3D 模型均勻細分算法及其GPU 實現方法研究
2024-06-26 07:52:14劉軒黃海于
電腦知識與技術 2024年13期
劉軒 黃海于

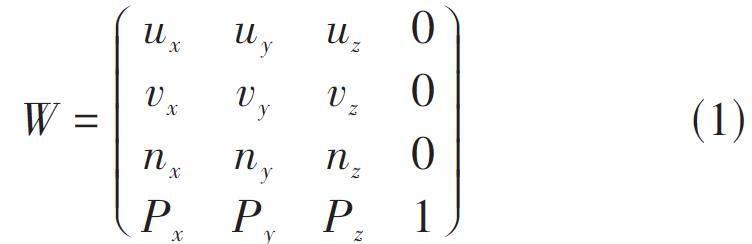
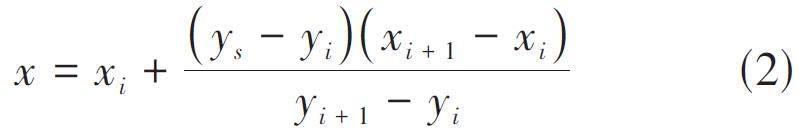
摘要:3D模型的細分是計算機圖形學重要的研究內容,在對較為復雜的3D模型進行高精度細分時,需要進行大量的計算,CPU并不能很好地完成該任務,GPU具有并行架構,計算能力十分強大,因此選擇使用GPU對細分算法進行加速,可以極大地提高模型細分的速度。文章設計了一種3D模型的均勻細分算法:掃描線-柵格填充法。對存儲模型信息的文件進行預處理,提取出細分所需要的數據,把對模型的均勻細分轉化為對三維空間中若干封閉圖形的均勻細分,將整個填充區域柵格化,利用掃描線算法對每個柵格進行填充。文章討論了該算法在GPU上的實現方法,展示了細分后的網格化3D模型,對比評估了該算法在CPU和GPU上的性能表現,探討了如何在GPU上獲得更好性能的方法。
關鍵詞: 圖形處理;模型細分;GPU并行處理;掃描線-柵格法;網格化模型
中圖分類號:TP311 文獻標識碼:A
文章編號:1009-3044(2024)13-0027-04 開放科學(資源服務)標識碼(OSID) :
0 引言
隨著科技的不斷進步,三維建模技術在計算機模擬領域的作用也越來越重要[1]。在工業制造領域,利用三維建模技術對其進行仿真模擬,可以真實地反映切削加工過程,清晰呈現工件加工后的形態,提高了生產效率,保證了加工質量[2]。在模擬加工過程中,需要對刀具和工件之間的碰撞進行檢測,涉及大量的運算[3]。若工件模型中三角面的大小各不相同,會嚴重影響模擬加工的速度,因此對工件模型按加工精細度進行均勻細分是非常必要的。
對3D模型進行均勻細分時,傳統的掃描線法在填充較為復雜的圖形時效果不佳[4]。文獻[5]提出了基于柵格的任意復雜區域自動填充算法,但該算法的細分精度和效率無法滿足工業加工的要求。本文結合掃描線和柵格填充算法,提出了一種掃描線-柵格的填充方法。將整個模型拆分為若干個三維空間中的超平面,將超平面轉化為二維平面上的封閉多邊形并使其所在區域柵格化,再利用掃描線算法對各柵格進行填充,實現圖形的均勻細分。該算法在CPU上實現比較容易,但工業加工領域中所采用的模型都比較復雜,對精細度的要求非常高,CPU無法滿足對處理速度的要求。GPU采用大規模并行處理架構[6],能同時處理多個柵格,從而快速完成復雜模型的均勻細分。
1 掃描線-柵格算法
本文使用的3D模型以STL文件格式存儲。STL 文件包含了模型中每個三角形的幾何信息[7]。在進行3D模型細分前,先對模型文件進行預處理,將共面三角形合并為封閉多邊形,然后將其轉換到XY平面上。在細分時,求出封閉多邊形的最小矩形包圍框,按所給精細度將矩形包圍框分為若干柵格;計算掃描線與圖形的交點和所在柵格的序號;以相鄰兩柵格作為待填充區域進行填充。對所有封閉圖形采用上述方法進行細分,就能實現對三維模型的均勻細分。
1.1 圖形預處理
1.1.1 共面三角形的合并
利用從STL文件中得到的三角形鄰接信息求共面三角形,使用種子生長法,需要用到一個代表當前平面號的整型變量numTri(初值為-1) 、記錄各三角形所在平面號的數組sur和一個循環隊列。算法如下:
1) 選擇一個初始三角形作為種子,將其入隊列并標記,使numTri的值加1,將數組sur中對應此三角形的元素值設為numTri;
2) 將種子三角形出隊列,判斷其鄰接三角形是否未標記且與它共面,是則將這些三角形入隊列并標記,并且把數組sur中對應這些三角形的元素值設為numTri,否則不對這些三角形和數組sur做任何處理;
