基于主成分分析和聚類的營運車輛道路行駛工況構建研究
2024-08-07 00:00:00杜宇程李會民宋尚斌晉杰
汽車科技 2024年4期



摘 要:《營運客車燃料消耗量限值及測量方法》和《營運貨車燃料消耗量限值及測量方法》系列標準是加快我國營運車輛綠色低碳運輸管理所依據的重要標準。修訂兩項標準一方面結合國內外汽車技術水平的迅速提升及道路運輸的迅猛發展狀況,另一方面對促進實現交通運輸節能減排目標、緩解石油資源短缺、降低營運車輛的碳排放量等具有重大的現實意義。其中,適時調整試驗各類工況時間占比系數是兩標準修訂的重要部分,需結合我國當前的地理類型、道路交通規則、道路結構等對實際行駛工況進一步研究分析。本文以營運貨車為例,基于各大主機廠車聯網平臺系統的數據采集來源,利用數據清洗、短行程篩選、數據規約和聚類等方法分析采集數據,能夠比較準確地反映營運車輛實際道路行駛特征。為營運車輛燃料消耗量各工況系數調整提供了技術方案和有力的數據支撐。
關鍵詞:營運車輛;行駛工況;燃料消耗量;降維;聚類
中圖分類號:U412 文獻標志碼:A 文章編號:1005-2550(2024)04-0047-07
Research on the Construction of Road Driving Conditions for Commercial Vehicles Based on Principal Component Analysis and Clustering
DU Yu-cheng, LI Hui-min, SONG Shang-bin, JIN Jie
(Research Institute of Highway Ministry of Transport, Beijing 100088, China)
Abstract: The series of standards “Limits and measurement methods of fuel consumption for commercial vehicle for passenger transportation” and “Limits and measurement methods of fuel consumption for commercial vehicle for cargos transportation” are important standards for accelerating the green and low-carbon transportation management of operating vehicles in China. The revision of the two standards combines the rapid improvement of domestic and foreign automotive technology and the rapid development of road transportation, and has significant practical significance in promoting the achievement of transportation energy conservation and emission reduction goals, alleviating