強化節點的全局重要度的會話推薦算法
2024-06-26 07:52:14龔文正謝程遠張恒
電腦知識與技術 2024年13期
龔文正 謝程遠 張恒

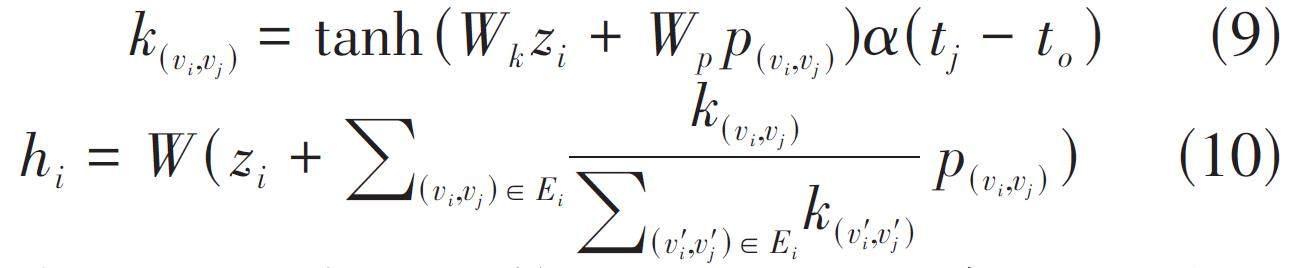

摘要:會話推薦旨在匿名會話中預測用戶下一次的交互信息。現有基于圖神經網絡的會話推薦模型(GNN) 在全局圖中融入了兩兩物品的轉移關系,但忽略了項目本身在全局圖中的重要性,從而影響了推薦精度。此外,在會話圖中對鄰居節點對當前節點的影響考慮不全面。因此,提出了一種新的強化節點全局重要度的會話推薦算法(EGIN-SR,EnhancedGlobal Importance of Nodes Session Recommendation Algorithm) 。該算法在全局圖中利用PageRank計算每個項目的重要度,以此更加精準地表示項目。同時,設計了一種轉換感知權重聚合方法,可以感知到不同的節點轉換,突出不同鄰居對其自身的重要性。在Diginetica、Tmall天貓數據集和Nowplaying數據集上的實驗表明,該方法在性能上優于現有的主流方法,證明了此方法的有效性。
關鍵詞:會話推薦;圖神經網絡;節點信息;全局重要度
中圖分類號:TP391 文獻標識碼:A
文章編號:1009-3044(2024)13-0017-04 開放科學(資源服務)標識碼(OSID) :
0 引言
隨著互聯網的快速發展和信息的爆炸性增長,人們在面對海量的內容和選擇時往往感到困惑和不知所措。在這個信息過載的時代,推薦系統[1]成了解決這一問題的有效工具。基于會話的推薦系統[2-4]作為推薦系統的重要分支之一,通過分析用戶的歷史行為和會話信息,能夠更準確地理解用戶的興趣和需求,并為其提供個性化的推薦服務。
基于會話的推薦系統的工作原理是基于用戶在一段時間內的行為和交互,而不僅僅是考慮單個事件。通過分析用戶的會話信息,包括點擊、瀏覽、購買等行為,可以更好地捕捉用戶的興趣演化和行為模式,并據此進行推薦。會話是指用戶在一段時間內的連續交互行為,可以包括點擊、瀏覽、購買等動作。一些研究將其看作一個行為序列,早先的研究采用馬爾可夫鏈、主題模型、概率生成模型等方法來對會話序列進行建模。隨著深度學習技術的不斷發展,越來越多的研究采用深度學習模型來分析用戶在不同上下文中的行為,以更好地理解用戶的興趣演化和行為模式。一些研究采用RNN對會話序列進行建模,通過將會話序列作為輸入,RNN可以學習到會話中不同項目之間的關聯性和順序,進而研究用戶行為的復雜性。以上方法包括早期的研究,都僅僅是對一個會話進行建模,并從中發現用戶的興趣偏好。然而不同的會話確實包含著用戶的不同偏好信息,例如,用戶在一個會話中可能會連續瀏覽幾個相似的商品,這表明用戶對這類商品有較高的興趣。而在另一個會話中,用戶可能會點擊一些與之前不同類型的商品,這可能意味著用戶對其他類型的商品也有一定的興趣。盡管現有的方法都已取得了不錯的效果,但是未考慮到項目的全局權重,可能會導致推薦結果的片面性和局限性。另一方面,其沒有對項目轉換的重要程度做區分。在會話中,不同的項目到項目的轉換反映了用戶不同的興趣與需求,通過了解項目轉換能夠捕捉用戶興趣的變化。
