基于自適應注意力機制的表格結構識別模型
2024-06-07 20:09:27鄭劍鋒張廣濤劉英莉
化工自動化及儀表 2024年3期
鄭劍鋒 張廣濤 劉英莉

基金項目:國家自然科學基金(批準號:52061020)資助的課題;云南計算機技術應用重點實驗室開放基金(批準號:2020103)資助的課題。
作者簡介:鄭劍鋒(1997-),碩士研究生,從事計算機視覺、文檔分析的研究。
通訊作者:劉英莉(1978-),副教授,從事機器學習、自然語言處理的研究,lyl@kust.edu.cn。
引用本文:鄭劍鋒,張廣濤,劉英莉.基于自適應注意力機制的表格結構識別模型[J].化工自動化及儀表,2024,51
(3):449-455.
DOI:10.20030/j.cnki.1000?3932.202403012
摘 要 針對圖像中表格結構識別問題,提出了基于自適應注意力機制的編碼-解碼架構,預測圖像中表格的HTML標簽。采用輕量化LCNet和CSP?PAN作為特征編碼網絡,獲得全局圖像特征;為解碼器設計自適應注意力機制,在解碼器的每個時間步驟添加語義特征,使模型自主選擇關注圖像信息或語義特征。另外,為提升研究效率,對訓練圖片數量與模型準確率之間的關系進行研究,結果表明合適的圖像數量在70k~100k之間,實驗從公開數據集PubTabNet中隨機選擇100k圖片進行訓練,模型的TEDS?Struct分數達到了95.1%。
關鍵詞 表格結構識別 注意力機制 文檔智能 深度學習 模式識別 圖像描述
中圖分類號 TP18?? 文獻標志碼 A?? 文章編號 1000?3932(2024)03?0449?07
文檔中的表格通常承載著特定主題的重要信息,將文檔圖像中的表格解析為機器可讀的HTML標簽是文檔智能分析中的一項具有挑戰性的特色任務[1]。表格結構識別的方法多樣,許多研究者選擇通過編碼-解碼結構的模型,利用編碼器抽取圖像特征、解碼器生成標簽。而表格的HTML標簽同時具有視覺性和非視覺性,已有方法只考慮了圖像信息,缺乏視覺信息和語義信息的動態融合。
為解決這一問題,筆者在圖像的空間注意力基礎上,添加自適應注意力模塊,為不同標簽分配語義注意力權重。另一方面,由于公開數據集數量龐大,為了提高算法研究效率,筆者研究了圖片數量與模型準確率之間的關系,以找出最合適的訓練集樣本數量。
1 相關工作
目前國內外學者提出了很多基于深度學習的表格結構識別方法,大致可分為3類:將表格視作圖像使用圖神經網絡進行處理的方法;將結構識別視作圖像領域的定位或分割任務;使用圖像描述方法直接從表格圖像中預測出代表結構的標簽序列。LI Y等將表格的每個文本單元視作圖節點,使用K臨近算法建圖,通過圖卷積算法處理每個節點的鄰接關系,最終計算出正確的表格結構[2],這類方法的局限在于建圖的難度較大且不適合處理復雜表格。將表格的文本單元視為待識別對象進行圖像目標的檢測也是常見手段,如CascadeTabNet表格檢測網絡[3],在定位表區域后進一步檢測表單元格,進而解析出表格結構;ZHANG T等提出了LRCAANet,在特征提取階段結合通道注意力機制,成功縮減了模型結構[4]。使用定位、分割方法進行表格結構識別的優點在于對表單元格位置的識別較為準確,使用同一種模型即可完成表格定位和結構識別任務,但這類方法通常需要人為設定后處理規則,用于構建表格單元之間的鄰接關系。
筆者采用圖像描述的方式進行表格結構識別,結合計算機視覺和自然語言處理技術,直接根據表格圖片生成表結構的標簽序列,避免冗余的后處理過程,使表結構的抽取過程更加簡潔,因此得到了大量關注。XU K等首次將基于注意力機制的編碼-解碼結構應用于圖像描述[5]。DENG Y T等通過在編碼階段添加遞歸層來捕獲水平空間依賴關系,從而將圖像中的數學公式轉成LATEX格式[6],同樣的模型也被用于Table2Latex數據集中,從表格圖像中生成LATEX格式的表格。