3) 將隊列中三角形依次出隊列,判斷其鄰接三角形是否未標記且與它共面,是則將這些三角形入隊列并標記,并且把數組sur中對應這些三角形的元素值設為numTri,否則不對這些三角形和數組sur做任何處理;
4) 當隊列為空時,得到一個共面三角形的信息;
5) 返回第1步,重新尋找下一個種子三角形;
6) 重復第2~5步,直到所有三角形均被標記,算法結束,此時數組sur中的每個元素值就代表了各三角形所在的平面序號。
1.1.2 圖形邊緣的提取
將各三角形按所在平面序號加入所屬的空間平面,就得到了若干封閉圖形。這些圖形包含內部邊和邊緣上的邊,而掃描線算法只要求保留圖形邊緣。圖形邊緣上的三角形一定有一條邊沒有鄰接三角形,通過三角形鄰接信息求出所有符合條件的邊,只保留這些邊,就能得到圖形的邊緣。
1.1.3 坐標轉換
在得到各空間平面上的封閉圖形后,把每個封閉圖形都轉換到XY平面上,根據某封閉圖形所在的空間平面上任意一點和法向量構建局部坐標系。
設P =(Px,Py,Pz,1) ,n =(nx,ny,nz,0) 為空間平面上一點和法向量(用作z 軸)相對于世界坐標系的齊次坐標,則任取一個與n 正交的向量u =(ux,uy,uz,0) 作為x軸,再用u 和n 的叉乘結果v =(vx,vy,vz,0) 作為y 軸。這樣從局部坐標系至世界坐標系的坐標變換矩陣為:
初始狀態下,封閉圖形上所有點都用世界坐標系的坐標表示,要將它轉換到XY平面上,使用W的逆矩陣對所有點進行坐標變換即可。
1.2 掃描線求交
將封閉多邊形轉換到XY平面后,計算它在x 軸和y 軸上的最大值和最小值,得到該圖形的一個長方形包圍框,將此包圍框橫向縱向按照所給精度均勻分為m 行n 列,使用m 條分別處于每行正中間且和x軸平行的直線作為掃描線。
設有一條掃描線y = ys,依次判斷封閉圖形各條邊和它的相交情況并記錄交點信息。設封閉圖形中某條邊的兩個端點的坐標為(xi,yi) 和(xi+1,yi+1) ,則:
1) 當yi = yi+1,即該邊與掃描線平行時,沒有任何交點,直接略過該邊。
2) 當(ys - yi)(ys - yi+1) < 0時,該邊與掃描線有一個交點,由式(2) 得出它的橫坐標:
3) 當ys = yi或ys = yi+1,此時會出現角點問題,針對這種情況,可對圖形中各邊采用上閉下開的原則[8],在一條邊的兩個端點中,上端點采用閉區間,可計算此處與掃描線的交點;下端點采用開區間,不計算此處與掃描線的交點。此原則能保證每條掃描線上的交點個數為偶數,此時交點坐標已知,無須計算。
1.3 特殊情況的處理
各條掃描線的間距是固定的,在許多情況下,掃描線和圖形中各邊無法匹配,這會使某些掃描線和圖形邊界的交點數被誤記為0。針對此類問題,需要做近似化處理,當某條非水平邊有一個端點和某條掃描線的距離足夠近時,就認為它們相交。圖1(a) 是由共面三角形合并生成的一個封閉圖形,圖1(b) 為保留其邊緣部分后得到的圖形。在圖1(c) 中,對該圖形使用本算法進行均勻細分時產生了上述問題,圖形上出現了空洞。在近似化處理后,如圖1(d) 所示,模型上的空洞問題得到解決。
1.4 使用柵格進行圖形均勻細分
本文將掃描線法與柵格法結合,將一條掃描線與一行柵格對應,從而使傳統區域填充算法中對像素點的填充轉變為對柵格的填充。
在得到了一條掃描線上與封閉圖形的所有交點之后,按照橫坐標值從小到大依次排列,將它們兩兩視為一組,作為一段待填充區域。對于一組交點,分別計算兩個點所在的方格序號,其中行序號與掃描線所在行相同,列序號可由式(3) 求得:
其中,x 為交點橫坐標值,left是封閉圖形矩形包圍框最左端的橫坐標值,tessellation為給定的精細度,┌ ┐為向上取整符號。
計算出兩個交點所在的方格序號后,對它們之間的每個方格使用兩個大小相同的三角形進行填充即可。對整個封閉圖形完成填充后,就實現了對該圖形的均勻細分。
