基于神經網絡的VSLAM綜述
2024-06-20 20:18:58尚光濤陳煒峰吉愛紅周鋮君王曦楊徐崇輝
南京信息工程大學學報 2024年3期
尚光濤 陳煒峰 吉愛紅 周鋮君 王曦楊 徐崇輝
摘要:傳統的基于視覺的SLAM技術成果頗豐,但在具有挑戰性的環境中難以取得想要的效果.深度學習推動了計算機視覺領域的快速發展,并在圖像處理中展現出愈加突出的優勢.將深度學習與基于視覺的SLAM結合是一個熱門話題,諸多研究人員的努力使二者的廣泛結合成為可能.本文從深度學習經典的神經網絡入手,介紹了深度學習與傳統基于視覺的SLAM算法的結合,概述了卷積神經網絡(CNN)與循環神經網絡(RNN)在深度估計、位姿估計、閉環檢測等方面的成就,分析了神經網絡在語義信息提取方面的優點,以期為未來自主移動機器人真正自主化提供幫助.最后,對未來VSLAM發展進行了展望.
關鍵詞同時定位和地圖構建(SLAM);深度學習;卷積神經網絡(CNN);循環神經網絡(RNN);位姿估計;閉環檢測;語義
中圖分類號TP242;TP391.41
文獻標志碼A
0引言
移動機器人執行任務的首要前提是確定自己在所在環境中的位置[1].室外空曠環境下,基于GPS的定位方法可以基本滿足機器人的定位需求,但有時接收不到GPS信號[2].室內環境中,通常需要提前設立導航信標如二維碼、磁條等,這大大限制了移動機器人的應用范圍[3].大多數情況下,移動機器人需要自主完成某些任務,這就要求機器人可以適應足夠陌生的環境.因此,能夠在未知環境中進行定位和地圖構建的SLAM(SimultaneousLocalizationandMapping)[4]技術成為自主移動機器人必備的能力.根據所使用的傳感器不同,SLAM技術主要分為激光SLAM與視覺SLAM(VSLAM)[5].與激光SLAM相比,VSLAM與人眼類似,主要以圖像作為環境感知信息源,更符合人類的認知.近年來,由于相機具有廉價、易安裝、可以獲得豐富的環境信息、易與其他傳感器融合等優勢[6],基于相機的VSLAM研究受到了科研人員的廣泛關注,大量以視覺為基礎的SLAM算法應運而生[7].
隨著深度學習的快速發展,不少學者嘗試采用深度學習的方法解決視覺SLAM所遇到的問題.深度學習可以根據具體問題學習更強大和有效的特征,并成功地展示了一些具有挑戰性的認知和感知任務的良好能力.最近的工作嘗試包括從單目圖像中對場景進行深度估計,以及視覺里程計和語義映射生成等.權美香等[8]對傳統的VSLAM進行了詳細總結,并對比了不同方法的優缺點;胡凱等[9]從視覺里程計的角度,對VSLAM的發展做了概述,并介紹了深度學習在VSLAM中的應用;劉瑞軍等[10]從里程計、閉環檢測等方面介紹了深度學習與VSLAM的結合,并與傳統方法進行了對比;李少朋等[11]將基于深度學習的VSLAM與傳統的VSLAM進行了對比,并展望了未來發展方向.上述文獻大多僅從深度學習角度講述部分方法,未詳細介紹典型神經網絡與傳統VSLAM的結合,也未將整個發展脈絡完整展開.本文首先概述了VSLAM發展脈絡,然后從深度學習的兩個主要的神經網絡,即卷積神經網絡(ConvolutionalNeuralNetwork,CNN)與循環神經網絡(RecurrentNeuralNetwork,RNN)入手,重點闡述了神經網絡在VSLAM系統中深度估計、位姿估計、閉環檢測,以及數據融合等方面的貢獻,并介紹了神經網絡在語義信息提取方面的優勢,最后對VSLAM的發展做出總結和展望.CNN和RNN,并列舉了部分優秀的VSLAM算法;第2節闡述了CNN與VSLAM的結合,并從單目深度估計、位姿估計、閉環檢測3個方面詳細總結了VSLAM的發展進程;第3節重點介紹了RNN與視覺慣性數據融合方面的優勢,并給出了神經網絡與傳統VSLAM結合的部分優秀方案;第4節為總結,并對未來VSLAM的發展做出了展望.
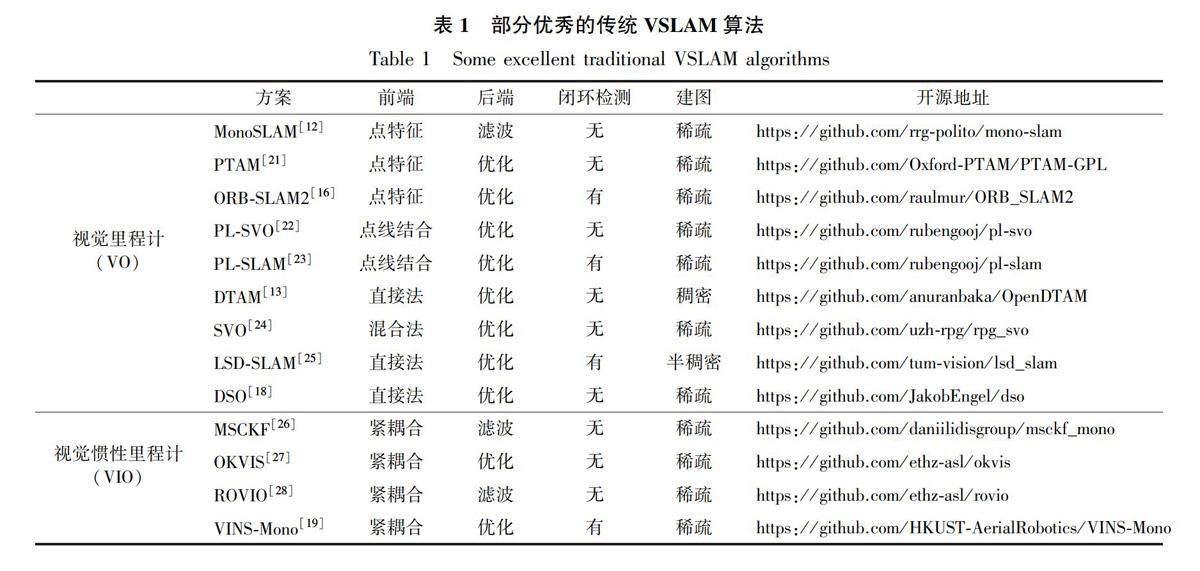
1神經網絡與VSLAM概述
傳統的VSLAM研究已經取得了諸多令人驚嘆的成就.2007年,Davidson等[12]提出了首個實時的單目VSLAM算法——MonoSLAM,該算法可實現實時無漂移的運動結構恢復.2011年,Newcombe等[13]提出了DTAM算法,該算法被認為是第一個實際意義上的直接法VSLAM.2015年,Mur-Artal等[14]提出了ORB-SLAM算法,創新地使用跟蹤、局部建圖和閉環檢測3個線程同時進行,有效地降低了累計誤差.閉環檢測線程采用詞袋模型BoW[15]進行閉環的檢測和修正,在處理速度和構建地圖的精度上都取得了很好的效果.