基于圖注意力網絡的時序知識圖譜人機交互模型
2024-08-23 00:00:00于泳喬少杰陳金勇高林黃江濤劉晨旭韓楠張?zhí)?/span>蔡宏果
無線電工程 2024年7期

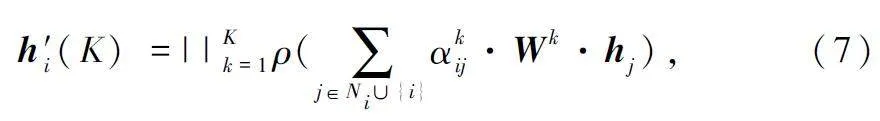
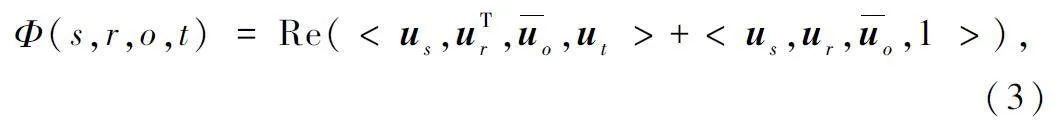
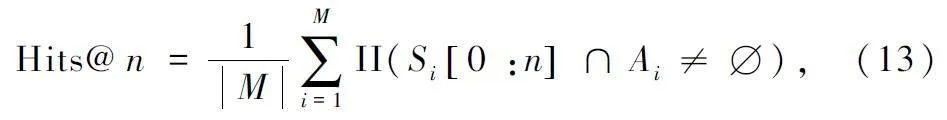



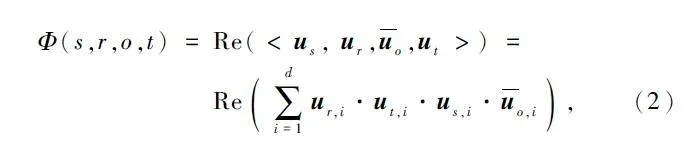


摘 要:組織和檢索信息是人機交互重點關注的話題之一。基于知識圖譜(Knowledge Graph,KG) 的智能問答系統(tǒng)通過語義解析用戶問題,檢索知識并回答問題,已成為一種信息檢索的有效途徑,是人機交互的典型應用。時序知識圖譜(Temporal Knowledge Graph,TKG) 問答系統(tǒng)通過語言模型獲取問題中的實體和時間戳,并在大型TKG 中檢索答案。TKG問答系統(tǒng)包含2 個挑戰(zhàn):① 給定問題,需檢索整個TKG,效率低且易受干擾項的影響;② 難以捕獲問題中隱含的時間詞和時間順序信息。提出一種基于圖注意力網絡的時間對比學習(Time Contrast Learning,TCL)模型,將源問題與替換時間詞后的對比問題同時訓練, 使用圖注意力網絡更新實體鄰接子圖的節(jié)點特征, 縮小潛在答案的檢索空間。在CRONQUESTIONS 數(shù)據(jù)集上進行大量實驗,結果表明TCL 比其他基準方法具有更好的性能,相較于最先進的基準方法在Hit@ 1 和Hits@ 10 指標上平均提升3. 44% 和2. 02% 。
關鍵詞:智能問答;時序知識圖譜;圖注意力網絡;時間對比學習;語言模型
中圖分類號:TP391. 9 文獻標志碼:A 開放科學(資源服務)標識碼(OSID):
文章編號:1003-3106(2024)07-1676-11
0 引言
信息社會中人們利用計算機、手機等通信設備進行交流,得益于人機交互領域的快速發(fā)展。人機交互是計算機科學領域的重要研究方向,其目的是提高計算機系統(tǒng)與人類之間的交互效率和用戶體驗,為人們生活和工作提供更加便捷、高效的技術支持。
組織和檢索信息是人機交互的關注點之一。在計算機的早期發(fā)展階段,專家系統(tǒng)、檢索系統(tǒng)作為信息的有效組織方式,可以滿足人們的信息需求。但隨著計算機技術的不斷發(fā)展,以往的信息組織方式已經無法滿足人們的需求。智能問答系統(tǒng)是一種基于人工智能技術的人機交互應用,可以根據(jù)用戶的提問,快速、準確地給出相應的答案或解決方案。這種系統(tǒng)可以幫助人們更加高效地獲取所需的信息,提高信息檢索的效率和準確性。早期的智能問答系統(tǒng)Baseball[1]利用基于規(guī)則的方法構建,通常只能處理特定領域中的限定形式問題。人工智能技術促進了基于知識圖譜(Knowledge Graph,KG)的智能問答系統(tǒng)的發(fā)展。利用神經網絡訓練模型,將KG 作為知識庫輔助模型推理,相較于基于規(guī)則的問答模型,基于KG 的智能問答系統(tǒng)在回答問題時更加準確,不再局限于特定領域和限定形式的問題。
基于KG 的智能問答系統(tǒng)的核心技術是KG,KG 是一種基于語義的知識表示方式,通常以圖結構描述實體、屬性與關系,以便更好地理解和利用知識。KG 解決了傳統(tǒng)搜索引擎存在的缺陷,即無法理解搜索內容的語義信息,只能根據(jù)關鍵詞匹配查詢結果,而KG 可以通過語義理解進行知識的查詢和推理。
傳統(tǒng)KG 中的事實大多是靜態(tài)的,其內部的知識在任何時間段都成立,忽略時間維度的重要性。然而,在現(xiàn)實中,事實通常只在一定時間內成立。在傳統(tǒng)KG 的基礎上,融入時間維度,構成了時序知識圖譜(Temporal Knowledge Graph,TKG)。TKG 除時間信息外,還隱含事件之間的發(fā)展規(guī)律,具有廣泛研究價值。
TKG 以四元組的形式記錄實體之間的關系和關系存在時的時間戳或時間段。例如,帶時間戳的四元組(北京,舉辦,2008 年奧運會,2008)和帶時間段的四元組(Drancy,head of government,MauriceNilès,[1959,1997])。TKG 可以更好地回答與時間相關的問題,包括推測某些事件發(fā)生的時間以及推測多個實體在時間上的相關性。
不同于關注關系推理的非時序問答,時序問答的核心挑戰(zhàn)是正確識別問題中顯式或隱式提出的時間信息,并通過對關系和時間戳的聯(lián)合推理來定位相關知識獲取正確答案。現(xiàn)有方法將TKG 應用到了問答模型中,使其具有處理時序問題的能力。然而,模型不具有捕獲給定問題中隱含的時間詞和時間順序的能力。而且,模型需要從整個TKG 檢索候選答案,效率低下且性能較差。
為了解決上述問題,本文提出了時間對比學習(Time Contrast Learning,TCL)模型,主要貢獻包括:
