基于知識圖譜嵌入的涉詐網絡鏈接補全和關鍵節點識別
2024-06-29 22:43:18李澤卿黃誠曾雨潼冷濤
四川大學學報(自然科學版) 2024年3期
李澤卿 黃誠 曾雨潼 冷濤

摘 要: 涉詐網站作為網絡詐騙的常見載體之一,在網絡犯罪中扮演著平臺內容提供者的重要角色. 該形式的犯罪具有高度的團隊性與合作性,涉詐網站在內的涉詐資產之間往往呈現出極強的關聯. 涉詐資產、涉詐團伙等共同構成了一個龐大的涉詐網絡. 雖然已有不少研究者針對涉詐網站識別開展了相關研究,但目前針對涉詐資產的關聯性研究還相對較少. 由于涉詐網絡中節點的匿名性,導致直接獲取涉詐資產相關的身份信息極為困難. 警務人員往往難以快速準確的對涉詐網站進行溯源反制. 本文基于本體論構建了細粒度的涉詐知識圖譜,創新性地將知識圖譜嵌入應用于涉詐網站溯源領域,將涉詐網絡中的關系抽象為多維復空間上的旋轉操作,并以知識圖譜嵌入向量為依據,通過向量的空間相似性探求涉詐實體間關系網絡的相似性,利用模型進行實體關系的補全;此外,本文創新性地對涉詐知識圖譜中關系對涉詐團隊身份的揭示程度進行量化,利用加權后的涉詐關系來優化特征向量中心性算法,以挖掘其中的關鍵線索節點. 實驗結果表明,在資產關系補全上本文使用的模型有著較高的準確率,在包含37 866 個實體的數據集上的HITS@10 準確率達到了47%,效果領先于其他知識圖譜嵌入模型. 在后續案例中證明,本文設計的關鍵線索挖掘方法能夠有效地對涉詐資產進行關聯溯源,并取得了顯著的成效.
關鍵詞: 知識圖譜嵌入; 涉詐團伙; 鏈接預測; 關鍵節點識別
中圖分類號: TP309. 1 文獻標志碼: A DOI: 10. 19907/j. 0490-6756. 2024. 030004
1 引言
隨著互聯網產業的快速發展,其在給教育,醫療和經濟領域帶來巨大便捷的同時,也成為了滋生網絡犯罪問題的溫床. 網絡詐騙作為一種常見的犯罪手段,給人們日常生活和社會秩序的穩定運行造成了極大的安全隱患. 因此發現涉詐網站,挖掘涉詐網站之間潛在的團伙關系,以及分析涉詐網站背后的運作模式,對凈化網絡環境有著重要的戰略意義.
作為網絡詐騙最常見的載體,涉詐網站是網絡公害治理領域中最普遍,危害最大的詐騙手段之一. 涉詐網站通過冒充合法的信息來源,商品和服務進行傳播,造成了數十億美元的損失. 給無數個人和企業造成了無法挽回的后果[1]. 涉詐網站的形式包括但不限于分發平臺,刷單詐騙,投資理財,殺豬盤詐騙,電商購物,網絡賭博和色情網站等. 隨著互聯網業務的發展與擴張,也不乏新型涉詐網站的產生.
針對互聯網中泛濫的網絡詐騙亂象,我國頒布了《中華人民共和國反電信網絡詐騙法》,為預防,遏制和懲治網絡電信詐騙,規范網絡行為,針對網絡電信的信息鏈,技術鏈,人員鏈等各環節做出了嚴格的制度規范. 但由于網絡詐騙團伙追蹤存在著周期短,溯源難的問題. 近年來電信詐騙熱度依舊不減.
目前已有工作往往局限于涉詐網站的識別與告警,在網站創建之初便將其檢測并封禁固然重要,但僅僅局限于涉詐網站的識別與封禁往往并不能從根本上解決網絡詐騙猖獗的問題. 目前缺少一種對涉詐網站背后的犯罪個體乃至團伙的識別方法,從根源上制止網絡詐騙行為. 隨著信息對抗技術的發展,不法分子會刻意在網絡上隱匿行蹤,或散布虛假信息. 在現實情況中,僅僅通過涉詐網站本身特征提取出的身份信息有限,很難形成情報挖掘分析、評價與利用為一體的方法,因此難以定位其背后的隱藏團伙[2]. 相較于傳統的詐騙模式,網絡詐騙具有更明顯的特點,即節點匿名化,行為集團化,網站壽命周期短,行為模式較為固定等. 涉詐團伙的欺詐行為常常伴隨著信息的遺留,隨著警務人員對涉詐團伙信息的收集與涉詐活動的持續運行,構建知識圖譜已經成為一種有效手段,通過利用已被識別的涉詐實體或資產揭露匿名節點的身份信息. 從而實現涉詐團伙的精準定位與打擊.
