基于知識圖譜的案件特征增強法律判決預測
2024-08-17 00:00:00李紫陽張亞娟黃義雄王云鶴
計算機應用研究 2024年7期
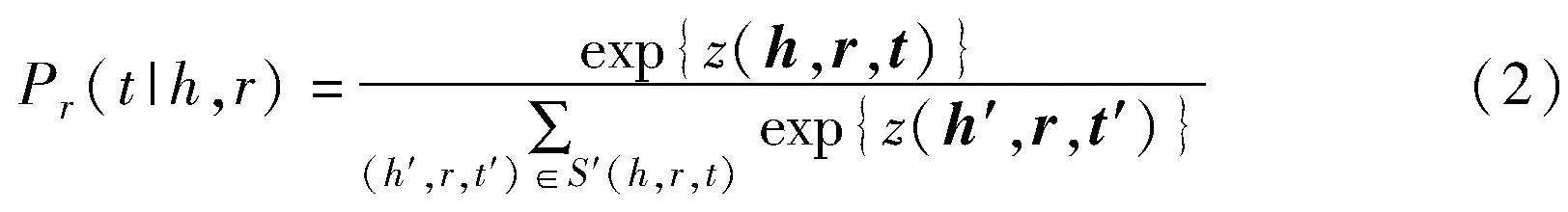
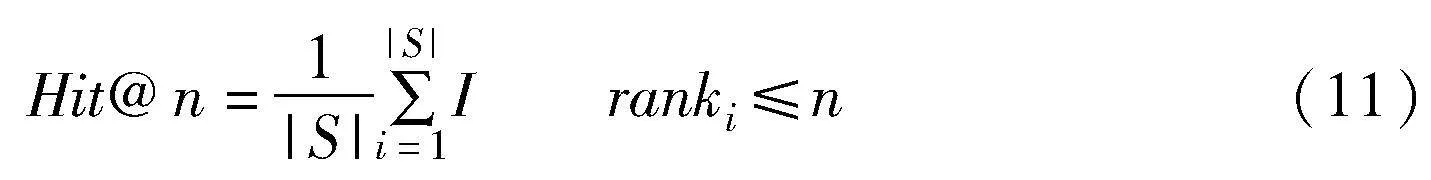
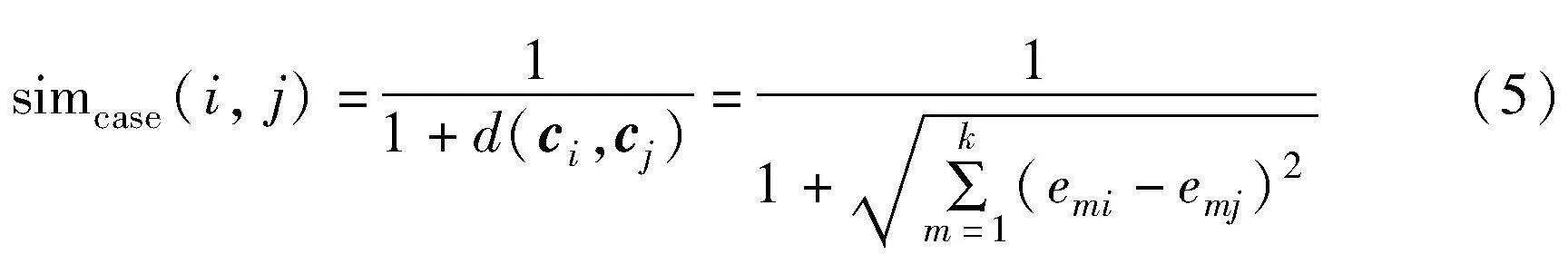

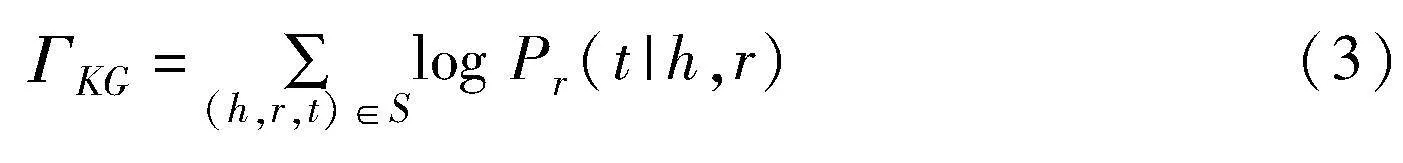






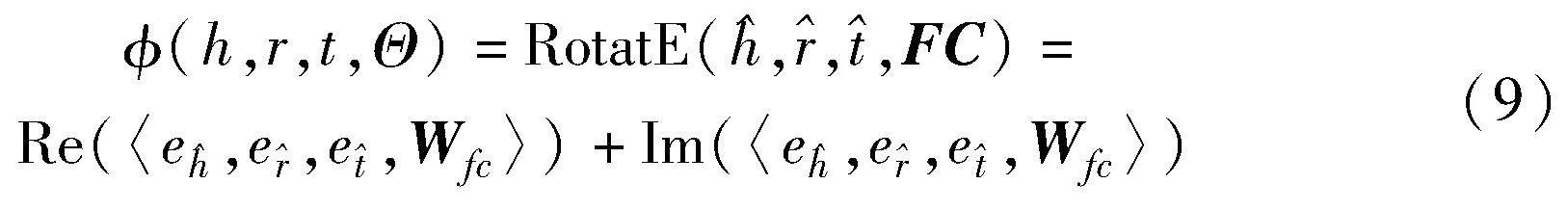

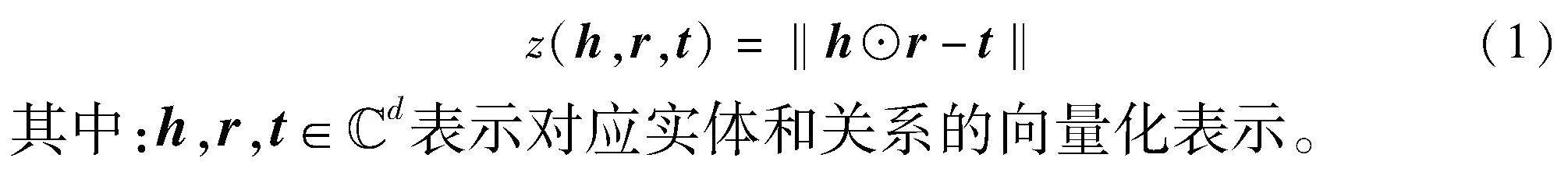
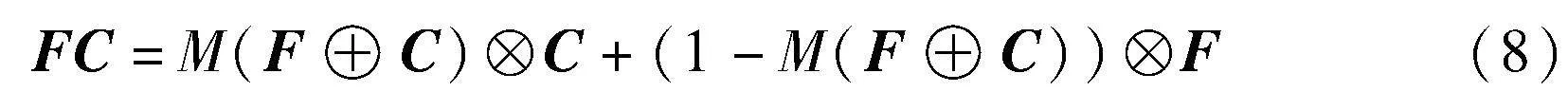
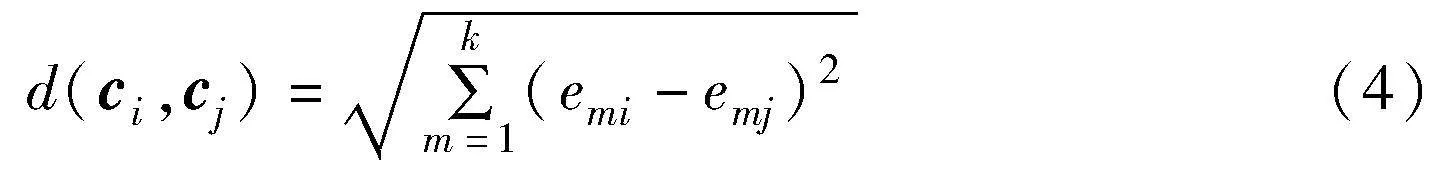
摘 要:現有基于知識圖譜的法律判決預測方法重點關注案件的要素實體和關系,不能充分地獲取案件的特征信息。針對該問題,提出了一種增強案件特征融合的知識圖譜法律判決預測方法。首先,該方法利用雙向門控循環神經網絡挖掘事實描述文本深層次的因果、時序等全文語義特征信息。然后通過知識圖譜向量空間中案例間相似度注意力計算學習類案特征表示。最后,融合特征信息和知識圖譜的結構化知識,豐富實體和關系在案件事實文本中的語義特征表示,實現法律判決鏈路預測任務。在危險駕駛罪和盜竊罪兩類罪名數據集上的實驗結果顯示,該方法在MRR、Hit@1兩個關鍵評價指標上與當前表現最好的鏈路預測模型相比提升了1.5%左右,Hit@3和Hit@10等指標也均有提升,驗證了案件特征增強融合能補充法律知識圖譜中缺失的案件特征信息并提高預測的效果。
關鍵詞:知識圖譜嵌入;特征增強;歷史相似案例;法律判決鏈路預測
中圖分類號:TP391.1 文獻標志碼:A 文章編號:1001-3695(2024)07-032-2153-07
doi: 10.19734/j.issn.1001-3695.2023.11.0533
Legal judgment prediction using case feature enhancement based on knowledge graph
Abstract: The existing legal judgment prediction methods based on knowledge graph focus on the element entities and relationships of the case, and cannot adequately capture the characteristic information of the case. Aiming at this problem, the paper proposed a knowledge graph legal judgment prediction method that enhanced the fusion of case features. Firstly, this me-thod used bidirectional gated recurrent neural network to mine the deep semantic feature information such as causality and time sequence of fact description text. Then, it calculated the feature representation of the learning class case by the similarity attention between cases in the knowledge graph vector space. Finally, the fusion of feature information and structured knowledge of knowledge graph enriched the semantic feature representation of entities and relationships in the case fact text, and realized the legal judgment link prediction task. The experimental results on the two types of crime datasets of dangerous driving and theft show that the method improves the two key evaluation indicators of MRR and Hit@1 by about 1.5% compared with the current best-performing link prediction models. The indicators such as Hit@3 and Hit@10 are also improved, which verifies that the case feature enhancement fusion can supplement the missing case feature information in the legal knowledge graph and improve the prediction effect.
