聘信息,通過分析與數據可視化圖表的展示,為南昌本地應聘者提供決策支持。……
登錄APP查看全文