oil resource shortages, and reducing carbon emissions from operating vehicles. Among them, timely adjustment of the proportion coefficient of various test conditions is an important part of the revision of the two standards. It is necessary to further study and analyze the actual driving conditions in combination with the current geographical types, road traffic rules, road structure, etc. in China. This article takes operational trucks as an example, based on the data collection sources of the vehicle networking platform systems of major host factories, and analyzes the collected data using methods such as data cleaning, short travel screening, data protocol, and clustering, which can accurately reflect the actual road driving characteristics of operational vehicles. This provides technical solutions and strong data support for adjusting the fuel consumption coefficients of operating vehicles under various operating conditions.
Key Words: Operational Vehicles; Driving Conditions; Fuel Consumption; Dimensionality Reduction; Clustering
《營運貨車輛燃料消耗量限值及測量方法》(JT/T 719-2016)與《營運客車輛燃料消耗量限值及測量方法》(JT/T 711-2016)標準發布至今已有7年多的時間。作為《道路運輸車輛燃料消耗量檢測和監督管理辦法》(交通運輸部11號部令)的配套實施標準,是落實國家《節約能源法》的重要舉措,是引導運輸經營者購買和使用節能車輛的重要方式,是控制高能耗、高排放的車輛進入營運市場的重要手段。通過標準的實施,促進了道路運輸車輛燃料消耗量管理要求的有效落地,全國道路運輸車輛節能減排效果明顯,自2017年以來,至2021年累計節油量達到632.2萬噸,二氧化碳減排量達到2041.6萬噸。對引領行業技術發展與道路運輸行業節能減排工作發揮了重要作用,經濟效益和社會效益顯著。
