基于合并子圖的雙通道跨網絡用戶身份識別
2024-08-23 00:00:00周小涵賈鵬楊頻寇蔣恒劉鑫哲
四川大學學報(自然科學版) 2024年4期

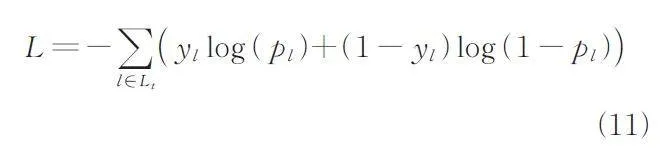
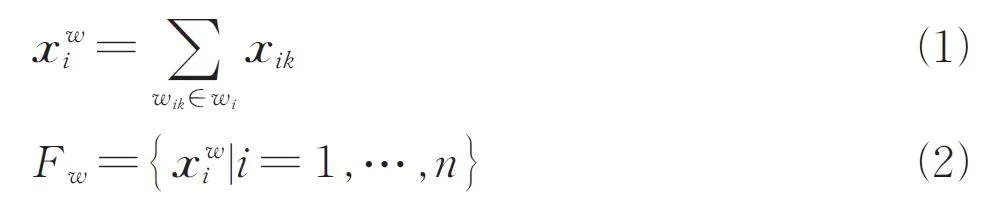
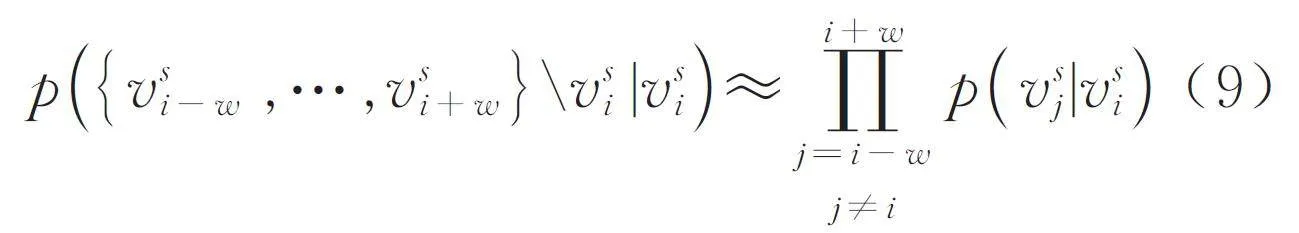

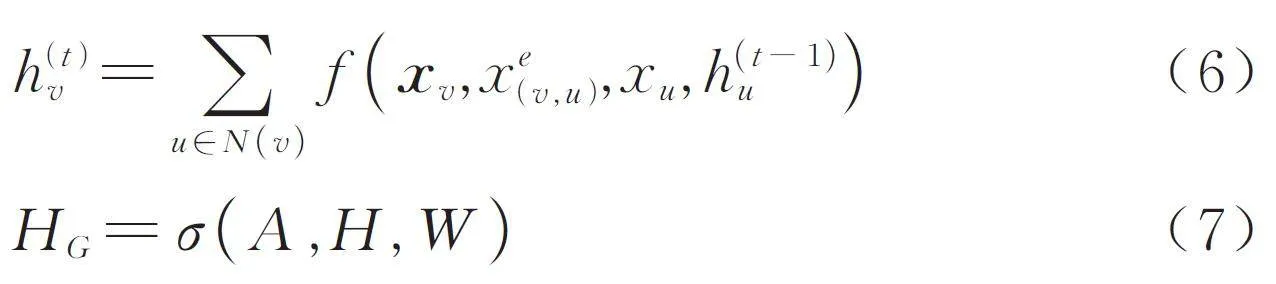

摘要: 跨社交網絡的用戶身份識別(UIL)的本質是通過各種方法發現跨社交平臺上的同一用戶或者實體. 現有方法的最新思路主要是對網絡中節點的各種結構或屬性特征進行聚合,然后構建相應的深度學習模型,學習相同用戶在不同網絡中特征的相似性,以此來實現不同網絡中相同用戶的對齊. 但是大多數方法較少考慮用戶的屬性信息或者是只用單一方法來處理不同類型的屬性特征,這樣處理的后果就是不能完美捕獲到屬性文本中的有效特征. 此外,現有的方法是對2 個網絡分別在各自的嵌入空間進行學習然后映射到同一個公共空間,也就只能學習到各自網絡的信息. 本文提出了一個新的方法,即基于合并子圖的雙通道跨網絡用戶身份識別(TCUIL). 為了解決獲取節點特征單一性問題,提出了多維特征提取方法實現了針對不同特征采用不同方法進行處理. 為了解決2 個網絡嵌入空間互不相交的問題,提出了圖合并方法實現了2 個網絡中信息的交互. 此外,為了能學習到2 個網絡的多維度信息,設計了雙通道網絡結構實現了對網絡拓撲結構、屬性特征、節點間關系特征的有效學習. 通過在2個真實數據集上的大量實驗,證明了本文方法優于現有最先進的對齊方法. 我們在2 個真實數據集(社交網絡和合著網絡)上進行了大量實驗,在F1 方面社交網絡至少提高了44. 32%,合著網絡至少提高了25. 04%.
關鍵詞: 社交網絡; 用戶身份識別; 合并子圖; 圖神經網絡
中圖分類號: TP391. 1 文獻標志碼: A DOI: 10. 19907/j. 0490-6756. 2024. 040001
1 引言
隨著在線社交網絡平臺(Online Social Network,OSN)的日益普及,各種各樣的社交網絡平臺應運而生,如微博、豆瓣、騰訊、Facebook、Twitter和LinkedIn 等. 這些平臺迅速融入并在一定程度上豐富了人們的生活. 不同社交媒體平臺的內容風格迥異,用戶為滿足不同的需求,會同時使用多個社交媒體平臺. 每個平臺只有很小一部分用戶僅使用該平臺. 而跨社交網絡用戶身份識別的本質在于通過分析多個虛擬賬號的交互模式、行為模式和偏好等,推斷出背后的實體用戶. 該問題的研究對網絡安全、推薦系統和數據挖掘等領域都有著重要意義[1].