Key words:knowledge graph embedding; feature enhancement; historical similarity cases; legal judgment link prediction
0 引言
人工智能技術下的法律判決預測(legal judgment prediction,LJP)是指從海量司法案件中學習判決模式,根據案件的事實文本來預測案件的判決結果,如適用法律條款、所犯罪名和刑期等。基于深度學習的法律判決預測方法[1~5]取得了非常高的預測準確率,但由于判決模式對法律工作人員不可見以及對案件中的核心要素刻畫不足,導致其無法很好地解釋判決結果的由來。基于知識圖譜的法律判決預測方法以三元組的形式關注案件事實描述中關鍵要素實體及實體間的關系,能有效地提取和展示海量案件信息知識,將影響最終判決結果的案件事實要素直觀地展現出來,為案件的判決結果提供清晰有力的支持。洪文興等人[6]依托命名實體識別和關系抽取技術,概括案件事實的骨架結構,提出司法案件的案情知識圖譜自動構建模型,為后續中文法律知識圖譜的下游任務奠定了基礎。
為增強法律知識圖譜實體關系的表達能力,杜文源[7]提出基于知識圖譜的刑事案件判決預測模型,融合多源信息的向量化表示,取得了較好的效果,但采取直接拼接的方式實現知識圖譜多源異質信息的融合會產生融合損失。陳思[8]通過在司法圖譜嵌入四種類型的罪名空間標簽特征,捕獲更多的罪名信息來學習魯棒的罪名向量表示,實現了更好的預測效果,但卻未針對如何融合這些罪名標簽的表征提出更有效的嵌入方式。Dhani等人[9]基于印度知識產權相關法律法規構建知識圖譜,借鑒遠程監督思想提出了一種通過從法律知識圖譜中自動學習節點特征來預測案例圖節點的解決方案,發現結合相關領域特征可以獲得更好的預測結果。另外,為了豐富知識圖譜結構化表示的信息,Li等人[10]針對文本理解和法律推理困難的問題提出了基于文本和圖的法律條文補全方法,通過文本特征增強圖節點表示,提升了預測效果。王治政等人[11]提出基于多視角知識圖譜嵌入的量刑預測方法,通過學習要素的初始表示以及融合知識圖譜特征,在量刑預測任務中表現較優。針對當前法律判決任務不能完全有效地整合法律條款的信息,Zhao等人[12]設計了一種圖融合方法來融合文本和外部知識的法律條文區分信息,有效提升了預測效果。考慮到判決預測過程中相似案例的影響,黃治綱等人[13]針對傳統的知識圖譜向量化表示精度較低等問題,提出一種基于知識圖譜的案件推薦模型,通過知識表示學習尋找相似案件,提升推薦準確率。綜上所述,基于知識圖譜的法律判決預測方法主要集中于提取案件事實描述的關鍵信息,過度依賴實體關系,未能全面地捕捉到案件事實的特征信息,而通過融合外部信息來豐富特征表示以彌補不足,對于預測結果準確率的提升具有不錯的效果。
受此啟發,本文提出了一種對知識圖譜進行特征增強的法律判決預測方法。從案件事實描述文本中抽取實體關系構建法律知識圖譜,以結構化信息概括影響判決結果的案件核心要素。利用案件事實描述文本的全文語義特征以及歷史類案特征來增強當前案例實體關系的特征表示,進行全局信息學習和歷史信息學習。實現融合外部信息的同時,增強知識圖譜內部類案特征的表示,既強化案情描述和案件要素實體之間的信息交互,又增強相似案件之間的影響,減少無關因素的干擾,為知識圖譜案件事實要素三元組中的實體關系向量表示提供更豐富的特征信息,增強案件文本與法律知識圖譜之間的關聯性,提高最終的預測效果。
本文的主要貢獻如下:
a)采用雙向門控循環神經網絡理解文本描述上下文信息,進行全局信息學習,獲取案件文本中的全局語義信息特征,增強知識圖譜嵌入空間中實體關系與案件事實描述文本之間的關聯表示。
