生成式AI驅動下的知識封裝與知識傳播新形態研究*
2024-05-29 12:33:32易龍
數字出版研究 2024年2期

摘 要:知識封裝技術的發展推動了出版形態的更新,從數據庫技術、搜索引擎再到大語言模型技術,知識表示、提取、生成和傳播的方式不斷演化。生成式AI可對各類數據文本進行學習并推理預測,進而生成知識性內容輸出。一方面,生成式AI技術因其知識生成的潛在效果而被普遍用于知識封裝產品之中;另一方面,也必須關注生成式AI可能帶來的一些問題,如數據可耗盡性、輸入依賴性、不平等性、解釋性不足及穩健性不足等。生成式AI通過對話式知識提取、多模態知識表達和知識智能體等方式,正在深層重塑知識傳播形態,理解其演進特征將有助于更好地駕馭這一新型知識系統。
關鍵詞:生成式AI;知識封裝;出版形態;知識傳播;大語言模型
DOI:10.3969/j.issn.2097-1869.2024.02.011 文獻標識碼:A
著錄格式:易龍.生成式AI驅動下的知識封裝與知識傳播新形態研究[J].數字出版研究,2024,3(2):84-93.
*基金項目:2023年度湖南省教育廳科學研究優秀青年項目“生成式人工智能背景下的知識封裝與傳播形態研究”(項目編號:23B0019)。
出版活動包含了知識封裝(Packaging)和知識傳播(Dissemination)這兩個重要并置功能。知識封裝貫穿紙質出版到AI出版的各個發展階段。紙質出版和電子出版階段,更多地將封裝視為出版物固態化的過程或狀態。張志強等[1]區分了網絡型出版物和封裝型出版物,強調了兩者之間存在的差異。徐麗芳[2]通過辨析數字出版與電子出版、網絡出版,指出了封裝型載體變化導致的概念趨同。隨著出版形態的進一步演化,封裝被賦予了更多內涵。張新雯等[3]探討了將資源封裝成不同產品形態結構的可能性。馮宏聲等[4]認為在數字出版語境里,“容器”并非物理形態的介質,而是“以數字形態封裝內容的符號”。周葆華[5]認為,人類傳統的知識媒介由專家系統生產和把關,知識生產遵循特定的專業法則和審核標準,凝結成確定的知識產品形態,保存于固定的“本質性資料庫”中。常江等[6]提到,在數字媒介邏輯的支配下,整個出版業的“操作系統”完全被打開了,各種類型的出版物與其說是某一知識產品的最終形態,不如說是流行性、網絡化的知識生產過程中的某一個“凝固的瞬間”,是用戶生活經驗與知識獲取實踐的一個語境化的交叉點。綜合以上觀點,不難發現,學者大多認同封裝是將知識凝結固定的技術實現和形態結構的塑造過程。
進入智能出版階段,知識的封裝與傳播實現了功能同步。生成式AI技術展現了其在大規模知識挖掘、組織、表示與傳播方面的能力,推動了出版新形態和新業態的不斷涌現。生成式AI作為一種AI技術,能夠通過學習已有數據集生成新的文本、聲音、圖形、視頻、虛擬現實等多模態內容。方卿等[7]從出版作為一個以知識內容選擇、傳播、傳承為內在追求的內容產業出發,指出“類人”的智能和出版的系統化封裝與傳播,使得人工智能生成內容(Artificial Intelligence Generated Content,AIGC)產生巨大的影響力和破壞力。劉珍等[8]指出AI的內容生成功能和出版行業的深度融合將實現知識封裝過程中的全流程互動性和個性化,并更好地整合多模態的出版內容,實現更完整、優質的內容出版。