為了促進基于圖像和深度學習的表格識別任務的研究,ZHONG X等公開了自動生成的PubTabNet數據集,使用雙解碼器結構同時進行結構解碼和單元內容解碼,并提出了新的表格識別任務評價指標——樹編輯距離相似度(Tree Edit Distance Based Similarity,TEDS)[7]。PubTabNet與TEDS也分別成為ICDAR2021科研文獻分析競賽[8]的數據集和評價指標。YE J等發布的TableMaster模型是ICDAR2021的解決方案之一,結合了ResNet的殘差模塊和多頭注意力模塊構成圖像編碼部分[9],使用基于Transformer[10]的解碼架構組成兩個分支分別預測結構和單元格坐標。與之類似的還有LI C等提出的SLANet[11],結合LCNet[12]和CSP?PAN[13]作為編碼網絡,解碼器由單層GRU構成,在循環網絡的每個輸出節點使用回歸網絡和結構識別網絡分別預測表格結構和單元格坐標,雖然精度與TableMaster相比略微下降,但模型尺寸遠小于前者。
受SLANet啟發,筆者構建的表格結構模型使用基于長短時記憶網絡(Long Short?term Memory,LSTM)[14]的解碼器結構,結合自適應注意力機制,使得在每個時間步驟,模型能夠選擇從圖像或語義信息中預測表格結構標簽和單元格坐標,最終提高表格結構識別的準確率。
2 表格結構識別
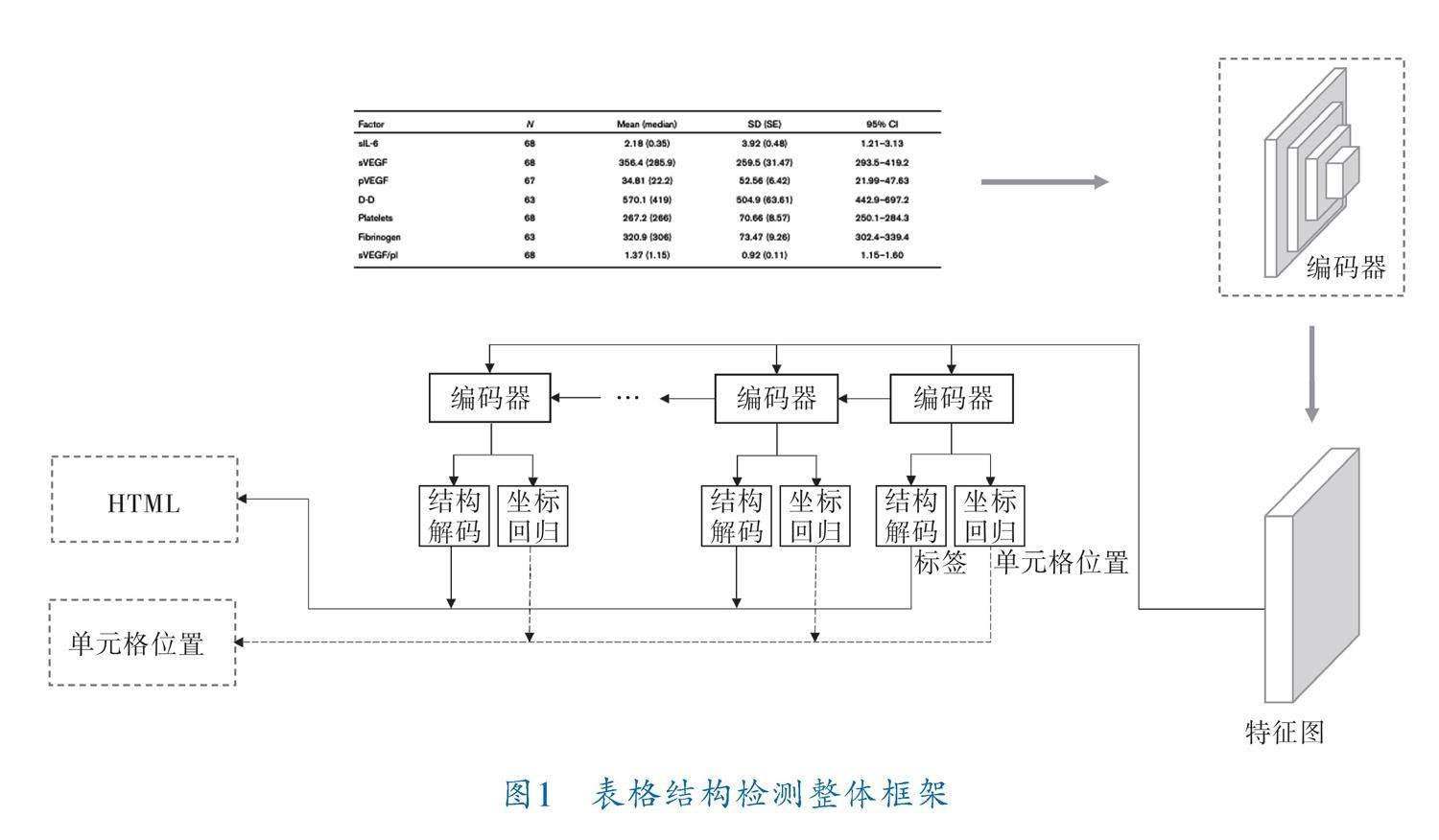
本節詳細描述了所提方法的整體結構,模型為編碼-解碼結構,其中編碼器采用基于卷積的深度神經網絡,主要用于提取圖片特征;解碼器主要用于解析表格結構和單元格坐標。整體框架如圖1所示。表格圖像輸入編碼器中獲得特征圖,特征圖將送入解碼結構進行解碼。每個步驟中解碼器的輸出都將送入結構解碼器(Structure Decoder,SD)和單元格坐標回歸器(Cell Regression,CR),分別生成結構標簽序列和單元格坐標,同一步驟生成的標簽和坐標一一對應,拼接所有步驟下生成的標簽即為該表格HTML表示。
2.1 編碼器結構
編碼器主要由骨干網絡和頸網絡組成,筆者使用輕量級的LCNet作為骨干網絡進行特征提取。為了能夠融合骨干網絡提取的特征,解決尺度變化帶來的性能下降,在骨干網絡后添加CSP?PAN作為頸網絡,在充分融合各層次特征的同時,降低了計算代價。編碼器結構如圖2所示,其中,LCNet采用DepthSepConv[12]作為基礎模塊,生成4層不同級別的特征圖。CSP?PAN網絡則結合了路徑聚合網絡(Path Aggregation Network,PAN)與局部跨階(Cross Stage Partial,CSP)模塊[13],用于融合不同層次的特征圖。
2.2 解碼器結構
解碼器由基于注意力機制的循環神經網絡(Recurrent Neural Networks,RNN)構成,具體包括LSTM、注意力模塊和最后的結構解碼模塊、坐標解碼模塊(圖3)。特征圖的長寬維度作為時間序列輸入,由遞歸網絡提取序列特性,結構解碼器只生成預先定義的表格結構HTML標記,位置編碼器負責生成表格單元位置。
圖3中,c為注意力1模塊產生的上下文向量;[c][^]為注意力2模塊最終生成的上下文向量;S為保留了前文語義信息的語義向量;y、l分別為結構解碼器和坐標解碼器生成的HTML標簽類別與單元格坐標;h為該時刻LSTM的隱藏層狀態;V為經過編碼器處理后的特征圖;x為當前步驟下LSTM的輸入。
由卷積編碼結構生成的特征圖V∈Rd×k和LSTM前一時刻的隱藏層狀態h可經空間注意模塊(圖3中注意力1模塊)生成當前步驟下特征圖k個網格的空間注意力分數α∈Rk,具體公式為:
z=Wtanh(WV+(Wh))(1)
α=softmax(z)(2)
其中,W、W∈Rk×d與Wh∈Rk均為可學習參數。
基于圖片的空間注意力分數可以得到僅包含圖像特征的圖片上下文特征向量c:
c=αv(3)
其中,v表示特征圖V的第i個網格的特征值,v∈Rd。
參照LSTM內部機制,可由下式計算得到語義特征向量S:
S=σ(Wx+Wh)☉tanh(m)(4)