早期的研究通過利用用戶配置文件屬性來解決UIL 問題,包括用戶簡介[2-4](例如:用戶名,頭像,地理位置)和用戶生成的內容[5- 7](例如:推文,帖子). 許多基于屬性的方法大都是轉化為對特定字符串的相似性比較的問題. 然而,對于像用戶名或者地理位置這類屬性,它們都極短,由幾個詞組成. 而用戶的生成內容則通常是長文本,包含多個段落,語句間具有強相關性. 因此,在進行特征處理時,不區分內容長度而采用單一的方法既不能覆蓋整個不同屬性的特征集,也不能捕獲屬性文本中的高級語義特征. 直觀地說,每個用戶的社交鄰居只能涉及來自同一社交網絡的用戶. 因此大多數方法都是在2 個網絡分別學習,然后通過投影將2 個網絡映射到1 個公共相關空間或者直接將一個網絡映射到另一個網絡[8-10]. 但是這類方法存在一個問題:2 個網絡分別在各自的嵌入空間進行特征學習,那么所提取的用戶對特征是相互獨立毫無交集的. 一方面,這可能會導致一對錨節點的嵌入表示差別很大;另一方面,如果對2 個網絡中的信息分別進行學習,這可能忽略跨網絡的許多有價值的補充信息.
為了解決上述問題,本文提出了基于合并子圖的雙通道跨網絡用戶身份識別方法TCUIL. 本文的主要研究貢獻總結如下.
(1) 提出新的監督UIL 方法TCUIL,該方法由多維特征提取、子圖合并、雙通道圖網絡結構組成. 與現有的方法不同,TCUIL 將跨網絡的鏈路預測轉化為單個網絡內的鏈路預測問題.
(2) TCUIL 根據屬性信息的類型采用不同的嵌入方法,以此得到每個屬性更有效的嵌入表示.
(3) 提出子圖合并的方法,將2 個目標節點及各自鄰居節點提取至1 個圖中,可以同時捕獲目標節點對在2 個網絡的交互關系.
(4) 設計雙通道網絡結構. 具體來說,使用圖卷積神經網絡GCN 提取網絡拓撲結構以及傳統的屬性特征,同時,使用DeepWalk 提取節點間的關系特征. 2 個通道并行執行,從多個維度學習合并子圖的節點表示.
(5) 進行了充分實驗,從準確率、召回率等維度與CENALP、MAUIL 等方法進行了比較,驗證了本文方法的有效性.
2 相關工作
跨在線社交網絡的用戶身份鏈接是社交媒體中的新興任務,近年來受到越來越多的關注. 跨社交網絡用戶身份識別也被稱為用戶身份關聯、錨鏈路預測和實體對齊等,按照傳統的方法對數據挖掘和機器學習模型進行分類,我們將現有的模型歸納為3 組:監督模型、半監督模型和無監督模型[11].
基于監督學習的用戶對齊方法需要將預先匹配的用戶對作為標記數據,然后使用訓練好的模型對待匹配的候選用戶對進行預測[12]. 大多數文獻涉及監督學習的方法,其目的是學習排名模型或二進制分類器來識別用戶身份. 由于獲取帶標簽的匹配用戶身份對的成本較高,因此提出了一些無監督模型來解決UIL 問題. 目前,基于無監督學習的方法來實現用戶身份識別主要有2 種模式:一種是設計一組規則,對具有較強辨識度的屬性特征自動獲取標記數據,然后進行有監督的對齊;另一種模式就是通過無監督的表示學習抽取候選用戶特征,然后利用對齊算法識別匹配用戶. 無監督方法不依賴標記數據,但是無監督方法通常比有監督方法性能差. 于是,一些半監督方法充分利用少量標記樣本和大量未標記數據被用來解決UIL 問題.
無論上述哪種方法,其核心大都是需要通過一定的方式提取用戶不同維度的特征,然后基于特征訓練相應的模型實現鏈路預測. 在特征提取方面,現有方法主要關注用戶的屬性和結構特征,對節點間關系特征關注較少,而用戶關系中含的虛假信息量更少. 同時,采取單一方法提取特征既不能涵蓋整個不同屬性特征集,也不能捕獲屬性文本中的高級語義特征. 在模型方面,近年來,部分研究將圖神經網絡應用于用戶對齊任務,現有的GNN 模型大多局限于局部結構信息,然而部分研究多直接將GNN 模型“ 移植”到無權跨社交網絡用戶對齊任務中,未結合現實需求做出有針對性的改進與調整. 這些問題導致跨網絡用戶對齊的效果還有很大的提升空間,因此,如何進一步挖掘能夠反應用戶相似性的特征,進一步構造能夠更加敏銳地捕獲到相似性特征的模型,是跨網絡對齊領域需要持續進行研究的內容.
3 TCUIL 方法
3. 1 概述
本節主要介紹方法TCUIL 的詳細信息. 如圖1 所示,該模型有3 個組成部分:多維特征提取、圖合并和雙通道網絡結構. 結合用戶屬性和網絡結構信息的應用是近年來的研究熱點. 而這些信息從內容上來看差異性很大,所以針對不同的特征,用不同的方法進行提取和處理. 多維特征提取則用于融合2 個網絡中所有節點的屬性信息和拓撲結構,以此得到信息量更為豐富的節點低維嵌入.
圖合并則是基于將2 個網絡的嵌入空間交互在一起的思想而提出的. 基于合并后的子圖進行特征學習,不僅能夠實現對網絡中相鄰節點特征的學習,還能實現對另外一個網絡中間接相鄰節點特征的學習. 因此,這就將網絡間鏈路預測轉換為網絡內兩節點的鏈路預測問題.
雙通道網絡結構則是對由每個節點對構建的新網絡中的特征進行學習. 為了能夠使用用戶的多個維度的信息進行用戶身份識別,本文設計了雙通道結構,一方面使用多層圖卷積神經網絡GCN[13]挖掘網絡拓撲結構并提取傳統的屬性特征,另一方面使用深度游走(DeepWalk)[14]構建頂點序列并從中學習節點間的關系特征. 雙通道并行學習,將輸出特征進行拼接,然后送入Transformer[15]得到節點最終特征表示. 最后通過前饋神經網絡實現二分類任務.