考慮到出版業知識組織的核心功能與生成式AI封裝知識的內在勾連,可以將知識封裝視為基于用戶信息使用行為習慣,利用不同的媒介技術系統對知識內容進行產品化組織并為用戶提供知識服務的實現形式[9]。出版是知識密集型、智力密集型的行業,也是對媒介技術敏感的行業。出版業圍繞知識的組織不斷地革新媒介應用方式和出版物封裝形態,以求更好地進行知識傳播。生成式AI表現出的知識生成和處理能力,對出版業的核心能力帶來了直接的沖擊。為了應對,部分出版機構積極擁抱生成式AI以提升競爭力。考慮到生成式AI應用所需要的開發能力、算力成本和數據資源,出版行業鮮少能夠直接開發通用大語言模型,故將生成式AI技術與出版業態相結合成為主流路徑,應用場景選擇和產品形態設計成為出版智能化過程中需優先考慮的因素。出版業擁有優質內容和數據供給,生成式AI則是數據和知識挖掘的先進技術,兩者能有效結合的關鍵在于能夠產生符合新技術條件下用戶使用行為習慣的出版產品形態。因此,考慮著眼于產品化的知識封裝和著眼于用戶接受的知識傳播是需要重點討論的問題。
1 封裝技術對出版形態的形塑
媒介技術固有的物質結構及與生俱來的對信息符號的重構力量,使其對傳播形態發揮著重要的限定性作用,一旦與內容結合便可固化為特定的出版物形態。封裝不總是意味著出版內容物的凝固和編輯開放性的終結,相反,通過梳理封裝技術與出版形態的關系可以發現,與以完成態為目標的出版物封裝技術不同,生成式AI技術對知識的封裝是在與用戶共生的知識交互中完成的,是一種更關注個性化知識獲取的封裝方式。
1.1 封裝技術與內容物的組合共同塑造了出版形態
出版是文化傳承、知識傳播和信息傳遞的重要方式,而這些目標的實現離不開出版物這一重要載體,因此文化、知識、信息的封裝方式在一定程度上決定了出版價值的實現。對文化、知識和信息的封裝方式,是根據不同的出版目標選擇特定內容組織方式形成不同出版物形態的過程。數據庫和大數據技術的發展,加上數據作為重要生產要素發揮的經濟社會價值,使得數據這一知識來源的初始形態成為相對獨立的一種內容物,發展為數據出版形態。組織理論家羅素·艾可夫(Russell L. Ackoff)最早提出了“數據—信息—知識—智慧”層次結構,揭示了知識的本質,成為知識組織理論的重要基礎[10]。數據庫技術(包括大數據技術)、搜索引擎技術、大模型技術三類知識封裝技術與知識的層次結構模型相結合,產生了數據出版、信息檢索、知識服務等各類出版形態的發展。
1.1.1 數據庫技術與數據封裝
數據封裝的目標是提供一定規模數據集的存儲、查詢和分析,追求存儲記錄和檢索利用價值,并不直接提供知識挖掘和深入見解,涉及數據庫及大數據技術。早期的知識以高度結構化的方式進行存儲,通過關系型數據的方式來表示人類知識,通過數據庫語言來檢索、訪問、調用知識,具備較高的使用門檻。后來則出現了專門存儲非結構化數據的數據庫技術,通過數據挖掘和機器學習等技術可用于處理使用非結構化數據。
1.1.2 搜索引擎技術與信息封裝