其中,W為可學習參數;m為LSTM內部的記憶單元狀態。
基于前文所得到的語義向量S和圖片上下文特征向量c,通過應用自適應注意力機制(圖3中注意力2模塊)生成最終的上下文特征向量[c][^],計算式為:
[c][^]=βt St(1-β)c(5)
其中,β為語義注意力分數,其值越高,表示當前時刻模型更加關注語義信息而非圖像信息。β由下式計算的[α][^]得到:
[α][^]=softmax([z;W tanh(WS+Wh)])(6)
其中,W為可學習參數;[α][^]∈Rk+1,β=[α][^][k+1]。
兩個解碼器均由單層全連接神經網絡構成,最后的輸出y、l可由下式計算得出:
y=W[c][^](7)
l=W[c][^](8)
其中,W為可學習參數。
以上公式單獨將LSTM的語義向量分離出來,并賦予注意力機制,使得模型在生成下一個標簽類別時,自發地選擇關注圖像特征或語義特征。
3 實驗結果與分析
3.1 實驗背景
為了驗證筆者所提算法的有效性,在PubTabNet數據集上進行實驗。PubTabNet數據集是IBM澳大利亞研究院公開的基于圖像的表格識別數據集,包含了568k表格圖像以及相應的HTML結構化表示。在PubTabNet中,用“” “
常以準確率作為性能指標來評價表格結構識別算法的好壞。正確的預測結果意味著一張表格內所有結構標簽均與真實值相同。在PubTabNet中使用TEDS作為識別結果的度量方法,TEDS能夠同時識別結構錯誤和單元內容錯誤。筆者著重研究結構識別算法,且單元內容可由不同OCR算法進行識別,考慮到OCR的識別誤差可能影響比較結果,因此參照文獻[11,15]中的工作,除了準確率外,文中將忽略單元內容,使用TEDS?Struct作為評價方法。
文中使用在ImageNet上預訓練的LCNet網絡參數進行初始化以加快訓練速度。訓練過程中,采用Adam優化器,初始學習率設為0.001,并在50次迭代后調整為0.000 1,共進行70次迭代。訓練使用一塊NVIDIA 3090 GPU,訓練批大小設為48。
3.2 訓練集樣本數量對模型的影響
PubTabNet包含了大量數據集,從經驗來看,數據集數量越多,所訓練的神經網絡性能越好。為了有效使用計算資源,對訓練集樣本數量與準確率之間的關系進行評估。對原數據集的訓練樣本進行隨機采樣,產生6組數量不同的訓練集,其樣本數量分別為9k、18k、36k、72k、108k、200k,在使用同樣卷積的情況下,分別使用了文獻[11]與文獻[16]的方法進行測試,結果見表1。
神經網絡模型性能通常與訓練集樣本數量呈對數關系,參照文獻[17]所使用的建模方法,筆者通過最小二乘估計預測模型的性能,使用ln函數對其進行擬合,擬合曲線如圖4虛線所示,擬合函數為y=0.0889ln x+0.8039,其中x為歸一化后的訓練樣本數量,y為模型準確率。根據擬合曲線,當x=0.14時,曲線斜率為0.6,對應訓練樣本數
量為72k,此時訓練集樣本數量的增加對模型性能的提升開始變得有限;x從0.2(108k)到0.4(200k)時,準確率的提升約為0.05,在x超過0.4(200k)后,模型性能的提升沒有實質性改善。因此,后續的對比實驗將在訓練集樣本數量為108k條件下進行。
3.3 自適應注意力的有效性
筆者對不同注意力機制對解碼效果的影響進行了實驗,結果見表2,雖然使用LSTM的準確率
較GRU有所下降,但整體而言,結合筆者提出的自適應注意力機制能夠提升表結構識別的準確率。
表3展示了筆者所提方法與PubTabNet數據集上一些先進方法的對比,如EDD、LGPMA[18]和SLANet。可以看出,筆者所提方法對SLANet的改進基本保持了模型尺寸大小,但提升了準確率。
3.4 注意力機制可視化分析
為更好地分析解碼器中自適應注意力機制的工作原理,筆者對語義注意力分數和圖像中的空間注意力分數進行了可視化。
圖5展示了各個標簽的語義注意力分數,可以發現,所有的“”標簽均得到了很高的語義注意力分數。除此之外,由于HTML標簽的標記規則,所有表格的“”和“