為了實現用戶身份鏈接,給定任意節點對(vs,vt),節點分別來自2 個不同的網絡Gs 和Gt. 我們預測該節點對是否屬于現實世界同一用戶通過觀察前饋神經網絡最后輸出的二分類預測值,如果預測值為True,則表明vs 和vt 屬于同一用戶,反之,則屬于不同用戶. 圖1 展示了TCUIL 的概述.
3. 2 多維特征提取
綜合考慮用戶屬性信息和網絡拓撲結構來實現跨社交網絡的用戶身份鏈接,包含信息更為豐富,可以提高用戶身份識別的性能[16]. 用戶屬性信息根據文本長短劃分為詞級別屬性嵌入和文本級別屬性嵌入.
3. 2. 1 詞級別屬性嵌入
短文本主要由用戶配置信息組成,包括用戶名和位置信息等屬性. 在大多數情況下,1 個用戶在1 個社交網絡中只擁有1個賬戶,該賬戶由唯一的用戶名標識,而同一用戶在不同的社交網絡中的多個賬戶通常是相同或相似的用戶名. 本節采用Word2vec[17]方法來捕獲用戶屬性信息的詞級別特征.
用戶vi 在社交網絡中的詞級別屬性文本表示為awi. 在我們選取的這些社交平臺上,主要是以中文和英文為主,對中英文分別使用jieba 和NLTK分詞工具,將屬性awi劃分為有m 個單詞的序列w wi = w wi1, w wi2,…,w wik,…, w wim,其中w wik 是awi中第k 個單詞. 使用用戶名屬性來對上述表達進行解釋. 假設網絡中某用戶的用戶名為awi=\"ThumbPeak 拇指山\",它可以被標記為如下所示的單詞序列,其后跟著的是單詞的計數數字:w wi =\"ThumbPeak\":1, \"拇指\":1,\"山\":1, others:0. 所有詞級別屬性信息構成1 個詞匯表,每個單詞在詞匯表中的ID 唯一.
我們將具有n 個用戶的社交網絡中的詞級別屬性集合表示為Aw = { aw1,aw2,…,awi,…,awn }. 每1個屬性awi的w wi 都可以看作1 個用于深度學習的詞級別文檔,則共有n 個詞級別文檔構成訓練時的語料庫. 本文計劃使用CBOW 語言模型訓練語料庫中的詞向量. 在訓練過程中,文檔w wi 中的任意w wik 的詞向量都是dw 維的向量,記為xik ∈ Rdw × 1. 用戶vi 的詞級別屬性集的特征向量x wi 是通過對文檔wi 中的所有詞的詞向量求和得到,將所有用戶的詞級嵌入向量構造為詞級特征矩陣Fw.
3. 2. 2 文本級別屬性嵌入
文本級屬性主要指用戶生成內容UGC,如用戶發布的帖子、關注的電影信息等. 我們認為同一用戶在不同社交網絡平臺上關注的內容和發布評論的語言風格是相似的. 這里我們對長文本使用長短期記憶網絡(LSTM)[18]進行嵌入學習.
用戶vi 在社交網絡中的文本級別屬性文本表示為atei ,用戶的每個行為信息作為1 個句子,該用戶發布的所有內容聚合在一起構成相應的長文本屬性. 屬性atei 的每個句子都可以劃分為有m 個單詞的序列w tei = w tei1, w tei2,…,w teik,…, w teim,其中w teik 表示句子中的第k個單詞. 因此可以得到網絡中所有用戶的文本級別屬性集合Ate ={ ate1,ate2,…,atei ,…,aten },文本級別屬性atei 中的每個句子對應的序列w tei 被視為文本級別文檔. 同樣使用CBOW 語言模型來訓練語料庫中的詞向量,文檔w tei 中的任意wik 的詞向量都是dte 維的向量. 句向量則通過將該句子的所有詞向量累加得到,記為xik ∈ Rdte × 1.
由于文本級別屬性是用戶生成內容,每個文本的句子長短不一致,文本級別文檔中詞語總數也不一致. 因此文本級屬性經過詞嵌入轉換成低維向量后需要進行補齊或截斷操作. 考慮到過長的文本反而會給LSTM 帶來超長訓練時間的問題,我們設置每個用戶文本級別屬性的最大句子數Wmax 為200,然后將文本句子總數低于Wmax 的嵌入用0 補齊,高于Wmax 的則截斷. 最終得到用戶vi 的初始文本級別屬性特征F tei0 ∈ RWmax × dte 作為LSTM 的輸入. LSTM 會返回output 和hidden,其中output 包含輸入序列中每個句子的輸出向量,最后1 個句子的輸出向量x tei 代表用戶vi 的文本語義向量;hidden 是1 個元組,元組中的第1 個元素代表每個詞的隱藏層向量,第2 個元素代表所需遺忘的元素. 因此取output 的最后1 個輸出向量構成文本級別屬性集合的特征矩陣Fte.
Fte ={x tei |i = 1,…,n} (3)
3. 2. 3 拓撲結構嵌入
中心性(Centrality)是社交網絡分析(Social Network Analysis, SNA)中的重要概念,可以幫助我們理解節點(即網絡中的個體或群體)在網絡中的位置和影響力,通常用數字或度量來表示,被稱為中心度[19]. 對于節點的中心性而言,有表征節點局部結構特征的局部中心性,有表征節點全局結構特征的全局中心性,還有一些其他中心性,我們從不同類型的中心性指標中,分別選取了一些知名的中心性方法,捕獲用戶在社交網絡中的結構特征. 本文采用了8 種判定中心性的度量指標來捕獲整個網絡的結構性特征.具體包括以下8 個指標:度中心性、特征向量中心性、介數中心性、緊密中心性、PageRank、K-core、聚類系數、局部中心性. 節點vi 的結構向量是上述8個度量指標的拼接. 將所有用戶的結構嵌入向量拼接起來構成結構特征矩陣Fs.
Fs ={x si |i = 1,…,n} (4)
3. 2. 4 用戶中間表示
通過上述對社交網絡中用戶的多維特征進行建模,分別得到描述用戶詳細信息的屬性特征和代表用戶社交關系的結構特征矩陣,并將3 個特征矩陣串聯起來構建用戶中間特征矩陣.