① 提出一種基于圖注意力網絡的TCL 模型,使用鄰接圖抽取模塊從TKG 中獲取問題中實體的鄰接子圖,縮小候選答案的搜索空間,并使用圖注意力網絡更新鄰接圖中的節(jié)點表示,引導模型更加關注與問題相關的實體和時間戳,減少與問題不相關的實體的干擾,提高了檢索效率。
② 提出TCL 模塊,利用時間詞對比詞典將源問題轉化為對比問題,同時訓練源問題與對比問題,引導模型學習源問題與對比問題中的時間詞差異,提高了模型對時間順序信息的敏感程度。
③ 在CRONQUETIONS 數(shù)據(jù)集上進行大量實驗,相較于最先進的基準算法Time-aware MultiwayAdaptive(TMA),在一次命中率Hits@ 1 上和前10 次命中率Hits@ 10 兩個指標上平均提升了3. 44% 和2. 01% 。實驗結果表明本文提出的TCL 模型具有較好的性能。
1 相關工作
1. 1 TKG 嵌入
由于KG 內部的知識的完備性和正確性不能得到保證,導致其應用場景受限。研究者們先后提出Translating Embedding(TransE)[2]、Complex Embedding(ComplEx)[3]、Rotation Embedding(RotatE)[4]等KG嵌入模型,通過將KG 中的實體和關系投影到連續(xù)的低維向量空間,從而在方便計算的同時保留KG中的結構信息。
Jiang 等[5]使用時間維度的一致性作為約束,將時間信息與得分函數(shù)相結合,將TransE 模型應用于TKG,但這種方法學習的嵌入沒有明確的時間感知能力,僅能矯正一些順序邏輯關系,例如wasBorIn→wonPrize→ diedIn。為了解決這一問題,Dasgupta等[6]提出一種基于超平面的時間感知KG 嵌入方法(Hyperplanebased Temporally aware Embedding,HyTE)。HyTE 將KG 按照時間戳分割為多個子圖,然后將子圖中的實體和關系投影到其對應的時間戳超平面中,直接將時間信息編碼到嵌入模型中,使得模型可以預測不包含時間范圍的事實的時序信息。García-Durán 等[7]提出一種學習某時間節(jié)點的潛在實體和關系類型表示法,使用詞元序列表示時間謂語,使用數(shù)字表示時間點并訓練遞歸神經網絡(Recursive Neural Network,RNN)模型,得到的表示結果可以應用到通用的KG 嵌入模型的得分函數(shù)中。Lacroix 等[8]引入正則化方案來分解4 階張量,提出ComplEx 在時間維度上的擴展(Temporal ComplexEmbedding,TComplEx),該方法很好地適應不同數(shù)據(jù)集的時間表達形式,如時間點、開始時間與結束時間的時間間隔。Goel 等[9]受歷時詞嵌入的啟發(fā),提出一種歷時實體嵌入(Diachronic Embedding,DE)函數(shù),將實體嵌入定義為函數(shù),為任意給定的時間戳提供實體特征。任何靜態(tài)KG 嵌入都可以借助DE 函數(shù)拓展為TKG 嵌入,具有較好的優(yōu)越性。
1. 2 TKG 問答
時序問答系統(tǒng)主要在閱讀理解的語境下進行研究。Jin 等[10]提出一種新的自動事件預測方法———ForecastQA,幫助人們規(guī)劃未來。該方法將事件預測問題轉化為多項選擇答題任務,數(shù)據(jù)集中的文章和問題均帶有時間戳。Ning 等[11]提出一種閱讀理解的數(shù)據(jù)集TORQUE,探尋文本中描述的事件之間的時間順序關系。
另一個重要研究方向是利用知識庫作為輔助信息,從其中檢索時序信息,來回答時序問題。傳統(tǒng)KG問答系統(tǒng)大多采用的是大規(guī)模的靜態(tài)KG 和語言模型相結合,例如,文獻[12]提出了一種語言模型驅動的KG 問答推理模型QAKGNet,具有優(yōu)越的結構化推理能力。但這些大規(guī)模的靜態(tài)KG 沒有考慮時間因素對問答模型預測答案時的影響,使現(xiàn)有方法無法有效、準確地處理帶有時間約束的問題[13]。
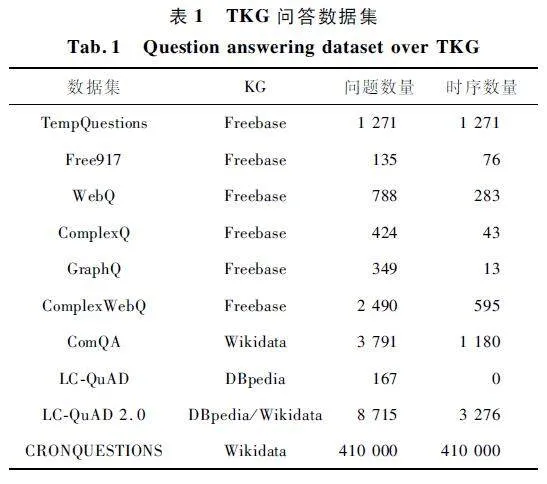
為了能更準確地回答用戶的問題,學者們開始研究時序問題。Jia 等[14]提出了一個時序問答基準數(shù)據(jù)集TempQuestions,包含1 271 個時序問題及其答案,旨在評估問答系統(tǒng)處理具有時間信息的復雜問題的能力,其研究結果表明,對復雜問題需要展開深入研究。基于該數(shù)據(jù)集,Jia 等[15]提出時序知識問答方法TEQUILA 來解決TKG 問答中包含時間信息的復雜問題。TEQUILA 利用規(guī)則將帶有時間信息的復雜問題分解為簡單的子問題,并使用子問題的答案集與時間約束進行聯(lián)合推理來獲取答案,可以與KG 問答系統(tǒng)結合使用。但TEQUILA 使用的規(guī)則模板是專家預先給定的,限定了處理復雜問題的能力。在此之后,Jia 等[16]希望提高問答系統(tǒng)回答時序問題的性能,提出了端到端問答系統(tǒng)Exaqt,該系統(tǒng)首先微調語言模型(Bidirectional Encoder Representationfrom Transformers,BERT),同時加入時間信息,構建與問題相關的實體鄰接子圖。此外,使用擴展的關系圖卷積網絡(Relational Graph Convolutional Network,R-GCN)來預測答案,實驗表明該方法在解決具有時間意圖的問題時具有較好的表現(xiàn)。然而TEQUILA 與Exaqt 所使用的數(shù)據(jù)集包含時間信息的問題數(shù)量有限,且使用的KG 大都為非TKG,如表1 所示。