”之后必定跟隨““
“
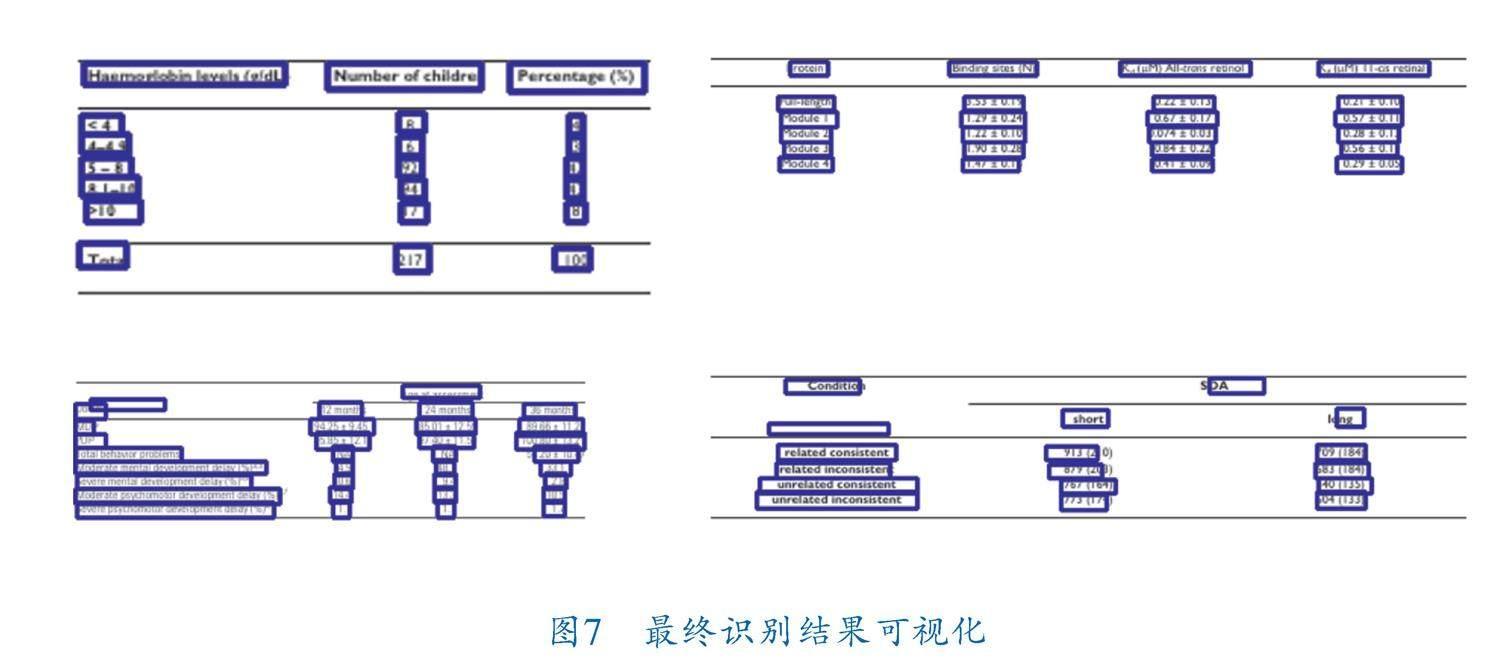
圖6展現了在預測不同標簽時,圖像特征中空間注意力機制對圖像各區域的關注程度。僅在預測“”時,空間注意力機制正確分辨出了表頭區域。當預測單元格標簽“ 模式,沒有傳達明確的行信息,導致注意力模塊始終關注圖像特征的局部信息,這也是后續工作中所要解決的問題。 如圖7所示,筆者從PubTabNet測試集中抽取了4張表格圖片進行了最終的可視化展示。可以看出筆者所提模型能夠準確預測表格結構和單元格坐標,雖然第2行圖像中,空單元格的坐標偏差較大,但不影響實際應用。 4 結束語 筆者探究了在表格結構識別問題中訓練集樣本數量對基于RNN預測模型的影響,實驗結果表明,模型樣本準確率與訓練集樣本數量呈對數關系,最有性價比的訓練樣本數量在70k~100k之間。同時,筆者提出了一種基于LSTM的表格結構識別方法,在應用圖像空間注意力機制的同時,拓展LSTM生成語義特征,并添加適應性注意力機制,為結構標簽的預測提供語義特征上的選擇,使模型能夠自主選擇需要關注的特征類別,通過實驗和可視化結果進一步驗證了自適應注意力機制的有效性,與僅使用圖像特征的空間注意力相比,自適應注意力機制提升了表格結構預測的準確性。 參 考 文 獻 [1]??? CUI L,XU Y,LYU T,et al.Document AI:Benchmarks,Models and Applications[J].Journal of Chinese Information Processing,2022,36(6):1-19. [2]?? LI Y,HUANG Z,YAN J,et al.GFTE:Graph?Based Financial Table Extraction[C]//Pattern Recognition ICPR International Workshops and Challenges.Berlin:Springer,2021:644-658. [3]??? PRASAD D, GADPAL A, KAPADNI K,et al.Cascade? TabNet:An approach for end to end table detection and structure recognition from image?based documents[C]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops.Piscataway,NJ:IEEE,2020:2439-2447. [4]?? ZHANG T,SUI Y,WU S Y,et al.Table Structure Recognition Method Based on Lightweight Network and Channel Attention[J].Electronics,2023,12(3):673. [5]??? XU K,BA J L,KIROS R,et al.Show,Attend and Tell:Neural Image Caption Generation with Visual Attention[C]//Proceedings of the 32nd International Conference on Machine Learning.Stroudsburg? PA,USA:Curran Associates Inc.,2015:2048-2057. [6]?? DENG Y T,KANERVISTO A,LING J,et al.Image?to?Markup Generation with Coarse?to?Fine Attention[C]//Proceedings of the 34th International Conference on Machine