基于被動視覺的三維重建技術研究進展
2024-08-13 00:00:00王兆慶牛朝一佘維宰光軍梁波易建鋒李英豪
鄭州大學學報(理學版) 2024年5期




摘要: 基于被動視覺的三維重建技術方法多樣、應用廣泛。按照不同的分類方法,對基于被動視覺的三維重建技術研究進展進行了分析總結。首先,根據采集裝置的數量進行分類,介紹了基于單目視覺、雙目視覺和多目視覺的三維重建技術,并對各種方法的優缺點進行比較。其次,根據不同應用方法進行分類,對運動恢復結構法和深度學習法的研究進展進行了闡述。最后,對基于被動視覺的三維重建方法進行了綜合對比分析,并對三維重建的應用和發展進行了展望。
關鍵詞: 三維重建; 被動視覺; 單目視覺; 雙目視覺; 多目視覺; 運動恢復結構; 深度學習
中圖分類號: TP391
文獻標志碼: A
文章編號: 1671-6841(2024)05-0013-07
DOI: 10.13705/j.issn.1671-6841.2023012
Progress of Study on 3D Reconstruction Technology Based on Passive Vision
WANG Zhaoqing1,2, NIU Chaoyi1,3, SHE Wei1,3, ZAI Guangjun1,3,
LIANG Bo4, YI Jianfeng4, LI Yinghao1,3
(1.School of Cyber Science and Engineering, Zhengzhou University, Zhengzhou 450002, China;
2.XJ Electric Co.,Ltd, Xuchang 461000, China; 3.Zhengzhou Key Laboratory of Blockchain and Data
Intelligence, Zhengzhou 450002, China; 4.Information Management Center, Zhongyuan Oilfield
Branch of SINOPEC, Puyang 457001, China)
Abstract: The methods of 3D reconstruction technology based on passive vision are diverse and widely used. Most of studies of 3D reconstruction technology based on passive vision were analyzed and summarized based on different classification methods. Firstly, according to the different number of acquisition devices, the 3D reconstruction techniques were classified into monocular vision, binocular vision and multi-version, and the advantages and disadvantages of each method were