當前,營運車輛燃料消耗量限值及測量方法系列標準,提出了適應我國道路運輸車輛行駛工況的道路試驗測試方法。隨著道路運輸車輛制造水平的不斷發展,道路運輸行業運力結構的不斷調整,以及道路等級等基礎設施的不斷建設。因此,營運車輛燃料消耗量測試評價技術一方面需要結合國內車輛技術發展與運輸行業需求現狀,另一方面相同測試方法下,試驗各類工況時間占比系數,需要結合我國的地理類型、道路交通規則、道路結構等運輸實際工況進一步研究分析。
本文針對道路運輸車輛行駛工況數據的量化分析問題,以營運貨車為例,依次對原始采集數據進行預處理和統計分析,提出道路試驗測試方法的各工況時間占比系數的修訂建議。同時,結合道路運輸車輛的實際交通情況,劃分短行程片段并篩選后構建有效的數據模型,基于PCA(Principal Component Analysis)主成分分析法的運動片段特征值降維模型和K均值(K-means)的聚類模型,將上述模型按照順序串聯分析,提出營運貨車行駛工況的現狀與分析思考,為營運車輛燃料消耗量限值及測量方法系列標準修訂和行業檢測評價技術提供有力的技術支撐。
1 數據采集及來源
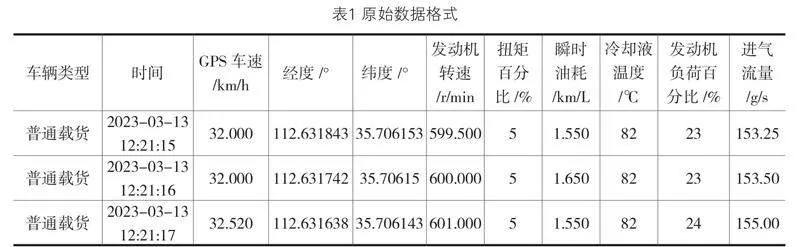
數據采集由各大主機廠車聯網平臺系統負責提供數據來源,從而充分保證了所需要采集數據的真實性和準確性。采集數據主要覆蓋了載貨汽車、牽引車輛、自卸和混凝土攪拌運輸車近一周時間內的實際行駛狀態和工況的數據采集,因各大主機廠車聯網平臺采集方式及用途差異,采集頻率和特征數據也有所不同,將每次采集后所獲得的數據都被單獨地保存到一個相應的文件夾中作為原始數據庫。原始數據庫中所需要獲得的主要數據形式如表1。
2 試驗數據預處理
與乘用車輛相比,營運貨車在實際行駛中面臨更多的變化和復雜的交通狀況。車輛在行駛時會受到多種因素的影響,這導致車輛的各種行駛參數也在不斷地變化。所收集到的數據主要涵蓋了速度、時間以及油耗等多個特性。在數據傳輸的過程中,可能會因為多種因素導致數據出現異常的情況。如果直接依賴這些數據進行分析,會導致結果出現偏差。因此,在進行統計分析前,有必要對這些數據進行數據清洗。
對數據進行清洗完成之后的數據變換、規約等一系列操作,統一被稱為數據的預處理階段。數據變換指的是將數據轉化為適合分析任務的適當格式,例如將速度-時間數據轉化為短行程參數特征;在進行數據規約的過程中,采用主成分分析法來進行數據規約,同時用更少的主成分數據來替代多維特征參數數據進行聚類分析。本文使用Python的Numpy、Scipy、Pandas等數據庫進行數據的挖掘和分析。其中,數據分析主要依賴于Pandas庫的數據分析函數,而數據規約和聚類分析則主要依賴于Scikit-Learn庫的數據分析函數,這確保了數據處理過程的高效性。
2.1 原始采集數據清洗
由于收集數據量較大,因為數據傳輸信號,解碼錯誤以及其他各種原因難免會出現異常情況,造成數據質量降低。如何有效地把這些非清潔數據轉化為高質量數據則需要對其進行清洗,通常有以下方式進行數據處理:通過刪除缺失部分的記錄從而繼續沿用連續部分記錄、對缺失數據進行預測插補和對數據不進行處理[1]。
在數據清洗前,抽取了部分原始數據,發現原始數據中存在部分數據狀態屬于只通信未采集,表現情況為車速與瞬時油耗量均為0的情況,利用代碼data.info()查看數據的缺失情況,各特征采集數據基本保證了數據的連續性,其缺失值占各樣本中的比例很小,故采用刪除缺失部分的記錄從而繼續沿用連續部分記錄不會造成數據質量下降,也大大提升了數據清洗的效率。使用pandas庫函數進行缺失數據刪除,代碼data.dropna(axis=0,how=“any”)。