F = Fw ∥ Fte ∥ Fs (5)
3. 3 圖合并
通過上一部分,將屬性嵌入與結構嵌入進行拼接即可得到帶有節點特征矩陣F 的網絡. 接著是圖合并,由2 部分組成:子圖提取和子圖合并. 2個節點之間的鏈接是否存在,可以通過以節點為中心的圖拓撲來確定. 通常,當涉及到更多拓撲信息時,我們可以獲得更好的性能. 然而在實際問題中,1 個網絡中的節點可能非常多,每次預測如果都考慮整個圖,會帶來更多的計算成本和內存消耗[20]. 為了在計算成本和預測性能之間尋求平衡,我們對2 個目標節點分別在各自網絡中提取了khop子圖來學習特征和預測潛在鏈接的存在[21]. 與此同時,一般的跨網絡鏈路預測方法都是將2 個網絡的高維數據空間通過某種形式的映射函數表示成低維連續的向量空間,然后基于它們的向量表示學習相似度評分函數去匹配實體. 在整個過程中,最明顯的缺陷就是2 個網絡都只能學習到該網絡本身的信息. 于是,我們提出子圖合并的方法,通過預先對齊的節點對將2 個子圖合并為1 個網絡,這就轉換為在1 個網絡中預測用戶對齊的問題. 更重要的是,在后續圖卷積的過程中,基于合并后的子圖進行卷積,不僅能夠實現對網絡中相鄰節點特征的聚合,還能實現對另外1 個網絡中間接相鄰節點特征的聚合.
3. 3. 1 子圖提取
具體做法如下:給定1 個節點對(vs, vt),根據節點id 分別找到各自對應所在的網絡. 以節點vs 為例,首先提取1 跳鄰域. 給定網絡Gs 和列表NodeList 即可得到鄰域,其中,NodeList 是存有要找尋1 跳鄰域的節點id 的列表,初始列表只有目標節點id,即NodeList=[vs]. 經過1 輪后,將找到的與vs 直接相連的節點集N_neighbor 加入至列表NodeList 中. 以此類推,如果想要得到目標節點的k-hop 子圖,將上述過程執行k 次即可得到該子圖所包含的所有節點. 需要注意的是,每輪更新節點集合NodeList 后都要進行去重操作. 根據子圖包含的全部節點就可從原始圖Gs 中誘導出節點vs 的子圖Sub_Gs ( v ),同時,子圖中節點的屬性表示和原始圖共享. 子圖提取的總體過程如算法1 所示.
3. 3. 2 子圖合并
該方法的具體做法如下:通過第3. 3. 1 節的處理,我們已經得到由1 個節點對(vs, vt)所提取的2 個k-hop 子圖. 首先,對2 個子網絡Sub_Gs 和Sub_Gt 的節點集和邊集進行并集操作,即可得到由2 個互不相交的子圖構成的合并圖Gm. Gm 中節點的屬性表示和2 個原始圖共享. 然后依次遍歷少量已知的預先對齊種子集S. 對于每個種子節點對(vs1, vt1),我們首先將2 個節點的特征表示做平均,并將該值賦給節點vs1,替換其原有特征. 其次,找到與vt1 直接相連的鄰域節點集合N_neighbor,然后依次增加由N_neighbor 中所有節點和vs1 組成的邊,最后刪除節點vt1. 重復此操作,直到將種子集S 中所有節點對遍歷結束,最后得到的網絡就是將2 個子圖合并后的結果. 子圖合并的偽代碼如算法2 所示.
3. 4 雙通道網絡結構
通過上述多維特征提取和圖合并,已經得到由1 個節點對(vs, vt)所誘發的合并子圖,接下來就需要學習該圖所有節點的特征表示來實現鏈路預測功能. 隨著圖結構變得越來越普遍、信息變得越來越豐富,圖神經網絡(GNN)已經成為許多重要應用的強大工具[22]. 本文采用的圖卷積網絡GGN通過聚合來自其鄰域的特征信息來封裝每個節點的隱藏表示,它能直接對圖的拓撲結構和頂點的屬性信息進行學習. 與此同時,TCUIL 采用Deep?Walk 對網絡中節點的關系特征進行并行學習.DeepWalk 基于隨機游走策略得到一系列節點序列,每條序列包含目標節點的1 跳或2 跳鄰域節點. 基于此,DeepWalk 能學習到鄰域間甚至鄰域的鄰域間的關聯. GCN 與DeepWalk 雙通道互相補充提取到用戶的多維度特征. 基于GNNs 的模型難以解決長期依賴問題,縮放GNN 的深度或寬度不足以擴大感受野,GNNs 過深或過寬反而會導致梯度消失和過度平滑問題[23],我們在對2 種表征方法進行拼接的基礎上提出使用基于Transformer的自我關注來學習長距離的成對關系.
GCN 是一種直接處理圖結構數據的神經網絡模型,它們將1 個圖作為輸入,并為每個節點輸出1個標簽. GCN 基于信息擴散機制,通過與鄰域節點周期性交換信息來更新節點表示,直到達到穩定均衡. 節點的隱藏狀態由式(6)可以得到,其中f是將輸入投影到d 維空間的轉移函數,h( t )v 表示節點的狀態向量,xv 表示節點的特征向量,節點的初始特征向量由特征矩陣F 得到,xe( v,u ) 表示邊的特征矩陣. 每個GCN 編碼器都以當前層節點表示的隱藏狀態作為輸入,計算新的節點表示,如式(7)所示. 其中A 是表示節點間連通性的鄰接矩陣,H 是當前節點表示,H ( 0 ) = F,W 是學習到的參數,σ 為激活函數.
給定屬性社交網絡Gs =(Vs,Es,As ),DeepWalk采用隨機游走的方式隨機選擇起點vsi,然后從與節點vsi存在連接關系的所有節點中以相同概率選擇下一跳節點,由此得到長度為L 的節點序列. 可以同時設置多個游走器并行執行. 接著,DeepWalk利用與詞嵌入skip-gram 模型相同的思路,將隨機游走序列與文本中的詞進行類比,實現對網絡節點的表示學習. 在長度為L 的隨機游走序列{ vs1,vs2 ,. . . ,vsi,. . . ,vsL } 中,DeepWalk 使用節點vsi預測其上下文節點來學習其嵌入,其目標是最小化損失函數,如式(8)所示.
