融合嵌入空間優化的超圖神經網絡會話推薦模型
2024-06-26 07:52:14黃文濤潘宇程樹林
電腦知識與技術 2024年13期
黃文濤 潘宇 程樹林

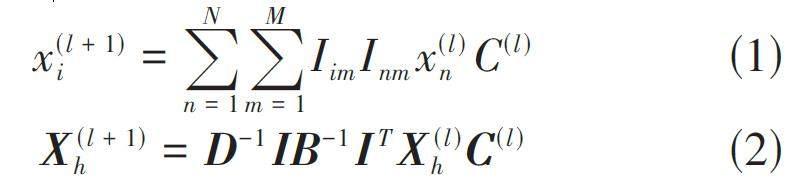
摘要:在會話推薦領域中,基于圖神經網絡挖掘和提取項目特征是一種主流方法。由于會話中的項目轉換通常受到多個項目的協同影響,且大多數推薦算法忽略了項目和會話的嵌入表示在嵌入空間中的分布情況對推薦任務的影響,使得推薦系統難以獲得高質量的嵌入表示,從而影響了推薦性能。為此,提出一種基于超圖神經網絡和嵌入空間優化的會話推薦方法。該方法首先基于會話序列特征采用超圖來建模項目間隱含的高階聯系,然后通過對比學習優化項目的空間嵌入表示,最后通過注意力機制來劃分用戶的長短期興趣。通過在兩個真實的公開數據集上進行多個實驗,驗證了該方法相對于基準方法具有更好的推薦性能。
關鍵詞:推薦系統;會話推薦;超圖神經網絡;對比學習;注意力機制
中圖分類號:TP181 文獻標識碼:A
文章編號:1009-3044(2024)13-0004-05 開放科學(資源服務)標識碼(OSID) :
0 引言
推薦系統在應對用戶信息過載問題中發揮著重要的信息過濾作用,尤其在電子商務和搜索引擎等場景下應用廣泛,成為用戶信息篩選的重要途徑。傳統的推薦方法主要是學習用戶歷史數據以提供個性化的推薦結果。然而,受限于冷啟動和用戶隱私保護等問題,在許多實際應用中,系統不能完整地獲得長期高度相關的用戶數據[1]。相比之下,基于會話的推薦系統[2-3](Session-based Recommendation System) 作為推薦系統的重要分支,通過對當前會話中的用戶行為進行建模,預測下一個可能點擊的項目,具有廣泛的工業應用,特別適用于電子商務和搜索領域,并且彌補了傳統方法中的不足,成為當前研究的熱點課題。
會話推薦的相關研究主要分為三個方面,即傳統會話推薦方法[4]、基于RNN[5-8] (Recurrent Neural Net?work) 的方法以及基于GNN[9](Graph Neural Network)的方法。傳統方法通常依賴協同過濾和最近鄰方法來定義項目之間的相似程度。這類方法只關注到項目出現在同一個會話的頻率以及項目之間的相似度,而忽略了其在會話中的序列關系和深層特征。為了提取項目之間的順序信息,研究人員提出了基于循環神經網絡RNN的方法,對會話進行建模以挖掘順序特征[5]。由于深度神經網絡具備優秀的表示能力,RNN 的引入顯著提高了推薦系統的性能。近年來,研究人員發現將會話序列編碼成圖結構更有利于捕獲項目之間復雜的轉換關系,由此提出了基于圖神經網絡GNN的推薦方法[10-11]。通過在會話圖中傳播和更新節點信息,GNN方法可以獲得信息更豐富的項目嵌入表示,從而提供更準確的推薦結果[12]。
最新的研究趨勢表明,在會話推薦領域,基于GNN的方法展現出更為顯著的優勢[9,13,14]。因此,當前主要的研究方向聚焦于對GNN方法的改進[9,13,14],取得了較好的性能提升,但仍然存在一些局限性和不足:1) 在實際場景中,項目之間的關系呈現出復雜多樣的特性,多個項目之間通常相互影響并協同作用,這意味著項目之間存在隱含的高階聯系。然而,傳統的圖結構難以準確描述這種復雜的關聯性和依賴性。2) 目前許多研究并未充分挖掘項目表示在嵌入空間中的分布規律對推薦結果的影響。如何有效地將相似項目聚集在嵌入空間中相鄰的位置,同時確保不同項目之間具有足夠的區分度更是一項重要挑戰。