因此,我們提出了一種新的強化節點的全局重要度的會話推薦算法。首先為會話圖引入類型編碼,以此來區分來自不同會話以及豐富項目節點的信息。其次計算每個項目在全局圖上的重要度,為不同項目賦予不同的全局重要度。同時,考慮通過項目轉換的頻率來判斷其重要性,并為其賦予更高的權重。在進行信息傳播的過程中,為不同的轉換賦予不同的權重,較近發生的轉換也賦予更高的權重。較高的權重可以使該項目在推薦過程中更加突出,從而更好地滿足用戶的個性化需求。
1 相關研究
基于會話的推薦系統是一種利用用戶的會話歷史數據進行個性化推薦的方法。這種推薦系統考慮了用戶在會話中的行為順序和上下文信息,能夠更準確地理解用戶的興趣和需求。在基于會話的推薦中,根據對會話建模方式的不同,將基于會話的推薦模型分為基于序列的模型和基于圖的模型。
基于序列的模型將用戶的會話歷史看作一個序列,通過建立序列模型來預測用戶下一個可能感興趣的物品。這些方法通過分析會話歷史中物品出現的頻率和順序,來預測用戶下一個可能選擇的物品。微軟研究院提出了FPMC模型[5],該模型結合了馬爾可夫鏈和矩陣分解的思想。它將用戶的行為序列看作是一個馬爾可夫鏈,其中每個行為都是鏈中的一個狀態。FPMC模型通過學習用戶的行為序列,來捕捉用戶的興趣演化和行為模式。循環神經網絡(RNN) 和長短期記憶網絡(LSTM) [6]也是常用的序列模型,它們可以捕捉用戶在不同時間點的興趣演化和偏好變化。Hidasi等[7]提出的GRU4Rec推薦模型使用門控循環單元作為其核心組件。GRU4Rec的一個重要特點是它是一個無狀態模型,這意味著它不需要維護用戶的狀態信息。相比于其他基于會話的推薦模型,如FPMC, GRU4Rec更加簡單和高效。Zhang等[8]在GRU4Rec基礎上提出了STAMP 模型,與GRU4Rec 相比,STAMP 引入了時間信息,以更好地捕捉會話中物品的順序和時間間隔。基于序列的推薦模型在處理長時間間隔的會話時可能會遇到挑戰。由于模型主要關注最近的行為,長時間間隔的行為可能會被忽略,導致模型對用戶興趣的理解不準確。在處理長序列時,可能會遇到難以捕捉到遠距離依賴關系的問題。
一些研究也引入圖思想進行推薦。基于圖的模型將用戶的會話歷史表示為一個圖結構,其中物品作為節點,用戶行為作為邊。通過分析圖結構中的節點和邊的特征,可以推斷用戶的興趣和偏好。Wu等[9]提出了一種基于圖神經網絡的會話推薦模型SR-GNN,它將用戶行為序列轉化為一個有向圖,使用圖神經網絡充分學習用戶之間的關系和物品之間的交互信息,從而提高推薦的準確性。Qiu等[10]將因子分解模型和圖神經網絡進行結合,在節點表示的計算中引入了因子分解的思想,將節點的表示分解為多個因子,以更好地建模節點之間的交互。但是由于引入了因子分解的計算,模型的復雜度較高,需要更多的計算資源和訓練時間。DSAN[11]通過自注意力機制在會話中學習到其中商品之間的協作信息,即同一會話中不同商品之間的關系。GCE-GNN[12]通過引入圖上下文嵌入,將節點的鄰居節點信息和全局圖結構信息融合到節點的嵌入表示中,使會話間可以互相輔助進而生成表示。從全局層面與會話層面進行建模學習,同時結合兩個層面得到最終的表示。GCE-GNN[12]利用全局級項目表示學習層,在全局圖上傳播學習項目轉換信息,并且使用注意力機制來區分項目的重要性。
