
基于改進YOLO v5s的溫室番茄檢測模型輕量化研究
2024-06-03 03:17:25趙方左官芳顧思睿任肖恬陶旭
江蘇農業科學 2024年8期
趙方 左官芳 顧思睿 任肖恬 陶旭

摘要:番茄檢測模型的檢測速度和識別精度會直接影響到番茄采摘機器人的采摘效率,因此,為實現復雜溫室環境下對番茄精準實時的檢測與識別,為采摘機器人視覺系統研究提供重要的參考價值,提出一種以YOLO v5s模型為基礎,使用改進的MobileNet v3結構替換主干網絡,平衡模型速度和精度。同時,在頸部網絡引入Ghost輕量化模塊和CBAM注意力機制,在保證模型檢測精度的同時提高模型的檢測速度。通過擴大網絡的輸入尺寸,并設置不同尺度的檢測網絡來提高對遠距離小目標番茄的識別精度。采用SIoU損失函數來提高模型訓練的收斂速度。最終,改進YOLO v5s模型檢測番茄的精度為94.4%、召回率為92.5%、均值平均精度為96.6%、模型大小為7.1 MB、參數量為3.69 M、浮點運算(FLOPs)為6.0 G,改進的模型很好地平衡了模型檢測速度和模型識別精度,能夠快速準確地檢測和識別復雜溫室環境下的番茄,且對遠距離小目標番茄等復雜場景都能實現準確檢測與識別,該輕量化模型未來能夠應用到嵌入式設備,對復雜環境下的溫室番茄實現實時準確的檢測與識別。
關鍵詞:番茄;小目標檢測;YOLO v5s;輕量化網絡;注意力機制
中圖分類號:S126? 文獻標志碼:A
文章編號:1002-1302(2024)08-0200-09
收稿日期:2023-06-05
基金項目:江蘇省高等學校基礎科學(自然科學)研究面上項目(編號:22KJB140015);江蘇省無錫市創新創業資金“太湖之光”科技攻關計劃(基礎研究)項目(編號:K20221043);教育部產學合作協同育人項目(編號:220604210140248)。
作者簡介:趙 方(1997—),男,山東臨沂人,碩士,主要從事嵌入式人工智能。E-mail:zhaofang_1997@163.com。
通信作者:左官芳,碩士,高級工程師,主要從事嵌入式設計研究。E-mail:zgf@cwxu.edu.cn。
近年來,自高性能、低功耗、嵌入式處理器出現以來,越來越多的視覺檢測任務可以在嵌入式系統上實現,這使得農業機器人變得更加先進。在智慧農業背景下,用番茄采摘機器人代替人工采摘、降低人工成本、提高勞動生產率成為發展趨勢[1]。目前國內外相關文獻針對番茄檢測算法研究主要分為傳統目標檢測算法與深度學習目標檢測算法。