b)計算案例間實體相似度來獲取知識圖譜中歷史相似案例特征信息,學習歷史信息特征,擴大法律圖譜向量空間中相似案例間實體關系特征影響。
c)采用基于注意力機制融合方法來減少兩種異質特征的融合損失。
1 問題定義
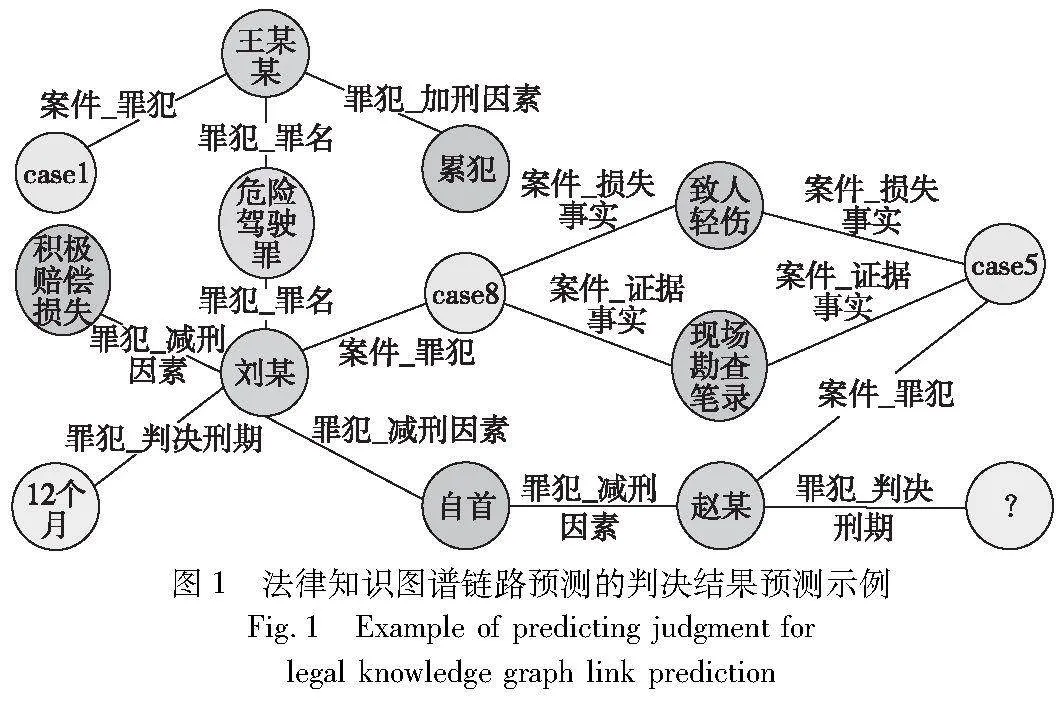
將法律判決預測任務定義為知識圖譜的鏈路預測任務,如圖1所示,通過結合知識圖譜中的結構化案件信息和案件事實描述文本的特征信息,豐富向量表示,提高最終判決預測結果的準確率。
針對案件事實描述進行知識抽取,并完成本體構建,旨在結構化表述案件的事實要素信息和審理過程,以本體模型作為表示、存儲案件事實要素信息的邏輯存儲介質,主要以裁判文書中案件事實描述的組成部分及它們之間的語義關系為依據。基于七步法[14],結合司法判決基本流程,構建法律判決本體模型,為法律知識圖譜構建提供邏輯支撐,具體定義實體類型和實體間關系如表1所示。其中,以案件號實體為出發點的關系主要描述案件事實基本信息,以罪犯實體為出發點的關系主要描述某罪犯在某案件中最終所獲判定信息。
對于法律知識圖譜中的實體集合E和關系集合R,鏈路預測任務的輸入端是從案件事實描述中提取到的案件事實要素三元組的集合S={(h,r,t)},其中h,t∈E,r∈R,每個三元組由頭實體h、關系r和尾實體t組成,輸出端是預測的三元組量刑尾實體。該任務的目標是通過給定的判決結果三元組(h,r,t)遮蓋尾實體,生成測試三元組(h,r,ttest),并利用知識圖譜鏈路預測模型來推斷該判決結果實體屬于目標實體的概率。在該預測模型中,通過對頭實體向量h和關系向量t進行計算,得到當前案件的判決結果實體屬于目標實體的概率值,根據概率值對判決結果三元組的尾實體進行預測。
2 基于知識圖譜的案件特征增強法律判決預測模型
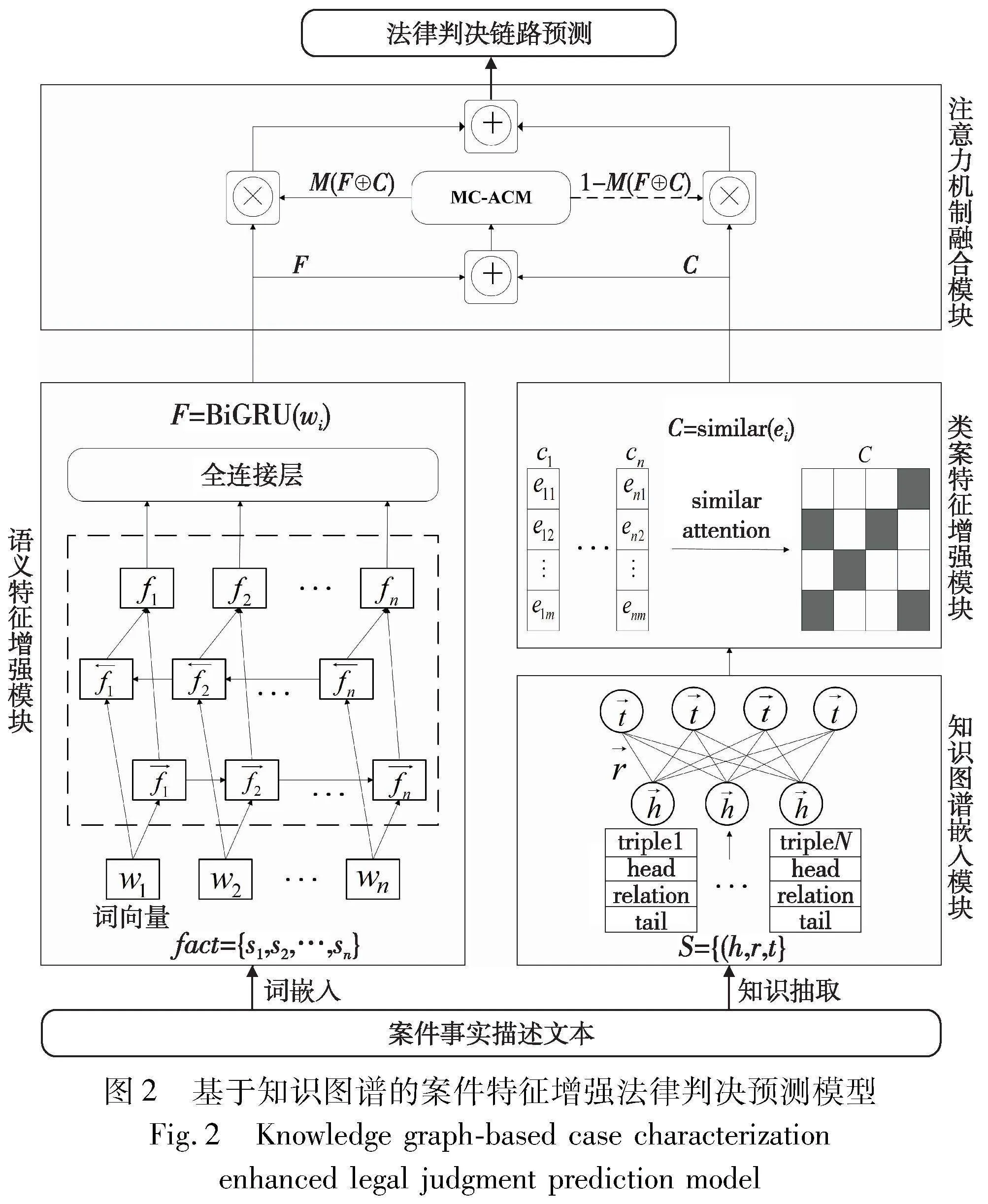
針對知識圖譜嵌入存在案件事實特征信息缺失的問題,提出基于知識圖譜的案件特征增強法律判決預測模型(know-ledge graph feature enhance legal judgment prediction,KGFELJP),模型主要由知識圖譜嵌入模塊、類案特征增強模塊、全文語義特征增強模塊和基于注意力機制的特征融合模塊組成,模型結構如圖2所示。
首先需要對案情描述的事實文本進行知識圖譜三元組提取,將自然語言的案件事實轉換為結構化的圖譜表示,有助于捕捉案件事實之間的關系。另外,為了獲取案件事實描述的整體語義信息,還需要對事實描述文本進行詞向量編碼,編碼后通過單層的雙向門控循環神經網絡(bidirectional gate recurrent unit,Bi-GRU)[15]作為理解上下文信息的嵌入機制來增強案件事實描述文本的全文語義特征,更準確地捕捉案件文本之間的關聯性。同時,對知識圖譜嵌入后的案件要素向量通過案例實體相似度計算學習歷史案例實體的向量表示,計算案例間實體相似度作為權重,讓當前案例學習到相似案例的關鍵實體和特征。最后通過基于注意力機制融合歷史案例特征增強后的知識圖譜案件要素向量表示和案件事實描述全文語義特征。在融合特征后進行法律判決鏈路預測任務,基于現有實體之間的關系,預測出判決結果的尾實體,實現法律判決預測的目標。通過全文語義特征和歷史相似案例特征來豐富知識圖譜三元組的向量表示,彌補知識圖譜嵌入過程中案件特征信息的丟失,在保證可解釋性的前提下提高預測結果的準確性。
2.1 知識圖譜嵌入模塊
通過知識抽取,將裁判文書中的案情事實描述轉換為事實三元組的形式來進行表示,使案件事實描述的自然語言文本轉換為結構化的知識圖譜向量,基于當前表現最好的RotatE[16]鏈路預測模型進行知識圖譜嵌入。RotatE 模型主要是通過將實體和關系映射到復數向量空間中,后續再將每個關系定義為復數向量空間中的旋轉,進而可以對不同類型的關系模式進行建模和推理,并且由于其在時間和內存上都保持線性,具有更強的表示能力,所以易擴展到大型的知識圖譜,正好符合法律領域大量相關數據的特點。可以實現將案件事實要素的初始向量映射到圖譜向量空間中,融合文本信息表示和知識圖譜結構,獲取法律知識圖譜中案件要素實體和關系的向量表示。