為此,本文提出一種融合了嵌入空間優化的超圖卷積網絡HCNOES-SR(Hypergraph Convolution Net?work with Optimized Embedding Space for sessionbasedrecommendation) 。本文方法采用超圖作為表征工具來建模項目之間潛在的高階聯系。與傳統的圖結構不同,超圖允許一條邊連接多于兩個節點,稱為超邊。超邊是一組節點的集合,這些節點作為一個整體連接在一起,因此,超圖可以更靈活地表示節點之間復雜的關聯性。為了進一步提升項目嵌入表示的質量,本文模型引入了對比學習,提出一種新的損失函數優化項目在嵌入空間中的分布,在保證項目之間具有足夠區分度的前提下盡可能地使相似的項目聚集在嵌入空間中相近的位置。最終,引入注意力機制動態地為項目分配不同的權重,從而使得模型更好地捕捉用戶關注的重點。通過多個實驗驗證,本文模型HCNOES-SR在召回率Recall以及平均倒數排名MRR 兩個典型指標上表現出了良好的綜合性能。
1 模型框架與推薦方法
1.1 問題定義
會話推薦的目標是根據當前匿名會話中的項目預測用戶下一次可能點擊的項目。設I ={v1 ,v2,v3,...,vn } 數據集中包含所有的項目,S ={ vs,1,vs,2,vs,3,...,vs,l }為會話按時間順序排列的匿名會話,其中n 表示數據集中的項目數量,l 表示會話中的項目數量。因此,本文模型 HCNOES-SR 的任務是生成一個推薦項目集合C = { vc,1,vc,2,vc,3,...,vc,k },并選取排名最前的N 個項目作為最終的推薦結果。
1.2 模型框架
HCNOES-SR模型的總體結構如圖1所示,包括4 個主要模塊:
1) 超圖構建模塊。該模塊接受會話序列作為輸入,創建一個完整的會話超圖。每個會話被獨立表示為一條超邊,而會話內的項目則兩兩相互連接。不同的會話通過共有的項目進行連接。這一過程將項目之間隱含的多對多關系轉化為超邊之間的關聯。
2) 超圖卷積與信息傳播模塊。模型采用超圖卷積來實現項目特征的聚合,特征沿著有共享項目的超邊之間傳播,實現了“項目-超邊-項目”的特征傳遞。經過多次迭代更新,每個項目能夠學習到更豐富的特征表示。
3) 嵌入空間優化模塊。現有研究表明,對比學習可以優化項目嵌入表示的對齊性和統一性,并對下游任務具有積極影響[15]。因此,為了優化嵌入表示質量,HCNOES-SR模型在采用有監督學習和自監督學習相結合的策略下,提取項目特征并生成嵌入表示。通過交叉熵損失減小相似項目之間的距離,并采用對比學習損失增加兩項目之間的距離,使得項目在嵌入空間中的分布更為合理。
4) 預測模塊。通過應用注意力機制來融合會話中包含的項目特征,生成最終的會話表示,用于進行用戶推薦預測。這一部分有助于模型更好地理解用戶的長短期興趣,從而提供個性化的推薦結果。
1.3 會話超圖構建與信息傳播
1.3.1 構建會話超圖
為了有效捕獲項目之間潛在的成對關系,本文將多條會話序列建模為一張超圖GS = (VS,ES )。在超圖中,每條超邊代表兩個或多個項目的組合,表示[VS,1,VS,2,VS,3,...,VS,M ] ∈ ES,頂點為超圖所包含項目的集合{V1,V2,V3,...,Vn } ∈ VS。假設該超圖包含M條會話以及N 個不同的項目,那么可以用一個關聯矩陣I ∈ RN × M 來表示這個超圖的結構。如果第m 條超邊包含第n 個項目,則關聯矩陣對應的元素值為Inm = 1,否則為Inm = 0。此外,每個頂點和超邊的度可以分別用兩個矩陣表示:頂點度矩陣Dii = ΣMe = 1 Iie 和超邊度矩陣Bii = ΣNi = 1 Iie。其中,節點的度表示與該節點直接連接的超邊的數量。節點的度越高表示該節點參與了更多的高階關系,具有更復雜的關聯性。超邊的度表示連接到該超邊的節點的數量,超邊的度越高表示這條超邊涵蓋了更多的節點,具有更廣泛的關聯性。
1.3.2 超圖神經網絡
與傳統圖神經網絡類似,超圖神經網絡[15]也是當前廣泛使用的深度學習模型之一。它可以為會話圖中包含的項目生成高維向量以表示項目豐富的特征,即項目的嵌入表示。在超圖構建階段,模型為每個項目初始化一個嵌入向量xi ∈ Rd。然后,通過多層的卷積操作,將鄰居節點的特征信息傳遞并融合到當前節點,這使得每個節點的嵌入表示不僅包含自身的特征,同時也包含了鄰居節點的特征和上下文的結構信息。本文采用譜超圖卷積更新項目的嵌入表示,如公式(1) 和(2) 所示:
其中,x(l + 1) i 表示第i 個項目在l+1 層的嵌入表示,C(l) ∈ Rd × d 是不同卷積層中可學習的參數矩陣。公式(2) 為公式(1) 的矩陣表示形式,X (l + 1) h 為所有項目在l+1 層的嵌入表示,I 為超圖的關聯矩陣,D、B 分別為頂點和超邊的度矩陣。
1.4 項目空間分布優化
對比學習(contrastive learning, CL) [16]已在多個研究領域,如計算機視覺和自然語言處理等,取得了顯著成功。其主要功能是將相似的節點映射到嵌入空間相鄰的位置,同時將不相似節點分散開。Wang等[15]研究發現,對比學習通過提高嵌入空間的分布情況、提高特征表示的質量,改進了模型對數據的理解,使其能夠更好地區分不同類別的數據。盡管對比學習可以帶來性能提升,但其需要通過添加噪聲擾動、舍棄部分節點等數據增強手段來設計復雜的正負樣例和采樣策略。因此,本文提出了一種簡化的正負樣例構建策略。具體來說,在每個訓練批次中,本文將每個項目自身作為正樣例,對于每個項目隨機采樣十個嵌入空間中的其他項目作為負樣例。通過多次迭代,逐漸增加項目之間的距離,使得項目的嵌入表示在嵌入空間中的分布更具區分度。這種簡化的方法能夠提高嵌入空間的質量,有助于模型對不同特征進行平衡學習,避免過于關注某些特征。同時,減少了對復雜數據增強技術的依賴以及計算開銷,為對比學習的實際應用提供了更高效的選擇。因此,對于一組包含n個項目的嵌入表示,本文提出的對比學習損失函LCL數如公式(3) 所示:
式中,f (x,x′)的計算方式為esim(x,x′)/τ,sim(x,x′)通過項目嵌入向量內積實現,τ 是溫度超參數用以控制分布的平滑度。
1.5 會話嵌入生成
1.5.1 注意力機制
為了準確評估每個項目在會話中的重要性,在HCNOES-SR模型中引入了軟注意力機制,用于計算每個項目的注意力系數。其主要策略是通過衡量每個項目與用戶主要意圖的相關性來確定該項目在整個會話中的影響程度。為此,本文采用對會話中所有項目的特征取平均來度量用戶在該次會話的主要意圖。因此,對于一個包含m 個項目的會話,每個項目的注意力系數的度量方式如公式(4) 所示:
ai = W0σ(W1 xi + W2em + b) (4)
式中,W0 ∈ Rd、W1 ∈ Rd × d、W2 ∈ Rd × d 是可學習的參數矩陣,b ∈ Rd 是偏置向量。σ 是sigmoid 激活函數。xi 為每個項目的嵌入表示,em 為所有項目嵌入表示的平均向量。
1.5.2 會話嵌入
為了綜合考慮用戶的短期和長期興趣,本文將會話的嵌入表示劃分為兩部分,分別是短期偏好Sl 和全局偏好Sg。由于會話的最后一個項目通常能夠更好地反映用戶當前的關注點,因此本文將會話的最后一個項目的嵌入表示作為短期偏好。同時,為了綜合考慮用戶在本次會話中的行為,本文將每個項目的嵌入表示按照其注意力系數進行加權求和,作為用戶的全局偏好。短期興趣Sl 和長期興趣Sg 分別如公式(5) 和(6) 所示:
因此,通過融合短期偏好和全局偏好得到會話的最終嵌入表示,如公式(7) 所示:
S = W3 [ Sl ? Sg ] (7)
式中,[?]表示向量拼接操作,W3 ∈ Rd × 2d 是映射矩陣將S從R2d轉換為Rd。
1.6 模型訓練與推薦生成
通過計算項目嵌入和會話嵌入的向量內積,可以得出每個項目的推薦分值。該分值反映了項目與當前會話的匹配程度,從而決定了其在推薦列表中的排名。經過歸一化和降序排列以后,本文分別取前10項和前20項作為最終的推薦結果。通過Softmax 函數對每個項目的推薦分值進行歸一化處理,如公式(8) 所示:
y = Soft max(y1,y2,y3,...,yn ) (8)
式中,yi 表示項目xi 出現在該會話中的推薦分值,yi =< S ? xi >,y 表示經過歸一化后的概率分布。
最后,本文使用交叉熵損失函數來訓練模型,如公式(9) 所示:
式中,pi 為項目xi 是否被推薦的真實值,如項目xi是會話的最后一個項目則pi為1,否則為0。
2 實驗結果與分析
2.1 數據集
為了驗證模型的有效性,本實驗分別在兩個真實的公共數據集Diginetica和Nowplaying上進行訓練和測試。其中,Diginetica是2016年CIKM挑戰杯比賽中發布的個性化電子商務數據集,由來自在線商店5個月內的用戶交互記錄組成,包含600 684個用戶,184047個商品和993 484條點擊記錄。Nowplaying是個性化音樂推薦數據集,主要包含用戶的音樂播放歷史、曲目名稱、藝術家信息、播放時間戳等。實驗前先對兩個數據集進行了預處理,刪除了長度為1的會話并過濾了出現次數少于5次的項目,最終數據集統計信息如表1所示。
2.2 評價指標
本文采用了2種廣泛應用于推薦領域的典型評價指標,即P@K(Precision @ K) 和MRR@K(Mean Recip?rocal Rank @K) 來進行實驗結果評價。其中,P@K用以表示推薦結果中前K個項目中用戶實際感興趣的比例,即推薦的準確性;而MRR@K表示前K個推薦結果中正確項目的倒數排名,即正確的項目是否排在靠前的位置。通過這兩個指標可以評價模型的推薦質量和排序效果。
2.3 基準模型和實驗設置
2.3.1 基準模型
為了對比模型性能,本文選取了傳統方法和深度學習方法中具有代表性的方法作為對比,各方法信息簡述如下:
1) FPMC[4]。該算法將用戶歷史行為序列建模為馬爾科夫鏈,并使用矩陣分解技術分別學習項目和用戶的特征。最終根據用戶歷史行為和上下文信息生成個性化推薦。
2) GRU4REC[5]。該算法采用基于RNN 改進的模型捕獲項目在會話中的順序關系和上下文信息。通過門控循環單元減輕了梯度消失問題,并針對會話的小批次數據使用基于排名的損失函數優化模型,獲得了較好的推薦性能。
3) NARM[6]。該算法基于GRU4REC算法進行改進,通過在RNN中增加注意力機制動態調整每個項目在會話中的重要性,從而進一步提高了推薦精度。
4) STAMP[17]。該算法考慮到了時間因素對推薦效果的影響,使模型能夠理解用戶興趣的動態演化過程。
5) SR-GNN[9]。該算法首次將基于圖的算法引入會話推薦領域,利用圖結構表示項目之間的關聯性,并通過圖卷積傳播項目特征獲得了高質量的項目嵌入表示,從而提升了性能。
2.3.2 實驗設置
本文模型HCNOES-SR在實驗中設定嵌入向量的維度為100,每個訓練批次大小也為100。同時,本文采用Adam優化器調優模型,其中初始的學習率設置為0.001,并在每三次訓練迭代后將學習率衰減10%。此外,如果在3次訓練迭代后兩個實驗指標都沒有提升,則提前終止訓練。
2.4 性能比較與分析
為了評估模型的綜合表現,本文通過實驗與其他基準模型在四個指標上進行了比較和分析。實驗結果如表2所示。
通過對表2進行分析:1) 傳統矩陣分解方法(如FPMC) 通常基于項目的共現或連續性生成推薦結果。這些方法使用相對簡單的模型,難以提取和表示項目內復雜的信息。相比之下,深度學習方法充分利用神經網絡的信息表示能力,因此在性能上優于傳統方法。2) 在使用循環神經網絡(RNN) 的方法中,GRU4REC模型的表現相對較差,而NARM取得更好的推薦性能。主要是因為GRU4REC模型僅使用了序列信息,而NARM通過引入注意力機制綜合考慮了序列信息和用戶的全局偏好。3) SR-GNN方法通過引入圖神經網絡帶來了相對較大的提升,突顯了圖結構在描述會話內項目轉化信息的有效性。4) 本文模型HCNOES-SR通過對比學習優化了項目的嵌入表示,有利于對相似項目細節上的不同進行捕獲,因此顯著提高了模型的準確度。
