期刊論文結構化數據加工存儲標準的研究與探索
2024-05-29 00:22:53彭勁松李璐
數字出版研究 2024年2期
彭勁松 李璐

專題主持人
趙婧,女,中圖科信數智技術(北京)有限公司期刊業務總監。研究方向:數字出版技術平臺建設、數字出版與標準研究。
主持人語
標準化是經濟社會發展強有力的技術支持,標準達到統一,才能獲得最佳秩序和社會效益。科技期刊數字化發展同樣離不開標準的引導與規范,只有保證標準化工作的順利開展,才能促進數字出版活動獲得共同秩序和共同效益,促進參與各環節的各相關主體互聯互通。特別是在全球開放科學大背景下,我國科技期刊高質量發展、參與國際競爭,培育世界一流科技期刊亟須標準化引領。
本專題共四篇文章,第一篇聚焦國內外科技論文結構化標準應用的歷程,提出既能完整保留論文原始信息,又便于提取各類結構化信息的數據處理方案,實現一次加工多渠道投放和傳播;第二篇參考科研與學術出版社區中多種持久標識符體系(PIDs)的發展現狀,提出基于PIDs構建技術解決方案;第三篇以科技期刊發布系統遷移作為切入點,按照論文數據、擴展數據及由此衍生的用戶數據進行層次劃分,提出數據遷移的思路、方法和注意事項;第四篇從個案切入,以中華醫學會系列雜志為例闡釋DOI在科技期刊傳播和評價中的重要價值,并提出防止DOI著錄錯誤的有效建議。四篇文章將視角集中于科技期刊平臺的軟設施建設,即:標準規范作為科技期刊數字化的基礎設施,能夠促進科技期刊數字出版的標準化、規范化,促進跨平臺、跨模態、跨機構數據交換、數據集成和多平臺傳播,就需要在資源整理、平臺建設、業務制度等層面,通過形成方案指南和實踐案例,使之被更多科技期刊共識和踐行,更積極地參與全球開放科學,服務我國科技強國建設,為我國科技創新提供支撐力量。本專題的初衷即在此。
摘 要:期刊論文結構化加工在期刊界已經逐步形成共識,國內期刊平臺多采用新版期刊文章標簽集(Journal Article Tag Suite,JATS)標準進行加工,但JATS標準僅對數據屬性提出建議值,自行拓展空間較大,導致實際的數據加工結果千差萬別,數據交換困難重重。本文分析了國內外數字化加工和標準進化的歷程及我國在XML結構化數據加工中存在的問題,進一步分析了存檔及交換標簽集、出版標簽集等不同子集的特點,提出既能完整保留論文原始信息,又便于提取各類結構化信息的數據加工及存儲解決方案,可以根據需要通過減法轉換生成符合各平臺標準的數據加工存儲格式,從而真正實現一次加工、多渠道投放和傳播。
關鍵詞:期刊論文結構化;JATS;存檔及交換標簽集;出版標簽集;數據加工存儲標準;XML
DOI: 10.3969/j.issn.2097-1869.2024.02.007文獻標識碼:A
著錄格式:彭勁松,李璐.期刊論文結構化數據加工存儲標準的研究與探索[J].數字出版研究,2024,3(2):57-64.