Learning.Sydney,NSW,Australia:JMLR.org,2017:980-989. [7]?? ZHONG X,SHAFIEIBAVANI E,JIMENO YEPES A. Image?Based Table Recognition: Data, Model, and Evaluation[C]//Computer Vision?ECCV 2020.Glasgow,UK:Spring,2020:564-580. [8]?? YEPES A J, ZHONG P,BURDICK D.ICDAR 2021 Competition on Scientific Literature Parsing[C]//International Conference on Document Analysis and Recognition.Lausanne, Switzerland:IAPR,2021:605-617. [9]??? YE J,QI X,HE Y,et al.PingAn?VCGroups Solution for ICDAR 2021 Competition on Scientific Literature Parsing Task B:Table Recognition to HTML[J/OL].arXiv,2021.https://doi.org/10.48550/arXiv.2105.01848. [10]?? VASWANI A,SHAZEER N,PARMAR N,et al.Atten? tion is all you need[C]//Proceedings of the 31st International Conference on Neural Information Proc? essing Systems.New York:Curran Associates Inc.,2017: 6000-6010. [11]?? LI C,GUO R,ZHOU J,et al.PP?StructureV2:A Stron? ger Document Analysis System[J/OL].arXiv,2022.https://doi.org/10.48550/arXiv.2210.05391. [12]?? CUI C,GAO T,WEI S,et al.PP?LCNet:A Lightweight CPU Convolutional Neural Network[J/OL].arXiv,2021.https://doi.org/10.48550/arXiv.2109.15099. [13]?? YU G H,CHANG Q Y,LV W Y,et al.PP?PicoDet:A Better Real?Time Object Detector on Mobile Devices [J/OL]. arXiv, 2021. https://doi. org/10.48550/arXiv.2111.00902. [14]?? GERS F,SCHMIDHUBER J,CUMMINS F.Learning to Forget:Continual Prediction with LSTM[C]//1999 Ninth International Conference on Artificial Neural Networks.Edinburgh,UK:IET,2000:850-855. [15]?? ZHENG X,BURDICK D,POPA L,et al.Global Table Extractor(GTE):A Framework for Joint Table Identi? fication and Cell Structure Recognition Using Visual Context[C]//2021 IEEE Winter Conference on Applications of Computer