2 算法在GPU 中的實現
機械加工過程中所涉及的模型比較復雜,對精細度的要求也比較高,導致填充過程中涉及大量的計算。GPU適合處理計算密集型任務[9],將填充任務交給GPU來執行,可以大大提高細分的速度。
2.1 在GPU 上的實現過程
對于每組交點,前面的算法已分別求出它們所在柵格單元號。GPU將對兩柵格和它們之間的柵格進行填充,每次向GPU傳送一對柵格信息,經GPU處理后將目標區域中的柵格填充并輸出。
繪制時每次的輸入是掃描行上的一對柵格信息,輸出是對應區間內的若干三角形構成的柵格。因此,將填充任務交給GPU端的幾何著色器(GS) 完成,GS 能夠接收完整的圖元(如單個點、線段的兩個點、三角形的三個點),處理后可以輸出指定的圖元,適合處理本文中的柵格填充操作。
為了向GPU中的GS傳送待填充的柵格信息,設計合適的數據結構十分重要。柵格信息除了所在列號和行號外,還應包含所在封閉圖形平面的法向量、細分精細度,以及二維到三維空間的轉換矩陣信息等。本文在Direct3D 12環境下進行圖形程序開發,向GPU傳輸數據時,要將它們包裝為4個一組的向量形式,由于每對相鄰的柵格都在同一平面上,它們除了列號之外的信息均相同,因此每次使用一個結構體變量表示一對柵格,結構體定義如下:
其中DirectX::XMFLOAT4為DirectX中的一種向量類型,可存儲4個float類型的分量數據。Pos存儲第一個柵格列號、第二個柵格列號、柵格行號和細分精細度;Nor存儲柵格所在平面的法向量;Matrix0、Ma? trix1、Matrix2、Matrix3分別存儲4x4的轉換矩陣每一行的數據。
將模型各超平面上的所有柵格對求出來之后,把它們依次按上述格式封裝并傳輸至GPU。一對柵格數據被GS接收后,判斷它們所在的列號是否相同,若相同則只計算填充一個柵格所需的兩個三角形的頂點信息;若不同,則計算填充兩個柵格之間所有柵格的若干三角形頂點信息。此時,各頂點還處于XY平面上,要將各頂點用轉換矩陣W進行變換,使其回到原位置。最后,將各頂點以三角形帶的形式輸出,即可完成對一塊目標區域的填充。
GS每次處理一對柵格,輸入為一個代表柵格對的pieceVertex類型變量gin,輸出為填充柵格區域的三角形頂點集合triStream。上述算法的偽代碼如下:
輸入:待填充的柵格對信息gin
輸出:用于填充柵格區域的三角形集合triStream
1) function GS<(gin,triStream)
2)column1<-gin.Pos[0];
3)column2<-gin.Pos[1];
4)y<-gin.Pos[2];
5)tes<-gin.Pos[3];
6)nor<-gin.Nor;
7)trans<-(gin.Matrix0,gin.Matrix1,gin.Matrix2,gin.Matrix3)
8)for column<-column 1 to column 2 do //填充一個或若干柵格
9)v[0]<-(column*tes,y+0.5*tes,0,1)//計算此柵格的四個頂點位置
10)v[1]<-((column+1)*tes,y+0.5*tes,0,1)
11)v[2]<-(column*tes,y-0.5*tes,0,1)
12)v[3]<-((column+1)*tes,y-0.5*tes,0,1)
13)for i<- 0 to 3 do
14)v[i]<- mul(v[i],trans)//將頂點位置轉換回三維空間
15)triStream<-(v[0],v[2],v[1])//將兩個三角形加入結果集中
16) triStream <- (v[1], v[2], v[3])
17) end function
2.2 在GPU 上獲得更好的性能