李寒等使用紅綠藍深度(RGB-D)相機捕捉圖像,對圖像進行預處理,得到水果輪廓,分離重疊水果的輪廓,并將其擬合成圓圈,將k均值聚類(KMC)與自組織映射(SOM)神經網絡算法相結合,對番茄進行識別,結果表明,輪廓提取受到光照的影響,對番茄的識別率僅為87.2%[2]。孫建桐等提出一種基于幾何形態學與迭代隨機圓的番茄識別方法,利用Canny邊緣檢測算法獲得果實邊緣輪廓點,并對果實邊緣輪廓進行幾何形態學處理,最后對果實輪廓點分組后進行迭代隨機圓的處理,試驗結果表明,對番茄識別的正確率為85.1%[3],但該研究沒有解決自然環境下番茄遮擋嚴重的問題。
傳統番茄檢測算法對番茄檢測的結果很容易受到光照、遮擋等影響導致番茄識別率低,同時傳統識別算法無法較好地達到精度和實時性平衡的要求,難以滿足實際需求。
近年來,隨著圖形處理器(GPU)計算能力的提升,深度學習被廣泛應用于各個領域,特別為智慧農業領域帶來了創新的解決方案[4]。目前基于深度學習算法的目標檢測算法主要可分為2類:one-stage與two-stage。One-Stage目標檢測方法的核心思想是使用單個卷積神經網絡(CNN)直接處理整個圖像來檢測物體并預測物體類別,它通常比two-stage更快,代表性的方法有單次多框檢測器(SSD)[5]和單次目標檢測器(YOLO)[6]。two-stage目標檢測方法的核心思想是首先生成候選區域,然后通過卷積神經網絡對區域進行分類,代表方法有基于區域的卷積神經網絡(R-CNN)[7]、快速區域卷積神經網絡(Fast R-CNN)[8]、更快的區域卷積神經網絡(Faster R-CNN)[9]、掩膜基于區域的卷積神經網絡(Mask-RCNN)[10]。
針對番茄生長環境復雜,枝葉對番茄遮擋影響番茄檢測與識別問題,張文靜等提出一種基于Faster R-CNN的番茄識別檢測方法,結果表明,平均精度達到83.9%,單樣本圖像處理時間為245 ms[11]。總體來看,該方法檢測時間過長且精度不高。為減少光照、遮擋的影響,Yuan等提出了一種基于SSD溫室場景櫻桃番茄檢測算法,試驗結果顯示,平均精度為98.85%[12]。但該模型耗時過長,難以滿足實時性要求。針對夜間光照不足影響檢測算法準確性問題,何斌等提出了一種改進YOLO v5的夜間番茄檢測模型,通過改進損失函數來構建檢測模型,結果表明,該模型的平均精度達到96.8%[13]。但該模型缺乏對枝葉遮擋以及番茄重疊問題的研究。