TEQUILA 與Exaqt 方法實驗結果表明,增強時序信息可顯著提升答案預測性能。Saxena 等[17]提出一個新的大規(guī)模TKG 問答數(shù)據(jù)集CRONQUES-TIONS,該數(shù)據(jù)集含有41 萬個問題-答案對,且所有的時間問題和TKG 都具有時間注釋。同時,基于該數(shù)據(jù)集,提出CRONKGQA 來解決時序問題,其性能優(yōu)于所有基線方法。該方法改進了EmbedKGQA[18],使其可以適用TKG 嵌入。CRONKGQA 首先使用BERT生成實體問題嵌入和時間問題嵌入,然后使用TComplEx 得分函數(shù)計算整個TKG 中的實體和時間得分數(shù),將實體和時間得分拼接后,使用softmax 函數(shù)計算答案概率。CRONKGQA 在處理簡單問題時具有較好的準確性,但處理復雜問題的性能不夠理想。近期,Liu 等[19]提出了一種時間感知多路自適應融合網絡TMA。TMA 使用多路自適應模塊生成問題的特定時間表示,與預訓練的TKG 嵌入結合,生成最終的預測答案。
2 問題描述
基于KG 的智能問答系統(tǒng)將KG 作為問答系統(tǒng)的知識庫,通過語言模型理解用戶問句中的語義信息,通過在知識庫中檢索相關信息,通過知識推理獲取正確答案。而傳統(tǒng)的KG 問答系統(tǒng)較難處理時序問題。本文采用TKG 代替?zhèn)鹘y(tǒng)KG,通過TKG 嵌入模型將其轉為低維向量,輔助問答系統(tǒng)利用KG 中隱含的時間信息,處理時序問題。
定義1(TKG)TKG G = (ε,R, T,γ),其中,ε 表示G 中實體的集合,R 表示G 中關系的集合, T表示G 中時間戳的集合,γ 表示由前三者組合而成的事實集合。事實v 四元組的形式為(s,r,o,t),其中<s,o>∈ε,r∈R,t∈T 。
例1. 已知時序事實四元組v = (北京,舉辦,奧運會,[2008,2008])。
定義2(TKG 嵌入)TKG 嵌入是指對于G 中的每個<s,o>∈ε,r∈R,t∈T ,將其學習為低維嵌入向量<us,ur,uo,ut >∈Rd,其中d 表示低維嵌入向量的維度。通過語義相似度來構建一個得分函數(shù)Φ(·)來學習這些嵌入。對于一個有效的事實v =(s,r,o,t)∈γ 的Φ(·)得分,要比一個無效事實v’= (s’,r’,o’,t’)∈γ 的Φ(·)得分高。得分函數(shù)Φ(·)需要滿足:
Φ(s,r,o,t) > Φ(s’,r’,o’,t’)。(1)
TComplEx 是針對時態(tài)KG 的語義匹配算法,是ComplEx 在時間維度上的擴展。它將實體、關系和時間戳嵌入到復數(shù)空間中,其對應的得分函數(shù)如式(2)所示:
式中:Re 表示取復數(shù)的實部,<· >表示多次線性的點積運算,uo 表示uo 的共軛復數(shù),<us,ur,uo,ut >∈Cd,是復數(shù)嵌入,d 表示復數(shù)嵌入向量的維度。
關系r 可能含有時間信息,也可能不含時間信息。基于此,提出另一種得分函數(shù)(Temporal andNotTemporal Complex Embedding,TNTComplEx)[8],該得分函數(shù)計算時間敏感部分和非時間敏感部分的得分之和,其計算公式如下:
式中:uTr表示具有時間信息的關系嵌入向量,T 表示轉置操作,ur 表示不包含時間信息的嵌入向量。
定義3(TKG 問答系統(tǒng))TKG 問答任務是指用戶給定一個自然語言問題q,問答系統(tǒng)通過理解q 中的語義信息,獲取問題實體信息,從G 中獲取與問題實體相關的四元組信息,通過時間推理,找到合適的時間段內的四元組信息,并給予用戶準確的答案。
例2. 已知問題q = “Who was the president of theRoyal Society in London 2012?”,針對這個問題,TKG問答系統(tǒng)從問句中提取實體the president of the RoyalSociety 和時間戳2012,找到實體對應的事實v= (PaulNurse,position held,the president of the Royal Society,[2010,2015]),利用v 中的信息回答問題。
TKG 問答系統(tǒng)所處理的時序問題,按照推理的復雜程度可分為簡單問題和復雜問題。