以滿足資訊獲取等淺閱讀需求為目標的封裝形態,是知識封裝的初級加工形態,往往知識密度低、技術復雜度低、折舊速度快。隨著因特網的誕生,大量的碎片化知識分布在不同的網站中,搜索引擎成為獲取知識的關鍵技術。關鍵詞輸入作為提取知識的基本使用方式,基本為單向操作。通用搜索引擎以滿足信息需求為主要目標,知識結構化程度較低。搜索引擎通過互聯網頁面信息的抓取、索引及排序算法等技術對信息進行封裝,并以關鍵詞匹配響應信息需求。信息封裝的主要目標是消除不確定性,因此以事實性內容提供為主要方式,早期搜索引擎索引的信息來源類型包括在線新聞、社交媒體文章、電子書籍等,本身通常不被視為一種數字出版形態。但是,搜索引擎作為一種信息封裝方式,為互聯網用戶提供了一種統一的信息或知識獲取的交互界面和訪問入口,其作為信息提取與表示的主要方式,具備強大的控制信息流動的權力,信息索引和頁面排序算法等則是這種信息分配權力的具體實現。
1.1.3 大語言模型與知識封裝
大語言模型(Large Language Model,LLM)是生成式AI的重要類型,主要用于自然語言的理解和生成任務。大語言模型以從信息和數據中提煉結構化認知為目標,可提供有組織和可解釋的信息,需要AI、深度學習等技術輔助實現知識挖掘的功能,通常具備良好的穩定性和較長期的價值。大模型時代首次以最自然的方式使用人類知識,通過對話即可提取知識,知識的組織圍繞人類提示詞而進行預測式生成,知識傳遞在對話協同中完成。
考慮到三種封裝方式各有其優缺點(見表1),未來封裝技術的發展有可能融合數據庫技術、搜索引擎技術、大語言模型技術三者的優勢,以保證知識封裝在知識時效性、密度、精確度、準確度等方面的可靠性,并減少機器幻覺和信息偏見所帶來的危害。
1.2 基于生成式AI技術的知識封裝產品
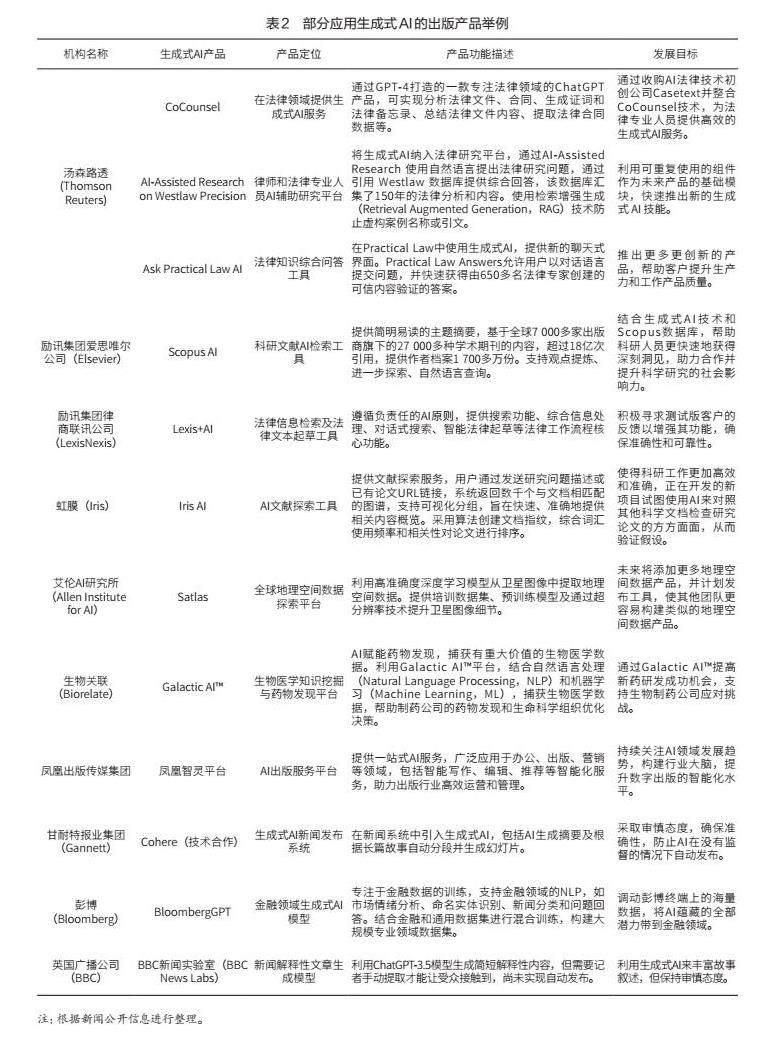
生成式AI技術的出現,推動出版行業應用AI從傳統的知識挖掘升級為知識生成。知識模型基于大模型的訓練機制,可以在某種意義上認為大模型學到了人類知識,并通過生成模式實現知識的重新表達和傳播。因此,可以說大模型即出版,大模型是集成性的、新形態的出版物[11]。從公開數據來看(見表2),開發相應產品、工具或平臺是出版機構應用生成式AI的主要方式。通過對現有部分出版機構的生成式AI產品的定位、功能和發展目標等方面的梳理,發現現階段出版相關企業的生成式AI產品部署主要用于增強傳統優勢業務板塊,進一步服務核心客戶,最終提升企業的市場競爭力。在金融、法律、科研等知識密集型行業及新聞等信息密集型行業,生成式AI得到了廣泛應用。
2 生成式AI知識封裝及知識處理方式
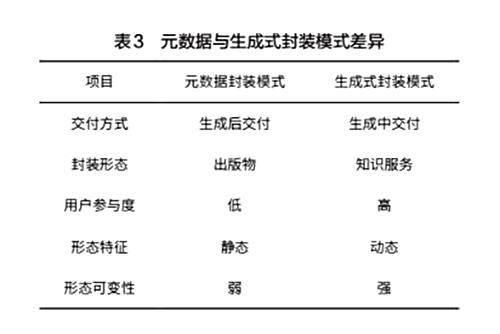
傳統數字出版一般采用元數據封裝模式,通過統一的制作規格保證出版物的交付質量,產品具備很高的標準化程度和結構穩定性,給知識的組織、檢索、存儲和利用帶來了很大的便利。生成式AI封裝模式則依賴于提示詞,通過單次或多輪對話提取知識,知識的組織圍繞人類提示詞而進行預測式提供。因此其相對元數據封裝模式而言是非標準化封裝,其形態因提示詞而異,具備知識供給的靈活性,是一種個性化的知識供給模式,需要人機協同才能共同完成知識的生產與獲取。元數據封裝模式和生成式封裝模式,在知識交付方式、封裝形態等方面都存在差異(見表3)。
2.1 生成式AI知識封裝特性
2.1.1 數據可耗盡性:大語言模型數據需求增長快而高質量語料有限