在復雜溫室環境中,番茄果實的姿態、大小、稀疏度和光照條件各不相同,在許多情況下,果實被枝葉嚴重遮擋,且當前算法對遠距離小目標番茄和輕量化番茄檢測模型的研究仍然不足。基于以上問題,本研究在自然光條件下收集了未成熟的綠色番茄和成熟的紅色番茄圖片構建數據集,使用改進MobileNet v3對YOLO v5s主干進行改進,在頸部網絡引入Ghost卷積和CBAM注意力機制,并改變網絡輸入大小和輸出網絡尺度大小,最后對原損失函數進行改進。
1 建立數據集
1.1 數據集采集
本研究的數據集拍攝于山東省蘭陵縣溫室大棚,拍攝時間為2023年1月5日09:00—16:00。番茄品種為愛吉158,所有圖片在距離番茄0.5~2 m 處進行多角度和不同光照條件下拍攝。選擇 1 200 張番茄圖片,存儲格式為.jpg,制作數據集,其中包含不同的光照條件、遮擋、重疊、遠距離小目標等復雜環境。
1.2 數據增強
為解決番茄受光照、遮擋等因素的影響,同時為了增強模型對小目標檢測能力及模型的魯棒性和泛化性,防止模型學習與目標無關的信息,避免樣本不平衡和過擬合現象,本研究采用數據增強技術[14]擴增數據集容量,對圖片進行裁剪、平移、改變亮度、加噪聲、旋轉角度、鏡像操作,使用Lableimg標注成熟的紅色番茄和未成熟的綠色番茄。由于綠色番茄在溫室環境下和綠色枝葉顏色相似,會造成目標檢測模型識別率低甚至漏檢的現象,所以本研究通過在數據集中增加綠色番茄圖片的比重,提高模型對綠色番茄的識別能力,將1 200張原始圖片按照1 ∶4擴展至6 000張圖片,訓練集、驗證集、測試集按照8 ∶1 ∶1進行分配,最終的數據集包含訓練集4 800張圖片、驗證集600張圖片、測試集600張圖片。對番茄進行圖像增強后的結果如圖1所示。
2 基于改進YOLO v5s的番茄識別網絡
2.1 YOLO v5s算法基本原理
YOLO v5網絡包括4種網絡模型:YOLO v5s、YOLO v5m、YOLO v5l、YOLO v5x。YOLO v5s是其中網絡深度和寬度最小的模型,越小的網絡模型對移動端的性能要求也越低,符合輕量化、實時性要求,因此本研究選擇在YOLO v5s網絡模型的基礎上進行改進。
YOLO v5s網絡分為4個部分:輸入、主干網絡、頸部和輸出。輸入端使用馬賽克數據增強、自適應錨框計算、自適應圖像縮放等方法。
主干網絡是一個可以提取圖像特征的CNN,它集成了Conv、C3、SPPF和其他特征提取模塊用于特征提取,其中Conv是YOLO v5s的基本卷積單元,依次對輸入進行二維卷積、正則化和激活操作。C3模塊采用殘差連接的設計思路,其結構分為2個分支,一支使用了卷積和Bottleneck,另一支僅經過基本卷積模塊,將2支進行Concat操作,最后經過基本卷積模塊。SPPF是基于SPP(spatial pyramid pooling)空間金字塔池化提出的,速度優于SPP,所以叫SPP-Fast,SPPF模塊使用3個不同的池化層,在特征圖執行這些池化操作之后,得到的結果將級聯在一起,形成一個固定大小的特征圖。它可以提高檢測精度,并且對不同大小的目標具有很好的適應性。