1 背景及既有研究
1.1 國際期刊數字化加工及標準進化的基本歷程
國際期刊論文全文內容的數字化加工及標準進化經歷了較長的發展過程,總體可分為萌芽期、發展期和成熟期三個階段。
1.1.1 萌芽期
國際出版業數字化加工及文檔格式標準起源于20世紀60年代,IBM研究人員發現,要提高數據的可移植性,必須采用一種通用的文檔格式來分離內容和數據樣式。在該原則下,IBM創建了通用標記語言(Generalized Markup Language,GML),并開始用該語言標記文檔內容、版式及相互關系。
1.1.2 發展期
1986年,國際標準化組織(International Organization for Standardization,ISO)在GML的基礎上發布了一個信息管理方面的國際標準通用標記語言(Standard Generalized Markup Language,SGML),是ISO、美國國家標準學會(American National Standards Institute,ANSI)、歐洲計算機制造商協會(European Computer Manufacturers Association,ECMA)的共同標準,主要用來注釋文本文檔,提供文檔片段類型信息的規范。在此階段,一些國際出版公司如Commerce Clearing House(CCH)等開始搭建基于SGML文檔存儲和展示的平臺,把大量的紙質膠片等文檔進行電子化處理,轉變為SGML文檔。部分科技期刊和數據庫開始搭建基于SGML規范底層的電子期刊及數據庫產品,還有一些國際出版公司(如EBSCO)更是采用了文本標記的方式對期刊的元數據信息進行分類標記。1996年,學術資源平臺SpringerLink在線出版項目建立了全球第一個電子期刊全文數據庫;同年,美國物理聯合會(American Institute of Physics,AIP)開發了在線期刊出版服務(Online Journal Publishing Service,OJPS);1997年,巴西創建了SciELO科技期刊出版平臺。這一階段的主要方向是通過平臺形成各自的網絡電子出版模式。
1.1.3 成熟期
20世紀90年代中期,萬維網聯盟(World Wide Web Consortium,W3C)又在SGML標準的基礎上衍生出可擴展標記語言(Extensible Markup Language,XML),形成了用以描述網絡上的數據內容和結構的數字化標準。XML繼承了SGML的大部分功能,去除了使用率較低的功能,降低了使用的復雜度,使科技期刊在出版網絡化的同時,能夠發揮數據集成的優勢,共享數據。國際科技期刊數字化出版自XML的出現開始走向成熟,通過底層數據標準的轉換對接,從單一出版社、出版平臺走向了集群化并購的道路。例如,愛思唯爾(Elsevier)搭建了ScienceDirect全文數據庫,包含近3 000種期刊的全文數據;施普林格(Springer)成為了世界最大的開放獲取出版集團之一;2004年,AIP將原OJPS升級為Scitation平臺,并為10多家出版商提供服務。國際上,期刊集群化開放獲取已經成為主流,為了更好地實現集群化和數據共享,美國國家信息標準組織(National Information Standards Organization,NISO)采用了美國國家生物技術信息中心(National Center for Biotechnology Information,NCBI)的期刊文章標簽集(Journal Article Tag Suite,JATS)作為NISO定義的標準規范,并在此后逐步推出一系列國際出版物標準,形成了標準體系。自2010年以來,全球出版行業開始加速數字化轉型。當前,國際數字化業務已經“顛覆”了傳統出版的概念。據市場調研機構Technavio評估,全球數字出版市場的總體規模會在2021—2025年以每年平均12.6%的增長率加速擴張[1]。以美國為例,其出版的核心業務逐漸從單一的平面化紙質內容生產向跨媒體、多元化的新型數字內容生產轉變,美國科技期刊業已基本完成數字化轉型,傳統的紙質出版已經成為一項小眾業務。
1.2 國內期刊數字化加工及標準進化的基本歷程
國內科技期刊的數字化加工及標準化進程整體與國際同行相比尚有較大發展空間。國內的數字化標準基本采用借鑒方式,主要是學習認知國際標準,國內科技期刊數字化發展過程同樣也可近似地分為萌芽期、快速發展期和初步成熟期三個階段。
1.2.1 萌芽期