大語言模型對人類所有可獲得的、可數據化的知識進行封裝,使其具有知識存儲方面的完備性,并且幾乎不存在知識上的盲區和短板。按照計算機專家陸奇博士的觀點,它幾乎封裝了全世界所有的知識,內嵌了足夠的學習能力和推理能力[12]。ChatGPT在不同版本中接入了GPT-3.5和GPT-4兩個模型:前者的參數數量達1 750億,訓練集的token數量達4 990億,其數據源來自Common Crawl數據庫、WebText數據集、英文維基百科、書籍期刊,其中僅蘊含在書刊內的知識就已超出一般個人的知識水平[13]。按照目前大模型的發展速度,很有可能在不遠的將來耗盡現有可獲得的高質量文本。由于知識生成的效果依賴于訓練所使用的數據集,一旦包含了人類存量知識的高質量語料被學習完畢,大模型的知識邊界便會暴露出來。
2.1.2 輸入依賴性:提示詞和知識輸出之間的聯動
應用生成式AI產品進行知識輸出和提取,嚴重依賴于提示詞的質量及其使用方式。可以通過一個提示詞實驗來觀察提示詞與知識輸出的關聯。通過讓ChatGPT就一個主題進行提問并作答,建立問題與輸出之間的問題序列。例如,給出的提示詞如下:“請就‘數字出版這一主題給出5個問題,要求這5個問題是同一個問題按抽象程度分為具體、稍微抽象、一般抽象、高度抽象、最高抽象5個層級逐級遞增的不同表達;給出參考答案;并請對你自己回答的每道題依次進行評價。”ChatGPT輸出的結果整理后見表4,當提示詞的抽象層級不斷提升時,答案的抽象程度也隨之提升,知識密度相應增加。
2.1.3 不平等性:算法的放大器效應強化了提示詞輸入者之間的既有“知溝”
一方面,生成式AI是新“知溝”產生的主要推動力量。由于知識的易獲得性,盡管目前還不可靠,生成式AI仍然一度被認為是知識普惠的代表性技術。但事實可能正好相反,受限于用戶認知水平、經濟狀況、地區分布、大模型存在的偏好迎合傾向等諸多因素,使得生成式AI并不能帶來信息和知識平權,甚至在一定程度上會放大兩者之間的差異,造成知識獲取的“剪刀差”。現以“剪刀模型”(見圖1)假設來描述生成式AI應用過程中所存在的個體間知識獲取差異:由于并非每個人都能平等地接入和使用大語言模型,造成了大模型采納過程的進度差異,最先使用大模型技術的用戶更有可能獲得技術帶來的知識獲取便利,因而可以更早積累知識,并受惠于此。對大模型技術的理解差異、語言表達水平、認知水平差異等也造成了輸入提示詞水平的差異,這導致了知識生成結果的差異。對輸出結果的使用評價能力則進一步導致了后續影響,例如在知識驗證、偏見防范等方面進一步造成了不平衡。大模型技術有時并不是解決知識平權問題的良方,相反它會放大原本存在的個體間知識獲取方面的不平等問題,即個體間固有條件差異越大,經過大模型的放大后,其導致的知識獲取效果差異也越大。人類的提示詞輸入細微差異經過Transformer模型放大后,機器會給出不同水平的輸出。
另一方面,英語知識生產的中心地位被強化。當前大模型數據集主要為英文,其他語料則相對偏少。中國工程院院士高文曾公開表示,全球通用50億大模型數據訓練集里,中文語料占比僅為1.3%[14]。這種源自語料層面的不平等,對文化安全等層面也將帶來深刻影響。哈爾濱工業大學長聘教授劉挺認為,語言成為輿論戰武器,而今的大模型能夠自動回答問題、發表評論、撰寫文章,使語言武器自動化了,其帶來的風險難以估量[15]。另外,牛津大學的一項研究表明,由于開放AI(OpenAI)等服務所采用的服務器成本衡量和計費的方式,英語輸入和輸出的費用要比其他語言低得多,其中簡體中文的費用大約是英語的2倍,西班牙語是英語的1.5倍,而緬甸的撣語(Shan)則是英語的15倍[16]。
2.1.4 弱可解釋性:智能涌現決定AI可預見性較弱