基于幾何模型RotatE的思想,定義如式(1)所示的評分函數來評估一個事實三元組(h,r,t)的置信度:
如果事實三元組(h,r,t)為真,評分函數應該得到一個盡可能大的值。基于評分函數z(h,r,t),法律知識圖譜中事實三元組(h,r,t)的條件概率定義如式(2)所示。
其中:h′、t′表示頭實體和尾實體的負例;負樣本集S′(h,r,t)={(h′,r,t)|h′∈E}∪{(h,r,t′)|t′∈E}。
知識圖譜嵌入模型的目標是最大化當前法律知識圖譜中已有事實三元組的條件概率,如式(3)所示。
2.2 類案特征增強模塊
實現類案特征增強首先要對相似案例進行分組,將具有相似特征的案例分到同一個組,每個組表示一個案例類。從每個案例類中學習差異性特征,分析每個案例類中的案件差異,作為該類的差異性特征。將當前案件的特征與每個案例類作比較,匹配相似度最高的那個類。根據匹配案例類的差異性特征調整當前案件的向量表示,糾正偏差,關注當前案件和匹配案例類的差異點,保留當前案件的獨特特征。
案例間相似度就是把一個案例的各個實體屬性間相似度綜合在一起,通常是通過距離來定義的。在構建好的知識圖譜實體向量空間中,每個案件ci都是由n個實體eni表示成ci=(e1i,e2i,…,eni)T的形式。為了計算每個不同案件之間的語義相似度,通常使用兩個案件之間的歐氏距離來體現案件的語義相似性。兩個案例ci、cj之間的歐氏距離為兩個k維向量(e1i,e2i,…,eki)與(e1j,e2j,…,ekj)之間的距離,如式(4)所示。
其中:d(ci,cj)表示兩個向量之間的歐氏距離。假設案例ci、cj的相似度使用simcase(i, j)來表示,如式(5)所示。為了進行歸一化處理,將案例間相似度限制在(0,1]來作為注意力權重系數:
得到當前案例與歷史相似案例的相似度之后,把相似度作為注意力機制的權重αj加權求和,使當前案例學習到對歷史案例注意力聚焦的實體特征c,沿著列方向平鋪得到具有歷史案例特征的案件要素向量表征C,如式(6)所示。
c=∑αjc:j
C=TiledT(c)(6)
其中:αj為上述得到的當前案例與歷史相似案例的相似度;TiledT(c)表示沿著列方向平鋪T次。
2.3 全文語義特征增強模塊
進行全文語義特征增強,需要對案件事實描述進行詞向量編碼,將每個字符映射到高維向量空間,其中每個向量元素代表了一個詞語或短語的語義表示。將案情描述向量表征輸入一個單層的雙向門控循環神經網絡來獲取上下文信息的語義向量序列。將案件事實的語義信息嵌入到文本編碼向量中,增強文本表示的語義特征,獲取更全面、準確的案件表示,繼而更好地理解案件各個要素之間的關系和影響,彌補知識圖譜嵌入重點關注于三元組信息而缺失全文語義特征的缺陷。
將輸入案件的案情描述分為m個句子,每個句子經過詞向量編碼后表示為si,每個句子中的詞使用詞向量wj進行表示,因此整個案件的案情描述可以表示為m個句子的向量序列fact={s1,s2,…,sm}。之后將案情描述的詞向量表示送入雙向門控循環神經網絡層中,模擬詞與詞之間的語義交互來獲取案情描述上下文語義依賴特征F,如式(7)所示。
2.4 基于注意力機制的融合模塊
對類案特征增強后的知識圖譜三元組向量特征表示C和對事實描述文本全文語義特征增強后的特征表示F采用注意力機制特征融合方法(attentional feature fusion,AFF)[17]進行融合,融合后的特征可以表示為