隨后幾年,Mur-Artal團隊相繼推出了ORB-SLAM2[16]與ORB-SLAM3[17].ORB-SLAM系列是基于特征點提取方法中的佼佼者,它將傳統VSLAM方法發展到了十分完善的程度.2018年,Engel等[18]提出了可以有效利用任何圖像像素的DSO算法,它是直接法中的經典,其在無特征的區域中也具有良好的魯棒性,并得到了廣泛使用.2018年,香港科技大學團隊推出了單目慣性緊耦合的VINS-Mono[19]算法,該算法是視覺慣性融合SLAM中最優秀的算法之一,它充分利用慣性測量單元(InertialMeasurementUnit,IMU)與單目相機的互補性,改善了具有挑戰性環境中的定位精度.表1根據前端所用傳感器不同,從視覺里程計(VisualOdometry,VO)及視覺慣性里程計(Visual-InertialOdometry,VIO)兩方面列舉了部分優秀的傳統VSLAM方案,并給出了其開源地址.
傳統方法多采用基于特征提取的間接法或者直接對像素進行操作的直接法.雖然在大多數環境中傳統方法可以穩定運行,但是在光照強烈、相機快速旋轉或是動態物體普遍存在等環境中魯棒性會大大降低,甚至可能會失效.近年來,深度學習的快速發展吸引了諸多學者的目光,將深度學習的方法與傳統VSLAM相結合成為廣受關注的研究領域[20].
深度學習可以學習不同數據中的特征或者是數據之間的某種關聯,學習得到的特征屬性與關聯關系都可以用于不同的任務中[29].深度學習通過層次化的處理方式,對視覺數據進行學習,得到數據的抽象表達,在圖像識別、語義理解、圖像匹配、三維重建[30]等任務中取得了顯著的成果[31].作為深度學習中兩個重要的神經網絡,CNN與RNN在多個領域取得了很高的成就,圖1為CNN和RNN的基本框圖,表2中給出了兩者主要特點的對比.CNN可以從圖像中捕捉空間特征,準確地識別物體以及它與圖像中其他物體的關系[32].RNN可以有效地處理圖像或數值數據,并且由于網絡本身具有記憶能力,因此可以學習具有前后相關的數據類型[33].此外,其他類型的神經網絡如深度神經網絡(DeepNeuralNetwork,DNN),在VSLAM領域也有一些嘗試性的工作,但尚在起步階段.如表3所示,結合深度學習進行VSLAM的研究已經有了許多突破性的進展.部分學者建議使用深度學習的方法替換傳統SLAM的某些模塊,如深度估計、閉環檢測、位姿估計等,從而改善傳統方法.這些方法都取得了一定效果,在不同程度上提高了傳統方法的性能.后文將從CNN和RNN兩個神經網絡入手,重點講述它們與傳統VSLAM的結合.
2CNN與VSLAM
CNN以一定的模型對事物進行特征提取,而后根據特征對該事物進行分類、識別、預測或決策等,可以對VSLAM的不同模塊提供幫助.
2.1單目深度估計
基于單目相機的VSLAM算法由于傳感器成本低、簡單實用,受到了諸多學者的喜愛.單目相機只能得到二維的平面圖像,無法獲得深度信息.簡單地說,單目的局限性主要在于無法得到確定尺度[53].CNN在圖像處理方面的優勢已得到充分驗證,使用CNN進行視覺深度估計,最大程度上解決了單目相機無法得到可靠的深度信息的問題[54].
2017年,Tateno等[34]在LSD-SLAM的框架上提出了基于CNN的實時SLAM算法CNN-SLAM.該算法用CNN做深度預測將其輸入到后續的傳統位姿估計等模塊,用來提升定位和建圖精度.此外,該算法利用CNN提取環境的語義信息,進行全局地圖和語義標簽的融合,提高了機器人的環境感知能力.類似利用CNN預測深度信息的工作還有Code-SLAM[36]以及DVSO[37]等.但上述方法只在某個方面利用了CNN的優勢,Yang等[42]提出的D3VO則從3個層面利用了CNN,包括利用深度學習進行深度估計、位姿估計以及不確定度估計Σ.如圖2所示,D3VO將預測深度(D)、位姿(Tt-1t)以及不確定度緊密結合到一個直接視覺里程計中,來同時提升前端追蹤以及后端非線性優化的性能.所提出的單目深度估計網絡的核心是自監督訓練體制,這種自監督訓練是通過最小化時間立體圖像和靜態立體圖像之間的光度重投影誤差來實現的,原理如下:
傳統方法對極幾何、PnP、ICP、LK光流幾何特征只能為相機的姿勢提供短期的限制,而且可能在有強烈的光和快速運動的環境中失敗,且復雜特征的提取相當耗時
基于CNN的方法數據關聯、高級信息提供幫助(如語義信息)無需提取環境特征,也無需進行特征匹配和復雜的幾何運算,當光照強度、觀測距離和角度變化時,語義信息保持不變
其中:V是圖片It上面所有像素的集合,文中將It設置為雙目相機中左側攝像頭所得幀;t′是所有源幀的索引(區別于時刻t的某一時刻,右上角的′表示將其與t區分開);It′為包含相鄰時間的兩幀以及右側攝像頭所得幀,即It′∈It-1,It+1,Its(It-1為t時刻前一時刻左側相機所得幀,It+1為t時刻后一時刻左側相機所得幀,Its為雙目相機中右側攝像頭所得幀).