中國的數字化出版起始時間并不晚,其開始于“748工程”。1974年,原國家計劃委員會發文批復,同意將漢字信息處理系統工程列入國家科學技術發展計劃,成立漢字信息處理系統工程(簡稱“748工程”)[2]。但國內科技期刊的數字化進度比較緩慢,直至20世紀90年代,隨著計算機的普及,數字化才真正開始。起初,國內科技期刊數字化的主要方向是圖片化,而數字化的主體主要是圖書館。
這一階段的標準體系主要是基于掃描圖片及以掃描圖片為基礎的PDF文件。PDF采用“掃描+光學字符識別(Optical Character Recognition,OCR)”的方式進行數據加工,這種方式的優勢在于,只要有紙質期刊,就可以進行加工,沒有其他任何前提要求。但這種方式也存在一些弊端,如數據加工后,閱讀時只能查看掃描形式的論文,不僅不美觀,而且文件體積大,不便于網絡傳輸,OCR識別出來的文字內容也經常出現錯誤。
1.2.2 快速發展期
20世紀末至2010年,國內眾多出版公司認識到掃描版PDF的問題而開始采用數字化的排版方式,直接進行轉換加工形成PDF文件。這種加工方式的優勢在于內容視覺效果美觀,便于閱讀,不會出現掃描文件常見的鋸齒現象,加工出來的文件體積小,便于使用。但這種方式對排版文件的收集提出了嚴格的要求,不僅要求完整收集排版文件及其附屬文件(如補字、補圖等),而且還要保證收集到的文件是最后印刷使用的文件版本,而非某個中間版本。雖然這種方式操作較為繁瑣,但通過適當增加特定性標簽并經過長時間的磨合和發展,這也成為了PDF加工的主流方式。這一時期,國內出現了以知網、萬方、維普為代表的一批期刊數據庫廠商,他們所采用的主要加工方式是“元數據+PDF展示”。此時,國內的各科技期刊編輯部也開始向紙刊與編輯部網站兩種產品并存的方向發展,2010年后,大部分科技期刊都已建立自己的網站。
1.2.3 初步成熟期
自2015年開始,國內科技期刊數字化的主體除圖書館和數據庫廠商外,也涌現出一批科技期刊出版機構。這一時期,國內科技期刊數字化轉型開始走向成熟,在國家政策的扶持下出現了一批以內容方為主體的期刊集群平臺,如Mednexus、Researching、SciEngine、SciOpen等。這些平臺借鑒了前沿國際技術信息,建立了可以進行全文XML結構化數據展示的期刊集群平臺,同時采用XML結構化數據進行全文內容加工,少量頭部期刊開始基于JATS編制適合自己的XML數據標準,如中華醫學會的CMA JATS、科學出版社和清華大學出版社各自的XML數據標準等,并分別根據標準開展XML結構化數據加工。2019年,中國科技期刊卓越行動計劃的開展大幅加快了國內科技期刊數字化的進程。2023年,“DOAJ China Day 2023”開放獲取研討會在海南召開,開放獲取方式已得到眾多科技期刊的認可。
1.3 我國期刊論文XML結構化數據加工中的問題
目前國際上進行期刊論文數字化加工的首要目的是數據存儲,用標注語言把內容和樣式進行分離,底層是用標注語言進行標注的文本文件,主要側重數據標準,并在數據標準的基礎上根據不同的產品需求提煉出對應的產品標準,由此在加工和制作數據時就可以不被產品標準所限制。筆者所在的機構已有近40年的數據加工經驗,一般國際客戶都會要求先按其自定義的數據規范加工和制作后,再轉換、輸出為目標平臺的格式。
而我國開始探索期刊XML數據加工的理念主要是按產品標準制定數據標準,從而導致數據加工和制作受產品需求所限,大多國內客戶都會要求直接制作成目標平臺的數據格式,這可能會產生如下問題。
1.3.1 無法完整保留期刊論文所有的原始信息
國內主流的數據加工方式是根據特定產品的需求進行加工,因此在加工具體的XML數據項時,需要根據產品的標準要求舍棄不需要的原始信息,這樣做的好處是在展示時可以通過渲染實現數據的統一展示;但也由于丟失了部分原始信息,導致加工出來的數據無法作為原始數據進行存檔,而強行存檔或將造成數據不完整等不可預期的后果。
1.3.2 無法基于已加工數據生成不同需求產品的數據
對于上述XML結構化數據加工方式,由于數據不能完全體現論文的原始狀況,若僅根據經驗將數據加工成目標產品需要的數據格式,那么當需要把數據按其他數據庫收錄要求進行轉換時,可能導致無法生成相應數據,只能根據加工后的不完全數據進行轉換或重新加工,造成資源浪費。
2 期刊論文結構化數據存儲標準的設計與實踐
2.1 國際數據標準設計思路