頸部采用FPN+PAN結構,FPN結構采用自頂向下的方法,利用上采樣將高層特征圖與低層特征圖融合,增強語義特征,提高對不同尺度物體的檢測。PAN結構采用自底向上路徑增強方法,將低層位置信息傳輸至高層,實現多尺度特征融合。FPN+PAN結構將提取的語義信息和位置信息融合,大大提高了模型的特征提取能力。
輸出端是一個包含3個不同尺度檢測頭的卷積層,它將網絡特征圖轉換為目標檢測結果。
2.2 改進YOLO v5s算法
番茄采摘機器人設計的難點在其視覺系統能否檢測和識別番茄目標,但是番茄生長在復雜環境下,番茄采摘機器人面臨光照變化、枝葉遮擋、重疊和遠距離小番茄難以識別的問題,同時番茄采摘機器人的工作效率與其視覺系統的檢測速度和識別精度有直接關系。因此,在復雜的環境下,研究快速、精確的識別和檢測番茄果實技術具有重要意義。
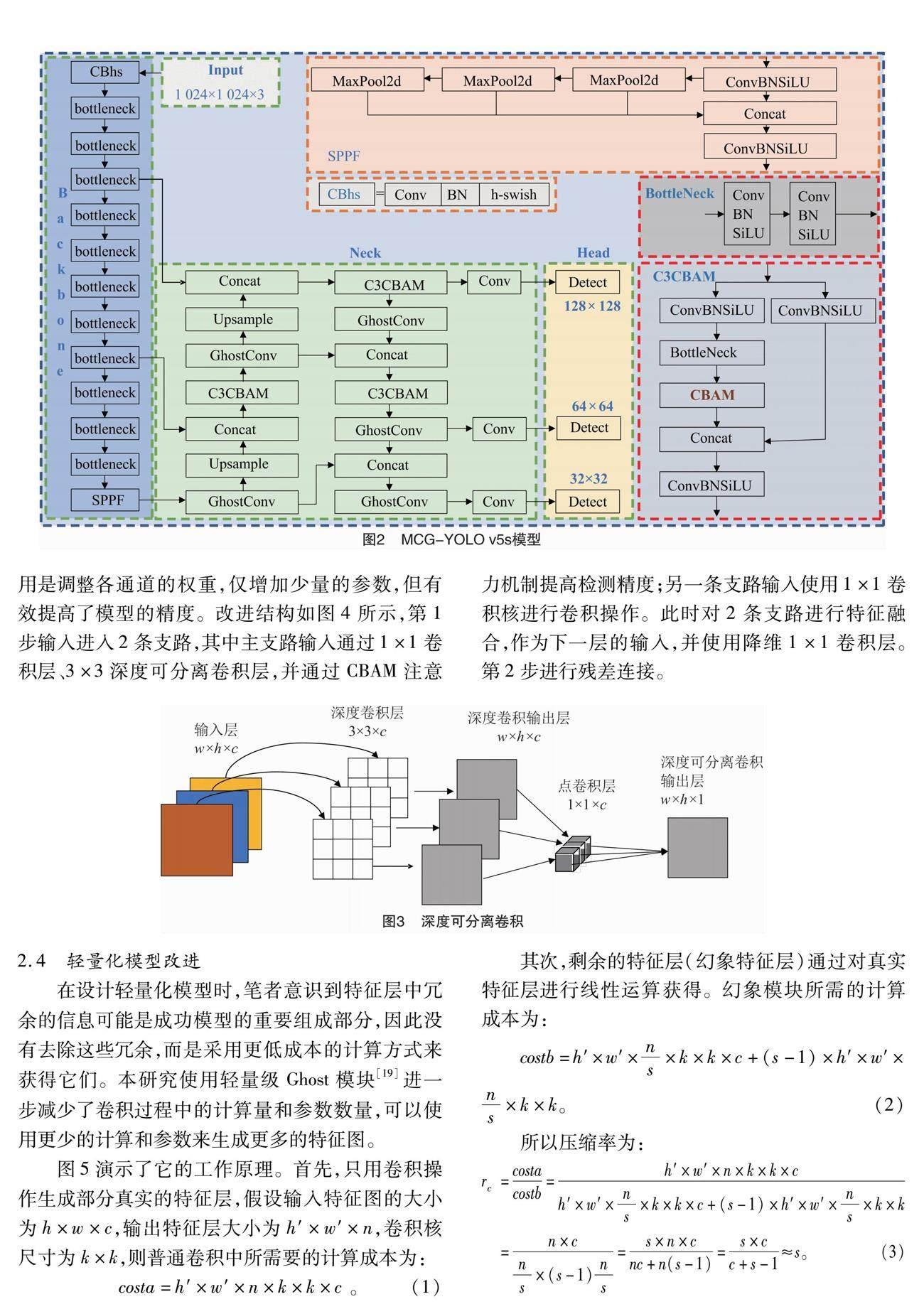
為構建輕量、高效的番茄檢測模型,本研究提出了MCG-YOLO v5s輕量化番茄檢測模型,模型如圖2所示。本研究對以下幾方面進行改進:首先,為實現番茄檢測速度與識別精度的平衡,使用改進的MobileNet v3取代YOLO v5s骨干網絡。其次,為進一步減少模型部署時所需的計算資源,提高模型的檢測速度,在頸部通過使用少量卷積與線性變換運算相結合的GhostConv代替頸部網絡中的普通卷積,實現進一步輕量化改進;使用C3CBAM代替原始C3,提高網絡對番茄特征提取能力,在空間和通道維度上更進一步準確提取番茄特征,使模型能準確定位和識別番茄;YOLO v5網絡的輸入圖像尺寸為640×640,預測頭部的輸出尺寸為80×80、40×40、20×20,由于遠距離小目標番茄圖像中目標特征較少,因此本研究為提高對小目標番茄的檢測精度,將網絡的輸入大小從640×640增加到1 024×1 024,將輸出的特征圖大小分別設置為128×128、64×64、32×32,通過擴大網絡的輸入大小和改變輸出網絡尺度的大小,克服遠距離圖像中番茄小目標漏檢問題。最后,SIOU作為改進算法的損失函數進一步提高模型訓練的收斂速度。
2.3 主干網絡改進
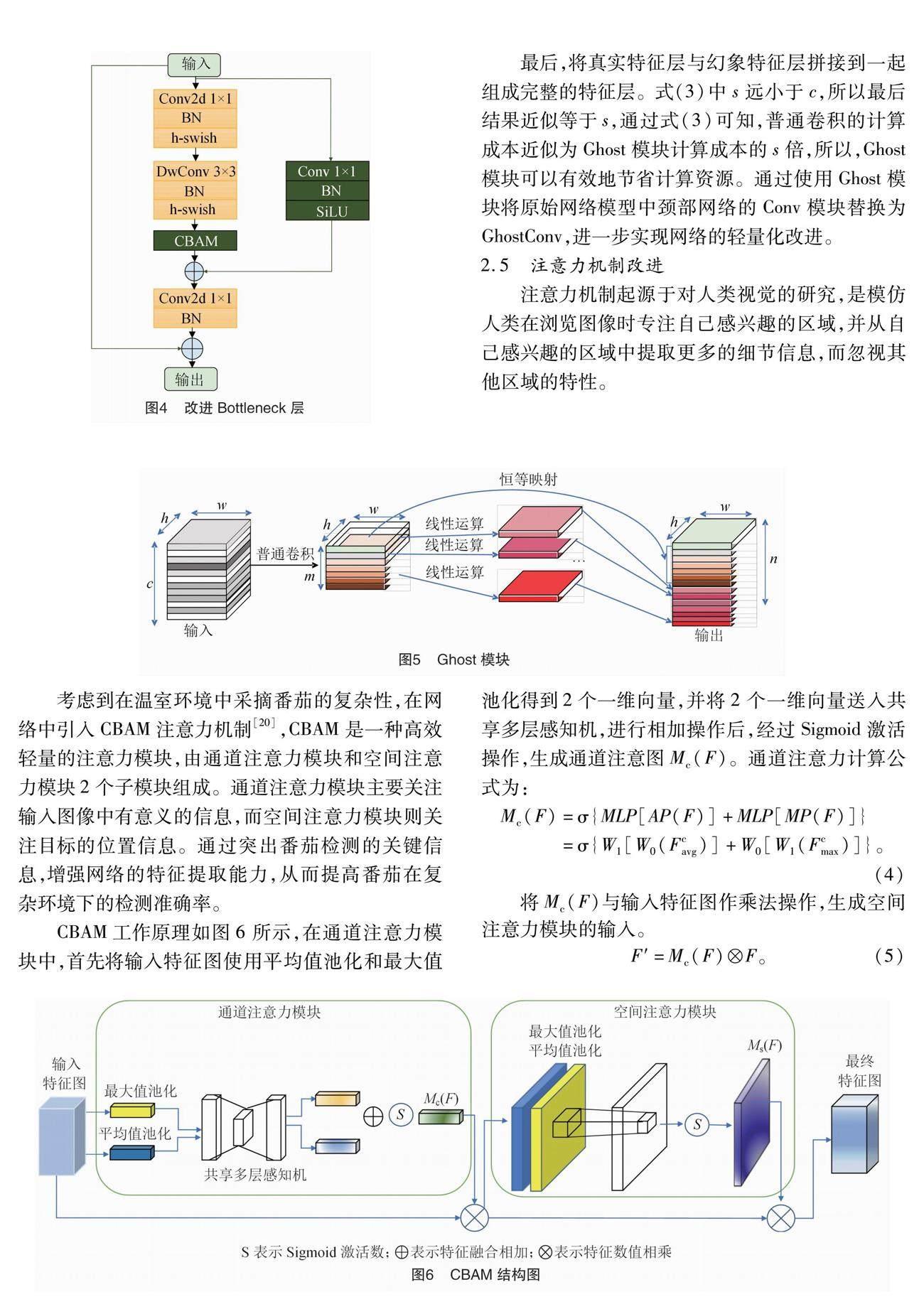