本文提出的模型在學習之前工作優點的基礎上更深層次地對會話信息進行挖掘,有效地利用這些信息從而進一步提升推薦的精準度。
2 EGIN-SR 模型框架
為了更好地利用大量會話中存在的相關信息,本文通過對會話級和全局級項目的處理,考慮每個項目的重要度和項目間轉換的重要性來增強推薦,更好地理解用戶需求,從而提供更具個性化的推薦。該算法的總體模型框架如圖1所示,主要由3個模塊組成:全局級項目表示學習、會話級項目表示學習以及推薦模塊。
2.1 問題定義
會話推薦的目標是通過分析會話和全局信息的復雜聯系來預測用戶下一個可能訪問的項目。將會話轉化為一個會話圖,用以反映項目之間的轉換。用V = {v1,v2,...,v } n 表示全部n 個物品的集合。用S = {s1,s2,...,s } m 表示一個已知的會話S,si 表示用戶在會話S中的第i 次瀏覽的物品,m 表示瀏覽物品總次數。會話推薦的任務是從V中選出TOP值最大的N個物品Ntop (1 ≤ N ≤ |V |)個最可能的候選項,用以預測會話S 的下一次點擊的項目sm + 1,并生成推薦列表。
2.2 會話圖構建
會話圖是每個單獨的會話序列構建而成,可以使得會話序列之間的轉換模式更加清晰。具體而言:對于給定的會話序列S = {s1,s2,...,s } m ,設Gs = (V ) s,Es 為其構造的會話圖,其中,Vs ? V(V 表示所有會話項目);Es = {e } ij 表示會話中相鄰項目的邊的集合,eij 是會話中相鄰項目(si,sj) 。在這里,筆者采用SR-GNN的方法,為每條邊分配一個歸一化權重,其計算方式為邊的出現次數除以該邊的起始節點的出度。
2.3 全局圖構建
全局圖是以所有會話中的項目表示的轉換信息構建的,其中包含了所有會話中出現的領域項目。具體而言,設全局圖為G′ = (V′,E′),其中,V′包含V中所有項目的節點集合,E′ = {e } ij| (s ) i,sj | si ∈ V,sj ∈ Nε (s ) i是其邊的集合,Nε (s ) i 是節點si 的ε-領域。圖1中,我們構建了全局圖(ε=2) ,并為其連接邊生成權重,用以區分si 的鄰居重要性。并且只保留圖G′上每個項目權重最高的前N 個邊,也不會動態更新圖的拓撲結構。
2.4 全局圖項目學習
本模型構建了一個全局級項目表示學習層,它在全局圖中傳播學習項目轉換信息,并使用注意力機制來區分項目的重要性。首先,考慮到項目的不同鄰居對自身具有不同程度的貢獻,因此更準確地判斷哪些鄰居對于生成準確推薦更具影響力。因此,本文使用注意力機制來計算鄰居項目節點的注意力系數,并根據當前上下文和目標項目自動學習鄰居的貢獻度。注意力系數的計算如公式(1) :
式中,ei,j 表示鄰居節點vj 對節點vi 的重要性,并采用LeakyReLU 作為激活函數,a* 為可學習的權重向量,ri,j 表示vj 和vi 的連接關系,h′i 和h′i 分別是節點vi 和其鄰居節點vj 的向量表示。由于圖中所有的節點之間并不全是相連接的,為了使不同的節點之間具有可比性,本文對其注意力系數進行歸一化。如公式(2) :
由于節點的鄰居不同,它們之間的貢獻也不同。因此,注意系數αi,j 是不對稱的,Ni 表示節點i 的鄰居節點集。
