一種減少對威脅情報標注依賴的自動化IOC 抽取方法
2024-08-23 00:00:00余堅王俊峰陳熳熳方智陽
四川大學學報(自然科學版) 2024年4期
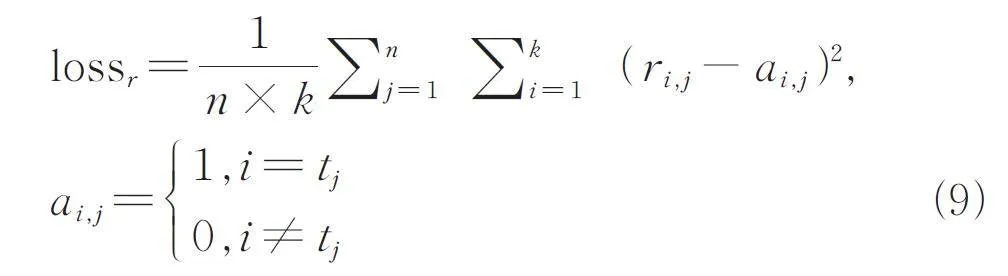
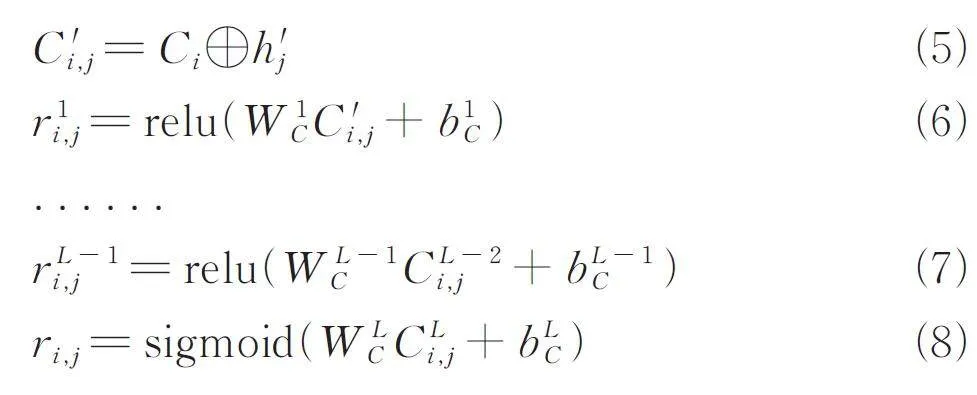
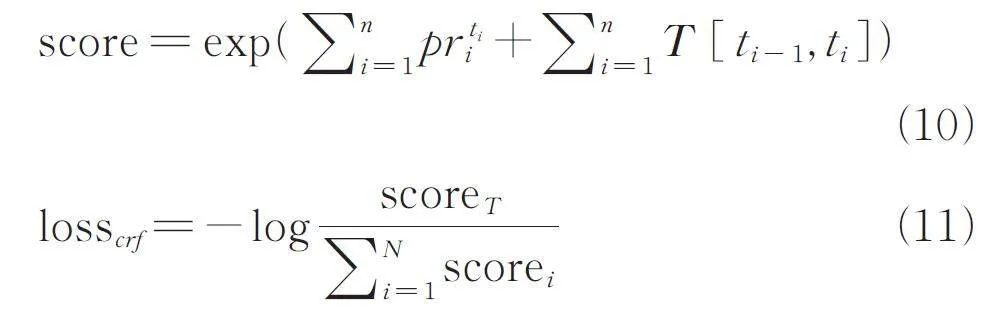


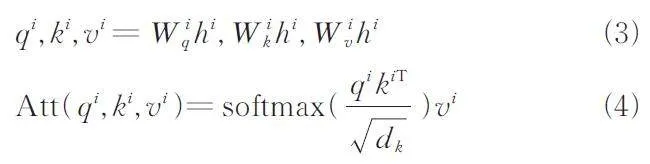

摘 要: 為了應對日益嚴峻的網絡威脅,需要對網絡攻擊做深入的分析. 網絡威脅指標(IOC)是網絡威脅情報(CTI)的重要組成部分,貫穿了網絡攻擊整個生命周期,準確描述了每個攻擊階段的關鍵信息(攻擊行為、威脅體等). 從CTI 中抽取IOC 可以幫助進行網絡防御、追蹤和對抗. 現有的IOC 抽取方法基于機器學習或深度學習方法取得了巨大進展,但是需要大量人工標注的CTI 進行訓練. 為了應對這一挑戰,本文提出了一種新穎的IOC 自動提取方法(L-AIE),僅使用少量標注的CTI 就能達到優秀的提取準確率. L-AIE 通過細粒度的分詞方式以從較少的CTI 中獲得足夠的信息,上下文層和組合層用于充分提取子詞級別的上下文信息. 在訓練階段,L-AIE 利用額外的關系層來擴大IOC 類別之間的差異. 實驗證明,L-AIE 對訓練數據量的依賴較小,而且提取效果也優于其他對比方法. L-AIE 僅使用其他模型10% 的數據訓練,就達到了87. 54% Macro F1 值,比其他方法高出20%. 當訓練數據量進一步減少時,L-AIE 受影響的程度也小于其他模型的一半.
關鍵詞: 網絡威脅; 網絡威脅情報; 威脅指標; 小樣本學習
中圖分類號: TP301. 6 文獻標志碼: A DOI: 10. 19907/j. 0490-6756. 2024. 040002
1 引言
隨著網絡的快速發展,網絡威脅逐漸反映出技術武器化、事件常態化和攻擊組織化的特點,越來越難以應對. 網絡威脅嚴重危害個人、公共網絡財產甚至國家網絡空間的安全[1]. 為了更好地應對網絡威脅,網絡安全公司和專家在網絡威脅情報(Cyber Threat Intelligence, CTI)[2]中分享他們對攻擊事件、惡意實體等的分析,所以各安全組織積極收集并廣泛共享了CTI. 開源CTI 主要使用威脅指標(Indicator Of Compromise, IOC)來描述網絡威脅實體和行為,越來越多地被分析和用于對抗攻擊. IOC 是網絡攻擊的關鍵指標,能夠闡明網絡攻擊的方法,描繪整個攻擊場景. 網絡防御者能夠根據IOC 深入了解快速演變的攻擊場景,及時識別攻擊對手的技戰術,并使用適當的手段進行反制[3]. IOC 也可以用于各種防御機制,不僅可以匹配現有的網絡實體,還可以識別相似的攻擊事件[4,5]. 起初,IOC 是人工進行抽取的,但安全網站的數量爆炸式增長. 在過去的5 年里,僅DarkReading 就發表了3 萬多篇CTI,ATamp;T 也發表了1 萬多篇. 人工處理已不再可行,因此研究者們提出了許多IOC 的自動抽取工具或系統. 基于規則的抽取方法首先被提出. 它使用預定義的規則(如正則表達式)來匹配IOC 實體,如開源工具IOCextractor、python-IOCextract 和集成經驗系統Twiti[6]、IOCMiner[7]等. 但該方法依賴于專家經驗,召回率相對較低,無法很好地處理IOC 的變體. 機器學習和深度學習越來越多地被用來改進或取代原有的方法. iACE[3]、iAES[8]和Chain?Smith[9]在規則匹配的基礎上,分別使用機器學習或深度學習,以判斷實體是否是IOC. 這種方法可以提高識別準確率,但并沒有擺脫規則的約束.Zhou 等[10]和Zhao 等[11]都將IOC 提取建模為序列標注問題. 這類方法需要領域專家對大量CTI 進行正確標注,才能達到出色的提取效果,需要耗費大量的時間和人力. 因此,當下迫切需要一種能夠在少量標注數據下就能表現出色的IOC 抽取方法.