HCNOES-SR 模型之所以能取得優異推薦性能主要有三個方面原因:1) 超圖內的每條超邊具有與集合類似的性質,因此很好的對應了項目間的高階多對多關系,有助于模型提取到更豐富的項目特征;2) 嵌入向量在嵌入空間的分布情況也會對最終的表示質量產生重要影響,對比學習的應用使得項目的嵌入表示分布更為均勻,也使得不同項目之間更具有區分度;3) 模型通過注意力機制學習到了不同項目的重要性,既抓住了用戶的當前興趣,也囊括了用戶長期的興趣。這些因素共同促成了HCNOESSR模型優秀的性能。
2.5 消融性實驗
為了驗證模型中每個模塊的有效性,本文通過進行消融性實驗來評估每個模塊對整體性能的影響。具體而言,分別通過移除超圖卷積模塊(HCNOESSR-A) 、移除對比學習模塊(HCNOES-SR-B) 和注意力機制模塊(HCNOES-SR-C) 構建3個子模型,并記錄性能變化,以探究每個模塊的作用。實驗結果如表3 所示。
從表3可以觀察到,三個子模型在兩個數據集上均出現了不同程度的性能下降,因此超圖卷積模塊、對比學習模塊和注意力機制模塊均對整體的推薦性能產生了積極的促進作用。
HCNOES-SR-A 子模型由于缺失了超圖卷積模塊,導致每個節點無法聚合鄰居節點的信息。對于兩個數據集的P@20和MRR@20指標,平均損失了7.1%和5.5% 的性能,驗證了信息傳播過程對推薦系統提取項目特征的重要性。HCNOES-SR-B 子模型因為缺失了對比學習對項目嵌入表示的優化作用,在P@20 和MRR@20 兩個指標上也分別損失了平均5.8% 和7.3% 的性能,說明項目在嵌入空間中均勻分布有助于推薦系統區分不同項目并提升性能。HCNOES-SR-C 子模型去除了注意力機制模塊,無法有效地區分會話中不同項目的重要性。對于兩個數據集的P@20和MRR@20指標平均帶來了8% 和11.2% 的性能損失,這說明區分用戶的關注重點、捕捉用戶的長短期興趣可以提供更有針對性的推薦結果。
在Diginetica數據集上,去除對比學習模塊帶來了較大的性能損失。這是因為對比學習優化了嵌入空間中的數據分布,從而提高了特征表示的質量。這種優化可以有利于模型對商品的歸類和區分,使得模型能夠更準確地理解和利用商品之間的相似性和差異性。而在Nowplay?ing數據集上,去除注意力機制模塊帶來較大的性能下降。這是因為音樂推薦需要考慮多個方面的用戶興趣,如音樂風格、情感、時間偏好等。注意力機制可以幫助模型有效地捕獲和組合這些多維度的興趣,從而提供更具個性化的推薦。
2.6 參數分析
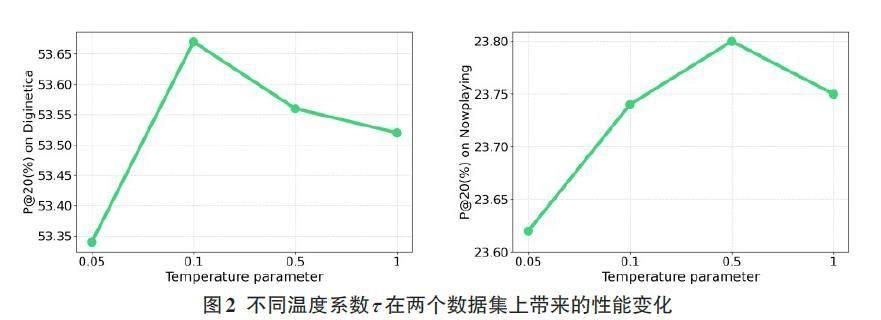
對比學習的關鍵作用是通過離散化嵌入空間中項目之間的距離,使得嵌入向量的分布更為均勻。為了探究對比學習中溫度超參數τ 對實驗結果的影響,本文將其取值范圍設為{0.05, 0.1, 0.5, 1},并在兩個數據集上進行實驗。不同取值對應的實驗結果如圖2所示。從實驗結果可以看出,兩個數據集上的峰值性能分別在τ 取值為0.1和0.5時出現。這是因為在個性化音樂推薦中,樂曲之間的相似性通常低于商品,需要取相對較大的溫度系數以使項目分布更趨于平滑。而在電子商務中,項目之間的關聯性通常較大,需要取相對較小的溫度系數以使項目分布更為集中。
3 結束語
本文提出了基于超圖卷積網絡和嵌入空間優化的會話推薦模型HCNOES-SR。該模型利用超圖來建模項目間隱含的高階多對多聯系,并通過對比學習優化了項目嵌入表示的分布和質量。最終,通過注意力機制捕獲了用戶的長短期興趣。在兩個真實數據集上進行了一系列的實驗,驗證了該模型總體上比基準模型具有更為準確的推薦性能。本文模型主要解決了會話推薦中項目間高階關聯關系的超圖建模和項目嵌入的空間分布優化問題。下一步將繼續研究如何設計簡潔高效的信息傳播方法,以構建更為輕量化的模型,在不損失推薦精度和準確率的前提下提升推薦的效率。
參考文獻:
[1] LUDEWIG M,JANNACH D. Evaluation of session-based rec?ommendation algorithms[J]. User Modeling and User-AdaptedInteraction,2018,28(4):331-390.