MobileNet v3[15]是一種輕量級的網絡架構,它結合NAS(neural architecture search)自動搜索技術和NetAdapt自適應算法來提高模型的性能和效率。首先,MobileNet v3使用了MobileNet v1[16]中的深度可分離卷積(depthwise separable convolution,DSC)。深度可分離卷積運算如圖3所示,分為深度卷積(depthwise convolution,DW)和逐點卷積(pointwise convolution,PW)2個步驟,深度卷積通過減少模型的參數量和計算量,使模型輕量化,逐點卷積將每個通道之間的信息進行交互和組合,從而提高網絡的表達能力。其次,MobileNet v3通過使用MobileNet v2[17]中的倒殘差結構使特征傳輸能力更好,并通過引入輕量化SE(squeeze and excitation)[18]注意力機制,更有利于通道信息來調整每個通道對應的權重。最后,MobileNet v2將原有的swish函數替換為h-swish激活函數,確保在參數數量一定的情況下,計算量大大減少,有效提高了模型的識別精度。本研究引入MobileNet v3模型主要是為了減少計算量,減小模型的尺寸,提高檢測精度。
從YOLO v5s中的C3設計模塊得到靈感,對原始MobileNet v3的bottleneck增加1個含有1×1卷積層的并行支路,目的是為了提高對小目標番茄的檢測精度,提高綠色背景下對綠色番茄特征提取能力,同時,由于2條支路的特征提取方式不同,可以使模型學習到不同的特征,提高模型的表達能力。考慮到CBAM模型將通道維度與空間維度結合,相比于只關注通道維度的ECA模型和SE模型,可以獲得更好的結果,所以本研究使用CBAM注意力機制將原MobileNet v3中的SE注意力機制替換,其作
用是調整各通道的權重,僅增加少量的參數,但有效提高了模型的精度。改進結構如圖4所示,第1步輸入進入2條支路,其中主支路輸入通過1×1卷積層、3×3深度可分離卷積層,并通過CBAM注意力機制提高檢測精度;另一條支路輸入使用1×1卷積核進行卷積操作。此時對2條支路進行特征融合,作為下一層的輸入,并使用降維1×1卷積層。第2步進行殘差連接。
2.4 輕量化模型改進
在設計輕量化模型時,筆者意識到特征層中冗余的信息可能是成功模型的重要組成部分,因此沒有去除這些冗余,而是采用更低成本的計算方式來獲得它們。本研究使用輕量級Ghost模塊[19]進一步減少了卷積過程中的計算量和參數數量,可以使用更少的計算和參數來生成更多的特征圖。
3.4 消融試驗