compared. Secondly, the research progress of structure from motion and deep learning method were described according to the classification of different application methods. Finally, the 3D reconstruction technology based on passive vision were compared and analyzed comprehensively, and the application and development of 3D reconstruction were explored.
Key words: 3D reconstruction; passive vision; monocular vision; binocular vision; multi-vision; structure from motion; deep learning
0 引言
三維重建是計算機視覺領域中非常重要的研究方向之一,其中基于視覺的三維重建是該領域的研究熱點。基于視覺的三維重建通過各種儀器或者相機設備,對真實的場景和目標物體進行掃描或拍攝,然后采用計算機算法加以處理,對物體的三維空間信息進行深入的解析,最終逆向求取空間點坐標,得到三維立體表面模型。經過四五十年的研究與發展,基于視覺的三維重建日益成熟,新技術層出不窮,逐漸應用于工業、醫療、交通、軍事等諸多領域,在工業檢測、醫學影像、無人駕駛、軍事探測等方面發揮著重大作用。
基于視覺的三維重建由于其適用領域和應用場景的不同,形成了不同的技術路線。隨著研究的不斷深入,基于視覺的三維重建技術通常可劃分為基于主動視覺的三維重建和基于被動視覺的三維重建。其中,主動視覺方法主要利用相關儀器掃描目標物體,通過調整自身參數發射激光、聲波、脈沖等信號,然后分析發出和接收結構聲光信號的時間差等數據,確定目標物體的距離、大小、形狀等三維結構的細節信息,最后精確地還原物體或場景的三維模型。而被動視覺自身并不會發射任何能量信號來收集目標信息,而是完全依靠自然光源下目標物體或場景對光照的漫反射效應,通過收集圖像的二維深度信息來完成檢測。相比之下,主動視覺方法在實際操作上存在較高的難度,可行性較低,難以很好地適應復雜環境,局限性比較大。而基于被動視覺的三維重建技術可操作性強,成本較低,適用于各種復雜環境中目標物體的三維重建,在實際應用中更為廣泛。因此,本文對基于被動視覺的三維重建技術研究進展進行了整理和分析。基于被動視覺的三維重建技術根據采集裝置的數量進行分類,可分為單目視覺法、雙目視覺法和多目視覺法;根據不同應用方法進行分類,可分為運動恢復結構法和深度學習法。
1 根據采集裝置數量分類
根據獲取二維圖像數據所采用的采集裝置數量,基于被動視覺的三維重建技術可以分為單目視覺法、雙目視覺法和多目視覺法。
1.1 單目視覺法
單目視覺法只采用一臺攝像機進行數據采集,采集的數據可以為單幅圖像或者多幅圖像。單目視覺法三維重建流程如圖1所示。
單目視覺法首先采用單目相機等裝置采集圖像數據,然后獲取圖像特征信息,通過算法進行特征信息匹配,最后選取合適的重建方法得到三維重建模型。從單目相機拍攝二維圖像中的某一點到三維立體模型空間點的轉換原理可表示為