[2] JANNACH D,QUADRANA M,CREMONESI P. Session-basedrecommender systems[M]//Recommender Systems Handbook.New York,NY:Springer US,2012:301-334.
[3] 趙海燕,趙佳斌,陳慶奎,等. 會話推薦系統[J]. 小型微型計算機系統,2019,40(9):1869-1875.
[4] RENDLE S, FREUDENTHALER C, SCHMIDT-THIEME L.Factorizing personalized Markov chains for next-basket recom?mendation[C]//Proceedings of the 19th international conference on World wide web. Raleigh North Carolina USA. ACM,2010.
[5] HIDASI, BAL?ZS, et al. Session-based recommendations withrecurrent neural networks[EB/OL]. arXiv preprint arXiv:1511. 06939 .
[6] LI J,REN P J,CHEN Z M,et al. Neural attentive session-basedrecommendation[C]//Proceedings of the 2017 ACM on Confer?ence on Information and Knowledge Management. SingaporeSingapore. ACM,2017.
[7] TAN Y K,XU X X,LIU Y. Improved recurrent neural networksfor session-based recommendations[C]//Proceedings of the 1stWorkshop on Deep Learning for Recommender Systems. Bos?ton MA USA. ACM,2016.
[8] 李亞超,熊德意,張民. 神經機器翻譯綜述[J]. 計算機學報,2018,41(12):2734-2755.
[9] WU S,TANG Y Y,ZHU Y Q,et al. Session-based recommenda?tion with graph neural networks[J]. Proceedings of the AAAIConference on Artificial Intelligence,2019,33(1):346-353.
[10] 孫鑫,劉學軍,李斌,等.基于圖神經網絡和時間注意力的會話序列推薦[J].計算機工程與設計,2020,41(10):2913-2920.
[11] 林幸,邵新慧.基于圖神經網絡的推薦系統模型[J].計算機應用與軟件,2023,40(3):325-330.
[12] XIA X,YIN H Z,YU J L,et al.Self-supervised hypergraph con?volutional networks for session-based recommendation[J].Pro?ceedings of the AAAI Conference on Artificial Intelligence,2021,35(5):4503-4511.
[13] CHEN T W,WONG R C W.Handling information loss of graphneural networks for session-based recommendation[C]//Pro?ceedings of the 26th ACM SIGKDD International Conferenceon Knowledge Discovery & Data Mining. Virtual Event CAUSA.ACM,2020.
[14] PAN Z Q,CAI F,CHEN W Y,et al.Star graph neural networksfor session-based recommendation[C]//Proceedings of the29th ACM International Conference on Information & Knowl?edge Management.Virtual Event Ireland.ACM,2020.
[15] WANG T Z,ISOLA P.Understanding contrastive representa?tion learning through alignment and uniformity on the hyper?sphere[C]//International Conference on Machine Learning.PMLR, 2020.
[16] KHOSLA, PRANNAY, et al. Supervised contrastive learn?ing. Advances in neural information processing systems,2020 (33): 18661-18673.
[17] LIU Q,ZENG Y F,MOKHOSI R,et al.STAMP:short-term atten?tion/memory priority model for session-based recommendation[C]//Proceedings of the 24th ACM SIGKDD International Con?ference on Knowledge Discovery & Data Mining. LondonUnited Kingdom.ACM,2018.
【通聯編輯:唐一東】
基金項目:安徽省自然科學基金項目(2008085MF193,2308085MF223) ,安徽質量工程項目(2021cyxy047)