“涌現”(Emergence)一詞的概念是由劉易斯(George Henry Lewes)于1875年在《生命與心靈問題》(Problems of Life and Mind)著作中首次提出的。心理學家勞埃德·摩根(C. Lloyd Morgan)指出,類似的概念在邏輯學家密爾(J. S. Mill)和心理學家文特(W. Wundt)的理論中也能找到,他們普遍認同涌現是對無法從構成先前狀態的元素中預測出來的新現象的描述。“涌現”不同于“結果”,它通常無法根據現有元素進行預測,是一種突現,這些對涌現的定義與現代的定義和討論非常接近[17]。
ChatGPT之類的大語言模型被認為具備一定的涌現特征,也是機器智能的重要標志。但也有研究認為,大模型所謂的涌現能力是由于研究者選擇的度量標準而產生的,而不是模型行為在規模擴展中發生了根本變化。所謂的涌現能力會隨著不同的度量或更好的統計學而消失,并且可能不是縮放AI模型的基本屬性[18]。智能涌現一方面導致了AI生成知識的可解釋性弱,進而降低了機器生成內容的可信度;但另一方面也可能是知識發現與知識創新的源泉。
考慮到機器輸出知識的精確性和穩定性直接關乎出版行業對其生成內容的采納程度,因此必須解決機器生成知識的可驗證、可預見及可靠性。出版行業是具有高質量標準要求的知識處理行業,只有經過嚴格編校程序的知識才能最終面向公眾進行發布。
2.1.5 弱穩健性:知識輸出結果的可靠性受制于模型幻覺程度
大模型輸出的幻覺(Hallucination)問題和穩健性(又稱魯棒性)是影響AI生成知識可靠性中的重要影響因素,也是目前阻礙其在出版領域廣泛應用的原因之一,尚未找到徹底解決機器幻覺以提升知識系統穩健性的方法。因此,大模型應用于知識生成,需要經過人工環節進行驗證才可用于發布。大模型幻覺可分為事實性幻覺(Factuality Hallucination)和忠實性幻覺(Faithfulness Hallucination)兩類,前者指模型生成內容與可驗證的現實世界事實之間的不一致,后者指生成內容與用戶指令或輸入提供的上下文的偏離,以及生成內容本身的自洽性。大模型幻覺來自預訓練數據中的錯誤信息和偏見,本身的知識邊界也導致存在領域知識缺陷和過時的事實知識[19]。
大模型的幻覺問題與其模擬大腦的學習模式也有關系。心理學的研究揭示了大腦具備兩類思考系統,即系統1和系統2。“雙過程理論(Dual Process Theory)”也指出了大腦存在兩個思考系統,最早由心理學家基思·斯坦諾維奇(Keith Stanovich)和理查德·韋斯特(Richard F. West)率先提出[20],后來諾貝爾經濟學獎得主丹尼爾·卡內曼在其著作《思考,快與慢》(Thinking, Fast and Slow)對其進一步闡發。系統1的運行是無意識且快速的,不怎么費腦力,沒有感覺,完全處于自主控制狀態。系統2將注意力轉移到需要費腦力的大腦活動上來,例如復雜的運算[21]。系統1依賴情感、記憶和經驗對外界做出迅速判斷,但也容易“上當”并產生錯覺。大模型的幻覺問題的產生與其所采取的自監督學習進行預訓練的技術路徑有關,后者接近大腦系統1的學習模式。麻省理工學院綜合計算神經科學(ICoN)中心的研究人員發現,當他們使用特定類型的自我監督學習來訓練神經網絡模型時,所得模型生成的活動模式與執行相同任務的動物大腦中看到的活動模式非常相似[22]。解決大模型幻覺問題的厚望被寄予在大模型和知識圖譜技術的協同發展上,知識圖譜技術被認為是建立可解釋的AI的重要路徑,與大模型技術具有很好的互補性,正如大腦的兩個系統相互補充一樣。