2.2 原始采集數據轉換
2.2.1 行駛工況的劃分
車輛在啟動開始到目的地停止這一過程中,受道路交通條件制約,會出現多次加速、減速、怠速、等速等運行現象。根據汽車行駛方式劃分原則定義了加速工況,減速工況,怠速工況及勻速工況,并依據這些行駛參數進行了行程工況計算[2]。
(1)加速工況:加速度大于或等于正加速度閾值時(閾值一般取為0.15m/s2)且速度不等于0的連續過程;
(2)減速工況:加速度小于等于負加速度的閾值時(閾值一般取為-0.15m/s2)且速度不等于0的連續過程;
(3)勻速工況:加速度的絕對值小于加速度閾值時(閾值一般取為0.15m/s2)且速度不等于0的連續過程;
(4)怠速工況:發動機工作,但車速為0的連續過程。
根據上述行駛工況的分類標準,本文對數據集采用pandas庫中的DataFrame數據結構,以加速度、速度、發動機轉速等主要特征參數,作為工況判定條件來劃分行駛工況。
2.2.2 特征參數選取與計算
特征參數的選取可以真實地反映出每段行程的行駛特征,其中最為重要的是加速度、速度和發動機輸出功率參數,然而僅依靠這些是不足以描述行駛特征的。通過參數的轉換,能夠反映出原始數據中的各種交通信息,包含道路的交通狀況和司機的駕駛習慣等隱藏信息,使最終構建的工況更符合汽車實際運行情況[3]。
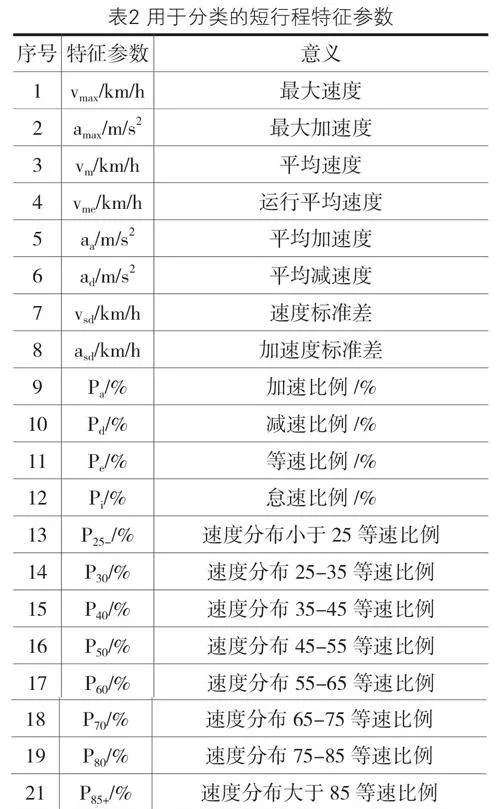
由此,在評價代表性行駛工況時,通常使用一些特征參數來評估該工況,選取了20個最為典型的特征參數用以較為全面地描述和表征所有短片段,并將采集到的數據通過一定的公式轉化為特征參數,以同樣的方法用于短行程的評估分析中,使用不同的特征參數代表短行程,這些特征參數能夠體現該短行程的交通特征。具體參數如表2:
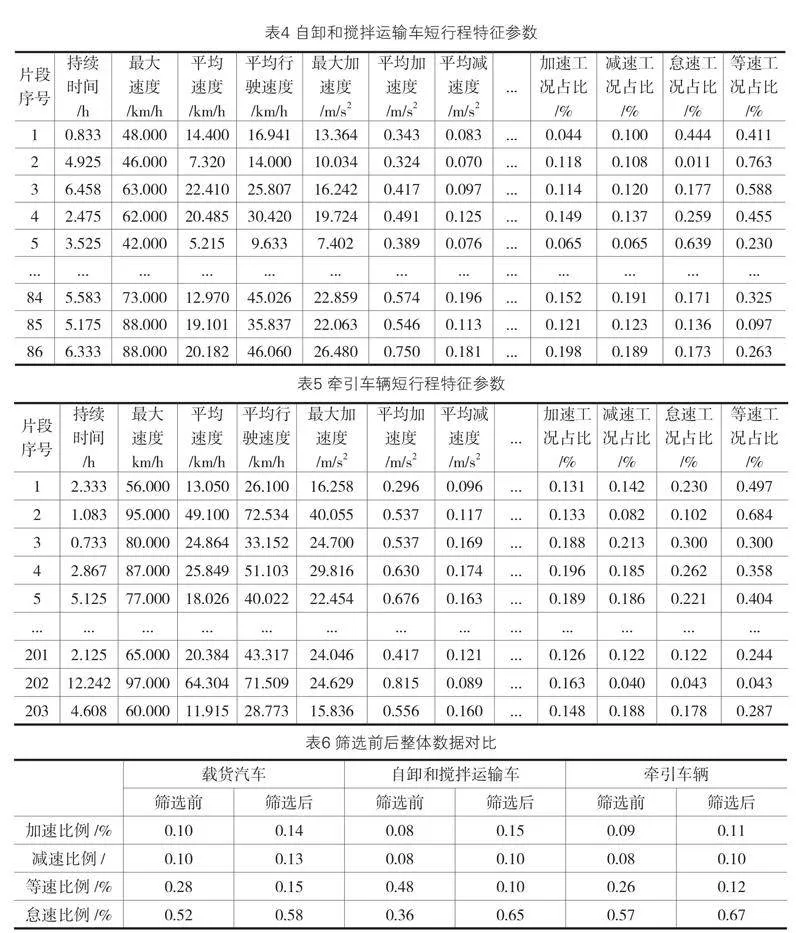
通過python編程將每個片段的多維特征參數進行計算,得到特征參數矩陣。其部分分析結果見下表3、4、5分別為載貨汽車、自卸和攪拌運輸車、牽引車輛所計算得出的值。
2.2.3 短行程片段數據篩選
從獲得的運動特征值矩陣可以看出,收集到的數據存在著一些速度突變造成加速度過大,怠速時間過長的短行程沒有表現交通特征等問題,這種做法明顯不盡合理,體現出篩選運動學片段的必要性。為確保用于工況構建的短行程的有效性和合理性,以國家法規為基礎,結合我國車輛的實際運輸特征,并參考WLTP(Worldwide Harmonized Light Vehicle Test Procedure)的相關短行程篩選原則制定5條篩選規則[4]:
(1)加速度絕對值大于4m/s2;
(2)短行程片段怠速時間超過10min,截取有效平均時長60s計算;
(3)自卸車和混凝土攪拌運輸車怠速工況中,發動機轉速>800r/min為作業工況,視為無效片段;
(4)最高時速低于3.6km/h的短行程片段;
(5)短行程片段持續時間低于10s。
基于上述篩選規則,提取的運動學片段總數量相較于篩選前基本保持不變,但各類工況占比系數發生變化,如表6。可看出篩選后整體怠速比例明顯下降,刪除了很多怠速時間過長和作業工況的無效片段,也導致了加速、減速、等速工況占比有所上升。根據以上操作,更能夠充分反映營運貨車實際工況特征,為營運貨車燃料消耗量各工況系數調整提供了技術方案與有力的數據支撐。