最終鏈路預測的結果分數采用與 RotatE一致的評分函數,如式(1)所示,區別在于加上了融合后的特征向量矩陣可以實現案件要素的向量表示與知識圖譜的三元組結構相結合,豐富三元組中實體和關系的特征表示,如式(9)所示。
其中:Re(·)表示向量的實部;lm(·)表示向量的虛部;Wfc表示增強融合后的特征在復數空間的向量矩陣;Θ為參數空間。
2.5 方法步驟
算法 基于知識圖譜的特征增強鏈路預測方法
3 實驗和分析
3.1 實驗數據集
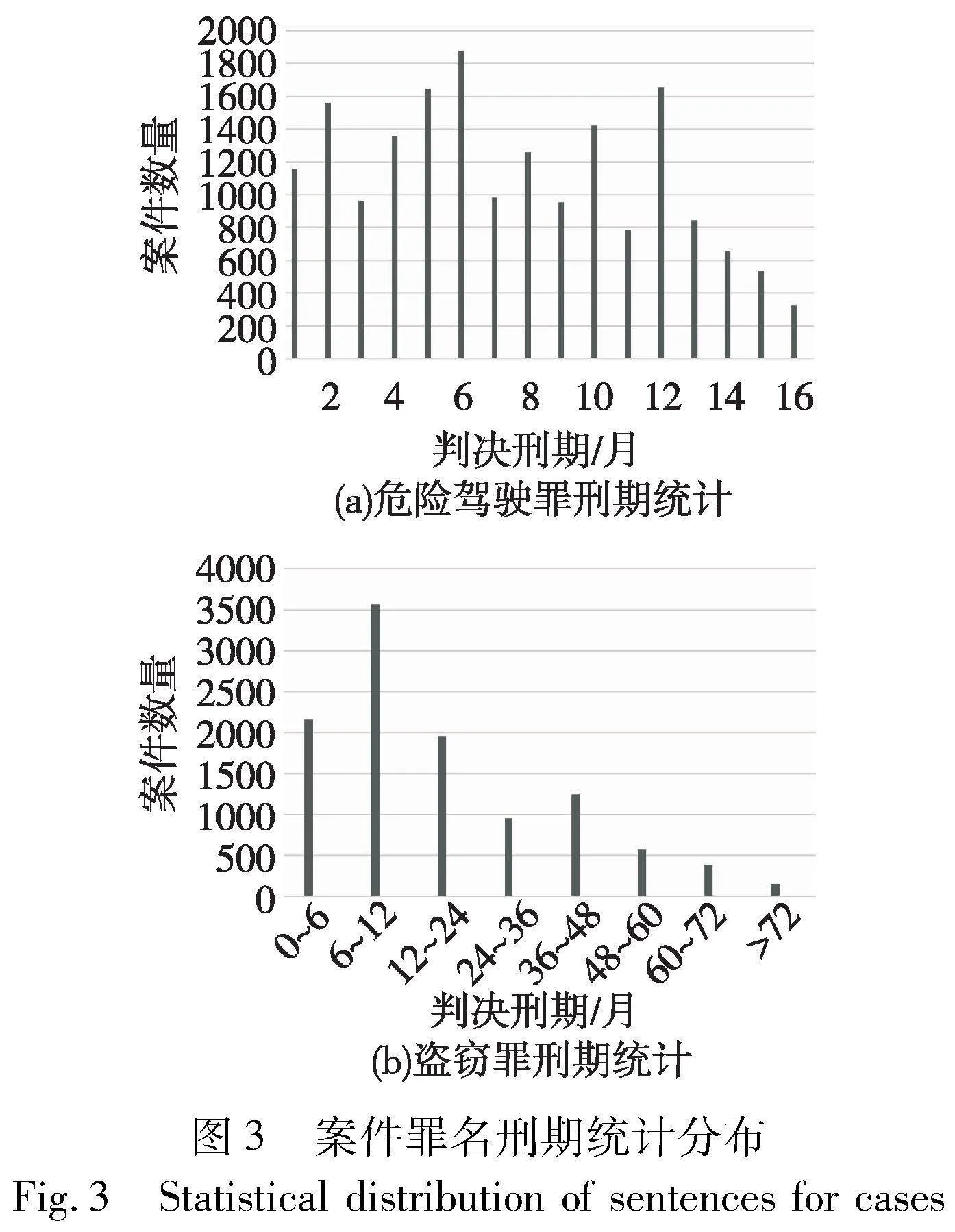
數據集選擇經過脫敏處理的CAIL2018的測試數據集[18],共包括268萬刑事法律文本,其中涉及202條罪名和183條法條,刑期長短包括0~25年、無期、死刑,內容對應到案情描述與罪名裁定兩部分,滿足對裁判文書中的數據源的需求。經過數據清洗,挑選出單人單罪的案件,即只有一個犯罪嫌疑人且只觸犯一個罪名的案件,最終選擇初始數據集和經過篩選得到的危險駕駛罪和盜竊罪這兩類罪名刑期標簽分布差距很大的類別案件為研究對象,并對數據的刑期結果進行統計,得到以月為單位刑期的案件數量統計,如圖3所示。
3.2 參數設置和評價指標
由于中文案件事實描述文檔長度大部分都在 300~750 字符,為減少裁剪和填補帶來的負面影響,設置最大文檔長度為 635字符;采用 Adam 算法作為優化器,學習率設為 0.000 1;提取案件事實語義特征的鄰域信息的長度為 50,即為案件事實要素采樣 50 字符節點作為其上下文信息;單層Bi-GRU 的dropout(隨機失活率)設置為丟失 0.2;批次處理大小設置為 8,訓練輪次設置為 99。
知識圖譜嵌入的實體和關系向量維度為200,每個計算批次的大小為 100 × 50,正例三元組的個數為100,每個三元組的負采樣個數為50,訓練輪數設置為 1 000,剩余參數為RotatE中所提供的默認參數。
鏈接預測任務通常以MRR、Hit@1、Hit@3、Hit@10作為評估模型的指標。MRR是指平均倒排序,主要用于衡量正例三元組的最高排名,計算值越大,表示模型的鏈接預測性能越好,表示為
Hit@n是指在鏈接預測中排名小于n的三元組的平均占比,側重于總體排名,數值越大,表示模型的鏈接預測性能越好,n的取值一般為1、3和10,具體公式如下:
其中:S表示三元組的集合;|S|是三元組集合的個數;ranki表示第i個三元組的鏈接預測排名;函數I(·)表示如果條件成立則為1,不成立則為0。
考慮到需要與基于深度學習的判決預測方法進行比較,使用準確率Acc和宏F值(macro-F)用于基于深度學習的法律判決預測的評價指標。Acc與Hit@1基本一致,主要用于評價結果中最大概率為正確標簽的比例;macro-F用于評價模型在所有標簽中的分類性能。
3.3 基線模型
為了驗證本文方法在基于法律知識圖譜的法律判決鏈路預測任務中的有效性,將本文方法與幾類非常典型的知識圖譜鏈路預測模型方法和深度學習預測方法進行對比。對比方法主要包括TransE[19]、TransH[20]、TransA[21]、TransR[22]、DistMult[23]、SimplE[24]、ComplEx[25]、ConvE[26]和當前鏈路預測表現效果最好的RotatE[16]以及當前最新的基于深度學習的法律判決預測方法NeurJudge[27]、EPM[4]以及ML-LJP[28]。
3.4 實驗結果和實驗分析
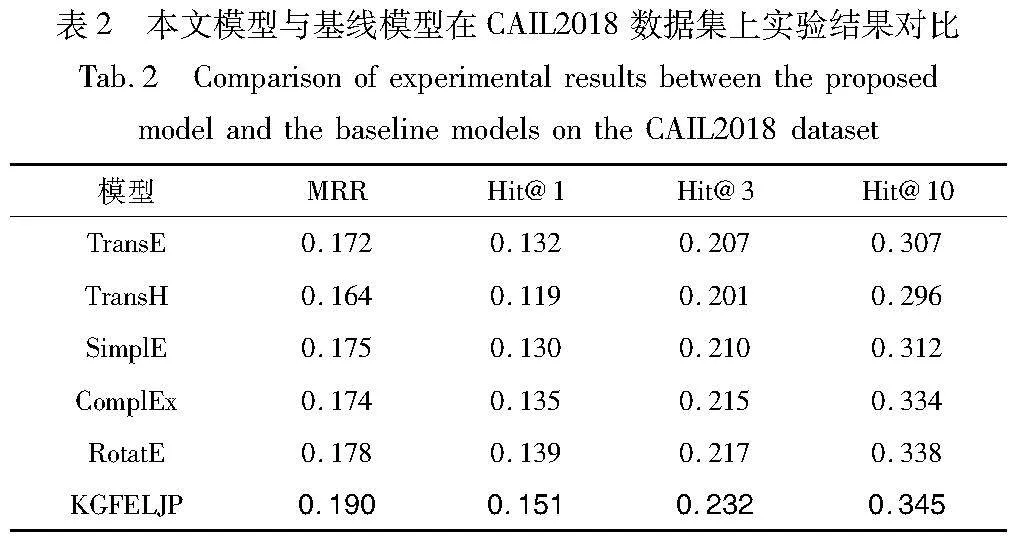
為了比較特征增強的知識圖譜法律判決鏈路預測模型 KGFELJP 和基線模型,在未篩選罪名的CAIL2018數據集和篩選某種罪名后的兩種罪名,即危險駕駛罪和盜竊罪的數據集上進行了大量的實驗,實驗結果如表2~5所示,黑體數字為最優結果(下同)。特別說明:考慮到基于知識圖譜和基于深度學習的判決預測任務具有兩種不同的評價指標體系,無法獲取對方的評價指標數據,因此在表5中使用“—”來代替表示。