2.2 大模型知識處理方式
人腦通過從環境中習得、加工和生成信息,最終將其作為適應環境的一種方式。在這個過程中,人作為目標,而知識則成為實現這一目標的手段。大腦的生物神經網絡自帶編解碼能力,大腦既是知識的生產者也是知識的獲取者。大模型則借助機器神經網絡將知識輸出作為目標,以人類反饋作為增強機器知識能力的手段。知識生產就是模型應用和結果調取的過程。大模型基于自注意力機制的深度神經網絡模型處理人類發布的存量文本并進行知識發現與生成,其對齊能力、泛化能力和更新能力仍然存在一定局限性(見表5)。
3 生成式AI賦能的知識傳播新形態
知識封裝更多是從媒介技術對出版產品帶來的影響出發考慮生成式AI出版產品的新形態和新業態,而知識傳播更多從用戶知識獲取的視角來考慮在生成式AI技術中介下所形成的用戶獲取知識和媒介知識供給的新變化。考慮到OpenAI在產品化方面的豐富經驗及其帶來的示范效應將波及各行各業,其中也包括出版業。其已開發的ChatGPT、Sora及正在開發的智能體(AI Agents)等產品類型將預示著未來生成式AI應用于知識傳播場景的三個重要方向,分別是對話式知識服務產品、多模態知識大模型及知識智能體。
3.1 信息交互方式:基于對話的知識提取
像ChatGPT之類的生成式AI產品是以對話形式封裝的信息和知識系統,自然語言成為人機知識互動的基礎,人機交流始于提示詞(Prompt),終于答案輸出(Output)。類人對話能力的背后是大模型對海量文本語料的學習,包括語言學知識和世界性知識。將大模型視為知識庫,人類通過設計提示詞,可以很好地提取其中蘊含的豐富知識。有學者認為,AI產品ChatGPT作為數字智能界面,絕不僅是提供了一個“類人性”對話主體,而是實現了超大語言模型系統與人類感官系統史無前例的交互,這是一個嶄新的交互界面,也是一種新型主體樣態,ChatGPT“類人性”形式表面所隱藏的,是超越人類的新型認知系統[23]。
在AI對話式生成系統誕生前,傳統的人機交互界面大多是圖形用戶界面(Graphical User Interface,GUI),雖然圖形界面設計一直強調用戶體驗優化,但依然不如自然語言使用來得直接和普遍。生成式AI采取自然用戶界面(Natural User Interface,NUI),不需要借助圖形交互工具和行為便能夠應對廣泛的知識交互場景。考慮到自然語言本身可能存在的表達局限性,目前并不能完全替代圖形交互。“交流的無奈”“一圖勝千言”現象的存在更是提醒人們不要把通過自然用戶界面進行信息交互看成萬能的交流方式。通過自然用戶界面能夠從大模型中提取知識,意味著大模型被封裝為一種動態供給的知識庫,知識主要以文本形式加以存儲。
3.2 多模態知識傳播:知識虛擬可視化與多模態表示