2.2位姿估計
傳統的位姿估計方法,一般采用基于特征的方法或直接法,通過多視圖幾何來確定相機位姿.但基于特征的方法需要復雜的特征提取和運算[55],直接法則依賴于像素強度值,這使得傳統方法在光照強烈或紋理稀疏等環境中很難取得想要的結果[56].基于深度學習的方法由于無需提取環境特征,也無需進行特征匹配和復雜的幾何運算,因此更加直觀簡潔[57].Zhu等[58]通過利用CNN關注光流輸入的不同象限來學習旋轉和平移,在數據集中測試結果比傳統SLAM效果更好.表4給出了在位姿估計方面傳統方法與基于CNN方法的不同.由于CNN的特征檢測層通過訓練數據進行學習,所以在使用CNN時,避免了顯示的特征抽取,而隱式地從訓練數據中進行學習,文獻[32,59]在這方面做出了較為詳細的總結.相比傳統位姿估計方法,CNN無需傳統方法復雜的公式計算,無需提取和匹配特征,因此在線運算速度較快[60].
2.3閉環檢測
閉環檢測可以消除累積軌跡誤差和地圖誤差,決定著整個系統的精度,其本質是場景識別問題[61].在閉環檢測方面,傳統方法多以詞袋模型為基礎.如圖3所示,首先需要從圖像中提取出相互獨立的視覺詞匯,通常經過特征檢測、特征表示以及單詞本的生成3個步驟,然后再將新采集到的圖像進行詞典匹配并分類,過程復雜.而深度學習的強大識別能力,可以提取圖像更高層次的穩健特征如語義信息,使得系統能對視角、光照等圖像變化具備更強的適應能力,提高閉環圖像識別能力[62].因此,基于深度學習的場景識別可以提高閉環檢測準確率,CNN用于閉環檢測也得到了諸多可靠的結果.
Memon等[63]提出一種基于詞典的深度學習方法,它不同于傳統的BoW詞典,創新地使用兩個CNN網絡一起工作,以加快閉環檢測的速度,并忽略移動對象對閉環檢測的影響.其核心如圖4所示,該方法使用并行線程(標記為虛線框)使閉合檢測可以達到更高的速度.將patch逐個送入移動對象識別層,從標記為靜止的patch中提取CNN特征,由創新檢測層進一步處理.所有不包含任何移動物體的patch再經過創新檢測層處理來判斷是否訪問過該場景.在新的場景下,自動編碼器在一個單獨的線程上并行地訓練這些特征.該方法可以魯棒地執行循環閉環檢測,比同類方法擁有更快的運行速度.Li等[64]使用CNN從每幀圖像中提取局部特征和全局特征,然后將這些特征輸入現代SLAM模塊,用于姿勢跟蹤、局部映射和重新定位.與傳統的基于BoW的方法相比,它的計算效率更高,并且計算成本更低.Qin等[65]采用CNN提取環境語義信息,并將視覺場景建模為語義子圖.該方法只保留目標檢測中的語義和幾何信息,并在數據集中與傳統方法進行了比較.結果表明,基于深度學習的特征表示方法,在不提取視覺特征的情況下,可以明顯改善閉環檢測的效果.
上述內容主要從單目深度估計、位姿估計、閉環檢測3個方面列舉了CNN與VSLAM的結合.表5給出了傳統方法與結合深度學習方法的對比.CNN在取代傳統的特征提取環節上取得了不錯的效果,改善了傳統特征提取環節消耗時間和計算資源的缺點.同時,CNN有效地提高了單目深度估計的精度.此外,文獻[34,66]利用CNN提取環境的語義信息,以更高層次的特征來優化傳統VSLAM的進程,使得傳統VSLAM獲得了更好的效果.采用神經網絡提取語義信息,并與VSLAM結合將會是一個備受關注的領域,借助語義信息將數據關聯從傳統的像素級別提升到物體級別,將感知的幾何環境信息賦以語義標簽,進而得到高層次的語義地圖,可幫助機器人進行自主環境理解和人機交互.
3RNN與VSLAM
循環神經網絡RNN的研究從20世紀八九十年代開始,并在21世紀初發展為深度學習經典算法之一,其中長短期記憶網絡(LongShort-TermMemory,LSTM)是最常見的循環神經網絡之一.LSTM是RNN的一種變體,它記憶可控數量的前期訓練數據,或是以更適當的方式遺忘[67].LSTM基本結構如圖5所示,從左到右依次為遺忘門、輸入門、輸出門.采用了特殊隱式單元的LSTM可以長期保存輸入,LSTM的這種結構繼承了RNN模型的大部分特性,同時解決了梯度反傳過程由于逐步縮減而產生的問題.此外GRU(GateRecurrentUnit)相比LSTM,更容易進行訓練,能夠很大程度上提高訓練效率,因此很多時候會傾向于使用GRU,但在VSLAM領域還處于嘗試階段.
環節傳統方法結合深度學習的方法
單目深度估計傳統方法無法很好地解決單目尺度不確定性問題CNN可以在一些挑戰性的環境中更有效地估計圖像深度,如低紋理區域相機位姿估計通過特征提取與匹配,或是基于像素亮度變化,需要復雜的計算環節,并且在具有挑戰性的環境中(低紋理區域、光照強烈、快速運動)無法得到可靠的效果可以取代傳統方法復雜的公式計算、特征提取與匹配,速度更快閉環檢測本質是場景識別問題,傳統方法多采用詞袋模型.在場景光照變化大、相機視野變化大等環境中,傳統的DBoW方法能力有限閉環過程使用深度學習中的圖像檢索,能有效地減少由于環境光照、季節更替、視角變化引起的匹配問題語義信息傳統的VSLAM算法中,基本不涉及高層次信息的提取,對于移動機器人的真正智能化沒有幫助采用深度學習的方法可以有效地提取環境中的語義信息,高層次的語義信息可以給系統帶來長期穩定的約束,并且使機器人更好地理解周圍環境循環神經網絡具有記憶性,參數共享,因此,在對序列的非線性特征進行學習時具有一定優勢.RNN在幫助建立相鄰幀之間的一致性方面具有很大的優勢,高層特征具備更好的區分性,可以幫助機器人更好地完成數據關聯.