有些項目可能會在不同的會話中出現,并且可能會頻繁出現。這表明許多用戶對該項目有較大的偏好。通過計算全局重要度,可以識別在會話中具有重要地位的項目,并確保具有更高全局重要度的項目信息能夠快e速R傳an播k 到整個全局網絡。因此,本文利用Pag? 算法[13]來計算所有全局圖中項目在圖中的全局重要度,以此來更加精準地表示項目,并進一步提高模型的表達能力,如公式(3) 所示:
其中,PR(v ) i 為每個節點vi 的全局重要度,用v′為指向節點vi的節點,in (v ) i 為節點vi的入度, out (v′)為v′的出度。為了防止沒有入度或出度使節點的PR值為0,加入了阻尼因子的d(0 ≤ d ≤ 1),并且保證每個節點的PR值之和為1。
以圖1為例,V4 有3個出度,分別指向了V5、V6、V7節點,那么我們認為用戶點擊V4 時下一個所點擊的項目就有V5、V6、V7 的可能性,概率為1/3。同樣地,我們可以得到全局圖中7個節點的轉移矩陣M,假設所有節點的初始重要度都是一樣的,即w0 全為1/7,設d 為0.85。通過一次轉移后,各節點的重要度w1如公式(6) :
得出的各節點重要度如圖1所示,在經過n 次迭代后,可得到最終平衡狀態下各個節點的重要度。
在得到鄰居項目的注意力權重和全局重要度后,將鄰居項目信息進行整合,生成新的項目特征hi,同時,通過注意力機制,降低了物品特征學習的噪聲,如公式(7) 所示:
2.5 會話圖項目學習
全局圖中項目的鄰居對其自身的重要性不同,利用注意力機制來學習不同節點之間的權重。在會話圖中,許多項轉換發生的次數很多,說明兩者存在著很強的聯系,該轉換(邊)的重要性很高。因此,對于發生次數更多的轉換賦予更高的權重。
會話序列輸入到圖神經網絡中,得到會話序列中涉及的所有項目表示為Ds = [h,v1 ] ,h,v2,...h,vm 同時,用一個可學習的位置嵌入矩陣R=[r1,r2,...rm ],ri表示特定位置i 的向量,m 為會話序列長度,位置信息zi 通過級聯和非線性變化進行聚合如公式(8) :
在進行信息傳播的過程中,利用注意力機制為項目vi 的轉換邊集Ei 中不同的轉換賦予不同的權重k(vi,vj ),進而計算得到基于項目轉換的項目表示hi 計算公式如下:
其中,tanh是激活函數W、Wk、Wp 和b 都是可學習的參數,qT 與W 為線性轉換矩陣增強模型的擬合能力。
再對項目表示hi 進行聚合,得到會話圖視角下的會話表示hs,計算如下公式(11) :
2.6 預測層
在2.4和2.5小節中分別得到全局圖與會話圖視角下的會話表示,為了進行推薦預測計算全部候選項目分數。本文首先將全局圖與會話圖視角下的會話表示進行融合,得到最終的會話表示hl,計算公式如下:
hl = wT ? [ h ] i||hs (12)
其中,||為拼接操作,?為矩陣乘法運算,wT 為可學習的參數矩陣。
最終,使用余弦相似度來計算會話表示l 與候選項目u的相似度Possibility(l, u),得到每個候選項目的推薦概率,計算如公式(13) :
式中,hu為候選項目的表示,hl為計算向量的模。
3 實驗
3.1 數據集
本文旨在構建基于會話的推薦模型,以建立準確、個性化的用戶模型,從而理解用戶的興趣和需求,并根據這些信息進行推薦。為驗證所提模型的有效性和優越性,選擇了三個數據集,分別是Diginetica、Tmall天貓數據集和Nowplaying。