3 主成分分析法數據降維
經過數據清洗、計算特征參數和短行程篩選后,為了對車輛行駛工況進行統計分類與數據挖掘,還需對短行程進行聚類分類。但當數據量過大會出現計算效率低,亦或變量間有一定相關性提供信息有一定重疊等問題都不宜直接聚類。降維是應對高維數據的有效辦法,通過特征選擇法或維度轉換法將高維空間降低到或映射到低維空間[5]。
本文使用主成分分析PCA降維法以減少變量的數目,PCA是基于降維思想下產生的處理高維數據的方法[6]。將20維的數據降維至4維。
3.1 主成分分析實現
Stepl:計算協方差矩陣。主成分的計算可采用協方差矩陣或相關系數矩陣。Scikit-Learn中的PCA默認使用協方差矩陣Cp×p,協方差矩陣元素Cij為Xi和Xj的協方差;
主成分的計算可采用協方差矩陣或相關系數矩陣。
Step2:計算特征值和特征向量。所得的特征值按由大到小排列:λ1≥λ2≥...≥λp≥0。每個特征向量ξi為單位向量;
Step3:計算主成分貢獻率及累計貢獻率。主成分Yi值的大小體現了該成分對原有信息的貢獻率,其值越大,越具有代表性。貢獻率是指該主成分的方差占全部p個主成分方差中的比例。計算方法:
其中,ξij表示ξi的第j個變量。
3.2 主成分編碼實現
使用Python的Scikit-Learn庫中的主成分分析(PCA)相關函數進行數據模型編碼。PCA編碼:
from sklearn import preprocessing
df = pd.read_excel(r”./車輛匯總表.xlsx”)
Df = preprocessing.scale(df) # 數據標準化處理
covX = np.around(np.corrcoef(df.T),decimal=3)
# 求解協方差矩陣,保留3為小數
featValue, featVec = np.linalg.eig(covX, T)
featValue = sorted(featValue)[::-1]
# 求解系數相關矩陣特征值和特征向量,特征值由高到低排序
gx = featValue/np.sum(featValue)
Lg = np.cumsum(gx)
# 求解特征值貢獻率及累計貢獻率
k = [i for i in range(len(lg)) if lg[i]≤0.80]
# 選出累計貢獻率小于0.8的主成分
selectVec = np.matrix(featValue.T[k]).T
selectVec = selectVec*(-1)
# 構建主成分載荷矩陣
3.3 主成分分析結果分析
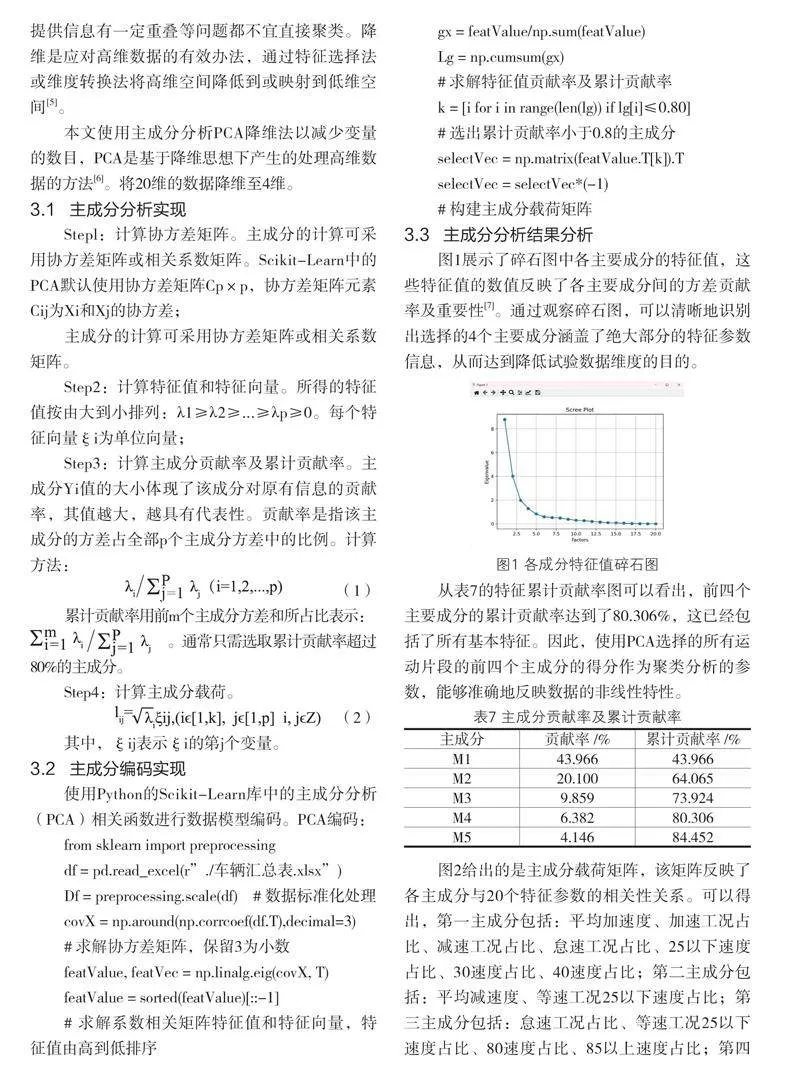
圖1展示了碎石圖中各主要成分的特征值,這些特征值的數值反映了各主要成分間的方差貢獻率及重要性[7]。通過觀察碎石圖,可以清晰地識別出選擇的4個主要成分涵蓋了絕大部分的特征參數信息,從而達到降低試驗數據維度的目的。
從表7的特征累計貢獻率圖可以看出,前四個主要成分的累計貢獻率達到了80.306%,這已經包括了所有基本特征。因此,使用PCA選擇的所有運動片段的前四個主成分的得分作為聚類分析的參數,能夠準確地反映數據的非線性特性。