一對柵格之間的柵格數是不確定的,二者的距離和細分的精細度都會影響這個數量。而GPU出于對GS性能方面的考量,限制了GS每次能輸出的標量數,此個數為每次輸出元素的頂點數量和輸出元素個數的乘積。每個柵格包括2個三角形,每個三角形有3 個頂點,因此每輸出一個柵格時標量數為6。GS每次輸出的標量數在大于40時,性能就會開始下降,考慮到該項限制,本文選擇將最大輸出標量數定為84,每次最多填充并輸出14個連續的柵格。需要在向GPU 傳輸前進行判斷,若一對柵格間的柵格數不超過14,則直接傳輸;若大于14,則要將這對柵格進行分割,使分割后的每個子段中需要填充的柵格數不超過14。
將每對柵格經過上述的檢查處理后,在不超過GS 規定的情況下盡可能每次填充一行上較多的柵格,在后續的具體實驗中得到了較好的效果。
3 實驗結果與分析
3.1 細分結果分析
對一個STL模型使用本文算法進行均勻細分,將細分的精細度分別設置為1、0.5、0.2,單位均為cm,如圖2所示。結果表明,精細度越高,網格越密集,細分效果越好。
3.2 細分效率分析
為測試該算法在GPU中的優勢,對2個STL文件大小(單位:KB) 不同的模型使用不同精度(單位:cm) 進行均勻細分,對比它們在CPU和GPU中進行細分任務時所花費的時間(單位:s) ,結果見圖3(a) 。結果表明,本文算法在GPU上的性能表現遠遠超過了在CPU 上的版本。在模型越復雜、精細度越高時,GPU中的算法優勢越大。
為測試GPU中的算法在處理不同模型時的效率表現,對3個STL文件大小(單位:KB) 不同的模型使用多種精細度(單位:cm) 進行均勻細分,對比它們在GPU中進行細分任務時所花費的時間(單位:s) ,結果見圖3(b) 。結果表明,在精度要求較低時,模型的文件大小對GPU中算法的處理速度幾乎沒有影響,這是因為GPU中對數據的處理和運算是并發進行的,在精細度情況下,不同模型對應的計算量的差距不是非常大,因此在GPU中經過并行處理所耗費的時間也相差不大;在模型間的復雜度差距很大或要求使用較高的精細度時,GPU中的處理時間才會有明顯差距。
4 結束語
針對傳統細分方法無法均勻細分模型的問題,提出了一種基于掃描線算法和柵格的均勻細分模型的算法。通過從模型STL文件中得到的信息,將對模型的每個三維空間面的處理轉化為對二維平面上封閉圖形的處理,對每個圖形用柵格作為單位進行區域填充,實現對整個模型的均勻細分,最后將填充任務交由GPU處理。經過測試,該方法可以正確地將模型按精細度均勻細分,得益于GPU強大的計算能力,算法效率有較大的提升。
參考文獻:
[1] 欒悉道,應龍,謝毓湘,等. 三維建模技術研究進展[J]. 計算機科學,2008,35(2):208-210,229.
[2] 李志鵬. 論三維建模技術在機械產品設計中的應用[J]. 內燃機與配件,2021(21):216-218.
[3] 項立富. 信息時代背景下數控加工仿真技術與軟件的開發路徑[J]. 南方農機,2019,50(22):194.
[4] 石燕.淺析區域填充算法[J]. 計算機光盤軟件與應用,2014,17(9):131-132.
[5] 邱國清. 基于柵格的任意復雜區域自動填充算法[J]. 圖學學報,2018,39(3):419-423.
[6] 董犖,葛萬成,陳康力. CUDA并行計算的應用研究[J]. 信息技術,2010,34(4):11-15.
[7] 朱虎,楊忠鳳,張偉. STL文件的應用與研究進展[J]. 機床與液壓,2009,37(6):186-189.
[8] 李慧賢,馬創新,馬良. 增材制造中GPU并行掃描線填充算法[J]. 熱加工工藝,2023(13):100-104,113.
[9] 田衛明,劉富強,謝鑫,等. 基于GPU粗細粒度和混合精度的SAR后向投影算法的并行加速研究[J]. 信號處理,2023,39(12):2213-2224.
【通聯編輯:光文玲】