為解決上述問題,可參考國際數據標準的設計思路。JATS是由NISO發布的期刊論文XML編碼的標準[3],鑒于該標準的完整性及各類內容提取的方便性,其成為全球科技期刊的一種通用數據交換文檔格式,支持出版商和數據庫進行期刊內容的存儲和交換[4],現在已經逐漸被全世界大部分期刊平臺認可并作為其底層數據的通用標準。
該標準體系分為三個標準子集:期刊存檔及交換標簽集(Journal Archiving and Interchange Tag Set)、期刊出版標簽集(Journal Publishing Tag Set)和文章創作標簽集(Article Authoring Tag Set),見表1。
期刊存檔及交換標簽集[5]是一套數據標準集,提供標準化格式以存儲期刊文章的知識內容。該標準集在系列標準中包容性最強,其中大部分屬性值都是字符數據值,可以容納任何源值,最大程度保留原始數據內容(包含元素之間的標點和空格等)而無需求助于樣式表生成文本元素。由于該標準集具有完整性特征,其還支持針對各種出版標準的用戶數據交換,而避免出現數據丟失的情況。
期刊出版標簽集[6]是為期刊出版用戶提供的一種出版發布規范標準化格式,是一種產品標準,側重于期刊發布,其包含的標簽比期刊存檔及交換標簽集少。根據該期刊發布標準,部分原文內容(如作者基金信息的分類標題等)會由發布平臺通過樣式表處理,從而丟棄原始的實際數據信息。
文章創作標簽集[7]是為論文作者提供的一種論文寫作標準化格式,很多編輯軟件針對該標準開發相應工具,方便作者寫作并對接期刊編輯。與前兩個標準集不同,文章創作標簽集是整體標簽套件,規定比較嚴格,很多元素內容必須以指定的順序出現并限制其格式設置選項,不允許在該標簽集上出現具有期刊編輯個體風格的內容,比如列表或參考文獻的標號等。
2.2 期刊論文數據加工實踐問題分析及解決思路
2.2.1 問題分析
對于國內期刊的XML結構化數據加工,除第一章提出的問題外,筆者在多年數據加工服務實踐中還遇到了如下問題:
(1)各期刊集群或出版社的規范不一致;
(2)在同一種規范下,平臺的樣式不同導致對數據的要求不同;
(3)期刊集群或出版社標準持續更新。
上述問題和第一章中提出問題的實質都在于,雖然期刊或期刊集群的標準規范都是產品類型的規范,但即使是同一期刊或同一集群,這一規范也會根據產品的適用場景不同而發生變化。
2.2.2 關鍵問題解決思路
為解決上述問題,本文提出如下解決思路。
(1)在構建數據加工存儲標準時,以期刊存檔及交換標簽集而非期刊出版標簽集為基礎來進行構建,可以加強相關標簽集的包容性,需要時再轉換為期刊出版標簽集或其他期刊自行定義標準。這種方法的核心是數據標準與產品標準的分離。
因此,在設計數據存儲標準時,要盡可能兼容其他平臺的顆粒度。同時,由于XML語言具有可擴展性,標簽名稱是否相同并非問題的關鍵,標簽內容的唯一性和準確性才是關鍵。具體來說,一是要針對各種期刊原文進行分析,對期刊中的各種元素進行總結;二是要制定囊括期刊所有內容的標準集(參考期刊存檔及交換標簽集的存儲方式),將期刊中的所有內容都以元素存儲的方式進行標識,且在加工過程中保證標簽內容的唯一性和準確性。
(2)采用多種手段保證論文原文信息完整,可通過如下方式處理:第一,將期刊出版標簽集或產品類型標簽集中需要舍棄的內容適當增加特定性標簽,放入專項內容進行存儲,同時采用適合其內容的標簽進行標注;第二,對于原文元素中出現的標點或空格等用于分割信息的內容,也應基于保留原則,采用特定標識進行標記,這樣既能保留原文內容(如原始的標點或間距等),實現原文重現,又能在根據產品標準統一渲染時去除相關標識的內容,使內容按照統一的規格得以呈現。
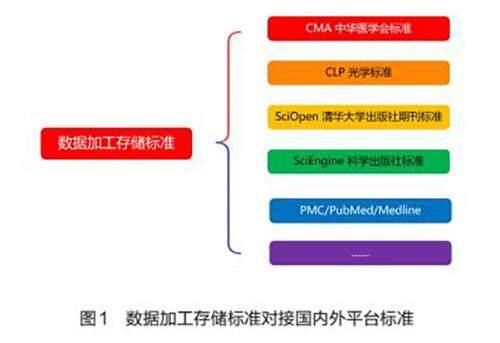
(3)數據加工存儲標準的應用針對不同的平臺標準轉換,也就是將數據加工后存儲的標簽和結構按照所需的平臺標準進行轉換,由于設計的標準集內容涵蓋期刊的所有內容,客戶需要的平臺標準和產品標準一般為該標準集的子集(見圖1)。因此實際操作時可以針對客戶的個性化需求刪減不需要的標簽內容,進行減法對接,并將標簽對應到客戶所需標準上,實現一次加工多次分發的目標。
筆者采用上述方式進行數據加工、存儲和轉換相關工具的調整和優化,并在實際的數據服務過程中進行了驗證,現已成功將加工后的數據與多個平臺進行對接,包括DOAJ、PubMed及PubMed Central(PMC)、Elsevier Digital Commons、Index Copernicus(ICI)、西太平洋地區醫學索引(WPRIM)、國家科技圖書文獻中心(NSTL)、中國科學引文數據庫(CSCD)、中國知網(CNKI)、萬方醫學、中國人文社會科學引文數據庫(CHSSCD)、中文社會科學引文索引數據庫(CSSCI)、中國科學院科技論文預發布平臺(ChinaXiv)、EDP Sciences、OVID Technologies、SciOpen、SciEngine、中國激光雜志社(CLP)、中華醫學會雜志社(CMA)、方正等平臺,全部采用同一個數據加工存儲標準并通過減法直接輸出,已實現一次加工多渠道投放的效果。