圖2給出的是主成分載荷矩陣,該矩陣反映了各主成分與20個特征參數的相關性關系。可以得出,第一主成分包括:平均加速度、加速工況占比、減速工況占比、怠速工況占比、25以下速度占比、30速度占比、40速度占比;第二主成分包括:平均減速度、等速工況25以下速度占比;第三主成分包括:怠速工況占比、等速工況25以下速度占比、80速度占比、85以上速度占比;第四主成分包括:60速度占比、70速度占比。
4 聚類分析
為了進一步研究我國營運貨車實際行駛的路況與交通特征,需要對不同的短行程按照道路交通特征分類,將擁有相同交通特征的短行程分為一類。由于短行程沒有明確的類別標簽,因此采用聚類方法對其進行分類。聚類分析就是用一定方法將具有不同特征和特性的樣本劃分為若干個類,并在每個類內部找出最相近的同類作為該組的代表[8]。
在數據分析領域,聚類被廣泛認為是一種關鍵的分類技術,它允許在沒有明確分類的前提下,基于數據的相似度來對樣本進行分類[9]。鑒于每一個短行程的具體類別都是未知的,因此選擇使用聚類技術來對其進行分類。為了實現數據的快速和高效聚類,本研究采用了Scikit-Learn庫中專為大量數據設計的K-Means聚類算法來處理短行程數據。
4.1 K-Means算法實現
Step1:隨機選取k個初始中心點;
Step2:計算每個點到中心點的距離,將點分到距離最近的中心點所在的簇中;
Step3:計算每個簇的平均值作為新的中心點;
Step4:重復過程Step2和Step3,直至中心點不再變化。
KMeans算法在sklearn.cluster包里有現成的函數,只需調用即可。函數及其參數如下:
主要參數選取:
n_clusters=3:聚類數目;
init=’K-Means++’:初始化方法{‘K- Means++’};
max_iter=300:最大迭代次數;
n_init=10:初始質心運行算法的次數;
algorithm=’auto’:根據數據值稀疏或稠密,自動選擇’full’或’elkan’。
4.2 K-Means算法結果分析
在聚類分析中,各類運動片段的數量如表8所示,聚類中心如表9所示,主要成分的特征值如表10所示。
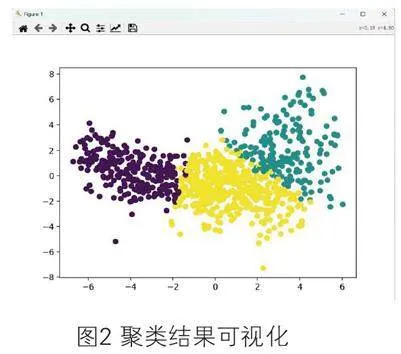
根據圖2中聚類結果的可視化分析,可以將882個運動學片段分為三個不同的類別:第一類(由紫色點表示)包含243個片段,第二類(由綠色點表示)包含184個片段,而第三類(由黃色點表示)則包含455個片段。利用聚類中心表9和表10中的主要成分所對應的特征值,對三種聚類后的動態片段進行了綜合描述:
第一類運動片段的第一、第二類主成分指標值偏低,第三、第四類成分指標值較高。可以觀察到,第一類的運動片段主要描述的是汽車在高速公路上的行駛狀態;此外,怠速時間占比以及部分低速占比稍高,這也與途徑收費站點排隊等待與低速行駛的現狀特征相匹配。可以確定出,第一類的運動片段描述的是在高速公路上的高速駕駛狀態。
第二類運動片段的一、二主成分指標最為突出。通過分析這些指標與運動特性,可以推斷這一類的運動片段反映了汽車在城市交通擁堵區域的緩慢行駛狀態,也可能是出現在節假日或者早晚高峰時間。
第三類運動片段的第一、二、三類主成分指標值較低,第四類主成分指標值為三類中最高。結合這些指標數據和運動特征,可以判斷第三類運動片段描述組要是在城郊路段,或者是在交通較為通暢的城區的行駛工況的中速行駛工況。