本文提出了一種新穎的端到端IOC 抽取方法L-AIE(Automatical IOC Extraction with Less labeledCTI),其總體架構可以分為5 個部分:(1) 文本處理;(2) 上下文層;(3) 組合層;(4) 關系層;(5) CRF 解碼層. L-AIE 將單詞拆分為子詞作為句子的基本單元,這些子詞位于單詞和字符2 個粒度之間. L-AIE 隨后重新組合子詞的表征,以集中分散的信息,并確保輸出序列與原始句子長度相同.為了更好地處理IOC 樣本數量稀少的問題,L-AIE在訓練階段引入了關系區分網絡,以增大不同類別IOC 表征的區別減少同一類別之間的差異. 本文還提出了一種內存緩存方法來簡化關系層的訓練復雜性. 預測階段不需要關系層,所以不會降低方法的計算速度.
實驗表明,L-AIE 的Macro F1 結果為87. 54%,優于其他對比方法. L-AIE 的訓練數據量比其他方法少得多,大約是其他研究數據量的10%. 結果表明,L-AIE 受數據量大小的干擾較小,具有較強的魯棒性.
本文的貢獻主要有以下3 點:
(1) 本文提出了一個新穎的端到端模型LAIE用于IOC 抽取. 大量實驗證明L-AIE 在小樣本的情況下也具有優異的抽取效果.
(2) CTI 文本基于子詞粒度進行處理,隨后對其編碼進行重新組合,僅使用少量數據就能對未知IOC 進行更全面的表征.
(3) L-AIE 引入了關系層,以增強模型區分不同IOC 類別的能力,在訓練階段能從較少的數據中學習更多的特征.
2 相關工作
2. 1 安全系統
目前,有很多關于安全和隱私的研究,如表1所示. James 等[12]提出了一種通過集成CTI 來增強商業組織安全性的解決方案. Riesco 等[13]利用CTI 實現了自動化的動態風險控制. Kumar 等[14]為自動駕駛環境提供了安全保障. Husari 等[15]通過CTI 更好地了解了APT 攻擊的特征和行為. 對于物聯網領域,Kumar 等解決了工業[16]、汽車[17]和海事運輸系統[18]的安全問題.
上述研究涵蓋了物聯網、商業等多個領域,其中大多數都利用CTI 來實現其中的關鍵技術,保護各自領域的安全和隱私. 這突出表明了CTI 在各領域安全系統中的重要性. CTI 最關鍵的組成部分是IOC,高效地從CTI 中抽取IOC 可以將不同領域的安全系統的能力提升到更高的水平.
2. 2 IOC 抽取
IOC 抽取任務是從非結構化的CTI 文本中提取威脅指標. 首先對CTI 文本做預處理,進行分句和分詞;然后提取單詞特征;最后綜合上下文判斷單詞是否為IOC 實體. 目前方法大致可分為3 類:(1) 基于規則的方法;(2) 規則與機器學習或深度學習相結合的方法;(3) 基于端到端模型的方法.
典型的IOC 具有不同的形式特征,如IPv4 地址和URL 鏈接. 基于規則的方法通過總結IOC 的特征來制定匹配規則. 如簡單抽取工具:IOCextractor、python IOCextract. 另外,Twiti[6]、IOCMiner[7]是包含CTI 爬蟲、數據清洗和IOC 抽取等操作的集成系統. 但這類方法的效果取決于規則和專家知識的全面性. IOC 有3 個特點是規則難以解決的.(1) IOC 會被混淆,以防止讀者誤點,這使得IOC 的規則變得更加復雜,甚至沒有規則可言.表2 列舉了IPv4 地址的幾種常見混淆方法. 很難用單個規則實現對這些混淆形式的全面覆蓋.(2) 有些IOC 在格式上非常相似,比如域名和文件名,在復雜的場景下它們會被識別錯誤.(3) 一些規則匹配得到的IOC 并不是真陽性樣本. 例如,作者的電子郵件被用作聯系人,不應該被視為IOC.
一些研究引入了機器學習和深度學習來解決上述問題. iACE[3]、iAES[8]和ChainSmith[9]首先使用規則來選出可能包含IOC 的句子,然后應用機器學習或深度學習來確定待定IOC 的真實性. 然而,正則表達式的覆蓋率直接影響算法的結果. 同時,多步驟算法的每個步驟之間存在難以消除的誤差傳播.
基于端到端模型的方法表現十分出色.AITI[22]應用卷積網絡來識別句子是否包含IOC.TTPDrill[23]和ATHRNN[24]專注于從CTI 中提取戰術和技術,而Neuhaus 等[25]的方法專注于抽取CVE. 這些方法側重于個別IOC 類型,后續研究旨在同時提取多種IOC. Zhou 等[10]首次應用命名實體識別思想,使用長短期記憶網絡(LSTM)[26]加注意力機制進行IOC 抽取. Zhao 等[11]利用n-gram細化了表示粒度,增強了模型的特征提取能力.Wang 等[27]和Zhou 等[28]都使用BERT[29]進行深度詞嵌入表征,以更好地表示IOC. 他們都針對IOC的特點進行了一些細節的優化. 彭嘉毅等[30]在深度學習的基礎上采用主動抽樣策略擴大訓練樣本,一定程度減少了標注工作,不過仍需人為干預.
上述所有研究工作都明確了IOC 具有領域特性,并有針對性地加以解決. 然而,一個IOC 一般不會出現在兩次攻擊中,所以在兩篇描述不同攻擊的CTI 中基本不存在重復IOC. 這使得模型無法對未知IOC 進行表征,因此需要大量有標注的CTI 來增加模型的魯棒性. 如表3 所示,如果沒有大量標注的CTI,上述模型不可能達到如此優秀的效果. 但標注CTI 需要專家經驗,耗時且耗費人力[31].
2. 3 小樣本學習
減少模型對數據量的依賴,以減少標注工作,是如今IOC 抽取迫切需要解決的問題. 小樣本學習的核心是從少量的樣本中獲得足夠的特征信息[32,33]. 這對解決上述問題有很大的啟發.
許多小樣本學習方法都基于度量,側重于學習好的度量方式,而不是擬合大量參數. SiameseNetwork 重用特征提取模塊來比較兩個輸入的相似性,大大減少了模型參數的數量[34]. MatchingNetwork 將二元關系擴展為一對多,并為支持集和查詢集使用不同的編碼器[35]. 原型網絡會對每個類別計算出1 個原型表示[36]. 從多個樣本中提取原型比計算樣本對的相似性更準確. 但是相似度在某些場景中不適用,關系網絡使用簡單的網絡代替相似度計算公式,提高了通用性[37].小樣本學習改變了學習目標,在樣本類別較多但每種類別數量較少的場景中表現出色. 但小樣本學習訓練比較復雜,需要按類別對樣本進行分組,而且類別特征是從獨立樣本提取的. 而IOC是包含在CTI 中的,脫離上下文是沒有意義的. 此外,IOC 的類別很多,簡單地使用小樣本學習很容易導致過擬合. 小樣本學習的思想對IOC 抽取非常有啟發意義,但很難以目前的形式直接應用.