其中:(u,v)表示在圖像坐標系下圖像點的坐標;(Xw,Yw,Zw)表示空間中物體的三維坐標;R和t分別表示旋轉矩陣和平移向量;(u0,v0)為攝像頭的中心點在二維圖像中的坐標;fx和fy分別為攝像機在x和y方向上的焦距。通過式(1)可以求出空間中任意一點的三維坐標。
單目視覺三維重建技術包括以下5種方法。
1) 明暗度法。明暗度法即明暗度恢復形狀法。該方法主要對圖像中由光源照射所產生的明暗陰影變化進行分析,借助反射光照模型計算物體表面的梯度場,由梯度場進行積分運算,最后得到物體表面高度值。Horn[1]于1970年第一次提出明暗度法的概念,推導出了明暗度方程。Ahmed等[2]利用Lax-Friedrichs sweeping算法對混合表面采用明暗度法進行求解,并建立了Ward模型下混合表面圖像輻照度方程。Vogel等[3]提出了基于非朗伯特模型的明暗度法,取得了良好的效果。為提高求解效率、降低重建誤差,王國琿等[4]改進了Ward模型,建立了透視投影下的輻照度方程,提出了基于牛頓-拉弗森法的混合表面快速三維重建求解算法。
2) 光度立體視覺法。光度立體視覺法是利用目標物體在各種光線環境下拍攝得到的圖像數據,重建該物體表面的立體結構。Woodham[5]對明暗度法進行改進,提出了光度立體視覺法,改善了單幅圖像中所包含的重建信息較少的問題。2010年,Shi等[6]提出了自標定的光度立體視覺法。2018年,Santo等[7]提出了深度光度立體網絡,通過使用深度神經網絡在復雜的反射率觀測值和表面法線之間建立靈活的映射,使得重建效果更加顯著。2020年,陳明漢等[8]提出了一種基于多尺度卷積網絡架構的光度立體視覺算法,極大提高了對非朗伯表面的適應性。
3) 紋理法。紋理法的基本理論為:物體表面均具備不同的紋理信息,這些信息由紋理元組成,當物體被投射在圖像上,根據紋理元可以確定表面方向,通過計算能夠獲取深度數據,恢復立體結構。Clerc等[9]于2002年使用小波變換進行改進,完成了紋理分析。2010年,Warren等[10]對正交投影解不唯一的問題進行了調整,采用透視投影模型進行紋理法重建實驗,使重建效果得到了提升。
4) 輪廓法。輪廓法即輪廓恢復形狀法。該方法通過對物體進行多角度拍攝,然后提取圖像中目標物體的輪廓數據,逆向推導出物體的三維結構。主流輪廓法是融合了體素、視殼和錐素的重建方法。2006年,Forbes等[11]實現了直接從物體的輪廓及其反射計算焦距、主點、鏡子和相機姿勢,從未標定的圖像中生成視殼。2020年,Jang等[12]通過重復計算視殼的殘差來處理凹面區域,并生成分層數據結構即可視外殼樹,解決了凹面區域的細節展示。
5) 焦距法。焦距法即焦點恢復形狀法,于1997年由Rajagopalan等[13]首次提出。焦距法需要精確計算聚焦量以及判斷噪聲對清晰度的影響。考慮焦距變化所產生的視差,Sahay等[14]對焦距法進行了改進。康宇等[15]針對焦距法內存空間占用量大的問題,提出一種基于擴散的聚焦形貌恢復算法,通過對聚焦評價曲線區間進行約束,降低了內存使用率。趙洪盛等[16]提出一種圖像噪聲檢測算法,通過濾波構建無噪聲圖像序列,進一步提升了焦距法的精確度。