綜上分析可知,當前我國營運貨車多行駛于城郊和高速路段,市內交通擁堵路段占比較小,這也與我國營運貨車實際行駛情況及車輛管理要求相匹配。下一步,結合營運貨車行駛數據統計與聚類分析研究,為主管部門對營運車輛技術管理要求以及《營運車輛燃料消耗量限值及測量方法》實際工況系數調整等工作,提供了技術方案與有力的數據支撐。
5 總結
行駛工況的構建分析能夠有效評估營運車輛的燃油消耗量,從而促進營運車輛節能減排技術的發展。本文以課題“《營運車輛燃料消耗量限值及測量方法》(JTT 711-2016、JTT 719-2016)系列標準跟蹤”項目為依托,根據營運貨車分類和使用用途,對各大主機廠車聯網平臺系統中采集到的數據,分別對原始數據進行了數據清洗、數據轉換、數據篩選,根據統計學原理,并對特征參數數據降維和聚類劃分,為營運貨車燃料消耗量各工況系數調整提供了技術方案與有力的數據支撐。
參考文獻:
[1]張良均,王路,譚立云等.Python數據分析與挖掘實戰[M].北京:機械工業出版社,2016.
[2]劉明哲.基于運動學片段和分層聚類的汽車行駛工況構建[J].內蒙古農業大學學報(自然科學版), 2021,42(02): 73-78.
[3]李加強,王洪榮,周建文,等.基于聚類分析法的公交車行駛工況構建研究[J].汽車工程學報,2017,7(06):400-406.
[4]Marotta A, Pavlovic J, Ciuffo B, et al. Gaseous Emissions from Light-Duty Vehicles: Moving from NEDC to the New WLTP Test Procedure[J].Environmental Science & Technology, 2015, 49(14):8315-22.
[5]宋天龍.Python 數據分析與數據化運營[M].北京:機械工業出版社,2017.
[6]Lim S. Nonlinear component analysis as a kernel eigenvalue problem[J]. 2011.
[7]范金城,梅長林.數據分析(第二版)[M].北京:科學出版社,2010.
[8]孫駿,方濤,張炳力,李傲伽,朱鶴.基于改進K-均值聚類算法的合肥市電動客車行駛工況構建[J].汽車技術,2020(08):56-62.
[9]高建平,任德軒,郗建國.基于全局K·means聚類算法的汽車行駛工況構建[J].河南理工大學學報(自然科學版),2019,38(1):112-118.
杜宇程
現就職于交通運輸部公路科學研究院,任助理研究員,主要從事道路運輸車輛技術與管理工作,已發表文章數篇。
專家推薦語
汪祖國
國家汽車質量檢驗檢測中心(襄陽)
整車試驗副總工程師 研究員級高級工程師
文章依托 “《營運車輛燃料消耗量限值及測量方法》系列標準跟蹤”項目,結合道路運輸車輛的實際交通情況,收集了各大主機廠車聯網平臺系統中的數據,以營運貨車為例,按不同車輛類型分別對原始數據進行了數據清洗、轉換和篩選,并根據統計學原理進行特征參數數據降維和聚類劃分,提出了道路試驗方法的各工況時間占比系數的修訂建議。相關研究對于營運車輛燃料消耗量限值及測量方法系列標準的修訂提供了較為重要的理論及數據支撐,對推動運輸行業節能減排戰略也具有一定的現實意義。