2.3 應用案例及成效
筆者根據對中華醫學會雜志社的多年數據加工經驗和對標準的理解,在上述數據加工存儲標準基礎上建立了規范、高效的“中華醫學會期刊文檔標簽集”(以下簡稱為“CMA-JATS標準”),現已完成中華醫學會雜志社全部回溯數據的標準化加工工作,并持續進行現刊的數據加工。
中華醫學會雜志社從2006年開始研究國際數字化成功案例,以內容建設為核心,參考國際標準并結合中國醫學期刊的特色制定了CMA-JATS標準[8]。雜志社于2015年開始搭建中華醫學期刊網,目前已收錄期刊206種,論文130余萬篇。2019年,為了更好地服務集群化期刊出版平臺,提升學術數據資源的價值,雜志社搭建了數據中臺和業務中臺,將通用能力進行抽象化和原子化處理,實現了數據、業務、用戶的集約化管理。其中,數據中臺在數據標準方面不斷迭代,將高精度、高價值的數據進行清洗、標引、分發、統計等,為數據資產的保值和增值打下基礎。目前,中華醫學會雜志社已經基于數字中臺架構開展了多種數字運營形式,除中華醫學期刊網外還建立了中華醫學期刊全文數據庫、中國臨床案例成果數據庫、中華醫學期刊App等多形態、多模式的前端應用,使其成為國內名列前茅的已實現數字出版可持續運營的科技期刊出版單位。
3 面向科技期刊的數據加工及標準建議
目前,大量科技期刊和出版單位正在嘗試構建自己的數據標準并開展數據加工,對此,本文提出如下建議。
3.1 從存儲標準中提取產品標準,以適應跨平臺傳播需要
對科技期刊、出版社等內容方而言,不建議以某單一平臺的產品標準作為數據存儲標準。建立數據存儲標準時應脫離產品需求,可使用JATS期刊存檔及交換標簽集為基礎來搭建存儲標準之上的數據中臺,以本刊或本單位能用到的最大集的方式保留期刊的原始內容。同時,建議以期刊出版標簽集為基礎來搭建期刊網站平臺,充分利用樣式表及平臺渲染實現網站平臺的效果。目前,國內大部分技術廠商的標準都基于JATS期刊出版標簽集搭建,因此這種方式也能夠適應技術廠商的發布平臺。由于期刊出版標簽集和文章創作標簽集都是期刊存檔及交換標簽集的子集,完全可以從數據平臺提取對應產品平臺的各項內容,使內容方真正掌握對數據的主動權,也只有全內容的存儲標準才能使內容方在對接第三方平臺時,僅在數據標準里做“減法”或“翻譯”即可生成第三方數據。存儲標準和樣式表是脫離的,所有內容均為文本化信息,而產品標準大多與樣式表相結合,若脫離了樣式表則可能導致部分數據內容缺失。目前國內很多科技期刊出版單位仍將產品標準置于首位,以產品標準來定義自己的數據標準,并且多以平臺展示作為數字化的發展方向,這就導致內容方的數據被產品標準所“綁架”,在跨平臺傳播時,數據的重用性會受到較大影響,甚至需要重復性加工。XML存儲和排版文件等數據都應是內容方的資產,不同的產品標準應該是從存儲標準中被針對性提煉出來的,這樣內容方才能自主選擇平臺產品,實現期刊平臺商的更迭與優化。
3.2 將數據底層進行結構化處理,避免偽數字化
期刊數字化主要是存儲方式的數字化,而網頁展示與檢索、PDF閱讀與下載等只是數字化的表面現象,是對期刊內容的數字化展示手段,后者仍屬于傳統出版的邏輯。真正的數字化應將數據底層進行結構化處理,而非僅為展示目的的偽數字化。
當前,一些科技期刊內容方存在一種認知誤區,即只要采用了國際JATS標準,能在數據庫Schema①中檢測通過,就可以和國際對接。但實際并非如此,Schema通過僅表明文件邏輯正確,可以導入對方平臺,但內容標識的正確性無法通過Schema驗證法進行檢測。一些加工商將內容生硬地關聯至標準元素(Element)中,可能會導致后續產品擴展出現問題,這就是對標準目的性理解不到位的結果。(①指數據庫的組織和結構。)