表1對比了上述5種單目視覺三維重建技術,羅列了各種方法的優缺點以及重建效果,同時對具體應用場景進行了簡要說明。可以看出,單目視覺法通過單張或較少數量的圖像即可完成目標物體的重建,重建速度快、效率高,但對于光照等因素的依賴較為嚴重;同時,重建效果存在表面殘缺、空洞等現象,依然有很大的改善空間。
1.2 雙目視覺法
雙目視覺法,也被稱為立體視覺法,能夠將雙目視差信息轉換為物體深度信息。該方法主要采用雙目攝像機獲取雙視圖圖像,然后利用立體匹配計算原理獲得視差圖,最后利用三角測量的方法對匹配點的視差信息進行轉換,得到物體表面的三維坐標,恢復三維立體模型結構。
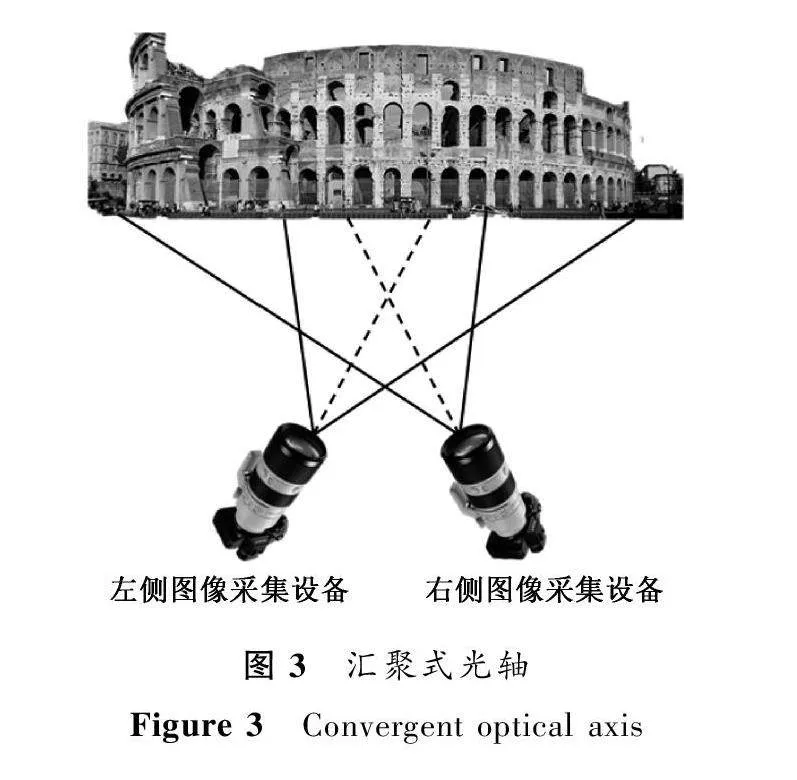
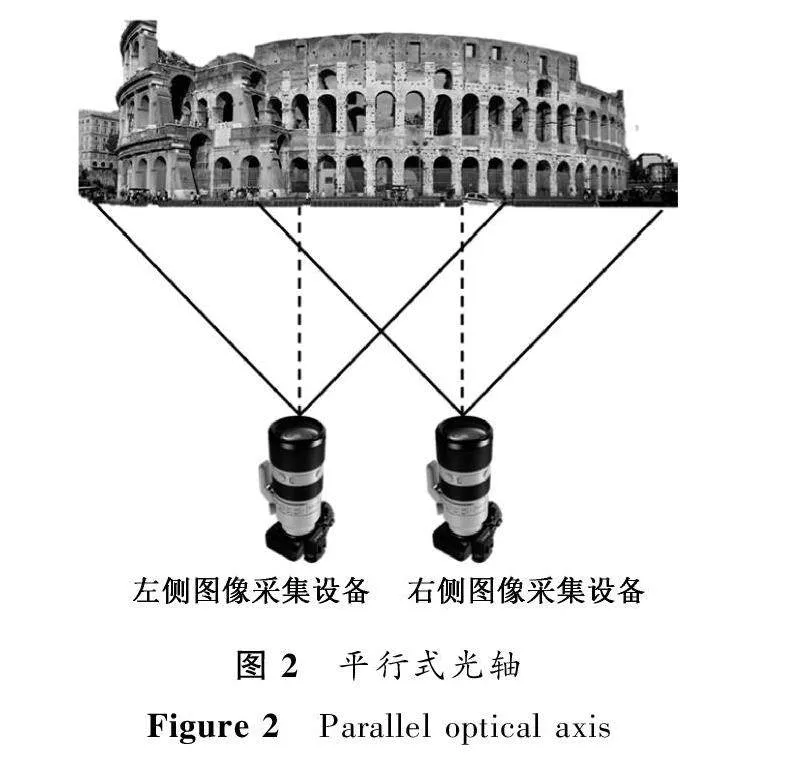
根據攝像機擺放位置的不同,雙目視覺三維重建可以分為平行式光軸三維重建方法[17]和匯聚式光軸三維重建方法[18]。平行式光軸和匯聚式光軸分別如圖2、圖3所示。
平行式光軸和匯聚式光軸三維重建方法的具體情況如下。
1) 平行式光軸三維重建方法。該方法的設備面向目標結構平行放置,保證光軸也與水平方向平行,能夠形成平行的成像平面。兩臺攝像機只存在光軸位置的左右差異,能很好地實現圖像的立體匹配。
2) 匯聚式光軸三維重建方法。匯聚式光軸雙目視覺三維重建方法在平行式光軸雙目視覺系統的基礎上,左右兩臺攝像機分別繞光心旋轉,使兩者向內呈八字。該方法的優勢是能夠擴大圖像采集設備的視野角度。
Hirschmuller[19]首次提出了半全局匹配算法,成為當下最流行的立體視覺算法之一。Michael等[20]提出了對該算法參數化的直接擴展,提升了半全局匹配算法的準確性。隨著神經網絡和深度學習的普及和發展,Bontar等[21]將卷積神經網絡與立體匹配算法相結合,提出一種從校正后圖像對中提取深度信息的方法,通過訓練卷積神經網絡來預測兩個圖像塊的匹配程度。Lu等[22]提出一種級聯多尺度和多維網絡的架構,將傳統方法的代價聚合考慮在內,取得了良好的效果。雙目視覺方法整體上已經比較成熟,廣泛應用于現代化人工智能領域,如電纜巡檢機器人[23]等自動化無人設備。
1.3 多目視覺法
多目視覺法是對雙目視覺進行擴展所形成的方法,采用3個或3個以上的攝像機獲取圖像,其研究難點在于視差圖信息匹配。2003年,雷成等[24]研發了CVSuit三維重建系統。之后,翟振剛[25]對立體匹配算法進行研究,提出一種自適應區域立體匹配算法。Zhang等[26]將基于多視覺的三維重建分為3個階段,提出了中心線匹配配準算法來實現對管道的重構。Bai等[27]將多目視覺法運用于無人機地質災害檢測,獲得精準的三維地形模型。陳星等[28]結合神經網絡和特征金字塔結構,對多尺度融合立體匹配算法進行改進,可以得到效果良好的視差圖。
2 根據不同應用方法分類
基于被動視覺的三維重建在不同領域所運用的重建方法有所差異,其達到的重建效果也各有不同,從而體現出相應的優缺點。根據其應用方法進行分類,可以分為運動恢復結構法和深度學習法。
2.1 運動恢復結構法
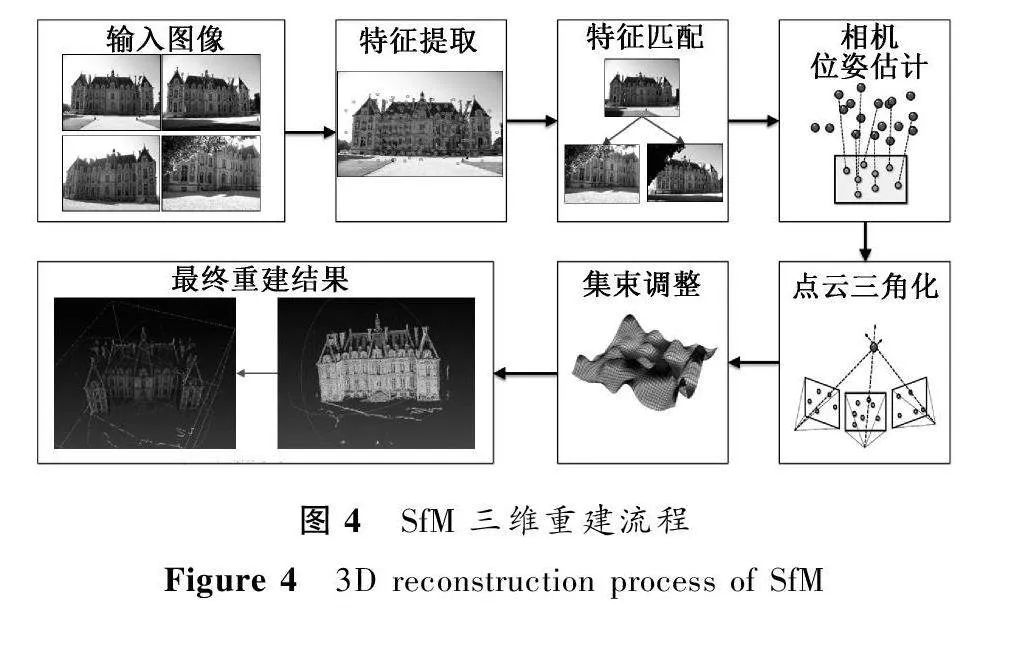
運動恢復結構法(structure from motion,SfM)是通過分析多視角二維圖像信息,求解三維立體模型數據的方法。由于涉及拍攝過程中相機多角度的移動,因此被稱為運動恢復結構。SfM三維重建流程如圖4所示。