隨著知識圖譜技術的發展,匿名涉詐節點溯源可以被建模為知識圖譜中的鏈接預測問題. 利用圖譜中已有的知識,通過規則匹配[3],協同過濾[4]和機器學習[5]等方式對潛在的實體間關系進行預測. 然而目前涉詐資產關聯的現實應用卻受到了知識圖譜補全技術的限制,如何處理涉詐知識圖譜之間的復雜關系,成為實體關系預測的關鍵.
近年來,隨著Bordes 等人[6]提出TransE 模型后,知識圖譜中的多關系數據的預測模型逐漸取得了人們的關注. 在涉詐網站溯源領域,傳統的圖數據嵌入諸如Grover 等人[7]提出的使用隨機游走的Node2vec,或是使用Skip-gram 學習圖嵌入的DeepWalk[8]等往往缺乏對異質節點間不同關系的表征能力,并不能夠很好地處理涉詐網絡中錯綜復雜的關系. 為了有效地捕捉知識圖譜中實體和關系之間的復雜性,Sun 等人[9]提出了RotatE 模型,通過將圖譜間的每個關系定義為復向量空間上的旋轉操作,在關系預測模型中取得了良好的預測成績.
為了解決涉詐網站溯源難,以及關鍵線索定位難等問題,本文將知識圖譜技術與涉詐網絡溯源領域相結合. 采用細粒度的涉詐知識圖譜構建方式,綜合考慮涉詐網站的注冊地,注冊服務商等信息,并利用RotatE 模型進行知識圖譜嵌入,通過使用復數嵌入和旋轉操作符來為涉詐資產的表征過程提供更強的學習能力,以此來實現缺失涉詐關系的補全. 在涉詐團隊溯源領域,本文以知識圖譜嵌入向量為基礎,對涉詐實體之間的相似關系進行表征. 再通過構建涉詐知識圖譜關系間的身份揭示系數矩陣計算實體的特征向量中心性,來挖掘涉詐知識圖譜中的關鍵線索節點. 最后利用余弦相似度將RotatE 學習到的目標資產與涉詐關鍵節點特征相關聯. 為涉詐資產的溯源提供精準的決策依據.
綜上所述,本文有以下貢獻:( 1) 設計了一種基于本體論的涉詐網站知識圖譜構建方法,為涉詐團伙資產建模提供了新的視角;( 2) 將知識圖譜嵌入技術RotatE 應用于涉詐資產追蹤的實踐,為解決涉詐資產關聯難問題提供了一種新思路,最終模型在37 866 個實體的數據集中HITS@10達到了47%,優于其他測試模型;( 3) 定制化調整特征向量中心性中涉詐資產關系邊的權重,用加權后涉詐關系來優化特征向量中心性算法,以更準確地挖掘涉詐網絡中的關鍵線索,增強算法可解釋性和適應性.
2 國內外研究現狀
2. 1 涉詐網站知識圖譜構建
針對于涉詐網站的圖譜構建,目前流行的方法是構建涉詐網絡行為與特征圖. 其中基于威脅元語的涉詐實體追蹤實踐被廣泛應用于犯罪組織追蹤過程. 例如以太坊欺詐數據,針對用戶的欺詐地址與交易行為進行建模,對基于以太坊的交易記錄進行挖掘來檢測以太坊欺詐[10].
但不同于傳統的網站特征構建方法,網絡公害治理關注的重點不僅僅在于涉詐網站的識別,還要注重涉詐網站的溯源,在圖譜構建中更關注能夠揭示涉詐網站背后團伙身份的關鍵信息.
自從”透明計算”項目啟動后,利用溯源圖進行威脅檢測便逐漸成為了實體追蹤領域的主流方向[10]. 通過構建威脅信息本體圖的形式,對不同類別實體之間的因果關系進行關聯,以處理緩慢又隱蔽的威脅溯源難題. 構建溯源圖以對涉詐網絡對象中復雜的數據流和控制流關系進行表征,將存在強因果聯系的實體關聯起來. 目前溯源圖的構建大多是粗粒度的,存在著“ 依賴爆炸”的問題[11]. 而重點在溯源涉詐領域的本研究需要構建更為細粒度的數據集. 針對涉詐團體提取出更有因果關系和代表性的本體. 同時,如何構建細粒度的溯源圖,為涉詐溯源提供準確的數據支持,也是未來涉詐領域研究的主流方向.