3.1位姿估計
傳統的位姿估計方法首先需要特征提取與匹配[68],或是基于像素亮度變化的復雜計算.其原理如圖6所示,該問題的核心是求解旋轉矩陣和平移向量,需要繁瑣的計算過程.基于特征的方法(圖6a)需要十分耗時地提取特征,計算描述子的操作丟失了除了特征點以外的很多信息(圖6a中R,t分別為旋轉矩陣和平移向量,紅色點為空間中的特征點,黑色點為特征點在不同圖像中的投影).直接法(圖6b)不同于特征點法最小化重投影誤差,而是通過最小化相鄰幀之間的灰度誤差估計相機運動,但是基于灰度不變假設:
如圖6b,假設空間點P在相鄰兩幀圖像上的投影分別為P1,P2兩點(用不同顏色的點表示二者像素強度的差別).它們的像素強度分別為I1(P1,i)和I2(P2,i),其中,i表示當前圖像中第i個點.則優化目標就是這兩點的亮度誤差ei的二范數.
其中,T和ξ分別是P1,P2之間的轉換矩陣及其李代數.ξ右上角的∧表示把ξ轉為一個四維矩陣,從而通過指數映射成為變換矩陣.
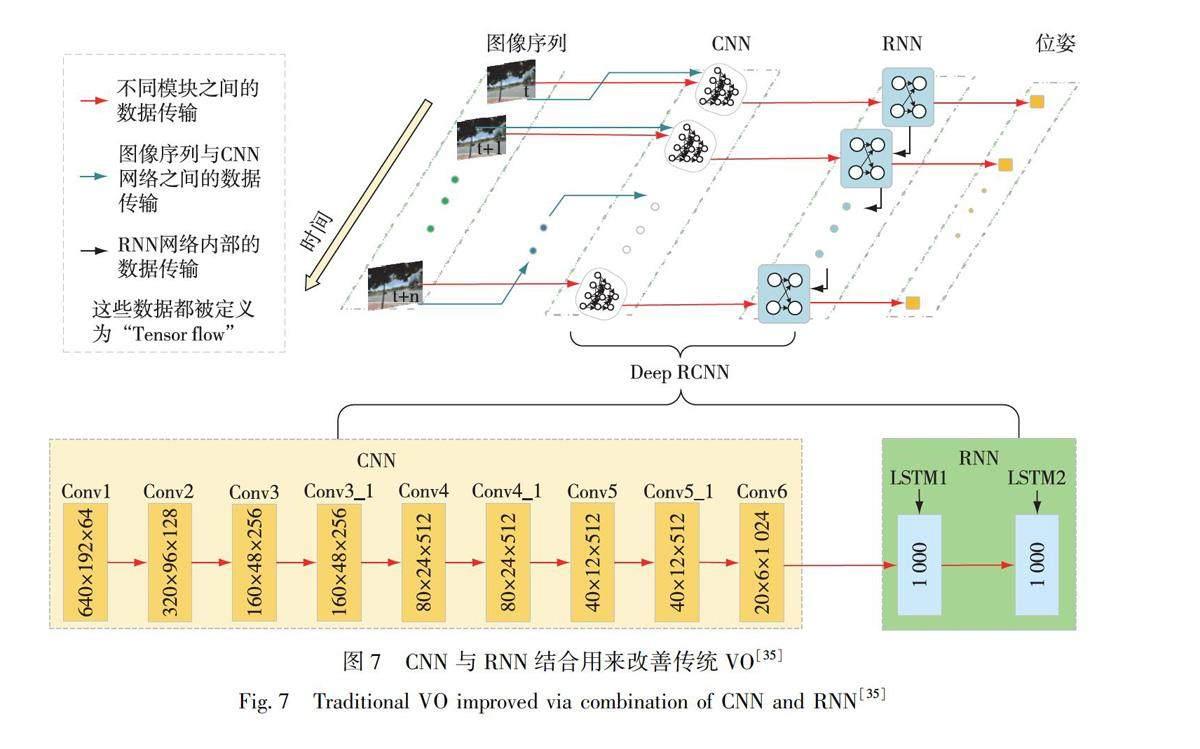
通過引入端對端的深度學習方法,使得視覺圖像幀間的位姿參數解算無須特征匹配與復雜的幾何運算,可快速得到幀間相對位姿參數[69].Xue等[70]基于RNN來實現位姿的估計.在位姿估計過程中,旋轉和位移是分開進行訓練的,相對于傳統方法有更好的適應性.2017年,Wang等[35]使用深度遞歸卷積神經網絡,提出一種新穎的端到端單目VO的框架.由于它是以端到端的方式進行訓練和配置的,因此可以直接從一系列原始的RGB圖像中計算得到姿態,而無需采用任何傳統VO框架中的模塊.該方法做到了視覺里程計的端到端實現,免去了幀間各種幾何關系的約束計算,有良好的泛化能力.如圖7所示,該方案使用CNN+RNN對相機的運動進行估計,直接從原始RGB圖像序列推斷姿態.它不僅通過卷積神經網絡自動學習VO問題的有效特征表示,而且還利用深度回歸神經網絡隱式建模順序動力學和關系.
3.2視覺慣性融合
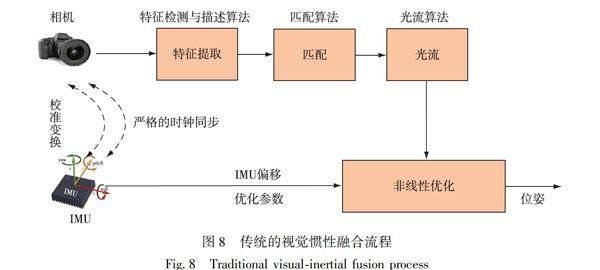
由于慣性測量元件IMU能夠在短時間內高頻地獲得精準的估計,減輕動態物體對相機的影響,而相機數據也能有效地修正IMU的累積漂移,IMU被認為是與相機互補性最強的傳感器之一[71].傳統方法中,視覺慣性融合按照是否將圖像特征信息加入到狀態向量中可以分為松耦合和緊耦合[72].松耦合是指IMU和相機分別進行自身的運動估計,然后對其位姿估計輸出結果進行融合[73].緊耦合是指把IMU的狀態與相機的狀態合并在一起,共同構建運動方程和觀測方程,然后進行狀態估計[74].圖8為傳統方法典型的視覺慣性融合流程,由于相機和IMU頻率相差較大,需要先進行嚴格的同步校準.但是,不同傳感器的數據融合,勢必會帶來計算資源消耗過多、實時性差等問題.