Vision.Piscataway,NJ:IEEE,2021:697-706. [16]?? LU J,XIONG C,PARIKH D,et al.Knowing When to Look:Adaptive Attention via a Visual Sentinel for Image Captioning[C]//2017 IEEE Conference on Computer Vision and Pattern Recognition.Piscataway,NJ:IEEE,2017:3242-3250. [17]?? SHAHINFAR S,MEEK P,FALZON G.“How many images do I need?” Understanding how sample size per class affects deep learning model performance metrics for balanced designs in autonomous wildlife monitoring[J]. Ecological Informatics, 2020, 57:101085. [18]?? QIAO L,LI Z,CHENG Z,et al.LGPMA:Complicated Table Structure Recognition with Local and Global Pyramid Mask Alignment[C]//Document Analysis and Recognition. Switzerland:ICDAR,2021:99-114. (收稿日期:2023-05-12,修回日期:2024-03-04) Table Structure Recognition Model Based on Adaptive Attention Mechanism ZHENG Jian?feng1,2, ZHANG Guang?tao1,2, LIU Ying?li1,2 (1. Faculty of Information Engineering and Automation, Kunming University of Science and Technology; 2. Yunnan Key Laboratory of Computer Technologies Applications) Abstract?? Aiming at recognizing table structure in images, an encoder?decoder architecture based on adaptive attention mechanism was proposed to predict tables HTML tags in images. Lightweight LCNet and CSP?PAN were adopted as feature coding networks to obtain global image features. In addition, an adaptive attention mechanism was designed for the decoder, and semantic features were added at each time step of the decoder so that the model can self?select to focus on the image information or semantic features. For purpose of improving research efficiency, the relationship between the number of training images and the accuracy of the model was studied to show that, the appropriate number of