目前主流的SfM方法可分為增量式[29]和全局式兩大類型。
增量式SfM的原理是通過攝像機獲取多角度圖像,選取兩張圖像初始化,然后不斷加入新的圖像進行迭代,對于初始化的圖像以及不斷添加的圖像一邊進行三角化生成三維點,一邊進行局部優化,最終實現整個圖像的三維重建過程。
全局式SfM是由Sturm等[30]率先提出的,其原理是一次性地對所有的圖像計算匹配關系生成三維點,最后進行整體優化。2011年,Crandall等[31]提出一種基于離散馬爾可夫隨機場的混合離散連續優化的全局式SfM。2015年,Cui等[32]在已有理論的基礎上提出一種全新的全局式SfM,使其處理數據更加多樣化。
2.2 深度學習法
深度學習法三維重建的過程可以理解為對函數的擬合,通過神經網絡訓練將圖像的像素信息轉化為因變量物體的深度信息,從二維圖像中恢復物體的三維結構。Sermanet等[33]提出了使用卷積網絡對圖像進行分類、定位和檢測的框架,實現了在ConvNet中多尺度和滑動窗口的方法。隨后,Eigen等[34]使用兩個深度網絡堆棧的方法預測場景三維信息,其中一個深度網絡對圖像進行全局預測,另一個對預測信息進行局部細化。張冀等[35]提出一種基于多尺度CNN-RNN的單圖三維重建網絡,通過高斯金字塔模型構建多尺度網絡,使得二維圖像的特征提取更加充分,提高了重建精度。
3 對比與分析
基于被動視覺的三維重建技術的對比結果如表2所示。
基于單目視覺的重建方法較為多樣,但各有其局限性,易受光照條件、噪聲、紋理特征等因素的影響;基于雙目視覺和多目視覺的重建方法,其穩定性比單目視覺法要高,技術相對成熟,能夠實現較高的重建精度,但在復雜場景及惡劣環境下,設備更為昂貴且操作復雜,普適性較差。運動恢復結構法可以結合單目視覺法,通過使用多張圖像達到更好的重建效果,但圖像數量增加也會增大計算量,降低三維重建的效率。深度學習法作為新興的三維重建技術,與傳統的方法有所區別,其通過神經網絡訓練可以重建出較為精確的三維模型,但重建的質量依賴于訓練過程,需要不斷地調整網絡框架,同時對數據集較為敏感。
4 小結與展望
本文根據采集裝置數量和應用方法的不同,對主流的基于被動視覺的三維重建技術進行了梳理、分類和對比分析。三維重建技術目前主要存在以下問題:
1) 運算量問題。為提高重建精度增加了圖像數量,導致計算量過于龐大,重建時間長,對于硬件資源的需求過高。
2) 魯棒性問題。部分三維重建技術的抗干擾能力差,易受外界各種自然因素的影響。
3) 重建效率問題。部分重建過程耗時較長,降低了整體的重建效率。
隨著研究的深入,上述問題的解決并不局限于原有方法的直接優化或提升,可通過各類新方法、新技術的融合進行解決。綜上,基于被動視覺的三維重建技術方興未艾,有必要基于目前的眾多方法進行組合、優化與創新。隨著各類新方法的加入,三維重建技術必定能更好地服務于人類社會的生產和生活。
參考文獻:
[1] HORN B K. Shape from shading: a method for obtaining the shape of a smooth opaque object from one view[D]. Cambridge:Massachusetts Institute of Technology,1970.