-log p ({vsi- w ,…,vsi+ w }\vsi|vsi) (8)
其中,{ vsi- w ,. . . ,vsi+ w } \vsi是節點vsi在滑動窗口為w 的范圍內的上下文節點所構成的序列,不包括vsi本身. p ( { vsi- w ,. . . ,vsi+ w } \vsi|vsi) 表示節點vsi出現的情況下序列中其他節點出現的概率. 通過使用獨立性假設,條件概率p ( { vsi- w ,. . . ,vsi+ w } \vsi|vsi)近似為式(9)形式.
通過借助隨機梯度下降算法更新節點的向量表示,得到網絡中所有節點的嵌入表示HD. 然后將其與GCNs 得到的嵌入表示HG 做拼接處理得到H. H 是整個合并子圖的嵌入,將其作為Transformer的輸入.
H = HG ∥ HD (10)
然后,我們將鏈路預測任務視為二元分類問題,并通過最小化所有潛在鏈路的交叉熵損失來訓練神經網絡,如式(11)所示.
其中,Lt 是要預測的鏈接集合;pl 是鏈接l 在網絡中存在的概率;yl ∈ ( 0,1 ) 是目標鏈接的標簽,表示該鏈路是否存在.
4 實驗
本節主要介紹實驗所使用的數據集、實驗設計以及實驗結果與分析.
4. 1 數據集
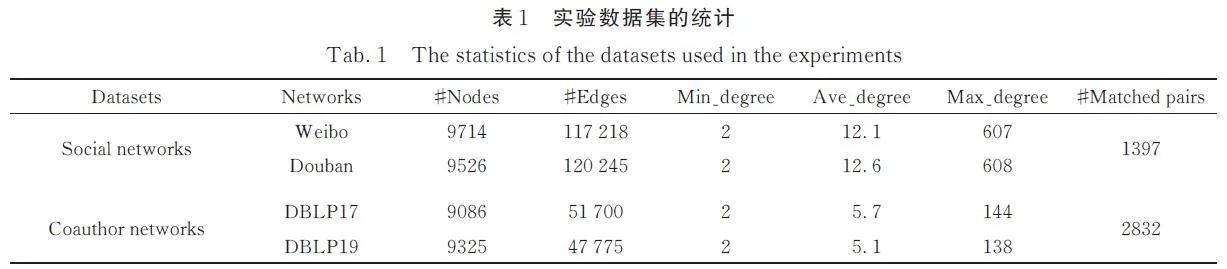
為了更好地評估TCUIL 模型的性能,本文在2 個數據集上進行實驗,包括2 個社交網絡和2 個學術合著網絡,均由Chen 等[8]提供.
社交網絡:該數據集被稱為微博-豆瓣(WD),指的是中國2 個流行的社交網絡平臺:新浪微博和豆瓣. 該社交網絡數據集包含9714 個微博用戶以及9526 個豆瓣用戶,每個用戶都包含了用戶名、地理位置和用戶生成內容等信息.
合著網絡:DBLP 是計算機領域內以作者為核心的英文文獻數據庫系統,并且公開免費. 本文所使用的數據集由Chen 等[10]提取的2 個不同時期的DBLP 數據庫中的部分數據構成. WD 和DBLPs數據集的具體信息如表1 所示.
4. 2 實驗設計
4. 2. 1 基線方法
在這項工作中,我們選擇以下基線方法來評估本文模型的性能.
(1) PALE[9]:一種基于嵌入的技術,它通過最大化邊緣頂點的共現似然來學習節點嵌入,然后應用線性或多層感知器(MLP)作為映射函數.PALE 是一個基于監督學習的UIL 模型.
(2) DeepLink[10]:一種新穎的基于半監督學習方式的端到端方法,DeepLink 對網絡節點進行采樣,并學習將網絡節點編碼為矢量表示,以捕獲局部和全局網絡結構,進一步通過深度神經網絡對齊錨節點.
(3) MAUIL[8]:一種新穎的半監督模型,可以實現對任意2 個社交網絡進行用戶身份識別. 首先使用無監督方法表達不同類型的屬性特征,然后基于正則規范化相關分析(RCCA)的線性投影將社會網絡投射到用于用戶身份鏈接的公共關聯空間中.
(4) CENALP[24]:一個聯合鏈接預測和網絡對齊的框架. CENALP 通過跨網絡帶偏隨機游走得到節點嵌入,然后基于節點相似性找尋最可靠的候選節點.
4. 2. 2 參數設置
本節概述了訓練TCUIL 模型參數,涉及屬性嵌入、圖合并和網絡結構設置.
(1) 在對屬性文本嵌入過程中,即便對不同類型的屬性采用不同的嵌入方法,所有特征的維度仍是相同的. 例如,dw = dte = 100.
(2) 在對2 個目標節點提取子圖過程中,提取鄰域的范圍是2 跳鄰域,即hop=2;在去除掉重復鄰域的情況下,每個節點在每跳鄰域上都最多采樣20 個鄰域節點.
(3) 在圖網絡結構中,我們使用了具有2 層卷積層的GCN,輸入維度為308,中間層維度為128,輸出維度為64. DeepWalk 的輸出維度也為64.Transformer 的詞嵌入維度為128,編碼層數為1.
4. 2. 3 研究問題
在這項工作中,我們解決了以下研究問題.
RQ1:與基準方法相比,TCUIL 的表現如何.與基線模型進行比較,驗證所提出的TCUIL 模型的總體表現性能的優越性.
RQ2:如何驗證TCUIL 中每個組件的有效性. 研究使用不同文本嵌入方法對TCUIL 性能的影響、采用合并和不合并2 種方式進行后續特征學習以此驗證基于合并子圖進行用戶對齊的有效性和研究等3 個TCUIL 變體以評估雙通道網絡結構的有效性.