定義4(簡單問題)q 只需要G 中的單個事實v便可以回答,回答的答案可能是一個實體或一個時間戳,具體如例2 所示。按照答案類型可進一步將問題劃分為簡單實體問題和簡單時間問題。
定義5(復雜問題)q 需要G 中的多個事實v 進行回答,回答的答案可能是單個實體或時間戳,也可能是實體集合或時間戳集合,通常需要進行一定的時間推理來獲得最終的答案。
例3. 已知問題“Which was the last award ThomasYoung got?”,針對這個問題需要與Thomas Young 相關的多個v,并進行一定的時間推理來獲取目標答案。復雜問題可進一步分為Before / After、First /Last、Time Join 三大類,具體舉例如表2 所示。
TKG 問答系統(tǒng)應對q 中隱含的時間詞和時間順序信息更為敏感。例如“Which was the last awardThomas Young got?”和“Which was the first awardThomas Young got?”,雖然這2 個問題只有一個時間詞不同,但這2 個問題的答案并不相同。現(xiàn)有的TKG 問答工作通常使用預訓練的語言模型理解問題中的語義信息,但這些模型對自然語言問題中的時間表達差異并不敏感,例如last 和first,before 和after 等,使得模型容易預測出錯誤的答案。
為解決上述問題,本文采用對比學習的方法,增強TKG 問答系統(tǒng)對q 中隱含的時間表達的敏感程度。通過生成源問題的對比問題,構建TCL 模型,同時訓練源問題與對比問題,使模型學習這組對比問題的潛在時間特征的差異,從而使模型可以更好地捕獲q 中隱含的時間表達,提高模型對復雜問題的處理能力,具有更好預測性能。
定義6(時間詞對比詞典)為了生成給定q 的對比問題qc,本文從CRONQUESTIONS 數(shù)據(jù)集中提取問題中的時間詞,然后查找反義詞,構建時間詞對比詞典,部分舉例如表3 所示。
3 TCL 模型
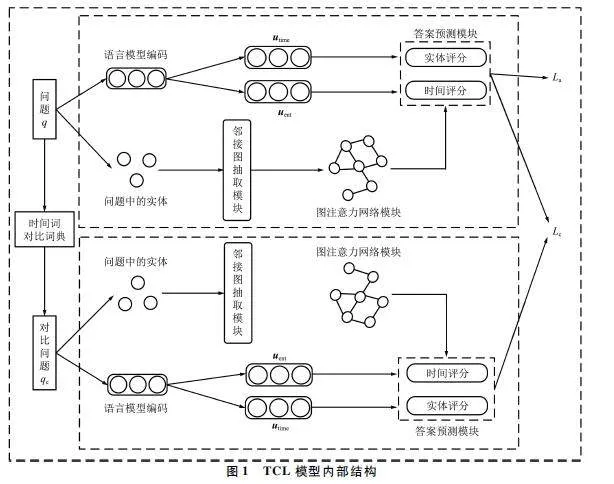
TCL 模型工作原理如圖1 所示。模型可以分為兩部分,一部分對問題q 進行推理,另一部分則是利用時間詞對比詞典將q 轉換為對比問題qc,然后將qc作為輸入進行推理。這兩部分的模型結構是一致的,只是輸入部分不同。針對于問題q,模型使用語言模型對q 進行編碼,獲得uent 和utime;同時,使用鄰接圖抽取模塊獲取q 中實體的鄰接圖,然后利用圖注意力網絡更新鄰接圖中的節(jié)點表示,使用TComplEx 得分函數(shù)計算鄰接圖中實體節(jié)點和時間節(jié)點的得分。通常q 和qc 的答案實體是不相同的,為了捕獲這種差異,本文基于實體不交叉原則,提出對比損失Lc。
3. 1 鄰接圖抽取模塊
假設從問題q 中可以抽取出n 個實體,即{E1 ,E2 ,…,En},首先從G 中提取每個實體Ei 的多跳鄰接子圖Gi;然后,組合這n 個實體的鄰接子圖,得到問題q 的潛在答案的搜索子圖Gq,其中,Gq 滿足Gq =∪ni= 1 Gi。將Gq 中的節(jié)點按節(jié)點類型分為實體節(jié)點和時間節(jié)點,所有的實體節(jié)點組成實體集合εq,所有的時間節(jié)點組成時間戳集合Tq。εq 和Tq 組成了TCL模型中答案預測部分的實體評分和時間評分的搜索空間,使得模型不需要對整個G 中的實體和時間戳進行評分來預測最終答案。在實際應用中,搜索子圖Gq的大小通常比整個TKG G 小得多。例如,在CronKGQA 中,|Gq | / |G|的平均值大約為3% 。
鄰接圖抽取模塊是為了縮小候選答案實體和時間戳的搜索空間,不僅提高了訓練過程的有效性,縮短了訓練時間,還提高了預測答案的性能。這是因為更多的候選答案通常會使模型學習預測答案的過程更加困難,訓練難度將大幅度提高。
3. 2 圖注意力網絡模塊
為了引導模型更加關注與問題相關的實體與時間戳,排除不相關實體的干擾,為尋找答案實體提供了錨點,本文引入圖注意力機制(Graph AttentionNetworks version 2,GATv2)[20]。使用GATv2 對Gq中鄰接節(jié)點與問題的重要性進行描述,過濾掉不重要的鄰居,進而獲取更小的搜索子圖G′q 。具體操作步驟如算法1 所示。
為了使圖注意力網絡的學習過程更加準確,受到文獻[21-22]的工作啟發(fā),在式(6)的基礎上為圖注意力網絡提供了不同角度(多頭)的考慮,提出了多頭圖注意力網絡,將式(6)優(yōu)化為式(7),如下所示:
式中:K 表示不同角度的數(shù)量(頭的數(shù)量),上標k 表示第k 個角度,每個角度的學習過程獨立執(zhí)行,將學到的向量進行拼接。
3. 3 答案預測模塊
本文使用預訓練的語言模型BERT 獲取問題嵌入uq,然后將其投影為實體嵌入uent 和時間嵌入utime,分別表示實體預測問題嵌入和時間預測問題嵌入。
經過圖注意力網絡模塊對搜索子圖Gq 進行剪枝得到G′q ,使用式(2)的得分函數(shù)Φ 計算G′q 中的每個實體節(jié)點和時間戳節(jié)點的得分,將所有實體和時間戳的得分拼接起來,得到答案得分集合Sa。然后,使用softmax 函數(shù)來計算每個答案為正確答案的概率:
式中:當?shù)冢?個候選答案是正確答案時,yi = 1;否則,yi = 0。
3. 4 TCL 模塊
為提高TKG 問答模型捕獲q 中隱含的時間表達式的能力,本文采用對比學習的方法,通過構建TCL 模型,同時訓練源問題與對比問題,提高模型對時間序列信息的敏感程度。
基于定義6,將問題q 中的時間詞替換為時間詞對比字典中的反義詞,生成對比問題qc,將問題q 和對比問題qc 放入模型訓練,得到相應的答案得分集合Sa和S′a ,將這2 個答案得分集合組合起來,得到Sq =[Sa,S′a ]∈R2C。然后,使用softmax 函數(shù)對Sq 進行計算,得到答案概率分布Pq∈R2C,具體計算公式如下:
Pq = softmax(Sq ), (10)
式中:Pq ∈R2C ,且滿足ΣCi = 0 Pq [:,i]= 1,其中Pq [:,i]表示第i 列的答案概率分布。
由于q 的答案肯定不是qc 的答案,可構建答案引導學習標簽[y1 ,y2 ,…,yC ],當且僅當?shù)冢?個候選對象是正確答案時,yi = 1;否則,yi = 0。由此得到TCL 的損失函數(shù),如下所示:
Lc = - 1/CΣCi = 0yi ln(Pq [0,i])。(11)
最后,組合答案預測的損失函數(shù)和TCL 的損失函數(shù)作為最終的損失函數(shù),進行模型訓練。
L = La + λc Lc , (12)
式中:λc 表示衡量時間對比損失的權重因子。
4 實驗與分析
4. 1 數(shù)據(jù)集
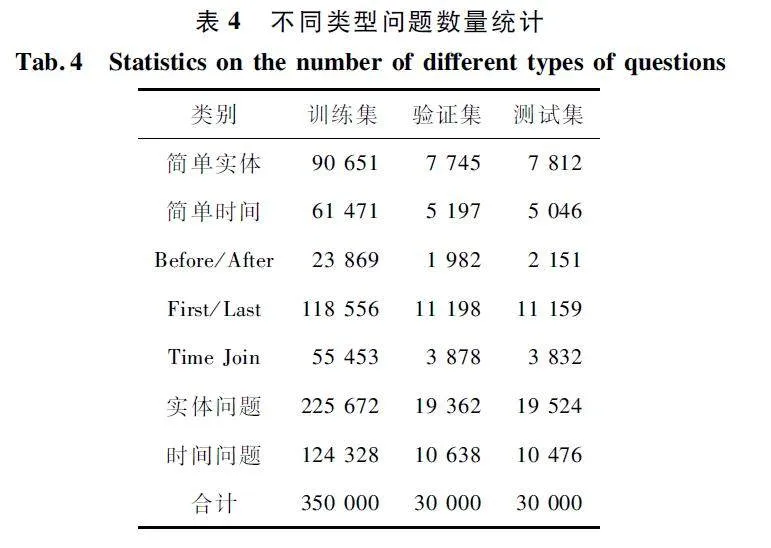
本文在CRONQUESTIONS 數(shù)據(jù)集進行實驗,驗證TCL 模型在TKG 問答任務中的有效性。CRONQUESTIONS 數(shù)據(jù)集包含帶有時間注釋的KG 和需要時間推理的自然語言問題集。TKG 具有12. 5 萬個實體和203 種關系,并由此組合成了32. 8 萬個事實(四元組)。這些事實四元組中含有以年為單位的時間信息。數(shù)據(jù)集中有41 萬個問題,按定義3 和定義4 將問題劃分為不同類型,不同類型的問題數(shù)量如表4 所示。
4. 2 實驗設置
本文使用PyTorch 框架實現(xiàn)所提模型,并按照CRONQUETIONS 數(shù)據(jù)集劃分為訓練集、驗證集和測試集對模型進行訓練,訓練時的超參數(shù)設置如下:初始學習率為0. 000 2,迭代次數(shù)epoch 為200,批大小為250,每5 個epoch 驗證一次模型的效果,驗證時批大小為50,對比損失權重λc 為0. 5。
實驗環(huán)境為英特爾至強W-2245 3. 90 GHz CPU,64 GB 內存,512 GB SSD 硬盤,Ubuntu 20. 04 操作系統(tǒng)以及GPU(GeForce RTX 3090)。對于基準模型,本文使用了其文中對應的參數(shù)設置進行實驗。
對于所有模型,采用Hits@ 1 和Hits@ 10 兩個指標對其進行評估,具體計算公式如下:
式中:II(·)為指示函數(shù),若后面的等式條件成立則輸出為1,否則輸出為0;M 表示數(shù)據(jù)集中問題的總數(shù),S = [Sq ,1 ,Sq ,2 ,…,Sq ,M ]表示所有問題的預測答案集合的集合,Si[0 :n]表示第i 個問題的預測答案中概率最高的前n 個答案。一般情況下n 取1、3、10,本文采用Hits @ 1 和Hits @ 10 兩種,A = [A1 ,A2 ,…,AM ]表示所有問題正確答案的集合。
4. 3 基準方法
本節(jié)對實驗過程中使用的基準對比算法進行介紹:① EmbedKGQA 是一種將KG 嵌入用于多跳KG 問答任務的方法,使用ComplEx 嵌入,只能處理非時態(tài)的KG 和簡單問題。② T-EaE-add/ replace 是用KG 增強語言模型Entities as Experts(EaE)[23]的2 種修改,將KG 中的實體信息集成到基于Transformer 的語言模型中。T-EaE-add 在問題中標明了所有真實的實體和時間跨度信息;T-EaE-replace 則使用實體/ 時間嵌入替換了BERT 嵌入,而不是用詞嵌入的形式添加實體和時間跨度信息。③ CronKGQA 將EmbedKGQA 擴展到時序問答問題,并利用TKG 嵌入來回答時序問題。④TMA 通過選擇、匹配、融合和預測的范式顯示地融合相關知識(Subject Predicate Object,SPO)到問題表示中,使問題嵌入具有時間特異性。
4. 4 實驗結果
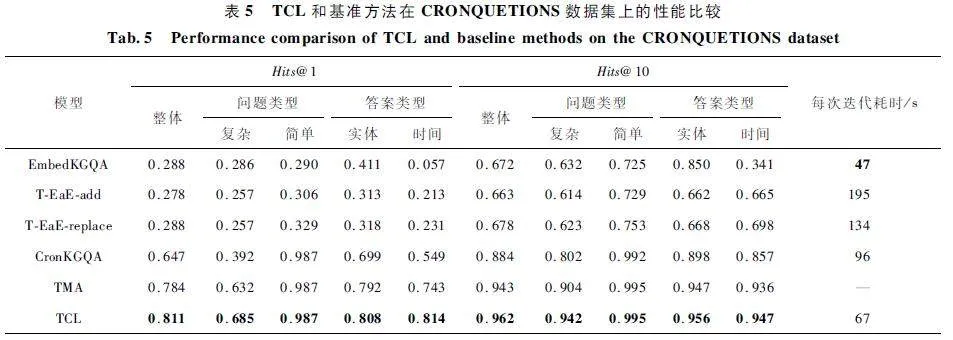
表5 給出了本文提出的TCL 和5 種基準方法在CRONQUESTIONS 數(shù)據(jù)集上的Hits@ 1 和Hits@10 兩種評價指標的對比結果。可以發(fā)現(xiàn),本文提出的TCL 方法在所有類型問題上的2 種評價指標性能均優(yōu)于基準方法。而EmbedKGQA、T-EaE-add /replace 方法的效果非常差,由于它們均使用非時序的KG 嵌入,在處理時序問題時性能較差。