RNN是深度學習領域數據驅動的時序建模的常用方法,IMU輸出的高幀率角速度、加速度等慣性數據,在時序上有著嚴格的依賴關系,特別適合使用RNN這類模型來優化.Clark等[47]使用一個常規的小型LSTM網絡來處理IMU的原始數據,得到了IMU數據下的運動特征.如圖9所示,在對相機數據和IMU數據結合后,送入一個核心的LSTM網絡進行特征融合和位姿估計.該方法通過神經網絡方法,避免了傳統方法復雜的數據融合過程,使得運行效率大大提升.
相比于單純用于位姿估計,RNN在視覺慣性數據融合方面做出的貢獻更具吸引力.此類方法對視覺慣性數據進行了非常有效的融合,相比傳統方法更便捷,類似的工作有文獻[50-51]等.此外,一些工作利用神經網絡提取環境中的語義信息,高層特征更具區分性,對于VSLAM數據關聯有很好的幫助.2017年,Xiang等[75]使用RNN與KinectFusion相結合,對RGB-D相機采集圖像進行語義標注,用來重建三維語義地圖.通過在RNN中引入了一個新的循環單元,來解決GPU計算資源消耗過大的問題.該方法充分利用RNN的優點,實現了語義信息的標注,高層特征具備更好的區分性,同時幫助機器人更好地完成數據關聯.
4總結與展望
本文對深度學習中的兩個典型神經網絡CNN與RNN進行了介紹,并詳細總結了神經網絡在VSLAM中的貢獻,從深度估計、位姿估計、閉環檢測等方面將基于神經網絡的方法與傳統方法進行對比.從CNN與RNN各自的特點入手,列舉出其對傳統VSLAM不同模塊的改善.神經網絡一定程度上改善了傳統VSLAM由于設計特征而帶來的應用局限性,同時對高層語義快速準確生成以及機器人知識庫構建也產生了重要影響,從而提高了機器人的學習能力和智能化水平.
綜合他人所做研究,筆者認為未來VSLAM的發展趨勢如下:
1)更高層次的環境感知.神經網絡可以更加方便地提取環境中高層次的語義信息,可以促進機器人智能化的發展.傳統的VSLAM算法只能滿足機器人基本的定位導航需求,無法完成更高級別的任務,如“幫我把臥室門關上”、“去廚房幫我拿個蘋果”等.借助語義信息將數據關聯從傳統的像素級別提升到物體級別,將感知的幾何環境信息賦以語義標簽,進而得到高層次的語義地圖,可以幫助機器人進行自主環境理解和人機交互,實現真正自主化.
2)更完善的理論支撐體系.通過深度學習技術學習的信息特征還缺少直觀的意義以及清晰的理論指導.目前深度學習多應用于SLAM局部的子模塊,如深度估計、閉環檢測等,而如何將深度學習應用貫穿于整個SLAM系統仍是一個巨大挑戰.
3)更高效的數據融合.CNN可以與VLSAM的諸多環節進行結合,如特征提取與匹配、深度估計、位姿估計等,RNN的應用范圍較小.但RNN在數據融合方面的優勢,可以更好地融合多傳感器的數據,快速推動傳感器融合SLAM技術的發展.未來可能會更多地關注CNN與RNN的結合,來提升VSLAM的整體性能.
參考文獻
References
[1]
任偉建,高強,康朝海,等.移動機器人同步定位與建圖技術綜述[J].計算機測量與控制,2022,30(2):1-10,37
RENWeijian,GAOQiang,KANGChaohai,etal.Overviewofsimultaneouslocalizationandmappingtechnologyofmobilerobots[J].ComputerMeasurement&Control,2022,30(2):1-10,37
[2]趙樂文,任嘉倩,丁楊.基于GNSS的空間環境參數反演平臺及精度評估[J].南京信息工程大學學報(自然科學版),2021,13(2):204-210
ZHAOLewen,RENJiaqian,DINGYang.PlatformforGNSSreal-timespaceenvironmentparameterinversionanditsaccuracyevaluation[J].JournalofNanjingUniversityofInformationScience&Technology(NaturalScienceEdition),2021,13(2):204-210
[3]尹姝,陳元櫞,仇翔.基于RFID和自適應卡爾曼濾波的室內移動目標定位方法[J].南京信息工程大學學報(自然科學版),2018,10(6):749-753
YINShu,CHENYuanyuan,QIUXiang.Indoormoving-targetlocalizationusingRFIDandadaptiveKalmanfilter[J].JournalofNanjingUniversityofInformationScience&Technology(NaturalScienceEdition),2018,10(6):749-753
[4]周韋,孫憲坤,吳飛.基于SLAM/UWB的室內融合定位算法研究[J].全球定位系統,2022,47(1):36-42,85
ZHOUWei,SUNXiankun,WUFei.ResearchonindoorfusionpositioningalgorithmbasedonSLAM/UWB[J].GNSSWorldofChina,2022,47(1):36-42,85
[5]BressonG,AlsayedZ,YuL,etal.Simultaneouslocalizationandmapping:asurveyofcurrenttrendsinautonomousdriving[J].IEEETransactionsonIntelligentVehicles,2017,2(3):194-220
[6]李曉飛,宋亞男,徐榮華,等.基于雙目視覺的船舶跟蹤與定位[J].南京信息工程大學學報(自然科學版),2015,7(1):46-52
LIXiaofei,SONGYanan,XURonghua,etal.Trackingandpositioningofshipbasedonbinocularvision[J].JournalofNanjingUniversityofInformationScience&Technology(NaturalScienceEdition),2015,7(1):46-52
[7]劉明芹,張曉光,徐桂云,等.單機器人SLAM技術的發展及相關主流技術綜述[J].計算機工程與應用,2020,56(18):25-35
LIUMingqin,ZHANGXiaoguang,XUGuiyun,etal.ReviewofdevelopmentofsinglerobotSLAMtechnologyandrelatedmainstreamtechnology[J].ComputerEngineeringandApplications,2020,56(18):25-35
[8]權美香,樸松昊,李國.視覺SLAM綜述[J].智能系統學報,2016(6):768-776
QUANMeixiang,PIAOSonghao,LIGuo.AnoverviewofvisualSLAM[J].CAAITransactionsonIntelligentSystems,2016(6):768-776
[9]胡凱,吳佳勝,鄭翡,等.視覺里程計研究綜述[J].南京信息工程大學學報(自然科學版),2021,13(3):269-280
HUKai,WUJiasheng,ZHENGFei,etal.Asurveyofvisualodometry[J].JournalofNanjingUniversityofInformationScience&Technology(NaturalScienceEdition),2021,13(3):269-280
[10]劉瑞軍,王向上,張晨,等.基于深度學習的視覺SLAM綜述[J].系統仿真學報,2020,32(7):1244-1256
LIURuijun,WANGXiangshang,ZHANGChen,etal.AsurveyonvisualSLAMbasedondeeplearning[J].JournalofSystemSimulation,2020,32(7):1244-1256
[11]李少朋,張濤.深度學習在視覺SLAM中應用綜述[J].空間控制技術與應用,2019,45(2):1-10
LIShaopeng,ZHANGTao.AsurveyofdeeplearningapplicationinvisualSLAM[J].AerospaceControlandApplication,2019,45(2):1-10
[12]DavisonAJ,ReidID,MoltonND,etal.MonoSLAM:real-timesinglecameraSLAM[J].IEEETransactionsonPatternAnalysisandMachineIntelligence,2007,29(6):1052-1067
[13]NewcombeRA,LovegroveSJ,DavisonAJ.DTAM:densetrackingandmappinginreal-time[C]//2011InternationalConferenceonComputerVision.November6-13,2011,Barcelona,Spain.IEEE,2011:2320-2327
[14]Mur-ArtalR,MontielJMM,TardosJD.ORB-SLAM:aversatileandaccuratemonocularSLAMsystem[J].IEEETransactionsonRobotics,2015,31(5):1147-1163