[2] AHMED A H, FARAG A A. Shape from shading under various imaging conditions[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press,2007: 1-8.
[3] VOGEL O, BREU M, WEICKERT J. Perspective shape from shading with non-lambertian reflectance[C]∥Joint Pattern Recognition Symposium. Berlin: Springer Press, 2008: 517-526.
[4] 王國琿, 張璇. 透視投影下混合表面3D重建的快速SFS算法[J]. 光學學報, 2021, 41(12): 179-187.
WANG G H, ZHANG X. Fast shape-from-shading algorithm for 3D reconstruction of hybrid surfaces under perspective projection[J]. Acta optica sinica, 2021, 41(12): 179-187.
[5] WOODHAM R J. Photometric method for determining surface orientation from multiple images[J]. Optical engineering, 1980, 19(1): 139-144.
[6] SHI B X, MATSUSHITA Y, WEI Y C, et al. Self-calibrating photometric stereo[C]∥Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press,2010: 1118-1125.
[7] SANTO H, SAMEJIMA M, SUGANO Y, et al. Deep photometric stereo network[C]∥Proceedings of the IEEE International Conference on Computer Vision Workshops. Piscataway:IEEE Press,2018: 501-509.
[8] 陳明漢, 任明俊, 肖高博, 等. 基于多尺度卷積網絡的非朗伯光度立體視覺方法[J]. 中國科學: 技術科學, 2020, 50(3): 323-334.
CHEN M H, REN M J, XIAO G B, et al. Non-Lambertian photometric stereo vision algorithm based on a multi-scale convolution deep learning architecture[J]. Scientia sinica: technologica, 2020, 50(3): 323-334.
[9] CLERC M, MALLAT S. The texture gradient equation for recovering shape from texture[J]. IEEE transactions on pattern analysis and machine intelligence, 2002, 24(4): 536-549.
[10]WARREN P A, MAMASSIAN P. Recovery of surface pose from texture orientation statistics under perspective projection[J]. Biological cybernetics, 2010, 103(3): 199-212.
[11]FORBES K, NICOLLS F, JAGER G, et al. Shape-from-Silhouette with two mirrors and an uncalibrated camera[C]∥Proceedings of the 9th European Conference on Computer Vision. New York: ACM Press, 2006: 165-178.
[12]JANG T Y, KIM S D, HWANG S S. Visual hull tree: a new progressive method to represent voxel data[J]. IEEE access, 2020, 8: 141850-141859.
[13]RAJAGOPALAN A N, CHAUDHURI S. A variational approach to recovering depth from defocused images[J]. IEEE transactions on pattern analysis and machine intelligence, 1997, 19(10): 1158-1164.
[14]SAHAY R R, RAJAGOPALAN A N. Dealing with parallax in shape-from-focus[J]. IEEE transactions on image processing, 2011, 20(2): 558-569.
[15]康宇, 陳念年, 范勇, 等. 基于擴散的聚焦形貌恢復算法[J]. 計算機工程, 2016, 42(3): 259-265.
KANG Y, CHEN N N, FAN Y, et al. Shape from focus algorithm based on spreading[J]. Computer engineering, 2016, 42(3): 259-265.
[16]趙洪盛, 丁華, 劉建成. 基于圖像區域像素重構的聚焦形貌恢復[J]. 計算機工程, 2019, 45(2): 233-239, 244.
ZHAO H S, DING H, LIU J C. Shape from focus based on image regional pixel reconstruction[J]. Computer engineering, 2019, 45(2): 233-239, 244.
[17]ZOU X J, ZOU H X, LU J. Virtual manipulator-based binocular stereo vision positioning system and errors modelling[J]. Machine vision and applications, 2012, 23(1): 43-63.