相較于最先進的基準方法TMA,TCL 方法在Hit@ 1 和Hits @ 10 指標上平均提升3. 44% 和2. 01% ,在復雜問題上平均提升了8. 39% 和4. 20% 。這是由于復雜問題中涉及的實體較多,TMA 在回答問題時使用整個TKG,導致許多與問題不相關的實體對最終結果造成干擾,產生偏差。而TCL 方法使用鄰接圖抽取模塊和圖注意力機制對搜索空間進行剪枝,在回答問題時使用的是搜索子圖G′q ,排除了不相關實體的干擾,可以更加準確地回答問題。
同時,CRONKGQA、TMA 和TCL 方法在簡單問題的Hits@ 1 指標上均達到了0. 987,而其他方法則要低很多。這3 種方法均采用TComplEx 作為評分函數(shù),該函數(shù)與實體和時間戳嵌入使用的評分函數(shù)是一致的,使得模型在組合問題中的嵌入信息時具有歸納偏置性,可以提高樣本的利用率,從而更易于回答簡單問題。
對比各模型訓練所需時間,可以發(fā)現(xiàn),Embed-KGQA 所消耗的訓練時間最短,但其預測命中率較差,而TCL 方法所消耗時間僅居其后,相比CRONKGQA 縮短了30. 21% 的訓練時間。這是由于,CRONKGQA 使用整個TKG 回答問題,而TCL 使用鄰接圖抽取模塊縮小搜索空間,提高了訓練效率。但由于TCL 的網絡結構比EmbedKGQA 更為復雜,所以在具有更高性能的同時,訓練時間也更長。而T-EaE-add / replace 采用6 層的Transformer 進行訓練,需要訓練大量的參數(shù),訓練時間更長。
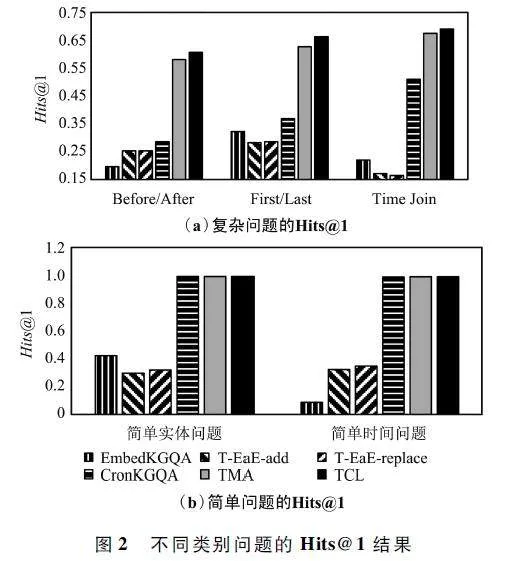
本文比較了TCL 方法與5 種基準模型對于不同類別問題的Hits@ 1,結果如圖2 所示。相比所有基準方法,本文所提出TCL 模型的性能更好,特別是在復雜問題的回答上。相較于最先進的基準方法TMA,TCL 在“Before / After”“First / Last”“Time Join”方面的表現(xiàn)分別提高了4. 48% 、5. 74% 和2. 37% 。實驗結果證明了本文提出的圖注意力網絡模塊和TCL 模塊的性能優(yōu)勢,有利于增強模型對時間詞和時間順序的敏感程度。
如圖2(a)所示,在復雜問題類型中,CronKGQA、TMA 和TCL 三種方法在Time Join 類問題上的表現(xiàn)最好。這是由于Time Join 類問題通常具有多個答案,例如“Who was Juan Carlos Lorenzo-s team memberin Unione Calcio Sampdoria?”這個例子的答案是JuanCarlos Lorenzo 為Unione Calcio Sampdoria 效力時的所有球員。這使得模型更容易做出正確的預測,而其他2 類問題,答案通常是單個實體或者時間戳。
“Before / After”“First / Last”兩類問題更具挑戰(zhàn)性,因為需要更好地理解問題中的時間詞或時間表達式。TCL 方法通過TCL 模塊,使模型可以更好地捕獲不同時態(tài)詞之間的差異,從而取得較大的性能提升。此外,對于簡單問題,如圖2(b)所示,TCL 方法仍然保持競爭力。
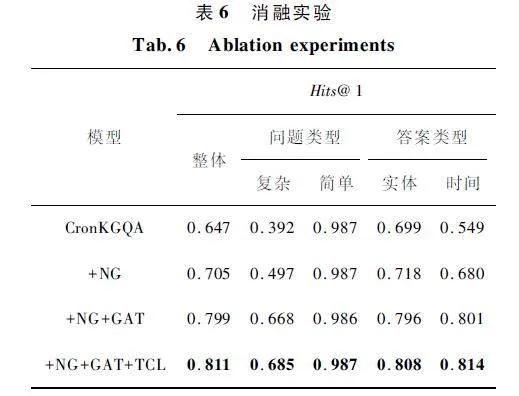
4. 5 消融實驗
為了驗證TCL 方法中每個模塊的貢獻均是有效的,本文通過在CronKGQA 的基礎上添加各模塊構成TCL 方法,進行消融實驗。其中,‘+’表示添加該模塊,GAT 表示圖注意力網絡模塊,NeighborGraph(NG)表示鄰接圖抽取模塊。每組實驗均重復執(zhí)行5 次,最后取平均結果,如表6 所示。
從表6 可以看出,本文所提模塊均有利于提高Hits@ 1 指標的整體性能,特別是針對具有較高復雜性的問題。添加鄰接子圖抽取模塊之后,模型在復雜問題的Hits@ 1 指標上提高了26. 8% ,這是由于顯著縮小了候選答案的搜索空間,有利于模型更加容易和準確地找到正確答案。圖注意力網絡模塊也帶來了顯著的提升,這是由于圖注意力網絡模塊對搜索子圖中的每個節(jié)點進行加權處理,去除了一些與問題無關的節(jié)點,進一步縮小了搜索空間,引導模型更加關注與問題相關的實體與時間戳,為尋找答案實體提供了很好的錨點。此外,TCL 模塊進一步提高了模型對復雜問題的處理性能。TCL 模塊通過學習問題q 與對比問題qc 中時間詞的差異,向模型中添加了明確的時間約束,增強了模型的時間順序學習能力,使得模型可以更好地捕獲問題中隱含的時間詞和時間順序信息。
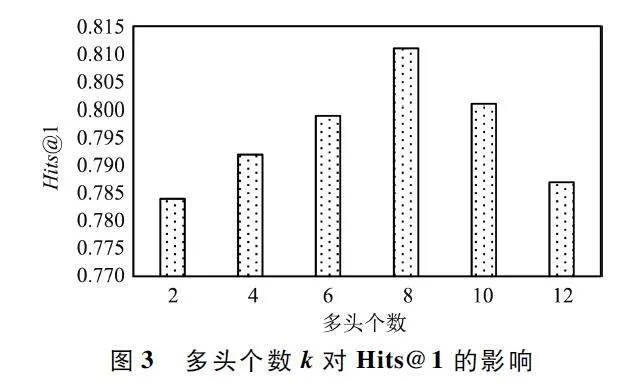