1) Diginetica數據集是廣泛應用于基于會話的推薦系統研究的開放數據集,為歐洲某電商平臺6個月內所有匿名用戶的交易數據,是CIKMCup2016公開數據集。2) Tmall天貓數據集是非常著名的電子商務數據集,被廣泛應用于推薦系統和數據挖掘領域的研究,包含大量真實交易數據,涵蓋多個商品類別和用i戶ng行為,包括數百萬用戶和數千萬商品。3) Nowplay? 數據集是用于基于會話的推薦系統的常用數據集之一,記錄了用戶在社交媒體平臺上發布的音樂播放信息,包括用戶ID、歌曲ID、播放時間等。這些數據可用于構建用戶的音樂播放歷史和會話信息,從而為推薦系統提供更準確的個性化推薦。以上數據集的詳細統計信息見表1。
3.2 實驗設置
通過分析所提模型的原理和結構,發現影響預測效果的主要超參數包括訓練輪次Epoch、隱藏層維度、注意力頭數、學習率等。因此,本研究對這些超參數進行了一系列實驗,通過反復實驗分析確定Epoch為20、隱藏層維度為16、注意力頭數為2,并采用學習率為1e-3的Adam優化器對參數進行優化。為避免模型過擬合,筆者在每層之間設置了Dropout 層,將Dropout率設為0.5。
為更好地評估所提模型的預測效果,選擇了相關研究中較常用的評價指標P@N 和MRR@N。其中, P@N通常用于評估推薦系統的性能,其中P表示準確率(Precision) ,N表示推薦列表的長度(Top-N) 。該指標表示在推薦列表中,有多少個項目是用戶真正感興趣的。例如,如果P@5為0.6,意味著在前5個推薦項目中,有60% 是用戶真正感興趣的。計算如公式(14) 所示,本文采用P@20作為衡量標準。
另一個評價指標是MRR@N,它代表平均倒數排名(Mean Reciprocal Rank) ,N 表示推薦列表的長度(Top-N) 。MRR@N衡量了推薦系統在給定的推薦列表中,用戶感興趣的項目在排名中的平均位置。MRR@N的取值范圍是0~1,數值越接近1表示推薦系統的性能越好。該指標可以幫助評估推薦系統在給定的推薦列表中,用戶感興趣的項目的排序質量。計算如公式(15) 所示,本文采用MRR@20作為衡量標準。
式中,nhit 表示前k 項中正確推薦項目的數量,N 是總樣本數,M 表示前k 項推薦項目中正確推薦的樣本集,Rank (t)是物品t在推薦中排名。
3.3 實驗結果與分析
3.3.1 對比試驗
為了驗證強化節點全局重要度的會話推薦算法的有效性和優越性,進行了對比實驗,實驗結果如表2 所示。本文選擇了經典模型和最新模型進行對比實驗。經典模型包括POP、Item-KNN[14]、FPMC、GRU4Rec、NARM[15]等模型。其中,POP、Item-KNN和FPMC 利用統計學方法對項目進行排名推薦,而GRU4Rec和NARM模型則利用GRU對用戶會話進行建模。除了這些經典模型外,還有STAMP、SR-GNN 和FGNN等采用了注意力機制或GNN的新穎模型。STAMP是一種基于會話的推薦系統模型,旨在解決傳G統N基N于會話推薦系統中的冷啟動和長尾問題。SR- 利用了圖神經網絡的能力,來捕捉會話中物品之間的順序依賴關系和語義關聯。FGNN模型通過結合矩陣分解和圖神經網絡的思想,在推薦系統中取得了較好的效果,提供更準確和個性化的推薦結果。