[18]李占賢, 許哲. 雙目視覺的成像模型分析[J]. 機械工程與自動化, 2014(4): 191-192.
LI Z X, XU Z. Analysis of imaging model of binocular vision[J]. Mechanical engineering & automation, 2014(4): 191-192.
[19]HIRSCHMULLER H. Accurate and efficient stereo processing by semi-global matching and mutual information[C]∥Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2005: 807-814.
[20]MICHAEL M, SALMEN J, STALLKAMP J, et al. Real-time stereo vision: optimizing semi-global matching[C]∥Proceedings of the IEEE Intelligent Vehicles Symposium. Piscataway:IEEE Press, 2013: 1197-1202.
[21]BONTAR J, LECUN Y. Computing the stereo matching cost with a convolutional neural network[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Piscataway:IEEE Press, 2015: 1592-1599.
[22]LU H H, XU H, ZHANG L, et al. Cascaded multi-scale and multi-dimension convolutional neural network for stereo matching[C]∥Proceedings of the IEEE Visual Communications and Image Processing. Piscataway:IEEE Press, 2019: 1-4.
[23]HUANG L, WU G P, LIU J Y, et al. Obstacle distance measurement based on binocular vision for high-voltage transmission lines using a cable inspection robot[J]. Science progress, 2020, 103(3): 1-35.
[24]雷成, 胡占義, 吳福朝, 等. 一種新的基于Kruppa方程的攝像機自標定方法[J]. 計算機學報, 2003, 26(5): 587-597.
LEI C, HU Z Y, WU F C, et al. A novel camera self-calibration technique based on the Kruppa equations[J]. Chinese journal of computers, 2003, 26(5): 587-597.
[25]翟振剛. 立體匹配算法研究[D]. 北京: 北京理工大學, 2010.
ZHAI Z G. Research on stereo matching algorithm[D]. Beijing: Beijing Institute of Technology, 2010.
[26]ZHANG T, LIU J H, LIU S L, et al. A 3D reconstruction method for pipeline inspection based on multi-vision[J]. Measurement, 2017, 98: 35-48.
[27]BAI S H, BAI S Y. Application of unmanned aerial vehicle multi-vision image 3D modeling in geological disasters[J]. Journal of information and optimization sciences, 2017, 38(7): 1101-1115.
[28]陳星, 張文海, 侯宇, 等. 改進的基于多尺度融合的立體匹配算法[J]. 西北工業大學學報, 2021, 39(4): 876-882.
CHEN X, ZHANG W H, HOU Y, et al. Improved stereo matching algorithm based on multi-scale fusion[J]. Journal of northwestern polytechnical university, 2021, 39(4): 876-882.
[29]WU C C. Towards linear-time incremental structure from motion[C]∥Proceedings of the International Conference on 3D Vision. Piscataway:IEEE Press,2013: 127-134.
[30]STURM P, TRIGGS B. A factorization based algorithm for multi-image projective structure and motion[M]∥Lecture Notes in Computer Science. Berlin: Springer Press, 1996: 709-720.
[31]CRANDALL D, OWENS A, SNAVELY N, et al. Discrete-continuous optimization for large-scale structure from motion[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Piscataway:IEEE Press, 2011: 3001-3008.
[32]CUI H N, SHEN S H, GAO W, et al. Efficient large-scale structure from motion by fusing auxiliary imaging information[J]. IEEE transactions on image processing, 2015, 24(11): 3561-3573.
[33]SERMANET P, EIGEN D, ZHANG X, et al. Overfeat: integrated recognition, localization and detection using convolutional networks[EB/OL].(2014-02-24)[2022-09-12]. https:∥arxiv.org/pdf/1312.6229v4.pdf.
[34]EIGEN D, PUHRSCH C, FERGUS R. Depth map prediction from a single image using a multi-scale deep network[EB/OL]. (2014-06-09)[2022-09-12]. https:∥doi.org/10.48550/arXiv.1406.2283.
[35]張冀, 鄭傳哲. 基于多尺度CNN-RNN的單圖三維重建網絡[J]. 計算機應用研究, 2020, 37(11): 3487-3491.
ZHANG J, ZHENG C Z. 3D reconstruction network based on multi-scale CNN-RNN[J]. Application research of computers, 2020, 37(11): 3487-3491.