XML是一種可擴展的標注語言,其元素及屬性(Attribute)均可自定義,并非只有嚴格按照國際通用定義才能與國際對接,JATS等通用標準都是由國際組織提供的一些指導性標準,主要是基于顆粒度的指導,國外的主流出版單位很少完全套用國際通用的標準,而是往往會根據自身的需求進行改動,或完全自定義一種自己的標準。國際對接的核心并不在于是否采用了國際標準元素,而在于顆粒度。如果數據加工的顆粒度足夠高,那么在與其他平臺對接時,只需進行每個元素的轉換或翻譯即可。這就如同語言翻譯,雖然中文和英文字集不同,但每個單詞對應的指示性內容是一致的,只需對應翻譯就可以讓對方理解。因此,對接標準的實質是內容的對接,而非標簽的對接,本質上也可以理解為存儲標準和產品標準的對接。
目前部分國內期刊平臺為了展示效果的視覺統一或美觀進行了很多樣式渲染,如一些原文的分類小標題等是通過平臺樣式表根據標簽渲染出來的,在底層數據上并沒有相應保留,有些期刊平臺甚至完全拋棄了原有數據的結構,對于科技期刊而言,若此后再想在其他平臺傳播就會面臨較大的麻煩。因此,數據標準和產品標準的分離是內容商實現數據多平臺傳播的基礎,應充分吸取成功經驗,避免造成“為了展示而展示”的偽數字化。
3.3 對數據進行高質量、高顆粒度的加工和存儲,基于標準開發平臺
目前國內大部分科技期刊內容方均采用現成的平臺,造成其數字化受限于平臺,形成“被數字化”的局面,其加工的數據在后續使用中都受到限制,甚至使出版資源數字化變成一個“雞肋”項目。而在國際上,數字化出版不僅實現了盈利,且大有替代傳統出版的架勢,主要區別就在于國外科技期刊出版單位的數據加工往往有的放矢,可以持續應用于后續產品中。
要緩解目前國內科技期刊內容數字化過程中存在的問題,首先要確認需求,明確數字化的目的及后期產品的種類,根據需求制定能夠滿足后續產品顆粒度需求的標準;然后在此基礎上對內容進行高質量、高顆粒度的數據加工和數據存儲,而這也是期刊論文結構化數據存儲標準的核心要求。平臺應基于標準來開發,而不是反過來由平臺決定標準。
數字化內容加工的精確度是關鍵,國外科技期刊出版單位往往都對基礎XML數據精度有明確要求,一般為99.95%或99.995%。當前國內出版物的質量有三審三校等過程體系進行保證,但期刊數字化內容的質量問題還沒有引起足夠的重視。
3.4 重視知識標注的專業化
在進行數據加工和知識標注的過程中,需要對二者的數據進行分別處理。其主要的不同在于,數據加工是根據加工的技術要求和質量要求,將期刊、論文的數據進行結構化處理,放置于不同的標簽中,除加工的知識外,不需要論文內容相關的領域知識;而知識標注則不同,需要標注人員具有與論文內容相關的學科背景,對其中的術語、知識有基本的了解,才能做好知識標注,如對論文的分類或研究方法進行標注等。數據加工可以由普通的熟悉相關操作的人員進行,而后者則建議由具有專業背景的人員進行操作。
3.5 增強版權意識,區分元數據和全文數據對接
在與第三方渠道進行對接時,科技期刊內容方應充分了解對接的各數據庫或渠道所需要的數據類型,區分元數據對接和全文數據對接,增強版權意識。一些編輯部對文章的版權認知尚不清晰,在元數據收錄時直接將全部數據信息提供給收錄方,這有可能導致內容方與收錄方在后期產生版權糾紛。
4 結語
本文基于對國內外科技期刊數字化加工及標準進化基本歷程的梳理,提出通過期刊論文結構化數據加工存儲標準的建立和實施,有效、完整保存期刊內容,并在此基礎上提出可以通過從存儲結構中提取相關標簽的信息并進行轉換的方式,生成任何類型平臺所需的包括JATS在內的多種出版標準數據,以及支持與各類數據庫減法對接的數據,從而實現一次加工多渠道投放的效果。本文還基于筆者所在機構在數字加工領域的長期經驗,對科技期刊提出區分存儲標準和產品標準、吸取結構化加工成功經驗并避免偽數字化、對內容進行高質量和高顆粒度的加工和存儲、分別處理數據加工與知識標注,以及增強版權意識,區分元數據和全文數據對接等建議。
作者簡介
彭勁松,男,北京欣博友數據科技有限公司技術總監。研究方向:數字化國際標準及傳播。
李璐,女,北京欣博友數據科技有限公司期刊XML結構化制作項目經理。研究方向:期刊國內外標準對接。
參考文獻
[1]付嬈,李暉.結構改變與模式創新:美國數字出版業發展的現狀、轉向及啟示[J].出版與印刷,2022(5):25-31.
[2]周程.轉載《知識分子》:王選當年是如何攻克核心技術戰勝外企的?[EB/OL].(2018-04-29)[2024-01-03].https://www.icst.pku.edu.cn/fqlm/icst_35th/zxbd/1223569.htm.
[3]MARK H N.NISO Z39.96-201x, JATS: Journal Article Tag Suite[J].Serials Review,2012,38(3):213-214.