3 IOC 抽取方法(L-AIE)
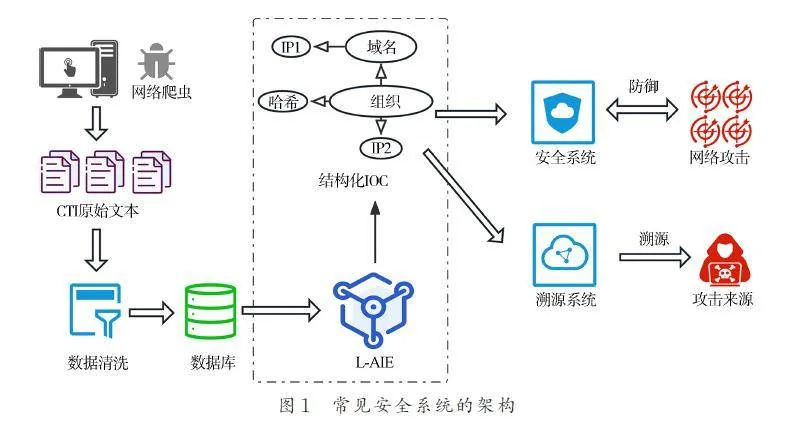
常見安全系統的架構如圖1 所示. 網絡爬蟲不斷地在網絡上爬取CTI,完成簡單的清理工作(如去重和清除HTML 標簽)后,CTI 被存儲在數據庫中. CTI 由L-AIE 處理,抽取其中的IOC,將其組織成結構化的信息,并在知識庫中存檔. 之后,安全系統可以利用知識庫的數據來對抗外部攻擊. 溯源系統還可以使用知識庫追蹤到攻擊來源. 因此,L-AIE 是最關鍵的步驟,其抽取的有效性決定了其他下游系統的能力上限.
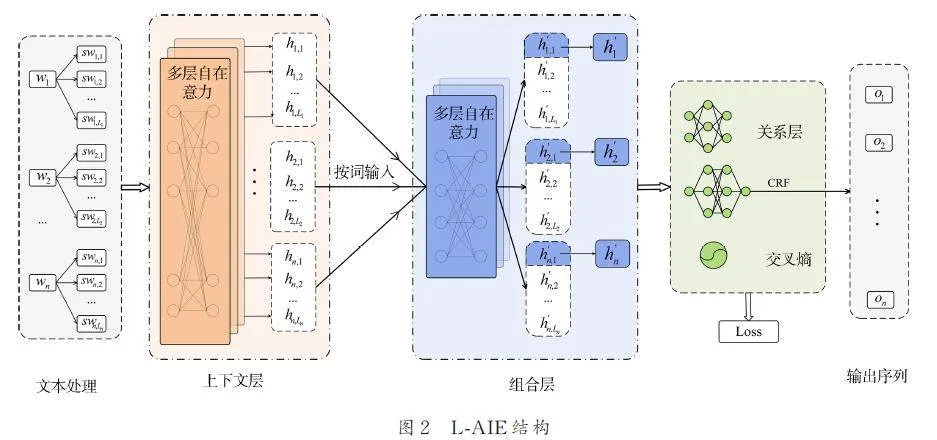
L-AIE 共有5 個部分:(1) 文本處理;(2) 上下文層;(3) 組合層;(4) 關系層;(5) CRF 解碼層.L-AIE 的結構如圖2 所示. L-AIE 將CTI 句子拆分為子詞序列. 上下文層提取子詞序列中的上下文信息. 組合層組合同個單詞下所有子詞的特征,使輸出序列長度與標簽序列匹配. 最后,CRF 解碼層[38,39]進行解碼. 關系層只存在于訓練階段,它增強了L-AIE 區分不同IOC 類別的能力.
3. 1 文本處理
L-AIE 對句子進行了2 步細致的處理. 步驟1,對句子進行分詞,并處理標點符號;步驟2,每個單詞通過Word Piece 算法[40]拆分為子詞. 舉個例子,例子中符號“/”表示拆分:
(1) Phishing domain www. googles. com(. 原句);
(2) Phishing/domain/www. googles. com/.(步驟1);
(3) Phishing/domain/www/. /googles/. /com/.( 步驟2).
域名””www. googles. com”只會出現在個別CTI 中,因為同個IOC 幾乎不被重復使用. 該域名經過Word Piece 算法后被分為5 個子詞,這些子詞會重復出現,其特征可以被重用. 子詞拆分主要發生在IOC 上,而常見單詞會被完整保留. 設CTI 句子S =[ w1,w2,. . . ,wn ],其中wi 表示經過步驟1之后的第i個單詞. 經過步驟2 之后,如式(1)所示.
S =[ sw1,1,sw1,2,...,sw1,l1,...,swn,ln ] (1)
其中,swi,j 是wi 的子詞;li 是wi 子詞的個數. 最終的子詞序列S 是后續層的輸入. 這種處理的優點是不僅解決了IOC 重復出現頻率低的問題,而且對于不同的子詞,表征的每個維度都可以充分利用,都包含上下文信息.
3. 2 上下文層
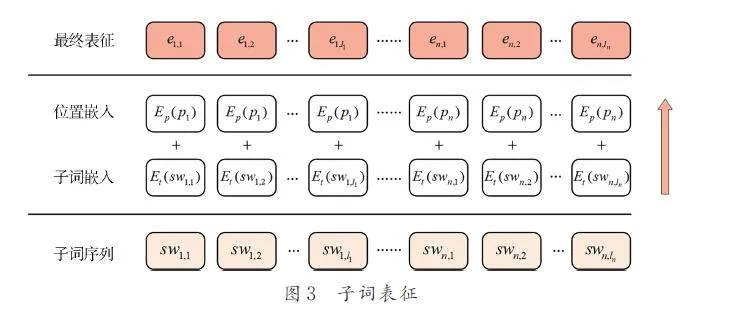
上下文層的目標是充分提取CTI 語句的上下文語義. 詳細的子詞表征過程如圖3 所示.
對于子詞序列S,有2 種不同的嵌入:子詞嵌入和位置嵌入. 子詞嵌入獲得每個子詞的表示向量.位置嵌入則一般按序列順序來標識,比如sw1,1 和sw1,2 具有不同的位置嵌入,但這種做法破壞了子詞之間的關聯性. 為了更好地聚合同單詞的特征,L-AIE 中同個單詞的所有子詞共享1 個位置嵌入,即pi,j = pi,j+ 1 = … = pi,li ≠ pi + 1,j,其中pi,j 是子詞swi,j 的位置,簡寫為pi. 最終子詞嵌入和位置嵌入相加,公式表示如下.
ei,j = Et ( swi,j )+ Ep ( pi ) (2)
其中,Et 和Ep 分別為子詞嵌入矩陣和位置嵌入矩陣. 表征e 被傳入后續的注意力層中.
注意力機制能夠更加關注IOC 或與其相關的重要子詞,減少非關鍵詞的影響. 計算過程如下,設hi =[ hi1,hi2,…,hin* ] 表示第i 層隱藏狀態序列,其中hi ∈R n* × m,n* 為子詞序列的長度,通常大于單詞序列的長度n,m 表示隱藏狀態的維度. 第i 層的注意力值計算公式如下.
其中,softmax 為歸一化指數函數;Att 為計算注意力函數;W iq,W iv,W iv 都是權重矩陣,上標T 表示矩陣轉置;根號 dk 表示k 的維度,在本文中等于m. 注意力值會輸入到后續全連接層中進行計算,最終輸出hi + 1.
3. 3 組合層
由于一些單詞被拆分為幾個子詞,標簽序列和子詞序列的長度不匹配導致無法解碼. 因此,LAIE把同個單詞所有子詞的隱藏狀態作為1 組,在每組內再次通過自注意力計算得到1 個表征. 該表征包含所有子詞的特征語義.