隨著網絡詐騙規模的增長,涉及到的資產和關系數量急劇增加,對全部的資產信息進行文本處理變得愈發困難. 基于知識提取的本體論在解決這一難題上表現出了良好的效果,在知識表示領域,本體論被用來對知識圖譜中的概念、實體和關系進行表示,以規范化的方式描述了涉詐領域中的實體和他們之間的關系[12]. 基于本體論的構建方法能夠清晰直觀地提供構建知識圖譜的數據,尤其是面對涉詐知識圖譜這種稀疏網絡時,其在信息抽取中發揮著重要的作用. 本體論在其他安全領域也發揮了重要的應用價值,如Mozzaquatro等人[13]創建了基于本體論的物聯網安全架構,其被用于監控物聯網設備并用于知識推理. Du等人[14]從攻擊鏈角度考慮實體關系,提出了針對APT 組織的高可讀性威脅情報推薦圖.
綜上所述,目前尚未有針對涉詐網絡知識圖譜的系統性構建方法,以解釋涉詐網絡中潛在的身份關系. 本文以域名對應涉詐資產信息為核心,包括域名創建信息和注冊者信息等構建涉詐知識圖譜,這些實體不僅是涉詐網絡研究的重要數據來源,同時也為涉詐行為復雜網絡關聯提供了有價值的信息基礎[15].
2. 2 涉詐網站溯源技術
涉詐網站的溯源一直是國內外網絡安全學者高度關注的課題. 在利用涉詐資產同源性分析技術實現追蹤溯源的研究中,安全研究人員提出了眾多方法. 目前較為主流的是基于規則匹配的溯源,通過涉詐網站頁面中包含的對身份的強表征信息,諸如郵箱、地點、電話等,對涉詐團伙的身份進行揭示[16].
目前的研究方法側重于在威脅情報關聯過程中利用URL,網頁內容等網絡特征進行關聯[17],對網站本身的身份屬性考慮較少. 隨著詐騙團伙反偵察意識的提高,傳統的身份溯源技術的效果往往較差[18]. 此時亟需能夠對涉詐網絡的深層次語義特征進行識別,來鎖定不同涉詐資產背后的同一威脅源的技術. Rid 等人[19]提出Q 模型,旨在解釋,指導和改進威脅歸因的設計,同時從戰術、操作和戰略等3 個層面相結合,將犯罪分子與犯罪行為相匹配,以最大程度地減少不確定性. 為溯源網絡威脅提供了一種系統化的方法.
隨著知識圖譜技術在實體關系表征領域取得優勢,知識圖譜表示學習正逐漸成為涉詐實體表征強有力的手段之一. 以Bordes 等人[6]提出的TransE 模型為代表,對于三元組( h,r,t ),通過將t表現為h 相對于r 的平移操作進行學習,來將實體和關系映射為空間上的向量. 隨著知識圖譜表示學習的發展,Sun 等人[9]受歐拉恒等式e-iφ =cosφ + isinφ 啟發提出了RotatE,通過將關系表示為實體在復空間上的旋轉操作,在關系預測的領域取得了較大的成功. 知識圖譜表示學習使得知識圖譜有了較低的緯度和較高的抽象層面. 利用知識圖譜表示學習生成的向量綜合了異質圖中復雜的語義信息. 結合知識圖譜本體構建方法能夠更深層次的探尋涉詐網絡中的語義信息.
由于涉詐犯罪網絡可以被建模成一個由節點和鏈接組成的廣義網絡,因此可以使用社交網絡分析和圖論的技術來識別網絡中的關鍵節點[20].傳統針對犯罪網絡的研究大多集中在未加權的關系分析上,例如度中心性[21]和介數中心性[22]等,未經拓展的這些算法可以幫助我們了解節點在網絡中的連接情況,但并不能對邊的類型和重要性進行表征. 而特征向量中心性的提出以及拓展則不僅考慮到了相鄰節點的中心性,更可以通過對關系賦予權重的方式表征節點間復雜的關系[23]. 在真實場景下,為了線索挖掘的準確性,需要設計涉詐網絡間不同關系的身份揭示權重,并結合其他的中心性指標用更復雜的指標來對涉詐網絡的關鍵節點進行挖掘.