圖3 展示了不同的多頭個數(shù)k 對模型Hits@ 1 的性能影響,即{2,4,6,8,10,12}。結果表明,當k = 8時,模型的Hits@ 1 的性能最好。當k 過少時,圖注意力網絡無法從多個角度充分理解搜索子圖G′q 各節(jié)點的特征,導致去除的不相關實體不夠充分,進而導致模型的Hits@ 1 性能降低。當k 過多時,圖注意力網絡過分關注某些重要特征,從而產生偏差。
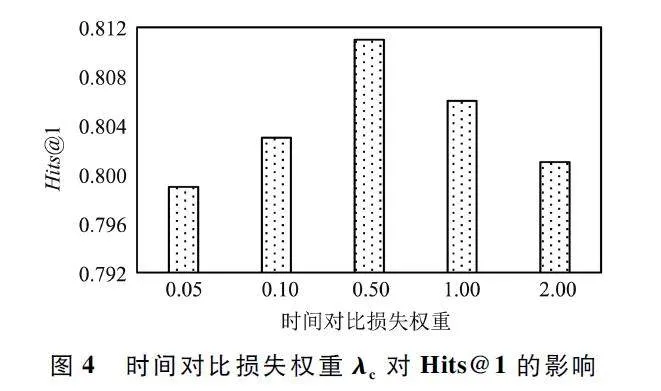
圖4 給出了時間對比損失的權重λc 對模型Hits@ 1 的性能影響,其中,λc 的取值為{0. 05,0. 10,0. 50,1. 00,2. 0}。可以觀察到,隨著λc 取值不斷變大,模型Hits@ 1 的性能在不斷提升,在λc 取值為0. 5 時達到最大,隨后遞減。因為當λc 取值較小時,模型無法充分捕獲在問題中隱含的時間順序信息,而當λc 取值較大后,模型過分關注對比問題的答案,從而產生偏差。
4. 6 模型推理可視化
本小節(jié)將介紹TCL 模型獲取問題q 的正確答案集合Sa 的推理過程,其過程可視化如圖5 所示。其中,Q967859 和Q1457 分別表示q 中的實體JuanCarlos Lorenzo-s 和Unione Calcio Sampdoria,P54 表示member of sports team 這種關系,Q170703 和Q1285795 等實體表示與實體Q967859 和Q1457 相關的實體。
首先,使用BERT 獲取q 的問題嵌入uent 和utime;其次,利用鄰接圖抽取模塊獲取問題中的實體Q967859 和Q1457 的多跳鄰接圖,構成搜索子圖Gq;然后,Gq 通過圖注意力網絡模塊后,去掉了與q 不相關的實體Q170703、Q5129424 等,得到剪枝后的搜索子圖G′q ;最后,通過答案預測模塊對G′q 中的各節(jié)點進行評分,得到答案集合Sa。其中,Q3611080 和Q3804433 實體的得分非常高,而Q1285795 實體的得分比較低。這是因為Q3611080 和Q3804433 與Q1457 的P54 關系成立的時間均在Q967859 與Q1457 的關系成立時間之內,符合q 中隱含的時間順序。而Q1285795 與Q1457 的關系成立時間不在[1947,1952],因此評分較低。
5 結束語。
本文提出一種基于圖注意力網絡的TCL 模型,其獲取給定問題q 的實體和時間戳,能夠從TKG 中抽取實體對應的鄰接子圖,并通過多頭圖注意力網絡進行消息傳遞,更新鄰接子圖中的節(jié)點表示,壓縮答題的搜索空間。利用TCL 方法,同時訓練問題q與對比問題qc,捕獲每組對比問題中隱含時間詞的差異,提高了模型對時間詞和時間順序信息的敏感程度。在CRONQUESTIONS 數(shù)據(jù)集上進行大量實驗,結果表明,TCL 模型相較于主流基準模型在時序問答任務上的性能提升。未來的工作將關注于時間評估方法以進一步提高模型的時間推理能力,以及如何使問題嵌入具有更好的時間特異性。
參考文獻
[1] 姚元杰,龔毅光,劉佳,等. 基于深度學習的智能問答系統(tǒng)綜述[J]. 計算機系統(tǒng)應用,2023,32(4):1-15.
[2] BORDES A,USUNIER N,GARCIADURAN A,et al.Translating Embeddings for Modeling MultirelationalData[C]∥Proceedings of the 27th Annual Conference onNeural Information Processing Systems. Lake Tahoe:Curran Associates Inc. ,2013:2787-2795.
[3] TROUILLON T,WELBL J,RIEDEL S,et al. ComplexEmbeddings for Simple Link Prediction[C]∥Proceedingsof the 33rd International Conference on MachineLearning. New York:JMLR,2016:2071-2080.
[4] SUN Z Q,DENG Z H,NIE J Y,et al. RotatE:KnowledgeGraph Embedding by Relational Rotation in ComplexSpace [C ] ∥ Proceedings of the 7th InternationalConference on Learning Representations. New Orleans:[s. n. ],2019:1981-1999.
[5] JIANG T S,LIU T Y,GE T,et al. Towards TimeawareKnowledge Graph Completion[C]∥Proceedings of COLING 2016,the 26th International Conference on Computational Linguistics:Technical Papers. Osaka:The COLING2016 Organizing Committee,2016:1715-1724.