比斯克(Yonatan Bisk)等[24]曾構建了一個“世界范圍(World Scope)”五層次模型來表示自然語言處理所需要的不同文本來源,分別是小規模語料庫(世界1)、互聯網文本(世界2)、多模態文本(世界3)、具身(世界4)、社交互動(世界5),我們正處在世界2向世界3轉換的進程中,未來將進一步發展到世界4和世界5。在世界3中,知識以多模態的形式生成、傳播和獲取。多模態生成式AI將加速虛擬出版時代的到來,知識的空間可視化表達、知識的演化仿真設計和知識的多模態獲取將成為知識傳播形態創新的方向。虛擬化技術賦能的知識空間化存儲、空間化計算和空間化表達,成為多模態知識傳播未來發展的重要方向。數字博物館、多模態計算[25]及新形態出版物成為未來知識多模態組織和多模態傳播的重要形態。生成式AI技術與虛擬現實技術將進一步融合推動虛擬內容智能生成。
3.3 知識智能體:從被動應答到自主行動
如果說對話式生成還停留在人機知識交流的層面,那么基于大模型的AI智能體(Agents)則超越對話,目標進一步指向機器決策乃至自主行動,即具身智能(Embodied Artificial Intelligence)。AI智能體將大模型作為大腦,通過信息交互來感知外界變化,最終作出自主行動,實現特定的任務。智能體這一概念起源于哲學,其根源可追溯到亞里士多德和休謨等思想家,它描述了擁有欲望、信仰、意圖和采取行動能力的實體。在AI研究領域,智能體是用來描述展示智能行為并具有自主性、反應性、主動性和社會能力等特質的實體,AI智能體通常被認為是實現通用AI(Artificial General Intelligence,AGI)的重要步驟[26]。OpenAI公司AI應用研究主管翁麗蓮(Lilian Weng)在一篇關于AI智能體的網絡文章中提出了基于大模型構建自主智能體的應用框架:智能體包括LLM、記憶(Memory)、規劃技能(Planning)和工具使用(Tool Use)等要素,其中大模型是智能體的大腦,其他是關鍵的組成部分[27]。大模型未來將逐漸向大腦功能逼近,在虛擬環境中成長并與現實環境交互,成為自主適應復雜環境甚至自主行動的智能體。未來的知識智能體將可能以自主方式開展知識傳播活動,進而改變人類的知識交流方式。
4 結語
生成式AI是一種知識封裝技術,它以全面性的知識占有、自然的人機交流模式和強大的知識推理能力改變著人類知識傳播的形態,將人類帶進了生成式傳播的時代。以知識傳遞為重要使命的出版業,將不可避免地遭受生成式AI技術帶來的沖擊。積極探索生成式AI背景下的新出版方式和新傳播形態,不斷改進知識生產與傳播效果,將為出版業轉型升級帶來歷史性重要機遇。
作者簡介
易龍,男,博士,中南大學人文學院傳媒系主任,副教授。研究方向:數字出版、智能傳播。
參考文獻
[1]張志強,唐舸.網絡出版研究綜述[J].出版科學,2002(S1):66-73.
[2]徐麗芳.數字出版:概念與形態[J].出版發行研究,2005(7):5-12.
[3]張新雯,陳丹.微版權概念生成的語境分析及其商業模式探究[J].出版發行研究,2016(3):30-32.
[4]馮宏聲,王樞.變革與重塑:出版業與AI共創未來[J].數字出版研究,2023,2(4):1-7.
[5]周葆華.或然率資料庫:作為知識新媒介的生成智能ChatGPT[J].現代出版,2023(2):21-32.
[6]常江,朱思壘.作為知識生產的數字出版:媒介邏輯與文化生態[J].現代出版,2021(5):19-24.
[7]方卿,丁靖佳.AI生成內容(AIGC)的三個出版學議題[J].出版科學,2023,31(2):5-10.
[8]劉珍,趙云澤.技術邏輯、實現方式與現實邊界:生成式AI對出版業的深層影響[J].中國出版,2023(15):11-16.