4. 3 實驗結果與分析
4. 3. 1 RQ1:與以往工作的比較
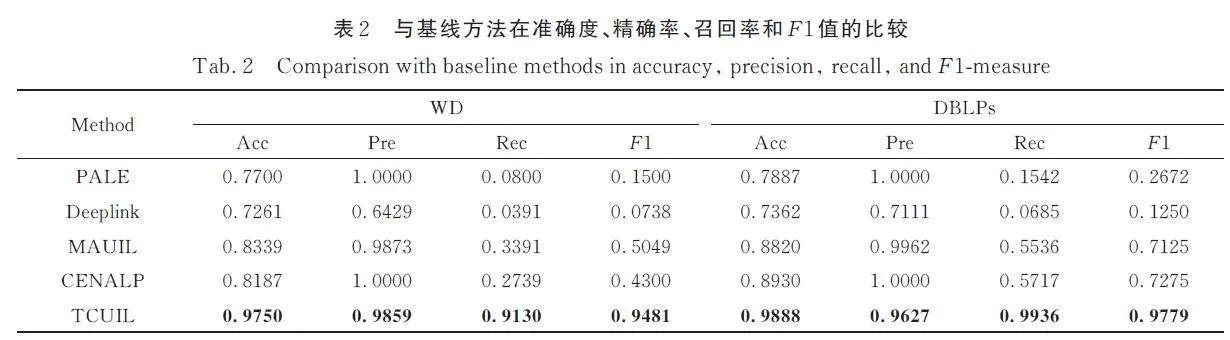
表2 顯示了我們的對齊模型與基線方法在2 個數據集上的總體結果. 總的來說,我們的模型在準確率、精確率、召回率和F1 值4 個分類評估指標上都優于所有基線模型(在WD 數據集,準確率至少提高了14. 11%,F1 值至少提高了44. 32%;在DBLSs 數據集,準確率至少提高了9. 58%,F1 值至少提高了25. 04%)
所有的基線方法根據訓練數據可以劃分為2類:一類是使用帶標簽數據訓練的監督學習執行UIL,包括PALE、TCUIL;一類是僅有一部分帶標簽數據的半監督學習方法,包括DeepLink、CENALP、MAUIL. 從表2 可以清楚地看出,數據集的質量會很大程度上影響模型的表現性能,所有模型在DBLPs 數據集上的表現都優于WD. 例如,PALE 在DBLPs 上的F1 值提高了11. 72%,Deeplink 提高了5. 12%,MAUIL 提高了20. 76%,CENALP 提高了29. 75%,TCUIL 提高了2. 98%.這主要是因為WD 真實社交網絡的數據結構完整性較低,無法為識別用戶身份提供有效線索. 首先是第1 類與TCUIL 模型同為監督學習方法的PALE,雖然它利用觀察到的錨鏈路作為監督信息,但是其在嵌入階段只捕獲了網絡的主要結構規律. 因此,我們模型在WD 和DBLPs 上關于F1值的表現分別比PALE 模型高出多達79. 81% 和71. 07%. 然后是第2 類半監督學習方法的實驗結果. DeepLink 模型采用深度神經網絡來對UIL 進行自動特征提取與表示,在整個對比實驗中表現最差,在WD 中F1 值僅有7. 38%. CENALP 雖然提出了跨圖的節點嵌入技術,但它僅是基于概率值在2 個網絡來回選取節點構成節點序列以此學習節點表示,而TCUIL 是通過已知的錨節點在2個網絡間建立連接,在F1 值上至少提高了25. 04%. 在對比的所有基線模型中,MAUIL 是整體性能相對最好的方法. 這是因為MAUIL 與我們的方法類似,它同時考慮到了社交網絡結構信息和社交賬戶文本屬性信息,涵蓋信息豐富. 但是其對文本嵌入和特征學習的方法與TCUIL 模型不同,我們模型在WD 上的F1 值提高了44. 32%,由此可看出我們提出的模型與基線方法相比,綜合考慮了用戶的結構、屬性和關系特征,有較好的表現.
4. 3. 2 RQ2:不同的文本嵌入方法
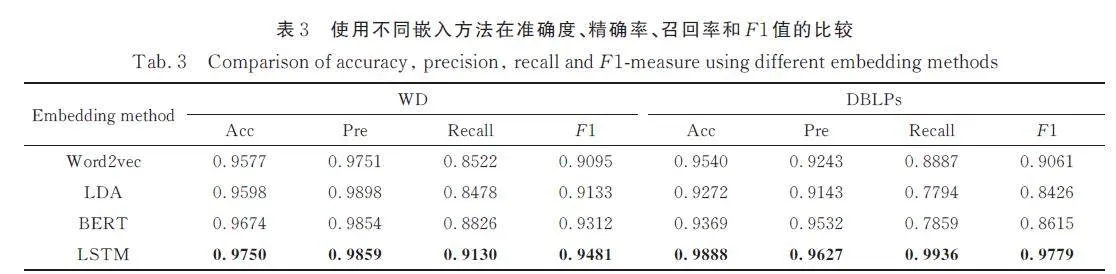
為了找出在我們提出的TCUIL 模型框架下,使用哪種長文本嵌入的模型達到的效果最好,我們進行了對比實驗. 表3 展示了使用不同方法處理長文本屬性信息對最終鏈路預測結果的影響. 這部分對4 種嵌入方法進行了比較. 首先是word2vec,它是最早的以詞語為基本處理單元的文本向量化方法. 在本次實驗中,首先得到屬性文本涵蓋的所有單詞的嵌入. 對于每個文本,將包含的單詞對應的詞嵌入相加之后計算平均值即作為該長文本的最終嵌入表示. 其次,主題模型LDA 是一種文檔-主題生成模型,在生成文檔時,LDA 模型首先根據一定概率選擇主題,然后從這個主題的詞匯分布中以一定概率選擇詞語. 然后是BERT 模型,其本質上是通過在海量語料庫上進行訓練,學習到了從語境中理解和生成文本的能力,從而用于為單詞學習好的特征表示. 對比試驗借助Simple Transformers庫,使用BERT 來實現文本向量化. 最后則是長短期記憶網絡LSTM,LSTM 是RNN 特殊的類型,可以學習長期依賴信息. 從表3 可以看出在4 個分類指標中,使用LSTM 對文本進行嵌入達到的效果最好. 在DBLPs 中,召回率相比另外3 種方法至少高出10. 49%,F1 值高出7. 18%. 因此,LSTM因其獨特的設計結構天然地適合處理序列數據.但用戶的屬性信息通常是變長序列數據,最直觀的方式是使用文本截斷方法使序列長度相等,本文則通過截斷的方式固定序列長度在200.