根據表3可知,在P@20、MRR@20指標上,本文所提模型均取得了最佳效果。這說明本文所提模型推薦的項目更符合用戶的選擇和興趣。相比之下, GRU4Rec、NARM等模型較POP、Item-KNN、FPMC等基于傳統統計學的方法表現更出色。后者主要基于物品的流行度或相似度進行推薦,未考慮到用戶的個性化需求和會話的上下文信息。而GRU4Rec、NARM 模型利用循環神經網絡(RNN) 建模用戶的會話歷史,能夠捕捉會話中物品的順序和上下文關系。STAMP 在Tmall和Nowplaying數據集上取得了比GRU4Rec、NARM更好的效果。STAMP模型使用了自適應記憶機制,根據用戶的歷史行為和當前會話的上下文動態選擇和更新記憶,更好地適應用戶的興趣變化和會話的動態特性。SR-GNN、FGNN 采用了圖神經網絡(GNN) 的思想,在推薦系統中取得了較好的效果,說明基于會話的圖結構利用圖神經網絡建模用戶的興趣和上下文信息,可以綜合考慮用戶和物品的特征以及它們之間的交互關系,提供個性化的推薦結果。
本文所提方法在所采用的數據集上都取得了最佳效果,與SR-GNN一樣采用GNN的思想,在會話圖上學習用戶的興趣變化。同時,為會話圖計算每個項目在全局圖上的重要度以及項目轉換的權重,使推薦模型能更好地利用會話歷史數據,并考慮到不同項目和類型之間的關系,從而提供更準確和個性化的推薦結果。
3.3.2 消融實驗
為進一步提高基于會話的推薦模型的推薦精準性,本文在GCE-GNN模型的基礎上,為全局級項目表示學習層添加全局重要性信息。在生成全局項目表示時,融合了PageRank算法計算vi 的全局貢獻度,提高了表達能力。另外,通過引入轉換感知來提高模型對會話表示的學習能力。為證明以上改進對模型推薦效果的影響,本研究設置了3個消融實驗,實驗結果見表3。
如圖2、圖3所示,單獨使用PageRank時,在三個數據集中的P@20、MRR@20指標均優于不使用的基礎模型,說明使用PageRank為節點賦予全局貢獻度,可以使全局級表示更精準地對鄰居節點進行聚合,從而提高全局級表示的表達能力。單獨引入轉換感知時的效果同樣優于基礎模型,證明為轉換邊賦予不同的權重,可以使模型更好地匹配用戶偏好,進而提升模型的推薦精度。最終,同時使用以上兩個策略時,獲得了最好的推薦效果。
4 結論
為了進一步提升基于會話的推薦模型的效果,本文在GCE-GNN模型的基礎上進行了改進。通過研究分析,發現GCE-GNN利用全局級項目表示學習層,在全局圖上傳播并學習項目表示,其只是利用了節點的局部重要性,未考慮節點的全局重要性。因此,本文利用PageRank得到全局圖中節點的全局重要性,在生成全局級項目表示時將其引入,令模型能夠獲知節點在全圖上對用戶的重要性,以此來提高全局級項目表示的表達能力。另一方面,我們對轉換邊的重要程度做出區分,頻繁出現的節點間的轉換更受用戶的偏愛。因此,本文在進行信息傳播的過程中,為不同的S轉R換賦予不同的權重。最后,將本文所提模型EGIN- SR與8個基準模型進行了對比實驗,結果表明EGIN- 具有更好的效果。本文還進行了消融實驗,進一步驗證了使用PageRank可以提高目標節點嵌入的表達能力與精確度。綜上所述,本文所提改進模型在進行推薦時,能夠更好地匹配用戶偏好。
【通聯編輯:唐一東】