從實驗結果可以看出:
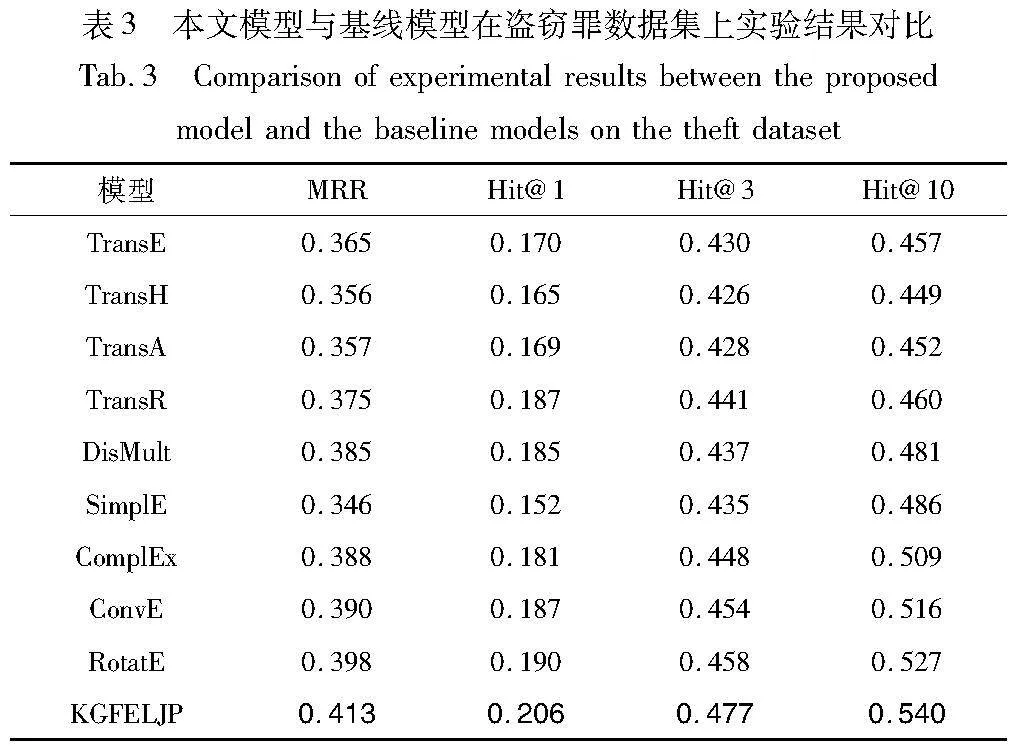
a)從基準模型的角度來說,KGFELJP模型在不同的數據集上,整體都優于當前最好的知識圖譜鏈路預測模型RotatE。其中在三類數據集上, KGFELJP 比最好的模型RotatE 在評價指標MRR上均有提升,說明本文方法對正確實體的結果預測位置更靠前,預測效果更好;在評價指標Hit @1、Hit @3、Hit @10上同樣有所提升,說明本文方法在預測精度上更加優秀。由此可以證明,通過增強知識圖譜中實體和關系的特征表示,獲取實體關系在案件事實描述文本中的語義信息及歷史案例中的特征信息,進行法律判決鏈路預測任務,可以提升最終預測的效果。但由表5可得,KGFELJP模型與最新表現較好的基于深度學習的法律判決預測模型ML-LJP相比,仍然存在一定的差距,但通過使用圖譜嵌入方法可以獲得案件要素的向量表示,為模型學習案件的審理邏輯提供推理鏈路規則,使辦案人員能清楚地理解模型的預測依據,提升預測結果的可解釋性。
b)從聚焦罪名的角度來說,KGFELJP模型在聚焦某類罪名的數據集上,評價指標的提升要比在CAIL2018整體數據集上提升效果高得多,很可能是通過篩選出某種特定的罪名,去掉了很多對結果無關的影響因素,控制模型復雜度,減少模型學習的困難,避免過擬合。
c)從刑期分布的角度來說,KGFELJP模型在危險駕駛罪的數據集上,評價指標的提升要比在盜竊罪的數據集上提升性能高,原因可能是危險駕駛罪的刑期標簽分布比較均勻,會減少很多因數據不均衡而產生的噪聲損失,后續研究需要在數據集處理時,對刑期標簽劃分固定區間范圍以減少損失。
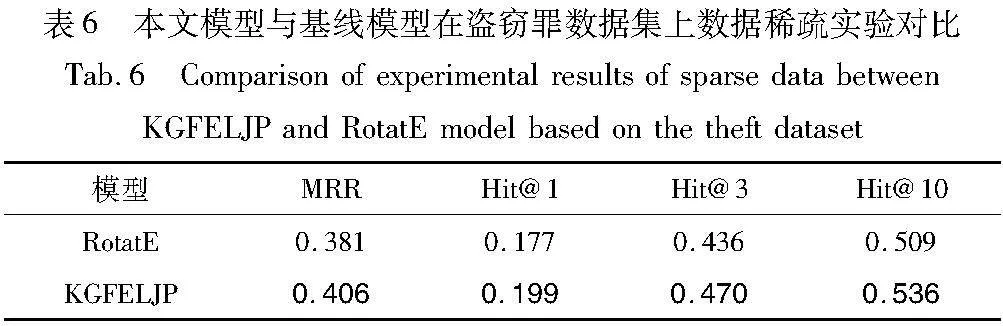
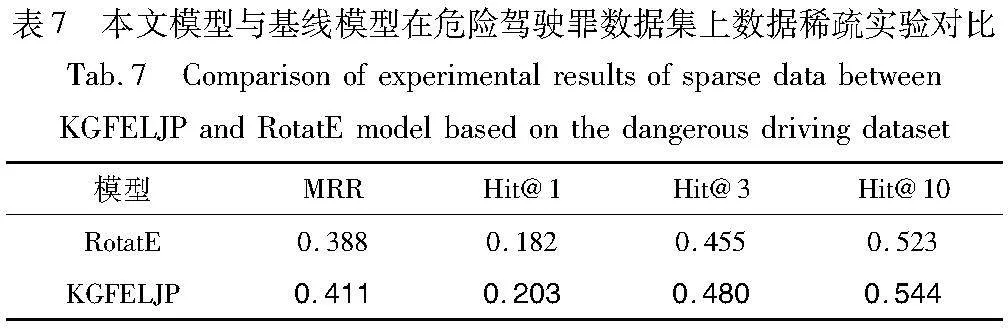
考慮到知識圖譜數據的稀疏問題,即由于信息表達的豐富性往往帶有偏好,且受限于知識抽取手段本身性能問題(一些暗含的常識信息并不會出現在自然語料中),實體間的關系往往是不完整的。為了充分驗證模型的有效性,額外在兩種罪名數據集上進行了稀疏知識圖譜信息實驗,在保證不剔除實體/關系的前提下,隨機剔除數據中的一些事實,結果如表6和7所示。
實驗結果顯示,在隨機剔除某些事實的條件下,在兩種罪名數據集上各模型表現均有下降,其原因可能是某些關系的缺失影響了部分實體描述的豐富性,制約了模型的進一步提升。這一問題在基于嵌入的模型RotatE中尤為明顯,這是由于缺乏結構信息在語義空間中會學習到錯誤的嵌入,最終效果會下降很多。而本文模型通過額外學習全局信息和歷史信息來彌補語義空間部分實體關系缺失的不足,雖然表現也有所下降,但相較于RotatE模型還算比較穩定。上述實驗驗證了本文模型在面對數據稀疏問題的有效性,為知識圖譜法律判決預測任務提供了一個新的有競爭力的解決方案。
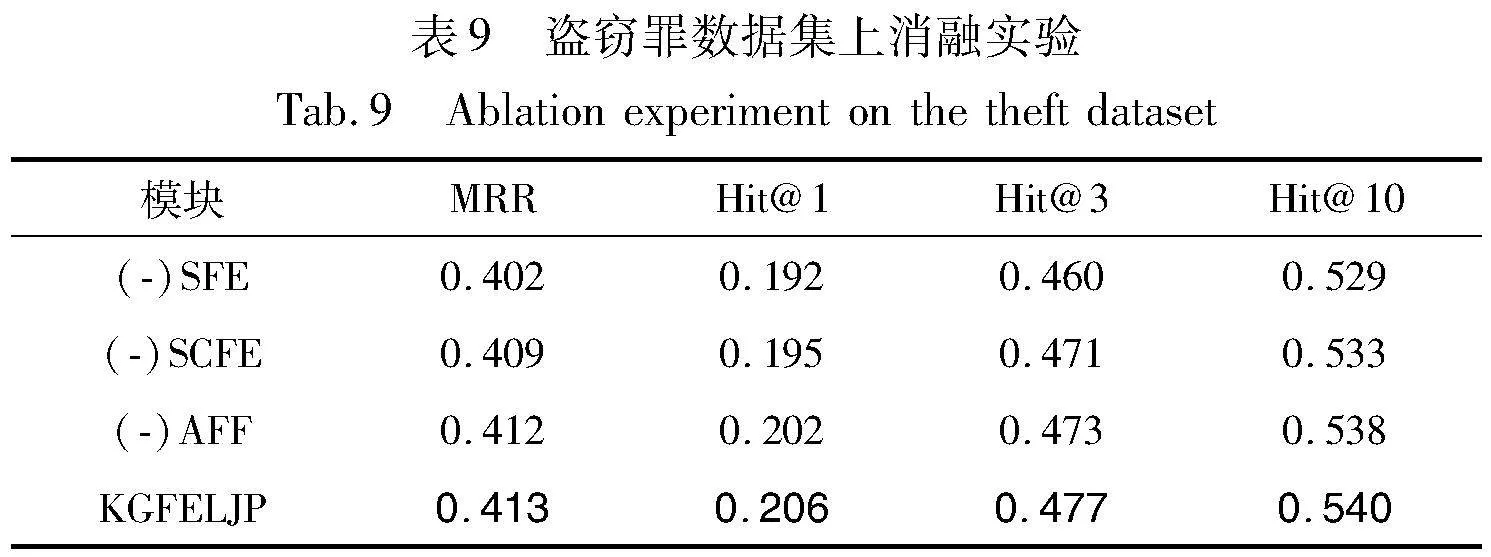
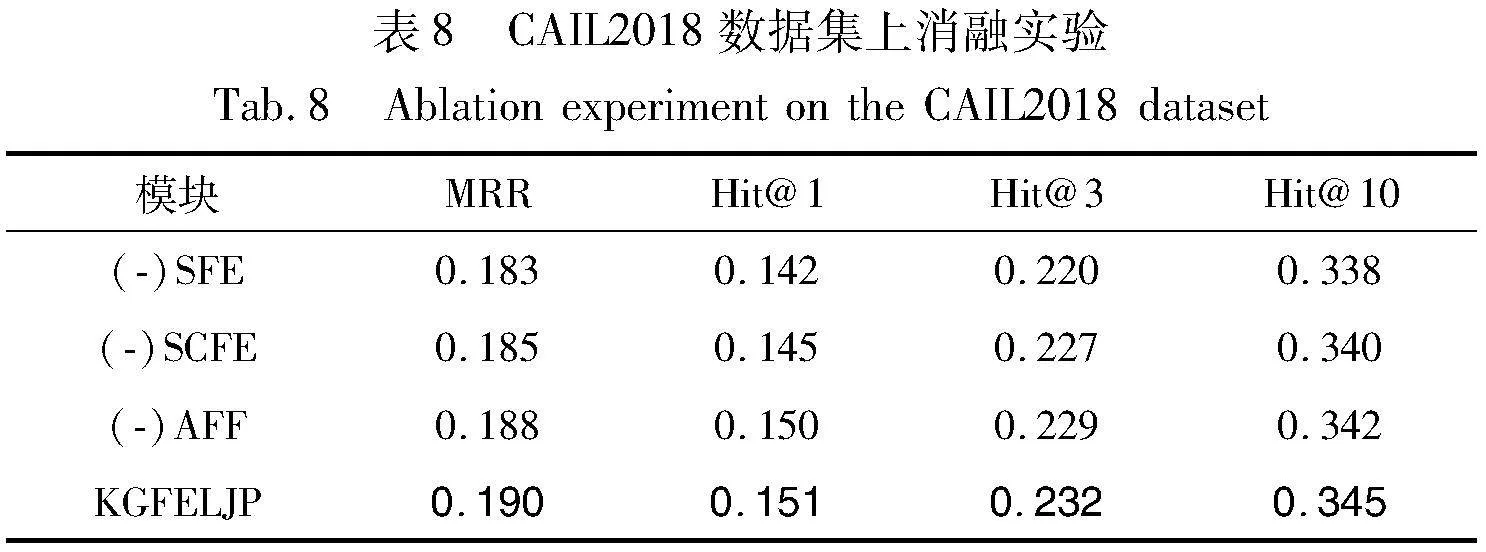
3.5 消融實驗
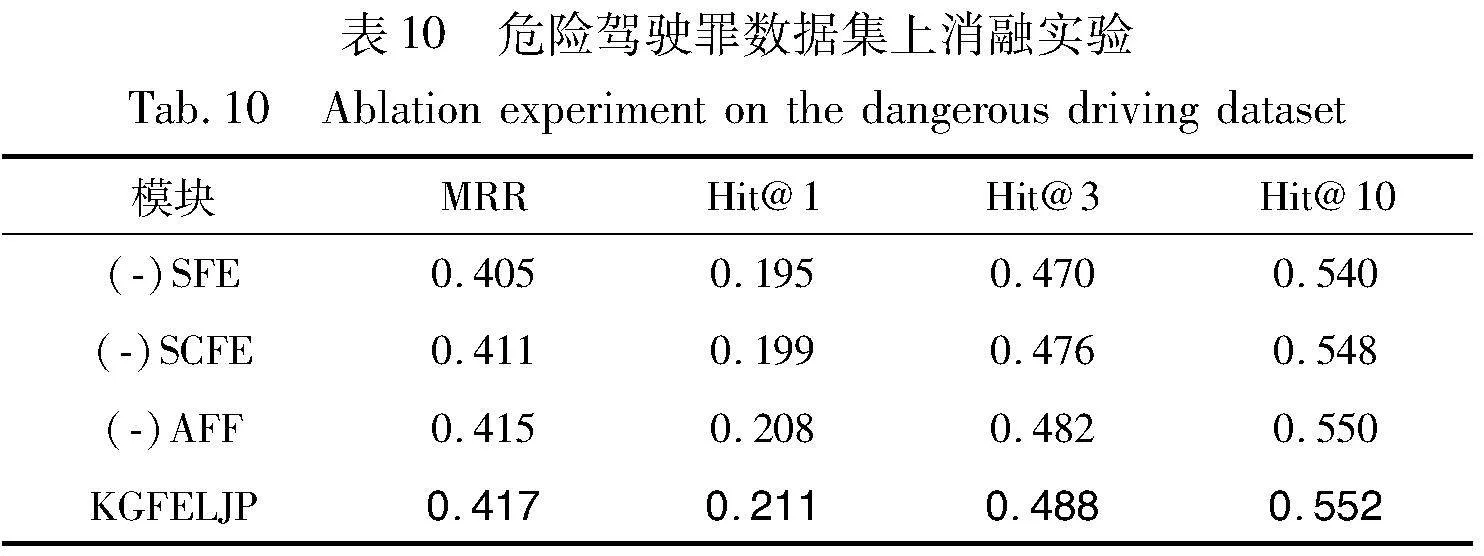
為了驗證本文模型的類案特征增強模塊、全文語義特征增強模塊以及注意力機制特征融合模塊的有效性,采用控制變量的方法進行比較,實驗結果如表8~10所示。特別說明:“(-)SCFE”表示未對知識圖譜向量空間使用相似案例特征增強;“(-)SFE”表示未使用全文語義特征增強來彌補語義損失;“(-)AFF”表示對特征增強后的向量采用直接拼接的向量融合方式,未引入注意力機制融合來減少損失。