為了驗證各個改進模塊的作用,本研究進行消融試驗。從表1可以看出,該模型輕量化主要是因為使用改進MobileNet v3模塊替換原模型主干網絡,原模型主干網絡中的C3結構有較大參數量,增加了模型的復雜度,而MobileNet v3模塊中運用了深度可分離卷積而減少了模型參數量,同時改進的MoblieNet v3增加了1×1卷積模塊分支,提高了模型精度,與原始模型相比,均值平均精度提高了1.7百分點,參數減少了2.54 M,浮點運算減少了9.0 G,因此,使用改進MoblieNet v3替換主干網絡進行輕量化操作的同時,仍能保證精度。在模型的頸部中使用C3CBAM模塊,不但均值平均精度提高了2.8百分點,而且參數減少了0.49 M,浮點運算減少了 1.0 G,所以C3CBAM對提高模型精度起到了很大的作用。同時,在頸部使用Ghost卷積替換普通卷積,均值平均精度提高了2.1百分點,參數減少了0.51 M,浮點運算減少了0.6 G,實現對模型進一步輕量化操作。對原模型的損失函數進行改進后,模型的均值平均精度提高了0.6百分點。將這4項改進融入模型中,與原始YOLO v5s模型相比,均值平均精度提高了6.0百分點,參數降低3.54 M,浮點運算減少了10.6 G。結果表明,MCG-YOLO v5s通過輕量化改進降低了模型的復雜性,對番茄目標具有更好的檢測性能。
3.5 對比試驗
為了驗證本研究提出的輕量化番茄檢測模型的性能,選擇YOLO v3-tiny、YOLO v4-tiny、YOLO v5s與MCG-YOLO v5s進行比較和測試,所有模型都使用相同的番茄數據集進行訓練和測試,選擇精度、召回率、均值平均精度、模型大小、參數量和浮點運算作為評價指標,結果見表2。
表2顯示,與YOLO v3-tiny、YOLO v4-tiny、YOLO v5s相比,MCG-YOLO v5s模型的精度分別提高6.1、5.8、4.9百分點,召回率分別提高5.8、7.3、3.9百分點,均值平均精度分別提高5.1、6.5、6.0百分點。與輕量化模型 YOLO v3-tiny、YOLO v4-tiny 模型相比,MCG-YOLO v5s模型大小分別減少22.97、17.97 MB,參數量分別減少5.21、4.21 M,浮點運算減少2.6、3.2 G。
MCG-YOLO v5s模型大小為7.1 MB,參數量為3.69 M,浮點運算為6.0 G。結果表明,MCG-YOLO v5s模型體積最小,參數量、浮點運算最小,非常適合部署至算力不高的嵌入式邊緣設備,為番茄采摘機器人的視覺系統提供切實可行的參考方案,提高番茄采摘機器人自動采摘番茄的工作效率。