設上下文層的最后輸出表示為h =[ h1,1,h1,2,…,h1,l 1,…,hn,l 1 ]. 首先對隱藏狀態分組,例如,[ h1,1,h1,2,…,h1,l1 ] 是單詞w1 的子詞表征序列,它們被分為1 組,獨立輸入到組合層中進行計算,組合層輸出序列的第1 個隱藏狀態h'1,1 作為w1 的最終表征. 因為注意力是全局的,每個子詞都關注其他所有子詞,習慣上取第1 個隱藏狀態作為表征.組合后的序列h'=[ h'1,1,h'2,1,…,h'n,1 ]為整個句子的最終表征,其長度與標簽序列相等.
需要注意的是,如果一個單詞沒有被拆分為多個子詞,則不需要通過組合層來組合表征. 本文也考慮了池化等無參數的函數,但會導致嚴重的過擬合,因此認為在組合子詞時需要使用有參數的模型結構.
3. 4 關系層
L-AIE 受小樣本學習的啟發,用關系層增大不同類別IOC 輸出表征的區別. L-AIE 關系層的重點是使上游網絡能夠學習不同類別單詞之間的特征,并在少量數據中得到盡可能大的差異表示. 關系層的輸出不用于預測,所以在預測階段不需要計算關系. 關系層在L-AIE 中是多層全連接網絡.除最后一層外,其余層都使用線性整流函數作為激活函數,符號表示為relu,最后一層使用邏輯斯諦函數生成相似性得分,符號表示為sigmoid. 上述關系層的具體計算過程如圖4 所示.
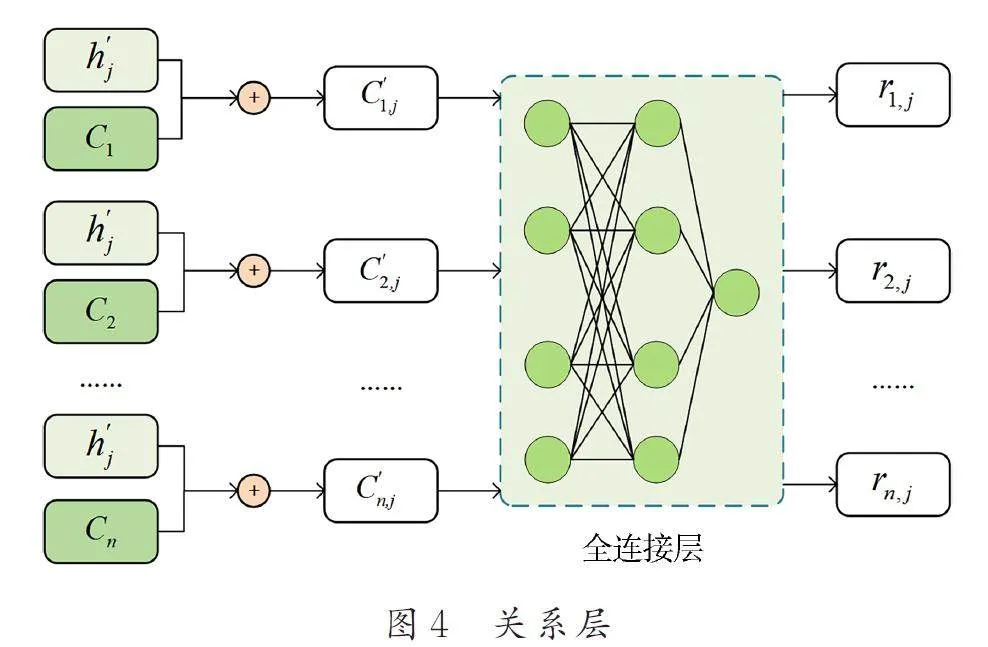
每個IOC 類別(包括“Other”,非IOC)有1 個中心表征,該表證由訓練集中該類IOC 表征平均計算得到,設Ci, i = 1,2,…,k,(簡稱中心),其中k是類別的數量. 對于新的單詞表征h'j,將其與所有中心拼接,得到C 'i,j, i= 1,2,…,k. 關系層將C 'i,j 作為輸入,輸出該表征對于每個中心的相似值ri,j, i = 1,2,…,k. 該值越接近于1,表示該表征與該類別越相似. 計算過程如下式所示.
其中,⊕ 表示向量拼接;L 是全連接層的層數量.關系層旨在使上游得到的表征與其真實類別的中心更類似,與其他中心區別更大.
關系層的損失函數如下式所示,其中tj 是h'j 的真實類別標簽.
因為單詞表征不能獨立計算,需要由包含多個類別IOC 的句子計算得到,復雜度較高. 本文設計了基于內存緩存的方法. 在訓練第1 批數據之前,所有中心都隨機初始化并緩存在內存中. 在訓練每個批次后,基于當前句子對每個類別的表征取平均值,替換內存中原來的值. 如果此批次數據中不存在某些類別,則該類別中心保持不變. 綜上所述,動態更新的過程避免了為每個批次重新計算中心表示. 這樣就不必額外組織數據編排形式,簡化了訓練過程. 具體計算流程如算法1 所示. 其中n 是句子的長度,count 是1 個類別單詞出現的次數,c '是臨時變量.
需要強調的是,關系層僅用在訓練過程以增強L-AIE 的特征區分能力. 由于IOC 的特殊性,如果只使用關系層進行分類,而不依賴L-AIE 的其他模塊,則會導致嚴重的過度擬合,無法泛化使用.
3. 5 CRF 解碼層
CRF 解碼層用于輸出具有最大概率的標簽序列. 組合層的輸出序列被映射到標簽的概率序列pr =[ pr1,pr2,. . . ,prn ]. 直接對取每個單詞的概率取最大值會忽略序列關系,因此L-AIE 使用CRF 來捕獲序列特征. CRF 的損失函數如下式所示.
其中,t 為預測的標簽序列;scorer 是真實標簽序列的分值;N 為所有可能的標簽序列數量;T 是CRF的轉移概率矩陣;T [ i,j ] 表示當前標簽為i,下1 個標簽為j 的概率. 在預測階段,CRF 輸出score 最大的1 個標簽序列.
3. 6 最終的損失函數
對于概率序列pr,除了lossr 和losscrf,還需要交叉熵損失函數lossce. 這是因為不同類別IOC 的實體數量極度不平衡,CRF 無法應對這種情況,會導致模型預測結果嚴重傾斜. L-AIE 在交叉熵中為不同類別的損失值添加權重,以平衡類別數量的差異并加速模型收斂. 類別數量差別過大的情況在IOC抽取中尤為嚴重,因為非IOC 單詞的數量通常是其他的成百甚至數千倍,這使得模型學習了許多非IOC 單詞的特征,忽略了真正IOC 實體. 最終損失值由3 部分組成,如下式.
loss = λce lossce + λcrf losscrf + λr lossr (12)
這里λ 是不同損失值的權重. 在第4 節中,實驗證明了在一定范圍內,每個損失值的權重λ 對模型的最終結果幾乎沒有影響.
4 實驗結果分析
4. 1 數據集
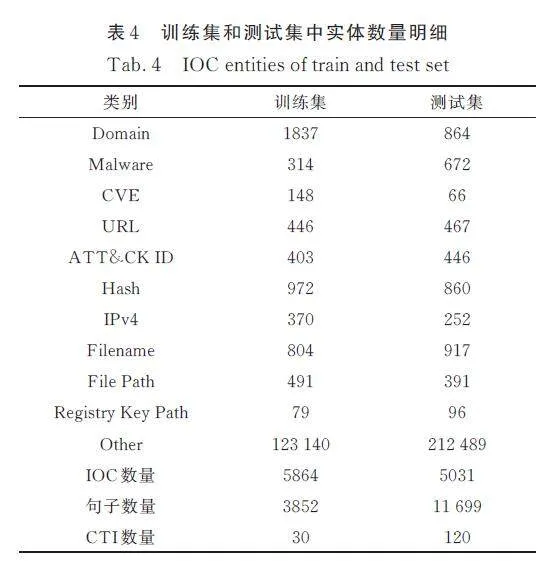
實驗數據集由近年真實發表的150 篇CTI 文章組成. 由專家手動標注并檢查,隨機選擇30 篇作為訓練集,其余作為測試集. 表2 顯示了不同研究所用的數據量.“IOC 數量比”是指訓練集和測試集中IOC 實體數量之比.“訓練集平均每類IOC數量”表示訓練集中每個IOC 類別的平均實體數量. 本文所使用的數據量是最小的,尤其是每類IOC 的平均樣本數量.