[4]包靖玲,李敬文,沈錫賓,等.美國NLM DTD 3.0期刊存儲和交換標簽集中文章正文部分標記解讀[J].中國科技期刊研究,2014,25(4):515-519.
[5]NCBI.Journal Archiving and Interchange Tag Set[EB/OL].[2024-01-03].https://jats.nlm.nih.gov/archiving.
[6]NCBI.Journal Publishing Tag Set[EB/OL].[2024-01-03].https://jats.nlm.nih.gov/publishing.
[7]NCBI.Article Authoring Tag Set[EB/OL].[2024-01-03].https://jats.nlm.nih.gov/articleauthoring.
[8]沈錫賓,李鵬,劉冰,等.CMA JATS在中華醫學會雜志社數字出版中的三年實踐總結[J].中國科技期刊研究,2018,29(3):248-252.
Research and Exploration on Structured Data Processing and Storage Standards for Academic Journals
PENG Jinsong, LI Lu
Formax BPO Beijing Inc., 100085, Beijing, China
Abstract: Structured data processing of papers has gradually formed a consensus in academic journal field. Domestic journals and platforms mostly adopt the Journal Article Tag Suite (JATS) standard for processing, but the JATS standard only puts forward suggested values for data attributes, which has a large space for self-expansion, resulting in different actual data processing results and difficulties in data exchange. This study analyzed the process of digital processing and standard evolution at home and abroad and the problems existing in XML structured data processing in China, and further analyzed the characteristics of different subsets such as Journal Archiving and Interchange Tag Set and Journal Publishing Tag Set. A data processing and storage solution were proposed, which can not only completely retain the original information of the paper, but also facilitate the extraction of various structured information. It can be used to generate data compliant with each platforms standard through subtraction and conversion as needed, thus truly realizing one-time processing and multi-channel delivery and communication.
Keywords: Structured data of academic journals; JATS; Journal Archiving and Interchange Tag Set; Journal Publishing Tag Set; Data processing and storage standard; XML