[15]Galvez-LopezD,TardosJD.Bagsofbinarywordsforfastplacerecognitioninimagesequences[J].IEEETransactionsonRobotics,2012,28(5):1188-1197
[16]Mur-ArtalR,TardosJD.ORB-SLAM2:anopen-sourceSLAMsystemformonocular,stereo,andRGB-Dcameras[J].IEEETransactionsonRobotics,2017,33(5):1255-1262
[17]CamposC,ElviraR,RodriguezJJG,etal.ORB-SLAM3:anaccurateopen-sourcelibraryforvisual,visual-inertial,andmultimapSLAM[J].IEEETransactionsonRobotics,2021,37(6):1874-1890
[18]EngelJ,KoltunV,CremersD.Directsparseodometry[J].IEEETransactionsonPatternAnalysisandMachineIntelligence,2018,40(3):611-625
[19]QinT,LiPL,ShenSJ.VINS-mono:arobustandversatilemonocularvisual-inertialstateestimator[J].IEEETransactionsonRobotics,2018,34(4):1004-1020
[20]鄧晨,李宏偉,張斌,等.基于深度學習的語義SLAM關鍵幀圖像處理[J].測繪學報,2021,50(11):1605-1616
DENGChen,LIHongwei,ZHANGBin,etal.ResearchonkeyframeimageprocessingofsemanticSLAMbasedondeeplearning[J].ActaGeodaeticaetCartographicaSinica,2021,50(11):1605-1616
[21]KleinG,MurrayD.ParalleltrackingandmappingforsmallARworkspaces[C]//20076thIEEEandACMInternationalSymposiumonMixedandAugmentedReality.November13-16,2017,Nara,Japan.IEEE,2007:225-234
[22]Gomez-OjedaR,BrialesJ,Gonzalez-JimenezJ.PL-SVO:semi-directmonocularvisualodometrybycombiningpointsandlinesegments[C]//2016IEEE/RSJInternationalConferenceonIntelligentRobotsandSystems(IROS).October9-14,2016,Daejeon,Korea(South).IEEE,2016:4211-4216
[23]PumarolaA,VakhitovA,AgudoA,etal.PL-SLAM:real-timemonocularvisualSLAMwithpointsandlines[C]//2017IEEEInternationalConferenceonRoboticsandAutomation.May29-June3,2017,Singapore.IEEE,2017:4503-4508
[24]ForsterC,PizzoliM,ScaramuzzaD.SVO:fastsemi-directmonocularvisualodometry[C]//2014IEEEInternationalConferenceonRoboticsandAutomation.May31-June7,2014,HongKong,China.IEEE,2014:15-22
[25]EngelJ,SchpsT,CremersD.LSD-SLAM:large-scaledirectmonocularSLAM[C]//EuropeanConferenceonComputerVision.Springer,Cham,2014:834-849
[26]MourikisAI,RoumeliotisSI.Amulti-stateconstraintKalmanfilterforvision-aidedinertialnavigation[C]//Proceedings2007IEEEInternationalConferenceonRoboticsandAutomation.April10-14,2007,Rome,Italy.IEEE,2007:3565-3572
[27]LeuteneggerS,LynenS,BosseM,etal.Keyframe-basedvisual-inertialodometryusingnonlinearoptimization[J].TheInternationalJournalofRoboticsResearch,2015,34(3):314-334
[28]BloeschM,OmariS,HutterM,etal.RobustvisualinertialodometryusingadirectEKF-basedapproach[C]//2015IEEE/RSJInternationalConferenceonIntelligentRobotsandSystems(IROS).September28-October2,2015,Hamburg,Germany.IEEE,2015:298-304
[29]XuD,VedaldiA,HenriquesJF.MovingSLAM:fullyunsuperviseddeeplearninginnon-rigidscenes[C]//2021IEEE/RSJInternationalConferenceonIntelligentRobotsandSystems(IROS).September27-October1,2021,Prague,CzechRepublic.IEEE,2021:4611-4617
[30]張彥雯,胡凱,王鵬盛.三維重建算法研究綜述[J].南京信息工程大學學報(自然科學版),2020,12(5):591-602
ZHANGYanwen,HUKai,WANGPengsheng.Reviewof3Dreconstructionalgorithms[J].JournalofNanjingUniversityofInformationScience&Technology(NaturalScienceEdition),2020,12(5):591-602
[31]LiJL,LiZJ,FengY,etal.Developmentofahuman-robothybridintelligentsystembasedonbrainteleoperationanddeeplearningSLAM[J].IEEETransactionsonAutomationScienceandEngineering,2019,16(4):1664-1674
[32]MumuniA,MumuniF.CNNarchitecturesforgeometrictransformation-invariantfeaturerepresentationincomputervision:areview[J].SNComputerScience,2021,2(5):1-23
[33]MaRB,WangR,ZhangYB,etal.RNNSLAM:reconstructingthe3Dcolontovisualizemissingregionsduringacolonoscopy[J].MedicalImageAnalysis,2021,72:102100
[34]TatenoK,TombariF,LainaI,etal.CNN-SLAM:real-timedensemonocularSLAMwithlearneddepthprediction[C]//2017IEEEConferenceonComputerVisionandPatternRecognition(CVPR).July21-26,2017,Honolulu,HI,USA.IEEE,2017:6565-6574
[35]WangS,ClarkR,WenHK,etal.DeepVO:towardsend-to-endvisualodometrywithdeeprecurrentconvolutionalneuralnetworks[C]//2017IEEEInternationalConferenceonRoboticsandAutomation.May29-June3,2017,Singapore.IEEE,2017:2043-2050
[36]BloeschM,CzarnowskiJ,ClarkR,etal.CodeSLAM:learningacompact,optimisablerepresentationfordensevisualSLAM[C]//2018IEEE/CVFConferenceonComputerVisionandPatternRecognition.June18-23,2018,SaltLakeCity,UT,USA.IEEE,2018:2560-2568