[9]易龍.從數字出版到智能出版:知識封裝方式的演進[J].出版科學,2023,31(1):81-90.
[10]ACKOFF R L. From data to wisdom[J]. Journal of Applied Systems Analysis,1989,16(1):3-9.
[11]毛文濤.出版的當下與未來[J].出版與印刷,2023(6):26-31.
[12]邵文,方曉.陸奇最新演講審定版:大模型帶來的新范式和新機會[EB/OL].(2023-05-13)[2024-01-20].https://www.thepaper.cn/newsDetail_forward_23057456.
[13]陳昌鳳,黃陽坤.ChatGPT的知識功能與人類的知識危機[J].現代出版,2023(6):10-18.
[14]羅云鵬.大模型發展亟需高質量“教材”相伴[N].科技日報,2024-01-15(06).
[15]劉挺.從ChatGPT談大語言模型及其應用[J].語言戰略研究,2023,8(5):14-18.
[16]PETROV A, LA MALFA E, TORR P, et al. Language model tokenizers introduce unfairness between languages[EB/OL]. (2023-10-20)[2024-04-09]. https://arxiv.org/ftp/arxiv/papers/2305/2305.15425.pdf.
[17]EMMECHE C, K?PPE S, STJERNFELT F.Explaining emergence: Towards an ontology of levels[J].Journal for General Philosophy of Science,1997(28):83-117.
[18]SCHAEFFER R, MIRANDA B, KOYEJO S. Are emergent abilities of large language models a mirage?[EB/OL].(2023-05-22)[2024-04-09]. https://arxiv.org/pdf/2304.15004.pdf.
[19]HUANG L, YU W, MA W, et al. A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions[EB/OL].(2023-11-09)[2024-04-09]. https://arxiv.org/pdf/2311.05232.pdf.
[20]STANOVICH K E, WEST R F. Advancing the rationality debate[J]. Behavioral and brain sciences,2000,23(5):701-717.
[21]丹尼爾·卡尼曼.思考,快與慢[M].胡曉姣,李愛民,何夢瑩,譯.北京:中信出版社,2012:5.
[22]TRAFTON A. The brain may learn about the world the same way some computational models do[EB/OL]. (2023-10-30) [2024-01-28]. https://news.mit.edu/2023/brain-self-supervised-computational-models-1030.
[23]孫瑋,程陶然.AI界面:系統交互的革新[J].新聞記者,2023(8):3-12,61.
[24]BISK Y, HOLTZMAN A, THOMASON J, et al. Experience grounds language[EB/OL].(2020-11-01)[2024-04-09].https://arxiv.org/pdf/2004.10151.pdf.
[25]周葆華,吳雨晴.超越單一模態:多模態計算傳播研究的進展與前瞻[J].傳媒觀察,2024(1):16-27.
[26]XI Z, CHEN W, GUO X, et al. The rise and potential of large language model based agents: A survey[EB/OL].(2023-09-19)[2024-04-09]. https://arxiv.org/pdf/2309.07864.pdf.
[27]WENG L. LLM powered autonomous agents[EB/OL].(2023-06-23)[2024-01-26].https://lilianweng.github.io/posts/2023-06-23-agent.
Research on New Forms of Knowledge Packaging and Dissemination Driven by Generative Artificial Intelligence
YI Long
School of Humanities, Central South University, 410012, Changsha, China
Abstract: Development of knowledge packaging technology has driven the renewal of publishing forms. Ways in which knowledge is represented, extracted, generated and disseminated continue to evolve from database and search engine technologies to large language model technology. Generative artificial intelligence (GAI) can learn from various data texts and make inferential predictions, thereby outputting knowledge-based content. On the one hand, GAI is widely used in knowledge-packaging products due to its potential for knowledge generation; on the other hand, issues such as data exhaustibility, input dependency, inequality, weak interpretability, and weak robustness highlight the need to pay attention to the potential consequences of GAI. It is profoundly reshaping knowledge dissemination form through dialogical knowledge extraction, multimodal knowledge expression and knowledge agents. Understanding its evolutionary characteristics may lend a hand to better navigate this new type of knowledge system.
Keywords: Generative artificial intelligence; Knowledge packaging; Publishing form; Knowledge dissemination; Large language model