3 方法
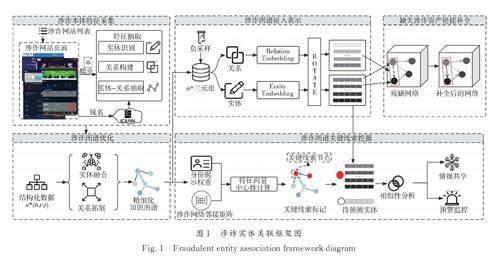
本節將介紹涉詐網站資產關聯與關鍵節點識別關聯方法,方法的整體框架如圖1 所示.
3. 1 基于本體論的涉詐知識庫構建
3. 1. 1 涉詐知識圖譜本體設計 通常,網絡涉詐活動存在著復雜的信息交換方式與運營模式. 其活動范圍從簡單的技術支持(第三方網絡服務提供商,服務器的注冊地點)到復雜的運營團隊網絡.
為更好地解釋涉詐活動,在這里引入現實場景中的一個實例,以提取對涉詐溯源有利的實體類別:
某涉詐團伙A 近日在域名注冊商B 處注冊了大量域名C 用于涉詐網站的搭建,并將其服務器地址選為D. 為了逃避國內網絡的監管,服務器地址可能會部署在國外. 如果部署在國內,需要向CNNIC(China Internet Network Information Center)申請備案,網站會擁有備案號E,與此同時網站的IP 被互聯網注冊機構分配到ASN(AutonomousSystem Number)為F 組進行管理.
依據此案例可以整理溯源需要的本體如下:
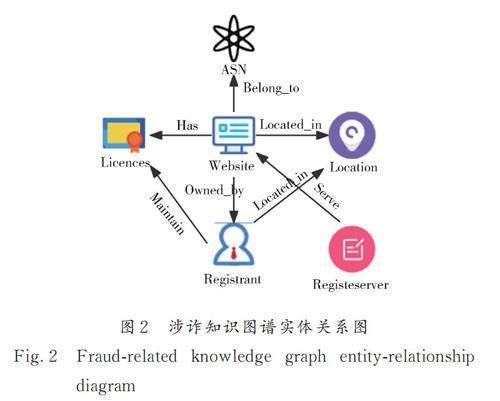
(1) Website 涉詐網站;(2) Location 實體所在的國家和地區;(3) Registrant 網站注冊人或組織;(4) ASN 網站的服務商編號;(5) Licences 網站提取的備案號;(6) RegisteServer 網站服務提供商.
在案例中,真實場景下能夠獲得的信息有限.涉詐團伙有著高度的匿名性,犯罪分子往往會故意隱藏起自己的身份信息,如地點、服務提供商等. 在知識圖譜中,匿名性表現為關系的缺失. 通過構建起足夠復雜的知識圖譜,利用知識圖譜表示學習對缺失的信息進行知識補全. 因此提取出的本體和關系需要盡可能地對涉詐資產的身份信息有著強表征能力. 在此定義能夠表征涉詐團伙身份信息的實體和關系如表1 所示.
為了全方位的建模涉詐資產的運營過程,將圖挖掘技術應用于涉詐節點的溯源中,需要用異質信息網絡來表示示例中的涉詐網絡. 為對涉詐資產更深層次的運行機理進行建模,本研究選擇了能夠更全面表征涉詐資產身份信息的本體,并以此為依據進行信息抽取,為知識圖譜嵌入提供數據支撐.
3. 1. 2 涉詐知識圖譜優化 在取得圖譜中結構化三元組后,仍需對其中冗余的實體和關系進行處理.
首先,需要對預處理后的結構化數據進行實體融合,涉詐實體在圖譜創建初期可能會出現冗余. 無論命名實體身份屬性如何,圖譜需要保證其在構建圖譜時只出現一次. 在此對知識圖譜中同一命名實體進行識別,并融合實體間的鏈接[24].
例如在本文數據集中涉詐網站這一實體與其他實體存在著不同關系,網站擁有不同的備案號,并且歸不同的服務提供商管理,這種1-n 的結構需要進行關系拓展. 使得知識圖譜嵌入過程中實體的關系特征更豐富[25].
在經過實體和鏈接處理后,涉詐知識圖譜實體-關系圖如圖2 所示.
3. 2 基于RotatE 的涉詐知識圖譜嵌入方法
RotatE 模型中關系的嵌入在空間中被表現為旋轉操作,以更好地捕捉涉詐網站實體與關系間復雜的語義關聯. 在此將實體e 與邊r 嵌入維度初始化為Ck,以將向量映射到復數空間中. 并對實體向量的實部和虛部進行隨機初始化.
根據知識圖譜的定義,對于每個實體關系對應的三元組RotatE 的得分函數定義如下,這一指標的數值越接近于零,表明模型對關系的擬合能力越強.