[37]YangN,WangR,StucklerJ,etal.Deepvirtualstereoodometry:leveragingdeepdepthpredictionformonoculardirectsparseodometry[C]//EuropeanConferenceonComputerVision(ECCV).September8-12,2018,Munich,Germany.2018.DOI:10.48550/arXiv.1807.02570
[38]LiRH,WangS,LongZQ,etal.UnDeepVO:monocularvisualodometrythroughunsuperviseddeeplearning[C]//2018IEEEInternationalConferenceonRoboticsandAutomation.May21-25,2018,Brisbane,QLD,Australia.IEEE,2018:7286-7291
[39]LooSY,AmiriAJ,MashohorS,etal.CNN-SVO:improvingthemappinginsemi-directvisualodometryusingsingle-imagedepthprediction[C]//2019InternationalConferenceonRoboticsandAutomation(ICRA).May20-24,2019,Montreal,QC,Canada.IEEE,2019:5218-5223
[40]AlmaliogluY,SaputraMRU,deGusmoPPB,etal.GANVO:unsuperviseddeepmonocularvisualodometryanddepthestimationwithgenerativeadversarialnetworks[C]//2019InternationalConferenceonRoboticsandAutomation(ICRA).May20-24,2019,Montreal,QC,Canada.IEEE,2019:5474-5480
[41]LiY,UshikuY,HaradaT.Posegraphoptimizationforunsupervisedmonocularvisualodometry[C]//2019InternationalConferenceonRoboticsandAutomation(ICRA).May20-24,2019,Montreal,QC,Canada.IEEE,2019:5439-5445
[42]YangN,vonStumbergL,WangR,etal.D3VO:deepdepth,deepposeanddeepuncertaintyformonocularvisualodometry[C]//2020IEEE/CVFConferenceonComputerVisionandPatternRecognition(CVPR).June13-19,2020,Seattle,WA,USA.IEEE,2020:1278-1289
[43]ChancánM,MilfordM.DeepSeqSLAM:atrainableCNN+RNNforjointglobaldescriptionandsequence-basedplacerecognition[J].arXive-print,2020,arXiv:2011.08518
[44]LiRH,WangS,GuDB.DeepSLAM:arobustmonocularSLAMsystemwithunsuperviseddeeplearning[J].IEEETransactionsonIndustrialElectronics,2021,68(4):3577-3587
[45]BrunoHMS,ColombiniEL.LIFT-SLAM:adeep-learningfeature-basedmonocularvisualSLAMmethod[J].Neurocomputing,2021,455:97-110
[46]ZhangSM,LuSY,HeR,etal.Stereovisualodometryposecorrectionthroughunsuperviseddeeplearning[J].Sensors(Basel,Switzerland),2021,21(14):4735
[47]ClarkR,WangS,WenH,etal.VINet:visual-inertialodometryasasequence-to-sequencelearningproblem[C]//Proceedingsofthe31stAAAIConferenceonArtificialIntelligence.February4-9,2017,SanFrancisco,CA,USA.2017:3995-4001
[48]ShamwellEJ,LindgrenK,LeungS,etal.Unsuperviseddeepvisual-inertialodometrywithonlineerrorcorrectionforRGB-Dimagery[J].IEEETransactionsonPatternAnalysisandMachineIntelligence,2020,42(10):2478-2493
[49]HanLM,LinYM,DuGG,etal.DeepVIO:self-superviseddeeplearningofmonocularvisualinertialodometryusing3Dgeometricconstraints[C]//2019IEEE/RSJInternationalConferenceonIntelligentRobotsandSystems(IROS).November3-8,2019,Macao,China.IEEE,2019:6906-6913
[50]ChenCH,RosaS,MiaoYS,etal.Selectivesensorfusionforneuralvisual-inertialodometry[C]//2019IEEE/CVFConferenceonComputerVisionandPatternRecognition(CVPR).June15-20,2019,LongBeach,CA,USA.IEEE,2019:10534-10543
[51]KimY,YoonS,KimS,etal.Unsupervisedbalancedcovariancelearningforvisual-inertialsensorfusion[J].IEEERoboticsandAutomationLetters,2021,6(2):819-826
[52]GurturkM,YusefiA,AslanMF,etal.TheYTUdatasetandrecurrentneuralnetworkbasedvisual-inertialodometry[J].Measurement,2021,184:109878
[53]傅杰,徐常勝.關于單目標跟蹤方法的研究綜述[J].南京信息工程大學學報(自然科學版),2019,11(6):638-650
FUJie,XUChangsheng.Asurveyofsingleobjecttrackingmethods[J].JournalofNanjingUniversityofInformationScience&Technology(NaturalScienceEdition),2019,11(6):638-650
[54]SteenbeekA,NexF.CNN-baseddensemonocularvisualSLAMforreal-timeUAVexplorationinemergencyconditions[J].Drones,2022,6(3):79
[55]唐燦,唐亮貴,劉波.圖像特征檢測與匹配方法研究綜述[J].南京信息工程大學學報(自然科學版),2020,12(3):261-273
TANGCan,TANGLianggui,LIUBo.Asurveyofimagefeaturedetectionandmatchingmethods[J].JournalofNanjingUniversityofInformationScience&Technology(NaturalScienceEdition),2020,12(3):261-273
[56]LiL,KongX,ZhaoXR,etal.Semanticscancontext:anovelsemantic-basedloop-closuremethodforLiDARSLAM[J].AutonomousRobots,2022,46(4):535-551
[57]SakkariM,HamdiM,ElmannaiH,etal.Featureextraction-baseddeepself-organizingmap[J].Circuits,Systems,andSignalProcessing,2022,41(5):2802-2824
[58]ZhuR,YangMK,LiuW,etal.DeepAVO:efficientposerefiningwithfeaturedistillingfordeepvisualodometry[J].Neurocomputing,2022,467:22-35