[6] DASGUPTA S S,RAY S N,TALUKDAR P. HyTE:Hyperplanebased Temporally Aware Knowledge Graph Embedding [C]∥ Proceedings of the 2018 Conference onEmpirical Methods in Natural Language Processing. Brussels:ACL,2018:2001-2011.
[7] GARC?ADUR?N A, DUMANC ˇ IC' S, NIEPERT M.Learning Sequence Encoders for Temporal KnowledgeGraph Completion[C]∥Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. Brussels:ACL,2018:4816-4821.
[8] LACROIX T,OBOZINSKI G,USUNIER N. Tensor Decompositions for Temporal Knowledge Base Completion[C]∥Proceedings of the 8th International Conference on LearningRepresentations. Addis:[s. n. ],2020:3057-3069.
[9] GOEL R,KAZEMI S M,BRUBAKER M,et al. DiachronicEmbedding for Temporal Knowledge Graph Completion[C]∥Proceedings of the AAAI Conference on ArtificialIntelligence. New York:AAAI,2020:3988-3995.
[10] JIN W,KHANNA R,KIM S,et al. ForecastQA:AQuestion Answering Challenge for Event Forecasting withTemporal Text Data[C]∥Proceedings of the 59th AnnualMeeting of the Association for Computational Linguisticsand the 11th International Joint Conference on NaturalLanguage Processing. Online:ACL,2021:4636-4650.
[11] NING Q,WU H,HAN R J,et al. TORQUE:A ReadingComprehension Dataset of Temporal Ordering Questions[C]∥Proceedings of the 2020 Conference on EmpiricalMethods in Natural Language Processing. Online:ACL,2020:1158-1172.
[12] 喬少杰,楊國平,于泳,等. QA-KGNet:一種語言模型驅動的知識圖譜問答模型[J]. 軟件學報,2023,34(10):4584-4600.
[13] 薩日娜,李艷玲,林民. 知識圖譜推理問答研究綜述[J]. 計算機科學與探索,2022,16(8):1727-1741.
[14] JIA Z,ABUJABAL A,ROY R S,et al. TempQuestions:ABenchmark for Temporal Question Answering[C]∥ Proceedings of Companion of the Web Conference 2018.Lyon:ACM,2018:1057-1062.
[15] JIA Z,ABUJABAL A,ROYS R,et al. TEQUILA:TemporalQuestion Answering over Knowledge Bases [C ]∥ Proceedings of the 27th ACM International Conference on Information and Knowledge Management. Torino:ACM,2018:1807-1810.
[16] JIA Z,PRAMANIK S,ROY R S,et al. Complex TemporalQuestion Answering on Knowledge Graphs[C]∥Proceedings of the 30th ACM International Conference on Information and Knowledge Management. Queensland:ACM,2021:792-802.
[17] SAXENA A,CHAKRABARTI S,TALUKDAR P. QuestionAnswering over Temporal Knowledge Graphs[C]∥ Proceedings of the 59th Annual Meeting of the Association forComputational Linguistics and the 11th International JointConference on Natural Language Processing. Online:ACL,2021:6663-6676.
[18] SAXENA A,TRIPATHI A,TALUKDAR P. ImprovingMultihop Question Answering over Knowledge GraphsUsing Knowledge Base Embeddings[C]∥Proceedings ofthe 58th Annual Meeting of the Association for Computational Linguistics. Online:ACL,2020:4498-4507.
[19] LIU Y H,LIANG D,FANG F,et al. Timeaware MultiwayAdaptive Fusion Network for Temporal Knowledge GraphQuestion Answering[EB / OL]. (2023 - 02 - 24)[2023 -04-17]. https:∥arxiv. org / abs / 2302. 12529.
[20] BRODY S,ALON U,YAHAV E. How Attentive are GraphAttention Networks?[EB / OL]. (2021 -05 -30)[2023 -05-10]. https:∥arxiv. org / abs / 2105. 14491.
[21] 俞海亮,彭冬亮,谷雨. 結合雙層多頭自注意力和BiL-STM-CRF 的軍事武器實體識別[J]. 無線電工程,2022,52(5):775-782.
[22] 梁禮明,何安軍,陽淵,等. 融合Transfomer 和多尺度并行注意的結直腸息肉分割算法[J]. 無線電工程,2023,53(1):209-219.
[23] F?VRY T,SOARES L B,FITZGERALD N,et al. Entitiesas Experts:Sparse Memory Access with Entity Supervision[EB / OL]. (2020 - 04 - 15)[2023 - 05 - 10]. https:∥arxiv. org / abs / 2004. 07202.
作者簡介
于 泳 男,(1998—),碩士研究生。主要研究方向:知識圖譜、移動數(shù)據(jù)挖掘。
(*通信作者)喬少杰 男,(1981—),博士后,教授。主要研究方向:時空數(shù)據(jù)庫、人工智能數(shù)據(jù)庫。
陳金勇 男,(1970—),碩士,研究員,碩士生導師。
高 林 男,(1984—),碩士,高級工程師。
黃江濤 男,(1979—),博士,副研究員。主要研究方向:人工智能。
劉晨旭 男,(1999—),碩士研究生。主要研究方向:人工智能數(shù)據(jù)庫。
韓 楠 女,(1984—),博士,副教授。主要研究方向:時空大數(shù)據(jù)、軌跡預測。
張 桃 男,(1990—),碩士。主要研究方向:數(shù)據(jù)挖掘、人工智能。
蔡宏果 男,(1978—),博士,副教授。主要研究方向:機器學習、數(shù)據(jù)挖掘。
基金項目:國家自然科學基金(62272066);四川省科技計劃(2021JDJQ0021,2022YFG0186,2022NSFSC0511,2023YFG0027);教育部人文社會科學研究規(guī)劃基金(22YJAZH088);宜賓市引進高層次人才項目(2022YG02);成都市“揭榜掛帥”科技項目(2022 -JB00 -00002 -GX,2021 -JB00-00025-GX);成都市技術創(chuàng)新研發(fā)項目(重點項目)(2024-YF08-00029-GX);成都市區(qū)域科技創(chuàng)新合作項目(2023-YF11-00020-HZ);中國電子科技集團公司第五十四研究所高校合作課題(SKX212010057);成都海關科研項目資助(2022CK008)