4. 3. 3 RQ3:子圖合并
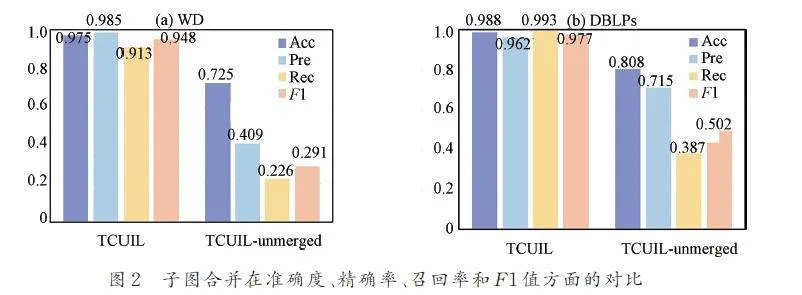
為了驗證TCUIL 模型所提出的子圖合并的有效性,進行了對比實驗.TCUIL-unmerged 表示對提取的2 個子圖不進行合并操作,其具體實現過程如下:針對所提取的每個子圖都單獨送進設計的雙通道網絡結構中進行特征學習,得到嵌入表示后再分別提取目標節點對的輸出向量進行拼接操作,最后得到最終表示進行鏈路預測. 從圖2 的柱狀圖明顯看出,TCUIL相比于TCUIL-unmerged 的表現效果更好,在WD和DBLPs 上精確率分別提高了57. 65% 和24. 73%,在F1 值上更是提升了65. 68% 和47. 51%. 這主要得益于子圖合并通過錨鏈路將2個網絡緊密聯系起來,不僅能夠實現對網絡中相鄰節點特征的學習,還能實現對另外一個網絡中間接相鄰節點特征的學習.
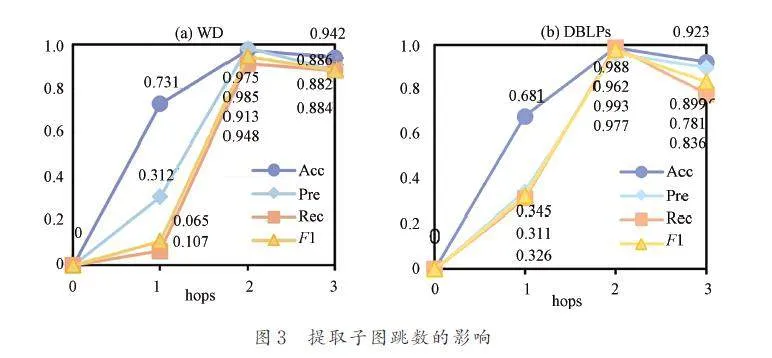
4. 3. 4 RQ4:子圖參數
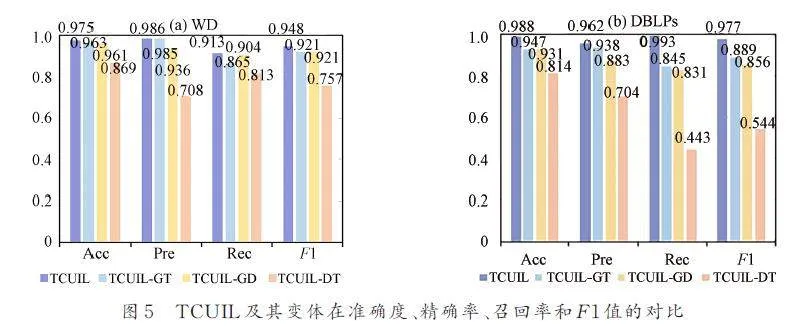
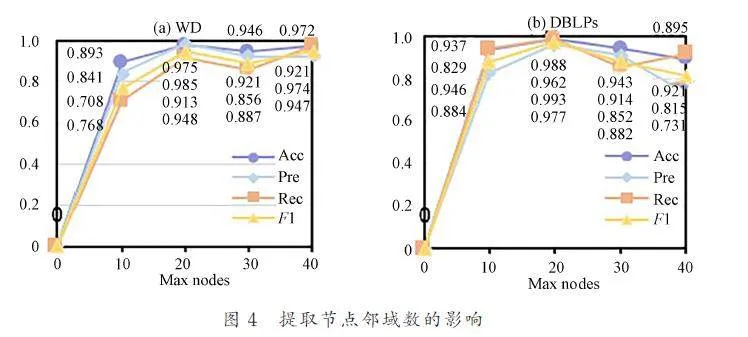
為了有效地學習良好的高階特征,我們似乎需要1 個非常大的跳數,以便提取的子圖包含整個網絡的絕大部分,這將導致大多數實際網絡無法承受時間和內存消耗. 圖3和圖4 則是對所提取子圖的跳數以及對每個節點截取的鄰域數進行的對比實驗,從圖3 可知,預測結果的正確性并不是隨著跳數的增加而增加,當跳數大于等于2 后整體性能通常不增反減,這主要因為最有用的信息通常在局部結構中,于是我們使用2 跳子圖來預測鏈路是否存在. 同時在提取子圖時并非選取所有的2 跳鄰域節點,由圖4 可看到當截取的鄰域數增加到30 時,2 個數據集的模型性能都有所下降. 繼續增加到40 后,DBLPs 上的精確率更是降低了23. 14%,即便在WD 上的表現可與鄰域數為20 時抗衡,但是從時間和內存消耗方面考慮,我們仍舊選擇20 作為截取鄰域節點的數量. 由此可以看出,當子圖過大時反而會因為一些無用信息帶來干擾,使模型性能降低.4. 3. 5 RQ5:雙通道網絡結構 在得到合并子圖中每個節點的低維嵌入后,需要通過特定的網絡結構來對節點特征進行學習,進而提取所要預測節點對的嵌入來進行二分類的鏈路預測. 實驗研究了3 個變體主要用于驗證本文設計的雙通道網絡結構的有效性. 其中,TCUIL-GT 表示只使用GCN 和Transformer 學習節點特征,TCUIL-GD 表示保留GCN 和DeepWalk 并刪除Transformer 部分,TCUIL-DT 表示保留DeepWalk 和Transformer,刪除GCN 部分. 從圖5 柱狀圖可以看出,我們提出的雙通道網絡結構在4 個分類評估指標上均是表現最好的. 在DBLPs 數據集上關于召回率的表現比3 個變體高出至少14. 8%,這主要是因為該網絡結構既考慮了目標節點的鄰域對其的影響,又考慮了目標節點的鄰域間的相互影響.