實驗結果顯示,在不同的罪名數據集上去掉某個模塊的結果,模型表現均有所降低,充分驗證了模型中各模塊的有效性。另一方面,在使用兩個模塊對知識圖譜向量空間進行豐富向量表示后,額外加入注意力特征融合機制可以明顯彌補兩種異構特征融合時的信息損失,從而進一步提升了最終的鏈路預測效果。綜上,通過定量分析,充分驗證了本文模型中各模塊的有效性,為知識圖譜法律判決預測任務提供了一個新的有競爭力的解決方案。
3.6 預測方法可解釋性分析
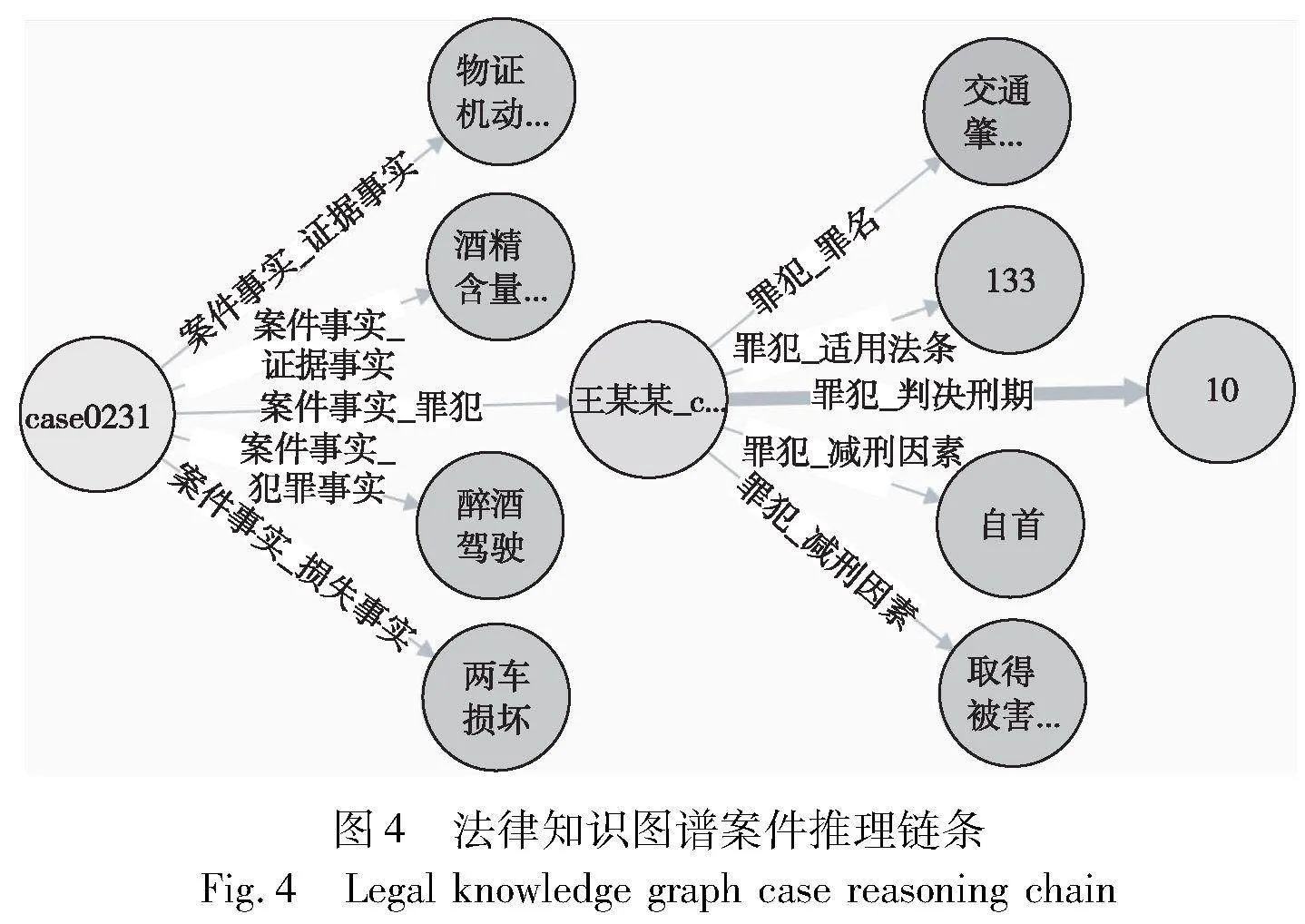
雖然本文模型的預測效果與當前表現較好的基于深度學習的法律判決預測模型相比,仍然存在一定的差距,但是基于知識圖譜的判決預測方法通過自然語言處理,對司法領域非結構化文本數據進行信息提取和知識融合,將文本中的案件事實和法律關系進行提煉和概括,實現了從非結構化文本向結構化知識圖譜的轉換,從而減少數據的模糊性和不確定性,獲得了更具解釋性和確定性的司法知識表達。知識圖譜結構化表示有利于案件分析和法律推理,可以實現對司法決策過程的可解釋性建模,在構建好的法律知識圖譜中,每一個案件事實實體和關系中都存在一條清晰明了的推理鏈條,即“案件基本信息-案件提交證據-案件犯罪主體-案件當事人違反罪名及法條-案件加(減)刑因素-案件最終判決結果”,如圖4所示。
從當前案件審判流程中所提交的案件關鍵證據事實出發,途經案件犯罪主體和對案件的判決結果有影響的案件因素,將識別出的案件要素與提交證據標準關聯匹配,獲取相符合的法條和罪名,并最終得到當前案件的法律判決結果,形成完整嚴謹的法律判決預測邏輯體系,清晰地展示出案件審理推斷的主要情況和發展趨勢,支撐法院審判工作流程中的案件演化分析,如圖5所示,輔助法官通過案件推理鏈條實現對案情的合理分析,可提高司法審判的效率和質量。
4 結束語
本文選取智慧司法領域中較為重要的法律判決預測任務作為研究重點,針對基于知識圖譜的法律判決預測方法未充分融合外部特征,存在案件特征信息缺slTl7RrN4ZhcxWyXgk90FdmzN3pnbZztqc1FVzEtpCE=失的問題,引入特征補全來彌補知識圖譜嵌入中案例信息的缺失。具體來說,本文通過雙向門控循環神經網絡獲取案件事實描述文本的語義信息表示,另一邊對知識圖譜嵌入后的案件要素向量表示進行歷史相似案例特征增強,最終兩者經注意力機制融合不同層次的案情描述的表示,以增強知識圖譜中的實體和關系與案件的文本描述之間的關聯,獲得實體和關系在案情文本中的語義信息,從而提升最終預測的性能。在經過數據處理后的公開數據集上進行了實驗,結果顯示,本文提出的特征增強的類案輔助鏈路預測方法在法律判決預測任務上優于當前表現最好的鏈路預測模型,且相較于基于深度學習的法律判決預測方法來說,更具有可解釋性,可以實現對司法決策過程的可解釋性建模。當然,本文研究也存在一定不足之處,如選取了只有一個當事人且只涉及到一個罪名的案件作為研究重點,此外效果也并未達到基于深度學習的法律判決預測方法的最優效果。未來,考慮從這兩個方面繼續進行研究,在保證可解釋性的前提下,不斷提高方法的最終預測效果。
參考文獻:
[1]Zhong Haoxi,Guo Zhipeng,Tu Cunchao,et al. Legal judgment prediction via topological learning [C]// Proc of Conference on Empirical Methods in Natural Language Processing. Stroudsburg,PA: Association for Computational Linguistics,2018: 3540-3549.