通過YOLO v5s與MCG-YOLO v5s模型對復雜溫室環境下的番茄圖片檢測進行可視化測試,驗證MCG-YOLO v5s模型的可行性。
可視化結果如圖9、圖10所示,對于多果、枝葉遮擋、光照不足的情形,YOLO v5s模型雖然能夠檢測與識別成熟的紅色番茄和未成熟的綠色番茄,但相比于MCG-YOLO v5s模型,YOLO v5s模型的精度低6~20百分點。對光照充足、番茄重疊、背景相似情形,YOLO v5s漏檢了圖片中的綠色番茄,這是由于綠色番茄與枝葉有相同的顏色,所以增加了模型的識別難度,然而MCG-YOLO v5s對于相似背景的綠色番茄具有更好的特征提取能力,能夠準確識別與檢測。對于單果情形,從圖9、圖10中可以看到枝葉嚴重遮擋了圖中的紅色番茄,導致YOLO v5s出現漏檢的情況,而MCG-YOLO v5s對嚴重遮擋的紅色番茄更友好,在嚴重遮擋環境下仍能準確識別與檢測。對于遠距離小目標番茄,YOLO v5s漏檢了圖片中的紅色番茄和綠色番茄;而MCG-YOLO v5s對于小目標番茄具有很強的識別能力,能識別與檢測圖中的遠距離小目標番茄,雖然圖中漏檢了幾個小目標番茄,但相比于YOLO v5s模型,MCG-YOLO v5s對小目標番茄的識別能力明顯提高了。
4 總結
本研究為實現在復雜溫室環境下對番茄進行準確實時檢測,提出一種MCG-YOLO v5s的番茄檢測模型,通過對YOLO v5s模型的改進,提高模型檢測速度與識別精度。首先是對數據集進行數據增強,提高對小目標番茄的檢測能力及模型魯棒性。其次在YOLO v5s中使用改進的MobileNet v3,改進后的MobileNet v3結構很好地平衡了番茄檢測模型的速度與精度;同時,使用Ghost模塊減少番茄檢測模型計算量,進一步實現模型輕量化,為提高模型的識別精度,引入CBAM注意力機制。最后對原損失函數改進,引入SIoU Loss,提高模型精度,同時也加快了模型的收斂速度。最終試驗結果表明,MCG-YOLO v5s的番茄檢測模型比原YOLO v5s模型,模型大小減少50.5%,參數量減少49.0%,浮點運算減少63.9%,均值平均精度提升6.0百分點。通過可視化檢測結果可知,MCG-YOLO v5s模型對遮擋嚴重番茄、重疊番茄、相似背景、小目標番茄的檢測與識別都有改善,魯棒性較好,檢測效果明顯優于未改進YOLO v5s,改進后的模型適用于復雜環境下對番茄進行實時檢測的任務,滿足對番茄準確識別且實時檢測的要求。
參考文獻:
[1] 王海楠,弋景剛,張秀花. 番茄采摘機器人識別與定位技術研究進展[J]. 中國農機化學報,2020,41(5):188-196.