L-AIE 在表4 的數據劃分下與其他優秀的IOC 抽取方法進行比較(除主動學習外). 因為同一篇CTI 的語法和IOC 實體非常相似,所以我們用CTI 作為單元劃分數據集,更加客觀. 盡管訓練集和測試集的IOC 數基本平均,但訓練集的語句要少很多,表示語義場景更少,這也是對模型泛化能力的考驗.
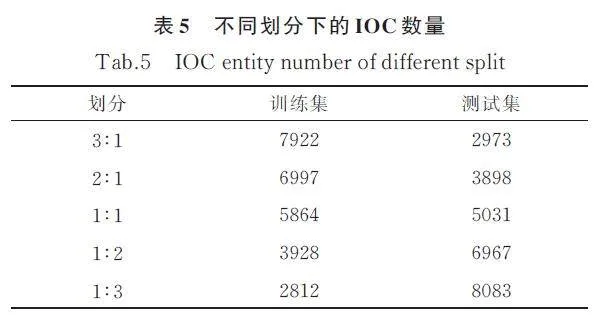
本文還根據IOC 的數量劃分了更小比例的數據集,以驗證L-AIE 在極少量訓練數據下的效果,如表5 所示.“劃分”是指訓練集和測試集之間IOC數量的大致比例.。
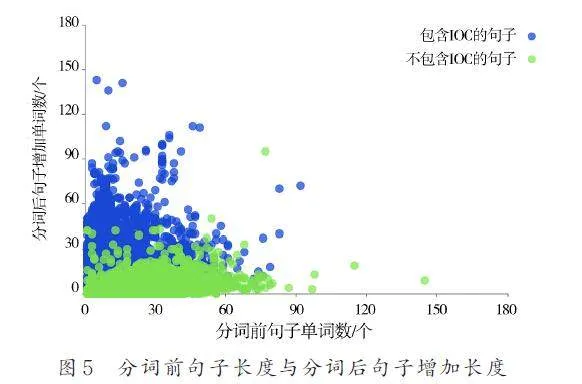
圖5 展示了處理前句子的長度和處理后句子增加長度的關系. 數據集中句子的長度約為1~90個單詞. 包含IOC 的語句在2 步分詞后增加的單詞數遠多于不包含IOC 的語句. 這證實了IOC 并不常見. 而常用單詞很少被拆分為子詞,有時會因為詞根、前綴而拆分.
4. 2 參數設置
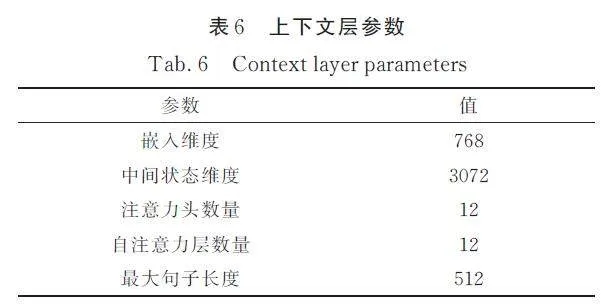
上下文層的參數設置如表6 所示. 組合層僅包含4 個自注意力層,其余參數和上下文層保持一致. 關系層包含2 個全連接層,其映射關系分別為( m × 2,m/2 )和( m/2,1 ),這里m 為嵌入維度,本文為768.
本文使用AdamW 作為優化器. 每個IOC 類別的交叉熵損失函數的權重為1000/nc,其中nc 為該類別IOC 實體的數量. 另外,對于“Other”類別再乘以1/10 的懲罰系數. 對于組合層及其之前的部分,學習率設置為1 × 10-5,之后部分設置為1 ×10-3. 實驗在NVIDIA GeForce RTX 2080 12G 的GPU 上進行. 不同IOC 類別的數量差異很大,Micro指標會消除類別不平衡的影響,因此使用Macro 指標更客觀地表達模型的效果. F1 值是精確度和召回率的調和結果,因此本文主要使用Macro F1 來比較模型的效果.
4. 3 效果比較
為了評估L-AIE 的有效性,在同等實驗條件下,與其他方法進行了對比. 所有模型都不使用預訓練的參數. 實驗表明,不論數據量多少,L-AIE的性能都比其他方法好很多. 對比方法如下.
方法1 spaCy NER:一個快速的基于統計的實體識別工具.
方法2 CRFsuite:用于預測序列數據的CRF的一種實現[41].
方法3 Wang 等[27]使用BERT 作為嵌入層,雙向LSTM 獲得序列信息,CRF 進行解碼,最后使用知識庫進行校正. 本文利用訓練集建立知識庫.
方法4 Zhou 等[28]的方法類似于方法3. 他們在LSTM 和CRF 中間加入了一層GRU,移除了對知識庫的依賴.
方法5 彭嘉毅等[30]的識別模型為雙向LSTM 加CRF,使用最大歸一化對數概率算法選擇訓練數據,因此該方法的訓練數據和其他方法存在一定差異,但總CTI 數量保持一致.
方法6 Zhou 等[10]利用字符嵌入計算出1 個單詞的表征,與詞嵌入拼接,隨后也使用雙向LSTM 與CRF.
方法7 Zhao 等[11]增加了n-gram 來作為表征,粒度更細,隨后也使用雙向LSTM 與CRF.
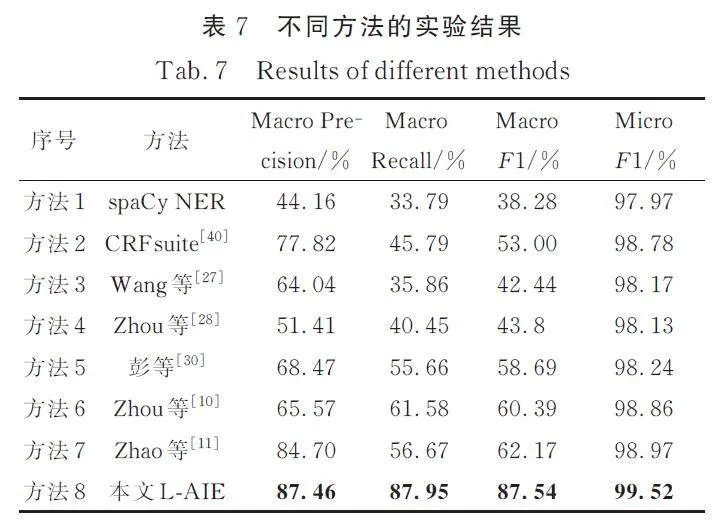
詳細的實驗結果如表7 所示(數據明細見表4). 可以看出L-AIE 取得了最好的效果. 針對Macro F1 值,L-AIE 比其他方法高25. 37%~49. 26%,針對精度和召回率,L-AIE 分別比其他模型高2. 76%~43. 3% 和26. 37%~54. 16%.