[2]Ma Luyao,Zhang Yating,Wang Tianyi,et al. Legal judgment prediction with multi-stage case representation learning in the real court setting [C]// Proc of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York : ACM Press,2021: 993-1002.
[3]Huang Yunyun,Shen Xiaoyu,Li Chuanyi,et al. Dependency learning for legal judgment prediction with a unified text-to-text transformer[EB/OL].(2021-12-13). https://arxiv.org/abs/2112.06370.
[4]Feng Yi,Li Chuanyi,Vincent N. Legal judgment prediction via event extraction with constraints [C]// Proc of the 60th Annual Meeting of the Association for Computational Linguistics. Stroudsburg,PA: Association for Computational Linguistics,2022: 648-664.
[5]張晗,鄭偉昊,竇志成,等. 融合法律文本結構信息的刑事案件判決預測 [J]. 計算機工程與應用,2023,59(3): 253-263.(Zhang Han,Zheng Weihao,Dou Zhicheng,et al. Integrating multi-layer structure information of law for legal judgment prediction [J]. Computer Engineering and Applications,2023,59(3): 253-263.)
[6]洪文興,胡志強,翁洋,等. 面向司法案件的案情知識圖譜自動構建 [J]. 中文信息學報,2020,34(1): 34-44.(Hong Wenxing,Hu Zhiqiang,Weng Yang,et al. Automated knowledge graph construction for judicial case facts [J]. Journal of Chinese Information Processing,2020,34(1): 34-44.)
[7]杜文源. 基于知識圖譜的刑事案件判決預測算法研究 [D]. 廈門:廈門大學,2020.(Du Wenyuan. Research on criminal case judgment prediction algorithm based on knowledge graph [D]. Xiamen:Xiamen University,2020.)
[8]陳思. 司法領域知識圖譜構建及推薦應用的研究與實現 [D]. 北京: 北京郵電大學,2020.(Chen Si. Research and implementation of knowledge graph construction and recommendation application in the judicial field [D]. Beijing:Beijing University of Posts and Tele-communications,2020.)
[9]Dhani J S,Bhatt R,Ganesan B,et al. Similar cases recommendation using legal knowledge graphs [EB/OL].(2024-03-02). https://arxiv.org/abs/2107.04771.
[10]Li Luoqiu,Zhen Bi,Ye Hongbin,et al. Text-guided legal knowledge graph reasoning [C]// Proc of the 6th China Conference on Know-ledge Graph and Semantic Computing. Singapore: Springer,2021: 27-39.
[11]王治政,王雷,李帥馳,等. 基于多視角知識圖譜嵌入的量刑預測 [J]. 模式識別與人工智能,2021,34(7): 655-665.(Wang Zhizheng,Wang Lei,Li Shuaichi,et al. Sentencing prediction based on multi-view knowledge graph embedding [J]. Pattern Recognition and Artificial Intelligence,2021,34(7): 655-665.)
[12]Zhao Qihui,Gao Tianhan,Zhou Song,et al. Legal judgment prediction via heterogeneous graphs and knowledge of law articles [J]. Applied Sciences,2022,12(5): 2531.
[13]黃治綱,謝新強,邢鐵軍,等. 基于司法案例知識圖譜的類案推薦 [J]. 南京大學學報:自然科學,2021,57(6): 1053-1063.(Huang Zhigang,Xie Xinqiang,Xing Tiejun,et al. Case recommendation based on knowledge graph of judicial cases [J]. Journal of Nanjing University Natural Science,2021,57(6): 1053-1063.)
[14]鄧詩琦,洪亮. 面向智能應用的領域本體構建研究——以反電話詐騙領域為例 [J]. 數據分析與知識發現,2019,3(7): 73-84.(Deng Shiqi,Hong Liang. Constructing domain ontology for intelligent applications: case study of anti tele-fraud[J]. Data Analysis and Knowledge Discovery,2019,3(7): 73-84.)
[15]Cho K,Van Merrienboer B,Gulcehre C,et al. Learning phrase representations using RNN encoder-decoder for statistical machine translation [EB/OL].(2014-09-03). https://arxiv.org/abs/1406.1078.
[16]Sun Zhiqing,Deng Zhihong,Nie Jianyun,et al. RotatE: knowledge graph embedding by relational rotation in complex space [EB/OL].(2019-02-26). https://arxiv.org/abs/1902.10197.
[17]Dai Yimian,Gieseke F,Oehmcke S,et al. Attentional feature fusion [C]// Proc of IEEE/CVF Winter Conference on Applications of Computer Vision. Piscataway,NJ: IEEE Press,2021: 3559-3568.
[18]Xiao Chaojun,Zhong Haoxi,Guo Zhipeng,et al. CAIL2018: a large-scale legal dataset for judgment prediction [EB/OL].(2018-07-04). https://arxiv.org/abs/1807.02478.
[19]Bordes A,Usunier N,Garcia-Durán A,et al. Translating embeddings for modeling multi-relational data [C]// Proc of the 26th Internatio-nal Conference on Neural Information Processing Systems. Red Hook,NY : Curran Associates Inc.,2013:2787-2795.
[20]Wang Zhen,Zhang Jianwen,Feng Jianlin,et al. Knowledge graph embedding by translating on hyperplanes [C]// Proc of the 28th AAAI Conference on Artificial Intelligence. Palo Alto,CA: AAAI Press,2014:1112-1119.
[21]Xiao Han,Huang Minlie,Hao Yu,et al. TransA: an adaptive approach for knowledge graph embedding [EB/OL].(2015-09-28). https://arxiv.org/abs/1509.05490.
[22]Lin Yankai,Liu Zhiyuan,Sun Maosong,et al. Learning entity and relation embeddings for knowledge graph completion [C]// Proc of the 29th AAAI Conference on Artificial Intelligence. Palo Alto,CA: AAAI Press,2015: 2181-2187.
[23]Yang Bishan,Yih W T,He Xiaodong,et al. Embedding entities and relations for learning and inference in knowledge bases [EB/OL].(2015-08-29). https://arxiv.org/abs/1412.6575.
[24]Kazemi S M,Poole D. Simple embedding for link prediction in know-ledge graphs [EB/OL].(2018-10-26). https://arxiv.org/abs/1802.04868.
[25]Trouillon T,Welbl J,Riedel S,et al. Complex embeddings for simple link prediction [EB/OL].(2016-06-20). https://arxiv.org/abs/1606.06357.
[26]Dettmers T,Minervini P,Stenetorp P,et al. Convolutional 2D know-ledge graph embeddings [C]// Proc of the 32nd AAAI Conference on Artificial Intelligence. Palo Alto,CA: AAAI Press,2018:1811-1818.
[27]Yue Linan,Liu Qi,Jin Binbin,et al. NeurJudge: a circumstance-aware neural framework for legal judgment prediction [C]// Proc of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York : ACM Press,2021: 973-982.
[28]Liu Yifei,Wu Yiquan,Zhang Yating,et al. ML-LJP: multi-law aware legal judgment prediction [C]// Proc of the 46th International ACM SIGIR Conference on Research and Development in Information Retrieval. New York : ACM Press,2023: 1023-1034.