images stays between 70k and 100k. Training 100k images randomly selected from the public dataset PubTabNet shows that, the marks of TEDS?Struct of the model can reach 95.1%. Key words?? table structure recognition, attention mechanism, document AI, deep learning, pattern recognition, image description”時,空間注意力僅能正確關注列區域,但無法分辨表格中各行的差異,注意力機制始終在第1行的空間范圍內選擇關注區域,筆者認為原因在于表格的HTML標簽在不斷重復“ …
猜你喜歡
中成藥(2018年2期)2018-05-09 07:19:52電子測試(2017年23期)2017-04-04 05:06:50智能系統學報(2017年5期)2017-01-22 11:21:30江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29現代情報(2016年10期)2016-12-15 11:50:53新教育時代·教師版(2016年23期)2016-12-06 06:02:38法制與社會(2016年32期)2016-12-01 15:25:53軟件導刊(2016年9期)2016-11-07 22:20:49軟件工程(2016年8期)2016-10-25 15:47:34海軍航空大學學報(2015年1期)2015-11-11 17:17:57
主站蜘蛛池模板:
特级欧美视频aaaaaa|
无码AV日韩一二三区|
免费一看一级毛片|
午夜天堂视频|
在线中文字幕网|
2020国产在线视精品在|
在线观看精品自拍视频|
日韩在线视频网|
欧美日韩动态图|
一级毛片在线免费视频|
欧美日韩一区二区三区四区在线观看
|
色亚洲成人|
亚洲综合经典在线一区二区|
免费 国产 无码久久久|
免费人成黄页在线观看国产|
亚洲人成影视在线观看|
亚洲欧洲日韩综合色天使|
成人午夜免费观看|
天天躁夜夜躁狠狠躁图片|
国产成人三级在线观看视频|
黄色福利在线|
色天天综合|
欧美激情视频一区二区三区免费|
亚洲三级成人|
精品国产美女福到在线直播|
亚洲精品制服丝袜二区|
激情午夜婷婷|
亚洲精品自拍区在线观看|
亚洲天堂网在线视频|
国产精品久久久久久久久久98|
亚洲欧美在线精品一区二区|
国产最新无码专区在线|
亚洲精品黄|
亚洲女同欧美在线|
国产黄在线观看|
亚洲天堂网视频|
亚洲AV无码一区二区三区牲色|
成人午夜网址|
www.91中文字幕|
色偷偷综合网|
久草视频一区|
免费人成网站在线观看欧美|
九九久久99精品|
国产精品99一区不卡|
国产主播在线一区|
欧美国产精品不卡在线观看|
AV无码一区二区三区四区|
亚洲欧美激情小说另类|
精品無碼一區在線觀看 |
精品国产一区二区三区在线观看|
国产综合欧美|
亚洲国产综合精品一区|
无码啪啪精品天堂浪潮av|
久夜色精品国产噜噜|
久久黄色小视频|
日韩欧美中文字幕一本|
欧美精品H在线播放|
国产精品无码久久久久AV|
日本亚洲欧美在线|
国产在线精品美女观看|
久久永久精品免费视频|
亚洲丝袜第一页|
99久久国产综合精品2023|
2022国产91精品久久久久久|
91精品国产自产在线老师啪l|
a级毛片毛片免费观看久潮|
亚洲成网777777国产精品|
91成人在线观看|
精品久久久久久久久久久|
国产三区二区|
中文字幕久久亚洲一区|
亚洲永久色|
日韩亚洲综合在线|
国产视频自拍一区|
亚洲无码高清一区二区|
亚洲有无码中文网|
中文字幕色在线|
成年女人a毛片免费视频|
国产高清国内精品福利|
亚洲天堂视频网|
亚洲人精品亚洲人成在线|
国产精品视屏|