方法1 和方法2 面向開放領域,未考慮IOC 的領域特征,精度和召回率表現較差. 方法2 考慮了單詞的前后綴,稍好于方法1,但仍有待改進. 方法3和方法4 利用BERT 模型提取深層上下文信息,在不考慮單詞特征的情況下,其精度勉強達到要求,但召回率仍較低,說明難以識別新的IOC. 方法5通過最大歸一化概率算法主動選擇概率最大的樣本迭代學習,在相同的數據下篩選到更有用的樣本,在數據總量、信息量都相對較少的情況下表現已有提升. 方法6 和方法7 在IOC 實體表征方面更為細致. 方法6 通過拼接單詞嵌入和字符表示的方式,對IOC 進行表征,而方法7 則通過組合ngram的方式進行表征. 因此,這2 種方法相較于其他方法,具有較高的召回率表現.
方法1~方法7 無法全面處理新出現的IOC,它們依賴于大量的標注數據進行訓練. L-AIE 利用多個重復出現的子詞來表示新的IOC,這比其他模型更具語義,可以有效提取未知IOC 的上下文信息,不需要大量的標注數據. 此外,本文中的關系層可以突出不同類別IOC 之間的差異. L-AIE可以從少量的標注數據中提取更多的IOC 類別特征,達到更優秀的提取結果.
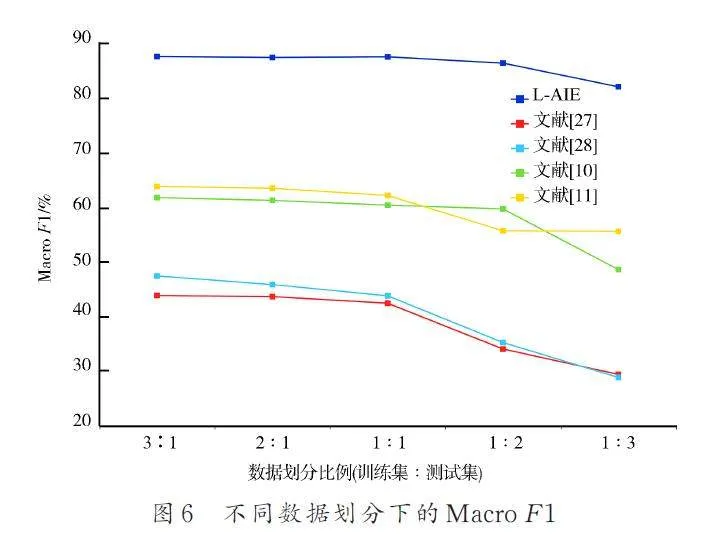
4. 4 數據量的影響
數據集不同劃分比例(詳見表5)的結果如圖6所示. 因為本文實驗設定的訓練樣本總量很少,所以即使在最高比例(3∶1)下,其余方法的效果也不好. 隨著訓練樣本的逐漸減少,所有模型的MacroF1 值逐漸下降,但L-AIE 下降幅度最小. L-AIE 共降低了5% 左右,而其他方法降低了超過10%.
圖6 中反映了另一個問題,當比例從1∶1 開始增加訓練數據時,模型的最終結果并沒有顯著改善. 這是因為本文是根據CTI 中包含的IOC 數量來劃分數據集. 盡管IOC 的數量增加了很多,但相應的句子和上下文并沒有明顯增加. IOC 抽取非常依賴上下文提取語義,因此,僅增加IOC 的數量而不相應地增加CTI 對于提高模型效果并不明顯.
4. 5 不同IOC 類別的抽取結果分析
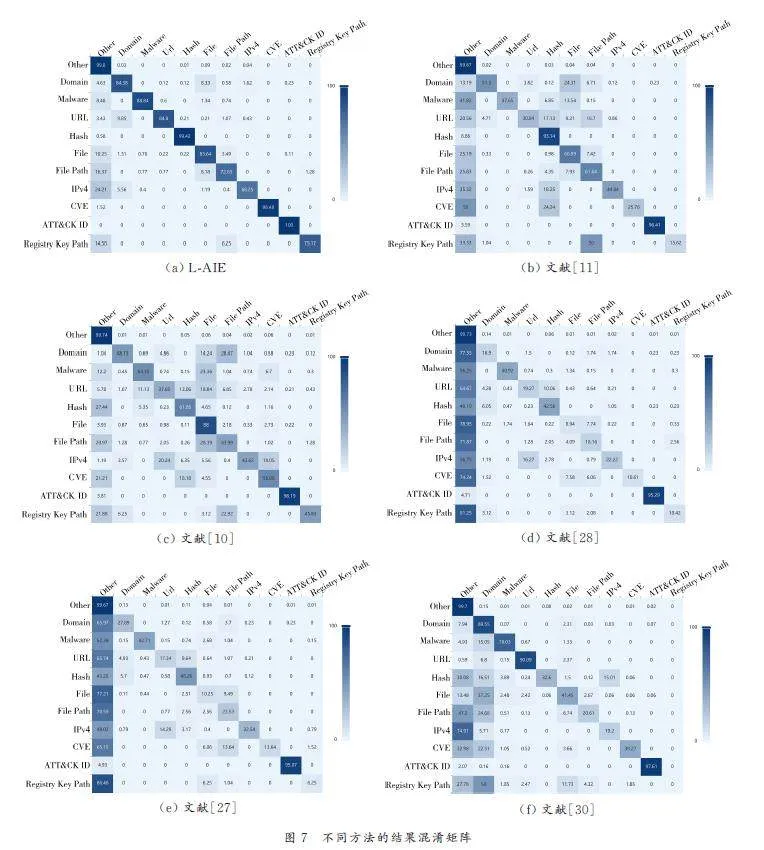
圖7 展示了10 個IOC 種類別結果的混淆矩陣. 每一行表示該類別IOC 被識別為每個類別的百分比. 因此,對角線中的概率越大,識別效果越好. 本文方法L-AIE 對于每種IOC 的識別結果都明顯優于其他方法,尤其對于IPv4 和File Path 等特征不明顯的類別,平均每類IOC 識別準確率比其他方法高出20% 以上.
由于樣本量較小,其他模型無法在少量數據中很好地提取類別特征,因此無法很好地區分IOC類別.“Other”類別具有最多的單詞,模型在學習過程中發生嚴重的傾斜,導致模型的誤判率很高.本文方法L-AIE 很好地解決了這個問題,有效降低了誤判概率.
此外,每類IOC 的抽取效果也有差異.“IPv4”有許多混淆規則,在形式上類似于Domain 和URL. File、File Path 和Registry Key Path 在規則上也非常相似. 這使得它們很容易被誤判. 但對于這些IOC,L-AIE 仍然保持相對較好的效果.
4. 6 消融實驗
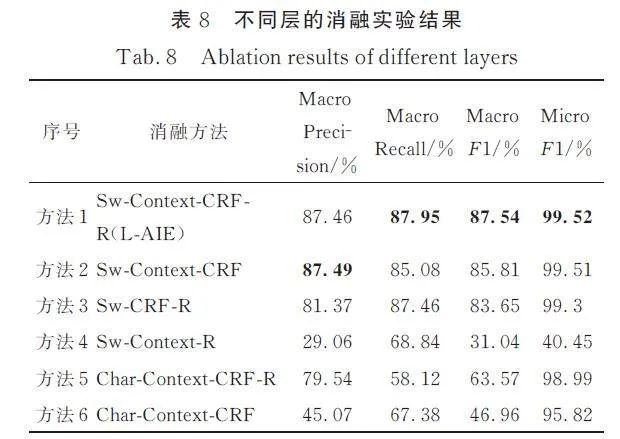
本文方法L-AIE 在解決IOC 抽取問題上有2個策略.(1) 構造以子詞為基本單位的序列來提取上下文,隨后拼接子詞表征,從而解決IOC 不重復出現問題;(2) 基于小樣本學習,在訓練中加入關系層,增強L-AIE 區分不同類別的能力. 表8 中消融方法1 為本文模型L-AIE,其余5 個比較方法用于驗證L-AIE 各部分的有效性. 其中,”Char”表示使用字符表征拼接單詞嵌入;”Sw”表示使用子詞序列,必須與組合層一起使用;”R” 表示訓練階段引入關系層;”Context”表示使用上下文層.