5 結論
本文提出了基于合并子圖的雙通道跨網絡用戶身份識別方法TCUIL,其目標是在2 個帶屬性的網絡中尋找潛在的同一用戶身份. TCUIL 模型建立在多維屬性嵌入的基礎上,其核心是得到包含用戶結構特征和屬性特征的嵌入. 具體來說,用戶初始嵌入由2 部分拼接而成:一是根據屬性文本的類型使用不同的文本嵌入方法得到的屬性嵌入;二是由多個中心性方法提取得到的結構嵌入.最后通過設計的雙通道網絡結構進行有效的表示學習,提升預測結果的準確性. 特別地,我們提出了子圖合并的方法,對于每個預測的節點對,將提取的2 個子圖通過已知錨鏈接進行合并,即可得到1 個同時包含2 個網絡部分節點的合并圖,使得基于1 個合并圖的表示學習即可同時實現對2 個網絡中節點特征的學習. 我們的實驗證明了本文模型在各方面的優越性. 進一步,本文提出的用戶身份識別方法在實際社交網絡分析、推薦系統或其他相關領域中都有著重要的實際價值.
參考文獻:
[1] Luan M M, Zhao T, Yang X H, et al. A survey ofcross social network user identification at home and abroad[J]. Journal of Qilu University of Technology,2020, 34: 55.[欒孟孟,趙濤,楊星華,等. 國內外跨社交網絡用戶身份識別綜述[J]. 齊魯工業大學學報, 2020, 34: 55.]
[2] Li Y, Peng Y, Zhang Z, et al. A deep dive into userdisplay names across social networks[J]. InformationSciences, 2018, 447: 186.
[3] Wu Z, Yu H, Liu S, et al. User identification acrossmultiple social networks based on information entropy[J]. Journal of Computer Applications, 2017,37: 2374.
[4] Chen H, XU Q, Huang R, et al. User identificationacross social networks based on user trajectory[J].Journal of Electronics amp; Information Technology,2018, 40: 2758.
[5] Kong X, Zhang J, Yu P S. Inferring anchor linksacross multiple heterogeneous social networks[C]//Proceedings of the 22nd ACM international conferenceon Information amp; Knowledge Management.New York: ACM, 2013: 179.
[6] Li Y, Zhang Z, Peng Y, et al. Matching user accountsbased on user generated content across socialnetworks[J]. Future Generation Computer Systems,2018, 83: 104.
[7] Nie Y, Jia Y, Li S, et al. Identifying users across socialnetworks based on dynamic core interests[J].Neurocomputing, 2016, 210: 107.
[8] Chen B, Chen X. MAUIL: Multilevel attribute em ?bedding for semisupervised user identity linkage[J].Information Sciences, 2022, 593: 527.
[9] Man T, Shen H, Liu S, et al. Predict anchor linksacross social networks via an embedding approach[C]// Proceedings of the Twenty-Eighth InternationalJoint Conference on Artificial Intelligence,IJCAI-16. New York: AAAI, 2016, 16: 1823.
[10] Zhou F, Liu L, Zhang K, et al. Deeplink: A deeplearning approach for user identity linkage[C]//IEEE INFOCOM 2018-IEEE conference on computercommunications. Honolulu, HI, USA:IEEE,2018: 1313.
[11] Shu K, Wang S, Tang J, et al. User identity linkageacross online social networks: A review[J]. ACMSigkdd Explorations Newsletter, 2017, 18: 5.
[12] Chen B Y, Chen X L. A survey on user alignmentacross social networks[J]. Journal of Xihua University(Natural Science Edition), 2021, 40: 11.
[13] Kipf T N, Welling M. Semi-supervised classificationwith graph convolutional networks[ EB/OL]. https://doi. org/10. 48550/arXiv. 1609. 02907.
[14] Perozzi B, Al-Rfou R, Skiena S. Deepwalk: Onlinelearning of social representations[C]//Proceedingsof the 20th ACM SIGKDD international conferenceon Knowledge discovery and data mining. New York:ACM, 2014: 701.
[15] Vaswani A, Shazeer N, Parmar N, et al. Attentionis all you need[J]. Advances in Neural InformationProcessing Systems, 2017, 30: 6000.
[16] Samad A, Qadir M, Nawaz I, et al. A comprehensivesurvey of link prediction techniques for social network[J]. EAI Endorsed Transactions on IndustrialNetworks and Intelligent Systems, 2020, 7: e3.
[17] Mikolov T, Chen K, Corrado G, et al. Efficient estimationof word representations in vector space[EB/OL]. https://doi. org/10. 48550/arXiv. 1301. 3781.
[18] Hochreiter S, Schmidhuber J. Long short-termmemory[J]. Neural Computation, 1997, 9: 1735.
[19] Opsahl T, Agneessens F, Skvoretz J. Node centralityin weighted networks: Generalizing degree andshortest paths[ J]. Social networks, 2010, 32: 245.
[20] Zhang M, Chen Y. Link prediction based on graphneural networks[J]. Advances in Neural InformationProcessing Systems, 2018, 31: 5171.
[21] Cai L, Li J, Wang J, et al. Line graph neural networksfor link prediction[J]. IEEE Transactions onPattern Analysis and Machine Intelligence, 2021,44: 5103.
[22] Wu Z, Pan S, Chen F, et al. A comprehensive surveyon graph neural networks[J]. IEEE Transactionson Neural Networks and Learning Systems, 2020,32: 4.
[23] Wu Z, Jain P, Wright M, et al. Representing longrangecontext for graph neural networks with globalattention[J]. Advances in Neural Information ProcessingSystems, 2021, 34: 13266.
[24] Du X, Yan J, Zha H. Joint link prediction and networkalignment via cross-graph embedding[C]//Proceedings of the Twenty-Eighth International JointConference on Artificial Intelligence, IJCAI-19. NewYork: AAAI, 2019: 2251.
(責任編輯: 伍少梅)
基金項目: 四川省科技廳重點研發項目(2021YFG0156)