[59]KimJJY,UrschlerM,RiddlePJ,etal.SymbioLCD:ensemble-basedloopclosuredetectionusingCNN-extractedobjectsandvisualbag-of-words[C]//2021IEEE/RSJInternationalConferenceonIntelligentRobotsandSystems(IROS).September27-October1,2021,Prague,CzechRepublic.IEEE,2021:5425
[60]AiYB,RuiT,LuM,etal.DDL-SLAM:arobustRGB-DSLAMindynamicenvironmentscombinedwithdeeplearning[J].IEEEAccess,8:162335-162342
[61]JavedZ,KimGW.PanoVILD:achallengingpanoramicvision,inertialandLiDARdatasetforsimultaneouslocalizationandmapping[J].TheJournalofSupercomputing,2022,78(6):8247-8267
[62]DuanR,FengYR,WenCY.Deepposegraph-matching-basedloopclosuredetectionforsemanticvisualSLAM[J].Sustainability,2022,14(19):11864
[63]MemonAR,WangHS,HussainA.LoopclosuredetectionusingsupervisedandunsuperviseddeepneuralnetworksformonocularSLAMsystems[J].RoboticsandAutonomousSystems,2020,126:103470
[64]LiDJ,ShiXS,LongQW,etal.DXSLAM:arobustandefficientvisualSLAMsystemwithdeepfeatures[C]//2020IEEE/RSJInternationalConferenceonIntelligentRobotsandSystems(IROS).October24,2020-January24,2021,LasVegas,NV,USA.IEEE,2020:4958-4965
[65]QinC,ZhangYZ,LiuYD,etal.Semanticloopclosuredetectionbasedongraphmatchinginmulti-objectsscenes[J].JournalofVisualCommunicationandImageRepresentation,2021,76:103072
[66]GodardC,AodhaOM,BrostowGJ.Unsupervisedmonoculardepthestimationwithleft-rightconsistency[C]//2017IEEEConferenceonComputerVisionandPatternRecognition.July21-26,2017,Honolulu,HI,USA.IEEE,2017:6602-6611
[67]SangHR,JiangR,WangZP,etal.Anovelneuralmulti-storememorynetworkforautonomousvisualnavigationinunknownenvironment[J].IEEERoboticsandAutomationLetters,2022,7(2):2039-2046
[68]LiGH,ChenSL.Visualslamindynamicscenesbasedonobjecttrackingandstaticpointsdetection[J].JournalofIntelligent&RoboticSystems,2022,104(2):1-10
[69]LiuL,TangTH,ChenJ,etal.Real-time3Dreconstructionusingpoint-dependentposegraphoptimizationframework[J].MachineVisionandApplications,2022,33(2):1-11
[70]XueF,WangQ,WangX,etal.Guidedfeatureselectionfordeepvisualodometry[C]//14thAsianConferenceonComputerVision.December2-6,2018,Perth,Australia.IEEE,2018:293-308
[71]TangYF,WeiCC,ChengSL,etal.Stereovisual-inertialodometryusingstructurallinesforlocalizingindoorwheeledrobots[J].MeasurementScienceandTechnology,2022,33(5):055114
[72]BucciA,ZacchiniL,FranchiM,etal.Comparisonoffeaturedetectionandoutlierremovalstrategiesinamonovisualodometryalgorithmforunderwaternavigation[J].AppliedOceanResearch,2022,118:102961
[73]WuJF,XiongJ,GuoH.ImprovingrobustnessoflinefeaturesforVIOindynamicscene[J].MeasurementScienceandTechnology,2022,33(6):065204
[74]HuangWB,WanWW,LiuH.Optimization-basedonlineinitializationandcalibrationofmonocularvisual-inertialodometryconsideringspatial-temporalconstraints[J].Sensors(Basel,Switzerland),2021,21(8):2673
[75]XiangY,FoxD.DA-RNN:semanticmappingwithdataassociatedrecurrentneuralnetworks[J].arXive-print,2017,arXiv:1703.03098
AreviewofvisualSLAMbasedonneuralnetworks
SHANGGuangtao1CHENWeifeng1JIAihong2ZHOUChengjun1WANGXiyang1XUChonghui1
1SchoolofAutomation,NanjingUniversityofInformationScience&Technology,Nanjing210044,China
2CollegeofMechanical&ElectricalEngineering/LabofLocomotionBioinspirationand
IntelligentRobots,NanjingUniversityofAeronauticsandAstronautics,Nanjing210016,China
Abstract
Althoughtraditionalvision-basedSLAM(VSLAM)technologieshaveachievedimpressiveresults,theyarelesssatisfactoryinchallengingenvironments.Deeplearningpromotestherapiddevelopmentofcomputervisionandshowsprominentadvantagesinimageprocessing.ItsahotspottocombinedeeplearningwithVSLAM,whichispromisingthroughtheeffortsofmanyresearchers.Here,weintroducethecombinationofdeeplearningandtraditionalVSLAMalgorithm,startingfromtheclassicalneuralnetworksofdeeplearning.TheachievementsofConvolutionalNeuralNetwork(CNN)andRecurrentNeuralNetwork(RNN)indepthestimation,poseestimationandclosed-loopdetectionaresummarized.Theadvantagesofneuralnetworkinsemanticinformationextractionareelaborated,andthefuturedevelopmentofVSLAMisalsoprospected.
Keywordssimultaneouslocalizationandmapping(SLAM);deeplearning;convolutionalneuralnetwork(CNN);recurrentneuralnetwork(RNN);poseestimation;closed-loopdetection;semantic
猜你喜歡
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