如表8 所示,任意一個改進點都能使抽取效果得到顯著提高. 消融方法1 和消融方法5、消融方法2 和消融方法6 之間的比較表明,子詞粒度更適合IOC,使模型的Macro F1 提高了20% 以上. 由子詞組成的序列可以更好地表示罕見的IOC,更好地結合上下文.
從消融方法1 與消融方法2、消融方法5 與消融方法6 的比較中可以看出,關系層在一定程度上起到區分IOC 類別的作用. 消融方法5 在消融方法6 的基礎上增加關系層,Macro F1 提高了約16%. 消融方法2 的結果已經很好,方法1 增加關系層后依舊可以使Macro F1 提高1. 7%.
消融方法4 不使用CRF,直接使用關系層來解碼標簽序列. 關系層獨立的詞分類忽略了標簽之間的轉移關系,提取效果較差. 這表明獨立于CTI 來判斷一個詞是否為IOC 沒有意義,也說明將小樣本學習直接應用于IOC 提取任務不可行.
沒有上下文層的消融方法3 比消融方法1 稍差. 這是因為CTI 的語境是復雜的,IOC 的具體含義需要通過語境來解讀. 這說明了上下文層的必要性.
4. 7 系數λ 的影響及方法計算速度
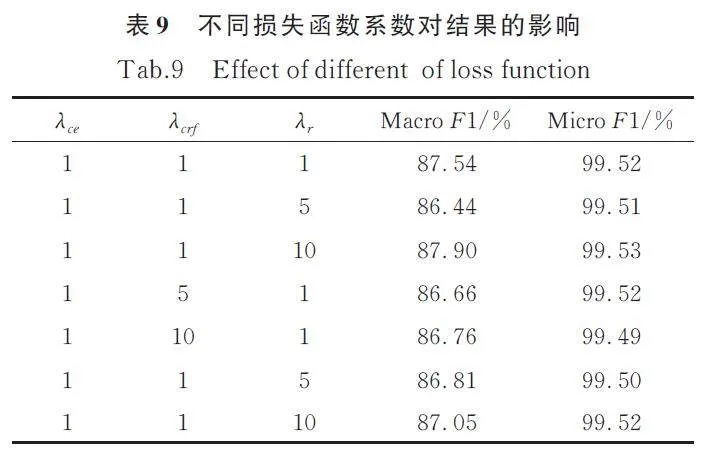
從表9 可知,不同的損失函數系數λ 對最終結果基本沒有影響. 結果只是產生輕微的抖動.
表9 中的許多模型的結果略低于最初的1-1-1系數,說明太大的系數會導致模型在收斂過程中振蕩過大,從而難以達到最佳狀態.
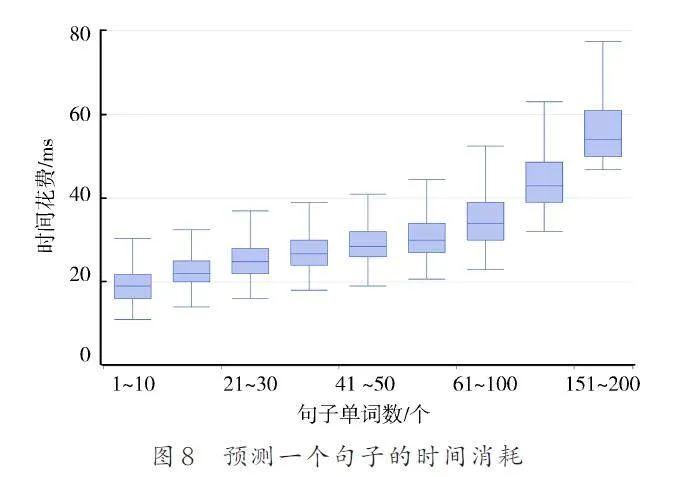
L-AIE 的時間消耗如圖8 所示,計算時間隨著CTI 語句長度的增加而緩慢增加. 由于在預測階段沒有關系層,IOC 提取速度非常快,在編譯優化的開發環境中都在80 ms 以內.
5 結論
本文提出了一種新的端到端IOC 抽取方法L-AIE. 本方法使用子詞序列來獲取上下文語義,用小樣本學習來擴大不同類別IOC 表征的差異.L-AIE 能夠有效處理未知的IOC,大大減少對標注數據的依賴. 實驗結果表明,與其他方法相比,L-AIE 只需要較少的標注數據就可以獲得顯著的IOC 提取效果和較強魯棒性,Macro F1 值為87. 54%,實驗證明了本文方法的優越性和可擴展性. L-AIE 對訓練數據量也是不敏感的,當訓練數據顯著減少時,L-AIE 的效果下降非常小. 此外,我們在訓練階段提出了關系層,這對分別不同類別的IOC 有著明顯的幫助. 總之,L-AIE 在準確地自動化地提取IOC 和減少標注數據投入方面具有實際意義.
目前,在樣本量較小的情況下,L-AIE 對訓練數據標注的質量有一定要求. 未來我們將繼續研究,以減少錯誤樣本對L-AIE 的影響. 此外,我們將努力實現L-AIE 的自學習和迭代升級,以不斷提高其性能,提取更多類別的IOC.
參考文獻:
[1] Tounsi W,Rais H. A survey on technical threat intelligencein the age of sophisticated cyber attacks[J].Computers amp; Security, 2017, 72: 212.
[2] Friedman J,Bouchard M. Definitive guide to cyberthreat intelligence: Using knowledge about adversariesto win the war against targeted attacks[M]. Amsterdam,Netherlands: CyberEdge Group, 2015.
[3] Liao X, Yuan K, Wang X, et al. Acing the iocgame: Toward automatic discovery and analysis ofopen-source cyber threat intelligence[C]//Proceedingsof the 2016 ACM SIGSAC Conference on Com ?puter and Communications Security. Vienna, Austria:ACM, 2016.
[4] Conti M, Dargahi T, Dehghantanha A. Cyber threatintelligence: challenges and opportunities[J]. CyberThreat Intelligence, 2018, 70: 1.
[5] Iklody A, Wagener G, Dulaunoy A, et al. Decayingindicators of compromise[EB/OL].[2018-08-13].http://arxiv. org/abs/1803. 11052.
[6] Shin H, Shim W C, Kim S, et al. Twiti: Social listeningfor threat intelligence[C]//Proceedings of theWeb Conference. Ljubljana Slovenia: ACM, 2021.
[7] Niakanlahiji A, Safarnejad L, Harper R, et al. Iocminer:Automatic extraction of indicators of compromisefrom twitter[C]//Proceedings of the 2019IEEE International Conference on Big Data. Los Angeles,USA: IEEE, 2019.
[8] Wang W P, Ning X K, Song H, et al. An indicatorof compromise extraction method based on deeplearning[J]. Chinese Journal of Computers, 2021,44: 15.[王偉平, 寧翔凱, 宋虹, 等. iAES:面向網絡安全博客的IOC 自動抽取方法[J]. 計算機學報,2021, 44: 15.]