[2]李 寒,陶涵虓,崔立昊,等. 基于SOM-K-means算法的番茄果實識別與定位方法[J]. 農業機械學報,2021,52(1):23-29.
[3]孫建桐,孫意凡,趙 然,等. 基于幾何形態學與迭代隨機圓的番茄識別方法[J]. 農業機械學報,2019,50(增刊1):22-26,61.
[4]封靖川,胡小龍,李 斌. 基于特征融合的目標檢測算法研究[J]. 數字技術與應用,2018,36(12):114-115.
[5]Liu W,Anguelov D,Erhan D,et al. SSD:single shot MultiBox detector[M]//Computer Vision-ECCV 2016.Cham:Springer International Publishing,2016:21-37.
[6]Redmon J,Divvala S,Girshick R,et al. You only look once:unified,real-time object detection[C]//2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas,2016:779-788.
[7]Girshick R,Donahue J,Darrell T,et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition.ACM,2014:580-587.
[8]Girshick R. Fast R-CNN[C]//Proceedings of the 2015 IEEE International Conference on Computer Vision. ACM,2015:1440-1448.
[9]Ren S Q,He K M,Girshick R,et al. Faster R-CNN:towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2017,39(6):1137-1149.
[10]He K M,Gkioxari G,Dollár P,et al. Mask R-CNN[C]//2017 IEEE International Conference on Computer Vision. Venice,2017:2980-2988.
[11]張文靜,趙性祥,丁睿柔,等. 基于Faster R-CNN算法的番茄識別檢測方法[J]. 山東農業大學學報(自然科學版),2021,52(4):624-630.
[12]Yuan T,Lyu L,Zhang F,et al. Robust cherry tomatoes detection algorithm in greenhouse scene based on SSD[J]. Agriculture,2020,10(5):160.
[13]何 斌,張亦博,龔健林,等. 基于改進YOLO v5的夜間溫室番茄果實快速識別[J]. 農業機械學報,2022,53(5):201-208.
[14]Shorten C,Khoshgoftaar T M. A survey on image data augmentation for deep learning[J]. Journal of Big Data,2019,6(1):60.
[15]Howard A,Sandler M,Chen B,et al. Searching for MobileNet v3[C]//2019 IEEE/CVF International Conference on Computer Vision. Seoul,2019:1314-1324.
[16]Howard A G,Zhu M,Chen B,et al. Mobilenets:effificient convolutional neural networks for mobile vision applications[EB/OL].(2017-04-17)[2023-04-24]. https://arxiv.org/abs/1704.04861.
[17]Sandler M,Howard A,Zhu M L,et al. MobileNet v2:inverted residuals and linear bottlenecks[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City,2018:4510-4520.
[18]Hu J,Shen L,Sun G. Squeeze-and-excitation networks[C]//2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition.Salt Lake City,2018:7132-7141.
[19]Han K,Wang Y H,Tian Q,et al. GhostNet:more features from cheap operations[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition. Seattle,2020:1577-1586.
[20]Woo S,Park J,Lee J Y,et al. CBAM:convolutional block attention module[M]//Computer Vision-ECCV 2018.Cham:Springer International Publishing,2018:3-19.
[21]Zheng Z H,Wang P,Ren D W,et al. Enhancing geometric factors in model learning and inference for object detection and instance segmentation[J]. IEEE Transactions on Cybernetics,2022,52(8):8574-8586.
[22]Zheng Z H,Wang P,Liu W,et al. Distance-IoU loss:faster and better learning for bounding box regression[J]. Proceedings of the AAAI Conference on Artificial Intelligence,2020,34(7):12993-13000.
[23]Gevorgyan Z. SIoU loss:more powerful learning for bounding box regression[EB/OL]. (2022-05-25)[2023-04-24]. https://arxiv.org/abs/2205.12740.
