集約化模式下基于機器學習的電費核算異常識別
2024-08-02 00:00:00賈穎
消費電子 2024年7期
關鍵詞:機器學習
【關鍵詞】集約化模式;機器學習;電費核算;異常;識別
引言
在電力產業領域內,電費核算作為確保電力順暢供應、捍衛市場公正性的核心步驟,其計算的精確性和作業的高效性,對電力企業經濟效益的穩定增長以及公眾形象的構建起著至關重要的作用。然而,電費核算過程中受到各種因素的影響,存在一定的異常情況,不僅影響了電費核算的準確性,也給供電企業和用戶帶來了諸多不便。因此,對電費核算異常進行識別與處理,成為當前電費管理領域亟待解決的重要問題。現階段,文獻[1]、文獻[2]提出的識別方法應用較為廣泛,雖然取得了一定的成果,但是在實際應用中仍然存在缺陷。其中,李佳凝[1]提出的識別方法在面對海量復雜與動態變化的電力數據時,難以有效應對各種異常情況,導致電費核算的準確性較低。何小宇[2]等人提出的識別方法通過構建異常識別模型實現電費核算異常識別目標,存在效率低下、錯誤率高等問題,無法滿足日益增長的業務需求。
在電力行業中,集約化模式的應用主要體現在資源的優化配置、流程的簡化與標準化、管理的精細化等方面[3]。機器學習作為人工智能的核心技術之一,在電費核算異常識別中,可以自動提取與電費核算異常相關的關鍵特征,學習電力數據的正常模式,并自動檢測與正常模式不符的異常數據,為異常識別提供有力的支持[4]。基于此,本文在集約化模式下,利用機器學習,開展了電費核算異常識別方法研究,以期為電費管理領域的可持續發展做出貢獻。
一、電費核算異常識別方法設計
(一)電費核算數據采集
為了精準識別電力客戶在電費核算過程中可能出現的異常情況,首要步驟是系統性地收集并深入剖析電力客戶的龐大用電數據集,特別是那些直接關系到電費核算精準度的關鍵信息。鑒于這些數據量龐大且復雜,本文采用了精細化的數據篩選和提煉方法,將焦點鎖定在負荷數據和數據采集等核心字段上,以確保分析結果的準確性和實用性。這些字段的詳細信息在表1中得到了具體呈現。

為了構建全面而精確的用電大數據集,首先從供電局的負控終端、智能電表或其他服務提供商處收集電費核算數據,包括電力客戶的用電記錄、賬單信息、歷史數據等。為了全面描繪電力使用的動態變化,將原始的日負荷數據轉化為直觀的日負荷曲線圖。此過程通過捕捉電力消費隨時間變化的趨勢,實現了電力使用情況的精確描繪[5]。進一步將每日連續的負荷數據精簡為24個具有代表性的時間節點數據點,這些節點涵蓋了從凌晨到深夜的負荷波動[6]。通過這種方式,構建了一個n×24維的初始負荷曲線矩陣,它集合了電力用戶的詳細用電信息,為后續的電費核算異常檢測任務提供了堅實的數據基礎。
(二)提取電費核算特征
為了聚焦關鍵信息并提升處理效率,應當提取出數據集中的重要數據點,并捕獲這些數據的核心特征,揭示用電數據與電費識別之間的潛在聯系。首先,運用流聚類技術,設定閾值,并在數據集中選擇初始簇的中心點。其次,分析每個用電數據點到這些簇中心點的距離,識別出那些與簇中心緊密相關且距離小于設定閾值的用電數據。將這些數據點歸為一組,形成數據集族簇。通過迭代更新,根據新的數據和聚類結果對族簇進行調整和優化,公式如下所示:

其中,ri+1表示迭代更新后的用電數據集族簇;i表示迭代更新的次數;mi表示當前批次加入用電數據集族簇的點的數量;ri表示上一次得到的初始族簇;qi表示當前批次的族簇中心;c表示衰減因子;ki表示族簇分配對應的點數。在此基礎上,識別出電費核算的周期性成分,公式如下:
其中,n表示時間序列的長度;μ表示時間序列的均值;σ2表示時間序列的方差。通過該公式衡量時間序列在不同時間延遲下的相似性,從而揭示用電數據的周期性特征,反映用電數據在一段時間內重復出現的模式[7]。
通過上述處理流程,能夠更精準地提取出用電數據中的關鍵特征信息,為電費核算異常識別提供有力支持。
(三)基于機器學習的電費核算異常識別
電費核算特征提取完畢后,在此基礎上,利用機器學習,對電費核算異常進行全方位地識別。利用機器學習構建適用于電費核算異常識別的人工神經網絡,如圖1所示。
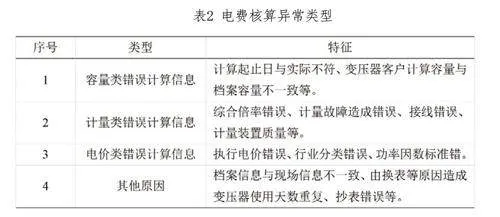
圖1中,輸入層主要包括電力用戶的各項基本信息、電費結算數據、采集數據等;輸出層包括電費核算異常、用電行為異常、抄表異常等。首先,將前期采集的詳細數據與提取的關鍵特征作為輸入,注入模型的起始層。隨后,調整并優化機器學習算法,確保其在多臺高性能服務器上能夠高效運行。接下來,通過監督學習的方式,利用這些電費核算數據對模型進行深度訓練,從而生成一個精準識別異常的人工神經網絡。一旦待審核的電費核算數據流入該模型,它能夠迅速捕捉并定位異常,準確判斷電費核算中的異常類型,并有效識別出潛在的風險點。若電費核算數據連續、穩定,波動范圍正常,且電量電費核算結果與電力系統提示的審核結果一致,無異常提示,則識別該電費核算無異常。若電費核算數據缺失或異常波動,如電量突然激增或減少,且電量電費核算結果與電力系統提示的審核結果不一致,存在錯誤提示,則識別該電費核算存在異常。電費核算異常類型,如下表2所示。

按照表2,識別出電費核算異常的具體類型。
二、實驗分析
(一)實驗準備
實驗所使用的數據集來源于某大型電網公司近五年的電費核算記錄,總數據量達到200萬個用戶記錄。這些記錄涵蓋了用戶的基本信息(如用戶ID、地址、用電類型等)、歷史用電量、電費金額以及用電時間等關鍵字段。數據的多樣性和豐富性為實驗提供了堅實的基礎。為了模擬真實的電費核算異常情況,在原始數據集中注入了不同比例和類型的異常數據,如下表3所示。
除了主動注入的異常數據外,對于用電量或電費金額明顯偏離正常范圍的異常值,進行刪除處理。本實驗在搭載Intel Core i7處理器、16GB RAM和1TB SSD的服務器上進行。使用Python 3.8作為編程語言,并安裝數據處理庫,旨在提供一個全面、真實且具有挑戰性的實驗環境,以驗證基于機器學習的電費核算異常識別方法的有效性和可靠性。
(二)識別結果分析
設定實驗場景,將客戶用電負載的變化細分為六個時間片段。實驗中,每秒接收高達1000條的電費核算數據。使用本文提出的異常識別方法,標記為方法A,為了進行對照,還引入了文獻[1]、[2]設計的兩種常規識別方法,分別標記為方法B和方法C。每種方法都獨立地處理了每秒接收的1000條電費核算數據,旨在從中識別出異常模式。完成異常識別后,我們將三種方法的識別結果與實際的電費核算異常情況進行了詳細的對比分析,評估每種識別方法在處理電費核算數據時的準確性和可靠性。通過對比,能夠清晰地識別出每種方法的識別誤差,并將這些結果以圖2進行了直觀展示。

由圖2的對比結果可以看出,本文提出的異常識別方法應用后,在識別數據量逐漸增加的情況下,識別誤差始終小于另外兩種常規方法。這意味著該方法在識別電費核算數據中的異常時,能夠更準確地捕捉和定位到實際存在的異常情況,從而提高了電費核算的準確性。
結束語
電費核算異常識別研究,旨在通過運用現代數據分析技術和人工智能算法,對電費核算過程中可能出現的各種異常情況進行深入分析和研究。該研究不僅有助于提升電費核算的準確性和效率,還能夠為供電企業制定更為科學合理的電費管理策略提供有力支持。同時,對于維護電力市場的健康、穩定運作、促進電力市場的可持續發展具有深遠影響。
猜你喜歡
電子技術與軟件工程(2016年22期)2016-12-26 21:36:42
時代金融(2016年27期)2016-11-25 17:51:36
科教導刊(2016年26期)2016-11-15 20:19:33
活力(2016年8期)2016-11-12 17:30:08
科學與財富(2016年28期)2016-10-14 21:19:17
電腦知識與技術(2016年20期)2016-08-19 18:49:49
電腦知識與技術(2016年12期)2016-06-14 00:45:31
科教導刊·電子版(2016年10期)2016-06-02 19:17:03
科教導刊·電子版(2016年10期)2016-06-02 18:04:11
電腦知識與技術(2016年3期)2016-04-07 16:12:55