[9] Zhu Z, Dumitras T. Chainsmith: Automaticallylearning the semantics of malicious campaigns by miningthreat intelligence reports[C]//Proceedings ofthe 2018 IEEE European Symposium on Securityand privacy. London,United Kingdom: IEEE, 2018.
[10] Zhou S, Long Z, Tan L, et al. Automatic identificationof indicators of compromise using neural-basedsequence labelling[C]//Proceedings of the 32nd PacificAsia Conference on Language, Information andComputation. Hongkong. China: ACL, 2018.
[11] Zhao J, Yan Q, Liu X, et al. Cyber threat intelligencemodeling based on heterogeneous graph convolutionalnetwork[C]//Proceedings of the 23rd InternationalSymposium on Research in Attacks,Intrusionsand Defenses. San Sebastian, Spain: USENIXAssociation, 2020.
[12] Kotsias J, Ahmad A, Scheepers R. Adopting and integratingcyber-threat intelligence in a commercial organisation[J]. European Journal of Information Systems,2023, 32: 35.
[13] Riesco R,Villagra V A. Leveraging cyber threat intelligencefor a dynamic risk framework [J]. InternationalJournal of Information Security, 2019, 18: 715.
[14] Kumar P,Kumar R,Gupta G P,et al. BDEdge:Blockchain and deep-learning for secure edgeenvisionedgreen CAVs[J]. IEEE Transactions onGreen Communications and Networking, 2022, 6:1330.
[15] Husari G,Al-Shaer E,Chu B,et al. Learning APTchains from cyber threat intelligence[C]//Proceedingsof the 6th Annual Symposium on Hot Topics inthe Science of Security. Nashville Tennessee USA:ACM, 2019.
[16] Kumar P, Kumar R, Gupta G P, et al. P2tif: Ablockchain and deep learning framework for privacypreservedthreat intelligence in industrial iot[J].IEEE Transactions on Industrial Informatics, 2022,18: 6358.
[17] Kumar R,Kumar P,Tripathi R, et al. BDTwin: Anintegrated framework for enhancing security and privacyin cybertwin-driven automotive industrial Internetof Things[J]. IEEE Internet of Things Journal,2021, 9: 17110.
[18] Kumar P,Gupta G P, Tripathi R,et al. DLTIF:Deep learning-driven cyber threat intelligence modelingand identification framework in IoT-enabled maritimetransportation systems[ J]. IEEE Transactions onIntelligent Transportation Systems, 2021, 24: 2472.
[19] Mohsin M,Anwar Z. Where to kill the cyber killchain:An ontology-driven framework for iot securityanalytics[C]//Proceedings of the 2016 InternationalConference on Frontiers of Information Technology(FIT). Islamabad,Pakistan: IEEE, 2016.
[20] Shi H,Wang W,Liu L,et al. Threat intelligencesharing model and profit distribution based on blockchainand smart contracts[C]//Proceedings of the11th International Conference on Computer Engineeringand Networks. Hechi, China: Springer, 2022.
[21] Cha J, Singh S K, Pan Y,et al. Blockchain-based cyberthreat intelligence system architecture for sustainablecomputing[ J]. Sustainability, 2020, 12: 6401.
[22] Xun S, Li X, Gao Y. AITI: An automatic identificationmodel of threat intelligence based on convolutionalneural network[ C]//Proceedings of the 4th InternationalConference on Innovation in Artificial Intelligence.Xiamen, China: ACM, 2020.
[23] Husari G, Al-Shaer E, Ahmed M, et al. Ttpdrill:Automatic and accurate extraction of threat actionsfrom unstructured text of cti sources[C]//Proceedingsof the 33rd Annual Computer Security ApplicationsConference. Orlando, USA: ACM,2017.
[24] Liu C, Wang J, Chen X. Threat intelligenceATTamp;CK extraction based on the attention transformerhierarchical recurrent neural network[J]. AppliedSoft Computing, 2022, 122: 108826.
[25] Neuhaus S,Zimmermann T. Security trend analysiswith cve topic models[C]//Proceedings of the 21stInternational Symposium on Software Reliability Engineering.San Jose, USA: IEEE, 2010.
[26] Hochreiter S, Schmidhuber J. Long short-termmemory[ J]. Neural Computation, 1997, 9: 1735.
[27] Wang X,Liu R,Yang J,et al. Cyber threat intelligenceentity extraction based on deep learning andfield knowledge engineering[C]//Proceedings of the25th International Conference on Computer SupportedCooperative Work in Design. Hangzhou,China: IEEE, 2022.
[28] Zhou Y,Tang Y,Yi M, et al. CTI view: APTthreat intelligence analysis system[J]. Security andCommunication Networks, 2022, 2022: 1.
[29] Devlin J, Chang M W, Lee K, et al. BERT: Pretrainingof deep bidirectional transformers for languageunderstanding[C]//Processdings of the 2019NAACL. Minneapolis, USA: ACL, 2019.
[30] Peng J Y,Fang Y,Huang C,et al. Cyber securitynamed entity recognition based on deep active learning[J]. J Sichuan Univ(Nat Sci Ed), 2019, 56:457.[彭嘉毅, 方勇, 黃誠, 等. 基于深度主動學習的信息安全領域命名實體識別研究[J]. 四川大學學報(自然科學版), 2019, 56: 457.]
[31] Liu J, Yan J, Jiang J, et al. TriCTI: An actionable cyberthreat intelligence discovery system via triggerenhancedneural network [J]. Cybersecurity, 2022,5: 1.
[32] Jadon S. An overview of deep learning architecturesin few-shot learning domain[EB/OL]. [2020-08-21]. https://arxiv. org/abs/2008. 06365.
[33] Wang Y, Yao Q, Kwok J T, et al. Generalizing froma few examples: A survey on few-shot learning[J].ACM Computing Surveys, 2020, 53: 1.
[34] Koch G,Zemel R,Salakhutdinov R. Siamese neuralnetworks for one-shot image recognition[C]// Proceedingsof the 32nd International Conference on MachineLearning. Lille, France: ICML, 2015.
[35] Vinyals O,Blundell C,Lillicrap T, et al. Matchingnetworks for one shot learning [J]. Advances in NeuralInformation Processing Systems, 2016, 29: 3637.
[36] Snell J,Swersky K,Zemel R. Prototypical networksfor few-shot learning[J]. Advances in Neural InformationProcessing Systems, 2017, 30: 4078.
[37] Sung F,Yang Y,Zhang L,et al. Learning to compare:Relation network for few-shot learning[C]//Proceedings of the IEEE Conference on ComputerVision and Pattern Recognition. Salt Lake City,UAS: IEEE, 2018.
[38] Sutton C, McCallum A. An introduction to conditionalrandom fields[J]. Foundations and Trends inMachine Learning, 2012, 4: 267.
[39] Lafferty J, McCallum A, Pereira F. Conditional randomfields: Probabilistic models for segmenting andlabeling sequence data[ C]//Proceedings of the EighteenthInternational Conference on Machine Learning.Williamstown, USA: Morgan Kaufmann, 2001.
[40] Schuster M, Nakajima K. Japanese and Korean voicesearch[C]//2012 IEEE International Conference onAcoustics, Speech and Signal Processing. Kyoto, Japan:IEEE, 2012.
[41] Okazaki N. Crfsuite: A fast implementation of conditionalrandom fields[ EB/OL].[2023-06-28]. http://www. chokkan. org/software/crfsuite/.
(責任編輯: 伍少梅)
基金項目: 國家自然科學基金(U2133208); 國家重點研發計劃(2022YFB3305200); 四川大學-瀘州市人民政府戰略合作項目(2022CDLZ-5)
